V razvijajočem se okolju proizvodnje je očitna transformativna moč umetne inteligence in strojnega učenja (ML), ki poganja digitalno revolucijo, ki poenostavlja delovanje in povečuje produktivnost. Vendar pa ta napredek predstavlja edinstvene izzive za podjetja, ki krmarijo po rešitvah, ki temeljijo na podatkih. Industrijski obrati se spopadajo z ogromnimi količinami nestrukturiranih podatkov, ki izvirajo iz senzorjev, telemetričnih sistemov in opreme, razpršene po proizvodnih linijah. Podatki v realnem času so ključnega pomena za aplikacije, kot sta predvideno vzdrževanje in odkrivanje nepravilnosti, vendar razvoj modelov ML po meri za vsak primer industrijske uporabe s takšnimi podatki časovnih vrst zahteva precej časa in virov podatkovnih znanstvenikov, kar ovira široko sprejetje.
Generativna AI z uporabo velikih vnaprej pripravljenih temeljnih modelov (FM), kot je npr Claude lahko hitro ustvari različne vsebine od pogovornega besedila do računalniške kode na podlagi preprostih besedilnih pozivov, znanih kot ničelni poziv. To odpravlja potrebo, da podatkovni znanstveniki ročno razvijajo posebne modele ML za vsak primer uporabe, in tako demokratizira dostop do umetne inteligence, kar koristi celo majhnim proizvajalcem. Delavci povečajo produktivnost z vpogledi, ustvarjenimi z umetno inteligenco, inženirji lahko proaktivno zaznajo anomalije, vodje dobavne verige optimizirajo zaloge, vodstvo tovarne pa sprejema informirane odločitve, ki temeljijo na podatkih.
Kljub temu se samostojni FM-ji soočajo z omejitvami pri ravnanju s kompleksnimi industrijskimi podatki z omejitvami velikosti konteksta (običajno manj kot 200,000 žetonov), kar predstavlja izzive. Če želite to rešiti, lahko uporabite sposobnost FM za ustvarjanje kode kot odgovor na poizvedbe v naravnem jeziku (NLQ). Agenti kot PandasAI pridejo v poštev, zagon te kode na podatkih časovnih vrst visoke ločljivosti in obravnavanje napak z uporabo FM-jev. PandasAI je knjižnica Python, ki pandam, priljubljenemu orodju za analizo in manipulacijo podatkov, dodaja generativne zmogljivosti AI.
Vendar pa lahko zapleteni NLQ-ji, kot je obdelava podatkov časovnih vrst, združevanje na več ravneh in operacije vrtilne ali skupne tabele, povzročijo nedosledno natančnost skripta Python s pozivom za ničelni strel.
Za izboljšanje natančnosti generiranja kode predlagamo dinamično konstruiranje pozive za več posnetkov za NLQ. Večkratni pozivi zagotavljajo dodaten kontekst za FM, tako da mu pokažejo več primerov želenih izhodov za podobne pozive, kar poveča natančnost in doslednost. V tej objavi so pozivi za več posnetkov pridobljeni iz vdelave, ki vsebuje uspešno kodo Python, ki se izvaja na podobni vrsti podatkov (na primer podatki časovnih vrst visoke ločljivosti iz naprav interneta stvari). Dinamično zgrajen poziv za več posnetkov zagotavlja najbolj relevanten kontekst za FM in povečuje zmožnost FM pri naprednem matematičnem izračunu, obdelavi podatkov časovnih vrst in razumevanju akronimov podatkov. Ta izboljšan odziv delavcem v podjetjih in operativnim ekipam olajša delo s podatki, pridobivanje vpogledov, ne da bi zahtevali obsežno znanje podatkovne znanosti.
Poleg analize podatkov časovnih vrst se FM-ji izkažejo za dragocene v različnih industrijskih aplikacijah. Vzdrževalne ekipe ocenjujejo stanje sredstev, zajemajo slike za Amazonsko ponovno vžiganjena podlagi povzetkov funkcionalnosti in analize vzroka anomalije z uporabo inteligentnih iskanj s Povečana generacija pridobivanja (RAG). Za poenostavitev teh delovnih tokov je AWS predstavil Amazon Bedrock, ki vam omogoča gradnjo in povečanje generativnih aplikacij AI z najsodobnejšimi vnaprej usposobljenimi FM-ji, kot je Claude v2. Z Baze znanja za Amazon Bedrock, lahko poenostavite razvojni proces RAG, da zagotovite natančnejšo analizo vzroka anomalije za delavce v obratu. Naša objava predstavlja inteligentnega pomočnika za primere industrijske uporabe, ki ga poganja Amazon Bedrock, obravnava izzive NLQ, ustvarja povzetke delov iz slik in izboljšuje odzive FM za diagnozo opreme s pristopom RAG.
Pregled rešitev
Naslednji diagram prikazuje arhitekturo rešitev.

Potek dela vključuje tri različne primere uporabe:
Primer uporabe 1: NLQ s podatki časovne vrste
Potek dela za NLQ s podatki časovne vrste je sestavljen iz naslednjih korakov:
- Uporabljamo sistem za spremljanje stanja z zmogljivostmi ML za odkrivanje anomalij, kot je npr Amazonov monitor, za spremljanje zdravja industrijske opreme. Amazon Monitron lahko zazna morebitne okvare opreme na podlagi meritev vibracij in temperature opreme.
- Podatke o časovnih serijah zbiramo z obdelavo Amazonov monitor podatkov prek Amazonski kinezi podatkovni tokovi in Amazon Data Firehose, ga pretvorite v tabelarično obliko CSV in shranite v Preprosta storitev shranjevanja Amazon (Amazon S3) vedro.
- Končni uporabnik lahko začne klepetati s svojimi podatki o časovni vrsti v Amazon S3 tako, da aplikaciji Streamlit pošlje poizvedbo v naravnem jeziku.
- Aplikacija Streamlit posreduje uporabniške poizvedbe na Model za vdelavo besedila Amazon Bedrock Titan za vdelavo te poizvedbe in izvede iskanje podobnosti znotraj Storitev Amazon OpenSearch indeks, ki vsebuje prejšnje NLQ in primere kod.
- Po iskanju podobnosti se najboljši podobni primeri, vključno z vprašanji NLQ, podatkovno shemo in kodami Python, vstavijo v poziv po meri.
- PandasAI pošlje ta poziv po meri modelu Amazon Bedrock Claude v2.
- Aplikacija uporablja agenta PandasAI za interakcijo z modelom Amazon Bedrock Claude v2, ustvarjanje kode Python za analizo podatkov Amazon Monitron in odzive NLQ.
- Potem ko model Amazon Bedrock Claude v2 vrne kodo Python, PandasAI zažene poizvedbo Python na podatkih Amazon Monitron, naloženih iz aplikacije, zbere rezultate kode in obravnava morebitne ponovne poskuse za neuspele zagone.
- Aplikacija Streamlit zbira odziv prek PandasAI in uporabnikom zagotavlja rezultate. Če je izhod zadovoljiv, ga lahko uporabnik označi kot uporabnega in shrani NLQ in kodo Python, ki jo je ustvaril Claude, v storitvi OpenSearch.
Primer uporabe 2: Generiranje povzetka nedelujočih delov
Naš primer uporabe generiranja povzetka je sestavljen iz naslednjih korakov:
- Ko uporabnik izve, katero industrijsko sredstvo kaže nepravilno vedenje, lahko naloži slike okvarjenega dela, da ugotovi, ali je s tem delom kaj fizično narobe glede na njegove tehnične specifikacije in stanje delovanja.
- Uporabnik lahko uporablja Amazon Recognition DetectText API za pridobivanje besedilnih podatkov iz teh slik.
- Ekstrahirani besedilni podatki so vključeni v poziv za model Amazon Bedrock Claude v2, kar omogoča modelu, da ustvari 200-besedni povzetek okvarjenega dela. Uporabnik lahko te podatke uporabi za nadaljnji pregled dela.
3. primer uporabe: diagnoza temeljnega vzroka
Naš primer uporabe diagnoze temeljnega vzroka je sestavljen iz naslednjih korakov:
- Uporabnik pridobi podatke podjetja v različnih formatih dokumentov (PDF, TXT in tako naprej), povezane z nedelujočimi sredstvi, in jih naloži v vedro S3.
- Baza znanja teh datotek je ustvarjena v Amazon Bedrock z modelom vdelave besedila Titan in privzeto vektorsko shrambo storitve OpenSearch Service.
- Uporabnik postavlja vprašanja v zvezi z diagnozo temeljnega vzroka za nedelujočo opremo. Odgovori so ustvarjeni prek baze znanja Amazon Bedrock s pristopom RAG.
Predpogoji
Če želite slediti tej objavi, morate izpolnjevati naslednje predpogoje:
Namestite infrastrukturo rešitve
Za nastavitev virov rešitve izvedite naslednje korake:
- Uvedite Oblikovanje oblaka AWS Predloga opensearchsagemaker.yml, ki ustvari zbirko in indeks OpenSearch Service, Amazon SageMaker primerek prenosnega računalnika in vedro S3. Ta sklad AWS CloudFormation lahko poimenujete kot:
genai-sagemaker. - Odprite primerek beležnice SageMaker v JupyterLab. Našli boste naslednje GitHub repo že preneseno v tem primeru: sprostitev-potenciala-generativne-ai-v-industrijskih-operacijah.
- Zaženite zvezek iz naslednjega imenika v tem skladišču: sprostitev-potenciala-generativne-ai-in-industrijskih-operacij/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Ta zvezek bo naložil indeks storitve OpenSearch z uporabo zvezka SageMaker za shranjevanje parov ključ-vrednost iz obstoječih 23 NLQ primerov.
- Naložite dokumente iz podatkovne mape assetpartdoc v repozitoriju GitHub v vedro S3, navedeno v izhodih sklada CloudFormation.

Nato ustvarite bazo znanja za dokumente v Amazon S3.
- Na konzoli Amazon Bedrock izberite Baza znanja v podoknu za krmarjenje.
- Izberite Ustvarite bazo znanja.
- za Ime baze znanja, vnesite ime.
- za Vloga med izvajanjemtako, da izberete Ustvarite in uporabite novo storitveno vlogo.
- za Ime vira podatkov, vnesite ime svojega vira podatkov.
- za S3 URI, vnesite pot S3 vedra, kamor ste naložili dokumente glavnega vzroka.
- Izberite Naslednji.
 Model Titan Embeddings je samodejno izbran.
Model Titan Embeddings je samodejno izbran. - Izberite Hitro ustvarite novo vektorsko trgovino.
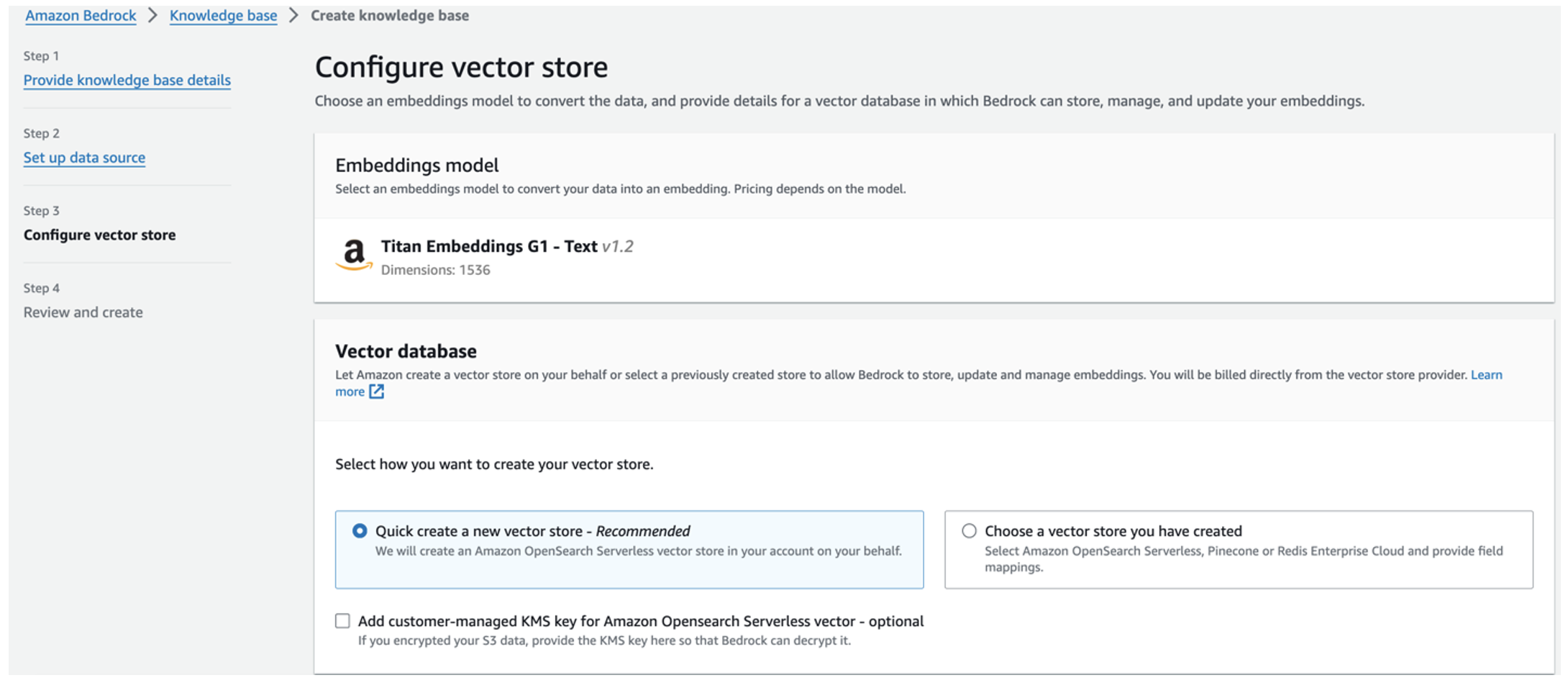
- Preglejte svoje nastavitve in z izbiro ustvarite bazo znanja Ustvarite bazo znanja.
- Ko je baza znanja uspešno ustvarjena, izberite Sinhronizacija za sinhronizacijo vedra S3 z bazo znanja.

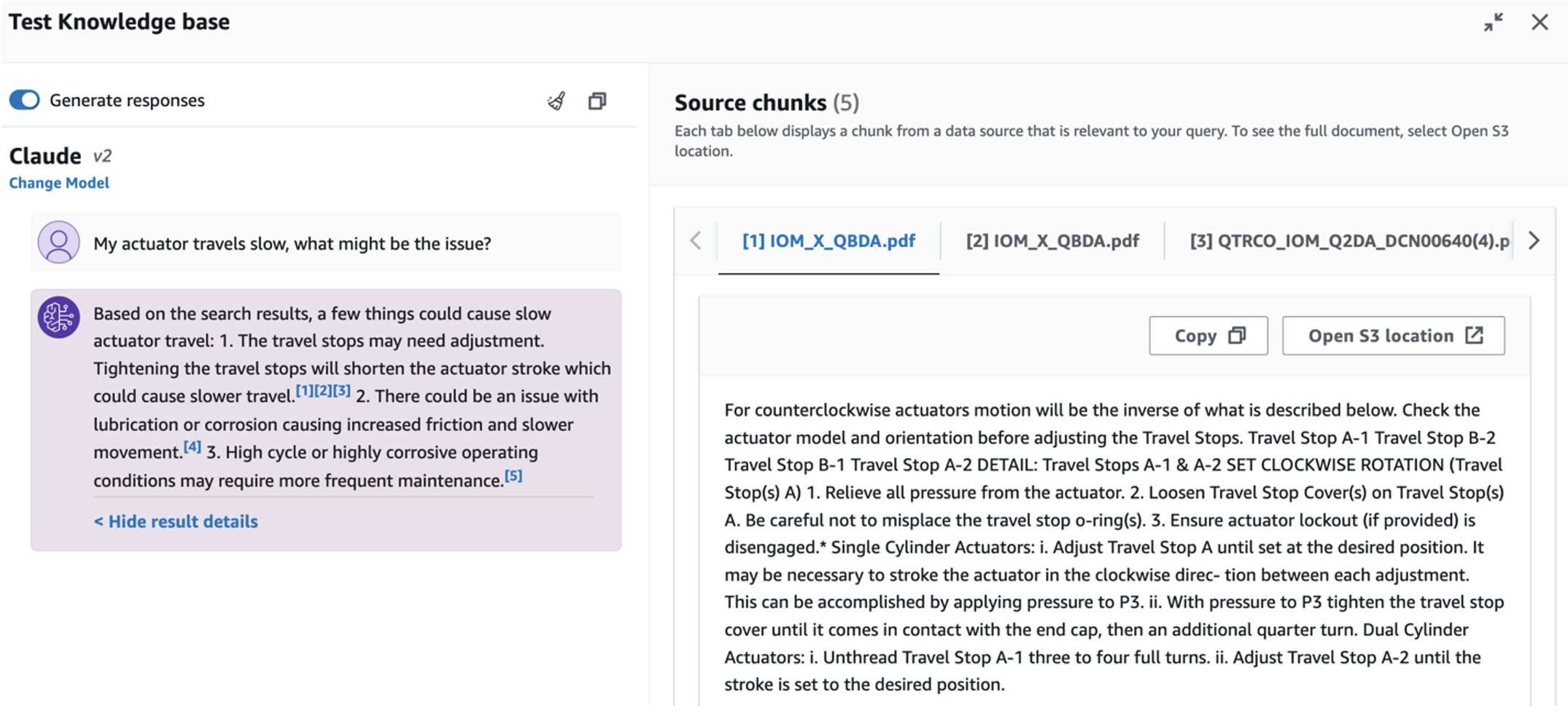
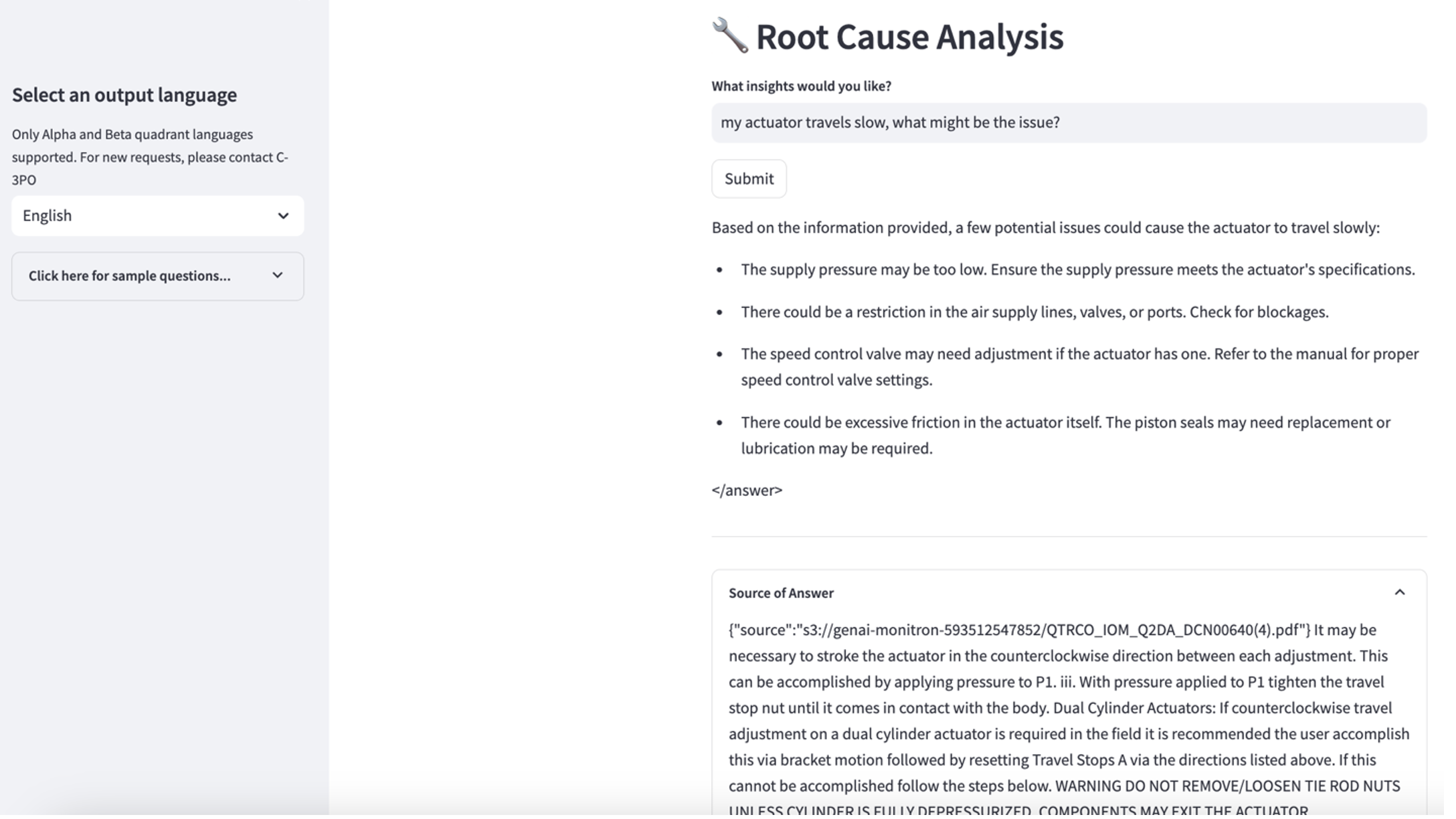
- Ko nastavite bazo znanja, lahko preizkusite pristop RAG za diagnozo temeljnega vzroka tako, da postavite vprašanja, kot je »Moj aktuator potuje počasi, kaj bi lahko bila težava?«
Naslednji korak je uvedba aplikacije z zahtevanimi knjižničnimi paketi v vašem računalniku ali primerku EC2 (Ubuntu Server 22.04 LTS).
- Nastavite svoje poverilnice AWS z AWS CLI na vašem lokalnem računalniku. Za poenostavitev lahko uporabite isto skrbniško vlogo, kot ste jo uporabili za uvedbo sklada CloudFormation. Če uporabljate Amazon EC2, primerku pripnite ustrezno vlogo IAM.
- Clone GitHub repo:
- Spremenite imenik v
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcin tečisetup.shskript v tej mapi za namestitev zahtevanih paketov, vključno z LangChain in PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Zaženite aplikacijo Streamlit z naslednjim ukazom:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Navedite zbirko ARN storitve OpenSearch, ki ste jo ustvarili v Amazon Bedrock v prejšnjem koraku.
Klepetajte s svojim pomočnikom za zdravje sredstev
Ko dokončate uvajanje od konca do konca, lahko do aplikacije dostopate prek lokalnega gostitelja na vratih 8501, ki odpre okno brskalnika s spletnim vmesnikom. Če ste aplikacijo uvedli na primerku EC2, dovoli dostop do vrat 8501 prek vhodnega pravila varnostne skupine. Krmarite lahko do različnih zavihkov za različne primere uporabe.
Raziščite primer uporabe 1
Če želite raziskati prvi primer uporabe, izberite Vpogled v podatke in grafikon. Začnite z nalaganjem podatkov o časovni vrsti. Če nimate obstoječe datoteke s podatki o časovni vrsti, ki bi jo lahko uporabili, lahko naložite naslednje vzorčna datoteka CSV z anonimnimi podatki projekta Amazon Monitron. Če že imate projekt Amazon Monitron, glejte Ustvarite uporabne vpoglede za napovedno upravljanje vzdrževanja z Amazon Monitron in Amazon Kinesis za pretakanje vaših podatkov Amazon Monitron v Amazon S3 in uporabo vaših podatkov s to aplikacijo.
Ko je nalaganje končano, vnesite poizvedbo, da začnete pogovor s svojimi podatki. Leva stranska vrstica ponuja vrsto primerov vprašanj za vaše udobje. Naslednji posnetki zaslona ponazarjajo odziv in kodo Python, ki jo ustvari FM pri vnosu vprašanja, kot je »Povejte mi edinstveno število senzorjev za vsako mesto, prikazano kot Opozorilo oziroma Alarm?« (težko vprašanje) ali »Ali lahko za senzorje, ki prikazujejo signal temperature kot NI zdrav, izračunate časovno trajanje v dnevih za vsak senzor, ki prikazuje signal nenormalne vibracije?« (vprašanje na ravni izziva). Aplikacija bo odgovorila na vaše vprašanje in prikazala tudi skript Python za analizo podatkov, ki ga je izvedla za ustvarjanje takšnih rezultatov.


Če ste z odgovorom zadovoljni, ga lahko označite kot pomoč, shranjevanje NLQ in kode Python, ki jo je ustvaril Claude, v indeks OpenSearch Service.

Raziščite primer uporabe 2
Če želite raziskati drugi primer uporabe, izberite Povzetek posnete slike v aplikaciji Streamlit. Naložite lahko sliko svojega industrijskega sredstva in aplikacija bo na podlagi informacij o sliki ustvarila 200-besedni povzetek njegovih tehničnih specifikacij in stanja delovanja. Naslednji posnetek zaslona prikazuje povzetek, ustvarjen iz slike jermenskega motornega pogona. Za preizkus te funkcije, če vam manjka ustrezna slika, lahko uporabite naslednje primer slike.
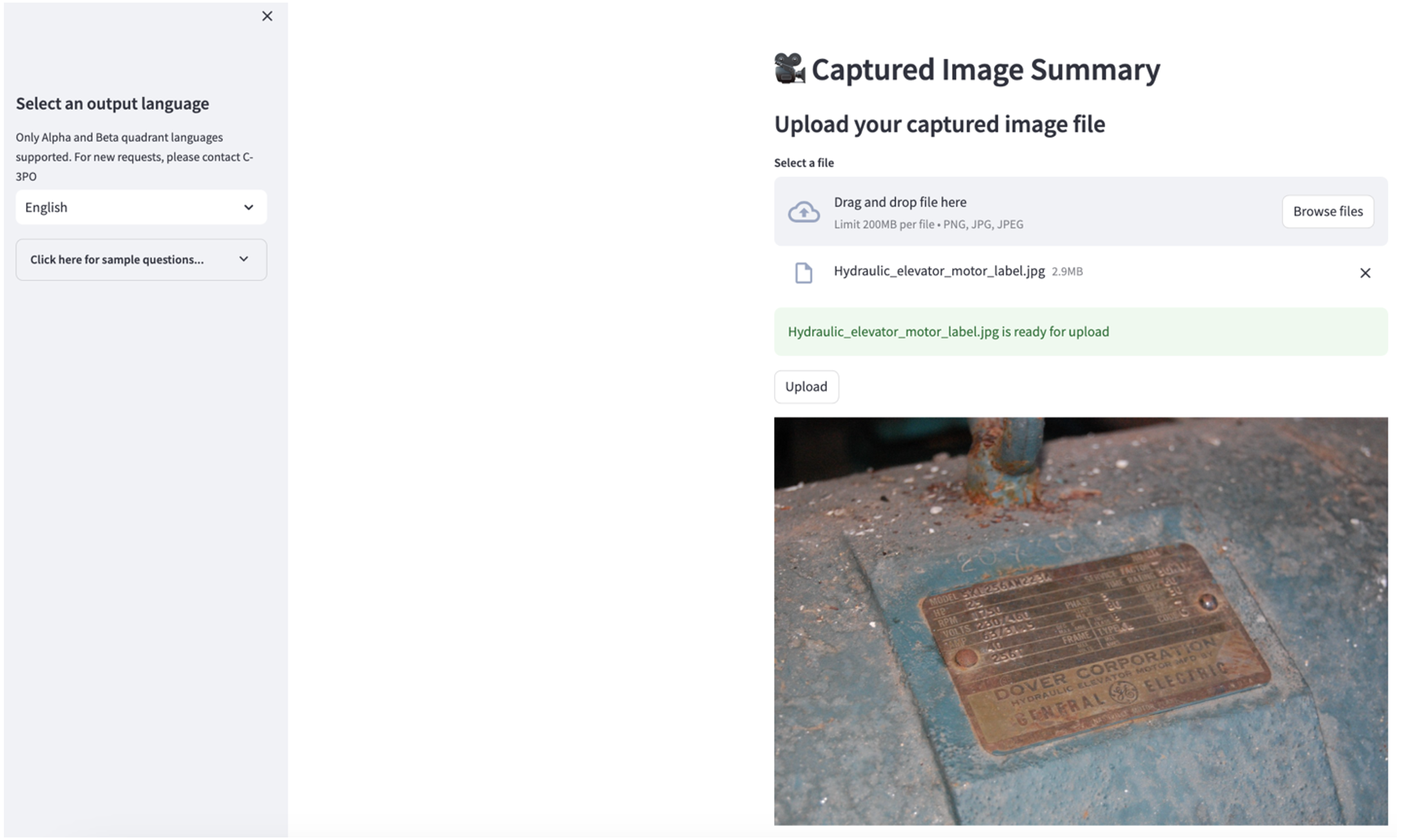
Oznaka motorja hidravličnega dvigala” avtorja Clarence Risher je licenciran pod CC BY-SA 2.0.

Raziščite primer uporabe 3
Če želite raziskati tretji primer uporabe, izberite Diagnoza temeljnega vzroka zavihek. Vnesite poizvedbo v zvezi z vašim pokvarjenim industrijskim sredstvom, na primer »Moj aktuator potuje počasi, kaj bi lahko bila težava?« Kot je prikazano na naslednjem posnetku zaslona, aplikacija dostavi odgovor z izvlečkom izvornega dokumenta, uporabljenega za ustvarjanje odgovora.
Primer uporabe 1: Podrobnosti oblikovanja
V tem razdelku razpravljamo o podrobnostih zasnove delovnega toka aplikacije za prvi primer uporabe.
Hitra gradnja po meri
Uporabnikova poizvedba v naravnem jeziku ima različne zahtevne ravni: enostavno, težko in zahtevno.
Enostavna vprašanja lahko vključujejo naslednje zahteve:
- Izberite edinstvene vrednosti
- Preštejte skupna števila
- Razvrsti vrednosti
Za ta vprašanja lahko PandasAI neposredno komunicira z FM, da ustvari skripte Python za obdelavo.
Težka vprašanja zahtevajo osnovno operacijo združevanja ali analizo časovnih vrst, kot je naslednje:
- Najprej izberite vrednost in hierarhično združite rezultate
- Izvedite statistiko po začetni izbiri zapisa
- Število časovnih žigov (na primer najmanj in največ)
Pri težkih vprašanjih FM-jem pri zagotavljanju natančnih odgovorov pomaga predloga za poziv s podrobnimi navodili po korakih.
Vprašanja na ravni izziva zahtevajo napredne matematične izračune in obdelavo časovnih vrst, kot je naslednje:
- Izračunajte trajanje anomalije za vsak senzor
- Mesečno izračunajte senzorje anomalij za lokacijo
- Primerjajte odčitke senzorjev pri normalnem delovanju in neobičajnih pogojih
Za ta vprašanja lahko uporabite več posnetkov v pozivu po meri, da povečate natančnost odgovora. Takšni večposnetki prikazujejo primere napredne obdelave časovnih vrst in matematičnih izračunov ter bodo zagotovili kontekst za FM, da izvede ustrezne sklepe o podobni analizi. Dinamično vstavljanje najbolj ustreznih primerov iz banke vprašanj NLQ v poziv je lahko izziv. Ena rešitev je izdelava vdelav iz obstoječih vzorcev vprašanj NLQ in shranjevanje teh vdelav v vektorsko shrambo, kot je OpenSearch Service. Ko je vprašanje poslano v aplikacijo Streamlit, bo vprašanje vektorizirano z BedrockEmbeddings. Prvih N najbolj ustreznih vdelav za to vprašanje je pridobljenih z uporabo opensearch_vector_search.similarity_search in vstavljen v predlogo poziva kot poziv za več posnetkov.
Naslednji diagram ponazarja ta potek dela.
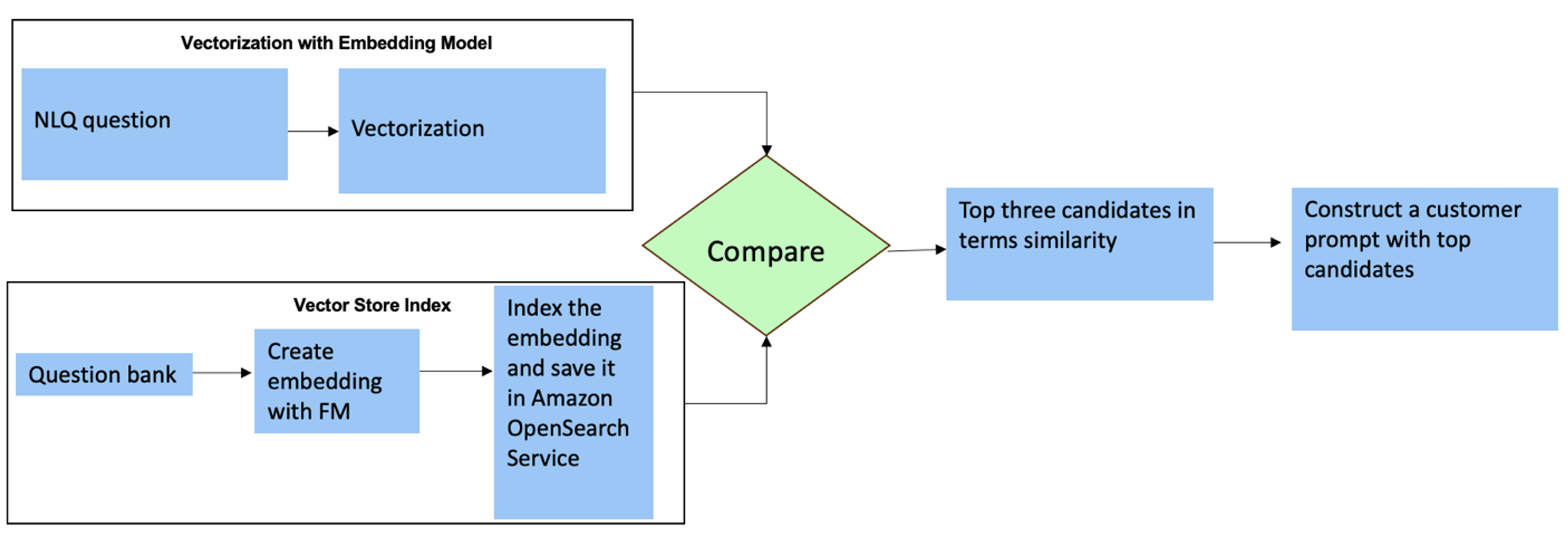
Vdelana plast je izdelana s tremi ključnimi orodji:
- Model vdelav – Uporabljamo vdelave Amazon Titan, ki so na voljo prek Amazon Bedrock (amazon.titan-embed-text-v1) za ustvarjanje numeričnih predstavitev besedilnih dokumentov.
- Vektorska trgovina – Za našo vektorsko trgovino uporabljamo storitev OpenSearch prek ogrodja LangChain, s čimer poenostavimo shranjevanje vdelav, ustvarjenih iz primerov NLQ v tem zvezku.
- Kazalo – Indeks storitve OpenSearch Service igra ključno vlogo pri primerjavi vdelanih vnosov z vdelanimi dokumenti in omogoča lažje iskanje ustreznih dokumentov. Ker so bile vzorčne kode Python shranjene kot datoteka JSON, so bile v storitvi OpenSearch indeksirane kot vektorji prek OpenSearchVevtorSearch.fromtexts Klic API.
Nenehno zbiranje človeško revidiranih primerov prek Streamlita
Na začetku razvoja aplikacije smo začeli s samo 23 shranjenimi primeri v indeksu OpenSearch Service kot vdelave. Ko aplikacija deluje na terenu, uporabniki začnejo vnašati svoje NLQ prek aplikacije. Vendar zaradi omejenih primerov, ki so na voljo v predlogi, nekateri NLQ morda ne bodo našli podobnih pozivov. Če želite nenehno obogatiti te vdelave in ponuditi ustreznejše uporabniške pozive, lahko uporabite aplikacijo Streamlit za zbiranje primerov, pregledanih s strani ljudi.
V aplikaciji je temu namenu naslednja funkcija. Ko se končnim uporabnikom zdi izhod koristen in izberejo pomoč, aplikacija sledi tem korakom:
- Za zbiranje skripta Python uporabite metodo povratnega klica PandasAI.
- Preoblikujte skript Python, vhodno vprašanje in metapodatke CSV v niz.
- Preverite, ali ta primer NLQ že obstaja v trenutnem indeksu storitve OpenSearch z uporabo opensearch_vector_search.similarity_search_with_score.
- Če ni podobnega primera, se ta NLQ doda indeksu storitve OpenSearch z uporabo opensearch_vector_search.add_texts.
V primeru, da uporabnik izbere Ni v pomoč, se ne ukrepa. Ta ponavljajoči se proces zagotavlja, da se sistem nenehno izboljšuje z vključevanjem primerov, ki jih prispevajo uporabniki.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Z vključitvijo človeškega nadzora se količina primerov v storitvi OpenSearch, ki so na voljo za takojšnjo vdelavo, povečuje z uporabo aplikacije. Rezultat tega razširjenega vdelanega nabora podatkov je izboljšana natančnost iskanja skozi čas. Natančneje, pri zahtevnih NLQ natančnost odziva FM doseže približno 90 % pri dinamičnem vstavljanju podobnih primerov za izdelavo pozivov po meri za vsako vprašanje NLQ. To predstavlja opazno 28-odstotno povečanje v primerjavi s scenariji brez pozivov za več posnetkov.
Primer uporabe 2: Podrobnosti oblikovanja
V aplikaciji Streamlit Povzetek posnete slike lahko neposredno naložite slikovno datoteko. To sproži API Amazon Rekognition (zaznaj_besedilo API), ekstrahiranje besedila iz slikovne nalepke s podrobnimi specifikacijami stroja. Nato se izvlečeni besedilni podatki pošljejo modelu Amazon Bedrock Claude kot kontekst poziva, rezultat pa je povzetek v 200 besedah.
Z vidika uporabniške izkušnje je omogočanje funkcije pretakanja za nalogo povzemanja besedila bistvenega pomena, saj uporabnikom omogoča branje povzetka, ki ga ustvari FM, v manjših delih, namesto da čakajo na celoten rezultat. Amazon Bedrock omogoča pretakanje prek svojega API-ja (bedrock_runtime.invoke_model_with_response_stream).
Primer uporabe 3: Podrobnosti oblikovanja
V tem scenariju smo razvili aplikacijo chatbot, ki se osredotoča na analizo temeljnih vzrokov in uporablja pristop RAG. Ta klepetalni robot črpa iz več dokumentov, povezanih z nosilno opremo, da olajša analizo temeljnih vzrokov. Ta klepetalni robot za analizo temeljnih vzrokov, ki temelji na RAG, uporablja baze znanja za generiranje vektorskih besedilnih predstavitev ali vdelav. Baze znanja za Amazon Bedrock so v celoti upravljana zmogljivost, ki vam pomaga implementirati celoten potek dela RAG, od vnosa do pridobivanja in takojšnjega povečanja, ne da bi vam bilo treba graditi integracije po meri z viri podatkov ali upravljati tokove podatkov in podrobnosti implementacije RAG.
Ko ste zadovoljni z odzivom baze znanja Amazon Bedrock, lahko integrirate odziv temeljnega vzroka iz baze znanja v aplikacijo Streamlit.
Čiščenje
Če želite prihraniti stroške, izbrišite vire, ki ste jih ustvarili v tej objavi:
- Izbrišite bazo znanja iz Amazon Bedrock.
- Izbrišite indeks storitve OpenSearch.
- Izbrišite sklad genai-sagemaker CloudFormation.
- Zaustavite primerek EC2, če ste za zagon aplikacije Streamlit uporabili primerek EC2.
zaključek
Generativne aplikacije umetne inteligence so že preoblikovale različne poslovne procese ter povečale produktivnost delavcev in nabor spretnosti. Vendar pa so omejitve FM-jev pri obdelavi analize podatkov časovnih vrst ovirale njihovo popolno uporabo pri industrijskih odjemalcih. Ta omejitev je ovirala uporabo generativne umetne inteligence za prevladujočo vrsto podatkov, ki se dnevno obdelujejo.
V tej objavi smo predstavili generativno rešitev AI Application, zasnovano za ublažitev tega izziva za industrijske uporabnike. Ta aplikacija uporablja odprtokodnega agenta, PandasAI, za krepitev zmožnosti analize časovnih vrst FM. Namesto pošiljanja podatkov časovnih vrst neposredno FM-jem, aplikacija uporablja PandasAI za ustvarjanje kode Python za analizo nestrukturiranih podatkov časovnih vrst. Za izboljšanje natančnosti generiranja kode Python je bil implementiran potek dela za generiranje pozivov po meri s človeško revizijo.
Z vpogledom v stanje svojih sredstev lahko industrijski delavci v celoti izkoristijo potencial generativne umetne inteligence v različnih primerih uporabe, vključno z diagnozo temeljnega vzroka in načrtovanjem zamenjave delov. Z bazami znanja za Amazon Bedrock je rešitev RAG za razvijalce preprosta za izdelavo in upravljanje.
Pot upravljanja podatkov in operacij podjetja se nedvomno premika proti globlji integraciji z generativno umetno inteligenco za celovit vpogled v operativno zdravje. Ta premik, ki ga je vodil Amazon Bedrock, je znatno okrepljen z naraščajočo robustnostjo in potencialom LLM-jev, kot je Amazon Bedrock Claude 3 za nadaljnje dviganje rešitev. Če želite izvedeti več, obiščite posvetovanje z Dokumentacija Amazon Bedrockin se seznanite z Delavnica Amazon Bedrock.
O avtorjih
 Julia Hu je starejši arhitekt rešitev AI/ML pri Amazon Web Services. Specializirana je za Generative AI, Applied Data Science in IoT arhitekturo. Trenutno je del ekipe Amazon Q in aktivna članica/mentorica v skupnosti tehničnega področja strojnega učenja. Sodeluje s strankami, od novoustanovljenih podjetij do podjetij, pri razvoju generativnih rešitev AI AWSome. Še posebej je navdušena nad uporabo velikih jezikovnih modelov za napredno podatkovno analitiko in raziskovanjem praktičnih aplikacij, ki obravnavajo izzive v resničnem svetu.
Julia Hu je starejši arhitekt rešitev AI/ML pri Amazon Web Services. Specializirana je za Generative AI, Applied Data Science in IoT arhitekturo. Trenutno je del ekipe Amazon Q in aktivna članica/mentorica v skupnosti tehničnega področja strojnega učenja. Sodeluje s strankami, od novoustanovljenih podjetij do podjetij, pri razvoju generativnih rešitev AI AWSome. Še posebej je navdušena nad uporabo velikih jezikovnih modelov za napredno podatkovno analitiko in raziskovanjem praktičnih aplikacij, ki obravnavajo izzive v resničnem svetu.
 Sudeesh Sasidharan je višji arhitekt rešitev pri AWS, znotraj ekipe Energy. Sudeesh rad eksperimentira z novimi tehnologijami in gradi inovativne rešitve, ki rešujejo kompleksne poslovne izzive. Ko ne snuje rešitev ali se ne ukvarja z najnovejšimi tehnologijami, ga lahko najdete na teniškem igrišču, ko dela na bekhendu.
Sudeesh Sasidharan je višji arhitekt rešitev pri AWS, znotraj ekipe Energy. Sudeesh rad eksperimentira z novimi tehnologijami in gradi inovativne rešitve, ki rešujejo kompleksne poslovne izzive. Ko ne snuje rešitev ali se ne ukvarja z najnovejšimi tehnologijami, ga lahko najdete na teniškem igrišču, ko dela na bekhendu.
 Neil Desai je tehnološki direktor z več kot 20-letnimi izkušnjami na področju umetne inteligence (AI), podatkovne znanosti, programskega inženiringa in arhitekture podjetij. Pri AWS vodi skupino svetovnih arhitektov rešitev za storitve umetne inteligence, ki strankam pomagajo zgraditi inovativne rešitve, ki temeljijo na umetni inteligenci, delijo najboljše prakse s strankami in vodijo načrt izdelka. V svojih prejšnjih vlogah pri Vestas, Honeywell in Quest Diagnostics je imel Neil vodilne vloge pri razvoju in lansiranju inovativnih izdelkov in storitev, ki so podjetjem pomagale izboljšati njihovo poslovanje, zmanjšati stroške in povečati prihodke. Navdušen je nad uporabo tehnologije za reševanje problemov v resničnem svetu in je strateški mislec z dokazano uspešnostjo.
Neil Desai je tehnološki direktor z več kot 20-letnimi izkušnjami na področju umetne inteligence (AI), podatkovne znanosti, programskega inženiringa in arhitekture podjetij. Pri AWS vodi skupino svetovnih arhitektov rešitev za storitve umetne inteligence, ki strankam pomagajo zgraditi inovativne rešitve, ki temeljijo na umetni inteligenci, delijo najboljše prakse s strankami in vodijo načrt izdelka. V svojih prejšnjih vlogah pri Vestas, Honeywell in Quest Diagnostics je imel Neil vodilne vloge pri razvoju in lansiranju inovativnih izdelkov in storitev, ki so podjetjem pomagale izboljšati njihovo poslovanje, zmanjšati stroške in povečati prihodke. Navdušen je nad uporabo tehnologije za reševanje problemov v resničnem svetu in je strateški mislec z dokazano uspešnostjo.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

