In bu serinin ilk gönderisi, nasıl olduğunu anlattık AWS Tutkal Apache Spark için Apache Hudi, Linux Foundation Delta Lake ve Apache Iceberg veri kümeleri tablolarıyla çalışır. bu veri gölü biçimlerinin yerel desteği. Bu yerel destek, veri göllerinizi işlem açısından tutarlı bir şekilde daha kolay bir şekilde oluşturabilmeniz ve sürdürebilmeniz için bu veri gölü çerçeveleri için verilerinizin okunmasını ve yazılmasını basitleştirir. Bu özellik, ayrı bir bağlayıcı yükleme ihtiyacını ortadan kaldırır ve bu çerçeveleri AWS Glue for Apache Spark işlerinde kullanmak için gereken yapılandırma adımlarını azaltır.
Bu veri gölü çerçeveleri, verileri daha verimli bir şekilde depolamanıza yardımcı olur ve uygulamaların verilerinize daha hızlı erişmesini sağlar. Büyük verileri depolayabilen Apache Parquet, CSV ve JSON gibi daha basit veri dosyası biçimlerinin aksine, veri gölü çerçeveleri, dağıtılmış büyük veri dosyalarını veri göllerinde temel veritabanları yapılarına olanak tanıyan tablolu yapılar halinde düzenler.
AWS re:Invent 2022'de duyurduğumuz işlevselliği genişleten AWS Glue, artık AWS Glue Studio görsel editörü aracılığıyla Hudi, Delta Lake ve Iceberg'i yerel olarak desteklemektedir. AWS Glue for Apache Spark işlerini görsel bir araç kullanarak yazmayı tercih ederseniz, artık herhangi bir özel kod olmadan bir grafik kullanıcı arabirimi (GUI) aracılığıyla bu üç data lake çerçevesinden herhangi birini kaynak veya hedef olarak seçebilirsiniz.
Daha önce Hudi, Delta Lake veya Iceberg kullanma deneyiminiz olmasa bile tipik kullanım durumlarını kolayca elde edebilirsiniz. Bu gönderide, AWS Glue Studio görsel düzenleyicisini kullanarak Hudi'de depolanan verilerin nasıl alınacağını gösteriyoruz.
Örnek senaryo
Görsel düzenleyici deneyimini göstermek için bu gönderi, Günlük Küresel Tarihsel Klimatoloji Ağı (GHCN-D) veri kümesi. Veriler, bir Amazon Basit Depolama Hizmeti (Amazon S3) paketi. Daha fazla bilgi için bkz. AWS'de Açık Veri Kaydı. Ayrıca şuradan daha fazla bilgi edinebilirsiniz: Amazon Athena ve Amazon QuickSight'ı kullanarak 200 yılı aşkın küresel iklim verilerini görselleştirin.
Amazon S3 konumu s3://noaa-ghcn-pds/csv/by_year/ 1763'ten günümüze kadar olan tüm gözlemler, her yıl için bir dosya olmak üzere CSV dosyalarında düzenlenmiştir. Aşağıdaki blok, kayıtların nasıl göründüğüne dair bir örnek gösterir:
Kayıtlarda ID, DATE, ELEMENT ve daha fazlasını içeren alanlar bulunur. Her bir kombinasyon ID, DATE, ve ELEMENT bu veri kümesindeki benzersiz bir kaydı temsil eder. Örneğin, ile kayıt ID as AE000041196, ELEMENT as TAVG, ve DATE as 20220101 benzersiz.
Bu öğreticide, dosyaların her gün yeni kayıtlarla güncellendiğini ve birincil anahtar başına yalnızca en son kaydı depolamak istediğimizi varsayıyoruz (ID ve ELEMENT) en son anlık görüntü verilerini sorgulanabilir hale getirmek için. Tipik bir yaklaşım, tüm geçmiş veriler için bir INSERT yapmak ve sorgulardaki en son kayıtları hesaplamaktır; ancak bu, tüm sorgularda ek yük getirebilir. Yalnızca en son kayıtları analiz etmek istediğinizde, birincil anahtara dayalı bir UPSERT (güncelleme ve ekleme) yapmak daha iyidir ve DATE yinelemeleri önlemek ve tek bir güncelleştirilmiş veri satırını korumak için yalnızca bir INSERT yerine alan.
Önkoşullar
Bu eğiticiye devam etmek için aşağıdaki AWS kaynaklarını önceden oluşturmanız gerekir:
AWS Glue Studio görsel düzenleyicisinde bir Hudi veri kümesini işleyin
2022'de günlük kayıtları okumak için bir AWS Glue işi yazalım ve UPSERT kullanarak S3 klasörünüzdeki Hudi tablosuna en son anlık görüntüyü yazalım. Aşağıdaki adımları tamamlayın:
- AWS Glue Studio'yu açın.
- Klinik Mesleki Öğretiler.
- Klinik Kaynak ve hedef içeren görsel.
- İçin Kaynak ve Hedef, seçmek Amazon S3, Daha sonra seçmek oluşturmak.
Yeni bir görsel iş yapılandırması görünür. Bir sonraki adım, veri kaynağını örnek bir veri kümesini okuyacak şekilde yapılandırmaktır:
- Altında Görsel, seçmek Veri kaynağı – S3 paketi.
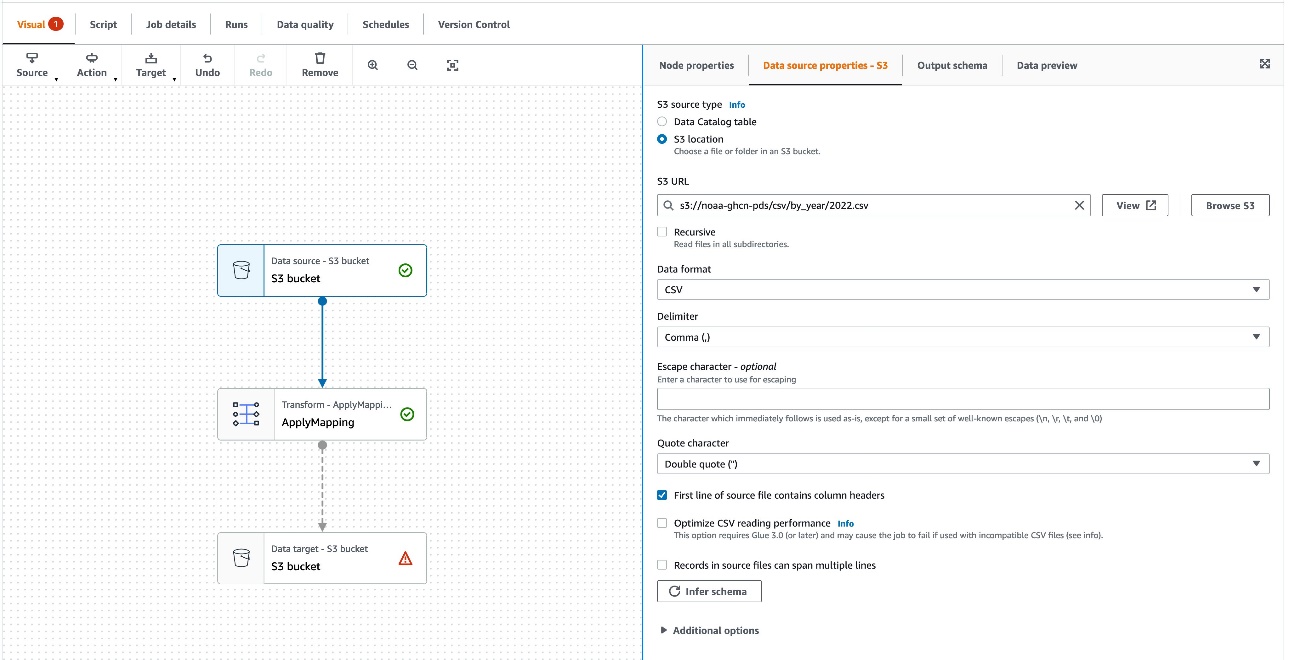
- Altında Düğüm özellikleri, Için S3 kaynak türüseçin S3 konumu.
- İçin S3 URL'si, girmek
s3://noaa-ghcn-pds/csv/by_year/2022.csv.
Veri kaynağı yapılandırılır.
Sonraki adım, veri hedefini S3 klasörünüzdeki Apache Hudi'ye veri alacak şekilde yapılandırmaktır:
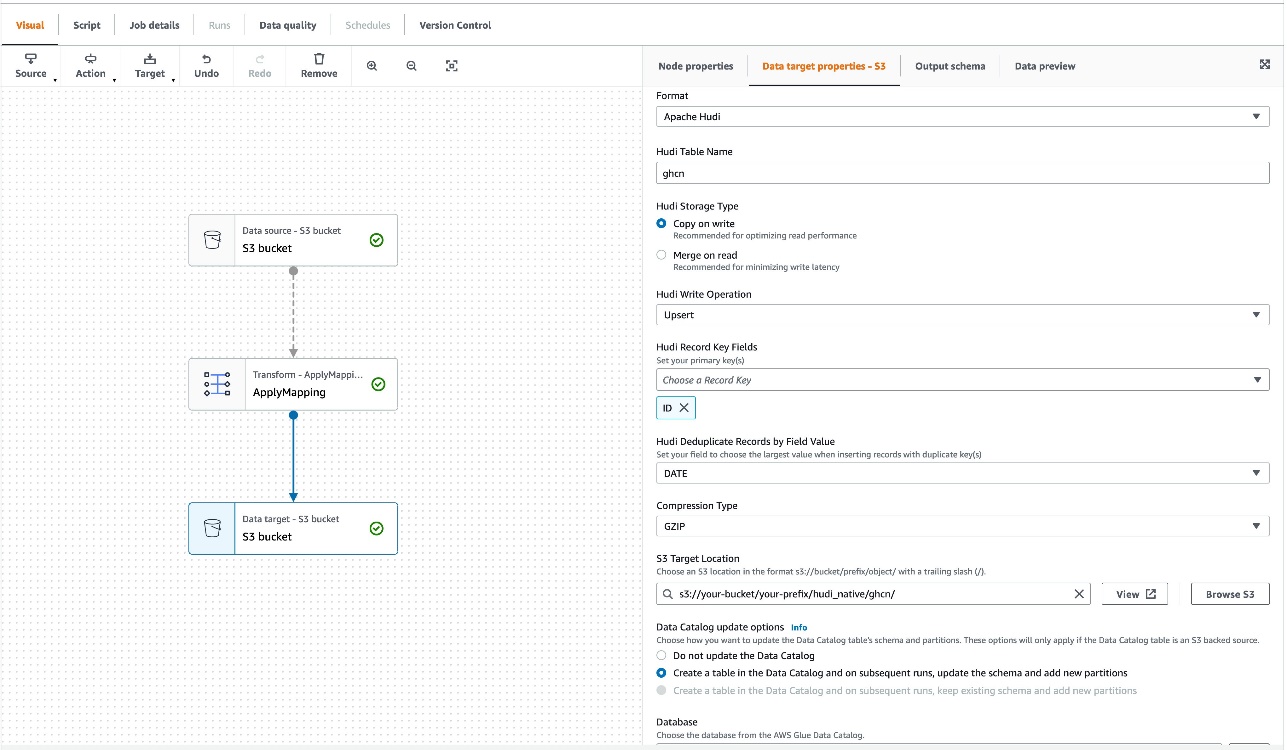
- Klinik Veri hedefi – S3 grubu.
- Altında Veri hedefi özellikleri- S3, Için oluşturulan, seçmek Apaçi Hudi.
- İçin Hudi Tablo Adı, girmek
ghcn. - İçin Hudi Saklama Türü, seçmek kopyala üzerine yaz.
- İçin Hudi Yazma İşlemi, seçmek yukarı.
- İçin Hudi Kaydı Anahtar Alanları, seçmek
ID. - İçin Hudi Ön Birleştirme Anahtar Alanı, seçmek
DATE. - İçin Sıkıştırma tipi, GZIP'i seçin.
- İçin S3 Hedef yer, girmek
s3://<Your S3 bucket name>/<Your S3 bucket prefix>/hudi_native/ghcn/. (S3 grup adınızı ve ön ekinizi sağlayın.)
Örnek verileri keşfetmeyi kolaylaştırmak ve Athena'dan sorgulanabilir hale getirmek için işi AWS Glue Data Catalog'da bir tablo tanımı oluşturacak şekilde yapılandırın:
- İçin Veri Kataloğu güncelleme seçenekleriseçin Veri Kataloğu'nda bir tablo oluşturun ve sonraki çalıştırmalarda şemayı güncelleyin ve yeni bölümler ekleyin.
- İçin veritabanı, seçmek
hudi_native. - İçin Tablo ismi, girmek
ghcn. - İçin Bölme anahtarları – isteğe bağlı, seçmek
ELEMENT.
Artık veri entegrasyon işiniz tamamen görsel düzenleyicide yazılmıştır. IAM rolüyle ilgili kalan bir ayarı ekleyelim, ardından işi çalıştıralım:
- Altında İş detayları, Için IAM Rolü, IAM rolünüzü seçin.
- Klinik İndirim, Daha sonra seçmek koşmak.
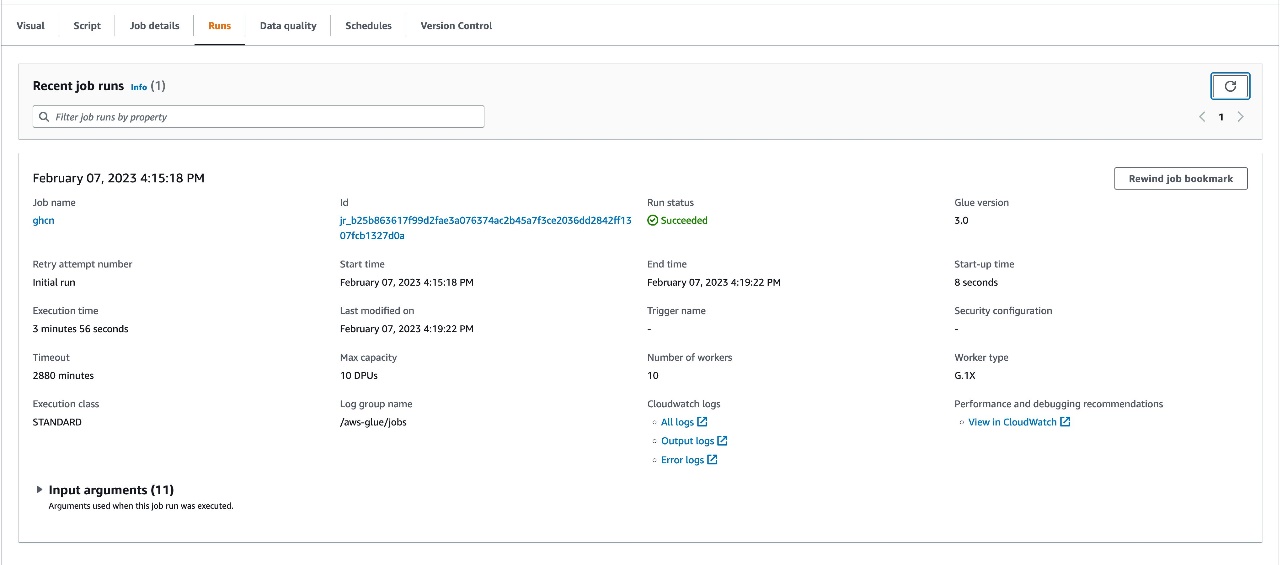
- gidin Runs İşin ilerleyişini izlemek ve tamamlanmasını beklemek için sekmesini tıklayın.
Athena ile masayı sorgula
İş, Hudi tablosunu başarıyla oluşturduğuna göre, tabloyu aşağıdakiler de dahil olmak üzere farklı motorlar aracılığıyla sorgulayabilirsiniz: Amazon Atina, Amazon EMR'si, ve Amazon Kırmızıya Kaydırma Spektrumu, AWS Glue for Apache Spark'a ek olarak.
Athena üzerinden sorgulamak için aşağıdaki adımları tamamlayın:
- Athena konsolunda sorgu düzenleyicisini açın.
- Sorgu düzenleyicide aşağıdaki SQL'i girin ve seçin koşmak:
SELECT * FROM "hudi_native"."ghcn" limit 10;Aşağıdaki ekran görüntüsü sorgu sonucunu gösterir.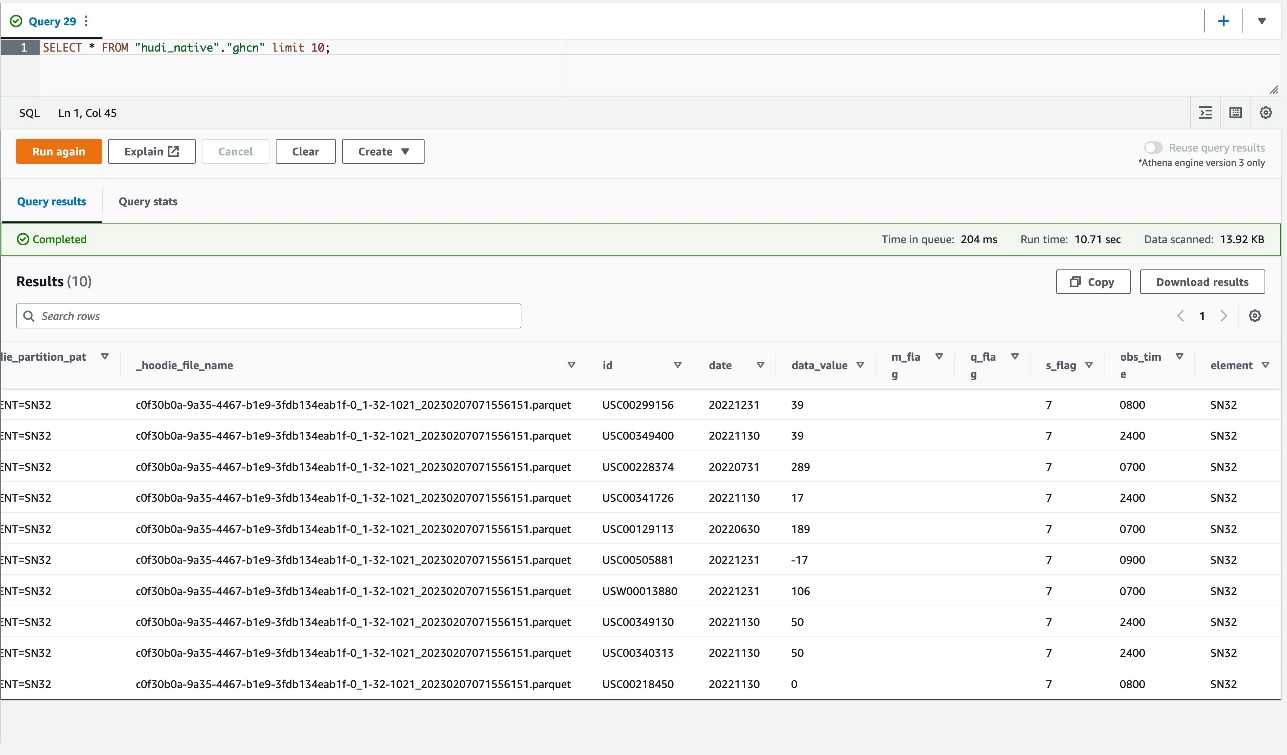
Verilerin nasıl alındığını anlamak için tablonun derinliklerine inelim ve ID='AE000041196′ olan kayıtlara odaklanalım.
- İle çok özel örnek kayıtlara odaklanmak için aşağıdaki sorguyu çalıştırın.
ID='AE000041196':
SELECT * FROM "hudi_native"."ghcn" WHERE ID='AE000041196';Aşağıdaki ekran görüntüsü sorgu sonucunu gösterir.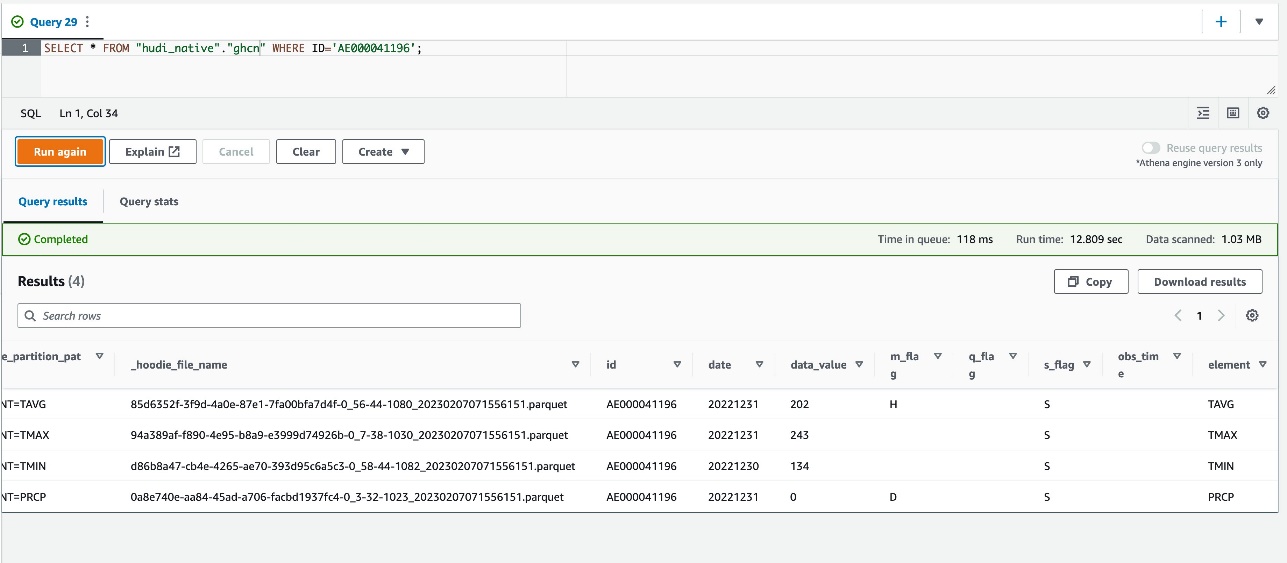
Orijinal kaynak dosya 2022.csv kayıt için tarihi kayıtlara sahiptir ID='USW00012894' itibaren 20220101 için 20221231, ancak sorgu sonucu yalnızca dört kayıt gösterir; ELEMENT günün en son anlık görüntüsünde 20221230 or 20221231. Veri yazarken UPSERT yazma seçeneğini kullandığımız için ID alanını Hudi record key alanı olarak yapılandırdık, DATE alanı bir Hudi ön birleştirme alanı olarak ve ELEMENT bölüm anahtar alanı olarak alan. İki kayıt aynı anahtar değerine sahip olduğunda, Hudi ön birleştirme alanı için en büyük değere sahip olanı seçer. İş verileri aldığında, içindeki tüm değerleri karşılaştırdı. DATE her bir çift için alan ID ve ELEMENTve ardından listedeki en büyük değere sahip kaydı seçti. DATE alan.
Önceki sonuca göre, tüm 2022 verilerinden en son anlık görüntüyü alabildik. Şimdi hedef Hudi tablosundaki kayıtların üzerine yazmak için yeni 2023 verilerinin bir UPSERT'sini yapalım.
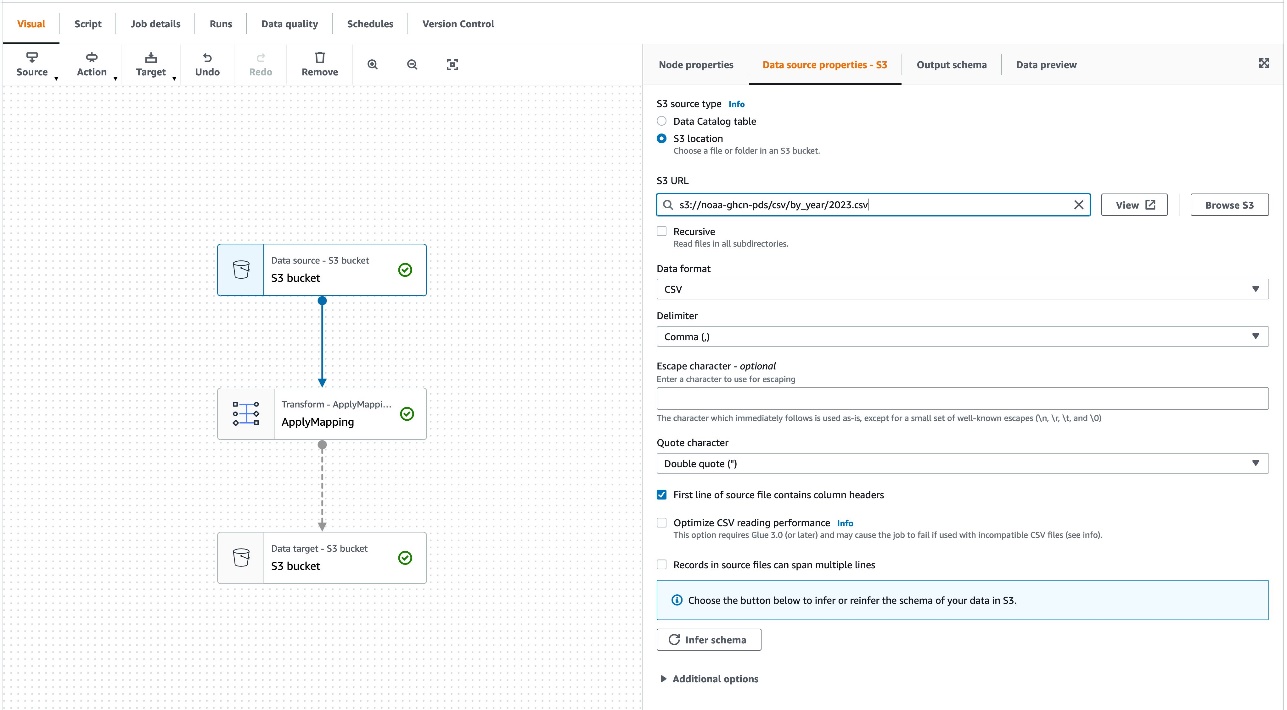
- AWS Glue Studio konsoluna geri dönün, kaynak S3 konumunu şu şekilde değiştirin:
s3://noaa-ghcn-pds/csv/by_year/2023.csv, ardından işi kaydedin ve çalıştırın.
- Aynı Athena sorgusunu Athena konsolundan çalıştırın.
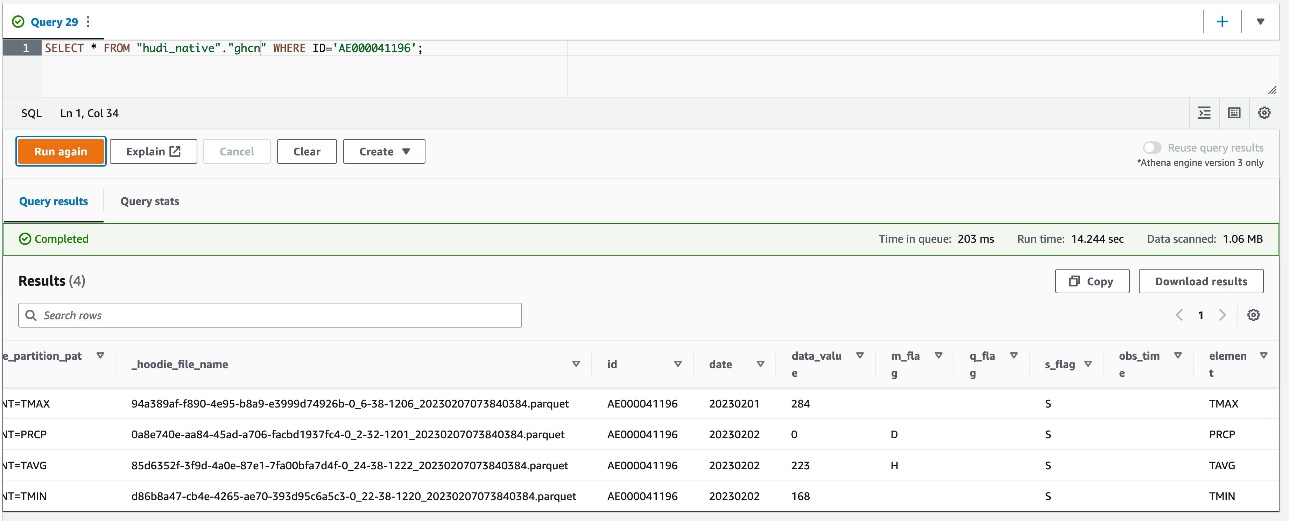
Artık dört kaydın 2023'teki yeni kayıtlarla güncellendiğini görüyorsunuz.
Gelecekte başka kayıtlarınız varsa, bu yaklaşım Hudi kayıt anahtarına ve Hudi ön birleştirme anahtarına dayalı olarak yeni kayıtları yükseltmek için iyi çalışır.
Temizlemek
Şimdi son adıma, kaynakları temizlemeye geçelim:
- AWS Glue veritabanını silin
hudi_native. - AWS Glue tablosunu silin
ghcn. - Altındaki S3 nesnelerini silin
s3://<Your S3 bucket name>/<Your S3 bucket prefix>/hudi_native/ghcn2022/.
Sonuç
Bu gönderi, AWS Glue Studio görsel düzenleyicisini kullanarak Hudi veri kümelerinin nasıl işleneceğini gösterdi. AWS Glue Studio görsel editörü, data lake formatlarından yararlanırken ve bu formatlarda uzmanlığa ihtiyaç duymadan işleri yazmanıza olanak tanır. Yorumlarınız veya geri bildirimleriniz varsa, lütfen bunları yorumlarda bırakmaktan çekinmeyin.
yazarlar hakkında
 Noritaka Sekiyama AWS Glue ekibinde Baş Büyük Veri Mimarıdır. Müşterilere yardımcı olmak için yazılım yapıları oluşturmaktan sorumludur. Boş zamanlarında yeni yol bisikletiyle bisiklete binmekten keyif alıyor.
Noritaka Sekiyama AWS Glue ekibinde Baş Büyük Veri Mimarıdır. Müşterilere yardımcı olmak için yazılım yapıları oluşturmaktan sorumludur. Boş zamanlarında yeni yol bisikletiyle bisiklete binmekten keyif alıyor.
 Scott Uzun AWS Glue ekibinde Ön Uç Mühendisidir. AWS Glue Studio'daki yeni özelliklerin uygulanmasından sorumludur. Boş zamanlarında arkadaşlarıyla sosyalleşmekten ve çeşitli outdoor aktivitelere katılmaktan hoşlanır.
Scott Uzun AWS Glue ekibinde Ön Uç Mühendisidir. AWS Glue Studio'daki yeni özelliklerin uygulanmasından sorumludur. Boş zamanlarında arkadaşlarıyla sosyalleşmekten ve çeşitli outdoor aktivitelere katılmaktan hoşlanır.
 Sean Anne AWS Glue ekibinde Baş Ürün Yöneticisidir. Kullanıcılar için verinin gücünü açığa çıkaran kurumsal ürünler geliştirme ve sunma konusunda 18 yılı aşkın bir geçmişe sahiptir. Sean, iş dışında tüplü dalış ve kolej futbolu ile ilgileniyor.
Sean Anne AWS Glue ekibinde Baş Ürün Yöneticisidir. Kullanıcılar için verinin gücünü açığa çıkaran kurumsal ürünler geliştirme ve sunma konusunda 18 yılı aşkın bir geçmişe sahiptir. Sean, iş dışında tüplü dalış ve kolej futbolu ile ilgileniyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/part-2-glue-studio-visual-editor-introducing-native-support-for-apache-hudi-delta-lake-and-apache-iceberg-on-aws-glue-for-apache-spark/

