บทนำ
การดึงข้อมูล Augmented-Generation (RAG) ได้ยึดครองโลกโดย Storm นับตั้งแต่ก่อตั้ง RAG คือสิ่งที่จำเป็นสำหรับ Large Language Models (LLM) ในการจัดหาหรือสร้างคำตอบที่ถูกต้องและเป็นข้อเท็จจริง เราแก้ไขข้อเท็จจริงของ LLM โดย RAG โดยที่เราพยายามให้ LLM มีบริบทที่คล้ายกับข้อความค้นหาของผู้ใช้ เพื่อให้ LLM ทำงานกับบริบทนี้และสร้างคำตอบที่ถูกต้องตามข้อเท็จจริง เราทำเช่นนี้โดยการแสดงข้อมูลและการสืบค้นของผู้ใช้ในรูปแบบของการฝังเวกเตอร์และดำเนินการความคล้ายคลึงโคไซน์ แต่ปัญหาก็คือว่าแนวทางดั้งเดิมทั้งหมดแสดงข้อมูลในการฝังเดียว ซึ่งอาจไม่เหมาะสำหรับผลดี ระบบการดึงข้อมูล- ในคู่มือนี้ เราจะดู ColBERT ซึ่งทำการดึงข้อมูลด้วยความแม่นยำที่ดีกว่ารุ่นเข้ารหัสคู่แบบดั้งเดิม
วัตถุประสงค์การเรียนรู้
- ทำความเข้าใจว่าการดึงข้อมูลใน RAG ทำงานอย่างไรในระดับสูง
- ทำความเข้าใจข้อจำกัดการฝังรายการเดียวในการเรียกข้อมูล
- ปรับปรุงบริบทการดึงข้อมูลด้วยการฝังโทเค็นของ ColBERT
- เรียนรู้ว่าการโต้ตอบล่าช้าของ ColBERT ช่วยปรับปรุงการดึงข้อมูลได้อย่างไร
- ทำความรู้จักกับวิธีการทำงานร่วมกับ ColBERT เพื่อการดึงข้อมูลที่แม่นยำ
บทความนี้เผยแพร่โดยเป็นส่วนหนึ่งของไฟล์ Blogathon วิทยาศาสตร์ข้อมูล
สารบัญ
RAG คืออะไร?
LLM แม้ว่าจะสามารถสร้างข้อความที่ทั้งมีความหมายและถูกต้องตามหลักไวยากรณ์ได้ แต่ LLM เหล่านี้ประสบปัญหาที่เรียกว่าภาพหลอน ภาพหลอนใน LLM เป็นแนวคิดที่ LLM สร้างคำตอบที่ผิดอย่างมั่นใจ นั่นคือพวกเขาสร้างคำตอบที่ผิดในลักษณะที่ทำให้เราเชื่อว่ามันเป็นเรื่องจริง นี่เป็นปัญหาสำคัญนับตั้งแต่มีการเปิดตัว LLM ภาพหลอนเหล่านี้นำไปสู่คำตอบที่ไม่ถูกต้องและผิดตามข้อเท็จจริง ดังนั้นจึงมีการแนะนำรุ่น Augmented การเรียกค้น
ใน RAG เรารวบรวมรายการเอกสาร/ชิ้นส่วนของเอกสารและเข้ารหัสเอกสารต้นฉบับเหล่านี้ให้เป็นการแสดงตัวเลขที่เรียกว่า vector embeddings โดยที่เวกเตอร์ฝังตัวเดียวแสดงถึงเอกสารชิ้นเดียวและจัดเก็บไว้ในฐานข้อมูลที่เรียกว่า ร้านเวกเตอร์- โมเดลที่จำเป็นสำหรับการเข้ารหัสชิ้นส่วนเหล่านี้เป็นการฝังเรียกว่าโมเดลการเข้ารหัสหรือตัวเข้ารหัสแบบไบ ตัวเข้ารหัสเหล่านี้ได้รับการฝึกฝนเกี่ยวกับคลังข้อมูลขนาดใหญ่ จึงทำให้มีประสิทธิภาพเพียงพอที่จะเข้ารหัสส่วนต่างๆ ของเอกสารในรูปแบบการฝังเวกเตอร์เพียงตัวเดียว
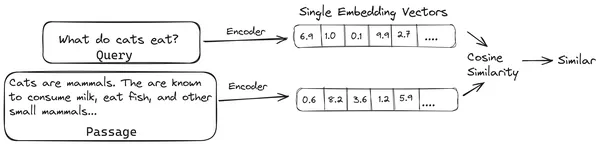
ตอนนี้เมื่อผู้ใช้ถามคำถามกับ LLM เราจะให้การสืบค้นนี้กับตัวเข้ารหัสเดียวกันเพื่อสร้างการฝังเวกเตอร์เดี่ยว การฝังนี้ใช้เพื่อคำนวณคะแนนความคล้ายคลึงกับการฝังเวกเตอร์อื่นๆ ของส่วนเอกสาร เพื่อให้ได้ส่วนที่เกี่ยวข้องมากที่สุดของเอกสาร LLM จะมอบส่วนที่เกี่ยวข้องมากที่สุดหรือรายการส่วนที่เกี่ยวข้องมากที่สุดพร้อมกับข้อความค้นหาของผู้ใช้ LLM จะได้รับข้อมูลบริบทเพิ่มเติมนี้ จากนั้นสร้างคำตอบที่สอดคล้องกับบริบทที่ได้รับจากข้อความค้นหาของผู้ใช้ เพื่อให้แน่ใจว่าเนื้อหาที่สร้างขึ้นโดย LLM นั้นเป็นข้อเท็จจริงและเป็นสิ่งที่สามารถตรวจสอบย้อนกลับได้หากจำเป็น
ปัญหาเกี่ยวกับตัวเข้ารหัสแบบ Bi แบบดั้งเดิม
ปัญหาของตัวเข้ารหัสรุ่นดั้งเดิมเช่น all-miniLM OpenAI โมเดลการฝัง และโมเดลตัวเข้ารหัสอื่น ๆ คือพวกมันบีบอัดข้อความทั้งหมดให้เป็นการแสดงการฝังเวกเตอร์เดียว การแสดงการฝังเวกเตอร์เดี่ยวเหล่านี้มีประโยชน์เนื่องจากช่วยในการเรียกค้นเอกสารที่คล้ายกันอย่างมีประสิทธิภาพและรวดเร็ว อย่างไรก็ตาม ปัญหาอยู่ที่บริบทระหว่างแบบสอบถามและเอกสาร การฝังเวกเตอร์เดี่ยวอาจไม่เพียงพอที่จะจัดเก็บข้อมูลบริบทของก้อนเอกสาร ซึ่งทำให้เกิดปัญหาคอขวดของข้อมูล
ลองนึกภาพว่ามีการบีบอัดคำ 500 คำเป็นเวกเตอร์เดียวขนาด 782 อาจไม่เพียงพอที่จะแสดงชิ้นส่วนดังกล่าวด้วยการฝังเวกเตอร์เพียงตัวเดียว ดังนั้นจึงให้ผลลัพธ์ที่ต่ำกว่ามาตรฐานในการดึงข้อมูลในกรณีส่วนใหญ่ การแสดงเวกเตอร์เดี่ยวอาจล้มเหลวในกรณีที่มีการสืบค้นหรือเอกสารที่ซับซ้อน วิธีแก้ไขประการหนึ่งคือการแสดงกลุ่มเอกสารหรือแบบสอบถามเป็นรายการเวกเตอร์ที่ฝังแทนที่จะเป็นเวกเตอร์ที่ฝังตัวเดียว นี่คือจุดที่ ColBERT เข้ามา
ColBERT คืออะไร?
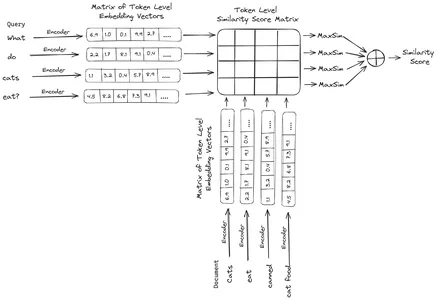
ColBERT (การโต้ตอบล่าช้าตามบริบท BERT) เป็นตัวเข้ารหัสสองตัวที่แสดงข้อความในการนำเสนอแบบฝังหลายเวกเตอร์ ใช้แบบสอบถามหรือชิ้นส่วนของเอกสาร / เอกสารขนาดเล็กและสร้างการฝังเวกเตอร์ในระดับโทเค็น นั่นคือแต่ละโทเค็นจะได้รับการฝังเวกเตอร์ของตัวเอง และแบบสอบถาม/เอกสารจะถูกเข้ารหัสลงในรายการของการฝังเวกเตอร์ระดับโทเค็น การฝังระดับโทเค็นจะถูกสร้างขึ้นจากการฝึกอบรมล่วงหน้า BERT โมเดลจึงได้ชื่อว่า BERT
จากนั้นสิ่งเหล่านี้จะถูกจัดเก็บไว้ในฐานข้อมูลเวกเตอร์ ตอนนี้ เมื่อมีการสืบค้นเข้ามา รายการของการฝังระดับโทเค็นจะถูกสร้างขึ้นสำหรับการค้นหา จากนั้นจะมีการคูณเมทริกซ์ระหว่างการสืบค้นของผู้ใช้กับแต่ละเอกสาร ซึ่งส่งผลให้เมทริกซ์มีคะแนนความคล้ายคลึงกัน ความคล้ายคลึงกันโดยรวมทำได้โดยการหาผลรวมของความคล้ายคลึงกันสูงสุดในโทเค็นเอกสารสำหรับโทเค็นการสืบค้นแต่ละรายการ สูตรนี้สามารถดูได้ในรูปด้านล่าง:
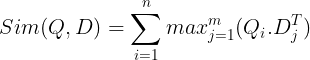
ในสมการข้างต้น เราจะเห็นว่าเราทำดอทโปรดัคระหว่าง Query Tokens Matrix (ที่มีการฝังเวกเตอร์ระดับโทเค็น N) และ Transpose ของ Document Tokens Matrix (ที่มีการฝังเวกเตอร์ระดับโทเค็น M) จากนั้นเราจะรับความคล้ายคลึงกันสูงสุด ข้ามโทเค็นเอกสารสำหรับโทเค็นการสืบค้นแต่ละรายการ จากนั้นเราจะนำผลรวมของความคล้ายคลึงสูงสุดเหล่านี้ทั้งหมด ซึ่งจะให้คะแนนความคล้ายคลึงกันขั้นสุดท้ายระหว่างเอกสารและแบบสอบถาม เหตุผลที่ทำให้ดึงข้อมูลได้อย่างมีประสิทธิภาพและแม่นยำก็คือ ที่นี่เรากำลังมีการโต้ตอบระดับโทเค็น ซึ่งให้พื้นที่สำหรับความเข้าใจบริบทมากขึ้นระหว่างแบบสอบถามและเอกสาร
ทำไมถึงชื่อโคลเบิร์ต?
ในขณะที่เรากำลังคำนวณรายการเวกเตอร์ที่ฝังไว้ข้างหน้าตัวมันเอง และดำเนินการเฉพาะการดำเนินการ MaxSim (ความคล้ายคลึงสูงสุด) นี้ในระหว่างการอนุมานโมเดลเท่านั้น จึงเรียกว่าขั้นตอนการโต้ตอบล่าช้า และในขณะที่เราได้รับข้อมูลเชิงบริบทมากขึ้นผ่านการโต้ตอบระดับโทเค็น จึงเรียกว่าบริบทตามบริบท การโต้ตอบล่าช้า ดังนั้นชื่อการโต้ตอบล่าช้าตามบริบท BERT หรือโคลเบิร์ต การคำนวณเหล่านี้สามารถดำเนินการแบบคู่ขนานได้ จึงสามารถคำนวณได้อย่างมีประสิทธิภาพ สุดท้าย ข้อกังวลประการหนึ่งคือพื้นที่ กล่าวคือ ต้องใช้พื้นที่จำนวนมากในการจัดเก็บรายการการฝังเวกเตอร์ระดับโทเค็น ปัญหานี้ได้รับการแก้ไขใน ColBERTv2 โดยที่การฝังจะถูกบีบอัดผ่านเทคนิคที่เรียกว่าการบีบอัดที่เหลือ ดังนั้นจึงเป็นการเพิ่มประสิทธิภาพพื้นที่ที่ใช้
ColBERT แบบลงมือปฏิบัติพร้อมตัวอย่าง
ในส่วนนี้ เราจะได้ลงมือปฏิบัติจริงกับ ColBERT และแม้แต่ตรวจสอบประสิทธิภาพการทำงานของมันกับโมเดลการฝังทั่วไป
ขั้นตอนที่ 1: ดาวน์โหลดไลบรารี
เราจะเริ่มต้นด้วยการดาวน์โหลดไลบรารี่ต่อไปนี้:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- รากาตูย: ไลบรารีนี้ช่วยให้เราทำงานกับวิธีการดึงข้อมูลที่ทันสมัย (SOTA) เช่น ColBERT ในวิธีที่ง่ายต่อการใช้งาน โดยมีตัวเลือกในการสร้างดัชนีบนชุดข้อมูล การสืบค้นชุดข้อมูล และแม้กระทั่งช่วยให้เราสามารถฝึกโมเดล ColBERT กับข้อมูลของเราได้
- แลงเชน: ไลบรารีนี้จะช่วยให้เราทำงานกับโมเดลการฝังโอเพ่นซอร์ส เพื่อให้เราสามารถทดสอบว่าโมเดลการฝังอื่นๆ ทำงานได้ดีเพียงใดเมื่อเปรียบเทียบกับ ColBERT
- langchain_openai: ติดตั้ง หลังเชน การพึ่งพาสำหรับ OpenAI เราจะทำงานร่วมกับโมเดล OpenAI Embedding เพื่อตรวจสอบประสิทธิภาพเทียบกับ ColBERT
- โครมาดีบี: ไลบรารีนี้จะให้เราสร้างร้านค้าเวกเตอร์ในสภาพแวดล้อมของเรา เพื่อให้เราสามารถบันทึกการฝังที่เราสร้างขึ้นในข้อมูลของเรา และทำการค้นหาเชิงความหมายระหว่างแบบสอบถามและการฝังที่เก็บไว้ในภายหลัง
- einops: ไลบรารีนี้จำเป็นสำหรับการคูณเมทริกซ์เทนเซอร์ที่มีประสิทธิภาพ
- หม้อแปลงประโยค และ ติ๊กต๊อก จำเป็นต้องมีไลบรารีเพื่อให้โมเดลการฝังโอเพ่นซอร์สทำงานได้อย่างถูกต้อง
ขั้นตอนที่ 2: ดาวน์โหลดโมเดลที่ได้รับการฝึกล่วงหน้า
ในขั้นตอนถัดไป เราจะดาวน์โหลดโมเดล ColBERT ที่ได้รับการฝึกล่วงหน้า สำหรับสิ่งนี้โค้ดจะเป็น
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- ก่อนอื่นเราจะนำเข้าคลาส RAGPretrainedModel จากไลบรารี RAGatouille
- จากนั้นเราเรียก .from_pretrained() และตั้งชื่อโมเดล เช่น “colbert-ir/colbertv2.0”
การรันโค้ดด้านบนจะสร้างอินสแตนซ์ของโมเดล ColBERT RAG ตอนนี้เรามาดาวน์โหลดหน้า Wikipedia และทำการดึงข้อมูลจากหน้านั้น สำหรับสิ่งนี้ รหัสจะเป็น:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille มาพร้อมกับฟังก์ชันที่มีประโยชน์ที่เรียกว่า get_wikipedia_page ซึ่งรับสตริงและรับหน้า Wikipedia ที่เกี่ยวข้อง ที่นี่เราดาวน์โหลดเนื้อหา Wikipedia บน Elon Musk และจัดเก็บไว้ในเอกสารตัวแปร มาพิมพ์จำนวนคำที่มีอยู่ในเอกสารและสองสามบรรทัดแรกของเอกสารกัน
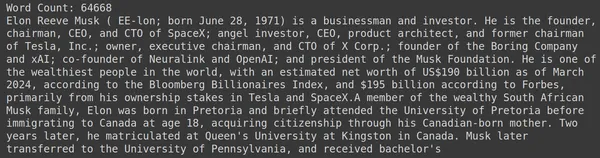
ที่นี่เราสามารถเห็นผลลัพธ์ในรูป เราจะเห็นได้ว่ามีคำศัพท์ทั้งหมด 64,668 คำในหน้า Wikipedia ของ Elon Musk
ขั้นตอนที่ 3: การสร้างดัชนี
ตอนนี้เราจะสร้างดัชนีในเอกสารนี้
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)ที่นี่เราเรียก .index() ของ RAG เพื่อสร้างดัชนีเอกสารของเรา เราผ่านสิ่งต่อไปนี้:
- คอลเลกชัน: นี่คือรายการเอกสารที่เราต้องการจัดทำดัชนี ที่นี่เรามีเอกสารเพียงฉบับเดียว ดังนั้นจึงเป็นรายการเอกสารฉบับเดียว
- document_ids: แต่ละเอกสารต้องการรหัสเอกสารที่ไม่ซ้ำกัน ต่อไปนี้เราจะตั้งชื่อว่า elon_musk เพราะเอกสารเกี่ยวกับ Elon Musk
- document_metadata: แต่ละเอกสารมีข้อมูลเมตาของมัน นี่เป็นรายการพจนานุกรมอีกครั้ง โดยแต่ละพจนานุกรมจะมีข้อมูลเมตาของคู่คีย์-ค่าสำหรับเอกสารหนึ่งๆ
- ดัชนี_ชื่อ: ชื่อของดัชนีที่เรากำลังสร้าง ตั้งชื่อมันว่า Elon2 กันเถอะ
- สูงสุด_เอกสาร_ขนาด: นี้จะคล้ายกับขนาดก้อน เราระบุจำนวนเอกสารแต่ละชิ้นว่าควรมีจำนวนเท่าใด ในที่นี้เราจะให้ค่าเป็น 256 หากเราไม่ระบุค่าใดๆ 256 จะถือเป็นขนาดเริ่มต้นของก้อน
- split_documents: เป็นค่าบูลีน โดยที่ True ระบุว่าเราต้องการแยกเอกสารตามขนาดก้อนที่กำหนด และ False บ่งชี้ว่าเราต้องการจัดเก็บเอกสารทั้งหมดเป็นชิ้นเดียว
การรันโค้ดด้านบนจะแบ่งเอกสารของเราเป็นชิ้นขนาด 256 ชิ้นต่อชิ้น จากนั้นฝังเอกสารเหล่านั้นผ่านโมเดล ColBERT ซึ่งจะสร้างรายการของการฝังเวกเตอร์ระดับโทเค็นสำหรับแต่ละชิ้น และสุดท้ายจัดเก็บไว้ในดัชนี ขั้นตอนนี้จะใช้เวลาสักครู่ในการรันและสามารถเร่งความเร็วได้หากมี GPU สุดท้ายจะสร้างไดเร็กทอรีที่เก็บดัชนีของเรา ที่นี่ไดเรกทอรีจะเป็น “.ragatouille/colbert/indexes/Elon2”
ขั้นตอนที่ 4: แบบสอบถามทั่วไป
ตอนนี้เราจะเริ่มการค้นหา สำหรับสิ่งนี้โค้ดจะเป็น
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- อันดับแรก เราเรียกเมธอด .search() ของอ็อบเจ็กต์ RAG
- ในการนี้ เราให้ตัวแปรที่มีชื่อแบบสอบถาม k (จำนวนเอกสารที่จะดึงข้อมูล) และชื่อดัชนีที่จะค้นหา
- ที่นี่เราให้คำถาม "บริษัทใดบ้างที่ Elon Musk พบ" ผลลัพธ์ที่ได้จะอยู่ในรายการรูปแบบพจนานุกรมซึ่งประกอบด้วยคีย์ต่างๆ เช่น เนื้อหา คะแนน อันดับ document_id Passage_id และ document_metadata
- ดังนั้นเราจึงทำงานร่วมกับโค้ดด้านล่างเพื่อพิมพ์เอกสารที่ดึงมาได้อย่างเรียบร้อย
- ที่นี่เราจะดูรายการพจนานุกรมและพิมพ์เนื้อหาของเอกสาร
การรันโค้ดจะให้ผลลัพธ์ดังต่อไปนี้:
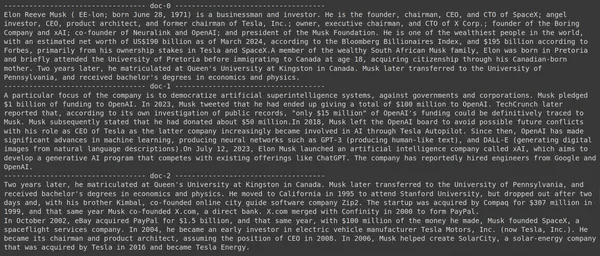
ในภาพ เราจะเห็นว่าเอกสารฉบับแรกและฉบับสุดท้ายครอบคลุมถึงบริษัทต่างๆ ที่ก่อตั้งโดย Elon Musk ทั้งหมด ColBERT สามารถดึงข้อมูลชิ้นส่วนที่เกี่ยวข้องซึ่งจำเป็นต่อการตอบคำถามได้อย่างถูกต้อง
ขั้นตอนที่ 5: แบบสอบถามเฉพาะ
ตอนนี้เรามาดูขั้นตอนต่อไปและถามคำถามที่เฉพาะเจาะจงกัน
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])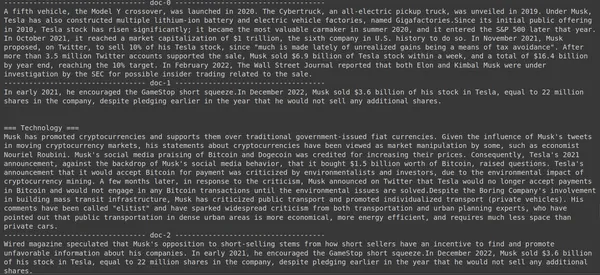
ในโค้ดด้านบนนี้ เรากำลังถามคำถามเฉพาะเจาะจงเกี่ยวกับมูลค่าหุ้นของ Tesla Elon ที่ขายได้ในเดือนธันวาคม 2022 เราสามารถดูผลลัพธ์ได้ที่นี่ เอกสาร-1 มีคำตอบสำหรับคำถาม Elon ขายหุ้นของเขาใน Tesla มูลค่า 3.6 พันล้านดอลลาร์ ขอย้ำอีกครั้งว่า ColBERT สามารถดึงข้อมูลส่วนที่เกี่ยวข้องสำหรับข้อความค้นหาที่กำหนดได้สำเร็จ
ขั้นตอนที่ 6: ทดสอบรุ่นอื่น ๆ
ตอนนี้เรามาลองคำถามเดียวกันกับโมเดลการฝังอื่นๆ ทั้งแบบโอเพ่นซอร์สและแบบปิดที่นี่:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- เราเริ่มต้นด้วยการดาวน์โหลดโมเดลก่อนผ่านคลาส AutoModel จากไลบรารี Transformers
- จากนั้นเราจะจัดเก็บ model_name และ model_kwargs ไว้ในตัวแปรตามลำดับ
- ตอนนี้เพื่อทำงานกับโมเดลนี้ใน LangChain เราจะนำเข้า HuggingFaceEmbeddings จาก หลังเชน และตั้งชื่อรุ่นและ model_kwargs
การรันโค้ดนี้จะดาวน์โหลดและโหลดโมเดลการฝัง Jina เพื่อให้เราสามารถทำงานกับมันได้
ขั้นตอนที่ 7: สร้างการฝัง
ตอนนี้ เราต้องเริ่มแยกเอกสารของเรา จากนั้นสร้างการฝังจากเอกสารนั้น และจัดเก็บไว้ใน Chroma vector store เพื่อสิ่งนี้ เราทำงานกับโค้ดต่อไปนี้:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- เราเริ่มต้นด้วยการนำเข้า Chroma และ RecursiveCharacterTextSplitter จากไลบรารี LangChain
- จากนั้นเราสร้างตัวอย่าง text_splitter โดยการเรียก .from_tiktoken_encoder ของ RecursiveCharacterTextSplitter แล้วส่งต่อเป็น chunk_size และ chunk_overlap
- ที่นี่เราจะใช้ chunk_size เดียวกันกับที่เราให้ไว้กับ ColBERT
- จากนั้นเราจะเรียกเมธอด .split_text() ของ text_splitter นี้ และมอบเอกสารที่มีข้อมูล Wikipedia เกี่ยวกับ Elon Musk ให้กับมัน จากนั้นจะแยกเอกสารตามขนาดชิ้นที่กำหนด และสุดท้าย รายการชิ้นส่วนเอกสารจะถูกจัดเก็บไว้ในการแยกตัวแปร
- สุดท้ายนี้ เราเรียกฟังก์ชัน .from_texts() ของคลาส Chroma เพื่อสร้างที่เก็บเวกเตอร์ สำหรับฟังก์ชันนี้ เราให้การแยก โมเดลการฝัง และ collection_name
- ตอนนี้เราสร้างรีทรีฟเวอร์ขึ้นมาโดยการเรียกใช้ฟังก์ชัน .as_retriever() ของอ็อบเจ็กต์ vector store เราให้ 3 สำหรับค่า k
การเรียกใช้โค้ดนี้จะนำเอกสารของเรามาแยกออกเป็นเอกสารขนาดเล็กขนาด 256 ต่อชิ้น จากนั้นฝังชิ้นเล็กๆ เหล่านี้ด้วยโมเดลการฝัง Jina และจัดเก็บเวกเตอร์ที่ฝังเหล่านี้ไว้ในที่เก็บเวกเตอร์โครมา
ขั้นตอนที่ 8: การสร้างรีทรีฟเวอร์
ในที่สุดเราก็สร้างรีทรีฟเวอร์ขึ้นมา ตอนนี้เราจะทำการค้นหาเวกเตอร์และตรวจสอบผลลัพธ์
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)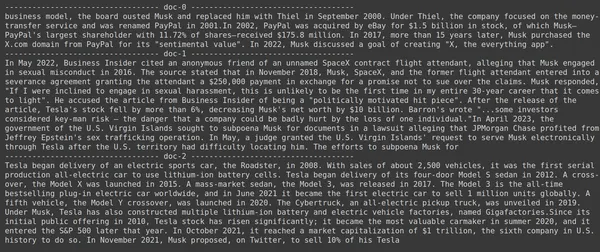
- เราเรียกฟังก์ชัน .get_relevent_documents() ของอ็อบเจ็กต์ตัวดึงข้อมูล และให้คำค้นหาเดียวกัน
- จากนั้นเราจะพิมพ์เอกสารที่ดึงมา 3 อันดับแรกอย่างเรียบร้อย
- ในภาพ เราจะเห็นว่า Jina Embedder แม้ว่าจะเป็นโมเดลการฝังที่ได้รับความนิยม แต่การดึงข้อมูลสำหรับการสืบค้นของเรายังทำได้ไม่ดี ไม่สามารถรับชิ้นส่วนเอกสารที่ถูกต้องได้
เราสามารถมองเห็นความแตกต่างได้อย่างชัดเจนระหว่าง Jina ซึ่งเป็นโมเดลการฝังที่แสดงถึงแต่ละชิ้นเป็นการฝังเวกเตอร์เดียว และโมเดล ColBERT ซึ่งแสดงถึงแต่ละชิ้นเป็นรายการของเวกเตอร์การฝังระดับโทเค็น ColBERT มีประสิทธิภาพเหนือกว่าอย่างชัดเจนในกรณีนี้
ขั้นตอนที่ 9: ทดสอบโมเดลการฝังของ OpenAI
ตอนนี้เรามาลองใช้โมเดลการฝังแบบโอเพนซอร์ส เช่น โมเดลการฝัง OpenAI
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})โค้ดที่นี่คล้ายกับโค้ดที่เราเพิ่งเขียนไปมาก
- ข้อแตกต่างเพียงอย่างเดียวคือ เราส่งคีย์ OpenAI API เพื่อตั้งค่าตัวแปรสภาพแวดล้อม
- จากนั้นเราจะสร้างอินสแตนซ์ของโมเดล OpenAI Embedding โดยการนำเข้าจาก LangChain
- และในขณะที่สร้างชื่อคอลเลกชัน เราจะตั้งชื่อคอลเลกชันอื่น เพื่อให้การฝังจากโมเดล OpenAI Embedding จะถูกเก็บไว้ในคอลเลกชันอื่น
การรันโค้ดนี้จะนำเอกสารของเราอีกครั้ง แบ่งเป็นเอกสารขนาดเล็กขนาด 256 จากนั้นฝังลงในการแสดงการฝังเวกเตอร์เดี่ยวด้วยโมเดลการฝัง OpenAI และสุดท้ายจะจัดเก็บการฝังเหล่านี้ใน Chroma Vector Store ตอนนี้เรามาลองดึงเอกสารที่เกี่ยวข้องไปยังคำถามอื่นกัน
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)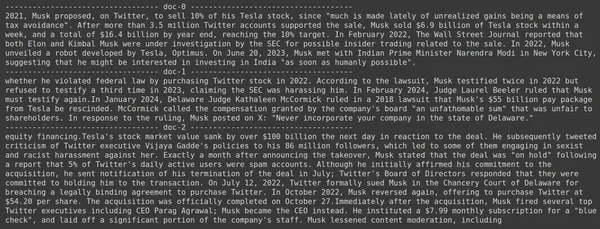
- เราเห็นว่าคำตอบที่เราคาดหวังนั้นไม่พบภายในส่วนที่ดึงมา
- ชิ้นนี้มีข้อมูลเกี่ยวกับหุ้นของ Tesla ในปี 2022 แต่ไม่ได้พูดถึงการขายหุ้นของ Elon
- สิ่งเดียวกันนี้สามารถเห็นได้จากเอกสารอีกสองชิ้นที่เหลือ ซึ่งข้อมูลที่มีอยู่ในนั้นเกี่ยวกับ Tesla และหุ้นของบริษัท แต่นี่ไม่ใช่ข้อมูลที่เราคาดหวัง
- ส่วนที่ดึงข้อมูลมาข้างต้นจะไม่ให้บริบทสำหรับ LLM ในการตอบคำถามที่เราให้ไว้
แม้แต่ที่นี่ เราก็สามารถเห็นความแตกต่างที่ชัดเจนระหว่างการแสดงแบบฝังเวกเตอร์เดี่ยว กับการแสดงแบบฝังหลายเวกเตอร์ การแสดงการฝังหลายรายการจะจับการสืบค้นที่ซับซ้อนได้อย่างชัดเจน ซึ่งส่งผลให้สามารถเรียกค้นข้อมูลได้แม่นยำยิ่งขึ้น
สรุป
โดยสรุป ColBERT แสดงให้เห็นถึงความก้าวหน้าที่สำคัญในประสิทธิภาพการดึงข้อมูลเหนือโมเดลตัวเข้ารหัสสองตัวแบบดั้งเดิมโดยการแสดงข้อความเป็นการฝังหลายเวกเตอร์ในระดับโทเค็น วิธีการนี้ช่วยให้มีความเข้าใจบริบทที่เหมาะสมยิ่งขึ้นระหว่างคำถามและเอกสาร ซึ่งนำไปสู่ผลลัพธ์การเรียกค้นที่แม่นยำยิ่งขึ้น และบรรเทาปัญหาภาพหลอนที่มักพบใน LLM
ประเด็นที่สำคัญ
- RAG แก้ไขปัญหาภาพหลอนใน LLM โดยการให้ข้อมูลเชิงบริบทสำหรับการสร้างคำตอบตามข้อเท็จจริง
- ตัวเข้ารหัสแบบคู่แบบดั้งเดิมประสบปัญหาคอขวดของข้อมูลเนื่องจากการบีบอัดข้อความทั้งหมดเป็นการฝังเวกเตอร์เดี่ยว ส่งผลให้ได้รับความแม่นยำต่ำกว่ามาตรฐาน
- ColBERT ซึ่งมีการแสดงการฝังระดับโทเค็น ช่วยให้เข้าใจบริบทระหว่างข้อความค้นหาและเอกสารได้ดีขึ้น ซึ่งนำไปสู่ประสิทธิภาพการดึงข้อมูลที่ดีขึ้น
- ขั้นตอนการโต้ตอบล่าช้าใน ColBERT รวมกับการโต้ตอบระดับโทเค็น ช่วยเพิ่มความแม่นยำในการดึงข้อมูลโดยการพิจารณาความแตกต่างทางบริบท
- ColBERTv2 เพิ่มประสิทธิภาพพื้นที่จัดเก็บข้อมูลผ่านการบีบอัดส่วนที่เหลือในขณะที่ยังคงประสิทธิภาพในการดึงข้อมูล
- การทดลองภาคปฏิบัติแสดงให้เห็นถึงความเหนือกว่าของ ColBERT ในด้านประสิทธิภาพในการดึงข้อมูล เมื่อเปรียบเทียบกับโมเดลการฝังแบบดั้งเดิมและแบบโอเพ่นซอร์ส เช่น Jina และ OpenAI Embedding
คำถามที่พบบ่อย
A. ตัวเข้ารหัสแบบคู่แบบดั้งเดิมจะบีบอัดข้อความทั้งหมดเป็นการฝังเวกเตอร์ตัวเดียว ซึ่งอาจสูญเสียข้อมูลเชิงบริบทไป ซึ่งจะจำกัดประสิทธิภาพในการดึงข้อมูล โดยเฉพาะเมื่อมีการสืบค้นหรือเอกสารที่ซับซ้อน
A. ColBERT (การโต้ตอบล่าช้าตามบริบท BERT) คือโมเดลตัวเข้ารหัสสองตัวที่แสดงข้อความโดยใช้การฝังเวกเตอร์ระดับโทเค็น ช่วยให้มีความเข้าใจบริบทที่เหมาะสมยิ่งขึ้นระหว่างการสืบค้นและเอกสาร ปรับปรุงความแม่นยำในการเรียกค้น
A. ColBERT สร้างการฝังระดับโทเค็นสำหรับการสืบค้นและเอกสาร ดำเนินการคูณเมทริกซ์เพื่อคำนวณคะแนนความคล้ายคลึงกัน จากนั้นเลือกข้อมูลที่เกี่ยวข้องมากที่สุดตามความคล้ายคลึงกันสูงสุดระหว่างโทเค็นต่างๆ ซึ่งช่วยให้สามารถดึงข้อมูลได้อย่างมีประสิทธิภาพด้วยความเข้าใจตามบริบท
A. ColBERTv2 ปรับ Space ให้เหมาะสมด้วยวิธีการบีบอัดส่วนที่เหลือ ช่วยลดความต้องการพื้นที่จัดเก็บข้อมูลสำหรับการฝังระดับโทเค็น ในขณะที่ยังคงความแม่นยำในการดึงข้อมูล
A. คุณสามารถใช้ไลบรารีเช่น RAGatouille เพื่อทำงานกับ ColBERT ได้อย่างง่ายดาย ด้วยการจัดทำดัชนีเอกสารและการสืบค้น คุณสามารถดำเนินการดึงข้อมูลได้อย่างมีประสิทธิภาพ และสร้างคำตอบที่แม่นยำซึ่งสอดคล้องกับบริบท
สื่อที่แสดงในบทความนี้ไม่ได้เป็นของ Analytics Vidhya และถูกใช้ตามดุลยพินิจของผู้เขียน
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

