
Slika avtorja
Nadzorovano je podkategorija strojnega učenja, pri kateri se računalnik uči iz označenega nabora podatkov, ki vsebuje tako vhodne kot tudi pravilne izhodne podatke. Poskuša najti funkcijo preslikave, ki povezuje vhod (x) z izhodom (y). Lahko si predstavljate to kot učenje svojega mlajšega brata ali sestre, kako prepoznati različne živali. Pokazali jim boste nekaj slik (x) in jim povedali, kako se imenuje posamezna žival (y). Po določenem času bodo spoznali razlike in bodo znali pravilno prepoznati novo sliko. To je osnovna intuicija za nadzorovano učenje. Preden gremo naprej, si poglejmo globlje njegovo delovanje.
Kako deluje nadzorovano učenje?
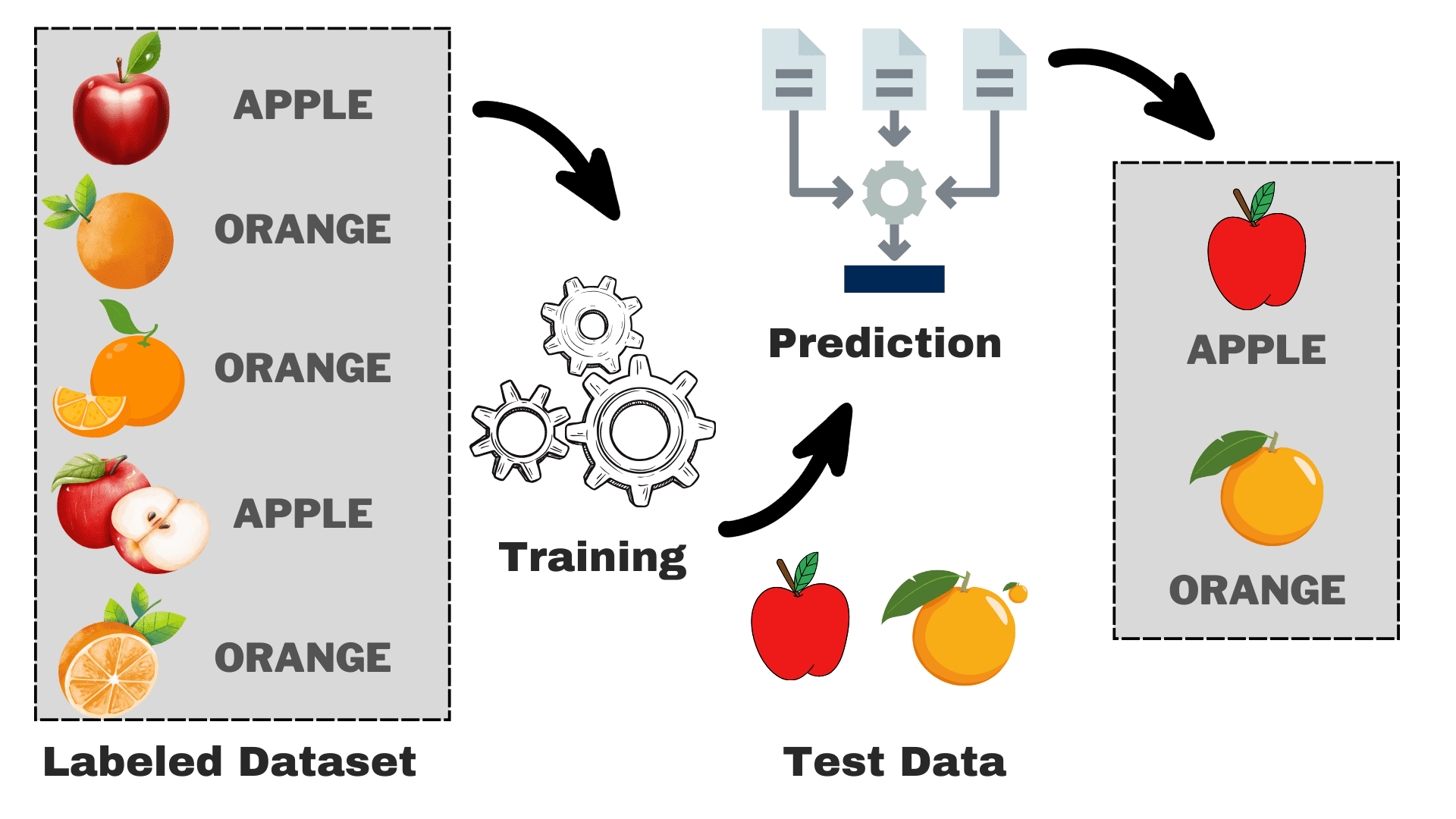
Slika avtorja
Recimo, da želite zgraditi model, ki lahko razlikuje med jabolki in pomarančami na podlagi nekaterih značilnosti. Postopek lahko razdelimo na naslednje naloge:
- Zbiranje podatkov: Zberite nabor podatkov s slikami jabolk in pomaranč in vsaka slika bo označena kot »jabolko« ali »pomaranča«.
- Izbira modela: Tukaj moramo izbrati pravi klasifikator, ki je pogosto znan kot pravi nadzorovani algoritem strojnega učenja za vašo nalogo. To je tako kot izbira pravih očal, ki vam bodo pomagala bolje videti
- Usposabljanje modela: Sedaj pa algoritem napolnite z označenimi slikami jabolk in pomaranč. Algoritem si ogleda te slike in se nauči prepoznati razlike, kot so barva, oblika in velikost jabolk in pomaranč.
- Ocenjevanje in testiranje: Da bi preverili, ali vaš model deluje pravilno, mu bomo dodali nekaj nevidenih slik in primerjali predvidevanja z dejanskim.
Nadzorovano učenje lahko razdelimo na dve glavni vrsti:
Razvrstitev
Pri nalogah klasifikacije je primarni cilj dodelitev podatkovnih točk določenim kategorijam iz nabora ločenih razredov. Če sta možna le dva izida, kot sta »da« ali »ne«, »neželena pošta« ali »ni neželena pošta«, »sprejeto« ali »zavrnjeno«, se to imenuje binarna klasifikacija. Če pa sta vključeni več kot dve kategoriji ali razredi, na primer ocenjevanje učencev na podlagi njihovih ocen (npr. A, B, C, D, F), postane to primer problema večrazvrščanja.
regresija
Za težave z regresijo poskušate napovedati neprekinjeno številčno vrednost. Morda vas bo na primer zanimalo napovedovanje rezultatov na končnem izpitu na podlagi vašega preteklega uspeha v razredu. Predvideni rezultati lahko obsegajo katero koli vrednost v določenem razponu, običajno od 0 do 100 v našem primeru.
Zdaj imamo osnovno razumevanje celotnega procesa. Raziskali bomo priljubljene nadzorovane algoritme strojnega učenja, njihovo uporabo in kako delujejo:
1. Linearna regresija
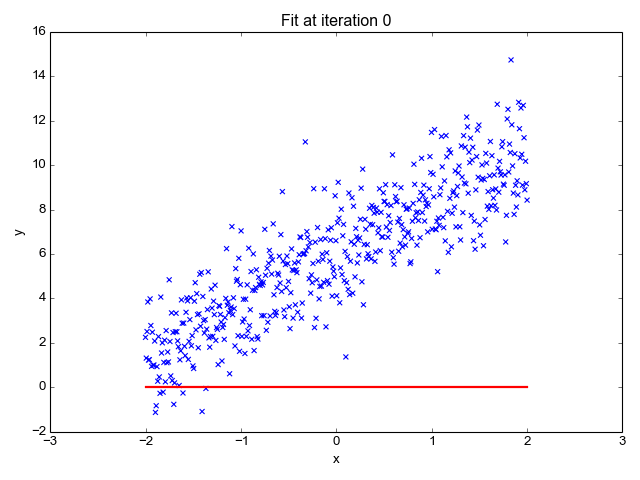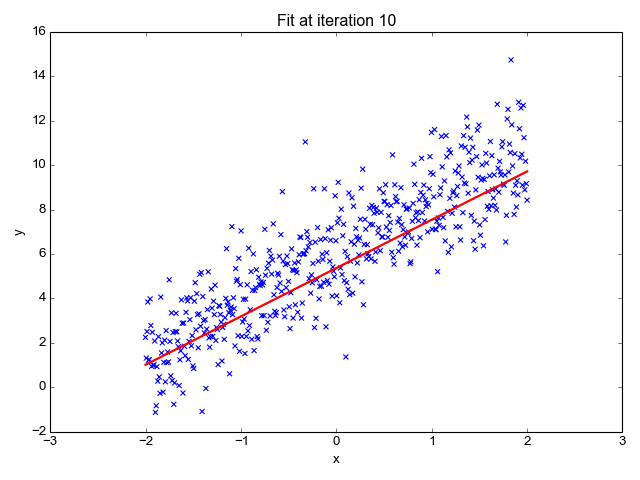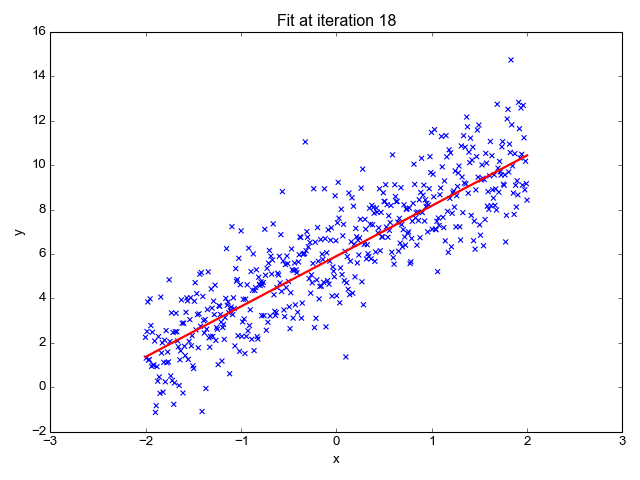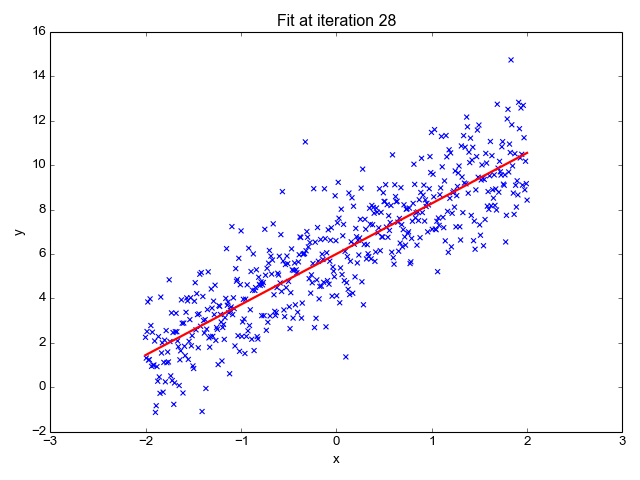
Kot že ime pove, se uporablja za regresijske naloge, kot so napovedovanje tečajev delnic, napovedovanje temperature, ocenjevanje verjetnosti napredovanja bolezni itd. Ciljno (odvisno spremenljivko) poskušamo predvideti z uporabo niza oznak (neodvisnih spremenljivk). Predpostavlja, da imamo linearno razmerje med našimi vhodnimi funkcijami in oznako. Osrednja ideja se vrti okoli napovedovanja črte, ki se najbolj prilega našim podatkovnim točkam, tako da se zmanjša napaka med našimi dejanskimi in predvidenimi vrednostmi. Ta vrstica je predstavljena z enačbo:
Kje,
- Y Predviden rezultat.
- X = Vhodna funkcija ali matrika značilnosti v večkratni linearni regresiji
- b0 = presek (kjer črta prečka os Y).
- b1 = Naklon ali koeficient, ki določa strmino črte.
Ocenjuje naklon črte (težo) in njen presek (pristranskost). To vrstico je mogoče nadalje uporabiti za napovedi. Čeprav je najenostavnejši in uporaben model za razvoj osnovnih linij, je zelo občutljiv na odstopanja, ki lahko vplivajo na položaj črte.
Gif vklopljen Primo.ai
2. Logistična regresija
Čeprav ima v svojem imenu regresijo, se v osnovi uporablja za probleme binarne klasifikacije. Napove verjetnost pozitivnega izida (odvisna spremenljivka), ki leži v območju od 0 do 1. Z nastavitvijo praga (običajno 0.5) razvrstimo podatkovne točke: tiste z verjetnostjo večjo od praga spadajo v pozitivni razred, in obratno. Logistična regresija izračuna to verjetnost z uporabo sigmoidne funkcije, uporabljene za linearno kombinacijo vhodnih značilnosti, ki je podana kot:
Kje,
- P(Y=1) = verjetnost, da podatkovna točka pripada pozitivnemu razredu
- X1 ,… ,Xn = vhodne funkcije
- b0,….,bn = vhodne uteži, ki se jih algoritem nauči med usposabljanjem
Ta sigmoidna funkcija je v obliki krivulje, podobne S, ki pretvori katero koli podatkovno točko v oceno verjetnosti v območju 0-1. Za boljše razumevanje si lahko ogledate spodnji graf.
Slika vklopljena Wikipedia
Vrednost, ki je bližja 1, pomeni večje zaupanje modela v njegovo napoved. Tako kot linearna regresija je znana po svoji preprostosti, vendar večrazredne klasifikacije ne moremo izvesti brez spremembe prvotnega algoritma.
3. Odločitvena drevesa
Za razliko od zgornjih dveh algoritmov se odločitvena drevesa lahko uporabljajo za naloge klasifikacije in regresije. Ima hierarhično strukturo tako kot diagrami poteka. Na vsakem vozlišču se odločitev o poti sprejme na podlagi nekaterih vrednosti lastnosti. Postopek se nadaljuje, razen če dosežemo zadnje vozlišče, ki prikazuje končno odločitev. Tukaj je nekaj osnovnih izrazov, ki se jih morate zavedati:
- Korensko vozlišče: Zgornje vozlišče, ki vsebuje celoten nabor podatkov, se imenuje korensko vozlišče. Nato z algoritmom izberemo najboljšo funkcijo, da nabor podatkov razdelimo na 2 ali več poddreves.
- Notranja vozlišča: Vsako notranje vozlišče predstavlja posebno funkcijo in pravilo odločanja za določitev naslednje možne smeri za podatkovno točko.
- Listni vozli: Končna vozlišča, ki predstavljajo oznako razreda, se imenujejo listna vozlišča.
Predvidi zvezne številčne vrednosti za regresijske naloge. Ko se velikost nabora podatkov poveča, zajame šum, ki vodi do prekomernega opremljanja. To je mogoče rešiti z obrezovanjem odločitvenega drevesa. Odstranimo veje, ki bistveno ne izboljšajo točnosti naših odločitev. To pomaga ohranjati naše drevo osredotočeno na najpomembnejše dejavnike in preprečuje, da bi se izgubilo v podrobnostih.
Slike, ki jih Jake Hoare na Displayrju
4. Naključni gozd
Naključni gozd se lahko uporablja tudi za naloge klasifikacije in regresije. Gre za skupino odločitvenih dreves, ki sodelujejo pri oblikovanju končne napovedi. Lahko si predstavljate to kot odbor strokovnjakov, ki sprejema skupno odločitev. Evo kako deluje:
- Vzorčenje podatkov: Namesto da bi vzel celoten nabor podatkov naenkrat, vzame naključne vzorce s postopkom, imenovanim bootstrapping ali bagging.
- Izbira funkcij: Za vsako odločitveno drevo v naključnem gozdu se pri odločanju upošteva le naključna podmnožica funkcij namesto celotnega nabora funkcij.
- Glasovanje: Za razvrstitev vsako odločilno drevo v naključnem gozdu odda svoj glas in izbran je razred z najvišjimi glasovi. Za regresijo povprečimo vrednosti, dobljene iz vseh dreves.
Čeprav zmanjša učinek prekomernega opremljanja, ki ga povzročajo posamezna odločitvena drevesa, je računsko drago. Beseda, ki jo boste pogosto prebrali v literaturi, je, da je naključni gozd učna metoda ansambla, kar pomeni, da združuje več modelov za izboljšanje splošne uspešnosti.
5. Podporni vektorski stroji (SVM)
Uporablja se predvsem za težave s klasifikacijo, vendar lahko obravnava tudi naloge regresije. Poskuša najti najboljšo hiperravnino, ki ločuje različne razrede z uporabo statističnega pristopa, za razliko od verjetnostnega pristopa logistične regresije. Za linearno ločljive podatke lahko uporabimo linearni SVM. Vendar je večina podatkov iz resničnega sveta nelinearnih in za ločevanje razredov uporabljamo trike jedra. Poglobimo se v to, kako deluje:
- Izbira hiperravnine: Pri binarni klasifikaciji SVM najde najboljšo hiperravnino (2-D črta) za ločevanje razredov, hkrati pa poveča rob. Rob je razdalja med hiperravnino in najbližjimi podatkovnimi točkami hiperravnini.
- Trik jedra: Za linearno neločljive podatke uporabljamo trik jedra, ki preslika prvotni podatkovni prostor v visokodimenzionalni prostor, kjer jih je mogoče linearno ločiti. Pogosta jedra vključujejo linearna, polinomska, radialna osnovna funkcija (RBF) in sigmoidna jedra.
- Maksimiranje marže: SVM prav tako poskuša izboljšati generalizacijo modela s povečanjem maksimalne marže.
- Razvrstitev: Ko je model usposobljen, je mogoče predvideti na podlagi njihovega položaja glede na hiperravnino.
SVM ima tudi parameter, imenovan C, ki nadzoruje kompromis med maksimiranjem marže in ohranjanjem napake klasifikacije na minimumu. Čeprav lahko dobro obravnavajo visokodimenzionalne in nelinearne podatke, izbira pravega jedra in hiperparametra ni tako enostavna, kot se zdi.
Slika vklopljena Javatpoint
6. k-najbližji sosedje (k-NN)
K-NN je najpreprostejši algoritem za nadzorovano učenje, ki se večinoma uporablja za naloge klasifikacije. Ne daje nobenih predpostavk o podatkih in novi podatkovni točki dodeli kategorijo na podlagi njene podobnosti z obstoječimi. Med fazo usposabljanja hrani celoten nabor podatkov kot referenčno točko. Nato izračuna razdaljo med novo podatkovno točko in vsemi obstoječimi točkami z uporabo metrike razdalje (npr. razdalja Eucilinedain). Na podlagi teh razdalj identificira K najbližjih sosedov tem podatkovnim točkam. Nato preštejemo pojavljanje vsakega razreda pri K najbližjih sosedih in dodelimo najpogosteje pojavljajoči se razred kot končno napoved.
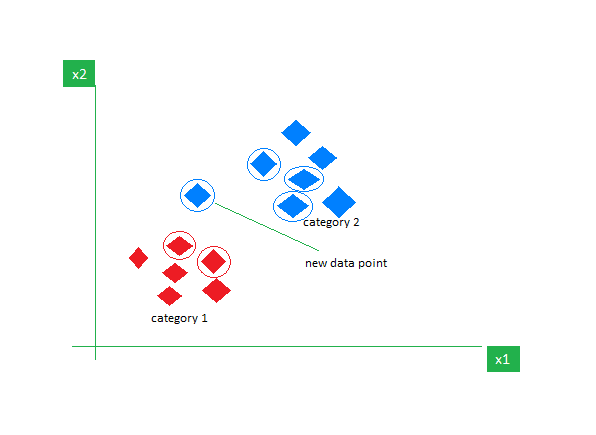
Slika vklopljena geeksforgeeks
Izbira prave vrednosti K zahteva eksperimentiranje. Čeprav je robusten do šumnih podatkov, ni primeren za visokodimenzionalne nize podatkov in ima visoke stroške zaradi izračuna razdalje od vseh podatkovnih točk.
Ko zaključujem ta članek, bi bralce spodbudil, da raziščejo več algoritmov in jih poskusijo implementirati iz nič. To bo okrepilo vaše razumevanje, kako stvari delujejo pod pokrovom. Tukaj je nekaj dodatnih virov, ki vam bodo v pomoč pri začetku:
Kanwal Mehreen je ambiciozen razvijalec programske opreme z velikim zanimanjem za podatkovno znanost in uporabo umetne inteligence v medicini. Kanwal je bil izbran za Google Generation Scholar 2022 za regijo APAC. Kanwal rad deli tehnično znanje s pisanjem člankov o trendovskih temah in se strastno trudi izboljšati zastopanost žensk v tehnološki industriji.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Avtomobili/EV, Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- ChartPrime. Izboljšajte svojo igro trgovanja s ChartPrime. Dostopite tukaj.
- BlockOffsets. Posodobitev okoljskega offset lastništva. Dostopite tukaj.
- vir: https://www.kdnuggets.com/understanding-supervised-learning-theory-and-overview?utm_source=rss&utm_medium=rss&utm_campaign=understanding-supervised-learning-theory-and-overview

