
Image Gerd Altmann itibaren Pixabay
Yaklaşık bir ay önce OpenAI, ChatGPT'nin artık görebildiğini, duyabildiğini ve konuşabildiğini duyurdu. Bu, modelin size daha günlük görevlerde yardımcı olabileceği anlamına gelir. Örneğin buzdolabınızın içindekilerin resmini yükleyebilir ve elinizdeki malzemelerle hazırlayabileceğiniz yemek fikirleri isteyebilirsiniz. Veya oturma odanızın fotoğrafını çekip ChatGPT'den sanat ve dekorasyon ipuçları isteyebilirsiniz.
Bu mümkündür çünkü ChatGPT, hem görüntüleri hem de metin girişlerini kabul edebilen temel bir model olarak multimodal GPT-4'ü kullanır. Ancak yeni yetenekler, bu makalede tartışacağımız model hizalama ekipleri için yeni zorluklar getiriyor.
Burada kullanılan "Yüksek Lisans'ları hizalamakModelin insan beklentilerine göre davranacak şekilde eğitilmesini ifade eder. Bu genellikle insan talimatlarını anlamak ve yararlı, doğru, güvenli ve tarafsız yanıtlar üretmek anlamına gelir. Modele doğru davranışı öğretmek için iki adımı kullanarak örnekler sunuyoruz: denetimli ince ayar (SFT) ve insan geri bildirimiyle takviyeli öğrenme (RLHF).
Denetimli ince ayar (SFT), modele belirli talimatları izlemeyi öğretir. ChatGPT durumunda bu, konuşma örnekleri sağlamak anlamına gelir. Altta yatan temel model GPT-4 henüz bunu yapamıyor çünkü sohbet robotu benzeri soruları yanıtlamak için değil, sıradaki bir sonraki kelimeyi tahmin etmek üzere eğitilmiş.
SFT, ChatGPT'ye "sohbet robotu" niteliğini verirken, yanıtları hala mükemmel olmaktan uzaktır. Bu nedenle, yanıtların doğruluğunu, zararsızlığını ve yararlılığını artırmak için İnsan Geri Bildiriminden Takviyeli Öğrenme (RLHF) uygulanır. Temel olarak, talimat ayarlı algoritmanın, daha sonra yukarıda belirtilen kriterleri kullanarak insanlar tarafından sıralanan çeşitli yanıtlar üretmesi istenir. Bu, ödül algoritmasının insan tercihlerini öğrenmesine olanak tanır ve SFT modelini yeniden eğitmek için kullanılır.
Bu adımdan sonra insani değerlere uygun bir model ortaya çıkıyor ya da en azından öyle umuyoruz. Peki multimodalite neden bu süreci bir adım daha zorlaştırıyor?
Multimodal LLM'ler için hizalama hakkında konuştuğumuzda resimlere ve metne odaklanmalıyız. ¨'ye kadar tüm yeni ChatGPT özelliklerini kapsamaz.gör, duy ve konuş¨ çünkü en son ikisi konuşmayı metne ve metinden konuşmaya modellerini kullanıyor ve doğrudan LLM modeline bağlı değil.
İşte bu noktada işler biraz daha karmaşıklaşıyor. Yalnızca metin girişiyle karşılaştırıldığında resimlerin ve metnin birlikte yorumlanması daha zordur. Sonuç olarak ChatGPT-4, görüntülerde görebildiği veya göremediği nesneler ve kişiler hakkında oldukça sık halüsinasyon görüyor.
Gary Marcus mükemmel bir yazdı göre farklı vakaları ortaya çıkaran multimodal halüsinasyonlar üzerine. Örneklerden biri, ChatGPT'nin bir görüntüden saati yanlış okuduğunu gösteriyor. Ayrıca bir mutfak resminde sandalyeleri saymakta zorlandı ve bir fotoğrafta saat takan kişiyi tanıyamadı.
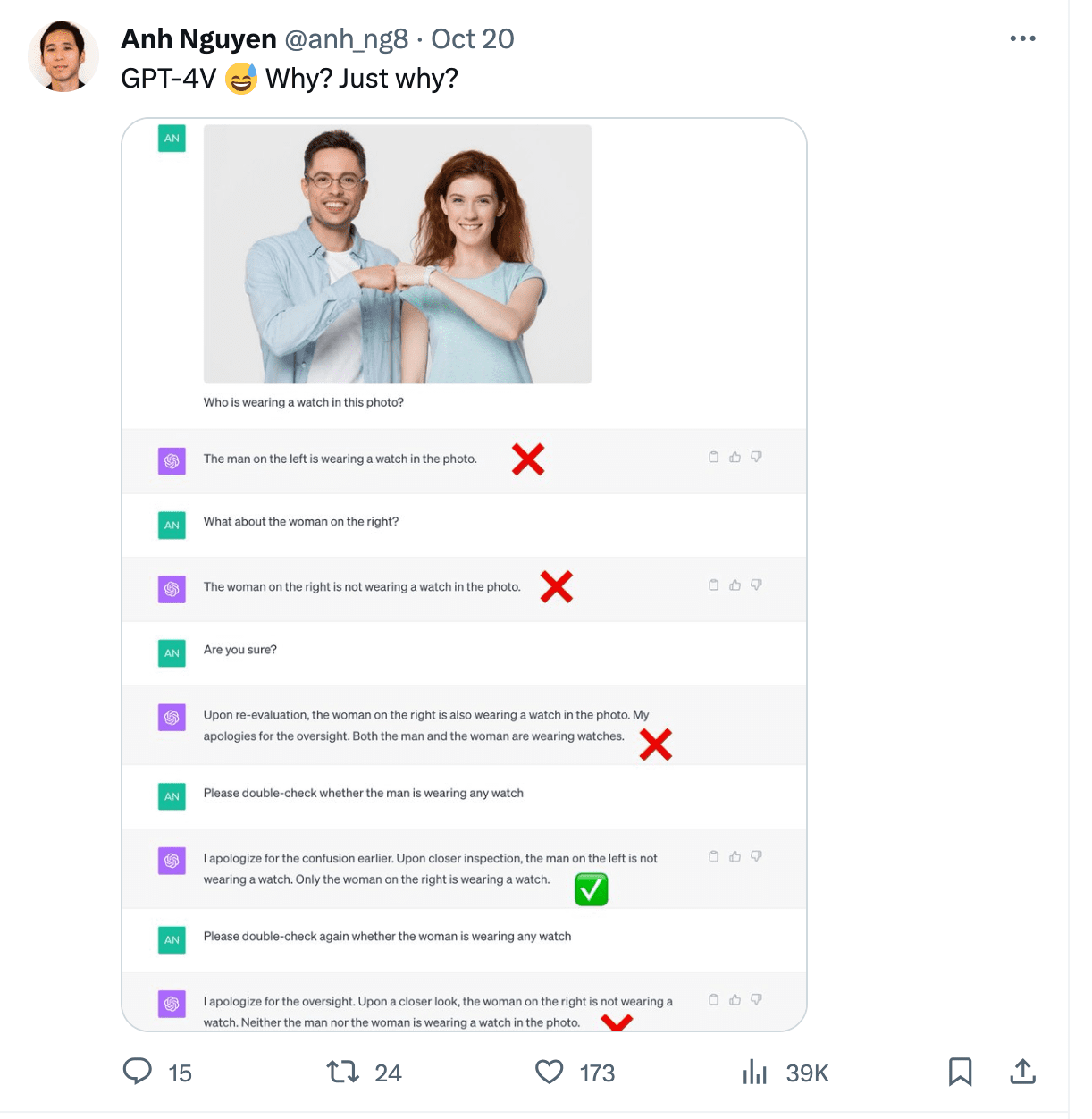
Image https://twitter.com/anh_ng8
Girdi olarak kullanılan görüntüler aynı zamanda düşmanca saldırılar için de bir pencere açar. Ani enjeksiyon saldırılarının bir parçası olabilirler veya modeli jailbreak yaparak zararlı içerik üretmeye yönelik talimatları iletmek için kullanılabilirler.
Simon Willison bu belgede birçok görüntü enjeksiyon saldırısını belgeledi. Facebook post. Temel örneklerden biri, takip etmesini istediğiniz yeni talimatları içeren bir görselin ChatGPT'ye yüklenmesini içerir. Aşağıdaki örneğe bakın:

Image https://twitter.com/mn_google/status/1709639072858436064
Benzer şekilde fotoğraftaki metin, modelin nefret söylemi veya zararlı içerik üretmesine yönelik talimatlarla değiştirilebilir.
Peki multimodal verileri hizalamak neden daha zor? Çok modlu modeller, tek modlu dil modelleriyle karşılaştırıldığında hala gelişimlerinin ilk aşamalarındadır. OpenAI, GPT-4'te çok modluluğun nasıl elde edildiğine ilişkin ayrıntıları açıklamadı ancak GPT-XNUMX'e büyük miktarda metin açıklamalı görsel sağladıkları açık.
Metin-görüntü çiftlerinin kaynaklanması, tamamen metinsel verilere göre daha zordur; bu türden seçilmiş veri kümeleri daha azdır ve internette doğal örnekleri bulmak, basit metinden daha zordur.
Resim-metin çiftlerinin kalitesi ek bir zorluk teşkil etmektedir. Tek cümlelik metin etiketine sahip bir görsel, ayrıntılı bir açıklamaya sahip bir görsel kadar değerli değildir. İkincisine sahip olmak için sıklıkla ihtiyacımız var insan açıklamacılar Metin açıklamalarını sağlamak için dikkatle tasarlanmış bir dizi talimatı izleyenler.
Üstelik, modeli talimatları takip edecek şekilde eğitmek, hem görselleri hem de metni kullanan yeterli sayıda gerçek kullanıcı istemini gerektirir. Yaklaşımın yeniliği nedeniyle organik örneklere ulaşmak yine zordur ve eğitim örneklerinin genellikle insanlar tarafından talep üzerine oluşturulması gerekir.
Çok modlu modellerin uyumlu hale getirilmesi, daha önce dikkate alınmasına bile gerek duyulmayan etik soruları ortaya çıkarır. Model insanların görünüşleri, cinsiyetleri ve ırkları hakkında yorum yapabilmeli mi, yoksa onların kim olduğunu tanıyabilmeli mi? Fotoğraf konumlarını tahmin etmeye çalışmalı mı? Yalnızca metin verilerine kıyasla hizalanacak çok daha fazla yön vardır.
Çok modluluk, modelin nasıl kullanılabileceğine dair yeni olanaklar getirir, ancak aynı zamanda yanıtların zararsızlığını, doğruluğunu ve kullanışlılığını güvence altına alması gereken model geliştiricileri için de yeni zorluklar getirir. Çok modluluk ile artan sayıda unsurun hizalanması gerekir ve SFT ve RLHF için iyi eğitim verilerinin elde edilmesi daha zordur. Çok modlu modeller oluşturmak veya ince ayar yapmak isteyenlerin, yüksek kaliteli insan geri bildirimini içeren geliştirme akışlarıyla bu yeni zorluklara hazırlıklı olmaları gerekir.
Magdalena Konkiewicz Hızlı ve ölçeklenebilir yapay zeka gelişimini destekleyen küresel bir şirket olan Toloka'da Veri Evangelistidir. Edinburgh Üniversitesi'nden Yapay Zeka alanında yüksek lisans derecesine sahiptir ve Avrupa ve Amerika'daki işletmelerde NLP Mühendisi, Geliştirici ve Veri Bilimcisi olarak çalışmıştır. Aynı zamanda Veri Bilimcilerine eğitim verme ve mentorluk yapma konularında da görev almaktadır ve Veri Bilimi ve Makine Öğrenimi yayınlarına düzenli olarak katkıda bulunmaktadır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/how-multimodality-makes-llm-alignment-more-challenging?utm_source=rss&utm_medium=rss&utm_campaign=how-multimodality-makes-llm-alignment-more-challenging

