บทนำ
Cohere เปิดตัวโมเดลพื้นฐานรุ่นถัดไป Rerank 3 เพื่อการค้นหาระดับองค์กรที่มีประสิทธิภาพและ การดึงข้อมูล Augmented Generation(แร็ก). โมเดล Rerank เข้ากันได้กับทุกประเภท ฐานข้อมูล หรือดัชนีการค้นหา และยังสามารถรวมเข้ากับแอปพลิเคชันทางกฎหมายใดๆ ที่มีความสามารถในการค้นหาแบบเนทีฟ คุณจะจินตนาการไม่ออกเลยว่าโค้ดเพียงบรรทัดเดียวสามารถเพิ่มประสิทธิภาพการค้นหาหรือลดค่าใช้จ่ายในการเรียกใช้ได้ แอปพลิเคชัน RAG โดยมีผลกระทบเล็กน้อยต่อเวลาในการตอบสนอง
เรามาสำรวจว่าโมเดลพื้นฐานนี้ได้รับการตั้งค่าอย่างไรเพื่อพัฒนาการค้นหาระดับองค์กรและระบบ RAG ด้วยความแม่นยำและประสิทธิภาพที่เพิ่มขึ้น

ความสามารถของการจัดอันดับใหม่
การจัดอันดับใหม่นำเสนอความสามารถที่ดีที่สุดสำหรับการค้นหาระดับองค์กรซึ่งรวมถึงสิ่งต่อไปนี้:
- ความยาวบริบท 4K ซึ่งช่วยเพิ่มคุณภาพการค้นหาสำหรับเอกสารที่มีรูปแบบยาวขึ้นอย่างมาก
- สามารถค้นหาข้อมูลหลายด้านและกึ่งโครงสร้าง เช่น ตาราง รหัส JSON เอกสาร ใบแจ้งหนี้ และอีเมล
- สามารถครอบคลุมได้มากกว่า 100 ภาษา
- เวลาแฝงที่เพิ่มขึ้นและต้นทุนรวมในการเป็นเจ้าของ (TCO) ที่ลดลง
โมเดล AI เจนเนอเรชั่น ด้วยบริบทที่ยาวมีศักยภาพในการดำเนินการ RAG เพื่อที่จะปรับปรุงคะแนนความแม่นยำ เวลาแฝง และต้นทุน โซลูชัน RAG จะต้องอาศัยการสร้างร่วมกัน โมเดล AI และแน่นอนว่าโมเดล Rerank การจัดอันดับความหมายใหม่ที่มีความแม่นยำสูงของการจัดอันดับใหม่ 3 ช่วยให้แน่ใจว่าเฉพาะข้อมูลที่เกี่ยวข้องเท่านั้นที่จะถูกป้อนไปยังโมเดลการสร้าง ซึ่งเพิ่มความแม่นยำในการตอบสนอง และรักษาเวลาแฝงและต้นทุนให้ต่ำมาก โดยเฉพาะอย่างยิ่งเมื่อดึงข้อมูลจากเอกสารนับล้าน
การค้นหาระดับองค์กรที่ได้รับการปรับปรุง
ข้อมูลองค์กรมักจะซับซ้อนมาก และระบบปัจจุบันที่อยู่ในองค์กรประสบปัญหาในการค้นหาผ่านแหล่งข้อมูลหลายด้านและกึ่งโครงสร้าง โดยหลักแล้ว ในองค์กร ข้อมูลที่มีประโยชน์ที่สุดไม่ได้อยู่ในรูปแบบเอกสารธรรมดา เช่น JSON ซึ่งพบได้ทั่วไปในแอปพลิเคชันระดับองค์กร อันดับ 3 สามารถจัดอันดับที่ซับซ้อนและหลากหลายแง่มุมได้อย่างง่ายดาย เช่น อีเมลโดยอิงตามช่องข้อมูลเมตาที่เกี่ยวข้องทั้งหมด รวมถึงความใหม่ด้วย

การจัดอันดับใหม่ 3 ปรับปรุงวิธีการดึงรหัสได้ดียิ่งขึ้นอย่างมาก สิ่งนี้สามารถเพิ่มประสิทธิภาพการทำงานของวิศวกรด้วยการช่วยให้พวกเขาค้นหาส่วนย่อยของโค้ดที่ถูกต้องได้รวดเร็วยิ่งขึ้น ไม่ว่าจะอยู่ในฐานโค้ดของบริษัทหรือในคลังเอกสารขนาดใหญ่
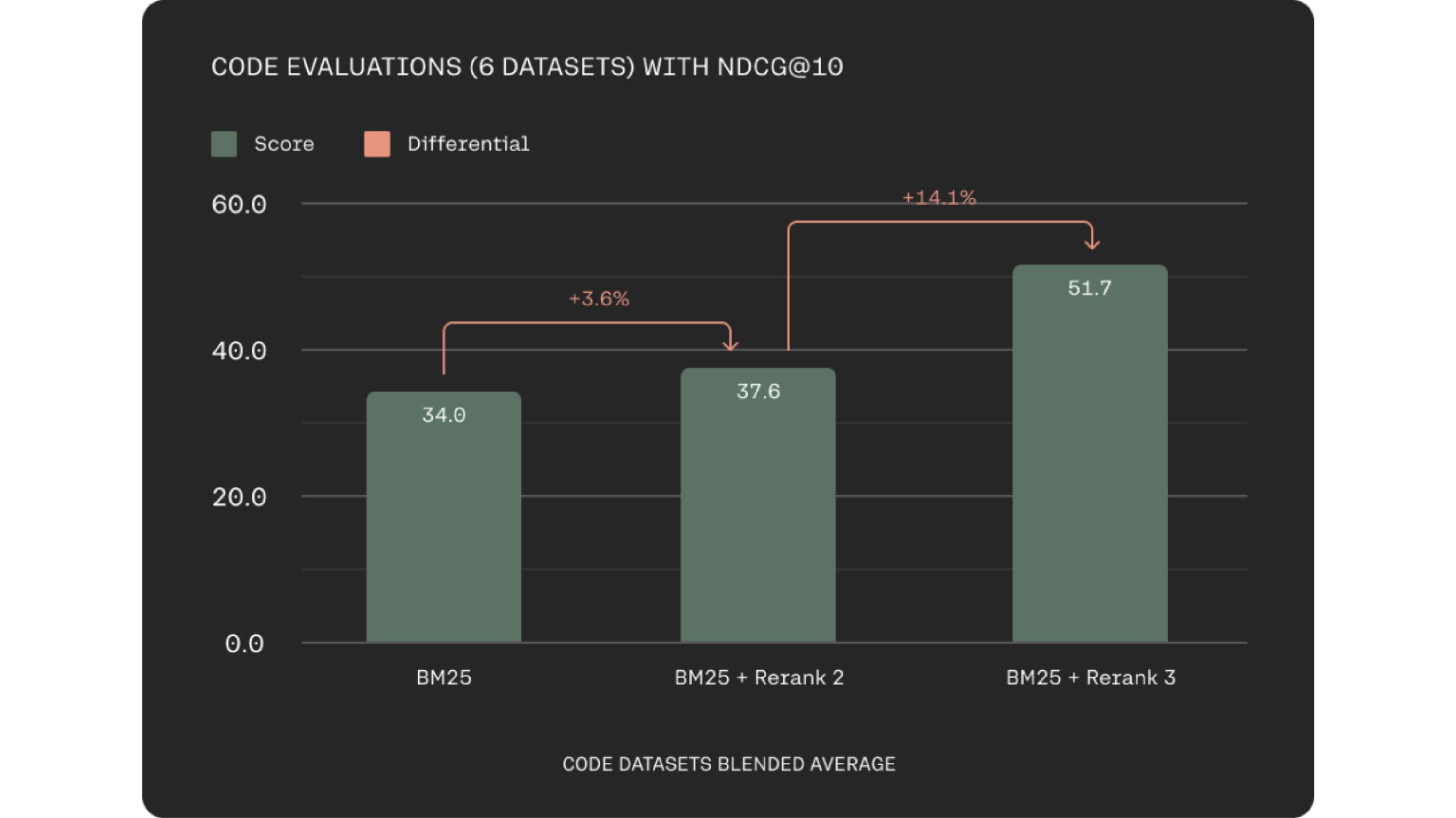
ยักษ์ใหญ่ด้านเทคโนโลยียังต้องจัดการกับแหล่งข้อมูลหลายภาษา และการดึงข้อมูลหลายภาษาก่อนหน้านี้ถือเป็นความท้าทายที่ใหญ่ที่สุดเกี่ยวกับวิธีการที่ใช้คำหลัก โมเดล Rerank 3 นำเสนอประสิทธิภาพหลายภาษาที่แข็งแกร่งด้วยภาษามากกว่า 100+ ภาษา ซึ่งทำให้กระบวนการดึงข้อมูลสำหรับลูกค้าที่ไม่พูดภาษาอังกฤษทำได้ง่ายขึ้น
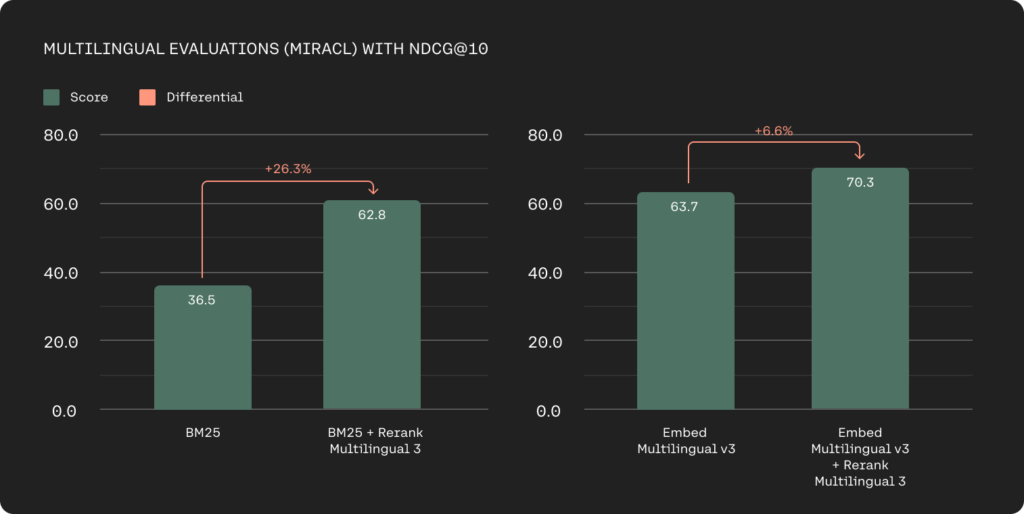
ความท้าทายที่สำคัญในการค้นหาความหมายและระบบ RAG คือการเพิ่มประสิทธิภาพการแบ่งกลุ่มข้อมูล การจัดอันดับใหม่ 3 แก้ไขปัญหานี้ด้วยหน้าต่างบริบท 4k ช่วยให้สามารถประมวลผลเอกสารขนาดใหญ่ได้โดยตรง สิ่งนี้นำไปสู่การพิจารณาบริบทที่ดีขึ้นในระหว่างการให้คะแนนความเกี่ยวข้อง
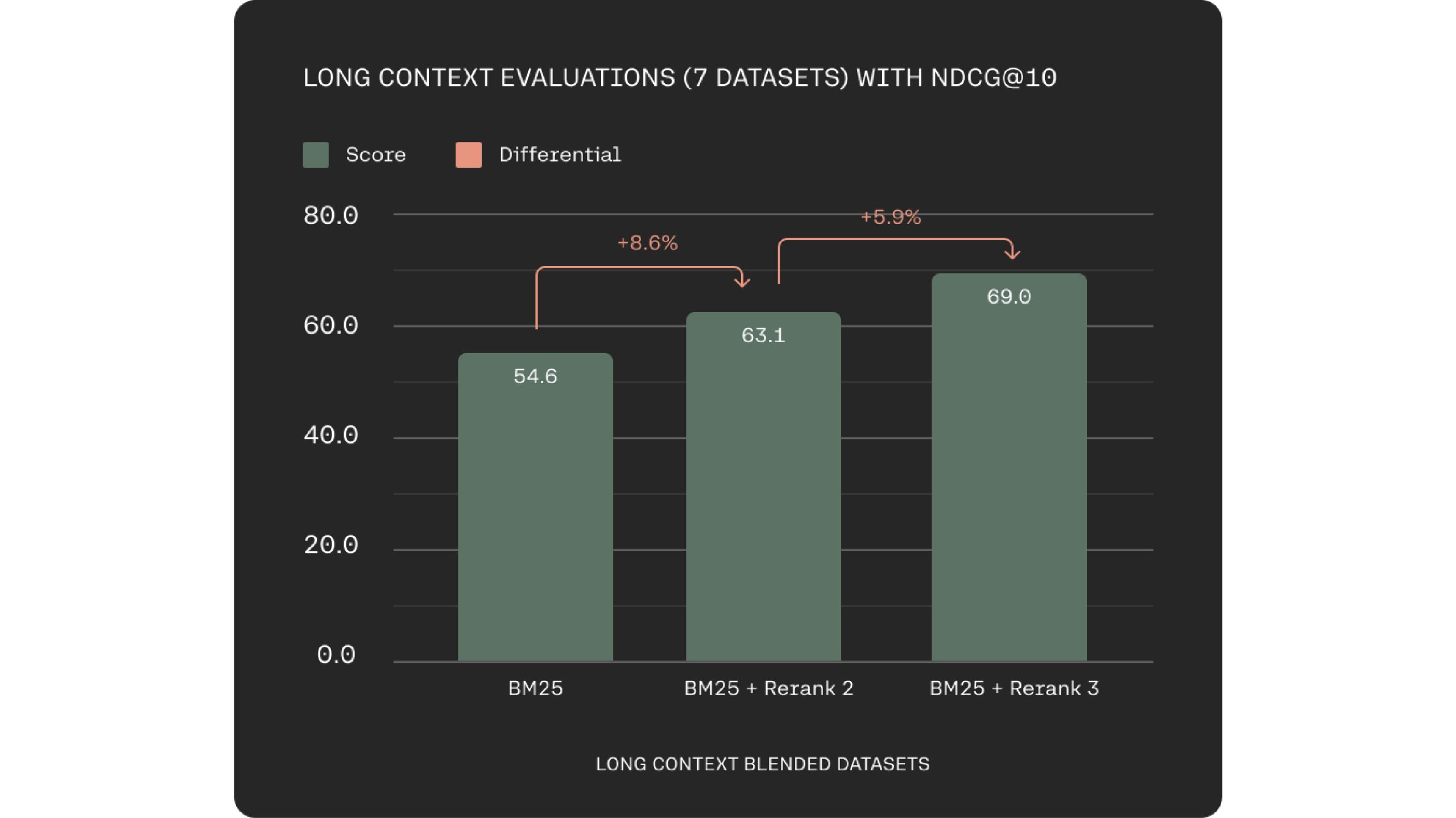
Rerank 3 ได้รับการสนับสนุนใน Inference API ของ Elastic ด้วย การค้นหาแบบยืดหยุ่นมีเทคโนโลยีการค้นหาที่นำมาใช้อย่างกว้างขวาง และความสามารถในการค้นหาคำสำคัญและเวกเตอร์ในแพลตฟอร์ม Elasticsearch ได้รับการสร้างขึ้นเพื่อจัดการข้อมูลองค์กรขนาดใหญ่และซับซ้อนมากขึ้นอย่างมีประสิทธิภาพ
“เรารู้สึกตื่นเต้นที่ได้เป็นพันธมิตรกับ Cohere เพื่อช่วยให้ธุรกิจต่างๆ ปลดล็อกศักยภาพของข้อมูลของพวกเขา” Matt Riley, GVP และ GM ของ Elasticsearch กล่าว โมเดลการดึงข้อมูลขั้นสูงของ Cohere ซึ่งได้แก่ Embed 3 และ Rerank 3 นำเสนอประสิทธิภาพที่ยอดเยี่ยมกับข้อมูลองค์กรที่ซับซ้อนและขนาดใหญ่ สิ่งเหล่านี้คือเครื่องมือแก้ปัญหาของคุณ ซึ่งกลายเป็นองค์ประกอบสำคัญในระบบการค้นหาระดับองค์กร
ปรับปรุงเวลาแฝงด้วยบริบทที่ยาวขึ้น
ในโดเมนธุรกิจจำนวนมาก เช่น อีคอมเมิร์ซหรือการบริการลูกค้า เวลาแฝงที่ต่ำเป็นสิ่งสำคัญในการมอบประสบการณ์ที่มีคุณภาพ พวกเขาคำนึงถึงสิ่งนี้ในขณะที่สร้าง Rerank 3 ซึ่งแสดงเวลาแฝงที่ต่ำกว่าถึง 2 เท่า เมื่อเทียบกับ Rerank 2 สำหรับความยาวเอกสารที่สั้นกว่า และการปรับปรุงสูงสุด 3 เท่าในบริบทที่ยาว
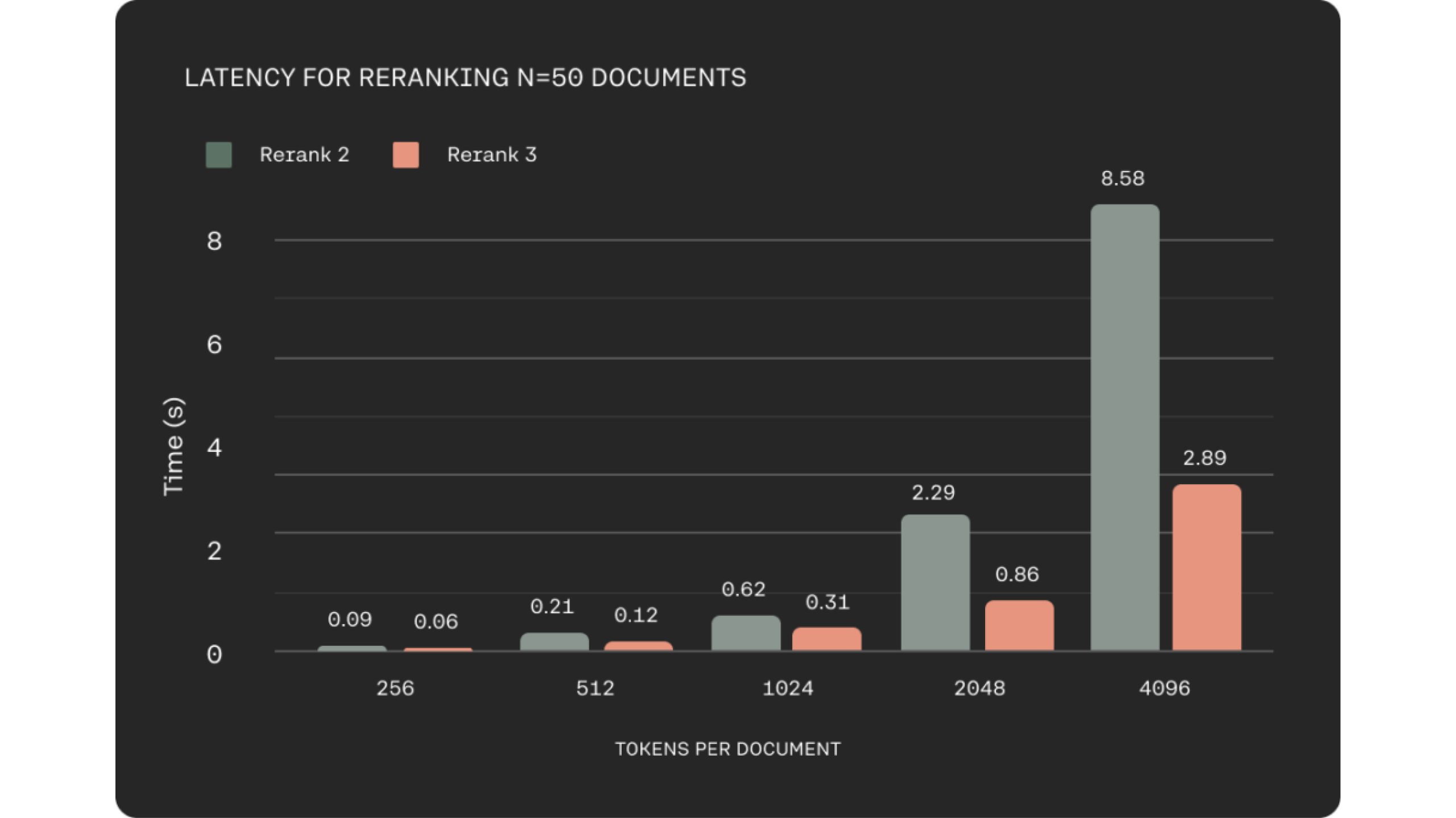
ประสิทธิภาพที่ดีขึ้นและ RAG ที่มีประสิทธิภาพ
ในระบบการดึงข้อมูล-Augmented Generation (RAG) ขั้นตอนการดึงเอกสารมีความสำคัญอย่างยิ่งต่อประสิทธิภาพโดยรวม อันดับ 3 กล่าวถึงปัจจัยสำคัญสองประการสำหรับประสิทธิภาพ RAG ที่ยอดเยี่ยม: คุณภาพการตอบสนองและเวลาแฝง โมเดลนี้ยอดเยี่ยมในการระบุเอกสารที่เกี่ยวข้องมากที่สุดกับข้อความค้นหาของผู้ใช้ผ่านความสามารถในการจัดอันดับทางความหมายใหม่
กระบวนการดึงข้อมูลแบบกำหนดเป้าหมายนี้ช่วยเพิ่มความแม่นยำในการตอบสนองของระบบ RAG ได้โดยตรง ด้วยการเปิดใช้งานการดึงข้อมูลที่เกี่ยวข้องจากชุดข้อมูลขนาดใหญ่ Rerank 3 ช่วยให้องค์กรขนาดใหญ่สามารถปลดล็อกคุณค่าของข้อมูลที่เป็นกรรมสิทธิ์ของตนได้ สิ่งนี้อำนวยความสะดวกให้กับฟังก์ชั่นทางธุรกิจต่างๆ รวมถึงการสนับสนุนลูกค้า กฎหมาย ทรัพยากรบุคคล และการเงิน โดยการให้ข้อมูลที่เกี่ยวข้องมากที่สุดเพื่อตอบคำถามของผู้ใช้
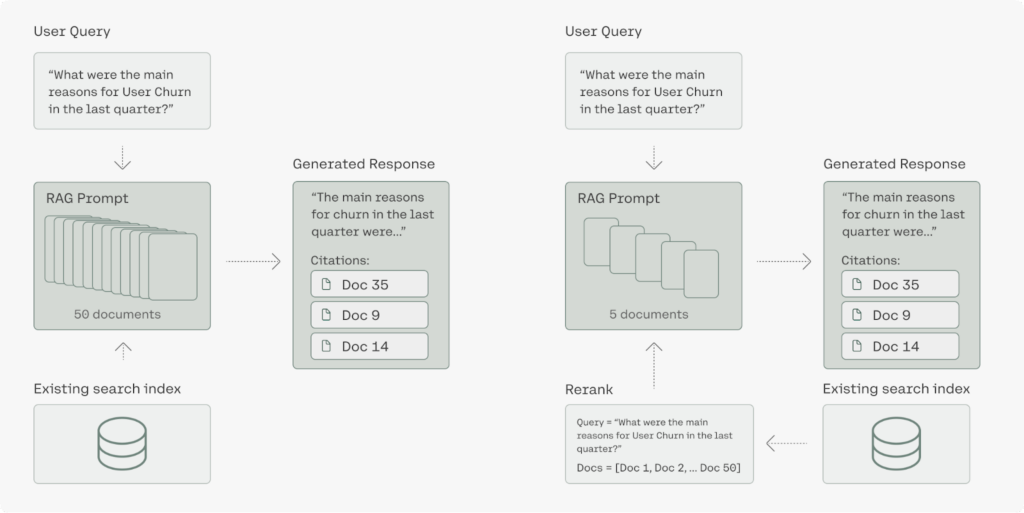
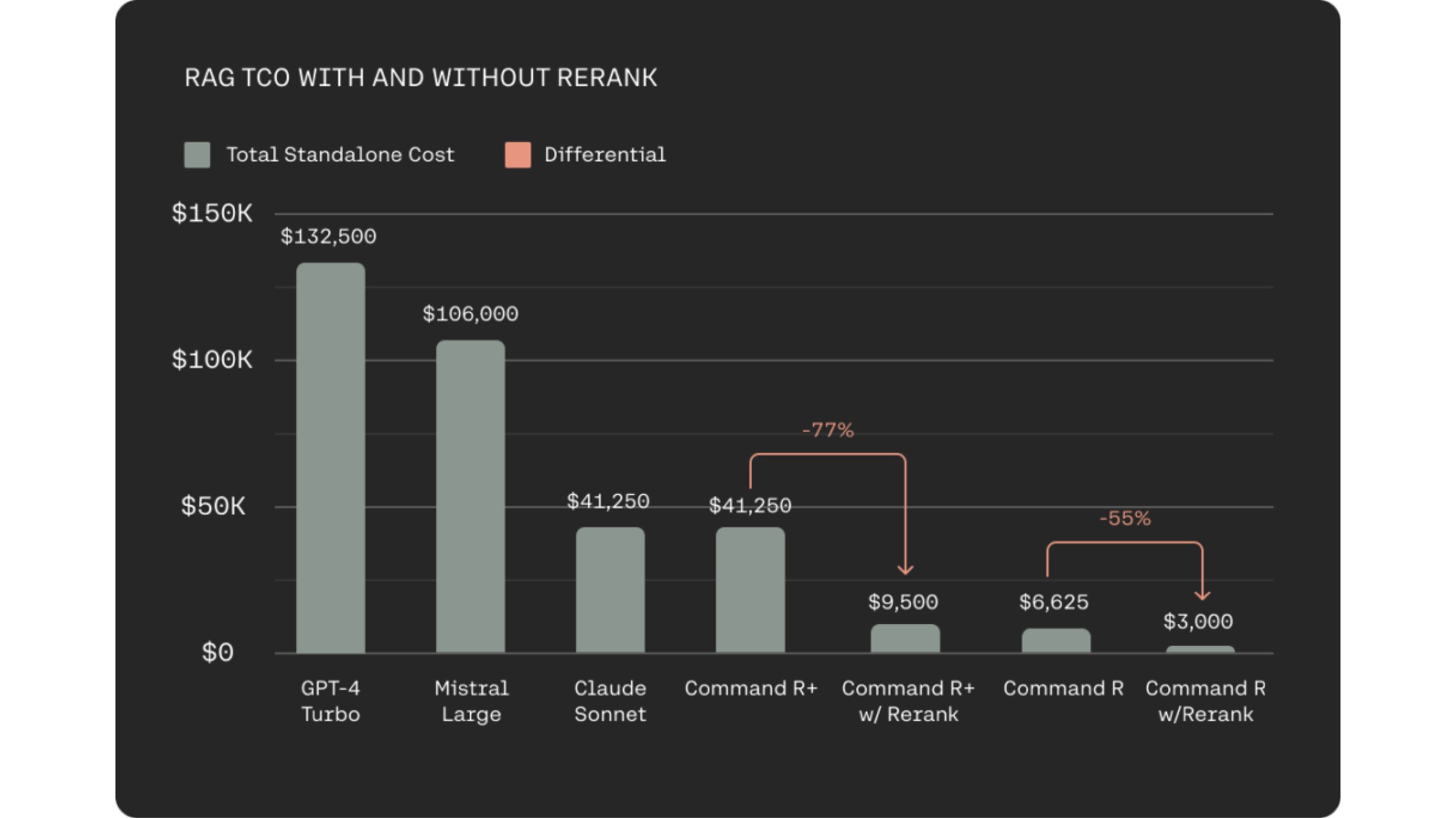
การรวม Rerank 3 เข้ากับกลุ่ม Command R ที่คุ้มค่าสำหรับระบบ RAG จะช่วยลดต้นทุนรวมในการเป็นเจ้าของ (TCO) สำหรับผู้ใช้ได้อย่างมาก สิ่งนี้สำเร็จได้ด้วยปัจจัยสำคัญสองประการ ประการแรก การจัดอันดับใหม่ 3 อำนวยความสะดวกในการเลือกเอกสารที่มีความเกี่ยวข้องสูง โดยกำหนดให้ LLM ประมวลผลเอกสารน้อยลงสำหรับการสร้างการตอบสนองที่มีเหตุผล สิ่งนี้จะรักษาความแม่นยำในการตอบสนองในขณะที่ลดเวลาแฝงให้เหลือน้อยที่สุด ประการที่สอง ประสิทธิภาพที่รวมกันของรุ่น Rerank 3 และ Command R นำไปสู่การลดต้นทุนได้ถึง 80-93% เมื่อเทียบกับ LLM ที่สร้างทางเลือกในตลาด ในความเป็นจริง เมื่อพิจารณาการประหยัดต้นทุนจากทั้งอันดับ 3 และ Command R การลดต้นทุนทั้งหมดอาจเกิน 98%
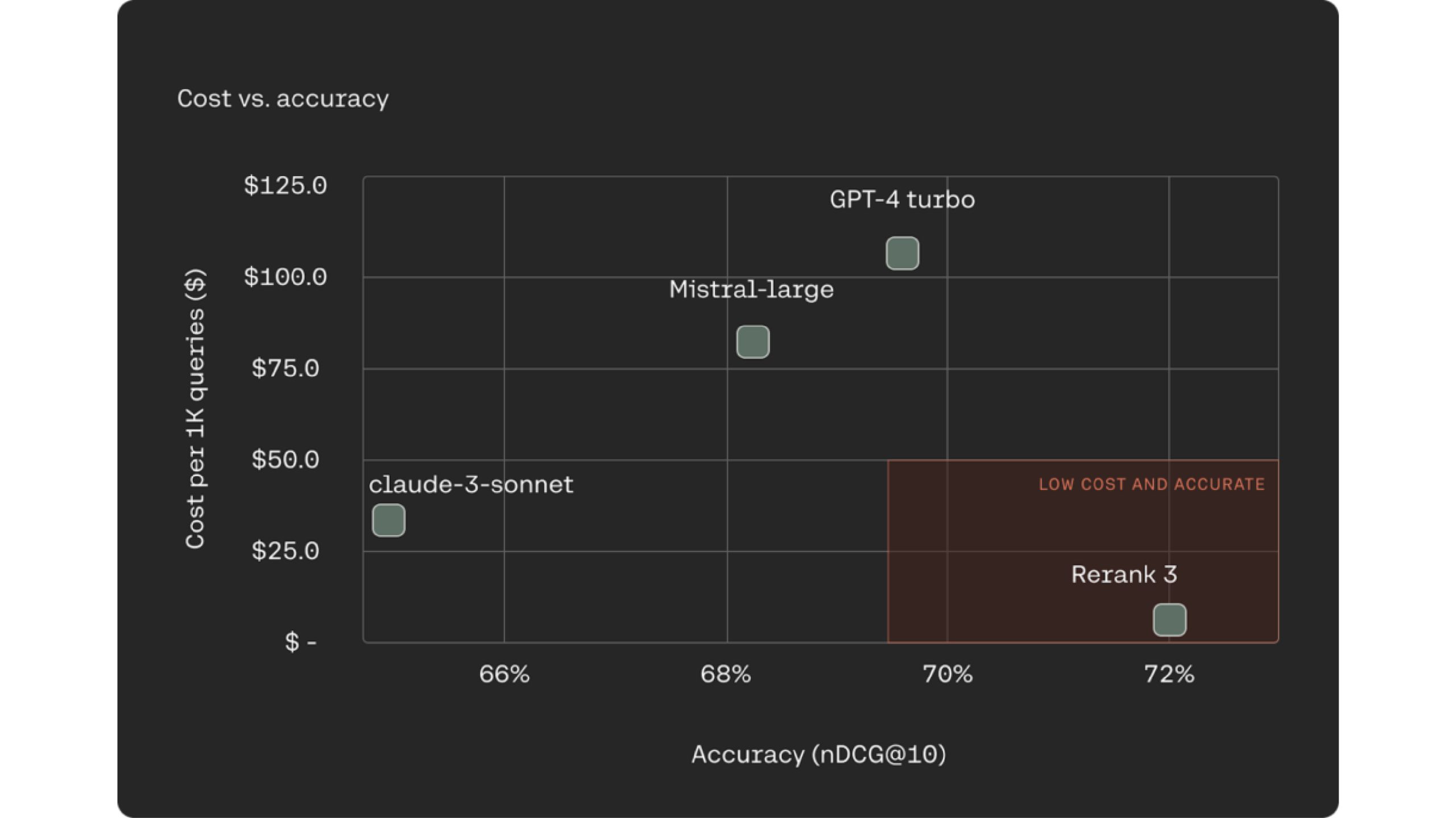
แนวทางหนึ่งที่ใช้กันทั่วไปและเป็นที่รู้จักมากขึ้นสำหรับระบบ RAG คือการใช้ LLM เป็นตัวจัดอันดับใหม่สำหรับกระบวนการดึงเอกสาร อันดับ 3 มีประสิทธิภาพเหนือกว่า LLM ชั้นนำของอุตสาหกรรม เช่น Claude -3 Sonte, GPT Turbo ในเรื่องความแม่นยำของการจัดอันดับ ในขณะที่ราคาถูกลง 90-98%
อันดับ 3 ช่วยเพิ่มความแม่นยำและคุณภาพของการตอบสนอง LLM นอกจากนี้ยังช่วยลด TCO จากต้นทางถึงปลายทางอีกด้วย จัดอันดับใหม่เพื่อให้บรรลุเป้าหมายนี้ด้วยการกำจัดเอกสารที่เกี่ยวข้องน้อยกว่าของเรา และคัดแยกเฉพาะส่วนย่อยเล็กๆ ของเอกสารที่เกี่ยวข้องเพื่อดึงคำตอบ
สรุป
Rerank 3 เป็นเครื่องมือปฏิวัติสำหรับการค้นหาระดับองค์กรและระบบ RAG ช่วยให้มีความแม่นยำสูงในการจัดการโครงสร้างข้อมูลที่ซับซ้อนและหลายภาษา อันดับ 3 ช่วยลดก้อนข้อมูล ลดเวลาแฝงและต้นทุนรวมในการเป็นเจ้าของ ส่งผลให้ผลการค้นหาเร็วขึ้นและการใช้งาน RAG ที่คุ้มต้นทุน มันทำงานร่วมกับ Elasticsearch เพื่อการตัดสินใจและประสบการณ์ของลูกค้าที่ดีขึ้น
คุณสามารถสำรวจเครื่องมือ AI และแอปพลิเคชันอื่นๆ อีกมากมายได้ โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม.
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.analyticsvidhya.com/blog/2024/04/rerank-3-boosting-enterprise-search-and-rag-systems/

