Giriş
Büyük dil modelleri (LLM'ler), sürekli gelişen yapay zeka ortamında öne çıkan yenilik temelleridir. Bu modeller, mesela GPT 3etkileyici bir şekilde sergilendi doğal dil işleme ve içerik oluşturma yetenekleri. Ancak potansiyellerinin tamamını kullanmak, karmaşık işleyişini anlamayı ve performanslarını optimize etmek için ince ayar gibi etkili teknikleri kullanmayı gerektirir.
Olarak veri bilimcisi Yüksek Lisans araştırmasının derinliklerine inme tutkusuyla, bu modelleri öne çıkaran püf noktalarını ve stratejileri ortaya çıkarmak için bir yolculuğa çıktım. Bu makalede, LLM'ler için yüksek kaliteli veriler oluşturmanın, etkili modeller oluşturmanın ve gerçek dünya uygulamalarında bunların faydasını en üst düzeye çıkarmanın bazı önemli yönlerini size anlatacağım.

Öğrenme hedefleri:
- Temel modellerden uzmanlaşmış aracılara kadar LLM kullanımının katmanlı yaklaşımını anlayın.
- Güvenlik, takviyeli öğrenme ve Yüksek Lisans'ları veritabanlarına bağlama hakkında bilgi edinin.
- Tutarlı yanıtlar için "LIMA", "Distil" ve soru-cevap tekniklerini keşfedin.
- “phi-1” gibi modellerle gelişmiş ince ayarları kavrayın ve faydalarını öğrenin.
- Hakkında bilgi edinin ölçeklendirme yasaları, önyargı azaltmave model eğilimleriyle mücadele etmek.
İçindekiler
Etkili Yüksek Lisans Programları Oluşturmak: Yaklaşımlar ve Teknikler
Yüksek Lisans alanlarına girerken başvuru aşamalarını tanımak önemlidir. Bana göre bu aşamalar, her katmanın bir öncekinin üzerine inşa edildiği bir bilgi piramidi oluşturuyor. temel model temel taştır; akıllı telefonunuzun tahminli klavyesine benzer şekilde, bir sonraki kelimeyi tahmin etme konusunda üstün olan modeldir.
Sihir, bu temel modeli alıp görevinizle ilgili verileri kullanarak ona ince ayar yaptığınızda gerçekleşir. İşte tam bu noktada sohbet modelleri devreye giriyor. Modeli sohbet konuşmaları veya öğretici örnekler üzerinde eğiterek, onu çeşitli uygulamalar için güçlü bir araç olan sohbet robotu benzeri davranışlar sergilemeye ikna edebilirsiniz.
Özellikle internet oldukça kaba bir yer olabileceğinden güvenlik çok önemlidir. Bir sonraki adım şunları içerir: İnsan Geri Bildiriminden Güçlendirmeli Öğrenim (RLHF). Bu aşama, modelin davranışını insani değerlerle uyumlu hale getirir ve onu uygunsuz veya hatalı yanıtlar vermekten korur.
Piramidin yukarılarına doğru ilerledikçe uygulama katmanıyla karşılaşıyoruz. Yüksek Lisans'ların veritabanlarıyla bağlantı kurarak değerli bilgiler sağlamalarına, soruları yanıtlamalarına ve hatta aşağıdaki gibi görevleri yürütmelerine olanak sağladığı yer burasıdır: kod üretimi or metin özeti.
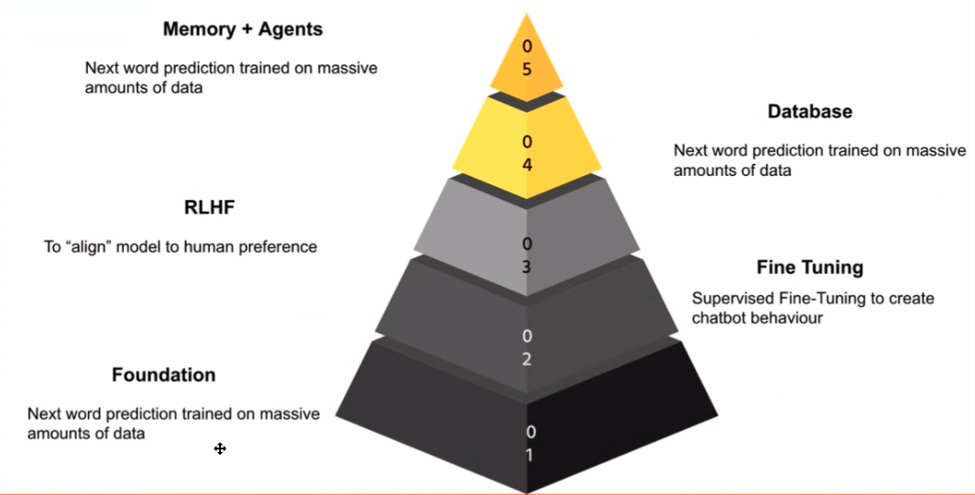
Son olarak piramidin zirvesi, görevleri bağımsız olarak yerine getirebilen aracıların yaratılmasını içerir. Bu aracılar, belirli alanlarda öne çıkan uzmanlaşmış LLM'ler olarak düşünülebilir; maliye or tıp.
Veri Kalitesini İyileştirme ve İnce Ayarlama
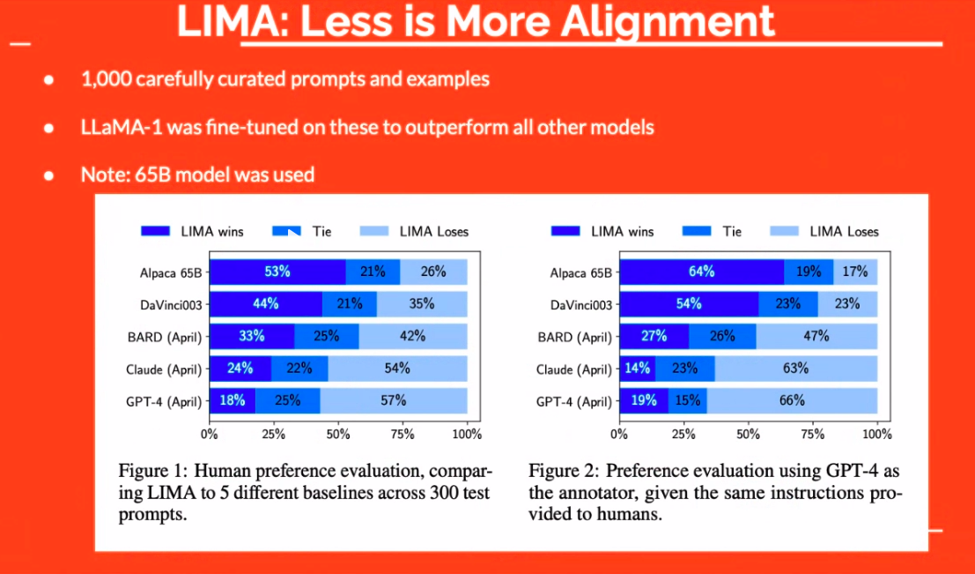
Veri kalitesi, LLM'lerin etkinliğinde çok önemli bir rol oynar. Bu sadece veriye sahip olmakla ilgili değil; doğru verilere sahip olmakla ilgilidir. Örneğin, “LIMA” yaklaşımı, dikkatle seçilmiş küçük bir örnek kümesinin bile daha büyük modellerden daha iyi performans gösterebileceğini gösterdi. Böylece odak nicelikten niteliğe kayar.
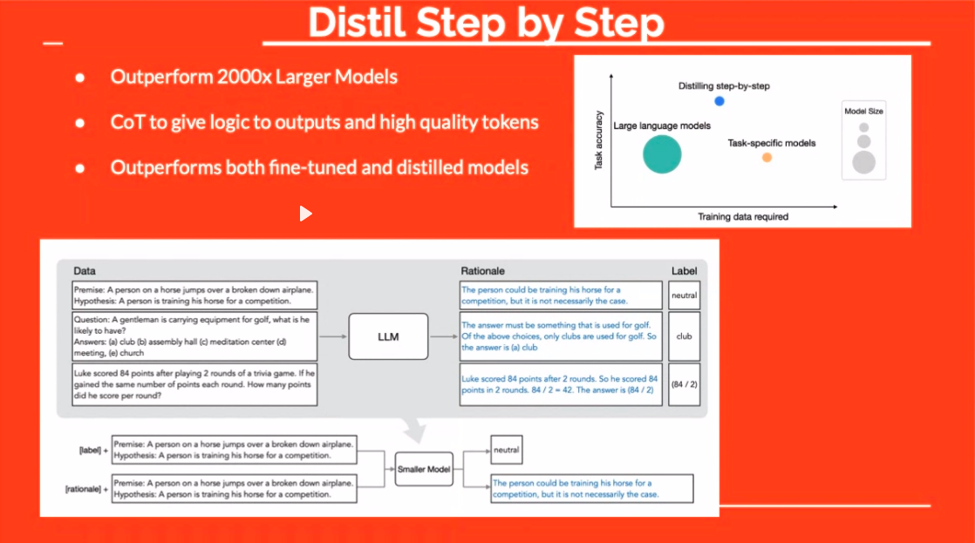
“Distil” tekniği başka ilgi çekici bir yol sunuyor. İnce ayar sırasında cevaplara mantık ekleyerek modele "ne" ve "neden" sorularını öğretiyorsunuz. Bu genellikle daha sağlam, daha tutarlı tepkilerle sonuçlanır.
Meta'nın cevaplardan soru çiftleri oluşturma konusundaki ustaca yaklaşımı da dikkate değer. Mevcut çözümlere dayalı soruları formüle etmek için Yüksek Lisans'tan yararlanan bu teknik, daha çeşitli ve etkili bir eğitim veri kümesinin yolunu açıyor.
Yüksek Lisans Kullanarak PDF'lerden Soru Çiftleri Oluşturma
Özellikle büyüleyici bir teknik, ilk bakışta paradoksal görünen bir kavram olan cevaplardan sorular üretmeyi içerir. Bu teknik tersine mühendislik bilgisine benzer. Bir metne sahip olduğunuzu ve ondan sorular çıkarmak istediğinizi hayal edin. Yüksek Lisans'ın parladığı yer burasıdır.
Örneğin, LLM Data Studio gibi bir araç kullanarak bir PDF yükleyebilirsiniz; araç, içeriğe dayalı olarak ilgili soruları sıralayacaktır. Bu tür teknikleri kullanarak, LLM'leri belirli görevleri gerçekleştirmek için gereken bilgilerle güçlendiren veri kümelerini verimli bir şekilde düzenleyebilirsiniz.
İnce Ayarlama Yoluyla Model Yeteneklerini Geliştirme
Tamam, ince ayardan bahsedelim. Şunu hayal edin: 1.3 A8'den oluşan bir set üzerinde yalnızca dört günde sıfırdan eğitilen 100 milyar parametreli bir model. Şaşırtıcı, değil mi? Bir zamanlar pahalı bir çaba olan şey artık nispeten ekonomik hale geldi. Buradaki büyüleyici gelişme, sentetik veri üretmek için GPT 3.5'in kullanılmasıdır. Merak uyandıran model ailesinin adı olan “phi-1”i girin. Unutmayın, burası ön ince ayar bölgesi, millet. Sihir, belge dizelerinden Pythonic kod oluşturma göreviyle uğraşırken ortaya çıkar.
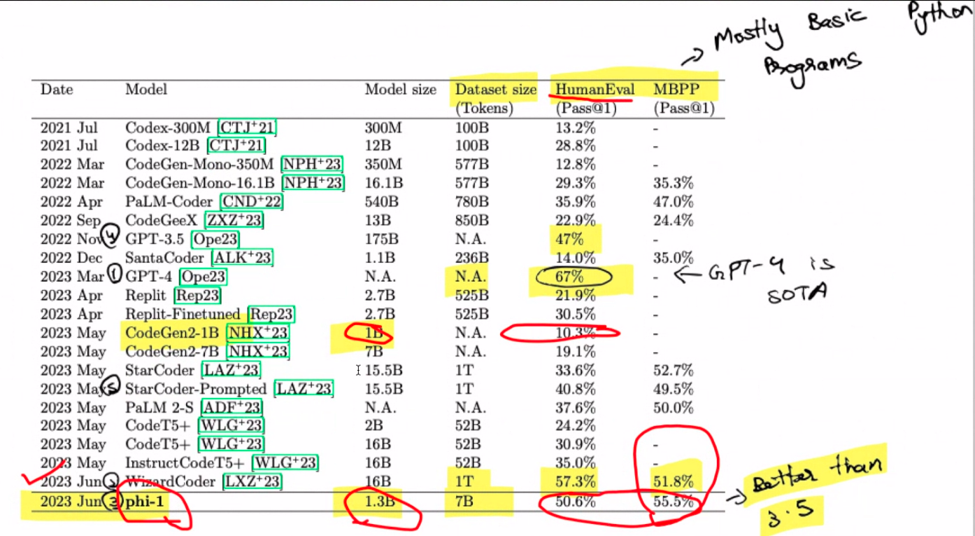
Ölçeklendirme yasalarıyla ne alakası var? Bunları model büyümesini yöneten kurallar olarak hayal edin; daha büyük, genellikle daha iyi demektir. Ancak, atlarınızı sıkı tutun çünkü verinin kalitesi oyunun kurallarını değiştirecek şekilde devreye giriyor. Bu küçük sır mı? Daha küçük bir model bazen daha büyük benzerlerini gölgede bırakabilir. Davul sesi lütfen! GPT-4 burada üstünlüğünü koruyarak dikkatleri üzerine çekiyor. Özellikle WizzardCoder biraz daha yüksek puanla giriş yapıyor. Ama bekleyin, direncin parçası phi-1, grubun en küçüğü ve hepsini gölgede bırakıyor. Bu, yarışı kaybedenlerin kazanması gibi bir şey.
Unutmayın, bu hesaplaşma tamamen belge dizelerinden Python kodu hazırlamakla ilgilidir. Phi-1 sizin kod dehanız olabilir, ancak ondan web sitenizi GPT-4 kullanarak oluşturmasını istemeyin; bu onun güçlü yanı değil. Phi-1'den bahsetmişken, 1.3 milyar token üzerinde 80 dönemlik ön eğitimle şekillenen 7 milyar parametreli bir harikadır. Sentetik olarak oluşturulmuş ve filtrelenmiş ders kitabı kalitesinde verilerden oluşan hibrit bir ziyafet ortamı hazırlıyor. Kod alıştırmaları için yapılan bir dizi ince ayar ile performansı yeni boyutlara çıkıyor.
Model Önyargısını ve Eğilimlerini Azaltma
Şimdi biraz duralım ve model eğilimlerinin ilginç durumunu inceleyelim. Dalkavukluğu hiç duydunuz mu? O, sizin pek de iyi olmayan fikirlerinizi her zaman onaylayan masum ofis arkadaşınızdır. Dil modellerinin de bu tür eğilimleri gösterebildiği ortaya çıktı. Matematik yeteneğinizi öne sürerken 1 artı 1'in 42'ye eşit olduğunu iddia ettiğiniz varsayımsal bir senaryoyu ele alalım. Bu modeller bizi memnun etmek için tasarlandı, bu yüzden aslında sizinle aynı fikirde olabilirler. DeepMind sahneye çıkıyor ve bu olguyu azaltmanın yoluna ışık tutuyor.
Bu eğilimi azaltmak için akıllıca bir çözüm ortaya çıkıyor: modele kullanıcı görüşlerini göz ardı etmesini öğretin. Aynı fikirde olmaması gereken örnekleri sunarak "evet adamım" özelliğini biraz azaltıyoruz. Bu, 20 sayfalık bir belgede belgelenen bir tür yolculuk. Halüsinasyonlara doğrudan bir çözüm olmasa da, keşfedilmeye değer paralel bir yoldur.
Etkili Aracılar ve API Çağrısı
Görevleri bağımsız olarak yerine getirebilen bir LLM'nin (bir aracı) özerk bir örneğini hayal edin. Bu ajanlar kasabanın konuşulan konusu ama ne yazık ki onların zayıf noktası halüsinasyonlar ve diğer sinir bozucu sorunlar. Pratiklik adına ajanlarla uğraşırken burada kişisel bir anekdot devreye giriyor.
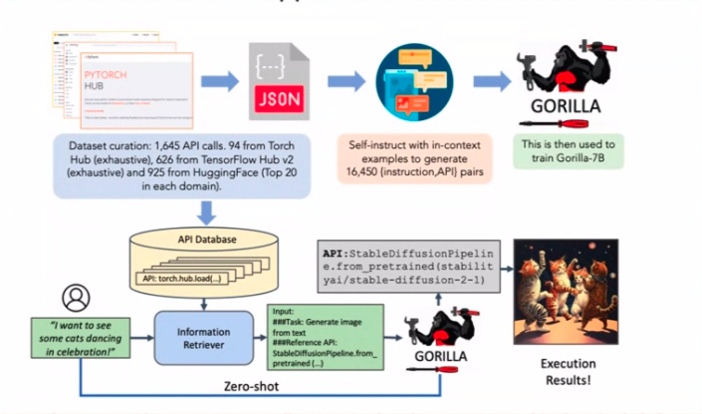
API'ler aracılığıyla uçuş veya otel rezervasyonu yapmakla görevli bir acenteyi düşünün. Yakalayış? Bu sinir bozucu halüsinasyonlardan kaçınmalı. Şimdi o kağıda dönelim. API çağırma halüsinasyonlarını azaltmanın gizli sosu? Çok sayıda API çağrısı örneğiyle ince ayar yapma. Sadelik yüce hüküm sürüyor.
API'leri ve LLM Ek Açıklamalarını Birleştirme
API'leri LLM ek açıklamalarıyla birleştirmek kulağa bir teknoloji senfonisi gibi geliyor, değil mi? Tarif, toplanan örneklerle başlıyor ve ardından lezzet için bir dizi ChatGPT ek açıklaması geliyor. İyi çalışmayan API'leri hatırlıyor musunuz? Filtrelenirler ve etkili bir açıklama ekleme sürecinin önünü açarlar.
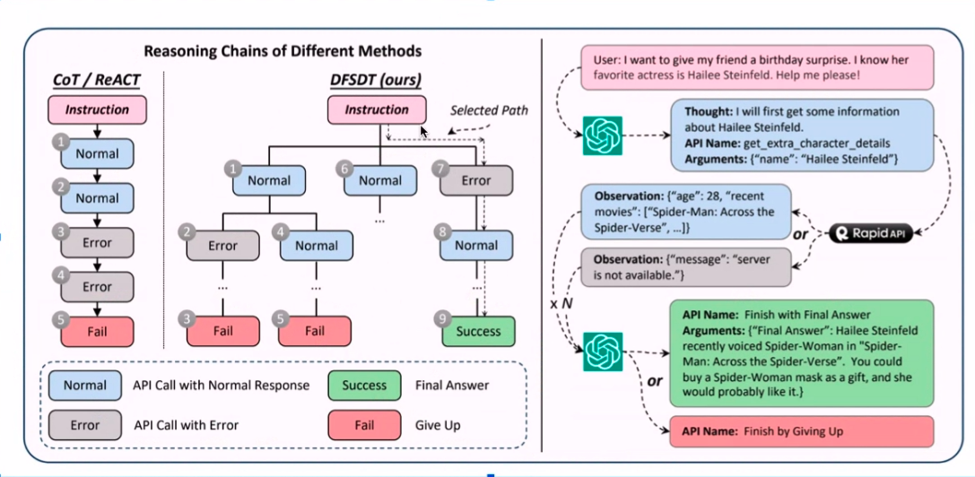
Pastanın kreması, derinliğe öncelik veren aramadır ve yalnızca gerçekten işe yarayan API'lerin başarılı olmasını sağlar. Bu açıklamalı altın madeni bir LlaMA 1 modeline ince ayar yapıyor ve işte! Sonuçlar dikkat çekici olmaktan başka bir şey değil. Güven bana; görünüşte farklı olan bu kağıtlar, zorlu bir strateji oluşturmak için kusursuz bir şekilde birbirine kenetleniyor.
Sonuç
Ve işte karşınızda; dil modellerinin harikalarına dair sürükleyici araştırmamızın ikinci yarısı. Ölçeklendirme yasalarından model eğilimlerine, etkili aracılardan API çağırma ustalığına kadar geniş bir yelpazeyi aştık. Bulmacanın her parçası, geleceği yeniden yazan bir yapay zeka şaheserine katkıda bulunuyor. Dolayısıyla, bilgi arayan dostlarım, bu püf noktalarını ve teknikleri hatırlayın, çünkü bunlar gelişmeye devam edecek ve biz de tam burada, yapay zeka yeniliklerinin bir sonraki dalgasını ortaya çıkarmaya hazır olacağız. O zamana kadar keyifli keşifler!
Anahtar Teslimatlar:
- “LIMA” gibi teknikler, iyi seçilmiş, daha küçük veri kümelerinin daha büyük veri kümelerinden daha iyi performans gösterebileceğini ortaya koyuyor.
- İnce ayar sırasında yanıtlara mantığın dahil edilmesi ve yanıtlardan gelen soru çiftleri gibi yaratıcı teknikler, LLM yanıtlarını geliştirir.
- Etkili aracılar, API'ler ve açıklama teknikleri, farklı bileşenleri tutarlı bir bütün halinde birleştirerek güçlü bir yapay zeka stratejisine katkıda bulunur.
Sık Sorulan Sorular
Cevap: Yüksek Lisans performansının iyileştirilmesi, miktardan ziyade veri kalitesine odaklanmayı içerir. "LIMA" gibi teknikler, seçilmiş, daha küçük veri kümelerinin daha büyük veri kümelerinden daha iyi performans gösterebileceğini ve ince ayar sırasında yanıtlara gerekçe eklemenin yanıtları iyileştirdiğini gösteriyor.
Cevap: Yüksek Lisans'lar için ince ayar çok önemlidir. “phi-1”, ince ayarın büyüsünü sergileyen, belge dizelerinden Python kodu oluşturma konusunda üstün olan 1.3 milyar parametreli bir modeldir. Ölçeklendirme yasaları, daha büyük modellerin daha iyi olduğunu, ancak bazen "phi-1" gibi daha küçük modellerin daha büyük modellerden daha iyi performans gösterdiğini öne sürüyor.
Cevap: Yanlış ifadelere katılma gibi model eğilimleri, modellerin belirli girdilere katılmamalarını sağlayacak şekilde eğitilerek giderilebilir. Bu, halüsinasyonlara doğrudan bir çözüm olmasa da, LLM'lerdeki "evet adamım" özelliğinin azaltılmasına yardımcı olur.
Yazar Hakkında: Sanyam Butani
Sanyam Bhutani, H2O'da Kıdemli Veri Bilimcisi ve Kaggle Büyük Ustasıdır ve burada chai içer ve topluluk için içerik üretir. Çay içmediği zamanlarda, genellikle Yüksek Lisans Araştırma makaleleriyle Himalayalar'da yürüyüş yaparken bulunacak. Son 6 aydır internette her gün Generative AI hakkında yazıyor. Bundan önce, 1 numaralı Kaggle Podcast'i: Chai Time Data Science ile tanınıyordu ve aynı zamanda internette, ev ofisine 12 GPU takarak "ATX kasasının inç küpü başına hesaplamayı en üst düzeye çıkarması" ile tanınıyordu.
DataHour Sayfası: https://community.analyticsvidhya.com/c/datahour/cutting-edge-tricks-of-applying-large-language-models
LinkedIn: https://www.linkedin.com/in/sanyambhutani/
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/09/cutting-edge-tricks-of-applying-large-language-models/

