Ta objava je napisana skupaj z Andriesom Engelbrechtom in Scottom Tealom iz Snowflake.
Podjetja se nenehno razvijajo in vodje podatkov se vsak dan soočajo z izzivi, da izpolnijo nove zahteve. Za mnoga podjetja in velike organizacije ni izvedljivo imeti enega procesorskega mehanizma ali orodja za obravnavo različnih poslovnih zahtev. Zavedajo se, da pristop "ena velikost za vse" ne deluje več, in priznavajo vrednost sprejemanja razširljivih, prilagodljivih orodij in odprtih podatkovnih formatov za podporo interoperabilnosti v sodobni podatkovni arhitekturi za pospešitev zagotavljanja novih rešitev.
Stranke uporabljajo AWS in Snowflake za razvoj namensko zgrajenih podatkovnih arhitektur, ki zagotavljajo zmogljivost, potrebno za primere uporabe sodobne analitike in umetne inteligence (AI). Implementacija teh rešitev zahteva izmenjavo podatkov med namensko zgrajenimi shrambami podatkov. Zato Snowflake in AWS zagotavljata izboljšano podporo za Apache Iceberg, da omogočita in olajšata interoperabilnost podatkov med podatkovnimi storitvami.
Apache Iceberg je odprtokodni format tabele, ki zagotavlja zanesljivost, preprostost in visoko zmogljivost za velike nabore podatkov s transakcijsko celovitostjo med različnimi procesorji. V tej objavi razpravljamo o naslednjem:
- Prednosti tabel Iceberg za podatkovna jezera
- Dva arhitekturna vzorca za skupno rabo tabel Iceberg med AWS in Snowflake:
- Upravljajte svoje mize Iceberg z AWS lepilo Katalog podatkov
- Upravljajte svoje mize Iceberg s Snowflake
- Postopek pretvorbe obstoječih tabel podatkovnih jezer v tabele Iceberg brez kopiranja podatkov
Zdaj, ko dobro razumete teme, se poglobimo v vsako od njih podrobno.
Prednosti Apache Iceberg
Apache Iceberg je porazdeljen format podatkovne tabele, ki ga vodi skupnost in ima licenco Apache 2.0, 100-odstotno odprtokodni format, ki pomaga poenostaviti obdelavo podatkov v velikih nizih podatkov, shranjenih v podatkovnih jezerih. Podatkovni inženirji uporabljajo Apache Iceberg, ker je hiter, učinkovit in zanesljiv v katerem koli obsegu ter vodi evidenco o tem, kako se nabori podatkov spreminjajo skozi čas. Apache Iceberg ponuja integracije s priljubljenimi ogrodji za obdelavo podatkov, kot so Apache Spark, Apache Flink, Apache Hive, Presto itd.
Tabele Iceberg vzdržujejo metapodatke za abstrahiranje velikih zbirk datotek, ki zagotavljajo funkcije upravljanja podatkov, vključno s potovanjem skozi čas, povrnitvijo nazaj, zgoščanjem podatkov in popolnim razvojem sheme, kar zmanjšuje stroške upravljanja. Prvotno razvit pri Netflixu, preden je bil odprtokoden za Apache Software Foundation, je bil Apache Iceberg prazna zasnova za reševanje pogostih izzivov podatkovnega jezera, kot je uporabniška izkušnja, zanesljivost in zmogljivost, zdaj pa ga podpira močna skupnost razvijalcev, ki se osredotočajo na nenehno izboljševanje in dodajanje novih funkcij v projekt, ki služijo resničnim potrebam uporabnikov in jim nudijo izbirne možnosti.
Transakcijska podatkovna jezera, zgrajena na AWS in Snowflake
Snowflake ponuja različne integracije za mize Iceberg z več možnostmi shranjevanja, vključno z Amazon S3in več možnosti kataloga, vključno z Katalog podatkov o lepilu AWS in Snowflake. AWS zagotavlja integracije za različne storitve AWS tudi s tabelami Iceberg, vključno s katalogom podatkov AWS Glue Data Catalog za sledenje metapodatkov tabel. Združevanje Snowflake in AWS vam daje več možnosti za izgradnjo transakcijskega podatkovnega jezera za analitične in druge primere uporabe, kot sta deljenje podatkov in sodelovanje. Z dodajanjem metapodatkovne plasti v podatkovna jezera dobite boljšo uporabniško izkušnjo, poenostavljeno upravljanje ter izboljšano zmogljivost in zanesljivost na zelo velikih nizih podatkov.
Upravljajte svojo mizo Iceberg z AWS Glue
AWS Glue lahko uporabite za vnos, katalogizacijo, transformacijo in upravljanje podatkov Preprosta storitev shranjevanja Amazon (Amazon S3). AWS Glue je storitev za integracijo podatkov brez strežnika, ki vam omogoča vizualno ustvarjanje, izvajanje in spremljanje cevovodov za ekstrakcijo, transformacijo in nalaganje (ETL) za nalaganje podatkov v vaša podatkovna jezera v formatu Iceberg. Z AWS Glue lahko odkrijete in se povežete z več kot 70 različnimi viri podatkov ter upravljate svoje podatke v centraliziranem katalogu podatkov. Snowflake se integrira s katalogom podatkov AWS Glue Data Catalog za dostop do kataloga tabele Iceberg in datotek na Amazon S3 za analitične poizvedbe. To močno izboljša zmogljivost in stroške računanja v primerjavi z zunanje mize na Snowflake, ker dodatni metapodatki izboljšajo obrezovanje v načrtih poizvedbe.
To isto integracijo lahko uporabite za izkoriščanje možnosti skupne rabe podatkov in sodelovanja v Snowflake. To je lahko zelo zmogljivo, če imate podatke v Amazon S3 in morate omogočiti skupno rabo podatkov Snowflake z drugimi poslovnimi enotami, partnerji, dobavitelji ali strankami.
Naslednji diagram arhitekture ponuja pregled tega vzorca na visoki ravni.
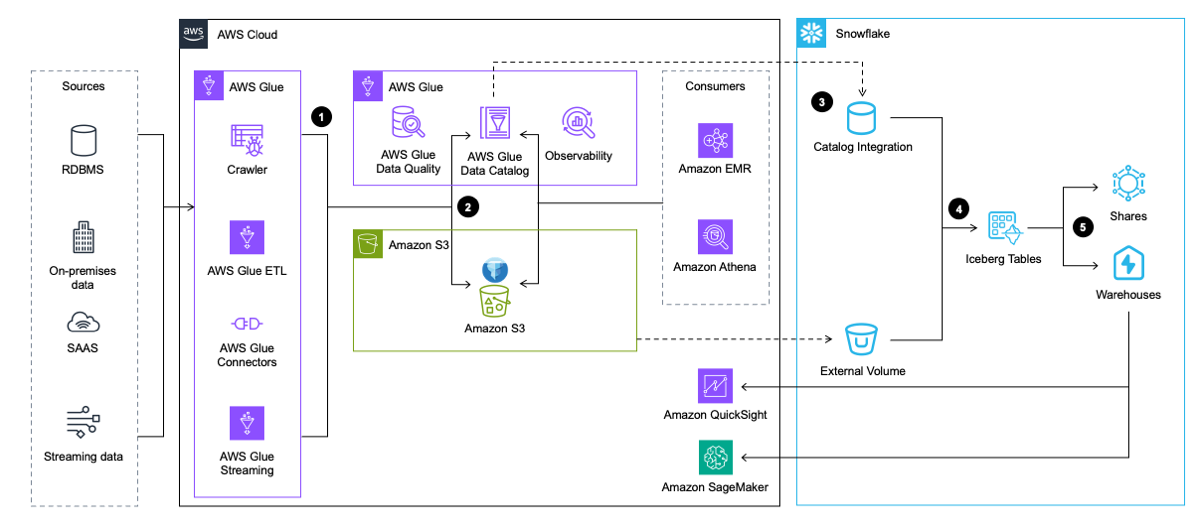
Potek dela vključuje naslednje korake:
- AWS Glue ekstrahira podatke iz aplikacij, baz podatkov in pretočnih virov. AWS Glue ga nato preoblikuje in naloži v podatkovno jezero v Amazon S3 v formatu tabele Iceberg, medtem ko vstavlja in posodablja metapodatke o tabeli Iceberg v katalogu podatkov AWS Glue.
- Pajek AWS Glue ustvari in posodobi metapodatke tabele Iceberg in jih shrani v katalog podatkov AWS Glue za obstoječe tabele Iceberg v podatkovnem jezeru S3.
- Snowflake se integrira s katalogom podatkov AWS Glue Data Catalog za pridobitev lokacije posnetka.
- V primeru poizvedbe Snowflake uporabi lokacijo posnetka iz kataloga podatkov AWS Glue Data Catalog za branje podatkov tabele Iceberg v Amazon S3.
- Snowflake lahko poizveduje po formatih tabel Iceberg in Snowflake. Ti lahko delite podatke za sodelovanje z enim ali več računi v isti regiji Snowflake. Podatke v Snowflake lahko uporabite tudi za vizualizacija uporabo Amazon QuickSight, ali ga uporabite za namene strojnega učenja (ML) in umetne inteligence (AI). z Amazon SageMaker.
Upravljajte svojo mizo Iceberg s Snowflake
Drugi vzorec prav tako zagotavlja interoperabilnost med AWS in Snowflake, vendar izvaja cevovode podatkovnega inženiringa za zaužitje in transformacijo v Snowflake. V tem vzorcu podatke v tabele Iceberg naloži Snowflake prek integracij s storitvami AWS, kot je AWS Glue, ali prek drugih virov, kot je Snowpipe. Snowflake nato zapiše podatke neposredno v Amazon S3 v formatu Iceberg za nadaljnji dostop s Snowflake in različnimi storitvami AWS, Snowflake pa upravlja katalog Iceberg, ki sledi lokacijam posnetkov v tabelah za dostop storitev AWS.
Tako kot prejšnji vzorec lahko uporabite tabele Iceberg, ki jih upravlja Snowflake, s skupno rabo podatkov Snowflake, lahko pa uporabite tudi S3 za skupno rabo naborov podatkov v primerih, ko ena stran nima dostopa do Snowflake.
Naslednji diagram arhitekture ponuja pregled tega vzorca s tabelami Iceberg, ki jih upravlja Snowflake.
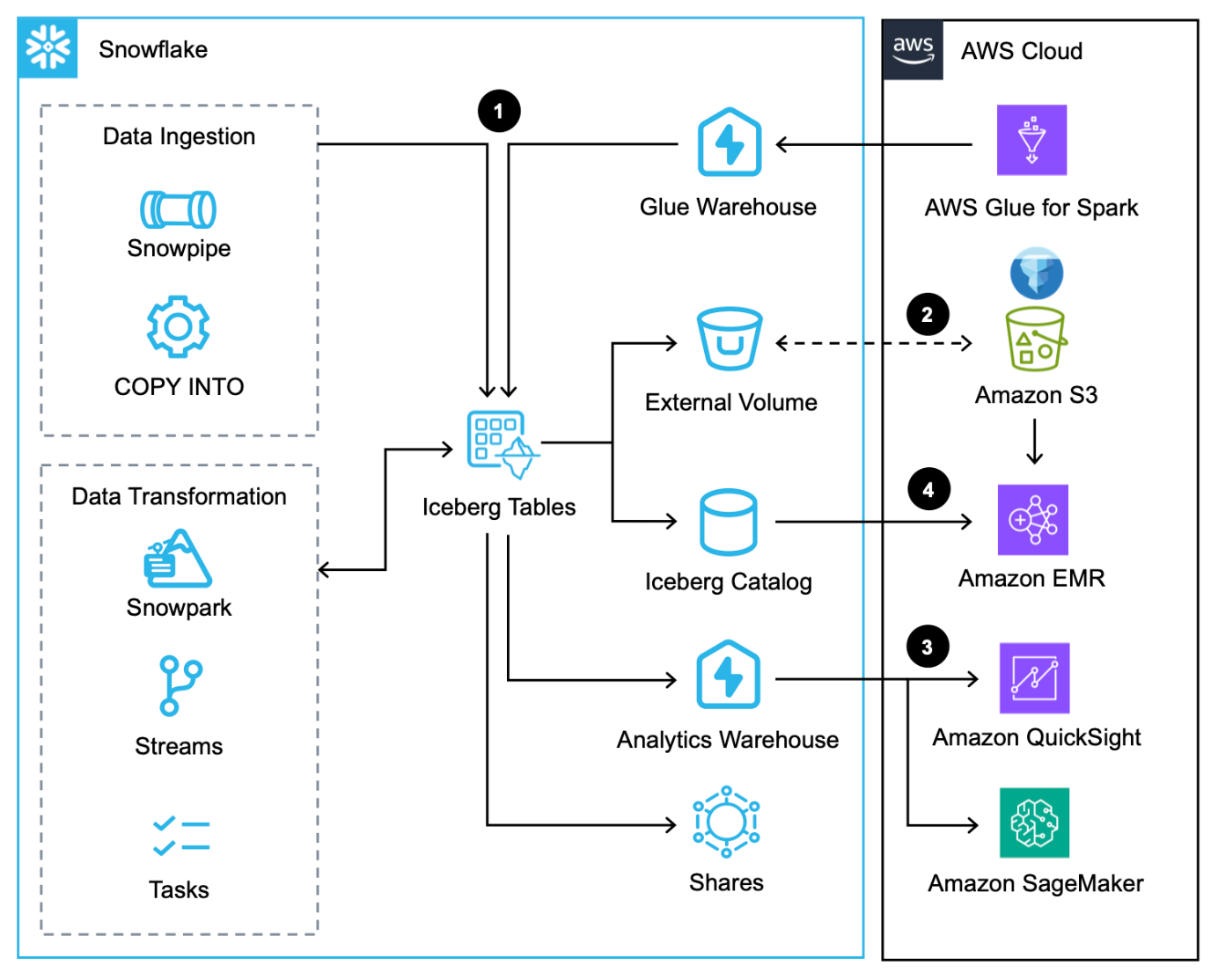
Ta potek dela je sestavljen iz naslednjih korakov:
- Poleg nalaganja podatkov prek ukaz COPY, Snežna cevin izvorni priključek Snowflake za AWS Glue, lahko podatke integrirate prek Snowflake Skupna raba podatkov.
- Snowflake piše tabele Iceberg v Amazon S3 in samodejno posodablja metapodatke z vsako transakcijo.
- Snowflake poizveduje po tabelah Iceberg v Amazonu S3 za analitične in delovne obremenitve ML z uporabo storitev, kot sta QuickSight in SageMaker.
- Storitve Apache Spark na AWS lahko dostop do lokacij posnetkov iz Snežinkee prek SDK-ja Snowflake Iceberg Catalog in neposredno skenirajte datoteke tabele Iceberg v Amazon S3.
Primerjava rešitev
Ta dva vzorca poudarjata možnosti, ki so danes na voljo podatkovnim osebam, da čim bolj povečajo interoperabilnost podatkov med Snowflake in AWS z uporabo Apache Iceberg. Toda kateri vzorec je idealen za vaš primer uporabe? Če že uporabljate AWS Glue Data Catalog in potrebujete samo Snowflake za bralne poizvedbe, lahko prvi vzorec integrira Snowflake z AWS Glue in Amazon S3 za poizvedovanje po tabelah Iceberg. Če še ne uporabljate AWS Glue Data Catalog in potrebujete Snowflake za branje in pisanje, potem je drugi vzorec verjetno dobra rešitev, ki omogoča shranjevanje in dostop do podatkov iz AWS.
Glede na to, da bosta branje in pisanje verjetno delovala na podlagi posamezne tabele in ne celotne podatkovne arhitekture, je priporočljivo uporabiti kombinacijo obeh vzorcev.
Preselite obstoječa podatkovna jezera v transakcijsko podatkovno jezero z uporabo Apache Iceberg
Obstoječe tabele podatkovnega jezera, ki temeljijo na Parquet, ORC in Avro, na Amazon S3 lahko pretvorite v format Iceberg, da izkoristite prednosti celovitosti transakcij in hkrati izboljšate zmogljivost in uporabniško izkušnjo. Obstaja več možnosti selitve tabele Iceberg (PREGLED, MIGRACIJAin DODAJ DATOTEKE) za selitev obstoječih tabel podatkovnega jezera na mestu v format Iceberg, kar je bolje kot prepisovanje vseh osnovnih podatkovnih datotek – drago in dolgotrajno prizadevanje z velikimi nabori podatkov. V tem razdelku se osredotočamo na ADD_FILES, ker je uporaben za selitve po meri.
Za možnosti ADD_FILES lahko uporabite AWS Glue za ustvarjanje metapodatkov in statističnih podatkov Iceberg za obstoječo tabelo podatkovnega jezera ter ustvarite nove tabele Iceberg v katalogu podatkov AWS Glue za prihodnjo uporabo, ne da bi morali prepisati temeljne podatke. Za navodila o ustvarjanju metapodatkov in statistike Iceberg z uporabo AWS Glue glejte Preselite obstoječe podatkovno jezero v transakcijsko podatkovno jezero z uporabo Apache Iceberg or Pretvorite obstoječe tabele podatkovnega jezera Amazon S3 v tabele Snowflake Unmanaged Iceberg z uporabo AWS Glue.
Ta možnost zahteva, da med pretvorbo datotek v tabele Iceberg začasno ustavite podatkovne cevovode, kar je preprost postopek v AWS Glue, ker je treba cilj le spremeniti v tabelo Iceberg.
zaključek
V tej objavi ste videli dva arhitekturna vzorca za implementacijo Apache Iceberg v podatkovno jezero za boljšo interoperabilnost med AWS in Snowflake. Zagotovili smo tudi navodila za selitev obstoječih tabel podatkovnega jezera v format Iceberg.
Prijavite se na Dan razvijalcev AWS 10. aprila da se udeležite ne le Apache Iceberg, ampak tudi cevovodov za pretakanje podatkov Amazon Data Firehose in Snowpipe Streamingin generativne aplikacije AI z Streamlit v Snowflake in Amazon Bedrock.
O avtorjih
 Andries Engelbrecht je glavni partner rešitev arhitekt pri Snowflake in sodeluje s strateškimi partnerji. Aktivno sodeluje s strateškimi partnerji, kot je AWS, ki podpirajo integracije izdelkov in storitev ter razvoj skupnih rešitev s partnerji. Andries ima več kot 20 let izkušenj na področju podatkov in analitike.
Andries Engelbrecht je glavni partner rešitev arhitekt pri Snowflake in sodeluje s strateškimi partnerji. Aktivno sodeluje s strateškimi partnerji, kot je AWS, ki podpirajo integracije izdelkov in storitev ter razvoj skupnih rešitev s partnerji. Andries ima več kot 20 let izkušenj na področju podatkov in analitike.
 Deenbandhu Prasad je višji strokovnjak za analitiko pri AWS, specializiran za storitve velikih podatkov. Strastno želi pomagati strankam zgraditi sodobne podatkovne arhitekture v oblaku AWS. Strankam vseh velikosti je pomagal uvesti rešitve za upravljanje podatkov, skladišče podatkov in podatkovno jezero.
Deenbandhu Prasad je višji strokovnjak za analitiko pri AWS, specializiran za storitve velikih podatkov. Strastno želi pomagati strankam zgraditi sodobne podatkovne arhitekture v oblaku AWS. Strankam vseh velikosti je pomagal uvesti rešitve za upravljanje podatkov, skladišče podatkov in podatkovno jezero.
 Brian Dolan se je pridružil Amazonu kot vodja vojaških odnosov leta 2012 po svoji prvi karieri mornariškega letalca. Leta 2014 se je Brian pridružil Amazon Web Services, kjer je pomagal kanadskim strankam od startupov do podjetij pri raziskovanju oblaka AWS. Nazadnje je bil Brian član skupine za nerelacijski poslovni razvoj kot strokovnjak za trg za Amazon DynamoDB in Amazon Keyspaces, nato pa se je leta 2022 pridružil organizaciji Analytics Worldwide Specialist Organisation kot strokovnjak za trg za AWS Glue.
Brian Dolan se je pridružil Amazonu kot vodja vojaških odnosov leta 2012 po svoji prvi karieri mornariškega letalca. Leta 2014 se je Brian pridružil Amazon Web Services, kjer je pomagal kanadskim strankam od startupov do podjetij pri raziskovanju oblaka AWS. Nazadnje je bil Brian član skupine za nerelacijski poslovni razvoj kot strokovnjak za trg za Amazon DynamoDB in Amazon Keyspaces, nato pa se je leta 2022 pridružil organizaciji Analytics Worldwide Specialist Organisation kot strokovnjak za trg za AWS Glue.
 Nidhi Gupta je starejši arhitekt partnerskih rešitev pri AWS. Dneve preživlja ob delu s strankami in partnerji ter reševanju arhitekturnih izzivov. Navdušena je nad integracijo in orkestracijo podatkov, brezstrežniško obdelavo in obdelavo velikih podatkov ter strojnim učenjem. Nidhi ima bogate izkušnje z vodenjem načrtovanja arhitekture in izdaje proizvodnje ter uvajanja podatkovnih delovnih obremenitev.
Nidhi Gupta je starejši arhitekt partnerskih rešitev pri AWS. Dneve preživlja ob delu s strankami in partnerji ter reševanju arhitekturnih izzivov. Navdušena je nad integracijo in orkestracijo podatkov, brezstrežniško obdelavo in obdelavo velikih podatkov ter strojnim učenjem. Nidhi ima bogate izkušnje z vodenjem načrtovanja arhitekture in izdaje proizvodnje ter uvajanja podatkovnih delovnih obremenitev.
 Scott Teal je vodja trženja izdelkov pri Snowflake in se osredotoča na podatkovna jezera, shranjevanje in upravljanje.
Scott Teal je vodja trženja izdelkov pri Snowflake in se osredotoča na podatkovna jezera, shranjevanje in upravljanje.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-your-data-lake-with-amazon-s3-aws-glue-and-snowflake/

