Amazon SageMaker Studio zagotavlja popolnoma upravljano rešitev za podatkovne znanstvenike za interaktivno gradnjo, usposabljanje in uvajanje modelov strojnega učenja (ML). V procesu dela na svojih nalogah ML podatkovni znanstveniki svoj potek dela običajno začnejo z odkrivanjem ustreznih podatkovnih virov in povezovanjem z njimi. Nato uporabljajo SQL za raziskovanje, analizo, vizualizacijo in integracijo podatkov iz različnih virov, preden jih uporabijo v svojem usposabljanju in sklepanju ML. Prej so se podatkovni znanstveniki pogosto znašli v žongliranju z več orodji za podporo SQL v svojem delovnem toku, kar je oviralo produktivnost.
Z veseljem sporočamo, da imajo prenosniki JupyterLab v SageMaker Studio zdaj vgrajeno podporo za SQL. Podatkovni znanstveniki lahko zdaj:
- Povežite se s priljubljenimi podatkovnimi storitvami, vključno z Amazonska Atena, Amazon RedShift, Amazon DataZonein Snežinka neposredno v zvezkih
- Prebrskajte in poiščite baze podatkov, sheme, tabele in poglede ter si oglejte predogled podatkov v vmesniku prenosnika
- Zmešajte kodo SQL in Python v istem zvezku za učinkovito raziskovanje in preoblikovanje podatkov za uporabo v projektih ML
- Uporabite funkcije produktivnosti razvijalca, kot je dokončanje ukazov SQL, pomoč pri oblikovanju kode in označevanje sintakse, da pospešite razvoj kode in izboljšate splošno produktivnost razvijalca
Poleg tega lahko skrbniki varno upravljajo povezave s temi podatkovnimi storitvami, kar podatkovnim znanstvenikom omogoča dostop do pooblaščenih podatkov, ne da bi morali ročno upravljati poverilnice.
V tej objavi vas vodimo skozi nastavitev te funkcije v SageMaker Studio in skozi različne zmožnosti te funkcije. Nato pokažemo, kako lahko izboljšate izkušnjo SQL v prenosnem računalniku z uporabo zmogljivosti Text-to-SQL, ki jih zagotavljajo napredni veliki jezikovni modeli (LLM), za pisanje zapletenih poizvedb SQL z uporabo besedila v naravnem jeziku kot vhoda. Nazadnje, da omogočimo širši publiki uporabnikov ustvarjanje poizvedb SQL iz vnosa v naravnem jeziku v svojih prenosnikih, vam pokažemo, kako uvesti te modele Text-to-SQL z uporabo Amazon SageMaker končne točke.
Pregled rešitev
Z integracijo SQL prenosnega računalnika SageMaker Studio JupyterLab se lahko zdaj povežete s priljubljenimi viri podatkov, kot so Snowflake, Athena, Amazon Redshift in Amazon DataZone. Ta nova funkcija vam omogoča izvajanje različnih funkcij.
Na primer, lahko vizualno raziskujete vire podatkov, kot so baze podatkov, tabele in sheme, neposredno iz vašega ekosistema JupyterLab. Če se vaša okolja prenosnika izvajajo na SageMaker Distribution 1.6 ali novejši, poiščite nov pripomoček na levi strani vmesnika JupyterLab. Ta dodatek izboljša dostopnost podatkov in upravljanje v vašem razvojnem okolju.
Če trenutno niste na predlagani distribuciji SageMaker (1.5 ali nižji) ali v okolju po meri, glejte dodatek za več informacij.
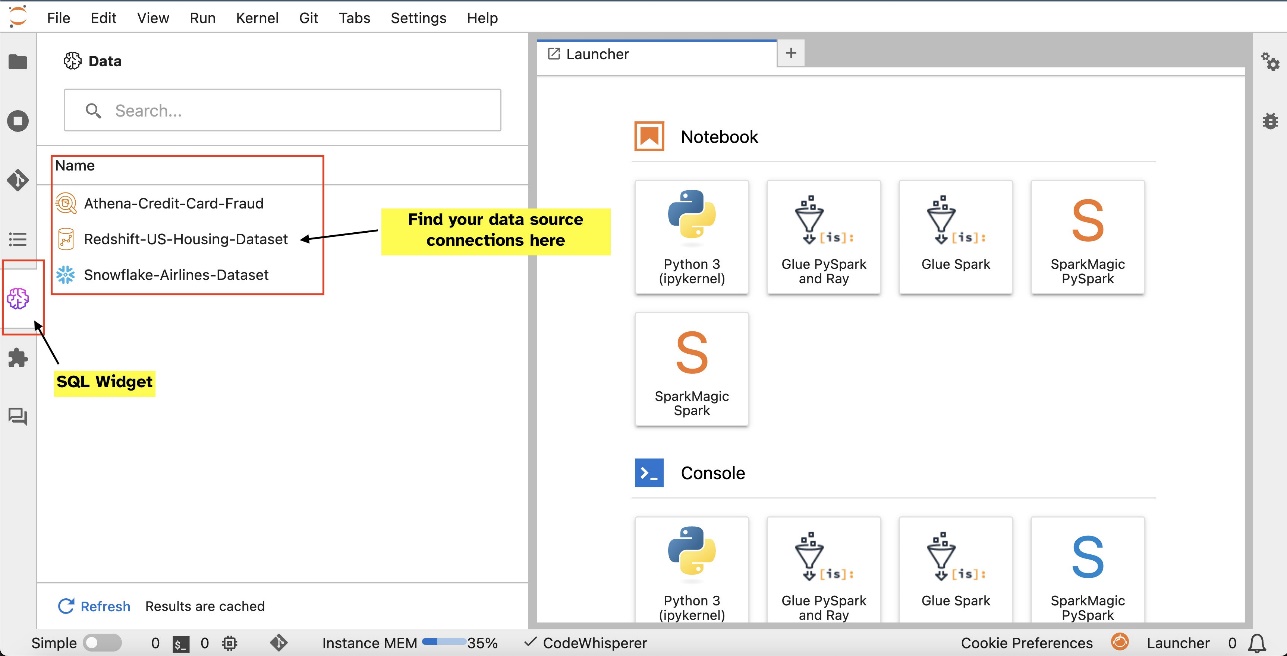
Ko nastavite povezave (prikazano v naslednjem razdelku), lahko navedete podatkovne povezave, brskate po bazah podatkov in tabelah ter pregledujete sheme.
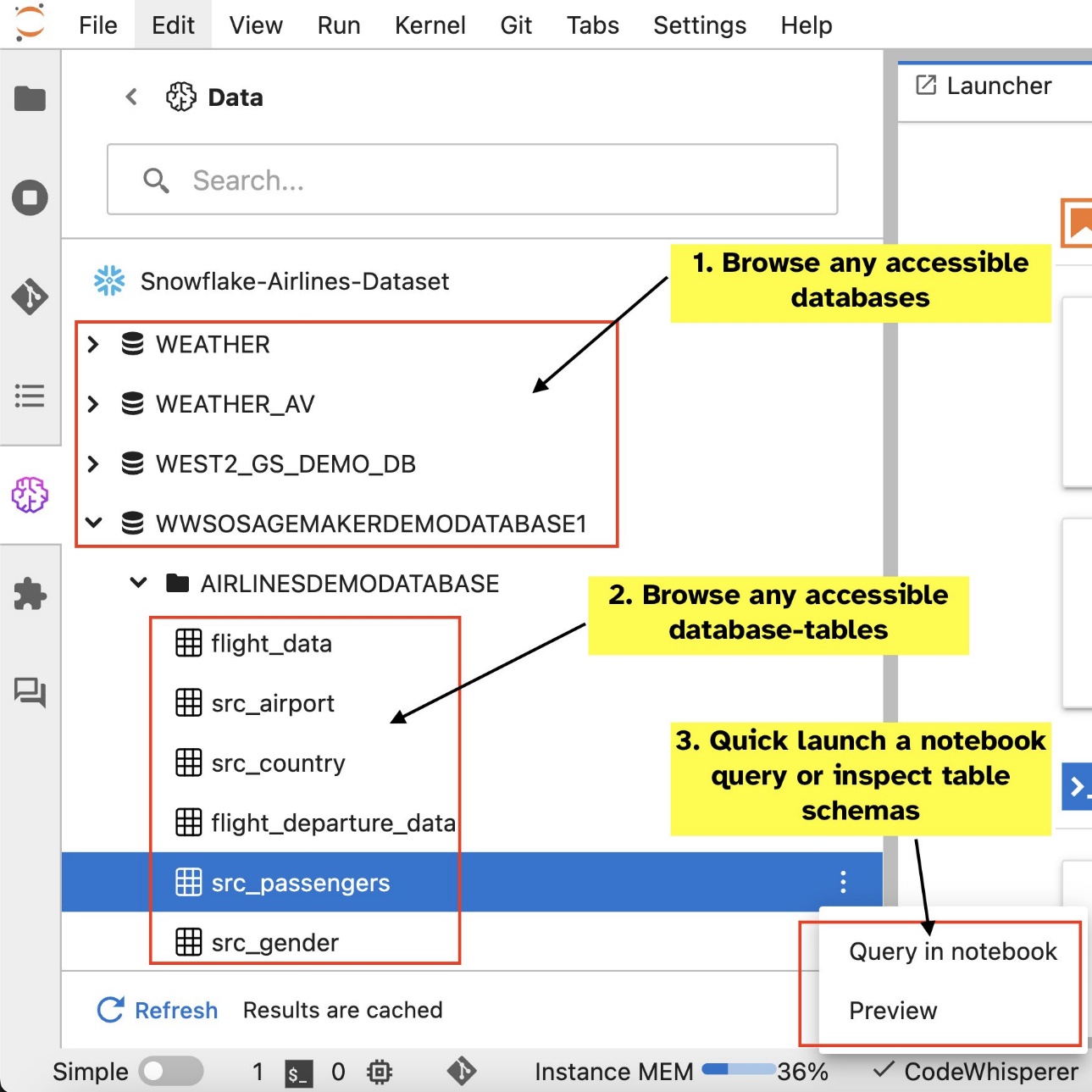
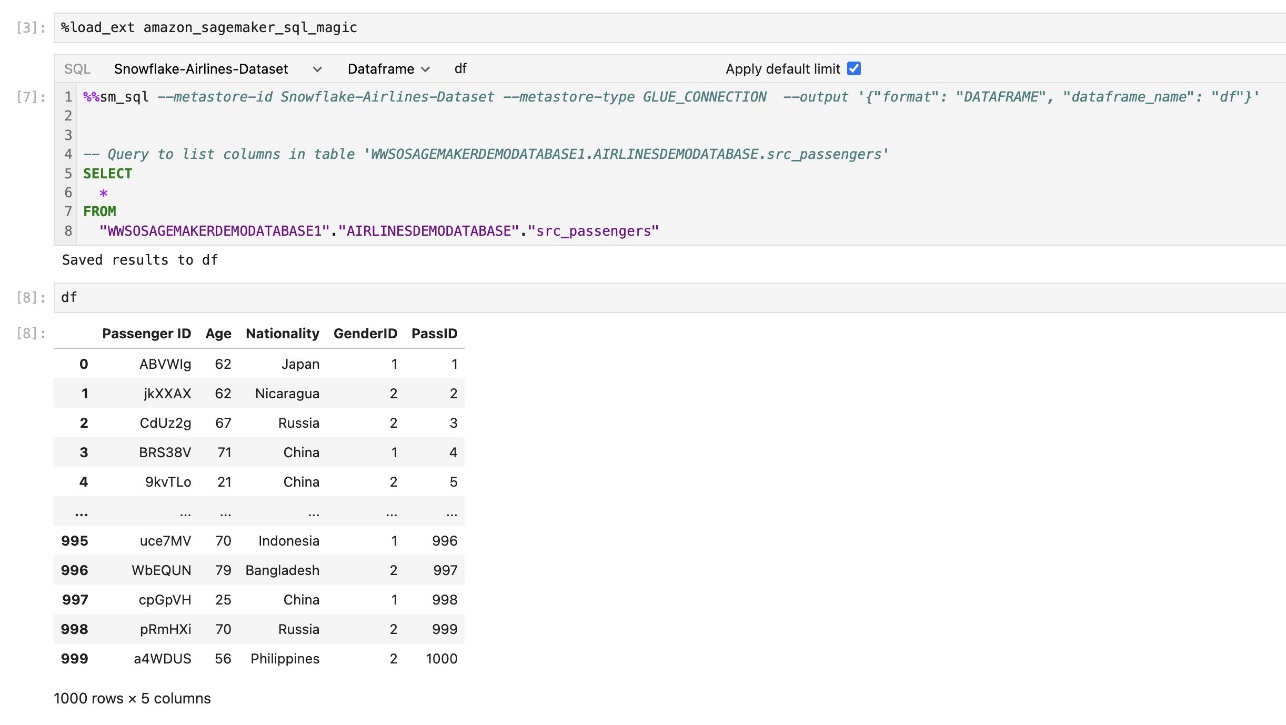
Vgrajena razširitev SQL SageMaker Studio JupyterLab vam omogoča tudi izvajanje poizvedb SQL neposredno iz prenosnega računalnika. Prenosni računalniki Jupyter lahko razlikujejo med kodo SQL in Python z uporabo %%sm_sql čarobni ukaz, ki mora biti postavljen na vrh katere koli celice, ki vsebuje kodo SQL. Ta ukaz sporoča JupyterLabu, da so naslednja navodila ukazi SQL in ne koda Python. Izhod poizvedbe je mogoče prikazati neposredno v zvezku, kar olajša brezhibno integracijo delovnih tokov SQL in Python v vaši analizi podatkov.
Rezultat poizvedbe je mogoče vizualno prikazati kot tabele HTML, kot je prikazano na naslednjem posnetku zaslona.

Lahko se napišejo tudi na a pandas DataFrame.
Predpogoji
Prepričajte se, da ste izpolnili naslednje predpogoje, če želite uporabljati izkušnjo SQL prenosnika SageMaker Studio:
- SageMaker Studio V2 – Prepričajte se, da uporabljate najnovejšo različico svojega Domena in uporabniški profili SageMaker Studio. Če trenutno uporabljate SageMaker Studio Classic, glejte Selitev iz Amazon SageMaker Studio Classic.
- Vloga IAM – SageMaker zahteva AWS upravljanje identitete in dostopa (IAM), ki bo dodeljena domeni SageMaker Studio ali uporabniškemu profilu za učinkovito upravljanje dovoljenj. Za uvedbo brskanja po podatkih in funkcije izvajanja SQL bo morda potrebna posodobitev vloge izvajanja. Naslednji primer pravilnika omogoča uporabnikom dodelitev, seznam in izvajanje AWS lepilo, Atena, Preprosta storitev shranjevanja Amazon (Amazon S3), Upravitelj skrivnosti AWSin viri Amazon Redshift:
- JupyterLab Space – Potrebujete dostop do posodobljenega SageMaker Studio in JupyterLab Space z Distribucija SageMaker v1.6 ali novejše različice slike. Če uporabljate slike po meri za JupyterLab Spaces ali starejše različice SageMaker Distribution (v1.5 ali starejše), glejte dodatek za navodila za namestitev potrebnih paketov in modulov za omogočanje te funkcije v vaših okoljih. Če želite izvedeti več o SageMaker Studio JupyterLab Spaces, glejte Povečajte produktivnost v studiu Amazon SageMaker: Predstavljamo JupyterLab Spaces in generativna orodja AI.
- Poverilnice za dostop do vira podatkov – Ta funkcija prenosnika SageMaker Studio zahteva dostop z uporabniškim imenom in geslom do virov podatkov, kot sta Snowflake in Amazon Redshift. Ustvarite dostop na podlagi uporabniškega imena in gesla do teh virov podatkov, če ga še nimate. Dostop do Snowflake, ki temelji na OAuth, od tega pisanja ni podprta funkcija.
- Naloži čarovnijo SQL – Preden zaženete poizvedbe SQL iz celice prenosnega računalnika Jupyter, je bistveno, da naložite razširitev SQL magics. Uporabite ukaz
%load_ext amazon_sagemaker_sql_magicda omogočite to funkcijo. Poleg tega lahko zaženete%sm_sql?ukaz za ogled izčrpnega seznama podprtih možnosti za poizvedovanje iz celice SQL. Te možnosti med drugim vključujejo nastavitev privzete omejitve poizvedbe na 1,000, izvajanje popolne ekstrakcije in vstavljanje parametrov poizvedbe. Ta nastavitev omogoča prilagodljivo in učinkovito manipulacijo podatkov SQL neposredno v okolju vašega prenosnika.
Ustvarite povezave z bazo podatkov
Vgrajene zmožnosti brskanja in izvajanja SQL programa SageMaker Studio so izboljšane s povezavami AWS Glue. Povezava AWS Glue je objekt AWS Glue Data Catalog, ki shranjuje bistvene podatke, kot so poverilnice za prijavo, nizi URI in informacije o navideznem zasebnem oblaku (VPC) za določene shrambe podatkov. Te povezave uporabljajo pajki AWS Glue, opravila in razvojne končne točke za dostop do različnih vrst podatkovnih shramb. Te povezave lahko uporabite za izvorne in ciljne podatke in celo znova uporabite isto povezavo v več pajkih ali opravilih ekstrahiranja, preoblikovanja in nalaganja (ETL).
Če želite raziskati vire podatkov SQL v levem podoknu SageMaker Studio, morate najprej ustvariti povezovalne objekte AWS Glue. Te povezave olajšajo dostop do različnih virov podatkov in vam omogočajo raziskovanje njihovih shematskih podatkovnih elementov.
V naslednjih razdelkih se sprehodimo skozi postopek ustvarjanja konektorjev AWS Glue, specifičnih za SQL. To vam bo omogočilo dostop, ogled in raziskovanje naborov podatkov v različnih shrambah podatkov. Za podrobnejše informacije o povezavah AWS Glue glejte Povezovanje s podatki.
Ustvarite povezavo AWS Glue
Edini način za prenos virov podatkov v SageMaker Studio so povezave AWS Glue. Ustvariti morate povezave AWS Glue z določenimi vrstami povezav. Od tega pisanja je edini podprti mehanizem za ustvarjanje teh povezav uporaba Vmesnik ukazne vrstice AWS (AWS CLI).
Datoteka JSON z definicijo povezave
Ko se povezujete z različnimi viri podatkov v AWS Glue, morate najprej ustvariti datoteko JSON, ki definira lastnosti povezave – imenovane datoteka z definicijo povezave. Ta datoteka je ključnega pomena za vzpostavitev povezave AWS Glue in mora vsebovati vse potrebne konfiguracije za dostop do vira podatkov. Za najboljšo varnostno prakso priporočamo uporabo upravitelja skrivnosti za varno shranjevanje občutljivih informacij, kot so gesla. Medtem lahko druge lastnosti povezave upravljate neposredno prek povezav AWS Glue. Ta pristop zagotavlja, da so občutljive poverilnice zaščitene, medtem ko je konfiguracija povezave še vedno dostopna in obvladljiva.
Sledi primer definicije povezave JSON:
Pri nastavljanju povezav AWS Glue za vaše vire podatkov morate upoštevati nekaj pomembnih smernic, da zagotovite funkcionalnost in varnost:
- Nizanje lastnosti - Znotraj
PythonPropertiesključ, se prepričajte, da so vse lastnosti nanizani pari ključ-vrednost. Ključnega pomena je, da se pravilno izognete dvojnim narekovajem z uporabo znaka nazaj (), kjer je to potrebno. To pomaga ohranjati pravilno obliko in se izogniti sintaksnim napakam v vašem JSON. - Ravnanje z občutljivimi informacijami – Čeprav je mogoče vključiti vse lastnosti povezave
PythonProperties, je priporočljivo, da občutljivih podrobnosti, kot so gesla, ne vključite neposredno v te lastnosti. Namesto tega uporabite Secrets Manager za ravnanje z občutljivimi informacijami. Ta pristop ščiti vaše občutljive podatke tako, da jih shranjuje v nadzorovanem in šifriranem okolju, stran od glavnih konfiguracijskih datotek.
Ustvarite povezavo AWS Glue z uporabo AWS CLI
Ko vključite vsa potrebna polja v datoteko JSON z definicijo povezave, ste pripravljeni na vzpostavitev povezave AWS Glue za vaš vir podatkov z uporabo AWS CLI in naslednjega ukaza:
Ta ukaz sproži novo povezavo AWS Glue na podlagi specifikacij, podrobno opisanih v vaši datoteki JSON. Sledi hitra razčlenitev komponent ukaza:
- – regija – To določa regijo AWS, kjer bo ustvarjena vaša povezava AWS Glue. Bistveno je, da izberete regijo, kjer se nahajajo vaši podatkovni viri in druge storitve, da zmanjšate zakasnitev in izpolnite zahteve glede stalnega prebivališča podatkov.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Ta parameter usmerja AWS CLI, da prebere vhodno konfiguracijo iz lokalne datoteke, ki vsebuje vašo definicijo povezave v formatu JSON.
Morali bi imeti možnost ustvariti povezave AWS Glue s prejšnjim ukazom AWS CLI iz terminala Studio JupyterLab. Na file izberite meni Novo in terminal.

Če create-connection ukaz uspešno izvaja, bi morali videti vir podatkov naveden v podoknu brskalnika SQL. Če svojega vira podatkov ne vidite na seznamu, izberite Osveži za posodobitev predpomnilnika.

Ustvarite povezavo Snowflake
V tem razdelku se osredotočamo na integracijo vira podatkov Snowflake s SageMaker Studio. Ustvarjanje računov, baz podatkov in skladišč Snowflake ne spada v obseg te objave. Če želite začeti uporabljati Snowflake, glejte Navodila za uporabo Snowflake. V tej objavi se osredotočamo na ustvarjanje datoteke JSON z definicijo Snowflake in vzpostavitev povezave z izvorom podatkov Snowflake z uporabo AWS Glue.
Ustvarite skrivnost upravitelja skrivnosti
S svojim računom Snowflake se lahko povežete tako, da uporabite ID uporabnika in geslo ali uporabite zasebne ključe. Če se želite povezati z ID-jem uporabnika in geslom, morate varno shraniti poverilnice v upravitelju skrivnosti. Kot je bilo že omenjeno, čeprav je te informacije mogoče vdelati pod PythonProperties, ni priporočljivo shranjevati občutljivih informacij v obliki navadnega besedila. Vedno se prepričajte, da se z občutljivimi podatki ravna varno, da se izognete morebitnim varnostnim tveganjem.
Za shranjevanje podatkov v upravitelju skrivnosti izvedite naslednje korake:
- Na konzoli Secrets Manager izberite Shrani novo skrivnost.
- za Skrivni tip, izberite Druga vrsta skrivnosti.
- Za par ključ-vrednost izberite Golo besedilo in vnesite naslednje:
- Vnesite ime za svojo skrivnost, npr
sm-sql-snowflake-secret. - Ostale nastavitve pustite privzete ali jih po potrebi prilagodite.
- Ustvari skrivnost.
Ustvarite povezavo AWS Glue za Snowflake
Kot smo že omenili, so povezave AWS Glue bistvene za dostop do katere koli povezave iz SageMaker Studio. Najdete lahko seznam vse podprte lastnosti povezave za Snowflake. Sledi vzorčna definicija povezave JSON za Snowflake. Zamenjajte vrednosti ograd z ustreznimi vrednostmi, preden ga shranite na disk:
Če želite ustvariti objekt povezave AWS Glue za vir podatkov Snowflake, uporabite naslednji ukaz:
Ta ukaz ustvari novo povezavo vira podatkov Snowflake v vašem podoknu brskalnika SQL, po kateri je mogoče brskati, in lahko izvajate poizvedbe SQL proti njej iz svoje celice prenosnega računalnika JupyterLab.
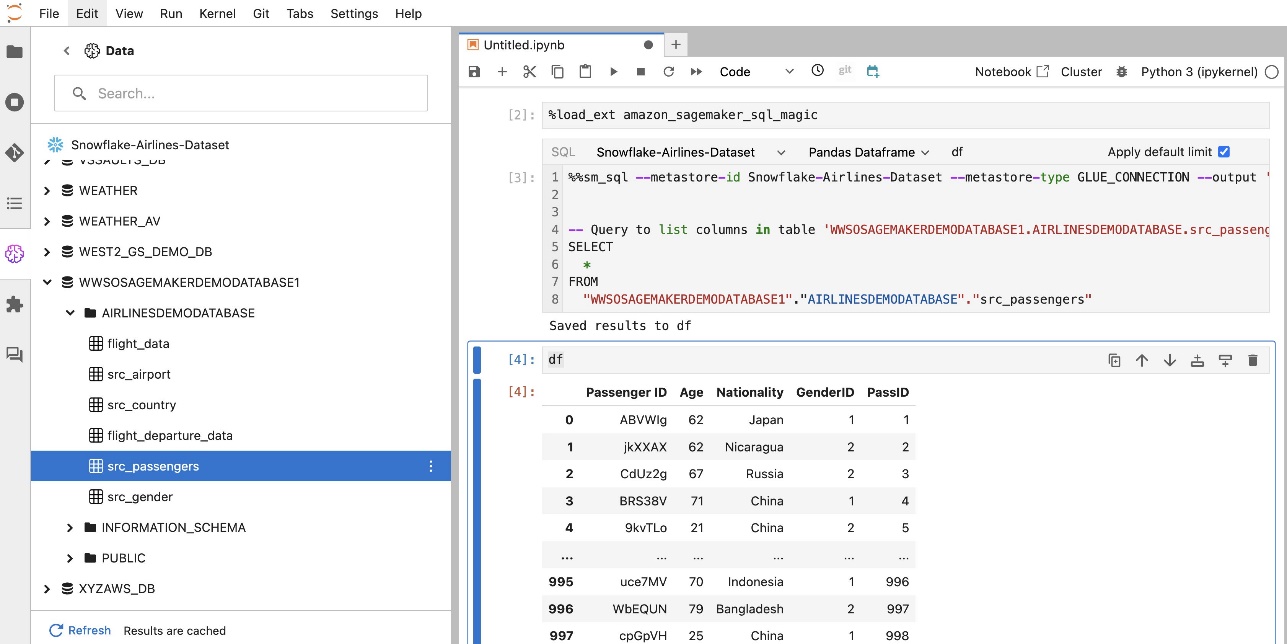
Ustvarite povezavo Amazon Redshift
Amazon Redshift je popolnoma upravljana storitev skladiščenja podatkov v velikosti petabajtov, ki poenostavi in zmanjša stroške analize vseh vaših podatkov s standardnim SQL. Postopek za ustvarjanje povezave Amazon Redshift je zelo podoben postopku za povezavo Snowflake.
Ustvarite skrivnost upravitelja skrivnosti
Podobno kot pri nastavitvi Snowflake morate za povezavo z Amazon Redshift z uporabniškim ID-jem in geslom varno shraniti tajne podatke v Secrets Managerju. Izvedite naslednje korake:
- Na konzoli Secrets Manager izberite Shrani novo skrivnost.
- za Skrivni tip, izberite Poverilnice za gručo Amazon Redshift.
- Vnesite poverilnice, uporabljene za prijavo za dostop do Amazon Redshift kot vira podatkov.
- Izberite gručo Redshift, povezano s skrivnostmi.
- Vnesite ime za skrivnost, npr
sm-sql-redshift-secret. - Ostale nastavitve pustite privzete ali jih po potrebi prilagodite.
- Ustvari skrivnost.
Če sledite tem korakom, zagotovite, da se vaše poverilnice za povezavo varno obravnavajo z uporabo robustnih varnostnih funkcij AWS za učinkovito upravljanje občutljivih podatkov.
Ustvarite povezavo AWS Glue za Amazon Redshift
Če želite vzpostaviti povezavo z Amazon Redshift z uporabo definicije JSON, izpolnite potrebna polja in shranite naslednjo konfiguracijo JSON na disk:
Če želite ustvariti povezovalni objekt AWS Glue za vir podatkov Redshift, uporabite naslednji ukaz AWS CLI:
Ta ukaz ustvari povezavo v AWS Glue, povezano z vašim virom podatkov Redshift. Če se ukaz uspešno izvede, boste lahko videli svoj vir podatkov Redshift v prenosnem računalniku SageMaker Studio JupyterLab, pripravljen za izvajanje poizvedb SQL in analizo podatkov.

Ustvarite povezavo Athena
Athena je popolnoma upravljana storitev poizvedb SQL podjetja AWS, ki omogoča analizo podatkov, shranjenih v Amazon S3, z uporabo standardnega SQL. Če želite nastaviti povezavo Athena kot vir podatkov v brskalniku SQL prenosnega računalnika JupyterLab, morate ustvariti definicijo vzorčne povezave Athena JSON. Naslednja struktura JSON konfigurira potrebne podrobnosti za povezavo z Atheno, pri čemer določa podatkovni katalog, uprizoritveni imenik S3 in regijo:
Če želite ustvariti povezovalni objekt AWS Glue za vir podatkov Athena, uporabite naslednji ukaz AWS CLI:
Če je ukaz uspešen, boste lahko dostopali do podatkovnega kataloga Athena in tabel neposredno iz brskalnika SQL v vašem prenosniku SageMaker Studio JupyterLab.
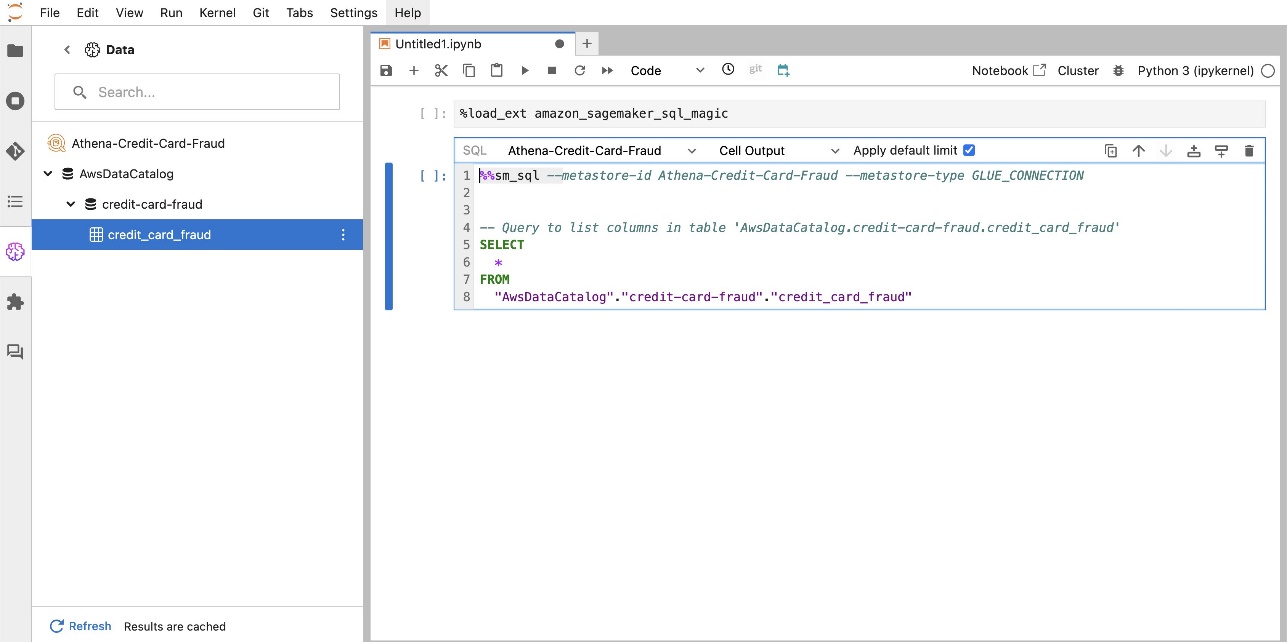
Poizvedujte po podatkih iz več virov
Če imate več podatkovnih virov integriranih v SageMaker Studio prek vgrajenega brskalnika SQL in funkcije SQL prenosnega računalnika, lahko hitro zaženete poizvedbe in brez napora preklapljate med zalednimi viri podatkov v naslednjih celicah znotraj prenosnega računalnika. Ta zmožnost omogoča brezhibne prehode med različnimi zbirkami podatkov ali viri podatkov med potekom dela analize.
Izvajate lahko poizvedbe glede na raznoliko zbirko ozadij virov podatkov in prenesete rezultate neposredno v prostor Python za nadaljnjo analizo ali vizualizacijo. To olajša %%sm_sql čarobni ukaz, ki je na voljo v prenosnikih SageMaker Studio. Za izpis rezultatov vaše poizvedbe SQL v pandas DataFrame sta na voljo dve možnosti:
- V orodni vrstici celice prenosnega računalnika izberite vrsto izpisa DataFrame in poimenujte svojo spremenljivko DataFrame
- Dodajte naslednji parameter vašemu
%%sm_sqlukaz:
Naslednji diagram ponazarja ta potek dela in prikazuje, kako lahko brez truda izvajate poizvedbe prek različnih virov v naslednjih celicah prenosnega računalnika, kot tudi urite model SageMaker z uporabo učnih opravil ali neposredno v prenosnem računalniku z uporabo lokalnega računalništva. Poleg tega diagram poudarja, kako vgrajena integracija SQL programa SageMaker Studio poenostavlja postopke ekstrakcije in gradnje neposredno v znanem okolju celice prenosnega računalnika JupyterLab.
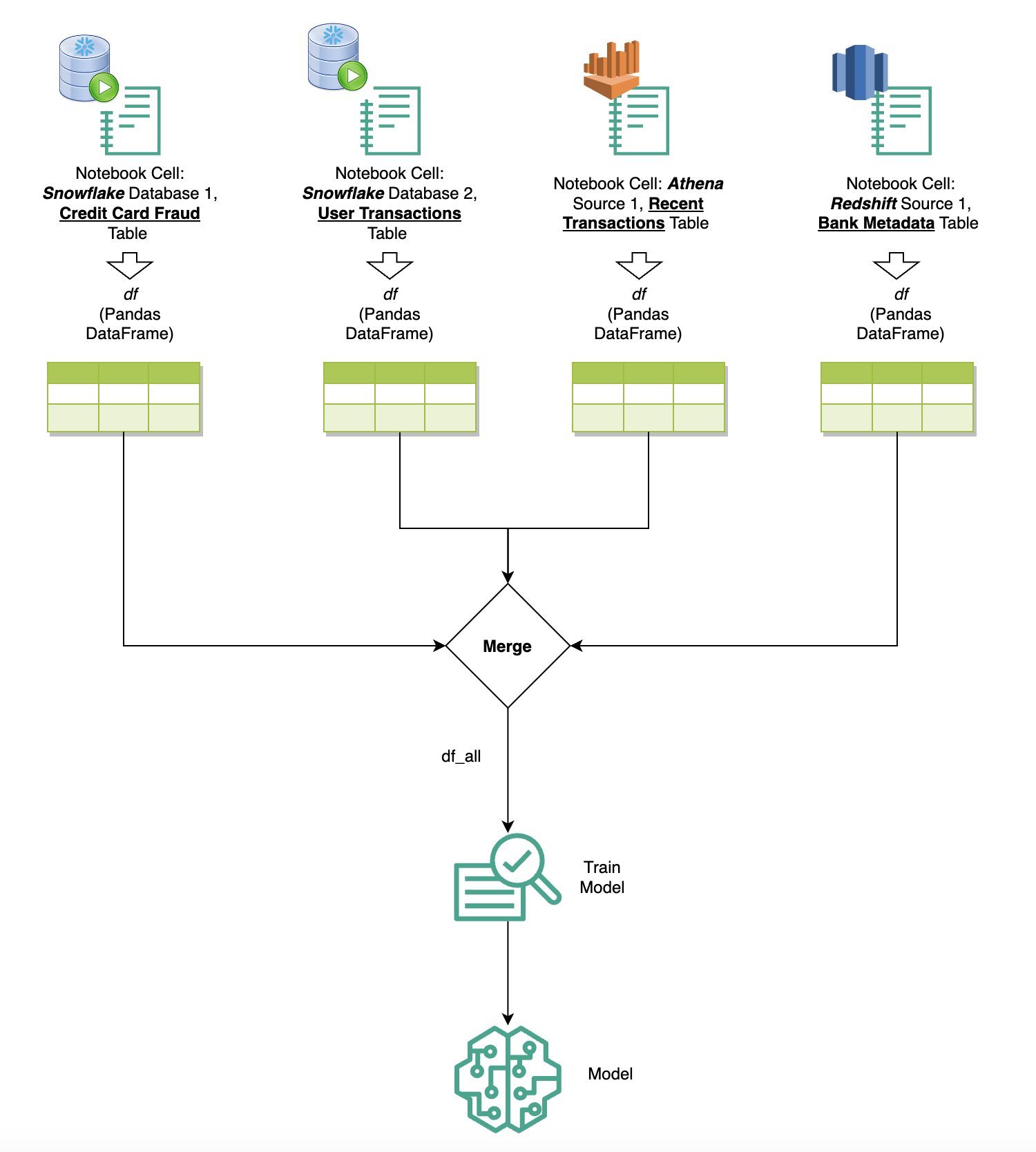
Besedilo v SQL: uporaba naravnega jezika za izboljšanje avtorstva poizvedb
SQL je kompleksen jezik, ki zahteva razumevanje baz podatkov, tabel, sintaks in metapodatkov. Danes vam lahko generativna umetna inteligenca (AI) omogoči pisanje zapletenih poizvedb SQL, ne da bi morali imeti poglobljene izkušnje s SQL. Napredek LLM-jev je znatno vplival na generiranje SQL, ki temelji na obdelavi naravnega jezika (NLP), kar omogoča ustvarjanje natančnih poizvedb SQL iz opisov naravnega jezika – tehnika, imenovana Text-to-SQL. Vendar pa je nujno priznati inherentne razlike med človeškim jezikom in SQL. Človeški jezik je včasih lahko dvoumen ali nenatančen, medtem ko je SQL strukturiran, ekspliciten in nedvoumen. Premostitev te vrzeli in natančna pretvorba naravnega jezika v poizvedbe SQL lahko predstavljata izjemen izziv. Ko so na voljo ustrezni pozivi, lahko LLM-ji pomagajo premostiti to vrzel z razumevanjem namena v ozadju človeškega jezika in ustrezno ustvarjanjem natančnih poizvedb SQL.
Z izdajo funkcije poizvedbe SQL v prenosnem računalniku SageMaker Studio SageMaker Studio omogoča enostavno pregledovanje baz podatkov in shem ter ustvarjanje, izvajanje in odpravljanje napak v poizvedbah SQL, ne da bi morali zapustiti IDE prenosnega računalnika Jupyter. Ta razdelek raziskuje, kako lahko zmožnosti Text-to-SQL naprednih LLM-jev olajšajo ustvarjanje poizvedb SQL z uporabo naravnega jezika v prenosnikih Jupyter. Uporabljamo najsodobnejši model Text-to-SQL defog/sqlcoder-7b-2 v povezavi z Jupyter AI, generativnim AI pomočnikom, posebej zasnovanim za prenosne računalnike Jupyter, za ustvarjanje kompleksnih poizvedb SQL iz naravnega jezika. Z uporabo tega naprednega modela lahko brez truda in učinkovito ustvarimo zapletene poizvedbe SQL z uporabo naravnega jezika in s tem izboljšamo našo izkušnjo SQL v prenosnikih.
Izdelava prototipov prenosnika z Hugging Face Hub
Za začetek izdelave prototipov potrebujete naslednje:
- Koda GitHub – Koda, predstavljena v tem razdelku, je na voljo v nadaljevanju GitHub repo in s sklicevanjem na primer zvezek.
- JupyterLab Space – Bistvenega pomena je dostop do prostora SageMaker Studio JupyterLab, ki ga podpirajo instance na osnovi GPU. Za
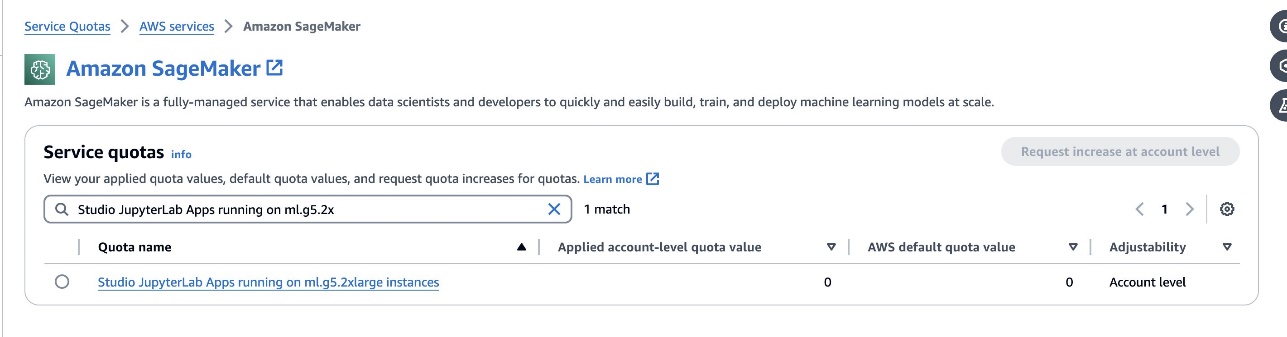
defog/sqlcoder-7b-2modela, je priporočljiv model parametrov 7B, uporaba primerka ml.g5.2xlarge. Alternative kot nprdefog/sqlcoder-70b-alpha alidefog/sqlcoder-34b-alphaso primerni tudi za pretvorbo naravnega jezika v SQL, vendar so za izdelavo prototipov morda potrebni večji tipi primerkov. Prepričajte se, da imate kvoto za zagon primerka, podprtega z GPU, tako da se pomaknete do konzole Service Quotas, poiščete SageMaker in poiščeteStudio JupyterLab Apps running on <instance type>.
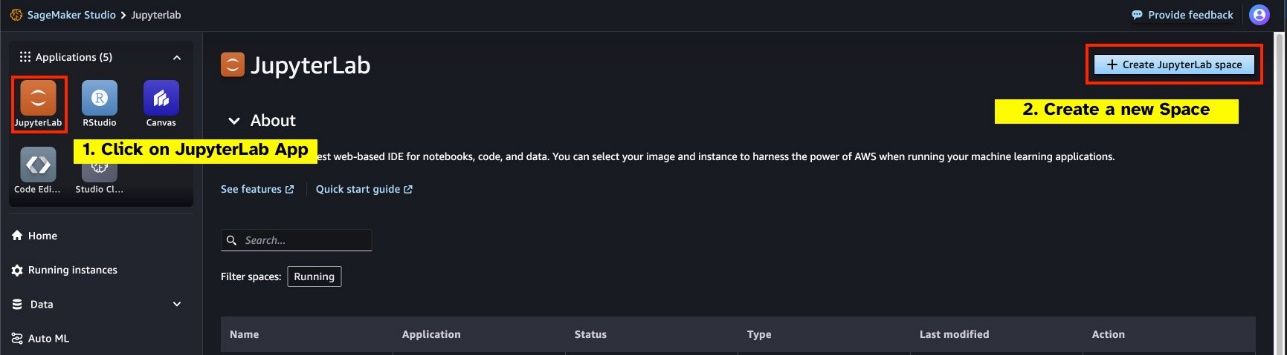
Zaženite nov JupyterLab Space, podprt z grafično procesorsko enoto, iz vašega studia SageMaker. Priporočljivo je ustvariti nov JupyterLab Space z vsaj 75 GB Trgovina z elastičnimi bloki Amazon (Amazon EBS) shranjevanje za model parametrov 7B.

- Hugging Face Hub – Če ima vaša domena SageMaker Studio dostop do prenosa modelov iz Hugging Face Hub, lahko uporabite
AutoModelForCausalLMrazred od huggingface/transformers za samodejni prenos modelov in njihovo pripenjanje na lokalne grafične procesorje. Uteži modela bodo shranjene v predpomnilniku vašega lokalnega računalnika. Oglejte si naslednjo kodo:
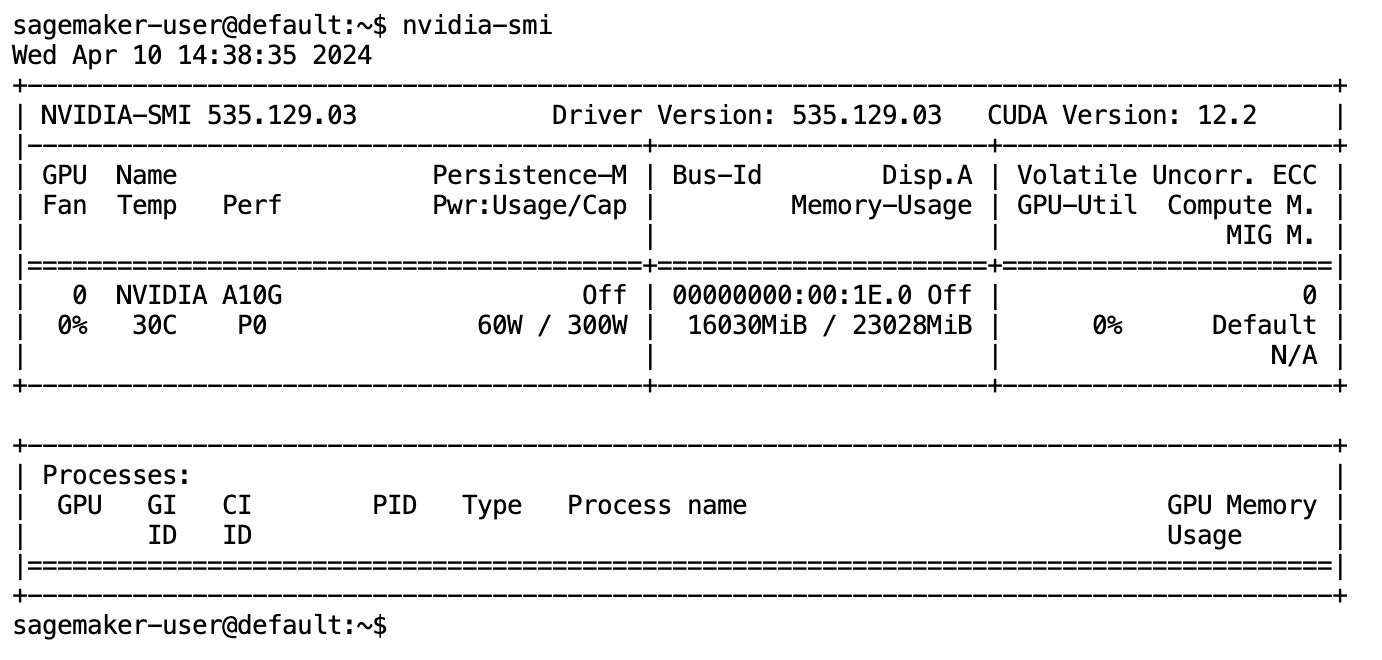
Ko je bil model v celoti prenesen in naložen v pomnilnik, bi morali opaziti povečanje uporabe GPE na vašem lokalnem računalniku. To pomeni, da model aktivno uporablja vire GPU za računalniške naloge. To lahko preverite v lastnem prostoru JupyterLab z zagonom nvidia-smi (za enkratni prikaz) oz nvidia-smi —loop=1 (ponoviti vsako sekundo) iz terminala JupyterLab.
Modeli Text-to-SQL so odlični pri razumevanju namena in konteksta uporabnikove zahteve, tudi če je uporabljeni jezik pogovorni ali dvoumen. Postopek vključuje prevajanje vnosov naravnega jezika v pravilne elemente sheme baze podatkov, kot so imena tabel, imena stolpcev in pogoji. Vendar standardni model Text-to-SQL sam po sebi ne bo poznal strukture vašega podatkovnega skladišča, specifičnih shem baze podatkov ali natančno interpretiral vsebine tabele samo na podlagi imen stolpcev. Za učinkovito uporabo teh modelov za generiranje praktičnih in učinkovitih poizvedb SQL iz naravnega jezika je treba prilagoditi model generiranja besedila SQL vaši specifični shemi baze podatkov skladišča. Ta prilagoditev je olajšana z uporabo LLM pozivi. Sledi priporočena predloga poziva za model besedila v SQL defog/sqlcoder-7b-2, razdeljena na štiri dele:
- Naloga – V tem razdelku mora biti navedena naloga na visoki ravni, ki jo mora model opraviti. Vključevati mora vrsto zaledja baze podatkov (kot je Amazon RDS, PostgreSQL ali Amazon Redshift), da se model zaveda morebitnih niansiranih sintaktičnih razlik, ki lahko vplivajo na ustvarjanje končne poizvedbe SQL.
- navodila – Ta razdelek bi moral definirati meje nalog in zavedanje domene za model ter lahko vključuje nekaj primerov, ki vodijo model pri ustvarjanju natančno nastavljenih poizvedb SQL.
- Shema zbirke podatkov – Ta razdelek mora podrobno opisati sheme vaše baze podatkov skladišča, ki opisujejo odnose med tabelami in stolpci, da bi modelu pomagali pri razumevanju strukture baze podatkov.
- Odgovor – Ta razdelek je rezerviran za model za izpis odgovora poizvedbe SQL na vnos naravnega jezika.
Primer sheme baze podatkov in poziva, uporabljenega v tem razdelku, je na voljo v GitHub Repo.
Pri hitrem inženiringu ne gre le za oblikovanje vprašanj ali izjav; to je niansirana umetnost in znanost, ki pomembno vplivata na kakovost interakcij z modelom AI. Način, kako oblikujete poziv, lahko močno vpliva na naravo in uporabnost odziva AI. Ta veščina je ključna pri povečanju potenciala interakcij AI, zlasti pri zapletenih nalogah, ki zahtevajo specializirano razumevanje in podrobne odgovore.
Pomembno je imeti možnost hitre izdelave in testiranja odziva modela za dani poziv ter optimizacije poziva na podlagi odziva. Prenosni računalniki JupyterLab omogočajo prejemanje takojšnjih povratnih informacij o modelu od modela, ki se izvaja v lokalnem računalniku, in optimizirajo poziv ter dodatno prilagodijo odziv modela ali popolnoma spremenijo model. V tej objavi uporabljamo prenosni računalnik SageMaker Studio JupyterLab, ki ga podpira ml.g5.2xlarge's NVIDIA A10G 24 GB GPE, za izvajanje sklepanja o modelu Text-to-SQL na prenosnem računalniku in interaktivno gradnjo poziva našega modela, dokler odziv modela ni dovolj prilagojen, da zagotovi odzive, ki so neposredno izvršljivi v celicah SQL JupyterLaba. Za zagon sklepanja modela in hkratno pretakanje odzivov modela uporabljamo kombinacijo model.generate in TextIteratorStreamer kot je opredeljeno v naslednji kodi:
Izhod modela lahko okrasite s čarovnijo SageMaker SQL %%sm_sql ..., ki omogoča prenosniku JupyterLab, da prepozna celico kot celico SQL.
Gostite modele Text-to-SQL kot končne točke SageMaker
Na koncu faze izdelave prototipov smo izbrali naš želeni LLM besedila v SQL, učinkovito obliko poziva in ustrezno vrsto primerka za gostovanje modela (bodisi z enim GPU ali z več GPU). SageMaker omogoča razširljivo gostovanje modelov po meri z uporabo končnih točk SageMaker. Te končne točke je mogoče opredeliti v skladu s posebnimi merili, kar omogoča uvajanje LLM-jev kot končnih točk. Ta zmožnost vam omogoča, da razširite rešitev na širšo publiko, kar uporabnikom omogoča ustvarjanje poizvedb SQL iz vnosov v naravnem jeziku z uporabo LLM-jev, ki gostujejo po meri. Naslednji diagram ponazarja to arhitekturo.

Če želite gostiti svoj LLM kot končno točko SageMaker, ustvarite več artefaktov.
Prvi artefakt so uteži modelov. Storitev SageMaker Deep Java Library (DJL). vsebniki vam omogočajo nastavitev konfiguracij prek meta serviranje.lastnosti datoteko, ki vam omogoča usmerjanje pridobivanja modelov – neposredno iz središča Hugging Face Hub ali s prenosom artefaktov modela iz Amazon S3. Če navedete model_id=defog/sqlcoder-7b-2, bo DJL Serving poskusil neposredno prenesti ta model iz središča Hugging Face Hub. Vendar pa lahko zaračunate vstopne/izstopne stroške omrežja vsakič, ko je končna točka razporejena ali elastično prilagojena. Da bi se izognili tem stroškom in potencialno pospešili prenos artefaktov modela, je priporočljivo, da preskočite uporabo model_id in serving.properties in shranite uteži modela kot artefakte S3 in jih določite samo z s3url=s3://path/to/model/bin.
Shranjevanje modela (z njegovim tokenizerjem) na disk in nalaganje v Amazon S3 je mogoče doseči z le nekaj vrsticami kode:
Uporabite tudi pozivno datoteko zbirke podatkov. Pri tej nastavitvi je poziv baze podatkov sestavljen iz Task, Instructions, Database Schemain Answer sections. Za trenutno arhitekturo dodelimo ločeno pozivno datoteko za vsako shemo baze podatkov. Vendar obstaja prilagodljivost za razširitev te nastavitve na vključitev več baz podatkov na datoteko poziva, kar omogoča modelu izvajanje sestavljenih združevanj med bazami podatkov na istem strežniku. Med fazo izdelave prototipov shranimo poziv baze podatkov kot besedilno datoteko z imenom <Database-Glue-Connection-Name>.prompt, Kjer Database-Glue-Connection-Name ustreza imenu povezave, ki je vidno v vašem okolju JupyterLab. Ta objava se na primer nanaša na povezavo Snowflake z imenom Airlines_Dataset, zato je datoteka poziva baze podatkov poimenovana Airlines_Dataset.prompt. Ta datoteka je nato shranjena na Amazon S3 in nato prebrana in predpomnjena z našo logiko streženja modela.
Poleg tega ta arhitektura dovoljuje vsem pooblaščenim uporabnikom te končne točke, da definirajo, shranjujejo in generirajo poizvedbe SQL v naravnem jeziku brez potrebe po večkratni ponovni umestitvi modela. Uporabljamo naslednje primer poziva baze podatkov za predstavitev funkcije Text-to-SQL.
Nato ustvarite logiko storitev modela po meri. V tem razdelku opisujete logiko sklepanja po meri z imenom model.py. Ta skript je zasnovan za optimizacijo delovanja in integracije naših storitev Text-to-SQL:
- Definirajte logiko predpomnjenja datotek pozivov baze podatkov – Da zmanjšamo zakasnitev, implementiramo logiko po meri za prenos in predpomnjenje datotek pozivov baze podatkov. Ta mehanizem zagotavlja, da so pozivi takoj na voljo, kar zmanjšuje stroške, povezane s pogostimi prenosi.
- Definirajte logiko sklepanja modela po meri – Za izboljšanje hitrosti sklepanja se naš model besedila v SQL naloži v natančnem formatu float16 in nato pretvori v model DeepSpeed. Ta korak omogoča učinkovitejše računanje. Poleg tega znotraj te logike določite, katere parametre lahko uporabniki prilagodijo med klici sklepanja, da prilagodijo funkcionalnost svojim potrebam.
- Določite vhodno in izhodno logiko po meri – Vzpostavitev jasnih in prilagojenih vhodno/izhodnih formatov je bistvena za gladko integracijo z nadaljnjimi aplikacijami. Ena taka aplikacija je JupyterAI, o kateri razpravljamo v naslednjem razdelku.
Poleg tega vključujemo a serving.properties ki deluje kot globalna konfiguracijska datoteka za modele, ki gostujejo s strežbo DJL. Za več informacij glejte Konfiguracije in nastavitve.
Nazadnje lahko vključite tudi a requirements.txt datoteko za definiranje dodatnih modulov, potrebnih za sklepanje, in zapakiranje vsega v arhiv za uvajanje.
Glej naslednjo kodo:
Integrirajte svojo končno točko s pomočnikom SageMaker Studio Jupyter AI
Jupiter AI je odprtokodno orodje, ki prinaša generativno umetno inteligenco v prenosnike Jupyter ter ponuja robustno in uporabniku prijazno platformo za raziskovanje generativnih modelov umetne inteligence. Izboljšuje produktivnost v JupyterLabu in prenosnikih Jupyter z zagotavljanjem funkcij, kot je %%ai magic za ustvarjanje generativnega igrišča z umetno inteligenco v prenosnikih, izvorni uporabniški vmesnik za klepet v JupyterLabu za interakcijo z umetno inteligenco kot pogovorni pomočnik in podporo za široko paleto LLM-jev iz ponudniki kot Amazon Titan, AI21, Anthropic, Cohere in Hugging Face ali upravljane storitve, kot je Amazon Bedrock in končne točke SageMaker. Za to objavo uporabljamo že pripravljeno integracijo Jupyter AI s končnimi točkami SageMaker, da prenesemo zmogljivost Text-to-SQL v prenosnike JupyterLab. Orodje Jupyter AI je vnaprej nameščeno v vseh prostorih SageMaker Studio JupyterLab Spaces, ki jih podpira Slike distribucije SageMaker; končnim uporabnikom ni treba narediti nobenih dodatnih konfiguracij, da začnejo uporabljati razširitev Jupyter AI za integracijo s končno točko, ki jo gosti SageMaker. V tem razdelku razpravljamo o dveh načinih uporabe integriranega orodja Jupyter AI.
Jupyter AI v zvezku z uporabo magije
Jupyter AI %%ai čarobni ukaz vam omogoča preoblikovanje vaših prenosnikov SageMaker Studio JupyterLab v ponovljivo generativno okolje AI. Če želite začeti uporabljati AI magics, se prepričajte, da ste naložili razširitev jupyter_ai_magics za uporabo %%ai magic in dodatno obremenitev amazon_sagemaker_sql_magic uporabiti %%sm_sql magija:
Če želite zagnati klic do vaše končne točke SageMaker iz vašega prenosnika z uporabo %%ai čarobni ukaz, podajte naslednje parametre in strukturirajte ukaz, kot sledi:
- – ime-regije – Določite regijo, kjer je nameščena vaša končna točka. To zagotavlja, da je zahteva usmerjena na pravo geografsko lokacijo.
- –shema zahteve – Vključite shemo vhodnih podatkov. Ta shema opisuje pričakovano obliko in vrste vhodnih podatkov, ki jih vaš model potrebuje za obdelavo zahteve.
- –odzivna pot – Določite pot znotraj odzivnega objekta, kjer se nahaja izhod vašega modela. Ta pot se uporablja za pridobivanje ustreznih podatkov iz odgovora, ki ga vrne vaš model.
- -f (izbirno) – To je izhodni formater zastavica, ki označuje vrsto izhoda, ki ga vrne model. V kontekstu prenosnega računalnika Jupyter, če je izhod koda, mora biti ta zastavica ustrezno nastavljena, da formatira izhod kot izvršljivo kodo na vrhu celice prenosnega računalnika Jupyter, ki ji sledi prosto območje za vnos besedila za interakcijo uporabnika.
Na primer, ukaz v celici zvezka Jupyter je lahko videti kot naslednja koda:
Okno za klepet Jupyter AI
Lahko pa komunicirate s končnimi točkami SageMaker prek vgrajenega uporabniškega vmesnika, kar poenostavi postopek generiranja poizvedb ali sodelovanja v dialogu. Preden začnete klepetati s svojo končno točko SageMaker, konfigurirajte ustrezne nastavitve v Jupyter AI za končno točko SageMaker, kot je prikazano na naslednjem posnetku zaslona.
 |
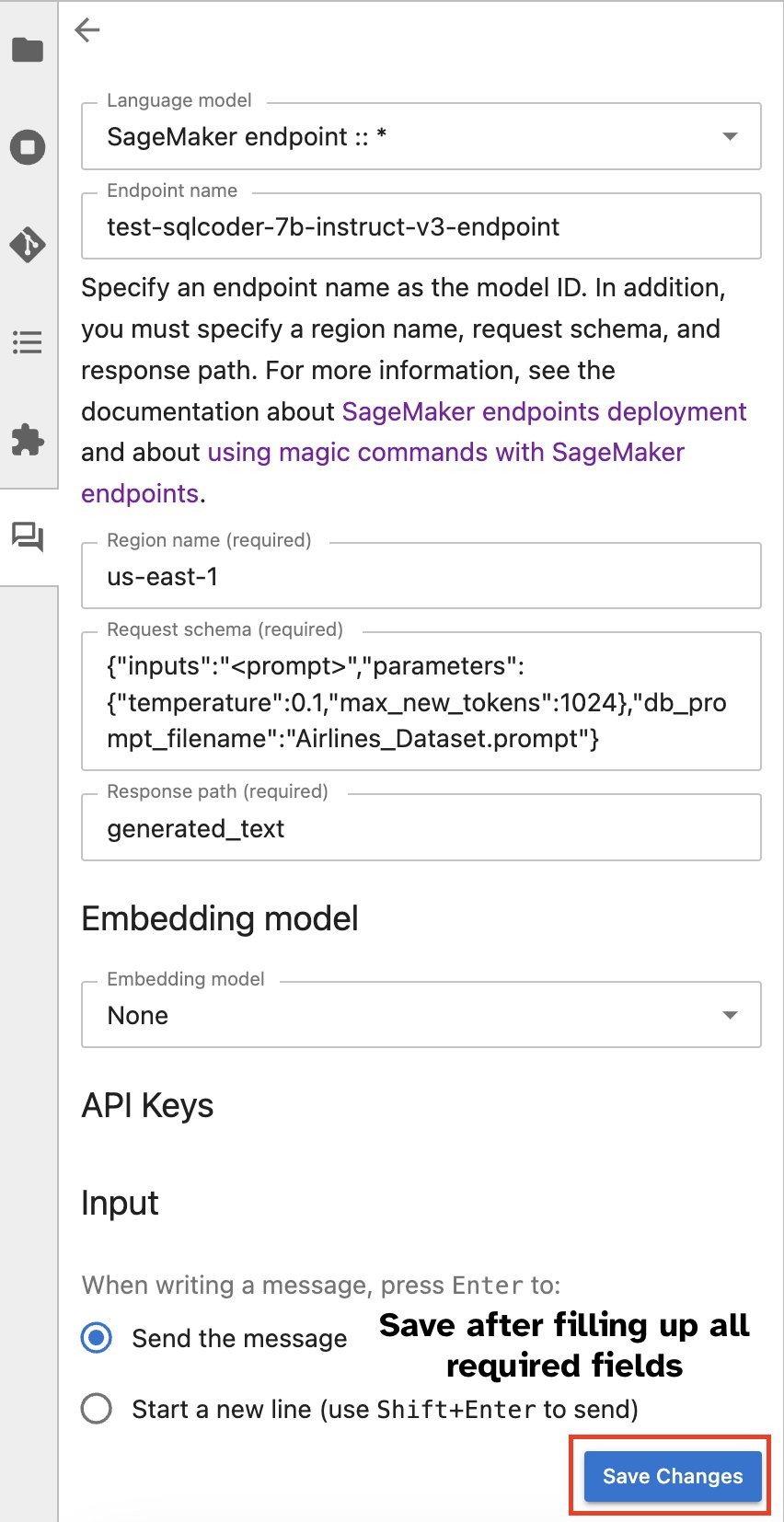 |
zaključek
SageMaker Studio zdaj poenostavlja in racionalizira potek dela podatkovnega znanstvenika z integracijo podpore SQL v prenosnike JupyterLab. To podatkovnim znanstvenikom omogoča, da se osredotočijo na svoje naloge, ne da bi morali upravljati več orodij. Poleg tega nova vgrajena integracija SQL v SageMaker Studio omogoča podatkovnim osebam, da brez truda ustvarijo poizvedbe SQL z uporabo besedila v naravnem jeziku kot vnosom, s čimer pospešijo njihov potek dela.
Svetujemo vam, da raziščete te funkcije v SageMaker Studio. Za več informacij glejte Pripravite podatke s SQL v Studiu.
Dodatek
Omogočite brskalnik SQL in celico SQL beležnice v okoljih po meri
Če ne uporabljate slike distribucije SageMaker ali slik distribucije 1.5 ali starejše, zaženite naslednje ukaze, da omogočite funkcijo brskanja SQL v vašem okolju JupyterLab:
Premaknite gradnik brskalnika SQL
Pripomočki JupyterLab omogočajo premestitev. Odvisno od vaših želja lahko premaknete pripomočke na obe strani podokna pripomočkov JupyterLab. Če želite, lahko premaknete smer gradnika SQL na nasprotno stran (od desne proti levi) stranske vrstice s preprostim desnim klikom na ikono gradnika in izbiro Preklopite stran stranske vrstice.
 |
 |
O avtorjih
 Pranav Murthy je specialist za rešitve AI/ML pri AWS. Osredotoča se na pomoč strankam pri gradnji, usposabljanju, uvajanju in selitvi delovnih obremenitev strojnega učenja (ML) v SageMaker. Pred tem je delal v industriji polprevodnikov in razvijal modele velikega računalniškega vida (CV) in obdelave naravnega jezika (NLP) za izboljšanje polprevodniških procesov z uporabo najsodobnejših tehnik ML. V prostem času rad igra šah in potuje. Pranav najdete na LinkedIn.
Pranav Murthy je specialist za rešitve AI/ML pri AWS. Osredotoča se na pomoč strankam pri gradnji, usposabljanju, uvajanju in selitvi delovnih obremenitev strojnega učenja (ML) v SageMaker. Pred tem je delal v industriji polprevodnikov in razvijal modele velikega računalniškega vida (CV) in obdelave naravnega jezika (NLP) za izboljšanje polprevodniških procesov z uporabo najsodobnejših tehnik ML. V prostem času rad igra šah in potuje. Pranav najdete na LinkedIn.
 Varun Šah je programski inženir, ki dela na Amazon SageMaker Studio pri Amazon Web Services. Osredotočen je na gradnjo interaktivnih rešitev ML, ki poenostavljajo obdelavo in pripravo podatkov. V prostem času Varun uživa v dejavnostih na prostem, vključno s pohodništvom in smučanjem, in je vedno pripravljen na odkrivanje novih, razburljivih krajev.
Varun Šah je programski inženir, ki dela na Amazon SageMaker Studio pri Amazon Web Services. Osredotočen je na gradnjo interaktivnih rešitev ML, ki poenostavljajo obdelavo in pripravo podatkov. V prostem času Varun uživa v dejavnostih na prostem, vključno s pohodništvom in smučanjem, in je vedno pripravljen na odkrivanje novih, razburljivih krajev.
 Sumedha Swamy je glavni produktni vodja pri Amazon Web Services, kjer vodi ekipo SageMaker Studio pri njeni misiji razvoja IDE po izbiri za podatkovno znanost in strojno učenje. Zadnjih 15 let je posvetil gradnji izdelkov za potrošnike in podjetja, ki temeljijo na strojnem učenju.
Sumedha Swamy je glavni produktni vodja pri Amazon Web Services, kjer vodi ekipo SageMaker Studio pri njeni misiji razvoja IDE po izbiri za podatkovno znanost in strojno učenje. Zadnjih 15 let je posvetil gradnji izdelkov za potrošnike in podjetja, ki temeljijo na strojnem učenju.
 Bosco Albuquerque je starejši arhitekt partnerskih rešitev pri AWS in ima več kot 20 let izkušenj pri delu z bazami podatkov in analitičnimi izdelki ponudnikov poslovnih baz podatkov in ponudnikov oblakov. Tehnološkim podjetjem je pomagal oblikovati in uvesti rešitve in izdelke za analizo podatkov.
Bosco Albuquerque je starejši arhitekt partnerskih rešitev pri AWS in ima več kot 20 let izkušenj pri delu z bazami podatkov in analitičnimi izdelki ponudnikov poslovnih baz podatkov in ponudnikov oblakov. Tehnološkim podjetjem je pomagal oblikovati in uvesti rešitve in izdelke za analizo podatkov.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

