
Kaynak: hampiksel.com
Konuşmalı Yapay Zeka, birçok endüstri ve kullanım senaryosunda ölçeklenebilirliği nedeniyle çok fazla ilgi ve ilgi uyandıran bir LLM uygulamasıdır. Konuşma sistemleri onlarca yıldır mevcut olsa da, Yüksek Lisanslar bunların geniş çapta benimsenmesi için gereken kaliteyi getirdi. Bu makalede, konuşmaya dayalı yapay zeka uygulamalarını incelemek için Şekil 1'de gösterilen zihinsel modeli kullanacağız (bkz. Bütünsel bir zihinsel modelle yapay zeka ürünleri oluşturma zihinsel modele giriş için). Konuşmaya dayalı yapay zeka sistemlerinin pazar fırsatlarını ve iş değerini göz önünde bulundurduktan sonra, veri, LLM ince ayarı ve konuşmaları yalnızca mümkün değil aynı zamanda yararlı kılmak için kurulması gereken konuşma tasarımı açısından ek "makineyi" açıklayacağız. ve keyifli.
1. Fırsat, değer ve sınırlamalar
Geleneksel UX tasarımı, her yeni uygulama için bir öğrenme eğrisi gerektiren çok sayıda yapay UX öğesi, kaydırma, dokunma ve tıklama etrafında inşa edilmiştir. Konuşmaya dayalı yapay zekayı kullanarak bu meşguliyeti ortadan kaldırabilir, bunun yerine farklı uygulamalar, pencereler ve cihazlar arasındaki geçişleri unutabileceğimiz, doğal olarak akan bir konuşmanın zarif deneyimini koyabiliriz. Farklı sanal asistanlarla (VA'lar) etkileşim kurmak ve görevlerimizi gerçekleştirmek için evrensel ve tanıdık iletişim protokolümüz olan dili kullanırız.
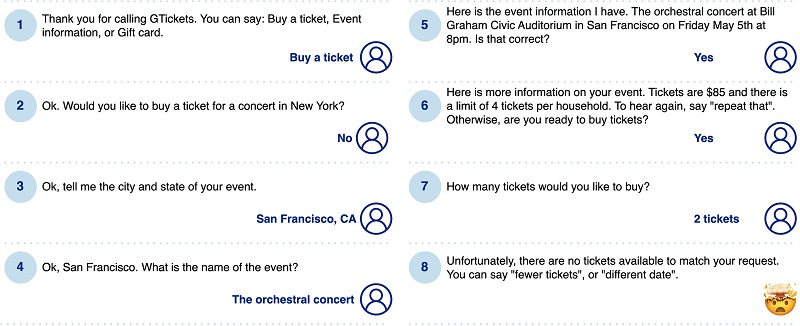
Konuşmaya dayalı kullanıcı arayüzleri tam olarak yeni popüler şeyler değil. İnteraktif sesli yanıt sistemleri (IVR'ler) ve sohbet robotları 1990'lardan bu yana ortalıkta dolaşıyor ve NLP'deki büyük ilerlemeleri, ses ve sohbet arayüzlerine yönelik umut ve gelişme dalgaları takip ediyor. Bununla birlikte, Yüksek Lisans'ın zamanından önce sistemlerin çoğu, kurallara, anahtar kelimelere ve konuşma kalıplarına dayalı olarak sembolik paradigmaya göre uygulanıyordu. Bunlar ayrıca belirli, önceden tanımlanmış bir "yeterlilik" alanıyla sınırlıydı ve bunların dışına çıkan kullanıcılar kısa sürede çıkmaza girecekti. Sonuç olarak, bu sistemler potansiyel arıza noktalarıyla birlikte kazıldı ve birkaç sinir bozucu denemeden sonra birçok kullanıcı bir daha onlara geri dönmedi. Aşağıdaki şekil örnek bir diyaloğu göstermektedir. Belirli bir konser için bilet siparişi vermek isteyen kullanıcı sabırla detaylı bir sorgulama sürecinden geçer ve sonunda konserin biletlerinin tükendiğini öğrenir.
Kolaylaştırıcı bir teknoloji olarak Yüksek Lisanslar, konuşma arayüzlerini yeni kalite ve kullanıcı memnuniyeti düzeylerine taşıyabilir. Konuşma sistemleri artık çok daha geniş bir dünya bilgisi, dilsel yeterlilik ve konuşma yeteneği sergileyebiliyor. Önceden eğitilmiş modellerden yararlanılarak, kuralların, anahtar kelimelerin ve diyalog akışlarının derlenmesi gibi sıkıcı çalışmanın yerini artık LLM'nin istatistiksel bilgisi aldığından, çok daha kısa zaman aralıklarında da geliştirilebilirler. Diyaloğa dayalı yapay zekanın geniş ölçekte değer sağlayabileceği iki önemli uygulamaya bakalım:
- Müşteri desteği ve daha genel olarak, sıklıkla benzer isteklerde bulunan çok sayıda kullanıcı tarafından kullanılan uygulamalar. Burada müşteri desteğini sağlayan şirket, kullanıcıya karşı açık bir bilgi avantajına sahiptir ve bunu daha sezgisel ve keyifli bir kullanıcı deneyimi yaratmak için kullanabilir. Bir uçuş için yeniden rezervasyon yapılması durumunu düşünün. Oldukça sık uçan biri olarak bu, yılda 1-2 kez gerçekleşen bir şeydir. Bu arada, belirli bir havayolunun kullanıcı arayüzünden bahsetmek yerine, sürecin ayrıntılarını unutma eğilimindeyim. Buna karşılık, havayolunun müşteri desteği operasyonlarının ön ve merkezinde yeniden rezervasyon talepleri barındırıyor. Yeniden rezervasyon sürecini karmaşık bir grafik arayüz aracılığıyla açığa çıkarmak yerine, mantığı destekle iletişime geçen müşterilerden "gizlenebilir" ve yeniden rezervasyon yapmak için dili doğal bir kanal olarak kullanabilirler. Tabii ki, daha az tanıdık taleplerin “uzun kuyruğu” olmaya devam edecek. Örneğin, bir iş müşterisini, çok sevdiği köpeğini, rezervasyonu yapılmış bir uçuşa fazla bagaj olarak eklemeye iten ani bir ruh hali değişimini hayal edin. Bu daha bireysel talepler insan temsilcilere aktarılabilir veya sanal asistana bağlı bir dahili bilgi yönetimi sistemi aracılığıyla karşılanabilir.
- Bilgi Yönetimi büyük miktarda veriye dayanmaktadır. Birçok modern şirket için, yıllar süren çalışma, yineleme ve öğrenme sonucunda biriktirdikleri iç bilgi, verimli bir şekilde depolandığı, yönetildiği ve erişildiği takdirde temel bir varlık ve fark yaratan bir unsurdur. İşbirliği araçlarında, dahili wiki'lerde, bilgi tabanlarında vb. gizli olan zengin miktarda veri üzerinde durarak, bunları eyleme dönüştürülebilir bilgiye dönüştürmekte genellikle başarısız olurlar. Çalışanlar ayrılırken, yeni çalışanlar işe alınır ve üç ay önce başlattığınız dokümantasyon sayfasını bir türlü sonuçlandıramazsınız; değerli bilgileriniz entropinin kurbanı olur. Dahili veri labirentinde bir yol bulmak ve belirli bir iş durumunda gerekli olan bilgi parçalarını elde etmek giderek daha zor hale geliyor. Bu durum bilgi çalışanları için büyük verimlilik kayıplarına yol açmaktadır. Bu sorunu çözmek için LLM'leri dahili veri kaynaklarında anlamsal aramayla güçlendirebiliriz. Yüksek Lisans'lar, bu veritabanına karşı soru sormak için karmaşık resmi sorgular yerine doğal dildeki soruların kullanılmasına olanak tanır. Kullanıcılar böylece bilgi tabanının yapısı veya SQL gibi bir sorgulama dilinin sözdizimi yerine kendi bilgi ihtiyaçlarına odaklanabilirler. Metin tabanlı olan bu sistemler, verilerle zengin bir anlamsal alanda çalışarak "kaputun altında" anlamlı bağlantılar kurar.
Bu ana uygulama alanlarının ötesinde, tele sağlık, zihinsel sağlık asistanları ve eğitim amaçlı sohbet robotları gibi kullanıcı deneyimini kolaylaştırabilen ve kullanıcılarına daha hızlı ve daha verimli bir şekilde değer katabilen çok sayıda başka uygulama da bulunmaktadır.
Bu kapsamlı eğitim içeriği sizin için yararlıysa şunları yapabilirsiniz: AI araştırma e-posta listemize abone olun yeni materyal çıkardığımızda uyarılmak.
2. Veri
Yüksek Lisans'lar başlangıçta akıcı küçük konuşmalar veya daha önemli konuşmalar yapmak için eğitilmemiştir. Bunun yerine, her çıkarım adımında aşağıdaki belirteci oluşturmayı öğrenirler ve sonunda tutarlı bir metin elde edilir. Bu düşük seviyeli hedef, insan konuşmasının zorluğundan farklıdır. Konuşma insanlar için inanılmaz derecede sezgiseldir, ancak bir makineye bunu yapmayı öğretmek istediğinizde inanılmaz derecede karmaşık ve incelikli hale gelir. Örneğin, temel niyet kavramına bakalım. Dili kullandığımızda, bunu iletişimsel amacımız olan belirli bir amaç için yaparız; bu, bilgi aktarmak, sosyalleşmek veya birinden bir şey yapmasını istemek olabilir. İlk ikisi bir LLM için oldukça basit olsa da (verilerde gerekli bilgileri gördüğü sürece), ikincisi zaten daha zordur. Yüksek Lisans'ın yalnızca ilgili bilgileri tutarlı bir şekilde birleştirmesi ve yapılandırması gerekmez, aynı zamanda formalite, yaratıcılık, mizah vb. gibi yumuşak kriterler açısından doğru duygusal tonu ayarlaması da gerekir. Bu, konuşma tasarımı için bir zorluktur. (bkz. bölüm 5), bu da verilerin ince ayarını oluşturma göreviyle yakından ilişkilidir.
Klasik dil üretiminden belirli iletişimsel amaçları tanımaya ve bunlara yanıt vermeye geçiş yapmak, konuşma sistemlerinin daha iyi kullanılabilirliğine ve kabulüne yönelik önemli bir adımdır. Tüm ince ayar çabalarında olduğu gibi bu da uygun bir veri setinin derlenmesiyle başlar.
İnce ayar verilerinin (gelecekteki) gerçek dünya veri dağıtımına mümkün olduğunca yakın olması gerekir. Öncelikle konuşma (diyalog) verileri olmalıdır. İkincisi, eğer sanal asistanınız belirli bir alanda uzmanlaşacaksa, gerekli alan bilgisini yansıtan ince ayar verilerini bir araya getirmeye çalışmalısınız. Üçüncüsü, müşteri desteği örneğinde olduğu gibi uygulamanızda sık sık tekrarlanacak tipik akışlar ve istekler varsa, bunların çeşitli örneklerini eğitim verilerinize dahil etmeye çalışın. Aşağıdaki tabloda, konuşma ince ayar verilerinin bir örneği gösterilmektedir. ChatBot için 3K Konuşma Veri Kümesi, Kaggle'da ücretsiz olarak mevcuttur:
Konuşma verilerini manuel olarak oluşturmak pahalı bir girişim haline gelebilir; kitle kaynak kullanımı ve veri oluşturmanıza yardımcı olmak için LLM'leri kullanmak, ölçeği büyütmenin iki yoludur. Diyalog verileri toplandıktan sonra konuşmaların değerlendirilmesi ve açıklamaların eklenmesi gerekir. Bu, modelinize hem olumlu hem de olumsuz örnekler göstermenize ve onu "doğru" konuşmaların özelliklerini seçmeye yönlendirmenize olanak tanır. Değerlendirme mutlak puanlarla yapılabileceği gibi farklı seçeneklerin kendi aralarında sıralanmasıyla da yapılabilir. İkinci yaklaşım, verilere daha doğru ince ayar yapılmasına yol açar çünkü insanlar normalde birden fazla seçeneği sıralamada bunları tek başına değerlendirmekten daha iyidir.
Verileriniz yerinde olduğunda, modelinize ince ayar yapmaya ve onu ek özelliklerle zenginleştirmeye hazırsınız. Bir sonraki bölümde, ince ayar yapmaya, bellekten ve anlamsal aramadan gelen ek bilgileri entegre etmeye ve belirli görevleri yürütmesi için aracıları konuşma sisteminize bağlamaya bakacağız.
3. Konuşma sisteminin kurulması
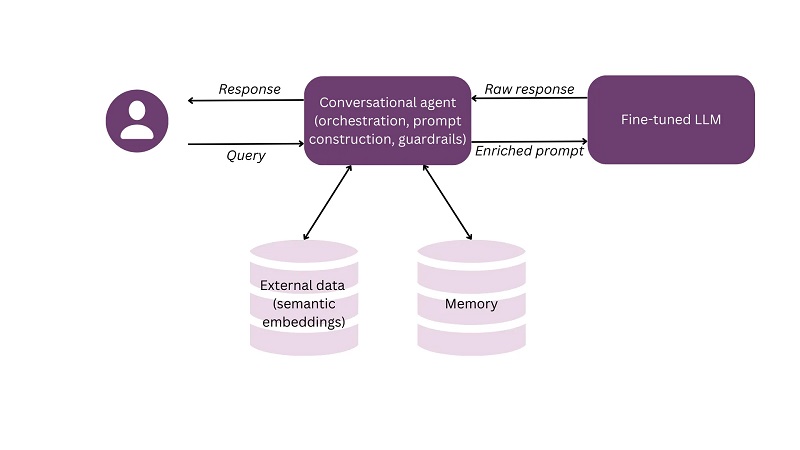
Tipik bir konuşma sistemi, LLM, bellek ve harici veri kaynakları gibi sistemin bileşenlerini ve yeteneklerini düzenleyen ve koordine eden bir konuşma aracısıyla oluşturulur. Konuşmaya dayalı yapay zeka sistemlerinin geliştirilmesi son derece deneysel ve ampirik bir iştir ve geliştiricileriniz verilerinizi optimize etmek, ince ayar stratejisini geliştirmek, ek bileşenler ve geliştirmelerle oynamak ve sonuçları test etmek arasında sürekli olarak ileri geri hareket edeceklerdir. . Ürün yöneticileri ve UX tasarımcıları da dahil olmak üzere teknik olmayan ekip üyeleri de ürünü sürekli olarak test edecek. Müşteri keşfetme faaliyetlerine dayanarak, gelecekteki kullanıcıların konuşma tarzını ve içeriğini tahmin etme konusunda mükemmel bir konumdadırlar ve bu bilgiye aktif olarak katkıda bulunmaları gerekir.
3.1 LLM'nize konuşma becerilerini öğretmek
İnce ayar için, ince ayar verilerinize (bkz. bölüm 2) ve önceden eğitilmiş bir LLM'ye ihtiyacınız vardır. Yüksek Lisans öğrencileri zaten dil ve dünya hakkında çok şey biliyor ve bizim görevimiz onlara konuşmanın ilkelerini öğretmek. İnce ayarda hedef çıktılar metinlerdir ve model, hedeflere mümkün olduğunca benzer metinler oluşturacak şekilde optimize edilecektir. Denetimli ince ayar için öncelikle modelin gerçekleştirmesini istediğiniz konuşma yapay zeka görevini açıkça tanımlamanız, verileri toplamanız ve ince ayar sürecini çalıştırmanız ve yinelemeniz gerekir.
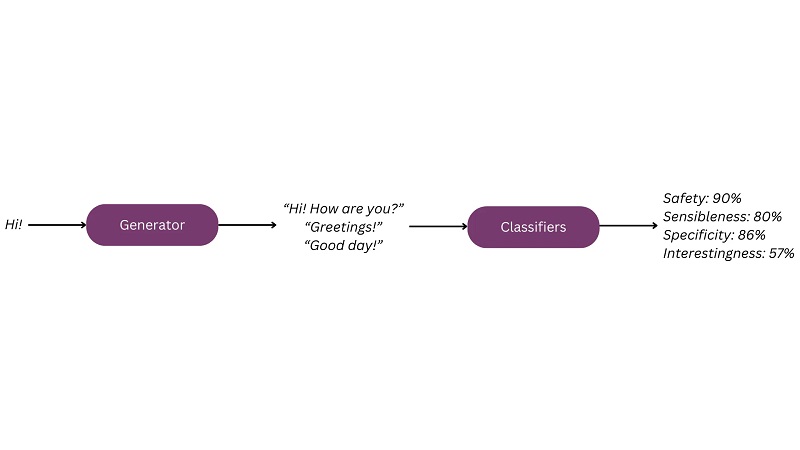
LLM'ler etrafındaki heyecanla birlikte çeşitli ince ayar yöntemleri ortaya çıktı. Konuşma için ince ayarın oldukça geleneksel bir örneği için LaMDA modelinin açıklamasına başvurabilirsiniz.[1] LaMDA'da iki adımda ince ayar yapıldı. İlk olarak diyalog verileri, modele konuşma becerilerini (“üretken” ince ayar) öğretmek için kullanılır. Daha sonra, verilerin değerlendirilmesi sırasında açıklayıcılar tarafından üretilen etiketler, modelin çıktılarını duyarlılık, özgüllük, ilgi çekicilik ve güvenlik (“ayırt edici” ince ayar) gibi istenen niteliklere göre değerlendirebilen sınıflandırıcıları eğitmek için kullanılır. Bu sınıflandırıcılar daha sonra modelin davranışını bu niteliklere yönlendirmek için kullanılır.
Ek olarak, gerçeklere dayalılık - çıktılarını güvenilir dış bilgilere dayandırma yeteneği - Yüksek Lisans'ın önemli bir özelliğidir. Gerçeklere dayalılığı sağlamak ve halüsinasyonu en aza indirmek için LaMDA, harici bilgi gerektiğinde harici bir bilgi alma sistemine yapılan çağrıları içeren bir veri kümesiyle ince ayar yaptı. Böylece model, kullanıcı yeni bilgi gerektiren bir sorgu yaptığında ilk olarak gerçek bilgilere ulaşmayı öğrendi.
Bir diğer popüler ince ayar tekniği ise İnsan Geri Bildiriminden Güçlendirmeli Öğrenmedir (RLHF)[2]. RLHF, LLM'nin öğrenme sürecini basit ama yapay bir sonraki belirteç tahmin görevinden, belirli bir iletişim durumunda insan tercihlerini öğrenmeye doğru "yönlendirir". Bu insan tercihleri doğrudan eğitim verilerinde kodlanmıştır. Ek açıklama süreci sırasında insanlara bilgi istemleri sunulur ve ya istenen yanıtı yazar ya da bir dizi mevcut yanıtı sıralar. Yüksek Lisans'ın davranışı daha sonra insan tercihini yansıtacak şekilde optimize edilir.
3.2 Harici veri ekleme ve anlamsal arama
Modele ince ayar yapmak için konuşmaları derlemenin ötesinde, konuşma sırasında yararlanılabilecek özel verilerle sisteminizi geliştirmek isteyebilirsiniz. Örneğin, sisteminizin patentler veya bilimsel makaleler gibi harici verilere veya müşteri profilleri veya teknik belgeleriniz gibi dahili verilere erişmesi gerekebilir. Bu normalde anlamsal arama (geri almayla artırılmış oluşturma veya RAG olarak da bilinir)[3] yoluyla yapılır. Ek veriler anlamsal yerleştirmeler biçiminde bir veritabanına kaydedilir (bkz. Bu makale yerleştirmelerin açıklaması ve daha fazla referans için). Kullanıcı isteği geldiğinde ön işleme tabi tutularak anlamsal gömmeye dönüştürülür. Anlamsal arama daha sonra istekle en alakalı belgeleri belirler ve bunları istemin bağlamı olarak kullanır. Anlamsal aramayla ek verileri entegre ederek halüsinasyonu azaltabilir ve daha yararlı, gerçeklere dayalı yanıtlar sağlayabilirsiniz. Gömme veritabanını sürekli güncelleyerek, ince ayar sürecinizi sürekli olarak yeniden çalıştırmanıza gerek kalmadan sisteminizin bilgilerini ve yanıtlarını da güncel tutabilirsiniz.
3.3 Bellek ve bağlam farkındalığı
Bir partiye gittiğinizi ve avukat Peter ile tanıştığınızı hayal edin. Heyecanlanırsınız ve şu anda oluşturmayı planladığınız yasal sohbet robotunun satış konuşmasını yapmaya başlarsınız. Peter ilgilenmiş görünüyor, sana doğru eğiliyor, hımm ediyor ve başını sallıyor. Bir noktada uygulamanızı kullanmak isteyip istemediğine dair onun fikrini istersiniz. Güzel konuşma yeteneğinizi telafi edecek bilgilendirici bir ifade yerine şunu duyarsınız: "Uhm... bu uygulama yine ne yapıyordu?"
İnsanlar arasındaki yazılı olmayan iletişim sözleşmesi, konuşma ortaklarımızı dinlediğimizi ve etkileşim sırasında birlikte yarattığımız bağlam üzerinde kendi konuşma edimlerimizi oluşturduğumuzu varsayar. Sosyal ortamlarda bu ortak anlayışın ortaya çıkışı, verimli ve zenginleştirici bir sohbeti karakterize eder. Bir restoran masası rezerve etmek veya tren bileti satın almak gibi daha sıradan ortamlarda, görevi gerçekleştirmek ve kullanıcıya beklenen değeri sağlamak için bu mutlak bir zorunluluktur. Bu, asistanınızın mevcut görüşmenin geçmişini bilmesini gerektirir, ancak aynı zamanda geçmiş konuşmaların da geçmişini bilmesini gerektirir; örneğin, bir görüşme başlattığında kullanıcının adını ve diğer kişisel ayrıntılarını tekrar tekrar sormamalıdır.
Bağlam farkındalığını sürdürmenin zorluklarından biri de çekirdek referans çözümlemesidir, yani zamirlerle hangi nesnelere atıfta bulunulduğunu anlamak. İnsanlar dili yorumlarken sezgisel olarak pek çok bağlamsal ipucu kullanırlar; örneğin, küçük bir çocuğa "Lütfen yeşil topu kırmızı kutudan çıkar ve bana getir" diye sorabilirsiniz; çocuk topu kastettiğinizi anlayacaktır. , kutu değil. Sanal asistanlar için bu görev, aşağıdaki diyalogda da gösterildiği gibi oldukça zorlayıcı olabilir:
Asistanı: Teşekkürler, şimdi uçuş rezervasyonunuzu yapacağım. Uçuşunuz için yemek de sipariş etmek ister misiniz?
Kullanıcı: Uhm… bunu isteyip istemediğime daha sonra karar verebilir miyim?
Asistanı: Üzgünüz, bu uçuş daha sonra değiştirilemez veya iptal edilemez.
Burada asistan zamiri fark edemiyor it Kullanıcının mesajı uçuştan değil yemekten bahsediyor, dolayısıyla bu yanlış anlaşılmayı düzeltmek için bir kez daha tekrarlanması gerekiyor.
3.4 Ek korkuluklar
Arada sırada, en iyi LLM bile yaramazlık yapacak ve halüsinasyon görecektir. Çoğu durumda halüsinasyonlar kesin doğruluk sorunlarıdır ve hiçbir yapay zekanın %100 doğru olmadığını kabul etmeniz gerekir. Diğer yapay zeka sistemleriyle karşılaştırıldığında, kullanıcı ile yapay zeka arasındaki "mesafe" kullanıcı ile yapay zeka arasındaki "mesafe" oldukça küçüktür. Basit bir doğruluk sorunu hızla toksik, ayrımcı veya genel olarak zararlı olarak algılanan bir şeye dönüşebilir. Ek olarak, Yüksek Lisans'ların doğası gereği bir gizlilik anlayışı bulunmadığından, kişisel olarak tanımlanabilir bilgiler (PII) gibi hassas verileri de açığa çıkarabilirler. Ek korkuluklar kullanarak bu davranışlara karşı çalışabilirsiniz. Guardrails AI, Rebuff, NeMo Guardrails ve Microsoft Guidance gibi araçlar, LLM çıktılarına ilişkin ek gereksinimler formüle ederek ve istenmeyen çıktıları engelleyerek sisteminizin risklerini azaltmanıza olanak tanır.
Konuşmalı yapay zekada birden fazla mimari mümkündür. Aşağıdaki şema, ince ayarlı LLM'nin, harici verilerin ve belleğin, aynı zamanda istem oluşturma ve korkuluklardan da sorumlu olan bir konuşma aracısı tarafından nasıl entegre edilebileceğinin basit bir örneğini göstermektedir.
4. Kullanıcı deneyimi ve konuşma tasarımı
Konuşma arayüzlerinin cazibesi, farklı uygulamalardaki basitlik ve tekdüzeliklerinde yatmaktadır. Kullanıcı arayüzlerinin geleceği tüm uygulamaların aşağı yukarı aynı görünmesiyse, UX tasarımcısının işi başarısızlığa mı mahkumdur? Kesinlikle hayır - konuşma, LLM'nize öğretilmesi gereken bir sanattır, böylece kullanıcılarınız için yararlı, doğal ve rahat konuşmalar gerçekleştirebilir. İnsan psikolojisi, dil bilimi ve kullanıcı deneyimi tasarımı bilgimizi birleştirdiğimizde iyi bir konuşma tasarımı ortaya çıkar. Aşağıda, bir konuşma sistemi oluştururken ilk olarak iki temel seçeneği, yani ses ve/veya sohbeti kullanıp kullanmayacağınızı ve sisteminizin daha geniş bağlamını ele alacağız. Daha sonra konuşmaların kendisine bakacağız ve yardımcınızın kişiliğini nasıl tasarlayabileceğinizi, ona yardımcı ve işbirlikçi sohbetler yapmayı öğrettiğinizi göreceğiz.
4.1 Ses ve sohbet
Konuşma arayüzleri sohbet veya ses kullanılarak uygulanabilir. Özetle, ses daha hızlıdır, sohbet ise kullanıcıların gizli kalmasına ve zenginleştirilmiş kullanıcı arayüzü işlevselliğinden faydalanmasına olanak tanır. Bu, bir konuşma uygulaması oluştururken karşılaşacağınız ilk ve en önemli kararlardan biri olduğundan, iki seçeneğe biraz daha derinlemesine bakalım.
İki alternatif arasında seçim yapmak için uygulamanızın kullanılacağı fiziksel ortamı göz önünde bulundurarak başlayın. Örneğin, Nuance Communications'ın sunduğu gibi otomobillerdeki neredeyse tüm konuşma sistemleri neden sese dayanıyor? Çünkü sürücünün elleri zaten meşgul ve sürekli olarak direksiyon ile klavye arasında geçiş yapamıyor. Bu aynı zamanda kullanıcıların uygulamanızı kullanırken kendi etkinliklerinin akışında kalmak istedikleri yemek pişirme gibi diğer etkinlikler için de geçerlidir. Arabalar ve mutfaklar çoğunlukla özel ortamlardır, bu nedenle kullanıcılar mahremiyet endişesi duymadan veya başkalarını rahatsız etmeden sesli etkileşimin keyfini yaşayabilirler. Aksine, uygulamanız ofis, kütüphane veya tren istasyonu gibi halka açık bir ortamda kullanılacaksa ses ilk tercihiniz olmayabilir.
Fiziksel ortamı anladıktan sonra duygusal tarafı düşünün. Ses tonu, ruh halini ve kişiliği iletmek için kasıtlı olarak kullanılabilir; bu sizin bağlamınıza değer katıyor mu? Uygulamanızı eğlence için geliştiriyorsanız, ses eğlence faktörünü artırabilir; zihinsel sağlık asistanı ise daha fazla empati kurabilir ve potansiyel olarak sorunlu bir kullanıcıya daha geniş bir ifade diyapazına izin verebilir. Buna karşılık, uygulamanız kullanıcılara ticaret veya müşteri hizmetleri gibi profesyonel bir ortamda yardımcı olacaksa, daha anonim, metin tabanlı bir etkileşim, daha objektif kararlara katkıda bulunabilir ve sizi aşırı duygusal bir deneyim tasarlama zahmetinden kurtarabilir.
Bir sonraki adım olarak işlevselliği düşünün. Metin tabanlı arayüz, konuşmaları görüntüler gibi diğer medyalarla ve düğmeler gibi grafiksel kullanıcı arayüzü öğeleriyle zenginleştirmenize olanak tanır. Örneğin, bir e-ticaret asistanında, resimlerini ve yapılandırılmış açıklamalarını yayınlayarak ürün öneren bir uygulama, ürünleri sesli olarak açıklayan ve potansiyel olarak tanımlayıcılarını sağlayan bir uygulamadan çok daha kullanıcı dostu olacaktır.
Son olarak, sesli kullanıcı arayüzü oluşturmanın ek tasarım ve geliştirme zorluklarından bahsedelim:
- Kullanıcı girişlerinin Yüksek Lisans ve Doğal Dil İşleme (NLP) ile işlenebilmesinden önce gerçekleşen ek bir konuşma tanıma adımı vardır.
- Ses, daha kişisel ve duygusal bir iletişim aracıdır; bu nedenle, sanal asistanınızın arkasında tutarlı, uygun ve keyifli bir kişilik tasarlama gereksinimleri daha yüksektir ve tını gibi "ses tasarımının" ek faktörlerini de hesaba katmanız gerekecektir. , stres, ton ve konuşma hızı.
- Kullanıcılar sesli görüşmenizin insan konuşmasıyla aynı hızda ilerlemesini bekler. Ses yoluyla doğal bir etkileşim sunmak için sohbete göre çok daha kısa bir gecikme süresine ihtiyacınız vardır. İnsan konuşmalarında sıralar arasındaki tipik boşluk 200 milisaniyedir — Bu hızlı tepki mümkün olabilir çünkü partnerimizin konuşmasını dinlerken sıralarımızı oluşturmaya başlarız. Sesli yardımcınızın etkileşimdeki bu akıcılık derecesine uyması gerekecektir. Bunun aksine, sohbet robotları için saniyeler süren zaman aralıklarıyla rekabet edersiniz ve hatta bazı geliştiriciler, sohbetin insanlar arasında yazılı bir sohbet gibi hissettirmesi için ek bir gecikme bile sunar.
- Ses yoluyla iletişim doğrusal, tek seferlik bir girişimdir; eğer kullanıcınız söylediklerinizi anlamadıysa sıkıcı, hataya açık bir açıklama döngüsüyle karşı karşıya kalırsınız. Bu nedenle dönüşlerinizin mümkün olduğunca kısa, net ve bilgilendirici olması gerekir.
Ses çözümünü tercih ederseniz, yalnızca sohbete kıyasla avantajlarını açıkça anladığınızdan değil, aynı zamanda bu ek zorlukların üstesinden gelebilecek beceri ve kaynaklara da sahip olduğunuzdan emin olun.
4.2 Konuşmaya dayalı yapay zekanız nerede yaşayacak?
Şimdi konuşma yapay zekasını entegre edebileceğiniz daha geniş bağlamı ele alalım. Hepimiz şirket web sitelerindeki sohbet robotlarına aşinayız; bir işletmenin web sitesini açtığımızda ekranınızın sağ tarafında beliren widget'lar. Kişisel olarak benim sezgisel tepkim çoğu zaman Kapat düğmesini aramak olur. Nedenmiş? Bu botlarla ilk "konuşma" denemeleri sırasında, bunların daha spesifik bilgi gereksinimlerini karşılayamayacaklarını öğrendim ve sonunda yine de web sitesini taramam gerekiyor. Hikayenin ahlaki? Bir chatbot'u havalı ve modaya uygun olduğu için oluşturmayın; bunun yerine, kullanıcılarınız için ek değer yaratabileceğinden emin olduğunuz için oluşturun.
Bir şirketin web sitesindeki tartışmalı widget'ın ötesinde, LLM'lerle mümkün hale gelen daha genel sohbet robotlarını entegre etmek için birkaç heyecan verici bağlam vardır:
- Yardımcı pilotlar: Bu asistanlar, programlama için GitHub CoPilot gibi belirli süreçler ve görevler konusunda size rehberlik eder ve tavsiyelerde bulunur. Normalde, yardımcı pilotlar belirli bir uygulamaya (veya ilgili uygulamaların küçük bir paketine) "bağlıdır".
- Sentetik insanlar (ayrıca dijital insanlar): Bu yaratıklar dijital dünyadaki gerçek insanları “taklit eder”. İnsanlar gibi görünüyor, hareket ediyor ve konuşuyorlar ve bu nedenle zengin konuşma becerilerine de ihtiyaçları var. Sentetik insanlar genellikle oyun, artırılmış ve sanal gerçeklik gibi sürükleyici uygulamalarda kullanılır.
- Dijital ikizler: Dijital ikizler, fabrikalar, arabalar veya motorlar gibi gerçek dünyadaki süreçlerin ve nesnelerin dijital “kopyalarıdır”. Gerçek nesnenin tasarımını ve davranışını simüle etmek, analiz etmek ve optimize etmek için kullanılırlar. Dijital ikizlerle doğal dil etkileşimleri, verilere ve modellere daha sorunsuz ve çok yönlü erişime olanak tanır.
- veritabanları: Günümüzde yatırım tavsiyelerinden kod parçacıklarına, eğitim materyallerine kadar her konuda veri mevcut. Çoğu zaman zor olan, kullanıcıların belirli bir durumda ihtiyaç duyduğu çok spesifik verileri bulmaktır. Veritabanlarının grafiksel arayüzleri ya çok kaba tanelidir ya da sonsuz arama ve filtre araçlarıyla kaplıdır. SQL ve GraphQL gibi çok yönlü sorgulama dillerine yalnızca ilgili becerilere sahip kullanıcılar erişebilir. Konuşmalı çözümler, kullanıcıların verileri doğal dilde sorgulamasına olanak tanırken, istekleri işleyen LLM bunları otomatik olarak ilgili sorgulama diline dönüştürür (bkz. Bu makale Text2SQL'in açıklaması için).
4.3 Asistanınıza bir kişilik damgalamak
İnsanlar olarak, insana belli belirsiz benzeyen bir şey gördüğümüzde antropomorfize etmeye, yani ek insani özellikler yüklemeye programlıyız. Dil, insanoğlunun en eşsiz ve büyüleyici yeteneklerinden biridir ve konuşma ürünleri otomatik olarak insanlarla ilişkilendirilecektir. İnsanlar ekranlarının veya cihazlarının arkasında bir kişiyi hayal edeceklerdir ve bu belirli kişiyi kullanıcılarınızın hayal gücüne bırakmamak, bunun yerine ona ürününüz ve markanızla uyumlu tutarlı bir kişilik kazandırmak iyi bir uygulamadır. Bu sürece “kişilik tasarımı” denir.
Persona tasarımının ilk adımı, kişiliğinizin sergilemesini istediğiniz karakter özelliklerini anlamaktır. İdeal olarak, bu zaten eğitim verileri düzeyinde yapılır; örneğin, RLHF kullanırken, modeli ön yargılı hale getirmek için açıklayıcılarınızdan verileri yardımseverlik, nezaket, eğlence vb. özelliklere göre sıralamalarını isteyebilirsiniz. istenilen özellikler. Bu özellikler, ürün deneyimi aracılığıyla markanızı sürekli olarak tanıtan tutarlı bir imaj oluşturmak için marka özelliklerinizle eşleştirilebilir.
Genel özelliklerin ötesinde, sanal asistanınızın “mutlu yol”un ötesinde spesifik durumlarla nasıl başa çıkacağını da düşünmelisiniz. Örneğin, kapsamı dışında kalan kullanıcı isteklerine nasıl yanıt verecek, kendisiyle ilgili sorulara nasıl yanıt verecek ve küfürlü veya kaba dille nasıl başa çıkacak?
Veri açıklayıcıları ve konuşma tasarımcıları tarafından kullanılabilecek, kişiliğiniz hakkında açık dahili yönergeler geliştirmek önemlidir. Bu, uygulamanız birden fazla yineleme ve iyileştirmeden geçerken kişiliğinizi amaca yönelik bir şekilde tasarlamanıza ve ekibiniz genelinde ve zaman içinde tutarlı tutmanıza olanak tanır.
4.4 “İşbirliği ilkesi” ile faydalı konuşmalar yapmak
Gerçekten bir insanla konuşurken, hiç bir tuğla duvarla konuştuğunuz izlenimine kapıldınız mı? Bazen sohbet ortaklarımızın konuşmayı başarıya götürmekle ilgilenmediğini görüyoruz. Neyse ki çoğu durumda işler daha sorunsuz gidiyor ve insanlar, dil filozofu Paul Grice tarafından ortaya atılan "işbirliği ilkesini" sezgisel olarak takip edecekler. Bu prensibe göre birbirleriyle başarılı bir şekilde iletişim kuran insanlar nicelik, nitelik, alaka ve tarz olmak üzere dört ilkeyi takip eder.
Maksimum miktar
Nicelik ilkesi, konuşmacının bilgilendirici olmasını ve gerektiği kadar bilgilendirici katkı yapmasını ister. Sanal asistan açısından bu aynı zamanda konuşmayı aktif olarak ileriye taşımak anlamına da geliyor. Örneğin, bir e-ticaret moda uygulamasından alınan şu pasajı düşünün:
Asistanı: Ne tür giyim ürünleri arıyorsunuz?
Kullanıcı: Turuncu bir elbise arıyorum.
Asistan: Yapmayın: Üzgünüz, şu anda turuncu elbisemiz yok.
Yapın: Üzgünüm, turuncu elbisemiz yok ama sarı renkte harika ve çok rahat bir elbisemiz var: …
Kullanıcı, uygulamanızdan uygun bir öğeyle ayrılmayı umuyor. Tam tanıma uyan öğeleriniz olmadığı için konuşmayı durdurmak, başarı olasılığını ortadan kaldırır. Ancak uygulamanız alternatif öğelerle ilgili önerilerde bulunursa daha yararlı görünecek ve başarılı bir etkileşim seçeneğini açık bırakacaktır.
Özellikle sesli etkileşimlerde, kullanıcının başarı için ihtiyaç duyabileceği tüm bilgileri sağlamak ve etkileşimi gölgeleyebilecek gereksiz bilgilerle kullanıcıyı bunaltmamak arasında doğru dengeyi bulmak önemlidir.
Maksimum kalite
Kalite ilkesi, konuşmacıların dürüst olmalarını ve yanlış olduğuna inandıkları veya yeterli kanıta sahip olmadıkları şeyleri söylememelerini ister. Burada çok fazla öznellik ve kişisel inanç söz konusudur; bu nedenle, bu özdeyiş doğrudan Yüksek Lisans'lara yansıtılamaz. Gördüğümüz gibi yüksek lisans öğrencileri halüsinasyon görme eğilimindedir ve bu risk özellikle konuşma daha az aşina olunan alanlara sürüklendiğinde yüksektir. Yanıltıcı ifadelerden kaçınmak ve konuşmayı tekrar rayına oturtmak için ek korkuluklar kullanılabilir.
alaka düzeyi maksimumu
İlgililik ilkesi bizden - yani, alakalı olmamızı ister. Bir ön koşul olarak sanal asistanın kullanıcının gerçek niyetini anlaması gerekir. İşte bu kuralı ihlal eden bir havayolu asistanının örneği:
Kullanıcı: Yarın sabah Berlin'den Zürih'e uçağa ihtiyacım var.
Asistanı: Tamam, yarın sabah için Berlin'den Zürih'e aşağıdaki uçuşları buldum. BZ36294 sefer sayılı uçuş Berlin'den sabah 6.30'da ayrılıyor ve sabah 8'de Zürih'e varıyor. BZ96294 sefer sayılı uçuş Berlin'den sabah 8'de ayrılıyor ve sabah 9.30'da varıyor. BZ96294 sefer sayılı uçuş Berlin'den sabah 8'de ayrılıyor ve sabah 9.30'da Zürih'e varıyor. BZ95614 sefer sayılı uçuş Berlin'den sabah 11'de ayrılıyor ve saat 12.30'da Zürih'e varıyor. Aktarmalı uçuş imkanı da mevcut, bu durumda Berlin'den saat 11.45'te ayrılıp saat 3'te Zürih'e varacaksınız.
Kullanıcı: Üzgünüm… bunu tekrar tekrarlayabilir misin?
Asistan, kullanıcıyı alakalı olmayabilecek ayrıntılı bilgilerle boğuyor. Bunu bölerek ve kullanıcıya arama alanını sınırlama konusunda rehberlik ederek diyaloğun sindirimi çok daha kolay hale gelir:
Kullanıcı: Yarın sabah Berlin'den Zürih'e uçağa ihtiyacım var.
Asistanı: Tamam, sabah 6.30, 8 ve 11'de kalkan uçuşlar buldum. Hangi saatte ayrılmak istersiniz?
Kullanıcı: Sabah 9'dan önce Zürih'te olmam gerekiyor.
Asistanı: Tamam, BZ36294 uçuşuna binebilirsin. Sabah 6.30'da yola çıkıyor ve sabah 8'de varıyor. Bileti sana mı almalıyım?
Kullanıcı: Evet teşekkürler.
Davranışın maksimumu
Son olarak, üslup ilkesi, konuşma eylemlerimizin açık, özlü ve düzenli olması, ifadenin belirsizliğinden ve belirsizliğinden kaçınılması gerektiğini belirtir. Sanal asistanınız teknik veya dahili jargondan kaçınmalı ve basit, evrensel olarak anlaşılabilir formülasyonları tercih etmelidir.
Grice'ın ilkeleri belirli bir alandan bağımsız olarak tüm konuşmalar için geçerli olsa da, konuşma için özel olarak eğitilmeyen LLM'ler genellikle bunları yerine getirmekte başarısız olur. Bu nedenle eğitim verilerinizi derlerken modelinizin bu ilkeleri öğrenmesini sağlayacak yeterli diyalog örneğine sahip olmak önemlidir.
Konuşma tasarımı alanı oldukça hızlı gelişiyor. İster halihazırda yapay zeka ürünleri geliştiriyor olun ister yapay zekadaki kariyer yolunuzu düşünüyor olun, bu konuyu daha derinlemesine incelemenizi tavsiye ederim (bkz. [5] ve [6]'daki mükemmel girişler). Yapay zeka bir metaya dönüşürken, iyi tasarım ve savunulabilir bir veri stratejisi, yapay zeka ürünleri için iki önemli farklılaştırıcı unsur haline gelecektir.
Özet
Makaleden önemli çıkarımları özetleyelim. Ek olarak, şekil 5'te referans olarak indirebileceğiniz ana noktaların yer aldığı bir "kopya sayfası" sunulmaktadır.
- Yüksek Lisanslar konuşmaya dayalı yapay zekayı geliştirir: Büyük Dil Modelleri (LLM'ler), çeşitli endüstriler ve kullanım örnekleri genelinde konuşmaya dayalı yapay zeka uygulamalarının kalitesini ve ölçeklenebilirliğini önemli ölçüde artırdı.
- Konuşmaya dayalı yapay zeka, çok sayıda benzer kullanıcı isteği içeren (örn. müşteri hizmetleri) veya büyük miktarda yapılandırılmamış veriye (örn. bilgi yönetimi) erişmesi gereken uygulamalara çok fazla değer katabilir.
- Veri: LLM'lerin konuşma görevleri için ince ayarının yapılması, gerçek dünyadaki etkileşimleri yakından yansıtan yüksek kaliteli konuşma verileri gerektirir. Kitle kaynak kullanımı ve LLM tarafından oluşturulan veriler, veri toplamayı ölçeklendirmek için değerli kaynaklar olabilir.
- Sistemi bir araya getirmek: Konuşmaya dayalı yapay zeka sistemlerinin geliştirilmesi, verilerin sürekli optimizasyonunu, ince ayar stratejilerini ve bileşen entegrasyonunu içeren yinelemeli ve deneysel bir süreçtir.
- Yüksek Lisans'lara konuşma becerilerini öğretmek: Yüksek Lisans'lara ince ayar yapmak, onları belirli iletişimsel niyetleri ve durumları tanıma ve bunlara yanıt verme konusunda eğitmeyi içerir.
- Anlamsal aramayla harici veri ekleme: Anlamsal aramayı kullanarak harici ve dahili veri kaynaklarını entegre etmek, bağlamsal olarak daha alakalı bilgiler sağlayarak yapay zekanın yanıtlarını geliştirir.
- Bellek ve bağlam farkındalığı: Etkili konuşma sistemleri, anlamlı ve tutarlı yanıtlar sağlamak için mevcut konuşmanın geçmişini ve geçmiş etkileşimleri takip etmek de dahil olmak üzere bağlam farkındalığını korumalıdır.
- Korkulukların ayarlanması: Sorumlu davranışın sağlanması için, konuşmaya dayalı yapay zeka sistemleri yanlışlıkları, halüsinasyonları ve mahremiyet ihlallerini önlemek için korkuluklar kullanmalıdır.
- Kişilik tasarımı: Konuşma asistanınız için tutarlı bir kişilik tasarlamak, uyumlu ve markalı bir kullanıcı deneyimi yaratmak için çok önemlidir. Persona özellikleri, ürün ve marka özelliklerinizle uyumlu olmalıdır.
- Ses ve sohbet: Ses ve sohbet arayüzleri arasında seçim yapmak, fiziksel ortam, duygusal bağlam, işlevsellik ve tasarım zorlukları gibi faktörlere bağlıdır. Konuşmaya dayalı yapay zekanızın arayüzüne karar verirken bu faktörleri göz önünde bulundurun.
- Çeşitli bağlamlarda entegrasyon: Konuşmaya dayalı yapay zeka, yardımcı pilotlar, sentetik insanlar, dijital ikizler ve veritabanları dahil olmak üzere her biri özel kullanım örnekleri ve gereksinimlere sahip farklı bağlamlara entegre edilebilir.
- İşbirliği İlkesine Uyum: Konuşmalarda nicelik, nitelik, uygunluk ve tarz ilkelerine uymak, konuşmaya dayalı yapay zeka ile etkileşimleri daha yararlı ve kullanıcı dostu hale getirebilir.

Referanslar
[1] Heng-Tze Chen ve ark. 2022. LaMDA: Her Şey İçin Güvenli, Topraklanmış ve Yüksek Kaliteli İletişim Modellerine Doğru.
[2] OpenAI. 2022. ChatGPT: Diyalog için Dil Modellerini Optimize Etme. Erişim tarihi: 13 Ocak 2022.
[3] Patrick Lewis ve ark. 2020. Bilgi Yoğun NLP Görevleri için Erişim Arttırılmış Nesil.
[4] Paul Grice. 1989. Kelimelerin Yolunda Çalışmalar.
[5] Cathy Pearl. 2016. Sesli Kullanıcı Arayüzlerinin Tasarlanması.
[6] Michael Cohen ve ark. 2004. Sesli Kullanıcı Arayüzü Tasarımı.
Not: Aksi belirtilmedikçe tüm görseller yazara aittir.
Bu yazı orijinalinde Veri Bilimine Doğru ve yazarın izniyle TOPBOTS'a yeniden yayınlandı.
Bu makaleyi beğendiniz mi? Daha fazla AI araştırma güncellemesi için kaydolun.
Bunun gibi daha özet makaleler yayınladığımızda size haber vereceğiz.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.topbots.com/redefining-conversational-ai-with-large-language-models/

