Makine öğrenimi modelinin zirveye ulaştığı bir çağda yaşıyoruz. Onlarca yıl öncesiyle karşılaştırıldığında çoğu insan ChatGPT veya Yapay Zeka hakkında hiçbir şey duymazdı. Ancak bunlar insanların konuşmaya devam ettiği konular. Neden? Çünkü verilen değerler emekle kıyaslandığında çok önemli.
Yapay zekanın son yıllardaki atılımı pek çok şeye bağlanabilir, ancak bunlardan biri büyük dil modelidir (LLM). İnsanların kullandığı metin oluşturma yapay zekasının çoğu, LLM modeli tarafından desteklenmektedir; Örneğin ChatGPT, GPT modelini kullanır. LLM önemli bir konu olduğu için bunu öğrenmeliyiz.
Bu makale Büyük Dil Modellerini 3 zorluk seviyesinde tartışacak, ancak Yüksek Lisans'ın yalnızca bazı yönlerine değineceğiz. Yalnızca her okuyucunun LLM'nin ne olduğunu anlamasını sağlayacak şekilde farklılaşacağız. Bunu aklımızda tutarak konuya girelim.
İlk seviyede okuyucunun Yüksek Lisans hakkında bilgi sahibi olmadığını ve veri bilimi/makine öğrenimi alanı hakkında biraz bilgi sahibi olabileceğini varsayıyoruz. Bu nedenle, Yüksek Lisans'a geçmeden önce kısaca AI ve Makine Öğrenimini tanıtacağım.
Yapay Zeka akıllı bilgisayar programları geliştirme bilimidir. Programın, insanların yapabileceği ancak insanın biyolojik ihtiyaçları üzerinde herhangi bir sınırlaması olmayan akıllı görevleri gerçekleştirmesi amaçlanıyor. Makine öğrenme istatistiksel algoritmalarla veri genelleme çalışmalarına odaklanan yapay zeka alanıdır. Bir bakıma Makine Öğrenimi, programın herhangi bir talimat olmadan zeka görevlerini yerine getirebilmesi için veri çalışması yoluyla Yapay Zeka elde etmeye çalışıyor.
Tarihsel olarak bilgisayar bilimi ile dilbilimin kesiştiği alana Doğal Bilimler adı verilmektedir. Dil İşleme alan. Bu alan esas olarak metin belgeleri gibi insan metnine yönelik her türlü makine işleme faaliyetiyle ilgilidir. Daha önce bu alan yalnızca kural tabanlı sistemle sınırlıydı ancak modelin herhangi bir yön olmadan öğrenmesine olanak tanıyan gelişmiş yarı denetimli ve denetimsiz algoritmaların kullanıma sunulmasıyla daha da genişledi. Bunu yapabilecek gelişmiş modellerden biri de Dil Modelidir.
Dil model çeviri, dilbilgisi düzeltmesi ve metin oluşturma gibi birçok insan görevini gerçekleştirmek için olasılıksal bir NLP modelidir. Dil modelinin eski biçimi, bir sonraki kelimenin olasılığının yalnızca önceki kelimenin sabit boyutlu verilerine bağlı olduğu varsayımının yapıldığı n-gram yöntemi gibi tamamen istatistiksel yaklaşımları kullanır.
Ancak tanıtımı Sinir ağı önceki yaklaşımı tahtından indirdi. Yapay sinir ağı veya NN, insan beyninin nöron yapısını taklit eden bir bilgisayar programıdır. Sinir Ağı yaklaşımının kullanımı iyidir çünkü metin verilerinden karmaşık model tanımayı ve metin gibi sıralı verileri işleyebilir. Bu nedenle mevcut Dil Modeli genellikle NN'ye dayanmaktadır.
Büyük Dil Modelleriveya LLM'ler, genel amaçlı dil oluşturmayı gerçekleştirmek için çok sayıda veri belgesinden öğrenen makine öğrenimi modelleridir. Bunlar hâlâ bir dil modelidir ancak NN tarafından öğrenilen çok sayıda parametre, onların büyük sayılmasına neden olur. Meslekten olmayanların ifadesiyle, model, verilen giriş sözcüklerinden sonraki sözcükleri çok iyi tahmin ederek insanların nasıl yazdığını gerçekleştirebilir.
Yüksek Lisans görevlerine örnek olarak dil çevirisi, makine sohbet robotu, soru yanıtlama ve çok daha fazlası verilebilir. Model, herhangi bir veri girişi dizisinden kelimeler arasındaki ilişkileri tanımlayabilir ve talimatlara uygun çıktı üretebilir.
Metin oluşturmayı kullanan bir şeye sahip olan Üretken Yapay Zeka ürünlerinin neredeyse tamamı Yüksek Lisans'lar tarafından desteklenmektedir. ChatGPT, Google'ın Bard'ı ve çok daha fazlası gibi büyük ürünler, ürünlerinin temeli olarak Yüksek Lisans'ı kullanıyor.
Okuyucunun veri bilimi bilgisi vardır ancak bu düzeyde Yüksek Lisans hakkında daha fazla bilgi edinmesi gerekmektedir. Okuyucu en azından veri alanında kullanılan terimleri anlayabilir. Bu seviyede temel mimarinin derinliklerine ineceğiz.
Daha önce açıklandığı gibi LLM, büyük miktarda metin verisi üzerinde eğitilmiş bir Sinir Ağı modelidir. Bu kavramı daha iyi anlamak için sinir ağlarının ve derin öğrenmenin nasıl çalıştığını anlamak faydalı olacaktır.
Bir önceki seviyede sinir nöronunun insan beyninin sinir yapısını taklit eden bir model olduğunu açıklamıştık. Sinir Ağının ana unsuru, genellikle düğümler olarak adlandırılan nöronlardır. Konsepti daha iyi açıklamak için aşağıdaki resimdeki tipik Sinir Ağı mimarisine bakın.
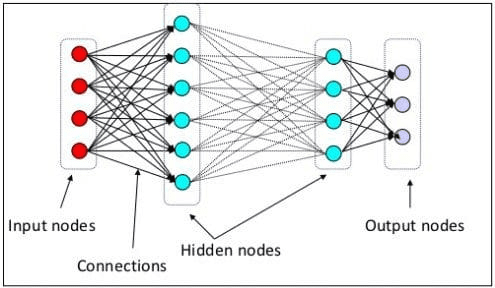
Sinir Ağı Mimarisi(Resim kaynağı: KDNuggets)
Yukarıdaki görselde de görebileceğimiz gibi Sinir Ağı üç katmandan oluşmaktadır:
- Giriş katmanı, bilgiyi alır ve bir sonraki katmandaki diğer düğümlere aktarır.
- Tüm hesaplamaların gerçekleştiği gizli düğüm katmanları.
- Hesaplamalı çıktıların bulunduğu çıktı düğümü katmanı.
Sinir Ağı modelimizi iki veya daha fazla gizli katmanla eğittiğimizde buna derin öğrenme denir. Arada birçok katman kullandığı için buna derin deniyor. Derin öğrenme modellerinin avantajı, geleneksel makine öğrenimi modellerinin yapamadığı verilerden otomatik olarak öğrenmeleri ve özellikler çıkarmalarıdır.
Büyük Dil Modelinde, model derin sinir ağı mimarileri üzerine kurulduğundan derin öğrenme önemlidir. Peki neden LLM deniyor? Bunun nedeni milyarlarca katmanın devasa miktarda metin verisi üzerinde eğitilmiş olmasıdır. Katmanlar, modelin dilbilgisi, yazma stili ve daha pek çok şey dahil olmak üzere dildeki karmaşık kalıpları öğrenmesine yardımcı olan model parametreleri üretecektir.
Model eğitiminin basitleştirilmiş süreci aşağıdaki resimde gösterilmektedir.
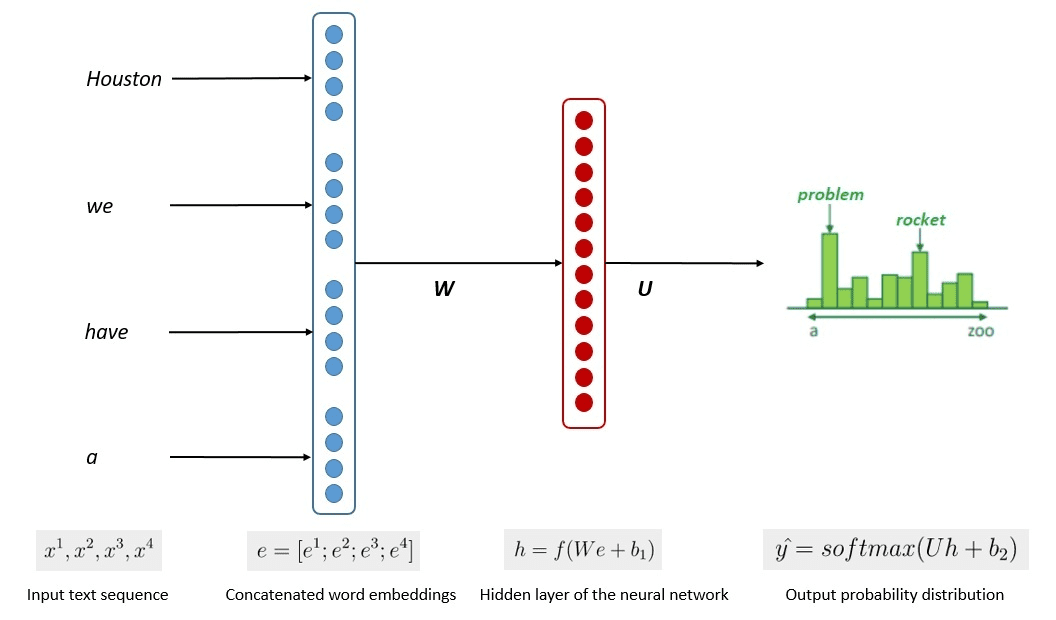
Görüntü: Kumar Chandrakant (Kaynak: Baeldung.com)
Süreç, modellerin, girdi verisindeki her kelimenin veya cümlenin olasılığına dayalı olarak ilgili metni üretebildiğini gösterdi. Yüksek Lisans'ta ileri yaklaşım şunları kullanır: öz denetimli öğrenme ve yarı denetimli öğrenme genel amaçlı yeteneğe ulaşmak için.
Kendi kendine denetimli öğrenme, etiketlerimizin olmadığı ve bunun yerine eğitim verilerinin eğitim geri bildirimini sağladığı bir tekniktir. Verilerde genellikle etiket bulunmadığından LLM eğitim sürecinde kullanılır. LLM'de, sonraki kelimeleri tahmin etmek için çevredeki bağlam bir ipucu olarak kullanılabilir. Buna karşılık, Yarı denetimli öğrenme, büyük miktarda etiketlenmemiş veri için yeni etiketler oluşturmak üzere denetimli ve denetimsiz öğrenme kavramlarını az miktarda etiketli veriyle birleştirir. Yarı denetimli öğrenme genellikle belirli bağlam veya alan ihtiyaçları olan Yüksek Lisans'lar için kullanılır.
Üçüncü seviyede, LLM'yi daha derinlemesine tartışacağız, özellikle de LLM yapısını ve bunun insan benzeri üretim kabiliyetine nasıl ulaşabileceğini ele alacağız.
LLM'nin Derin Öğrenme teknikleriyle Sinir Ağı modelini temel aldığını tartışmıştık. LLM tipik olarak temel alınarak oluşturulmuştur. trafo tabanlı son yıllarda mimarlık. Transformatör, tarafından tanıtılan çok kafalı dikkat mekanizmasına dayanmaktadır. Vasvani ve ark. (2017) ve birçok LLM'de kullanılmıştır.
Transformers, daha önce RNN'lerde ve LSTM'lerde karşılaşılan sıralı görevleri çözmeye çalışan bir model mimarisidir. Dil Modelinin eski yöntemi, verileri sırayla işlemek için RNN ve LSTM'yi kullanmaktı; burada model, her kelime çıktısını kullanır ve modelin unutmaması için bunları geri döngüye alırdı. Ancak transformatörler kullanılmaya başlandıktan sonra uzun dizili verilerle ilgili sorunlar yaşarlar.
Transformers'ların derinliklerine inmeden önce, daha önce RNN'lerde kullanılan kodlayıcı-kod çözücü kavramını tanıtmak istiyorum. Kodlayıcı-kod çözücü yapısı, giriş ve çıkış metninin aynı uzunlukta olmamasına olanak tanır. Örnek kullanım durumu, genellikle farklı bir sıra boyutuna sahip olan bir dil çevirisidir.
Yapı ikiye ayrılabilir. İlk bölüme, veri dizisini alan ve buna dayalı olarak yeni bir gösterim oluşturan bölüm olan Encoder adı verilir. Gösterim, modelin ikinci kısmı olan kod çözücüde kullanılacaktır.
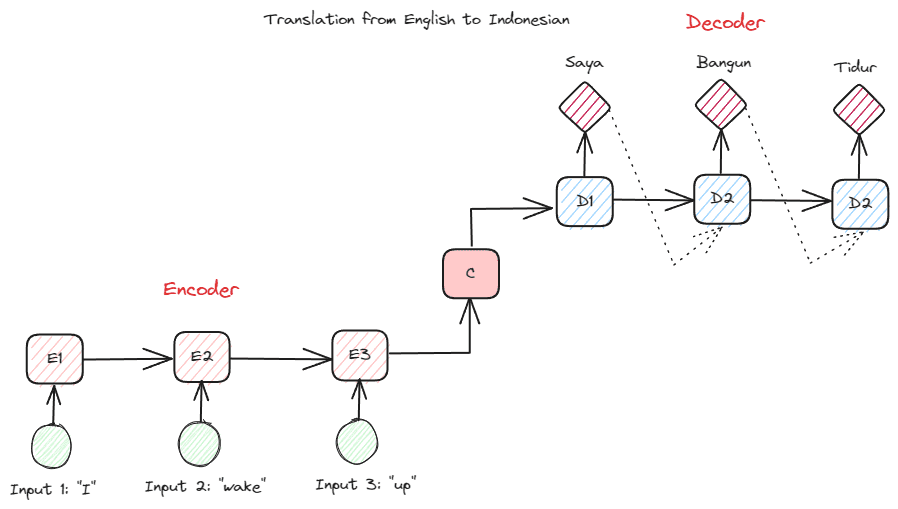
Yazara göre resim
RNN ile ilgili sorun, yukarıdaki kodlayıcı-kod çözücü yapısında bile modelin daha uzun dizileri hatırlama konusunda yardıma ihtiyaç duyabilmesidir. Dikkat mekanizmasının problemin çözümüne yardımcı olabileceği yer burasıdır, uzun girdi problemlerini çözebilecek bir katman. Makalede dikkat mekanizması şu şekilde tanıtılmaktadır: Bahdanau ve diğerleri. (2014) Çıkış tahmini yaparken model girişinin önemli bir kısmına odaklanarak kodlayıcı-kod çözücü tipi RNN'leri çözmek.
Transformatörün yapısı kodlayıcı-kod çözücü tipinden esinlenilerek dikkat mekanizması teknikleriyle inşa edildiğinden verileri sıralı bir şekilde işlemesine gerek yoktur. Genel transformatör modeli aşağıdaki resimdeki gibi yapılandırılmıştır.

Transformatör Mimarisi (Vasvani ve ark. (2017))
Yukarıdaki yapıda transformatörler, veriyi orijinal forma dönüştürmek için kod çözmeyi kullanırken veri vektör dizisini sözcük yerleştirmeye kodlar. Kodlama, dikkat mekanizması ile girdiye belirli bir önem atayabilir.
Veri vektörünü kodlayan transformatörlerden biraz bahsettik ama veri vektörü nedir? Bunu tartışalım. Makine öğrenimi modelinde ham doğal dil verilerini modele giremiyoruz, bu nedenle bunları sayısal formlara dönüştürmemiz gerekiyor. Dönüşüm sürecine kelime gömme adı verilir; burada her giriş kelimesi, veri vektörünü elde etmek için kelime gömme modeli aracılığıyla işlenir. Birçok başlangıç sözcük yerleştirmesini kullanabiliriz, örneğin Word2vec or Eldiven, ancak birçok ileri düzey kullanıcı, kelime dağarcığını kullanarak bunları hassaslaştırmaya çalışır. Temel haliyle kelime yerleştirme işlemi aşağıdaki görselde gösterilebilir.
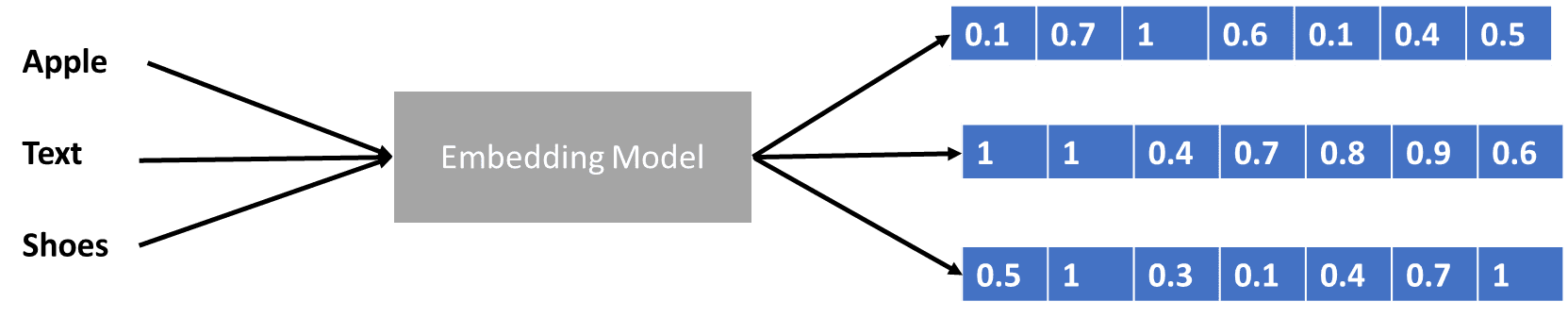
Yazara göre resim
Transformatörler girdiyi kabul edebilir ve kelimeleri yukarıdaki veri vektörü gibi sayısal formlarda sunarak daha alakalı bağlam sağlayabilir. LLM'lerde kelime yerleştirmeler genellikle bağlama bağlıdır ve genellikle kullanım senaryolarına ve amaçlanan çıktıya göre geliştirilir.
Büyük Dil Modelini başlangıç seviyesinden ileri seviyeye kadar üç zorluk seviyesinde tartıştık. LLM'nin genel kullanımından, nasıl yapılandırıldığına kadar kavramı daha detaylı açıklayan bir açıklama bulabilirsiniz.
Cornellius Yudha Wijaya bir veri bilimi müdür yardımcısı ve veri yazarıdır. Allianz Endonezya'da tam zamanlı çalışırken, sosyal medya ve yazılı medya aracılığıyla Python ve Veri ipuçlarını paylaşmayı seviyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/large-language-models-explained-in-3-levels-of-difficulty?utm_source=rss&utm_medium=rss&utm_campaign=large-language-models-explained-in-3-levels-of-difficulty

