Giriş
Retrieval Augmented-Generation (RAG), başlangıcından bu yana dünyayı Storm'un eline geçirdi. RAG, Büyük Dil Modellerinin (LLM'ler) doğru ve gerçek yanıtlar sağlaması veya üretmesi için gerekli olan şeydir. LLM'lerin gerçekliğini RAG ile çözüyoruz; burada LLM'ye bağlamsal olarak kullanıcı sorgusuna benzer bir bağlam vermeye çalışıyoruz, böylece LLM bu bağlamla çalışacak ve gerçeklere dayalı olarak doğru bir yanıt oluşturacaktır. Bunu, verilerimizi ve kullanıcı sorgumuzu vektör yerleştirmeleri biçiminde temsil ederek ve kosinüs benzerliği gerçekleştirerek yapıyoruz. Ancak sorun şu ki, tüm geleneksel yaklaşımlar verileri tek bir yerleştirmede temsil ediyor ve bu da iyi bir sonuç için ideal olmayabilir. geri alma sistemleri. Bu kılavuzda, geleneksel çift kodlayıcılı modellere göre daha iyi doğrulukla veri alma işlemi gerçekleştiren ColBERT'i inceleyeceğiz.
Öğrenme hedefleri
- RAG'da alma işleminin yüksek düzeyde nasıl çalıştığını anlayın.
- Almada tekli yerleştirme sınırlamalarını anlayın.
- ColBERT'in belirteç yerleştirmeleriyle alma bağlamını geliştirin.
- ColBERT'in geç etkileşiminin erişimi nasıl iyileştirdiğini öğrenin.
- Doğru erişim için ColBERT ile nasıl çalışılacağını öğrenin.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
RAG nedir?
Yüksek Lisans'lar, hem anlamlı hem de dilbilgisi açısından doğru metinler üretebilmelerine rağmen, bu Yüksek Lisanslar halüsinasyon adı verilen bir sorundan muzdariptir. Yüksek Lisans'ta halüsinasyon LLM'lerin güvenle yanlış cevaplar ürettiği, yani bizi doğru olduğuna inandıracak şekilde yanlış cevaplar uydurdukları kavramdır. Bu, LLM'lerin uygulamaya konmasından bu yana büyük bir sorun olmuştur. Bu halüsinasyonlar yanlış ve aslında yanlış cevaplara yol açar. Bu nedenle Geri Alma Artırılmış Nesil tanıtıldı.
RAG'da, belgelerin/belge yığınlarının bir listesini alırız ve bu metinsel belgeleri, tek bir vektör yerleştirmenin tek bir belge yığınını temsil ettiği ve bunları, vektör mağazası. Bu parçaları gömmelere kodlamak için gereken modellere kodlama modelleri veya çift kodlayıcılar denir. Bu kodlayıcılar geniş bir veri kümesi üzerinde eğitilir, böylece onları belge parçalarını tek bir vektör gömme gösteriminde kodlayacak kadar güçlü kılar.
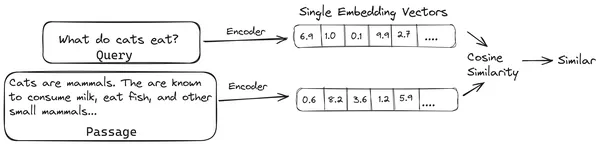
Artık bir kullanıcı LLM'ye bir sorgu sorduğunda, tek bir vektör yerleştirme üretmek için bu sorguyu aynı kodlayıcıya veriyoruz. Bu yerleştirme daha sonra belgenin en alakalı parçasını elde etmek amacıyla belge parçalarının diğer çeşitli vektör yerleştirmeleriyle benzerlik puanını hesaplamak için kullanılır. En alakalı parça veya en alakalı parçaların listesi, kullanıcı sorgusu ile birlikte LLM'ye verilir. LLM daha sonra bu ekstra bağlamsal bilgiyi alır ve ardından kullanıcı sorgusundan alınan bağlamla uyumlu bir yanıt üretir. Bu, LLM tarafından oluşturulan içeriğin gerçekçi olmasını ve gerektiğinde geriye doğru izlenebilecek bir şey olmasını sağlar.
Geleneksel Çift Kodlayıcılarla İlgili Sorun
Tamamen miniLM gibi geleneksel Kodlayıcı modellerindeki sorun, OpenAI Gömme modelinin ve diğer kodlayıcı modellerinin avantajı, metnin tamamını tek bir vektör gömme temsiline sıkıştırmalarıdır. Bu tek vektör gömme gösterimleri, benzer belgelerin verimli ve hızlı bir şekilde alınmasına yardımcı oldukları için faydalıdır. Ancak sorun, sorgu ile belge arasındaki bağlamsallıkta yatmaktadır. Tek vektör yerleştirme, bir belge öbeğinin bağlamsal bilgisini depolamak için yeterli olmayabilir, dolayısıyla bir bilgi darboğazı yaratabilir.
500 kelimenin 782 boyutunda tek bir vektöre sıkıştırıldığını hayal edin. Böyle bir öbeği tek bir vektör yerleştirmeyle temsil etmek yeterli olmayabilir, dolayısıyla çoğu durumda geri almada ortalamanın altında sonuçlar verir. Tek vektör gösterimi, karmaşık sorgular veya belgeler durumunda da başarısız olabilir. Böyle bir çözüm, belge yığınını veya bir sorguyu tek bir gömme vektörü yerine gömme vektörlerinin bir listesi olarak temsil etmek olabilir; ColBERT burada devreye giriyor.
ColBERT nedir?
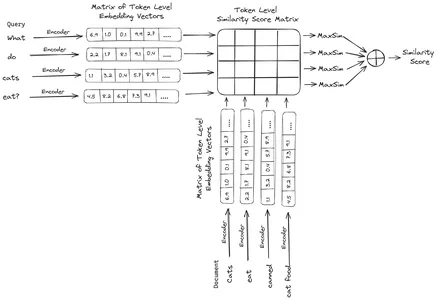
ColBERT (Bağlamsal Geç Etkileşimler BERT), metni çok vektörlü gömme gösteriminde temsil eden bir çift kodlayıcıdır. Bir Sorguyu veya bir Belgenin / küçük bir Belgenin bir kısmını alır ve belirteç düzeyinde vektör yerleştirmeleri oluşturur. Yani, her belirteç kendi vektör yerleştirmesini alır ve sorgu/belge, belirteç düzeyindeki vektör yerleştirmelerinin bir listesine kodlanır. Belirteç düzeyindeki yerleştirmeler önceden eğitilmiş bir sistemden oluşturulur. Bert model dolayısıyla BERT adı.
Bunlar daha sonra vektör veritabanında saklanır. Artık bir sorgu geldiğinde, bunun için belirteç düzeyindeki yerleştirmelerin bir listesi oluşturulur ve ardından kullanıcı sorgusu ile her belge arasında bir matris çarpımı gerçekleştirilir, böylece benzerlik puanlarını içeren bir matris elde edilir. Genel benzerlik, her sorgu belirteci için belge belirteçleri arasındaki maksimum benzerliğin toplamı alınarak elde edilir. Bunun formülünü aşağıdaki resimde görebilirsiniz:
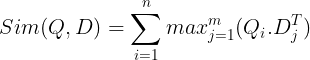
Yukarıdaki denklemde, Sorgu Belirteçleri Matrisi (N belirteç düzeyinde vektör yerleştirmeleri içeren) ile Belge Belirteçleri Matrisinin Transpozesi (M belirteç düzeyinde vektör yerleştirmeler içeren) arasında bir nokta çarpım yaptığımızı görüyoruz ve ardından maksimum benzerliği alıyoruz. her sorgu belirteci için belge belirteçlerini çaprazlayın. Daha sonra tüm bu maksimum benzerliklerin toplamını alırız, bu da bize belge ile sorgu arasındaki nihai benzerlik puanını verir. Bunun etkili ve doğru bir erişim sağlamasının nedeni, burada sorgu ve belge arasında daha bağlamsal anlayışa yer veren belirteç düzeyinde bir etkileşim yaşıyor olmamızdır.
Neden ColBERT İsmi?
Kendisinden önceki gömülü vektörlerin listesini hesapladığımız ve model çıkarımı sırasında yalnızca bu MaxSim (maksimum benzerlik) işlemini gerçekleştirdiğimiz için buna geç etkileşim adımı adını veriyoruz ve belirteç düzeyindeki etkileşimler aracılığıyla daha fazla bağlamsal bilgi elde ettiğimiz için buna bağlamsal adı veriliyor. geç etkileşimler Dolayısıyla Bağlamsal Geç Etkileşimler adı Bert veya ColBERT. Bu hesaplamalar paralel olarak yapılabilir, dolayısıyla verimli bir şekilde hesaplanabilirler. Son olarak, endişe duyulan konulardan biri alandır, yani jeton düzeyindeki vektör yerleştirmelerinin bu listesini depolamak için çok fazla alan gerekir. Bu sorun, yerleştirmelerin artık sıkıştırma adı verilen teknikle sıkıştırıldığı ve böylece kullanılan alanın optimize edildiği ColBERTv2'de çözüldü.
Örnekle Uygulamalı ColBERT
Bu bölümde ColBERT'i uygulamalı olarak ele alacağız ve hatta normal yerleştirme modeline göre nasıl performans gösterdiğini kontrol edeceğiz.
1. Adım: Kitaplıkları İndirin
Aşağıdaki kütüphaneyi indirerek başlayacağız:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- - RAGatouille: Bu kütüphane, ColBERT gibi en gelişmiş (SOTA) erişim yöntemleriyle kullanımı kolay bir şekilde çalışmamıza olanak tanır. Veri kümeleri üzerinde dizinler oluşturma, bunları sorgulama ve hatta verilerimiz üzerinde bir ColBERT modeli yetiştirmemize olanak tanıyan seçenekler sunar.
- LangChain: Bu kütüphane, açık kaynak gömme modelleriyle çalışmamıza izin verecek, böylece diğer gömme modellerinin ColBERT ile karşılaştırıldığında ne kadar iyi çalıştığını test edebiliriz.
- langchain_openai: yükler Dil Zinciri OpenAI için bağımlılıklar. Performansını ColBERT'e göre kontrol etmek için OpenAI Embedding modeliyle bile çalışacağız.
- ChromaDB: Bu kütüphane, verilerimiz üzerinde oluşturduğumuz yerleştirmeleri kaydedebilmemiz ve daha sonra sorgu ile saklanan yerleştirmeler arasında anlamsal bir arama yapabilmemiz için ortamımızda bir vektör mağazası oluşturmamıza olanak tanıyacaktır.
- not: Bu kütüphane verimli tensör matris çarpımları için gereklidir.
- cümle dönüştürücüler ve tiktoken Açık kaynak gömme modellerinin düzgün çalışması için kütüphaneye ihtiyaç vardır.
Adım 2: Önceden Eğitilmiş Modeli İndirin
Bir sonraki adımda önceden eğitilmiş ColBERT modelini indireceğiz. Bunun için kod şöyle olacak
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Öncelikle RAGPretrainedModel sınıfını RAGatouille kütüphanesinden içe aktarıyoruz.
- Daha sonra .from_pretrained() adını veriyoruz ve model adını yani “colbert-ir/colbertv2.0” veriyoruz.
Yukarıdaki kodu çalıştırmak bir ColBERT RAG modelini başlatacaktır. Şimdi bir Vikipedi sayfası indirelim ve oradan geri alma işlemini gerçekleştirelim. Bunun için kod şöyle olacaktır:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille, get_wikipedia_page adında, bir dize alan ve karşılık gelen Wikipedia sayfasını alan kullanışlı bir işlevle birlikte gelir. Burada Elon Musk'taki Wikipedia içeriğini indirip değişken belgede saklıyoruz. Belgede bulunan kelime sayısını ve belgenin ilk birkaç satırını yazdıralım.
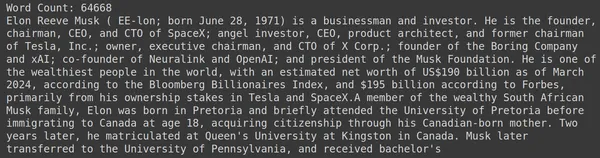
Burada çıktıyı resimde görebiliriz. Elon Musk'un Wikipedia sayfasında toplam 64,668 kelimenin bulunduğunu görebiliyoruz.
Adım 3: Dizin Oluşturma
Şimdi bu belge üzerinde bir indeks oluşturacağız.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Burada belgemizi indekslemek için RAG'ın .index() fonksiyonunu çağırıyoruz. Bunun için aşağıdakileri geçiyoruz:
- Toplamak: Bu, indekslemek istediğimiz belgelerin bir listesidir. Burada yalnızca bir belgemiz var, dolayısıyla tek bir belgenin listesi.
- belge_kimlikleri: Her belge benzersiz bir belge kimliği bekler. Belge Elon Musk ile ilgili olduğu için burada elon_musk adını veriyoruz.
- document_metadatas: Her belgenin kendi meta verileri vardır. Bu yine her bir sözlüğün belirli bir belge için anahtar-değer çifti meta verilerini içerdiği sözlüklerin bir listesidir.
- dizin_adı: Oluşturduğumuz indexin adı. Adını Elon2 koyalım.
- max_document_size: Bu, yığın boyutuna benzer. Her bir belge öbeğinin ne kadar olması gerektiğini belirtiriz. Burada 256 değerini veriyoruz. Eğer herhangi bir değer belirtmezsek varsayılan yığın boyutu olarak 256 alınacaktır.
- split_documents: Bu bir boolean değeridir; True, belgemizi verilen yığın boyutuna göre bölmek istediğimizi, False ise tüm belgeyi tek bir yığın halinde depolamak istediğimizi belirtir.
Yukarıdaki kodu çalıştırmak, belgemizi parça başına 256 boyutunda parçalayacak, ardından bunları ColBERT modeli aracılığıyla gömecek, bu da her parça için belirteç düzeyinde vektör yerleştirmelerin bir listesini üretecek ve son olarak bunları bir dizinde saklayacak. Bu adımın çalışması biraz zaman alacaktır ve GPU varsa hızlandırılabilir. Son olarak indeksimizin saklandığı bir dizin oluşturur. Burada dizin “.ragatouille/colbert/indexes/Elon2” olacaktır.
Adım 4: Genel Sorgu
Şimdi aramaya başlayacağız. Bunun için kod şöyle olacak
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Burada öncelikle RAG nesnesinin .search() metodunu çağırıyoruz.
- Buna sorgu adı, k (alınacak belge sayısı) ve aranacak dizin adını içeren değişkenleri veriyoruz.
- Burada “Elon Musk hangi şirketleri buldu?” sorgusunu sağlıyoruz. Elde edilen sonuç; içerik, puan, sıralama, document_id,passage_id ve document_metadata gibi anahtarları içeren sözlük formatındaki bir listede olacaktır.
- Bu nedenle, alınan belgeleri düzgün bir şekilde yazdırmak için aşağıdaki kodla çalışıyoruz.
- Burada sözlüklerin listesini inceliyoruz ve belgelerin içeriğini yazdırıyoruz
Kodu çalıştırmak aşağıdaki sonuçları üretecektir:
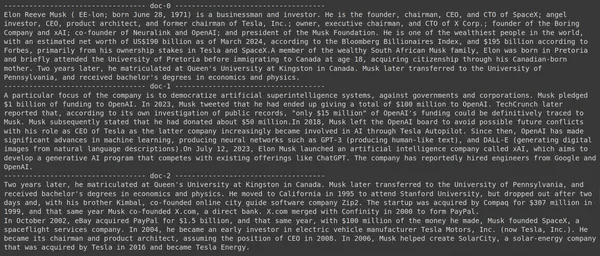
Resimde ilk ve son belgenin tamamen Elon Musk'un kurduğu farklı şirketleri kapsadığını görebiliyoruz. ColBERT, sorguyu yanıtlamak için gereken ilgili parçaları doğru bir şekilde almayı başardı.
Adım 5: Özel Sorgu
Şimdi bir adım daha ileri gidelim ve ona spesifik bir soru soralım.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])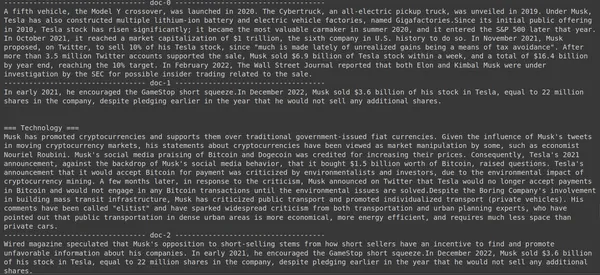
Burada yukarıdaki kodda Tesla Elon'un Aralık 2022'de kaç hisse senedi değerinde satıldığına dair çok spesifik bir soru soruyoruz. Çıktısını burada görebiliyoruz. Doküman-1 sorunun cevabını içermektedir. Elon, Tesla'daki 3.6 milyar dolarlık hissesini sattı. ColBERT yine verilen sorgu için ilgili parçayı başarılı bir şekilde almayı başardı.
Adım 6: Diğer Modelleri Test Etme
Şimdi aynı soruyu hem açık kaynaklı hem de kapalı diğer gömme modelleriyle deneyelim:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Modeli öncelikle Transformers kütüphanesinden AutoModel sınıfı üzerinden indirerek başlıyoruz.
- Daha sonra model_name ve model_kwargs'ı ilgili değişkenlerde saklarız.
- Şimdi bu modelle LangChain'de çalışmak için HuggingFaceEmbeddings'i şuradan içe aktarıyoruz: Dil Zinciri ve ona model adını ve model_kwargs'ı verin.
Bu kodu çalıştırmak, onunla çalışabilmemiz için Jina yerleştirme modelini indirip yükleyecektir.
Adım 7: Yerleştirmeler Oluşturun
Şimdi belgemizi bölmeye başlamamız, ardından ondan gömmeler oluşturmamız ve bunları Chroma vektör deposunda saklamamız gerekiyor. Bunun için aşağıdaki kodla çalışıyoruz:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- LangChain kütüphanesinden Chroma ve RecursiveCharacterTextSplitter'ı içe aktararak başlıyoruz
- Daha sonra RecursiveCharacterTextSplitter'ın .from_tiktoken_encoder'ını çağırıp ona chunk_size ve chunk_overlap'ı ileterek bir text_splitter örneği oluştururuz.
- Burada ColBERT'e sağladığımız chunk_size'ın aynısını kullanacağız.
- Daha sonra bu text_splitter'ın .split_text() metodunu çağırıp ona Elon Musk hakkında Wikipedia bilgileri içeren belgeyi veriyoruz. Daha sonra belgeyi verilen yığın boyutuna göre böler ve son olarak Belge Parçalarının listesi splits değişkeninde saklanır.
- Son olarak bir vektör deposu oluşturmak için Chroma sınıfının .from_texts() fonksiyonunu çağırıyoruz. Bu fonksiyona bölmeleri, yerleştirme modelini ve koleksiyon_adı'nı veriyoruz.
- Şimdi, vektör depolama nesnesinin .as_retriever() fonksiyonunu çağırarak ondan bir alıcı yaratıyoruz. k değeri için 3 veriyoruz
Bu kodu çalıştırmak belgemizi alacak, onu parça başına 256 boyutunda daha küçük belgelere bölecek ve ardından bu küçük parçaları Jina yerleştirme modeliyle gömecek ve bu gömme vektörlerini kroma vektör deposunda saklayacak.
Adım 8: Bir Retriever Oluşturma
Son olarak ondan bir av köpeği yaratıyoruz. Şimdi bir vektör araması yapıp sonuçları kontrol edeceğiz.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)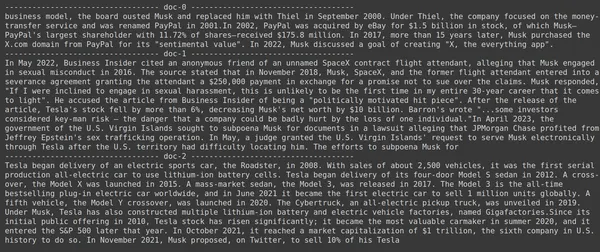
- Retriever nesnesinin .get_relevent_documents() fonksiyonunu çağırıp ona aynı sorguyu veriyoruz.
- Daha sonra alınan ilk 3 belgeyi düzgün bir şekilde yazdırıyoruz.
- Resimde Jina Embedder'ın popüler bir yerleştirme modeli olmasına rağmen sorgumuzun geri alımının zayıf olduğunu görüyoruz. Doğru belge parçalarının alınmasında başarılı olunamadı.
Her bir parçayı tek bir vektör yerleştirme olarak temsil eden yerleştirme modeli Jina ile her bir parçayı simge düzeyinde yerleştirme vektörlerinin bir listesi olarak temsil eden ColBERT modeli arasındaki farkı açıkça görebiliriz. ColBERT bu durumda açıkça daha iyi performans gösteriyor.
Adım 9: OpenAI'nin Yerleştirme Modelini Test Etme
Şimdi OpenAI Gömme modeli gibi kapalı kaynaklı bir yerleştirme modeli kullanmayı deneyelim.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Buradaki kod az önce yazdığımız koda çok benziyor
- Tek fark, ortam değişkenini ayarlamak için OpenAI API anahtarını aktarmamızdır.
- Daha sonra LangChain'den içe aktararak OpenAI Embedding modelinin bir örneğini oluşturuyoruz.
- Ve koleksiyon adını oluştururken farklı bir koleksiyon adı veriyoruz, böylece OpenAI Embedding modelinden gelen yerleştirmeler farklı bir koleksiyonda saklanıyor.
Bu kodu çalıştırmak belgelerimizi tekrar alacak, onları 256 boyutunda daha küçük belgelere ayıracak ve ardından bunları OpenAI gömme modeliyle tek vektör gömme gösterimine gömecek ve son olarak bu yerleştirmeleri Chroma Vector Store'da depolayacak. Şimdi diğer soruya ilgili belgeleri getirmeye çalışalım.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)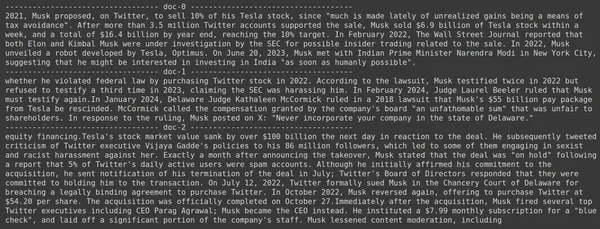
- Alınan parçalarda beklediğimiz cevabın bulunmadığını görüyoruz.
- Birinci parça, 2022'deki Tesla hisse senetleri hakkında bilgi içeriyor ancak Elon'un bunları satmasından bahsetmiyor.
- Aynı şeyi kalan iki belge parçasında da görmek mümkün; içerdikleri bilgiler Tesla ve hisseleri hakkında ancak beklediğimiz bilgi bu değil.
- Yukarıda alınan parçalar, LLM'nin sunduğumuz sorguyu yanıtlaması için bağlam sağlamayacaktır.
Burada bile tek vektörlü gömme gösterimi ile çok vektörlü gömme gösterimi arasında açık bir fark görebiliriz. Çoklu yerleştirme gösterimleri, karmaşık sorguları net bir şekilde yakalar ve bu da daha doğru alımlara olanak sağlar.
Sonuç
Sonuç olarak ColBERT, metni belirteç düzeyinde çok vektörlü yerleştirmeler olarak temsil ederek geleneksel çift kodlayıcı modellere göre alma performansında önemli bir ilerleme göstermektedir. Bu yaklaşım, sorgular ve belgeler arasında daha incelikli bağlamsal anlayışa olanak tanıyarak, daha doğru sonuçların alınmasını sağlar ve LLM'lerde yaygın olarak gözlemlenen halüsinasyon sorununu azaltır.
Önemli Noktalar
- RAG, gerçek yanıt üretimi için bağlamsal bilgi sağlayarak Yüksek Lisans'taki halüsinasyon sorununu giderir.
- Geleneksel çift kodlayıcılar, metnin tamamını tek vektör yerleştirmeleri halinde sıkıştırmak nedeniyle bilgi darboğazından muzdariptir ve bu da ortalamanın altında bir geri alma doğruluğuna neden olur.
- ColBERT, belirteç düzeyinde yerleştirme gösterimiyle, sorgular ve belgeler arasındaki bağlamsal anlayışın daha iyi olmasını sağlayarak, alma performansının iyileşmesine yol açar.
- ColBERT'teki geç etkileşim adımı, belirteç düzeyindeki etkileşimlerle birleştiğinde bağlamsal nüansları dikkate alarak alma doğruluğunu artırır.
- ColBERTv2, geri alma etkinliğini korurken artık sıkıştırma yoluyla depolama alanını optimize eder.
- Uygulamalı deneyler, Jina ve OpenAI Embedding gibi geleneksel ve açık kaynaklı yerleştirme modelleriyle karşılaştırıldığında ColBERT'in alma performansındaki üstünlüğünü göstermektedir.
Sık Sorulan Sorular
C. Geleneksel çift kodlayıcılar metnin tamamını tek vektör yerleştirmeleri halinde sıkıştırarak bağlamsal bilgileri kaybetme potansiyeline sahiptir. Bu, özellikle karmaşık sorgular veya belgelerle ilgili olarak alma görevlerindeki etkinliğini sınırlar.
A. ColBERT (Bağlamsal Geç Etkileşimler BERT), simge düzeyinde vektör yerleştirmeleri kullanarak metni temsil eden iki kodlayıcılı bir modeldir. Sorgular ve belgeler arasında daha incelikli bağlamsal anlayışa olanak tanıyarak alma doğruluğunu artırır.
A. ColBERT, sorgular ve belgeler için belirteç düzeyinde yerleştirmeler oluşturur, benzerlik puanlarını hesaplamak için matris çarpımı gerçekleştirir ve ardından belirteçler arasındaki maksimum benzerliğe dayalı olarak en alakalı bilgileri seçer. Bu, bağlamsal anlayışla etkili erişime olanak tanır.
C. ColBERTv2, geri alma doğruluğunu korurken belirteç düzeyindeki yerleştirmeler için depolama gereksinimlerini azaltarak, artık sıkıştırma yöntemi yoluyla Alanı optimize eder.
C. ColBERT ile kolaylıkla çalışmak için RAGatouille gibi kütüphaneleri kullanabilirsiniz. Belgeleri ve sorguları dizine ekleyerek etkili erişim görevlerini gerçekleştirebilir ve bağlama uygun, doğru yanıtlar oluşturabilirsiniz.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

