Beskrivning
På bara sex månader har OpenAIs ChatGPT blivit en integrerad del av våra liv. Det är inte längre bara begränsat till teknik; människor i alla åldrar och yrken, från studenter till författare, använder det i stor utsträckning. Dessa chattmodeller utmärker sig i noggrannhet, hastighet och mänskliga konversationer. De är redo att spela en betydande roll inom olika områden, inte bara inom teknik.
Verktyg med öppen källkod som AutoGPTs, BabyAGI och Langchain har dykt upp och utnyttjar kraften i språkmodeller. Automatisera programmeringsuppgifter med uppmaningar, anslut språkmodeller till datakällor och skapa AI-applikationer snabbare än någonsin tidigare. Langchain är ett ChatGPT-aktiverat Q&A-verktyg för PDF-filer, vilket gör det till en one-stop-shop för att bygga AI-applikationer.
Inlärningsmål
- Bygg ett chatbot-gränssnitt med Gradio
- Extrahera texter från pdf-filer och skapa inbäddningar
- Lagra inbäddningar i Chroma vektordatabasen
- Skicka förfrågan till backend (Langchain-kedjan)
- Utför semantisk sökning i texter för att hitta relevanta datakällor
- Skicka data till LLM (ChatGPT) och få svar på chatboten
Langkedjan gör det enkelt att utföra alla dessa steg i några rader kod. Den har omslag för flera tjänster, inklusive inbäddningsmodeller, chattmodeller och vektordatabaser.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Vad är Langchain?
Langchain är ett verktyg med öppen källkod skrivet i Python som hjälper till att koppla extern data till stora språkmodeller. Det gör chattmodellerna som GPT-4 eller GPT-3.5 mer agentiska och datamedvetna. Så på sätt och vis erbjuder Langchain ett sätt att mata LLM:er med ny data som den inte har tränats på. Langchain tillhandahåller många kedjor som abstraherar bort komplexitet i interaktion med språkmodeller. Vi behöver också flera andra verktyg, som modeller för att skapa vektorinbäddningar och vektordatabaser för att lagra vektorer. Innan vi går vidare, låt oss ta en snabb titt på textinbäddningar. Vad är dessa och varför är det viktigt?
Textinbäddningar
Textinbäddningar är hjärtat och själen i Large Language Operations. Tekniskt sett kan vi arbeta med språkmodeller med naturligt språk men att lagra och hämta naturligt språk är mycket ineffektivt. Till exempel, i det här projektet kommer vi att behöva utföra höghastighetssökningar över stora databitar. Det är omöjligt att utföra sådana operationer på naturliga språkdata.
För att göra det mer effektivt måste vi omvandla textdata till vektorformer. Det finns dedikerade ML-modeller för att skapa inbäddningar från texter. Texterna omvandlas till flerdimensionella vektorer. När vi väl är inbäddade kan vi gruppera, sortera, söka och mer över dessa data. Vi kan beräkna avståndet mellan två meningar för att veta hur nära de är relaterade. Och det bästa med det är att dessa operationer inte bara är begränsade till nyckelord som traditionella databassökningar utan snarare fångar den semantiska närheten av två meningar. Detta gör den mycket kraftfullare, tack vare Machine Learning.
Verktyg för långkedja
Langchain har omslag för alla större vektordatabaser som Chroma, Redis, Pinecone, Alpine db och mer. Och detsamma gäller för LLMs, tillsammans med OpeanAI-modeller, stöder den också Coheres modeller, GPT4ALL - ett alternativ med öppen källkod för GPT-modeller. För inbäddningar tillhandahåller den omslag för Inbäddningar av OpeanAI, Cohere och HuggingFace. Du kan också använda dina anpassade inbäddningsmodeller också.
Så kort sagt, Langchain är ett metaverktyg som abstraherar bort många komplikationer av interaktion med underliggande teknologier, vilket gör det lättare för vem som helst att snabbt bygga AI-applikationer.
I den här artikeln kommer vi att använda OpenAI-inbäddningar modell för att skapa inbäddningar. Om du vill distribuera en AI-app för slutanvändare, överväg att använda alla Opensource-modeller, som Huggingface-modeller eller Googles Universal-satskodare.
För att lagra vektorer kommer vi att använda Chroma DB, en vektorbutiksdatabas med öppen källkod. Utforska gärna andra databaser som Alpine, Pinecone och Redis. Langchain har omslag för alla dessa vektorbutiker.
För att skapa en Langchain-kedja kommer vi att använda ConversationalRetrievalChain(), perfekt för konversation med chattmodeller med historik (för att behålla konversationens kontext). Kolla in deras officiell dokumentation angående olika LLM-kedjor.
Ställ in Dev Environment
Det finns en hel del bibliotek vi kommer att använda. Så installera dem i förväg. För att skapa en sömlös, rörig utvecklingsmiljö, använd virtuella miljöer or Hamnarbetare.
gradio = "^3.27.0"
openai = "^0.27.4"
langchain = "^0.0.148"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
pypdf = "^3.8.1"
pymupdf = "^1.22.2"Importera nu dessa bibliotek
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import ImageBygg chattgränssnitt
Applikationens gränssnitt kommer att ha två huvudfunktioner, den ena är ett chattgränssnitt och den andra återger den relevanta sidan i PDF-filen som en bild. Bortsett från detta, en textruta för att acceptera OpenAI API-nycklar från slutanvändare. Jag rekommenderar starkt att gå igenom artikeln för bygga en GPT-chatbot med Gradio från början. Artikeln diskuterar de grundläggande aspekterna av Gradio. Vi kommer att låna många saker från den här artikeln.
Klassen Gradio Blocks låter oss bygga en webbapp. Klasserna Row och Columns gör det möjligt att justera flera komponenter i webbappen. Vi kommer att använda dem för att anpassa webbgränssnittet.
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()
Gränssnittet är enkelt med några få komponenter.
Det har:
- Ett chattgränssnitt för att kommunicera med PDF:en.
- En komponent för att rendera relevanta PDF-sidor.
- En textruta för att acceptera API-nyckeln och en knapp för att ändra nyckel.
- En textruta för att ställa frågor och en skicka-knapp.
- En knapp för att ladda upp filer.
Här är en ögonblicksbild av webbgränssnittet.
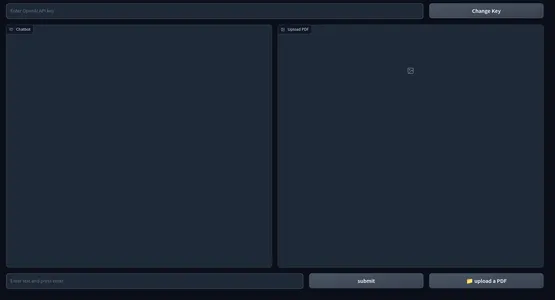
Frontend-delen av vår ansökan är komplett. Låt oss hoppa vidare till backend.
backend
Låt oss först beskriva de processer vi kommer att hantera.
- Hantera uppladdad PDF och OpenAI API-nyckel
- Extrahera texter från PDF och skapa textinbäddningar av den med OpenAI-inbäddningar.
- Lagra vektorinbäddningar i ChromaDB-vektorarkivet.
- Skapa en kedja för samtalshämtning med Langchain.
- Skapa inbäddningar av efterfrågad text och utför en likhetssökning över inbäddade dokument.
- Skicka relevanta dokument till OpenAI-chattmodellen (gpt-3.5-turbo).
- Hämta svaret och streama det på chattgränssnittet.
- Återge relevant PDF-sida på webbgränssnittet.
Dessa är översikten över vår applikation. Låt oss börja bygga det.
Gradio-evenemang
När en specifik åtgärd på webbgränssnittet utförs utlöses dessa händelser. Så, händelserna gör webbappen interaktiv och dynamisk. Gradio låter oss definiera händelser med Python-koder.
Gradio Events använder komponentvariabler som vi definierade tidigare för att kommunicera med backend. Vi kommer att definiera några händelser som vi behöver för vår ansökan. Dessa är
- Skicka API-nyckelhändelse: Om du trycker på enter efter att ha klistrat in API-nyckeln utlöses denna händelse.
- Ändra nyckel: Detta gör att du kan tillhandahålla en ny API-nyckel
- Ange frågor: Skicka textfrågor till chatboten
- Ladda upp fil: Detta gör att slutanvändaren kan ladda upp en PDF-fil
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )Hittills har vi inte definierat våra funktioner som kallas inuti ovanstående händelsehanterare. Därefter kommer vi att definiera alla dessa funktioner för att göra en funktionell webbapp.
Hantera API-nycklar
Att hantera en användares API-nycklar är viktigt eftersom det hela körs på BYOK-principen (Bring Your Own Key). Närhelst en användare skickar in en nyckel måste textrutan bli oföränderlig med en prompt som föreslår att nyckeln är inställd. Och när "Change Key"-händelsen utlöses måste boxen kunna ta emot ingångar.
För att göra detta, definiera två globala variabler.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)Definiera funktioner
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box def enable_api_box(): return enable_boxFunktionen set_apikey tar en stränginmatning och returnerar variabeln disable_box, vilket gör textrutan oföränderlig efter exekvering. I avsnittet Gradio Events definierade vi api_key Submit Event, som anropar set_apikey-funktionen. Vi ställer in API-nyckeln som en miljövariabel med hjälp av OS-biblioteket.
Om du klickar på knappen Ändra API-nyckel returneras variabeln enable_box, vilket gör att textrutan kan ändras igen.
Skapa kedja
Detta är det viktigaste steget. Detta steg innebär att extrahera texter och skapa inbäddningar och lagra dem i vektorbutiker. Tack vare Langchain, som tillhandahåller omslag för flera tjänster som gör saker enklare. Så låt oss definiera funktionen.
def process_file(file): # raise an error if API key is not provided if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') # Load the PDF file using PyPDFLoader loader = PyPDFLoader(file.name) documents = loader.load() # Initialize OpenAIEmbeddings for text embeddings embeddings = OpenAIEmbeddings() # Create a ConversationalRetrievalChain with ChatOpenAI language model # and PDF search retriever pdfsearch = Chroma.from_documents(documents, embeddings,) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever= pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True,) return chain- Skapade en kontroll om API-nyckeln är inställd eller inte. Detta kommer att uppstå ett fel på fronten om nyckeln inte är inställd.
- Ladda PDF-fil med PyPDFLoader
- Definerad inbäddningsfunktion med OpenAIEmbeddings.
- Skapat en vektorbutik från listan över texter från PDF:en med hjälp av inbäddningsfunktionen.
- Definierat en kedja med chatOpenAI (som standard använder ChatOpenAI gpt-3.5-turbo), en basretriever (använder en likhetssökning).
Generera svar
När kedjan har skapats ringer vi kedjan och skickar våra frågor. Skicka en chatthistorik tillsammans med frågorna för att behålla kontexten för konversationer och streama svar till chattgränssnittet. Låt oss definiera funktionen.
def generate_response(history, query, btn): global COUNT, N, chat_history # Check if a PDF file is uploaded if not btn: raise gr.Error(message='Upload a PDF') # Initialize the conversation chain only once if COUNT == 0: chain = process_file(btn) COUNT += 1 # Generate a response using the conversation chain result = chain({"question": query, 'chat_history':chat_history}, return_only_outputs=True) # Update the chat history with the query and its corresponding answer chat_history += [(query, result["answer"])] # Retrieve the page number from the source document N = list(result['source_documents'][0])[1][1]['page'] # Append each character of the answer to the last message in the history for char in result['answer']: history[-1][-1] += char # Yield the updated history and an empty string yield history, ''
- Ger ett felmeddelande om det inte finns någon PDF uppladdad.
- Anropar process_file-funktionen endast en gång.
- Skickar frågor och chatthistorik till kedjan
- Hämtar sidnumret för det mest relevanta svaret.
- Ge svar till frontend.
Återge bild av en PDF-fil
Det sista steget är att återge bilden av PDF-filen med det mest relevanta svaret. Vi kan använda PyMuPdf- och PIL-biblioteken för att återge bilderna av dokumentet.
def render_file(file): global N # Open the PDF document using fitz doc = fitz.open(file.name) # Get the specific page to render page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) # Create an Image object from the rendered pixel data image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) # Return the rendered image return image
- Öppna filen med PyMuPdfs Fitz.
- Skaffa den relevanta sidan.
- Skaffa pix karta för sidan.
- Skapa bilden från PIL:s bildklass.
Detta är allt vi behöver göra för en funktionell webbapp för att chatta med vilken PDF-fil som helst.
Att sätta ihop allt
#import csv
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import Image # Global variables
COUNT, N = 0, 0
chat_history = []
chain = ''
enable_box = gr.Textbox.update(value=None, placeholder='Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value='OpenAI API key is Set', interactive=False) # Function to set the OpenAI API key
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box # Function to enable the API key input box
def enable_api_box(): return enable_box # Function to add text to the chat history
def add_text(history, text): if not text: raise gr.Error('Enter text') history = history + [(text, '')] return history # Function to process the PDF file and create a conversation chain
def process_file(file): if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') loader = PyPDFLoader(file.name) documents = loader.load() embeddings = OpenAIEmbeddings() pdfsearch = Chroma.from_documents(documents, embeddings) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever=pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True) return chain # Function to generate a response based on the chat history and query
def generate_response(history, query, btn): global COUNT, N, chat_history, chain if not btn: raise gr.Error(message='Upload a PDF') if COUNT == 0: chain = process_file(btn) COUNT += 1 result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) chat_history += [(query, result["answer"])] N = list(result['source_documents'][0])[1][1]['page'] for char in result['answer']: history[-1][-1] += char yield history, '' # Function to render a specific page of a PDF file as an image
def render_file(file): global N doc = fitz.open(file.name) page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) return image # Gradio application setup
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )
demo.queue()
if __name__ == "__main__": demo.launch()Nu när vi har konfigurerat allt, låt oss starta vår applikation.
Du kan starta programmet i felsökningsläge med följande kommando
gradio app.py
Annars kan du också helt enkelt köra programmet med kommandot Python. Nedan är en ögonblicksbild av slutprodukten. GitHub-arkivet för koder.
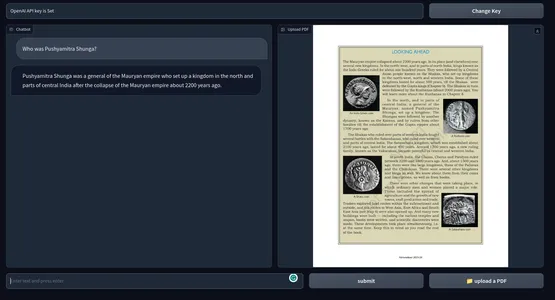
[Inbäddat innehåll]
Möjliga förbättringar
Den nuvarande applikationen fungerar utmärkt. Men det finns några saker du kan göra för att göra det bättre.
- Detta använder OpenAI-inbäddningar som kan vara dyra i det långa loppet. För en produktionsklar app kan alla offline-inbäddningsmodeller vara mer lämpliga.
- Gradio för prototyper är bra, men för den verkliga världen skulle en app med ett modernt javascript-ramverk som Next Js eller Svelte vara mycket bättre när det gäller prestanda och estetik.
- Vi använde cosinuslikhet för att hitta relevanta texter. Under vissa förhållanden kan en KNN-strategi vara bättre.
- För PDF-filer med tätt textinnehåll kan det vara bättre att skapa mindre bitar av text.
- Bättre modell, desto bättre prestanda. Experimentera med andra LLM och jämför resultaten.
Praktiska användningsfall
Använd verktygen inom flera områden från utbildning till juridik till akademin eller något område du kan föreställa dig som kräver att personen går igenom stora texter. Några av de praktiska användningsfallen för ChatGPT för PDF-filer är
- Läroinstitut: Eleverna kan ladda upp sina läroböcker, studiematerial och uppgifter, och verktyget kan svara på frågor och förklara specifika avsnitt. Detta kan göra den övergripande inlärningsprocessen mindre ansträngande för eleverna.
- Adress: Advokatbyråer måste hantera ett stort antal juridiska dokument i PDF-format. Detta verktyg kan användas för att enkelt extrahera relevant information från ärendedokument, juridiska kontrakt och stadgar. Det kan hjälpa advokater att snabbare hitta klausuler, prejudikat och annan information.
- Akademin: Forskare arbetar ofta med forskningsartiklar och teknisk dokumentation. Ett verktyg som kan sammanfatta litteraturen, analysera och ge svar från dokument kan räcka långt vilket sparar total tid och förbättrar produktiviteten.
- Administration: Govt. kontor och andra administrativa avdelningar hanterar stora mängder formulär, ansökningar och rapporter dagligen. Att använda en chatbot som svarar på dokument kan effektivisera administrationsprocessen, vilket sparar allas tid och pengar.
- Finans : Att analysera finansiella rapporter och gå igenom dem om och om igen är tråkigt. Detta kan göras enklare genom att använda en chatbot. I huvudsak en praktikant.
- Media: Journalister och analytiker kan använda ett chatGPT-aktiverat PDF-verktyg för att svara på frågor för att söka i stora textkorpus för att snabbt hitta svar.
Ett chatGPT-aktiverat PDF Q&A-verktyg kan samla in information snabbare från massor av PDF-text. Det är som en sökmotor för textdata. Inte bara PDF-filer, utan vi kan också utöka det här verktyget till allt med textdata med lite kodmanipulation.
Slutsats
Så det här handlade om att bygga en chatbot för att konversera med vilken PDF-fil som helst med ChatGPT. Tack vare Langchain har det blivit mycket lättare att bygga AI-applikationer. Några av de viktigaste tipsen från artikeln är:
- Gradio är ett verktyg med öppen källkod för prototyper av AI-applikationer. Vi skapade applikationens frontend med Gradio.
- Langchain är ett annat verktyg med öppen källkod som låter oss bygga AI-applikationer. Den har omslag för populära LLM:er och vektordatalager, vilket gör att vi enkelt kan interagera med underliggande tjänster.
- Vi använde Langchain för att bygga backend-systemen för vår applikation.
- OpenAI-modeller var överlag avgörande för vår app. Vi använde OpenAI-inbäddningar och GPT 3.5-motorn för att chatta med PDF-filer.
- Ett ChatGPT-aktiverat Q&A-verktyg för PDF-filer och annan textdata kan räcka långt för att effektivisera kunskapsuppgifter.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/05/build-a-chatgpt-for-pdfs-with-langchain/

