Beskrivning
Inom maskininlärning är avvägningen mellan bias-varians ett grundläggande koncept som påverkar prestandan för alla prediktiva modeller. Det hänvisar till den känsliga balansen mellan förspänningsfel och variansfel i en modell, eftersom det är omöjligt att samtidigt minimera båda. Att hitta rätt balans är avgörande för att uppnå optimal modellprestanda.
I den här korta artikeln kommer vi att definiera bias och varians, förklara hur de påverkar en maskininlärningsmodell och ge några praktiska råd om hur man hanterar dem i praktiken.
Förstå bias och varians
Innan vi dyker in i förhållandet mellan bias och varians, låt oss definiera vad dessa termer representerar i maskininlärning.
Bias error hänvisar till skillnaden mellan förutsägelsen av en modell och de korrekta värden den försöker förutsäga (grundsanning). Med andra ord är bias det fel som en modell begår på grund av sina felaktiga antaganden om den underliggande datafördelningen. Modeller med hög bias är ofta för förenklade och lyckas inte fånga datas komplexitet, vilket leder till underanpassning.
Variansfel å andra sidan syftar på modellens känslighet för små fluktuationer i träningsdata. Modeller med hög varians är alltför komplexa och tenderar att passa bruset i data snarare än det underliggande mönstret, vilket leder till överanpassning. Detta resulterar i dålig prestanda på ny, osynlig data.
Hög bias kan leda till underanpassning, där modellen är för enkel för att fånga datas komplexitet. Den gör starka antaganden om data och misslyckas med att fånga det verkliga förhållandet mellan ingångs- och utdatavariabler. Å andra sidan kan hög varians leda till överanpassning, där modellen är för komplex och lär sig bruset i data snarare än det underliggande sambandet mellan in- och utvariabler. Således tenderar överanpassade modeller att passa träningsdata för nära och kommer inte att generalisera bra till nya data, medan underanpassade modeller inte ens kan anpassa träningsdata exakt.
Som nämnts tidigare är bias och varians relaterade, och en bra modell balanserar mellan bias-fel och variansfel. Avvägningen mellan bias-varians är processen att hitta den optimala balansen mellan dessa två felkällor. En modell med låg bias och låg varians kommer sannolikt att prestera bra på både träning och nya data, vilket minimerar det totala felet.
Avvägningen mellan bias och varians
Att uppnå en balans mellan modellens komplexitet och dess förmåga att generalisera till okända data är kärnan i avvägningen mellan bias-varians. I allmänhet kommer en mer komplex modell att ha en lägre bias men högre varians, medan en enklare modell kommer att ha en högre bias men lägre varians.
Eftersom det är omöjligt att samtidigt minimera bias och varians, är det avgörande att hitta den optimala balansen mellan dem för att bygga en robust maskininlärningsmodell. Till exempel, när vi ökar komplexiteten i en modell ökar vi också variansen. Detta beror på att en mer komplex modell är mer sannolikt att passa ljudet i träningsdata, vilket kommer att leda till överanpassning.
Å andra sidan, om vi håller modellen för enkel kommer vi att öka biasen. Detta beror på att en enklare modell inte kommer att kunna fånga de underliggande sambanden i datan, vilket kommer att leda till underanpassning.
Målet är att träna en modell som är tillräckligt komplex för att fånga de underliggande sambanden i träningsdatan, men inte så komplex att den passar bruset i träningsdatan.
Bias-Varians Trade-Off i praktiken
För att diagnostisera modellens prestanda beräknar och jämför vi vanligtvis tåg- och valideringsfel. Ett användbart verktyg för att visualisera detta är en plottning av inlärningskurvorna, som visar modellens prestanda på både tåget och valideringsdata under hela träningsprocessen. Genom att undersöka dessa kurvor kan vi avgöra om en modell är överanpassad (hög varians), underanpassning (hög bias) eller välanpassad (optimal balans mellan bias och varians).
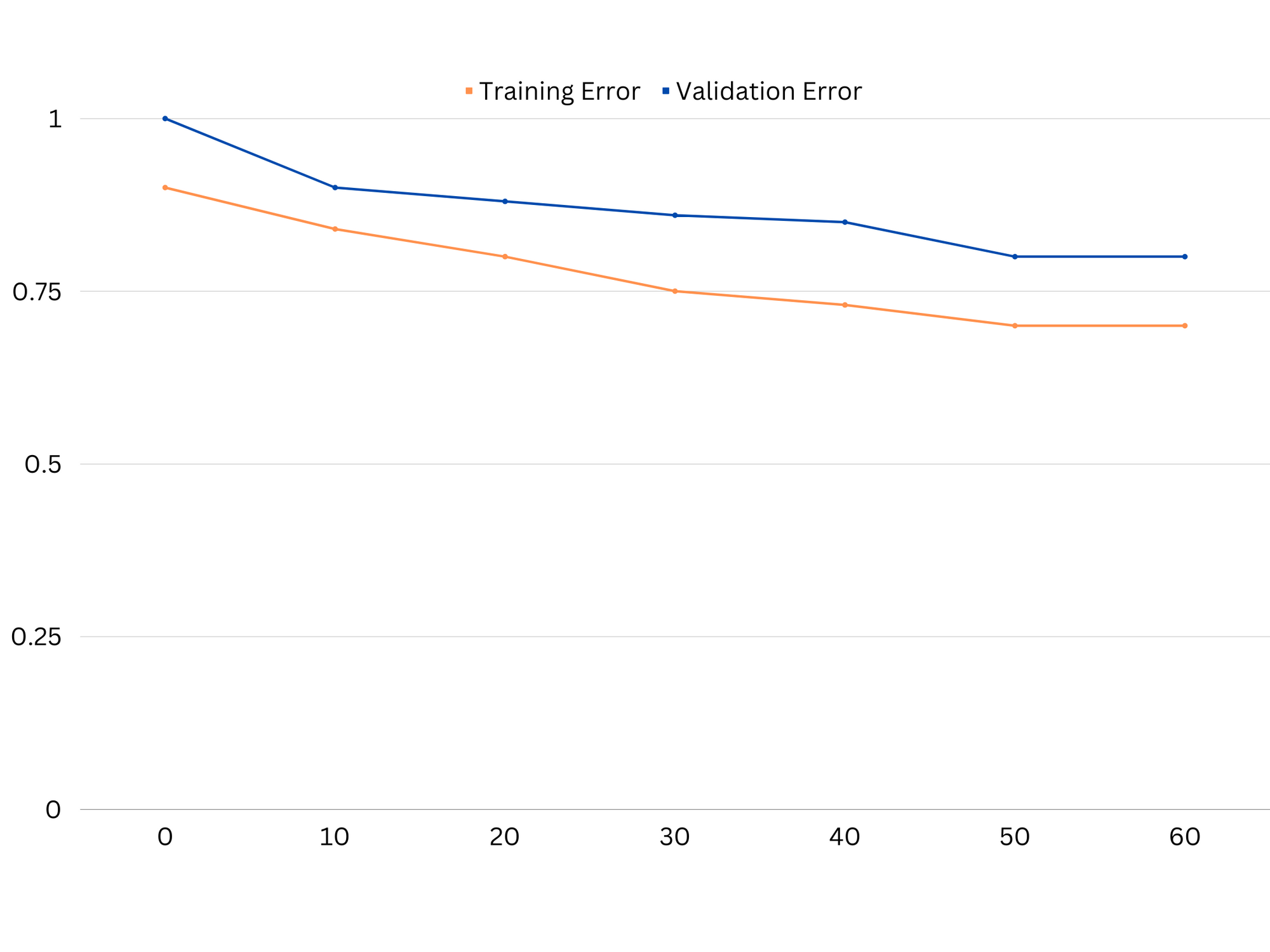
Exempel på inlärningskurvor för en undermonterad modell. Både tågfel och valideringsfel är höga.
I praktiken tyder låg prestation på både tränings- och valideringsdata på att modellen är för enkel, vilket leder till underanpassning. Å andra sidan, om modellen presterar mycket bra på träningsdata men dåligt på testdata, är modellens komplexitet sannolikt för hög, vilket resulterar i överanpassning. För att komma till rätta med underanpassning kan vi försöka öka modellens komplexitet genom att lägga till fler funktioner, ändra inlärningsalgoritmen eller välja olika hyperparametrar. I fallet med överanpassning bör vi överväga att reglera modellen eller använda tekniker som korsvalidering för att förbättra dess generaliseringsförmåga.
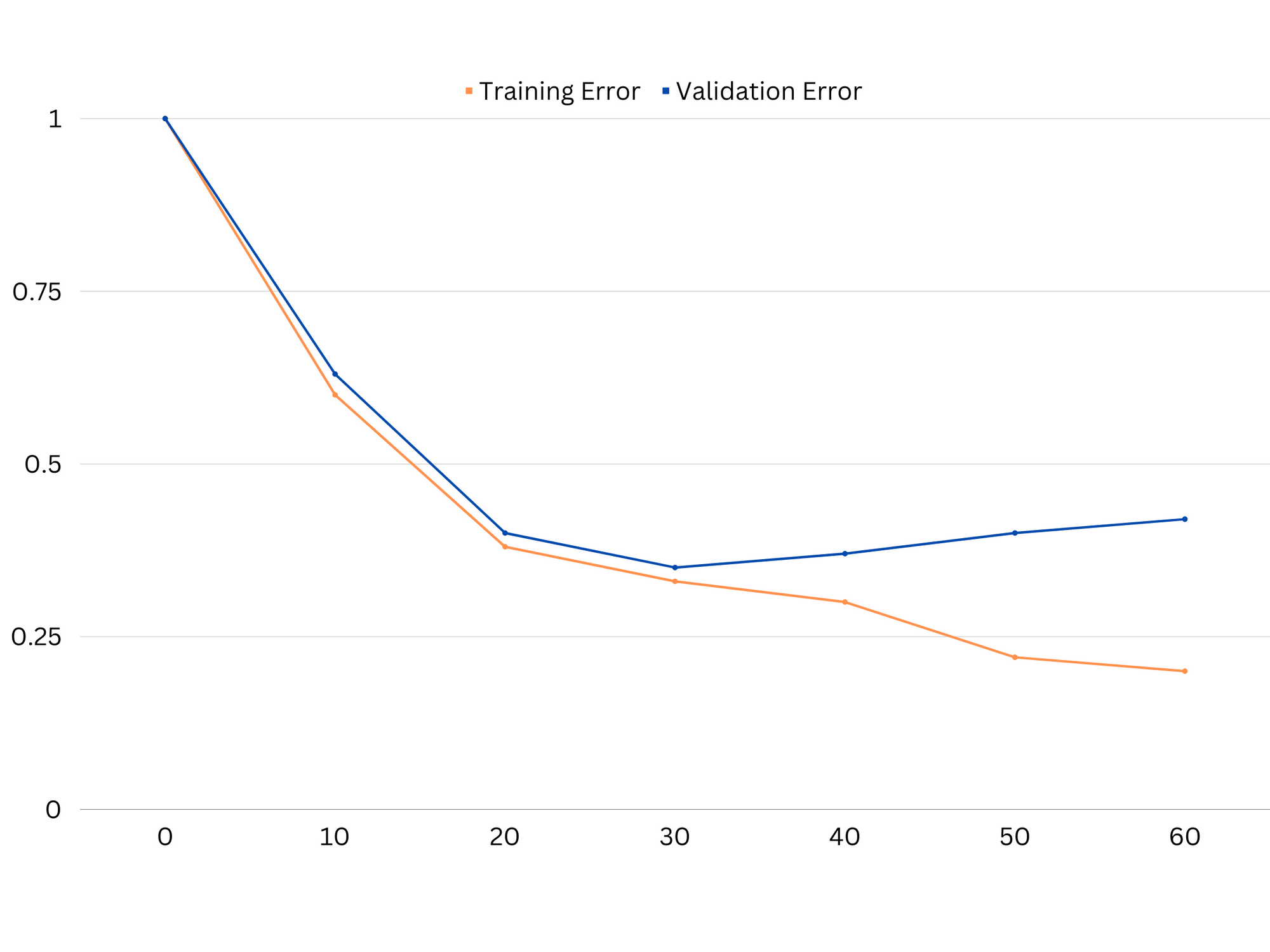
Exempel på inlärningskurvor av en överanpassad modell. Tågfelet minskar medan valideringsfelet börjar öka. Modellen kan inte generalisera.
Regularisering är en teknik som kan användas för att minska variansfelet i maskininlärningsmodeller, vilket hjälper till att ta itu med bias-varians-avvägningen. Det finns ett antal olika regleringstekniker, var och en med sina egna fördelar och nackdelar. Några populära regulariseringstekniker inkluderar åsregression, lassoregression och elastisk nettoreglering. Alla dessa tekniker hjälper till att förhindra överanpassning genom att lägga till en straffterm till modellens objektiva funktion, vilket motverkar extrema parametervärden och uppmuntrar till enklare modeller.
Ridge regression, även känd som L2-regularisering, lägger till en straffterm som är proportionell mot kvadraten på modellparametrarna. Denna teknik tenderar att resultera i modeller med mindre parametervärden, vilket kan leda till minskad varians och förbättrad generalisering. Den utför dock inte funktionsval, så alla funktioner finns kvar i modellen.
Kolla in vår praktiska, praktiska guide för att lära dig Git, med bästa praxis, branschaccepterade standarder och medföljande fuskblad. Sluta googla Git-kommandon och faktiskt lära Det!
Lasso-regression, eller L1-regularisering, lägger till en straffterm som är proportionell mot det absoluta värdet av modellparametrarna. Denna teknik kan leda till modeller med glesa parametervärden, som effektivt utför funktionsval genom att ställa in vissa parametrar till noll. Detta kan resultera i enklare modeller som är lättare att tolka.
Elastisk nettoreglering är en kombination av både L1- och L2-regularisering, vilket möjliggör en balans mellan ås- och lasso-regression. Genom att kontrollera förhållandet mellan de två straffvillkoren kan elastiskt nät uppnå fördelarna med båda teknikerna, såsom förbättrad generalisering och val av egenskaper.
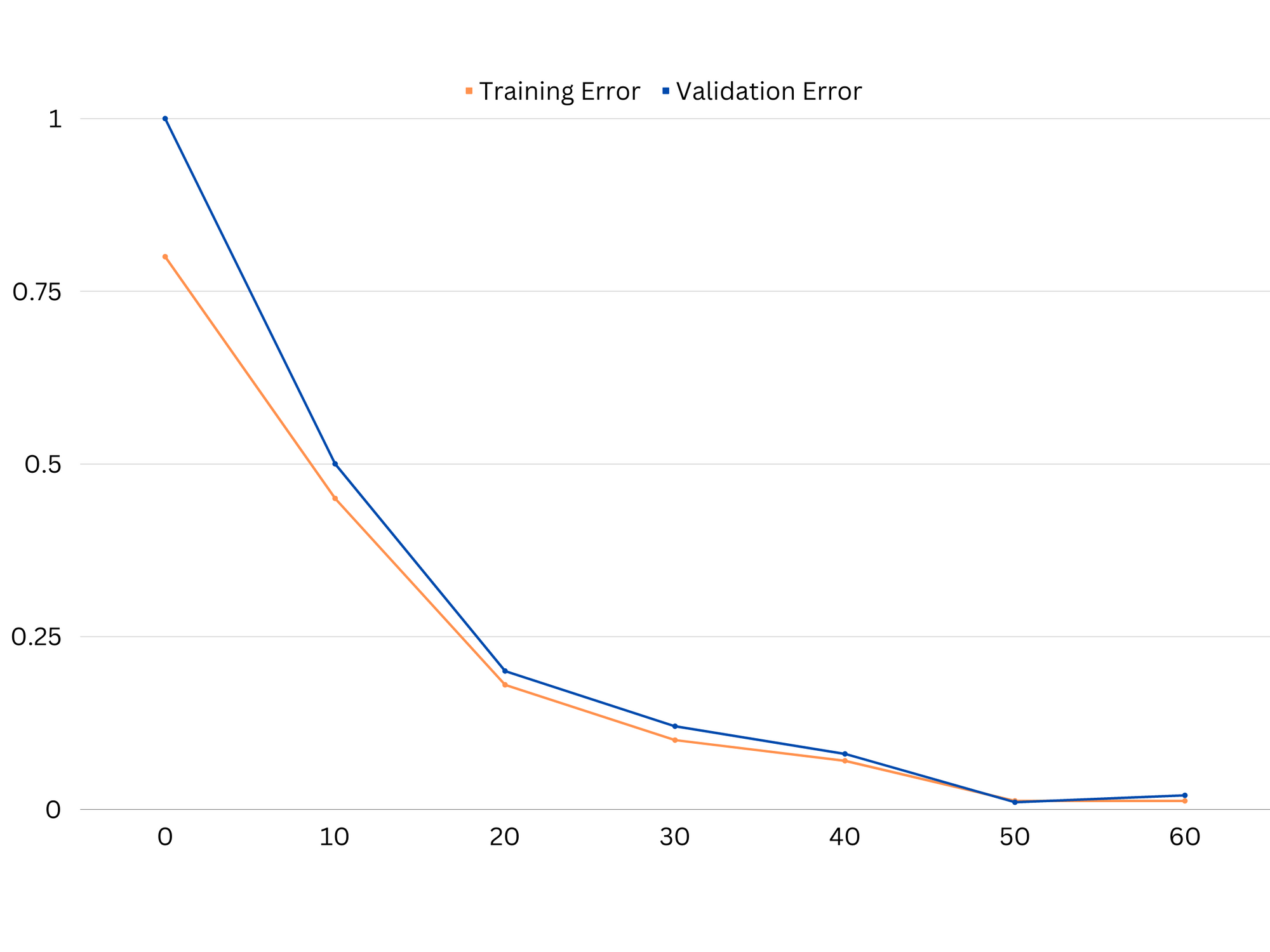
Exempel på inlärningskurvor av bra passande modell.
Slutsatser
Avvägningen mellan bias-varians är ett avgörande koncept inom maskininlärning som avgör effektiviteten och godheten hos en modell. Medan hög bias leder till underanpassning och hög varians leder till överanpassning, är det nödvändigt att hitta den optimala balansen mellan de två för att bygga robusta modeller som generaliserar väl till nya data.
Med hjälp av inlärningskurvor är det möjligt att identifiera över- eller underanpassningsproblem, och genom att trimma modellens komplexitet eller implementera regulariseringstekniker är det möjligt att förbättra prestandan på både tränings- och valideringsdata, samt testdata.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://stackabuse.com/the-bias-variance-trade-off-in-machine-learning/

