Amazon EMR på EKS tillhandahåller ett distributionsalternativ för Amazon EMR som tillåter organisationer att köra stordataramverk med öppen källkod på Amazon Elastic Kubernetes Service (Amazon EKS). Med EMR på EKS körs Spark-applikationer på Amazon EMR runtime för Apache Spark. Denna prestandaoptimerade körtid som erbjuds av Amazon EMR gör att dina Spark-jobb körs snabbt och kostnadseffektivt. EMR-körtiden ger upp till 5.37 gånger bättre prestanda och 76.8 % kostnadsbesparingar, jämfört med att använda Apache Spark med öppen källkod på Amazon EKS.
Byggande på framgången med Amazon EMR på EKS, har kunder drivit och hanterat jobb med hjälp av emr-behållare API, skapande EMR virtuella kluster, och skicka jobb till EKS-klustret, antingen via AWS Command Line Interface (AWS CLI) eller Apache luftflöde schemaläggare. Andra kunder som kör Spark-applikationer har dock valt Spark Operator eller infödd gnista-submit att definiera och köra Apache Spark-jobb på Amazon EKS, men utan att dra fördel av prestandavinsterna från att köra Spark på den optimerade EMR-körtiden. Som svar på detta behov, från och med EMR 6.10, har vi introducerat en ny funktion som låter dig använda den optimerade EMR-körtiden medan du skickar och hanterar Spark-jobb genom antingen Spark Operator eller spark-submit. Detta innebär att alla som kör Spark-arbetsbelastningar på EKS kan dra nytta av EMR:s optimerade körtid.
I det här inlägget går vi igenom processen att ställa in och köra Spark-jobb med både Spark Operator och spark-submit, integrerad med EMR runtime-funktionen. Vi tillhandahåller steg-för-steg-instruktioner för att hjälpa dig att sätta upp infrastrukturen och skicka in ett jobb med båda metoderna. Dessutom kan du använda Data om EKS-ritning att distribuera hela infrastrukturen med Terraform-mallar.
Infrastrukturöversikt
I det här inlägget går vi igenom processen med att implementera en omfattande lösning med hjälp av eksctl, Helm och AWS CLI. Vår implementering inkluderar följande resurser:
- En VPC, EKS-kluster och en hanterad nodgrupp, inrättad med
eksctlverktyg - Viktiga Amazon EKS-hanterade tillägg, såsom VPC CNI, CoreDNS och KubeProxy som konfigurerats med
eksctlverktyg - Cluster Autoscaler och Spark Operator-tillägg, konfigurerade med hjälp av Helm
- Ett Spark-jobbutförande AWS identitets- och åtkomsthantering (IAM) roll, IAM-policy för Amazon enkel lagringstjänst (Amazon S3) hinkåtkomst, servicekonto och rollbaserad åtkomstkontroll, konfigurerad med AWS CLI och
eksctl
Förutsättningar
Kontrollera att följande förutsättningar är installerade på din maskin:
Ställ in AWS-uppgifter
Innan du går vidare till nästa steg och kör kommandot eksctl måste du konfigurera din lokala AWS-referensprofil. För instruktioner, se Inställningar för konfiguration och autentiseringsfil.
Distribuera VPC, EKS-klustret och hanterade tillägg
Följande konfiguration använder us-west-1 som standardregion. Om du vill köra i en annan region uppdaterar du region och availabilityZones fält i enlighet därmed. Kontrollera också att samma region används i de efterföljande stegen under hela inlägget.
Ange följande kodavsnitt i terminalen där dina AWS-uppgifter är inställda. Se till att uppdatera publicAccessCIDRs fält med din IP innan du kör kommandot nedan. Detta kommer att skapa en fil med namnet eks-cluster.yaml:
Använd följande kommando för att skapa EKS-klustret: eksctl create cluster -f eks-cluster.yaml
Distribuera Cluster Autoscaler
Cluster Autoscaler är avgörande för att automatiskt justera storleken på ditt Kubernetes-kluster baserat på aktuella resursbehov, för att optimera resursutnyttjande och kostnad. Skapa en autoscaler-helm-values.yaml fil och installera Cluster Autoscaler med hjälp av Helm:
Du kan också ställa in Snickare som en kluster autoscaler för att automatiskt starta rätt beräkningsresurser för att hantera ditt EKS-klusters applikationer. Du kan följa detta blogg om hur man ställer in och konfigurerar Karpenter.
Distribuera Spark Operator
Spark Operator är en Kubernetes-operatör med öppen källkod speciellt utformad för att hantera och övervaka Spark-applikationer som körs på Kubernetes. Det effektiviserar processen för att distribuera och hantera Spark-jobb, genom att tillhandahålla en anpassad Kubernetes-resurs för att definiera, konfigurera och köra Spark-applikationer, samt hantera jobblivscykeln genom Kubernetes API. Vissa kunder föredrar att använda Spark Operator för att hantera Spark-jobb eftersom det gör det möjligt för dem att hantera Spark-applikationer precis som andra Kubernetes-resurser.
För närvarande bygger kunderna sina Spark-bilder med öppen källkod och använder dem S3a committers som en del av jobbinlämningar hos Spark Operator eller spark-submit. Men med det nya alternativet för inlämning av jobb kan du nu dra nytta av EMR-körtiden i samband med EMRFS. Från och med Amazon EMR 6.10 och för varje kommande version av EMR-runtime kommer vi att släppa Spark Operator och dess Helm-diagram för att använda EMR-runtime.
I det här avsnittet visar vi dig hur du distribuerar ett Spark Operator Helm-diagram från ett Amazon Elastic Container Registry (Amazon ECR) arkiv och skicka in jobb med hjälp av EMR-runtime-bilder, dra nytta av prestandaförbättringarna som tillhandahålls av EMR-runtime.
Installera Spark Operator med Helm från Amazon ECR
Spark Operator Helm-diagrammet lagras i ett ECR-förråd. För att installera Spark Operator måste du först autentisera din Helm-klient med ECR-förvaret. Diagrammen lagras under följande sökväg: ECR_URI/spark-operator.
Autentisera din Helm-klient och installera Spark Operator:
Du kan autentisera till andra EMR på EKS-stödda regioner genom att skaffa AWS-konto-ID för motsvarande region. För mer information, se hur man väljer en basbilds-URI.
Installera Spark Operator
Du kan nu installera Spark Operator med följande kommando:
För att verifiera att operatören har installerats korrekt, kör följande kommando:
Konfigurera Spark-jobbexekveringsrollen och servicekontot
I det här steget skapar vi en Spark-jobbexekverings-IAM-roll och ett servicekonto, som kommer att användas i Spark Operator och spark-submit exempel på arbetsinlämning.
Först skapar vi en IAM-policy som kommer att användas av IAM-roller för tjänstekonton (IRSA). Denna policy gör det möjligt för drivrutinen och executor-podarna att komma åt de AWS-tjänster som anges i policyn. Slutför följande steg:
- Som en förutsättning, skapa antingen en S3-hink (
aws s3api create-bucket --bucket <ENTER-S3-BUCKET> --create-bucket-configuration LocationConstraint=us-west-1 --region us-west-1) eller använd en befintlig S3-skopa. Byta ut i följande kod med hinkens namn. - Skapa en policyfil som tillåter läs- och skrivåtkomst till en S3-bucket:
- Skapa IAM-policyn med följande kommando:
- Skapa sedan tjänstekontot med namnet
emr-job-execution-sa-rolesamt IAM-rollerna. Det följandeeksctlkommandot skapar ett tjänstekonto avgränsat till namnutrymmet och tjänstekontot som definierats för att användas av executorn och drivrutinen. Se till att byta ut med ditt konto-ID innan du kör kommandot: - Skapa en S3-bucket-policy för att endast tillåta exekveringsrollen skapad i steg 4 att skriva och läsa från S3-bucket skapa i steg 1. Se till att ersätta med ditt konto-ID innan du kör kommandot:
- Skapa en Kubernetes-roll- och rollbindning som krävs för tjänstekontot som används i Spark-jobbkörningen:
- Tillämpa Kubernetes roll- och rollbindningsdefinition med följande kommando:
Hittills har vi slutfört installationen av infrastrukturen, inklusive rollerna för Spark-jobbet. I följande steg kör vi exempel på Spark-jobb med både Spark Operator och spark-submit med EMR-körtiden.
Konfigurera Spark Operator-jobbet med EMR-körtiden
I det här avsnittet presenterar vi ett exempel på Spark-jobb som läser data från offentliga datauppsättningar lagrade i S3-buckets, bearbetar dem och skriver resultaten till din egen S3-bucket. Se till att du uppdaterar S3-skopan i följande konfiguration genom att byta ut den med URI:n till din egen S3-hink hänvisad till steg 2 av "Konfigurera Spark-jobbexekveringsrollen och servicekontot" avsnitt. Observera också att vi använder data-team-a som ett namnutrymme och emr-job-execution-sa som ett tjänstekonto, som vi skapade i föregående steg. Dessa är nödvändiga för att köra Spark-jobbpodarna i det dedikerade namnutrymmet, och IAM-rollen kopplad till tjänstekontot används för att komma åt S3-bucket för att läsa och skriva data.
Viktigast av allt, lägg märke till image med den EMR-optimerade runtime Docker-bilden, som för närvarande är inställd på emr-6.10.0. Du kan ändra detta till en nyare version när det släpps av Amazon EMR-teamet. När du konfigurerar dina jobb, se till att du inkluderar sparkConf och hadoopConf inställningar enligt definitionen i följande manifest. Dessa konfigurationer gör att du kan dra nytta av EMR-körningsprestanda, AWS-lim Datakatalogintegrering och den EMRFS-optimerade kontakten.
- Skapa filen (
emr-spark-operator-example.yaml) lokalt och uppdatera platsen för S3-skopan så att du kan skicka in jobbet som en del av nästa steg: - Kör följande kommando för att skicka jobbet till EKS-klustret:
Jobbet kan ta 4–5 minuter att slutföra och du kan verifiera att meddelandet lyckades i drivrutinspoddens loggar.
- Verifiera jobbet genom att köra följande kommando:
Aktivera åtkomst till Spark UI
Spark UI är ett viktigt verktyg för dataingenjörer eftersom det låter dig spåra framstegen för uppgifter, se detaljerad jobb- och sceninformation och analysera resursutnyttjande för att identifiera flaskhalsar och optimera din kod. För Spark-jobb som körs på Kubernetes finns Spark-gränssnittet på drivrutinspodden och dess åtkomst är begränsad till Kubernetes interna nätverk. För att komma åt den måste vi vidarebefordra trafiken till podden med kubectl. Följande steg tar dig igenom hur du ställer in den.
Kör följande kommando för att vidarebefordra trafik till förarkapseln:
Du bör se text som liknar följande:
Om du inte angav förarens podnamn när du skickade in SparkApplication, kan du få det med följande kommando:
Öppna en webbläsare och gå in http://localhost:4040 i adressfältet. Du bör kunna ansluta till Spark UI.
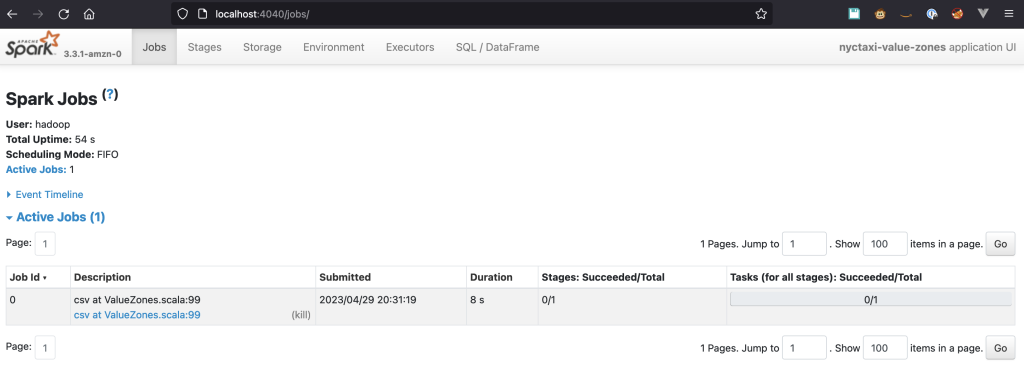
Spark History Server
Om du vill utforska ditt jobb efter körningen kan du se det via Spark History Server. Det föregående SparkApplication definition har händelseloggen aktiverad och lagrar händelserna i en S3-bucket med följande sökväg: s3://YOUR-S3-BUCKET/. För instruktioner om hur du ställer in Spark History Server och utforskar loggarna, se Starta Spark-historikservern och visa Spark-gränssnittet med Docker.
gnista-submit
gnista-submit är ett kommandoradsgränssnitt för att köra Apache Spark-applikationer i ett kluster eller lokalt. Det låter dig skicka in ansökningar till Spark-kluster. Verktyget möjliggör enkel konfiguration av applikationsegenskaper, resursallokering och anpassade bibliotek, vilket effektiviserar distributionen och hanteringen av Spark-jobb.
Från och med Amazon EMR 6.10, spark-submit stöds som en arbetsinlämningsmetod. Denna metod stöder för närvarande bara klusterläge som inlämningsmekanism. För att skicka in jobb med hjälp av spark-submit metoden återanvänder vi IAM-rollen för tjänstekontot som vi skapade tidigare. Vi använder även S3-skopan som används för Spark Operator-metoden. Stegen i det här avsnittet tar dig igenom hur du konfigurerar och skickar jobb med spark-submit och dra nytta av EMR-körningsförbättringar.
- För att skicka in ett jobb måste du använda Spark-versionen som matchar den som finns tillgänglig i Amazon EMR. För Amazon EMR 6.10 måste du ladda ner Spark 3.3-versionen.
- Du måste också se till att du har java installerad i din miljö.
- Packa upp filen och navigera till roten av Spark-katalogen.
- I följande kod, byt ut EKS-ändpunkt samt S3 hink kör sedan skriptet:
Jobbet tar cirka 7 minuter att slutföra med två exekutorer av en kärna och 1 G minne.
Använder anpassade kubernetes-schemaläggare
Kunder som kör en stor volym jobb samtidigt kan möta utmaningar relaterade till att tillhandahålla rättvis tillgång till beräkningskapacitet som de inte kan lösa med den standardiserade schemaläggningen och hanteringen av resursutnyttjande som Kubernetes erbjuder. Dessutom kommer kunder som migrerar från Amazon EMR på Amazon Elastic Compute Cloud (Amazon EC2) och hanterar sin schemaläggning med YARN-köer inte att kunna överföra dem till Kubernetes schemaläggningsfunktioner.
För att övervinna detta problem kan du använda anpassade schemaläggare som Apache Yunikorn or Volcano.Spark Operator stöder inbyggt dessa schemaläggare, och med dem kan du schemalägga Spark-applikationer baserat på faktorer som prioritet, resurskrav och rättvisa policyer, medan Spark Operator förenklar applikationsdistribution och hantering. För att ställa in Yunikorn med gängschemaläggning och använda det i Spark-ansökningar som skickas in via Spark Operator, se Spark Operator med YuniKorn.
Städa upp
För att undvika oönskade debiteringar på ditt AWS-konto, radera alla AWS-resurser som skapats under den här implementeringen:
Slutsats
I det här inlägget introducerade vi EMR runtime-funktionen för Spark Operator och spark-submit, och utforskade fördelarna med att använda den här funktionen på ett EKS-kluster. Med den optimerade EMR-körtiden kan du avsevärt förbättra prestandan för dina Spark-applikationer samtidigt som du optimerar kostnaderna. Vi demonstrerade distributionen av klustret med hjälp av eksctl verktyg, , du kan också använda Data om EKS-ritningar för att distribuera en produktionsklar EKS som du kan använda för EMR på EKS och utnyttja dessa nya distributionsmetoder utöver EMR på EKS API-jobbinlämningsmetoden. Genom att köra dina applikationer på den optimerade EMR-körtiden kan du ytterligare förbättra dina Spark-applikationsarbetsflöden och driva innovation i dina databearbetningspipelines.
Om författarna
 Lotfi Mouhib är en Senior Solutions Architect som arbetar för den offentliga sektorns team med Amazon Web Services. Han hjälper offentliga kunder i hela EMEA att förverkliga sina idéer, bygga nya tjänster och förnya för medborgarna. På fritiden tycker Lotfi om att cykla och springa.
Lotfi Mouhib är en Senior Solutions Architect som arbetar för den offentliga sektorns team med Amazon Web Services. Han hjälper offentliga kunder i hela EMEA att förverkliga sina idéer, bygga nya tjänster och förnya för medborgarna. På fritiden tycker Lotfi om att cykla och springa.
 Vara Bonthu är en dedikerad teknikprofessionell och världsomspännande teknisk ledare för data om EKS, specialiserad på att hjälpa AWS-kunder allt från strategiska konton till olika organisationer. Han brinner för öppen källkodsteknologi, dataanalys, AI/ML och Kubernetes, och har en omfattande bakgrund inom utveckling, DevOps och arkitektur. Varas primära fokus ligger på att bygga mycket skalbara data- och AI/ML-lösningar på Kubernetes-plattformar, vilket hjälper kunder att utnyttja den fulla potentialen hos spjutspetsteknologi för sina datadrivna sysselsättningar.
Vara Bonthu är en dedikerad teknikprofessionell och världsomspännande teknisk ledare för data om EKS, specialiserad på att hjälpa AWS-kunder allt från strategiska konton till olika organisationer. Han brinner för öppen källkodsteknologi, dataanalys, AI/ML och Kubernetes, och har en omfattande bakgrund inom utveckling, DevOps och arkitektur. Varas primära fokus ligger på att bygga mycket skalbara data- och AI/ML-lösningar på Kubernetes-plattformar, vilket hjälper kunder att utnyttja den fulla potentialen hos spjutspetsteknologi för sina datadrivna sysselsättningar.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/introducing-amazon-emr-on-eks-job-submission-with-spark-operator-and-spark-submit/

