Amazon Titan lmage Generator G1 je vrhunski model besedila v sliko, ki je na voljo prek Amazon Bedrock, ki lahko razume pozive, ki opisujejo več predmetov v različnih kontekstih, in zajame te pomembne podrobnosti v slikah, ki jih ustvari. Na voljo je v regijah AWS Vzhod ZDA (N. Virginia) in Zahod ZDA (Oregon) ter lahko izvaja napredna opravila urejanja slik, kot so pametno obrezovanje, slikanje in spreminjanje ozadja. Vendar bi uporabniki radi prilagodili model edinstvenim značilnostim v naborih podatkov po meri, na katerih model še ni usposobljen. Nabori podatkov po meri lahko vključujejo zelo zaščitene podatke, ki so skladni s smernicami vaše blagovne znamke ali posebnimi slogi, kot je prejšnja oglaševalska akcija. Če želite obravnavati te primere uporabe in ustvariti popolnoma prilagojene slike, lahko natančno nastavite Amazon Titan Image Generator z lastnimi podatki z modeli po meri za Amazon Bedrock.
Od generiranja slik do njihovega urejanja imajo modeli besedila v sliko široko uporabo v panogah. Lahko povečajo ustvarjalnost zaposlenih in omogočijo, da si zamislijo nove možnosti preprosto z besedilnimi opisi. Arhitektom lahko na primer pomaga pri oblikovanju in tlorisnem načrtovanju ter omogoča hitrejše inovacije z zagotavljanjem možnosti vizualizacije različnih modelov brez ročnega procesa ustvarjanja. Podobno lahko pomaga pri oblikovanju v različnih panogah, kot so proizvodnja, modno oblikovanje v maloprodaji in oblikovanje iger, tako da racionalizira ustvarjanje grafik in ilustracij. Modeli besedila v sliko prav tako izboljšajo vašo uporabniško izkušnjo, saj omogočajo prilagojeno oglaševanje ter interaktivne in poglobljene vizualne klepetalnice v primerih uporabe medijev in zabave.
V tej objavi vas vodimo skozi postopek natančnega prilagajanja modela Amazon Titan Image Generator, da se naučite dveh novih kategorij: psa Rona in mačke Smila, naših najljubših hišnih ljubljenčkov. Razpravljamo o tem, kako pripraviti vaše podatke za nalogo natančnega prilagajanja modela in kako ustvariti opravilo prilagajanja modela v Amazon Bedrock. Nazadnje vam pokažemo, kako preizkusite in uvedete svoj natančno nastavljen model Zagotovljena prepustnost.
 |
 |
| pes Ron | Smila mačka |
Ocenjevanje zmogljivosti modela pred natančno nastavitvijo opravila
Osnovni modeli so usposobljeni za velike količine podatkov, zato je možno, da bo vaš model deloval dovolj dobro takoj po izdelavi. Zato je dobra praksa, da preverite, ali morate svoj model dejansko natančno prilagoditi za vaš primer uporabe ali pa zadostuje takojšnje načrtovanje. Poskusimo ustvariti nekaj slik psa Rona in mačke Smile z osnovnim modelom Amazon Titan Image Generator, kot je prikazano na naslednjih posnetkih zaslona.
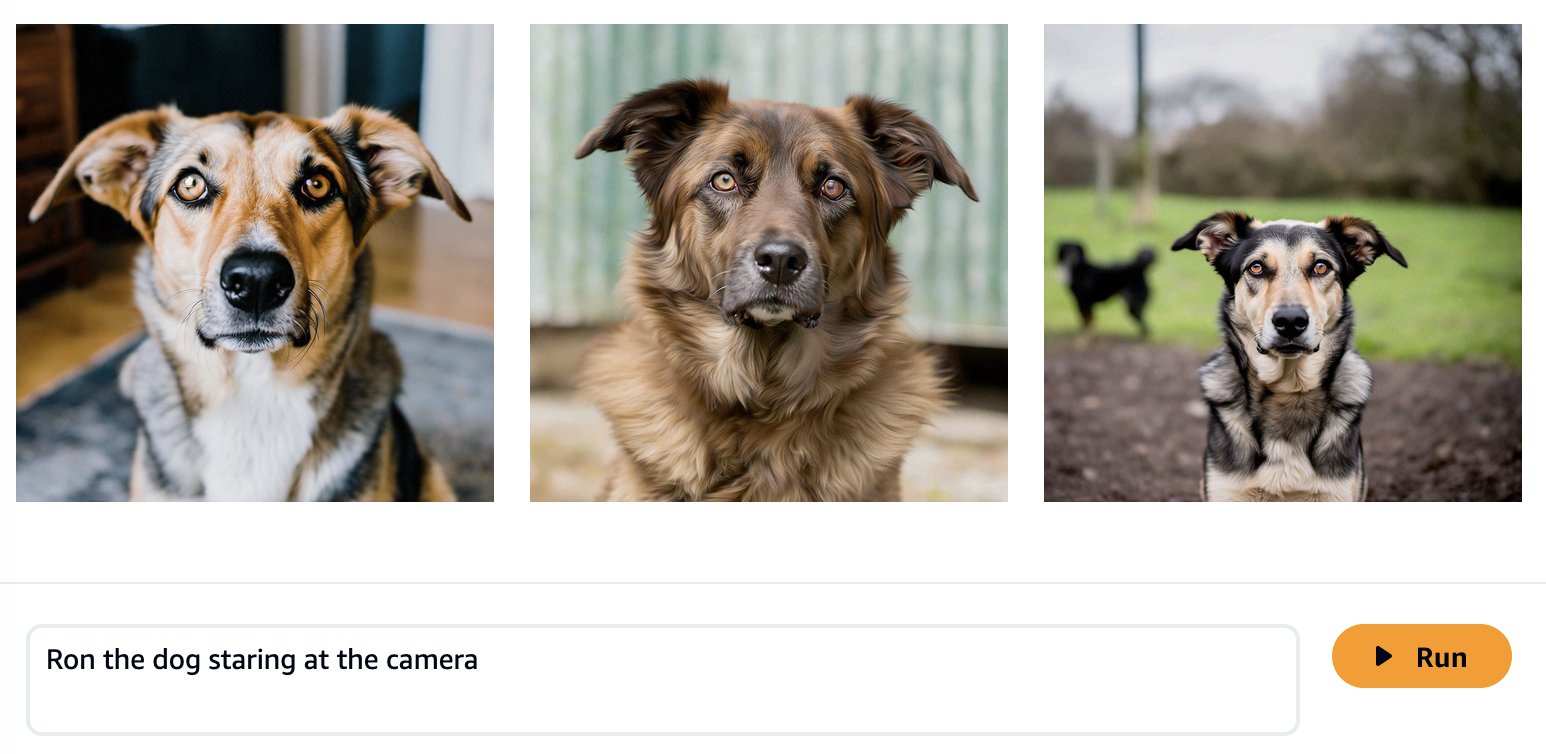

Kot je bilo pričakovano, model izven škatle še ne pozna Rona in Smile, ustvarjeni rezultati pa prikazujejo različne pse in mačke. Z nekaj hitrega inženiringa lahko zagotovimo več podrobnosti, da se približamo videzu naših najljubših ljubljenčkov.


Čeprav so ustvarjene slike bolj podobne Ronu in Smili, vidimo, da model ne more reproducirati njune popolne podobnosti. Zdaj pa začnimo natančno prilagajanje s fotografijami Rona in Smile, da dobimo dosledne, prilagojene rezultate.
Natančna nastavitev Amazon Titan Image Generator
Amazon Bedrock vam ponuja izkušnjo brez strežnika za natančno nastavitev vašega modela Amazon Titan Image Generator. Pripraviti morate le svoje podatke in izbrati svoje hiperparametre, AWS pa bo opravil težko delo namesto vas.
Ko za natančno nastavitev uporabite model Amazon Titan Image Generator, se ustvari kopija tega modela v računu za razvoj modela AWS, ki je v lasti in upravljanju AWS, in ustvarjeno je opravilo za prilagajanje modela. To opravilo nato dostopa do podatkov o natančnem uravnavanju iz VPC in model amazon Titan ima posodobljene uteži. Novi model se nato shrani v Preprosta storitev shranjevanja Amazon (Amazon S3), ki se nahaja v istem računu za razvoj modela kot predhodno usposobljeni model. Zdaj ga lahko za sklepanje uporablja samo vaš račun in ni v skupni rabi z nobenim drugim računom AWS. Ko izvajate sklepanje, do tega modela dostopate prek a predvidena zmogljivost izračuna ali neposredno z uporabo paketno sklepanje za Amazon Bedrock. Neodvisno od izbranega načina sklepanja vaši podatki ostanejo v vašem računu in se ne kopirajo v noben račun v lasti AWS ali se uporabljajo za izboljšanje modela Amazon Titan Image Generator.
Naslednji diagram ponazarja ta potek dela.
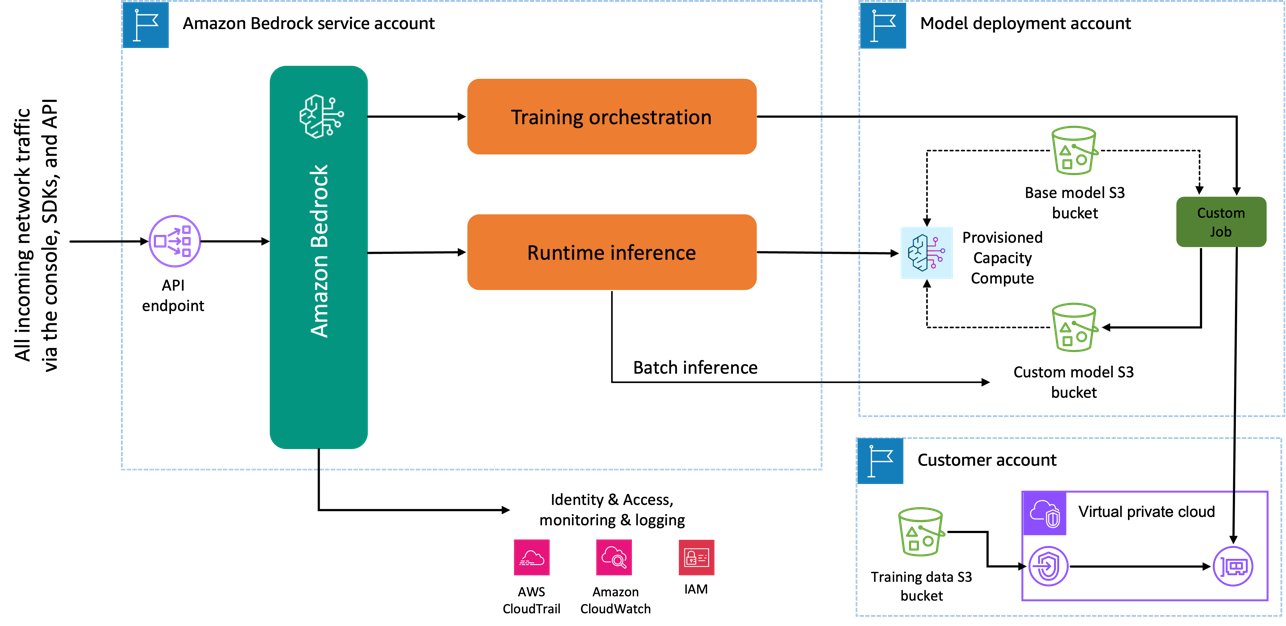
Zasebnost podatkov in varnost omrežja
Vaši podatki, ki se uporabljajo za natančno nastavitev, vključno s pozivi, kot tudi modeli po meri, ostanejo zasebni v vašem računu AWS. Ne delijo se ali uporabljajo za usposabljanje modela ali izboljšave storitev in se ne delijo s ponudniki modelov tretjih oseb. Vsi podatki, ki se uporabljajo za natančno nastavitev, so med prenosom in mirovanjem šifrirani. Podatki ostanejo v isti regiji, kjer se obdela klic API. Uporabite lahko tudi AWS PrivateLink za ustvarjanje zasebne povezave med računom AWS, kjer so vaši podatki, in VPC.
Priprava podatkov
Preden lahko ustvarite opravilo prilagajanja modela, morate pripravite svoj nabor podatkov o usposabljanju. Oblika vašega nabora podatkov o usposabljanju je odvisna od vrste opravila prilagajanja, ki ga ustvarjate (natančna nastavitev ali nadaljevanje predhodnega usposabljanja) in načina vaših podatkov (besedilo v besedilo, besedilo v sliko ali slika v- vdelava). Za model Amazon Titan Image Generator morate zagotoviti slike, ki jih želite uporabiti za natančno nastavitev, in napis za vsako sliko. Amazon Bedrock pričakuje, da bodo vaše slike shranjene na Amazon S3 in da bodo pari slik in napisi zagotovljeni v formatu JSONL z več vrsticami JSON.
Vsaka vrstica JSON je vzorec, ki vsebuje slikovni ref, S3 URI za sliko in napis, ki vključuje besedilni poziv za sliko. Vaše slike morajo biti v formatu JPEG ali PNG. Naslednja koda prikazuje primer formata:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Ker sta »Ron« in »Smila« imeni, ki ju je mogoče uporabiti tudi v drugih kontekstih, kot je ime osebe, dodamo identifikatorja »pes Ron« in »mačka Smila«, ko ustvarjamo poziv za natančno nastavitev našega modela . Čeprav to ni zahteva za potek dela natančnega prilagajanja, te dodatne informacije zagotavljajo več kontekstualne jasnosti za model, ko se prilagaja za nove razrede, in se bodo izognile zamenjavi »psa Rona« z osebo po imenu Ron in » Mačka Smila« z mestom Smila v Ukrajini. Z uporabo te logike naslednje slike prikazujejo vzorec našega nabora podatkov o usposabljanju.
 |
 |
 |
| Pes Ron leži na beli pasji postelji | Pes Ron, ki sedi na keramičnih tleh | Pes Ron leži na avtomobilskem sedežu |
 |
 |
 |
| Smila mačka, ki leži na kavču | Mačka Smila strmi v kamero in leži na kavču | Mačka Smila leži v nosilki za hišne ljubljenčke |
Pri preoblikovanju naših podatkov v obliko, ki jo pričakuje opravilo prilagajanja, dobimo naslednjo vzorčno strukturo:
{"image-ref": "/ron_01.jpg", "caption": "Pes Ron leži na beli pasji postelji"} {"image-ref": "/ron_02.jpg", "caption": "Pes Ron, ki sedi na keramičnih tleh"} {"image-ref": "/ron_03.jpg", "caption": "Pes Ron leži na avtomobilskem sedežu"} {"image-ref": "/smila_01.jpg", "caption": "Mačka Smila, ki leži na kavču"} {"image-ref": "/smila_02.jpg", "caption": "Mačka Smila, ki sedi ob oknu poleg mačjega kipa"} {"image-ref": "/smila_03.jpg", "caption": "Mačka Smila, ki leži na nosilki za hišne ljubljenčke"}
Ko ustvarimo našo datoteko JSONL, jo moramo shraniti v vedro S3, da lahko začnemo s prilagajanjem. Opravila natančne nastavitve Amazon Titan Image Generator G1 bodo delovala s 5–10,000 slikami. Za primer, obravnavan v tej objavi, uporabljamo 60 slik: 30 psa Rona in 30 mačke Smile. Na splošno bo zagotavljanje več različic sloga ali razreda, ki se ga poskušate naučiti, izboljšalo natančnost vašega natančno nastavljenega modela. Vendar pa več slik kot uporabite za natančno nastavitev, več časa bo potrebno za dokončanje natančne naravnave. Število uporabljenih slik vpliva tudi na ceno vašega natančnega dela. Nanašati se na Cene Amazon Bedrock za več informacij.
Natančna nastavitev Amazon Titan Image Generator
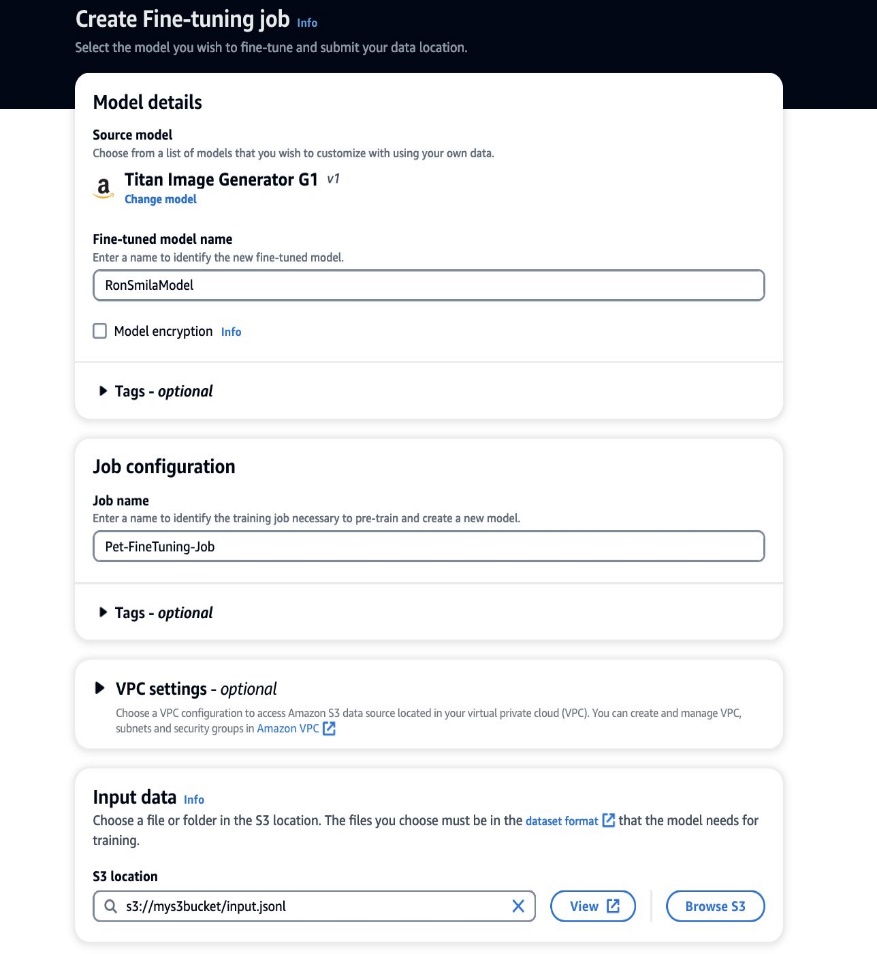
Zdaj, ko imamo pripravljene podatke o usposabljanju, lahko začnemo novo prilagajanje. Ta postopek je mogoče izvesti prek konzole Amazon Bedrock ali API-jev. Za uporabo konzole Amazon Bedrock izvedite naslednje korake:
- Na konzoli Amazon Bedrock izberite Modeli po meri v podoknu za krmarjenje.
- o Prilagodite model izberite meni Ustvarite nalogo natančnega prilagajanja.
- za Natančno prilagojeno ime modela, vnesite ime za vaš novi model.
- za Konfiguracija delovnega mesta, vnesite ime za usposabljanje.
- za Vhodni podatki, vnesite pot S3 vhodnih podatkov.
- v Hiperparametri podajte vrednosti za naslednje:
- Število korakov – Kolikokrat je model izpostavljen posamezni seriji.
- Velikost serije – Število vzorcev, obdelanih pred posodobitvijo parametrov modela.
- Stopnja učenja – Hitrost, s katero se parametri modela posodabljajo po vsaki seriji. Izbira teh parametrov je odvisna od danega nabora podatkov. Kot splošno vodilo priporočamo, da začnete tako, da določite velikost serije na 8, stopnjo učenja na 1e-5 in nastavite število korakov glede na število uporabljenih slik, kot je podrobno opisano v naslednji tabeli.
| Število ponujenih slik | 8 | 32 | 64 | 1,000 | 10,000 |
| Priporočeno število korakov | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Če rezultati vašega natančnega prilagajanja niso zadovoljivi, razmislite o povečanju števila korakov, če na ustvarjenih slikah ne opazite nobenih znakov sloga, in o zmanjšanju števila korakov, če opazite slog na ustvarjenih slikah, vendar z artefakti ali zamegljenostjo. Če se natančno nastavljeni model ne nauči edinstvenega sloga v vašem naboru podatkov niti po 40,000 korakih, razmislite o povečanju velikosti paketa ali stopnje učenja.
- v Izhodni podatki razdelku vnesite izhodno pot S3, kjer so shranjeni validacijski izhodi, vključno z redno zabeleženimi meritvami izgube validacije in natančnosti.
- v Dostop do storitve razdelek, ustvarite novo AWS upravljanje identitete in dostopa (IAM) ali izberite obstoječo vlogo IAM s potrebnimi dovoljenji za dostop do vaših veder S3.
Ta avtorizacija omogoča Amazonu Bedrocku pridobivanje vhodnih in validacijskih naborov podatkov iz vašega določenega vedra ter brezhibno shranjevanje validacijskih rezultatov v vašem vedru S3.
- Izberite Model za natančno nastavitev.
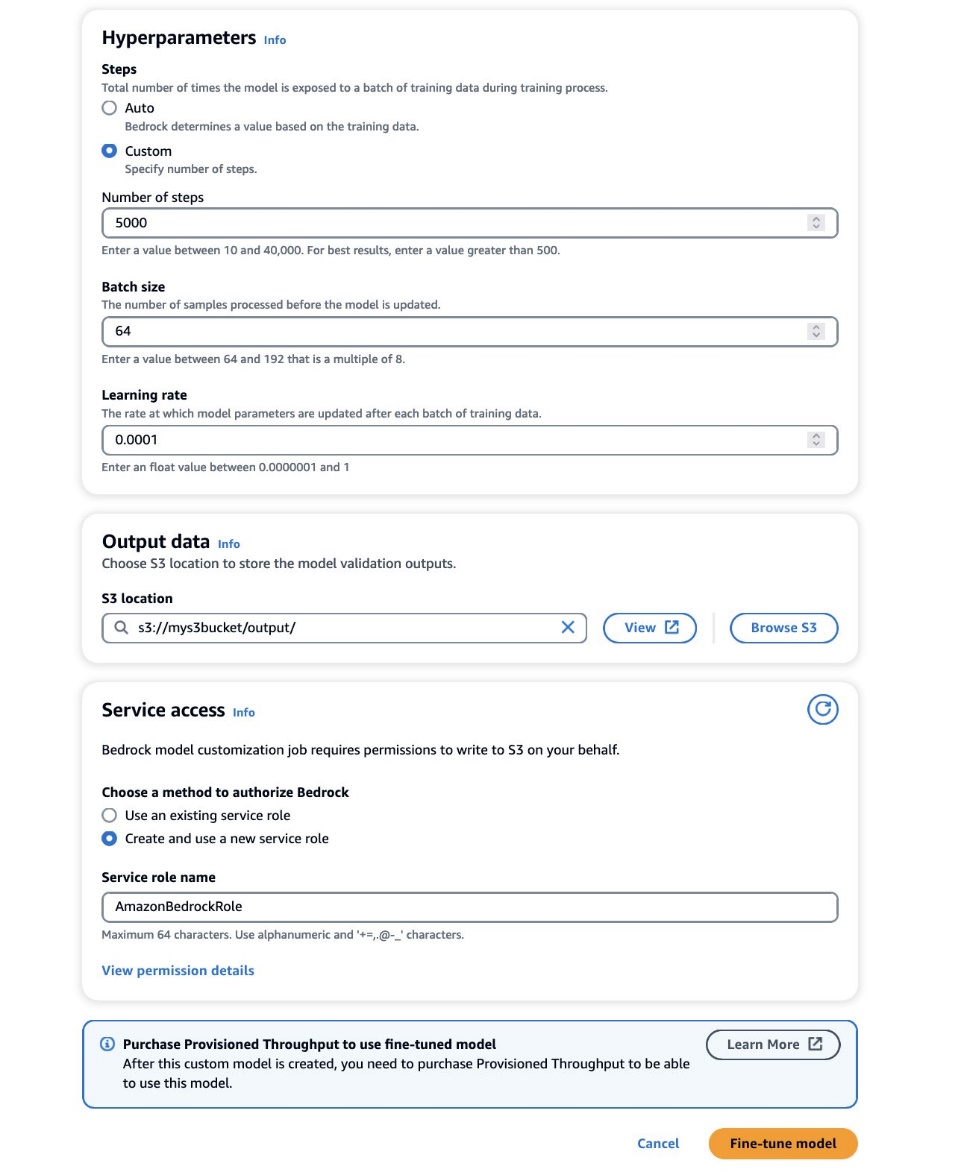
S pravilno nastavljenimi konfiguracijami bo Amazon Bedrock zdaj usposobil vaš model po meri.
Namestite natančno nastavljen Amazon Titan Image Generator z zagotovljeno prepustnostjo
Ko ustvarite model po meri, vam Provisioned Throughput omogoča, da modelu po meri dodelite vnaprej določeno, fiksno stopnjo zmogljivosti obdelave. Ta dodelitev zagotavlja dosledno raven zmogljivosti in zmogljivosti za obvladovanje delovnih obremenitev, kar ima za posledico boljšo zmogljivost pri produkcijskih delovnih obremenitvah. Druga prednost Provisioned Throughput je nadzor nad stroški, ker je standardno določanje cen na podlagi žetonov z načinom sklepanja na zahtevo težko predvideti v velikih obsegih.
Ko je fina nastavitev vašega modela končana, se bo ta model pojavil na modeli po meri' strani na konzoli Amazon Bedrock.
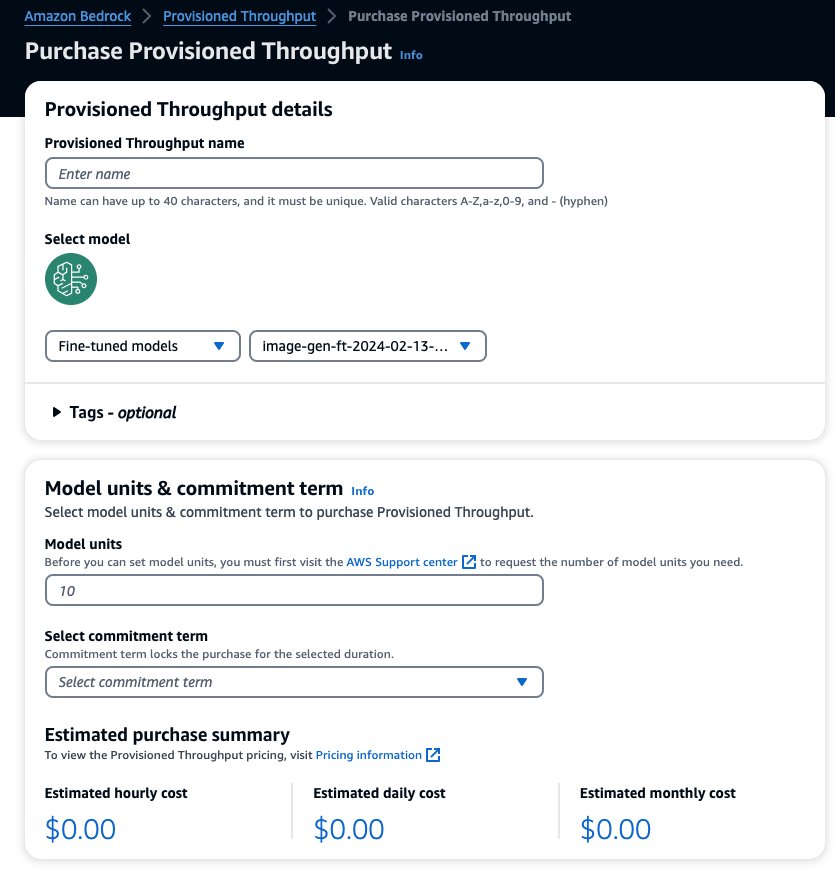
Če želite kupiti Provisioned Throughput, izberite model po meri, ki ste ga pravkar natančno nastavili, in izberite Prepustnost, predvidena za nakup.
To vnaprej izpolni izbrani model, za katerega želite kupiti Provisioned Throughput. Za preizkušanje natančno nastavljenega modela pred uvedbo nastavite enote modela na vrednost 1 in nastavite obdobje zaveze na Brez obveznosti. To vam omogoča, da hitro začnete preizkušati svoje modele s svojimi pozivi po meri in preverite, ali je usposabljanje ustrezno. Poleg tega, ko so na voljo novi natančno nastavljeni modeli in nove različice, lahko posodobite Provisioned Throughput, če ga posodobite z drugimi različicami istega modela.
Rezultati natančnega prilagajanja
Za našo nalogo prilagajanja modela psa Rona in mačke Smile so poskusi pokazali, da so bili najboljši hiperparametri 5,000 korakov z velikostjo serije 8 in stopnjo učenja 1e-5.
Sledi nekaj primerov slik, ustvarjenih s prilagojenim modelom.
 |
 |
 |
| Pes Ron, oblečen v ogrinjalo superjunaka | Pes Ron na luni | Ron psa v bazenu s sončnimi očali |
 |
 |
 |
| Smila mačka na snegu | Črno-bela mačka Smila strmi v kamero | Smila mačka z božičnim klobukom |
zaključek
V tej objavi smo razpravljali o tem, kdaj uporabiti natančno nastavitev namesto inženiringa vaših pozivov za ustvarjanje slike boljše kakovosti. Pokazali smo, kako natančno prilagoditi model Amazon Titan Image Generator in uvesti model po meri na Amazon Bedrock. Zagotovili smo tudi splošne smernice o tem, kako pripraviti svoje podatke za natančno nastavitev in nastaviti optimalne hiperparametre za natančnejšo prilagoditev modela.
Kot naslednji korak lahko prilagodite naslednje Primer vašemu primeru uporabe za ustvarjanje hiperpersonaliziranih slik z uporabo Amazon Titan Image Generator.
O avtorjih
 Maira Ladeira Tanke je višji generativni podatkovni znanstvenik za AI pri AWS. Z ozadjem strojnega učenja ima več kot 10 let izkušenj z arhitekturo in gradnjo aplikacij AI s strankami v različnih panogah. Kot tehnična vodja strankam pomaga pospešiti doseganje poslovne vrednosti z generativnimi rešitvami umetne inteligence na Amazon Bedrock. V prostem času Maira rada potuje, se igra s svojo mačko Smilo in preživlja čas s svojo družino nekje na toplem.
Maira Ladeira Tanke je višji generativni podatkovni znanstvenik za AI pri AWS. Z ozadjem strojnega učenja ima več kot 10 let izkušenj z arhitekturo in gradnjo aplikacij AI s strankami v različnih panogah. Kot tehnična vodja strankam pomaga pospešiti doseganje poslovne vrednosti z generativnimi rešitvami umetne inteligence na Amazon Bedrock. V prostem času Maira rada potuje, se igra s svojo mačko Smilo in preživlja čas s svojo družino nekje na toplem.
 Dani Mitchell je specialist za rešitve AI/ML pri Amazon Web Services. Osredotočen je na primere uporabe računalniškega vida in pomaga strankam v regiji EMEA, da pospešijo njihovo pot ML.
Dani Mitchell je specialist za rešitve AI/ML pri Amazon Web Services. Osredotočen je na primere uporabe računalniškega vida in pomaga strankam v regiji EMEA, da pospešijo njihovo pot ML.
 Bharathi Srinivasan je Data Scientist pri AWS Professional Services, kjer rada gradi kul stvari na Amazon Bedrock. Navdušena je nad ustvarjanjem poslovne vrednosti iz aplikacij strojnega učenja, s poudarkom na odgovorni umetni inteligenci. Poleg ustvarjanja novih izkušenj z umetno inteligenco za stranke, Bharathi rada piše znanstveno fantastiko in se preizkuša z vzdržljivostnimi športi.
Bharathi Srinivasan je Data Scientist pri AWS Professional Services, kjer rada gradi kul stvari na Amazon Bedrock. Navdušena je nad ustvarjanjem poslovne vrednosti iz aplikacij strojnega učenja, s poudarkom na odgovorni umetni inteligenci. Poleg ustvarjanja novih izkušenj z umetno inteligenco za stranke, Bharathi rada piše znanstveno fantastiko in se preizkuša z vzdržljivostnimi športi.
 Achin Jain je uporabni znanstvenik pri skupini Amazonove umetne splošne inteligence (AGI). Ima strokovno znanje o modelih besedila v sliko in je osredotočen na izdelavo Amazon Titan Image Generator.
Achin Jain je uporabni znanstvenik pri skupini Amazonove umetne splošne inteligence (AGI). Ima strokovno znanje o modelih besedila v sliko in je osredotočen na izdelavo Amazon Titan Image Generator.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

