To objavo v spletnem dnevniku je napisala skupaj s Caroline Chung iz podjetja Veoneer.
Veoneer je globalno podjetje za avtomobilsko elektroniko in vodilno podjetje v svetu na področju avtomobilskih elektronskih varnostnih sistemov. Ponujajo najboljše sisteme za nadzor zadrževanja v razredu in so proizvajalcem avtomobilov po vsem svetu dobavili več kot 1 milijardo elektronskih krmilnih enot in senzorjev za trke. Podjetje še naprej gradi na 70-letni zgodovini razvoja avtomobilske varnosti, specializirano za vrhunsko strojno opremo in sisteme, ki preprečujejo prometne incidente in blažijo nesreče.
Avtomobilsko zaznavanje v kabini (ICS) je nastajajoč prostor, ki uporablja kombinacijo več vrst senzorjev, kot so kamere in radar, ter algoritmov, ki temeljijo na umetni inteligenci (AI) in strojnem učenju (ML), za povečanje varnosti in izboljšanje izkušnje pri vožnji. Izgradnja takega sistema je lahko zapletena naloga. Razvijalci morajo ročno označiti velike količine slik za namene usposabljanja in testiranja. To je zelo zamudno in zahteva veliko virov. Obdobje za takšno nalogo je več tednov. Poleg tega se morajo podjetja ukvarjati s težavami, kot so nedosledne oznake zaradi človeških napak.
AWS je osredotočen na to, da vam pomaga povečati hitrost razvoja in znižati stroške za gradnjo takih sistemov z napredno analitiko, kot je ML. Naša vizija je uporaba ML za avtomatizirano označevanje, omogočanje ponovnega usposabljanja varnostnih modelov ter zagotavljanje doslednih in zanesljivih meritev uspešnosti. V tej objavi delimo, kako v sodelovanju z Amazonovo svetovno specializirano organizacijo in Generative AI Innovation Center, smo razvili cevovod aktivnega učenja za omejevalne okvirje glave slik v kabini in opombe ključnih točk. Rešitev zmanjša stroške za več kot 90 %, pospeši postopek označevanja iz tednov v ure v smislu časa izvedbe in omogoča ponovno uporabo za podobna opravila označevanja podatkov ML.
Pregled rešitev
Aktivno učenje je pristop ML, ki vključuje ponavljajoč se postopek izbiranja in označevanja najbolj informativnih podatkov za usposabljanje modela. Glede na majhen nabor označenih podatkov in velik nabor neoznačenih podatkov aktivno učenje izboljša zmogljivost modela, zmanjša napor pri označevanju in integrira človeško strokovno znanje za zanesljive rezultate. V tej objavi gradimo cevovod aktivnega učenja za opombe slik s storitvami AWS.
Naslednji diagram prikazuje splošni okvir za naš nabor aktivnega učenja. Cevovod za označevanje zajema slike iz Preprosta storitev shranjevanja Amazon (Amazon S3) vedro in izpiše označene slike s sodelovanjem modelov ML in človeškega strokovnega znanja. Učni cevovod vnaprej obdela podatke in jih uporabi za usposabljanje modelov ML. Začetni model je nastavljen in učen na majhnem nizu ročno označenih podatkov in bo uporabljen v cevovodu za označevanje. Cevovod za označevanje in cevovod za usposabljanje je mogoče postopoma ponoviti z več označenimi podatki, da izboljšate zmogljivost modela.
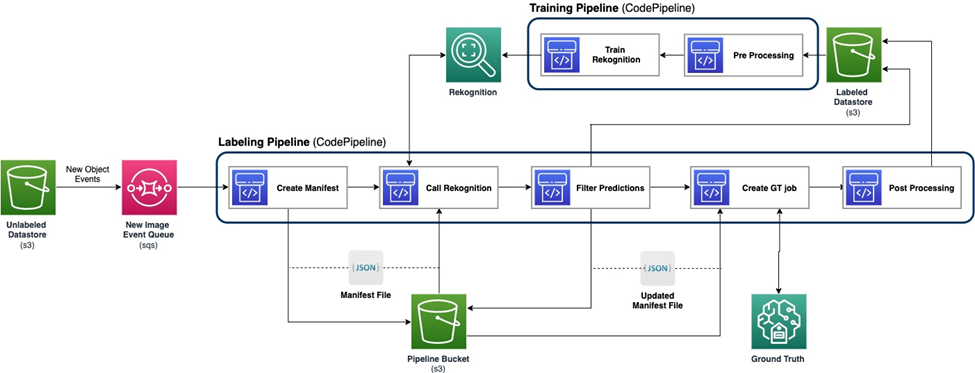
V procesu označevanja je an Obvestilo o dogodku Amazon S3 se prikliče, ko pride nov paket slik v vedro Unlabeled Datastore S3 in aktivira cevovod za označevanje. Model ustvari rezultate sklepanja na novih slikah. Prilagojena funkcija presoje izbere dele podatkov na podlagi ocene zaupanja sklepanja ali drugih funkcij, ki jih določi uporabnik. Ti podatki se skupaj z rezultati sklepanja pošljejo v opravilo človeškega označevanja Amazon SageMaker Ground Truth ki ga je ustvaril plinovod. Človeški postopek označevanja pomaga pri označevanju podatkov, spremenjeni rezultati pa so združeni s preostalimi samodejno označenimi podatki, ki jih lahko kasneje uporabi cevovod za usposabljanje.
Ponovno usposabljanje modela se zgodi v procesu usposabljanja, kjer uporabimo nabor podatkov, ki vsebuje podatke, označene s človekom, za ponovno usposabljanje modela. Izdela se datoteka manifesta, ki opisuje, kje so datoteke shranjene, isti začetni model pa se ponovno usposobi za nove podatke. Po ponovnem usposabljanju novi model nadomesti začetni model in začne se naslednja ponovitev aktivnega učenja.
Uvajanje modela
Razporejeni sta tako cevovod za označevanje kot cevovod za usposabljanje AWS CodePipeline. AWS CodeBuild za implementacijo se uporabljajo instance, ki so prilagodljive in hitre za majhno količino podatkov. Ko je potrebna hitrost, uporabimo Amazon SageMaker končne točke, ki temeljijo na primerku GPU, da dodelijo več sredstev za podporo in pospešitev procesa.
Cevovod za ponovno usposabljanje modela je mogoče priklicati, ko je na voljo nov nabor podatkov ali ko je treba izboljšati zmogljivost modela. Ena kritična naloga v procesu preusposabljanja je imeti sistem za nadzor različic tako za podatke o usposabljanju kot za model. Čeprav storitve AWS, kot npr Amazonsko ponovno vžiganje imajo integrirano funkcijo nadzora različic, zaradi česar je cevovod preprost za implementacijo, prilagojeni modeli zahtevajo beleženje metapodatkov ali dodatna orodja za nadzor različic.
Celoten potek dela je izveden z uporabo Komplet za razvoj oblaka AWS (AWS CDK) za ustvarjanje potrebnih komponent AWS, vključno z naslednjim:
- Dve vlogi za opravila CodePipeline in SageMaker
- Dve opravili CodePipeline, ki usklajujeta potek dela
- Dve vedri S3 za artefakte kode cevovodov
- Eno vedro S3 za označevanje manifesta opravila, nizov podatkov in modelov
- Predobdelava in naknadna obdelava AWS Lambda funkcije za opravila označevanja SageMaker Ground Truth
Skladi AWS CDK so visoko modularizirani in jih je mogoče ponovno uporabiti pri različnih nalogah. Učenje, kodo sklepanja in predlogo SageMaker Ground Truth je mogoče zamenjati za vse podobne scenarije aktivnega učenja.
Usposabljanje za modele
Usposabljanje modela vključuje dve nalogi: opombo omejevalnega polja glave in opombo ključnih točk človeka. Oba predstavljamo v tem razdelku.
Opomba o omejevalnem polju glave
Anotacija omejevalnega polja glave je naloga za predvidevanje lokacije omejevalnega polja človeške glave na sliki. Uporabljamo an Oznake po meri za ponovno odstranjevanje Amazon model za opombe o omejevalnem polju glave. Naslednji vzorec zvezka ponuja vadnico po korakih o tem, kako usposobiti model Rekognition Custom Labels prek SageMakerja.
Najprej moramo pripraviti podatke za začetek usposabljanja. Ustvarimo datoteko manifesta za usposabljanje in datoteko manifesta za testni nabor podatkov. Datoteka manifesta vsebuje več elementov, od katerih je vsak za sliko. Sledi primer datoteke manifesta, ki vključuje podatke o poti slike, velikosti in opombah:
Z uporabo datotek manifesta lahko naložimo nize podatkov v model Rekognition Custom Labels za usposabljanje in testiranje. Model smo ponovili z različnimi količinami podatkov o usposabljanju in ga preizkusili na istih 239 nevidenih slikah. V tem testu je mAP_50 ocena se je povečala z 0.33 pri 114 slikah za usposabljanje na 0.95 pri 957 slikah za usposabljanje. Naslednji posnetek zaslona prikazuje meritve zmogljivosti končnega modela Rekognition Custom Labels, ki daje odlično zmogljivost v smislu ocene F1, natančnosti in priklica.

Model smo dodatno preizkusili na zadržanem naboru podatkov, ki ima 1,128 slik. Model dosledno napoveduje natančne napovedi omejevalnega polja na nevidnih podatkih, kar daje visoko mAP_50 94.9 %. Naslednji primer prikazuje samodejno označeno sliko z okvirjem, ki omejuje glavo.

Anotacija ključnih točk
Anotacije ključnih točk ustvarijo lokacije ključnih točk, vključno z očmi, ušesi, nosom, usti, vratom, rameni, komolci, zapestji, boki in gležnji. Poleg predvidevanja lokacije je za predvidevanje v tej specifični nalogi potrebna vidnost vsake točke, za katero oblikujemo novo metodo.
Za opombe ključnih točk uporabljamo a Model Yolo 8 Pose na SageMaker kot začetni model. Najprej pripravimo podatke za usposabljanje, vključno z generiranjem datotek etiket in konfiguracijske datoteke .yaml v skladu z zahtevami podjetja Yolo. Po pripravi podatkov model usposobimo in shranimo artefakte, vključno z datoteko uteži modela. Z datoteko uteži naučenega modela lahko dodamo opombe novim slikam.
V fazi usposabljanja se za usposabljanje uporabljajo vse označene točke z lokacijami, vključno z vidnimi točkami in zakritimi točkami. Zato ta model privzeto zagotavlja lokacijo in zanesljivost napovedi. Na naslednji sliki lahko visok prag zaupanja (glavni prag) blizu 0.6 loči točke, ki so vidne ali zakrite, od točk zunaj zornega kota kamere. Vendar pa zamašene točke in vidne točke niso ločene z zaupanjem, kar pomeni, da predvideno zaupanje ni uporabno za napovedovanje vidljivosti.

Za pridobitev napovedi vidljivosti uvedemo dodaten model, usposobljen na naboru podatkov, ki vsebuje samo vidne točke, izključujoč zakrite točke in točke zunaj zornega kota kamere. Naslednja slika prikazuje porazdelitev točk z različno vidljivostjo. V dodatnem modelu lahko ločimo vidne točke in druge točke. Za pridobitev vidnih točk lahko uporabimo prag (dodatni prag) blizu 0.6. S kombinacijo teh dveh modelov oblikujemo metodo za napovedovanje lokacije in vidljivosti.

Ključno točko najprej napove glavni model z lokacijo in glavnim zaupanjem, nato dobimo dodatno napoved zaupanja iz dodatnega modela. Njegova vidnost je nato razvrščena na naslednji način:
- Vidno, če je njegovo glavno zaupanje večje od njegovega glavnega praga in je njegovo dodatno zaupanje večje od dodatnega praga
- Zaprto, če je njegova glavna zanesljivost večja od glavnega praga in je dodatna zanesljivost manjša ali enaka dodatnemu pragu
- Zunaj pregleda kamere, če drugače
Primer označevanja ključnih točk je prikazan na naslednji sliki, kjer so polne oznake vidne točke, votle oznake pa zamašene točke. Točke zunaj fotoaparata niso prikazane.

Na podlagi standarda OKS definicijo na naboru podatkov MS-COCO lahko naša metoda doseže mAP_50 98.4 % na naboru nevidnih testnih podatkov. Kar zadeva vidnost, metoda zagotavlja 79.2-odstotno natančnost klasifikacije na istem nizu podatkov.
Človeško označevanje in preusposabljanje
Čeprav modeli dosegajo odlično zmogljivost na testnih podatkih, še vedno obstajajo možnosti za napake na novih podatkih iz resničnega sveta. Človeško označevanje je postopek za popravljanje teh napak za izboljšanje učinkovitosti modela s prekvalifikacijo. Zasnovali smo funkcijo presoje, ki je združila vrednost zaupanja, ki izhaja iz modelov ML za izhod vseh omejevalnikov glave ali ključnih točk. Končno oceno uporabljamo za prepoznavanje teh napak in posledičnih slabo označenih slik, ki jih je treba poslati v postopek človeškega označevanja.
Poleg slabo označenih slik je majhen del slik naključno izbran za človeško označevanje. Te slike, označene s človekom, so dodane v trenutno različico nabora za usposabljanje za ponovno usposabljanje, izboljšanje zmogljivosti modela in splošne natančnosti opomb.
Pri izvedbi uporabljamo SageMaker Ground Truth za človeško označevanje postopek. SageMaker Ground Truth ponuja uporabniku prijazen in intuitiven uporabniški vmesnik za označevanje podatkov. Naslednji posnetek zaslona prikazuje opravilo označevanja SageMaker Ground Truth za pripis o omejevalnem polju glave.

Naslednji posnetek zaslona prikazuje opravilo označevanja SageMaker Ground Truth za opombe ključnih točk.

Cena, hitrost in možnost ponovne uporabe
Stroški in hitrost sta ključni prednosti uporabe naše rešitve v primerjavi s človeškim označevanjem, kot je prikazano v naslednjih tabelah. Te tabele uporabljamo za prikaz prihrankov stroškov in pospeškov hitrosti. Z uporabo pospešene instance GPU SageMaker ml.g4dn.xlarge je strošek celotnega življenjskega usposabljanja in sklepanja na 100,000 slikah 99 % nižji od stroškov človeškega označevanja, medtem ko je hitrost 10–10,000-krat večja od človeškega označevanja, odvisno od naloga.
Prva tabela povzema meritve stroškovne uspešnosti.
| Model | mAP_50 na podlagi 1,128 testnih slik | Stroški usposabljanja temeljijo na 100,000 slikah | Stroški sklepanja na podlagi 100,000 slik | Znižanje stroškov v primerjavi s človeškim zapisom | Čas sklepanja na podlagi 100,000 slik | Časovni pospešek v primerjavi s človeškim zapisom |
| Omejevalni okvir glave za prepoznavanje | 0.949 | $4 | $22 | 99% manj | 5.5 h | Dnevi |
| Ključne točke Yolo | 0.984 | $27.20 | * 10 dolarjev | 99.9% manj | min | Weeks |
Naslednja tabela povzema meritve uspešnosti.
| Naloga opomb | mAP_50 (%) | Stroški usposabljanja ($) | Stroški sklepanja ($) | Čas sklepanja |
| Okvir za omejevanje glave | 94.9 | 4 | 22 | 5.5 ur |
| Ključne točke | 98.4 | 27 | 10 | 5 minut |
Poleg tega naša rešitev omogoča ponovno uporabo za podobna opravila. Razvoj zaznavanja kamere za druge sisteme, kot je napredni sistem za pomoč vozniku (ADAS) in sistemi v kabini, lahko prav tako sprejme našo rešitev.
Povzetek
V tej objavi smo pokazali, kako zgraditi cevovod aktivnega učenja za samodejno označevanje slik v kabini z uporabo storitev AWS. Predstavljamo moč ML, ki vam omogoča avtomatizacijo in pospešitev postopka opomb, ter prilagodljivost ogrodja, ki uporablja modele, bodisi podprte s storitvami AWS ali prilagojene na SageMakerju. Z Amazon S3, SageMaker, Lambda in SageMaker Ground Truth lahko poenostavite shranjevanje podatkov, opombe, usposabljanje in uvajanje ter dosežete možnost ponovne uporabe, medtem ko znatno zmanjšate stroške. Z uvedbo te rešitve lahko avtomobilska podjetja postanejo bolj agilna in stroškovno učinkovita z uporabo napredne analitike, ki temelji na ML, kot je avtomatizirano označevanje slik.
Začnite danes in odklenite moč Storitve AWS in strojno učenje za vaše primere uporabe zaznavanja v kabini!
O avtorjih
 Yanxiang Yu je uporabni znanstvenik v Amazon Generative AI Innovation Center. Z več kot 9-letnimi izkušnjami pri gradnji rešitev AI in strojnega učenja za industrijske aplikacije je specializiran za generativno AI, računalniški vid in modeliranje časovnih vrst.
Yanxiang Yu je uporabni znanstvenik v Amazon Generative AI Innovation Center. Z več kot 9-letnimi izkušnjami pri gradnji rešitev AI in strojnega učenja za industrijske aplikacije je specializiran za generativno AI, računalniški vid in modeliranje časovnih vrst.
 Tianyi Mao je uporabni znanstvenik pri AWS iz okolice Chicaga. Ima več kot 5 let izkušenj z gradnjo rešitev za strojno in globoko učenje ter se osredotoča na računalniški vid in okrepljeno učenje s človeškimi povratnimi informacijami. Uživa v delu s strankami, da bi razumel njihove izzive in jih rešil z ustvarjanjem inovativnih rešitev z uporabo storitev AWS.
Tianyi Mao je uporabni znanstvenik pri AWS iz okolice Chicaga. Ima več kot 5 let izkušenj z gradnjo rešitev za strojno in globoko učenje ter se osredotoča na računalniški vid in okrepljeno učenje s človeškimi povratnimi informacijami. Uživa v delu s strankami, da bi razumel njihove izzive in jih rešil z ustvarjanjem inovativnih rešitev z uporabo storitev AWS.
 Yanru Xiao je uporabni znanstvenik v Amazon Generative AI Innovation Center, kjer gradi rešitve AI/ML za resnične poslovne težave strank. Delal je na več področjih, vključno s proizvodnjo, energetiko in kmetijstvom. Yanru je pridobil doktorat znanosti. doktorat iz računalništva na univerzi Old Dominion.
Yanru Xiao je uporabni znanstvenik v Amazon Generative AI Innovation Center, kjer gradi rešitve AI/ML za resnične poslovne težave strank. Delal je na več področjih, vključno s proizvodnjo, energetiko in kmetijstvom. Yanru je pridobil doktorat znanosti. doktorat iz računalništva na univerzi Old Dominion.
 Paul George je uspešen vodja izdelkov z več kot 15-letnimi izkušnjami na področju avtomobilskih tehnologij. Spreten je pri vodenju ekip za produktno upravljanje, strategijo, Go-to-Market in sistemski inženiring. Po vsem svetu je inkubiral in lansiral več novih izdelkov za zaznavanje in zaznavanje. Pri AWS vodi strategijo in tržišča za delovne obremenitve avtonomnih vozil.
Paul George je uspešen vodja izdelkov z več kot 15-letnimi izkušnjami na področju avtomobilskih tehnologij. Spreten je pri vodenju ekip za produktno upravljanje, strategijo, Go-to-Market in sistemski inženiring. Po vsem svetu je inkubiral in lansiral več novih izdelkov za zaznavanje in zaznavanje. Pri AWS vodi strategijo in tržišča za delovne obremenitve avtonomnih vozil.
 Caroline Chung je vodja inženiringa pri Veoneerju (ki ga je prevzela Magna International), ima več kot 14 let izkušenj z razvojem sistemov zaznavanja in zaznavanja. Trenutno vodi predrazvojne programe notranjega zaznavanja pri Magna International in vodi skupino inženirjev za računalniški vid in podatkovnih znanstvenikov.
Caroline Chung je vodja inženiringa pri Veoneerju (ki ga je prevzela Magna International), ima več kot 14 let izkušenj z razvojem sistemov zaznavanja in zaznavanja. Trenutno vodi predrazvojne programe notranjega zaznavanja pri Magna International in vodi skupino inženirjev za računalniški vid in podatkovnih znanstvenikov.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

