Danes stranke v vseh panogah – pa naj gre za finančne storitve, zdravstvo in znanosti o življenju, potovanja in gostinstvo, medije in razvedrilo, telekomunikacije, programsko opremo kot storitev (SaaS) in celo ponudnike lastniških modelov – uporabljajo velike jezikovne modele (LLM) za gradite aplikacije, kot so klepetalni roboti za vprašanja in odgovore (QnA), iskalniki in baze znanja. te generativni AI aplikacije se ne uporabljajo samo za avtomatizacijo obstoječih poslovnih procesov, ampak imajo tudi možnost preoblikovanja izkušenj za stranke, ki uporabljajo te aplikacije. Z napredkom, doseženim z LLM, kot je Mixtral-8x7B Instruct, izpeljanka arhitektur, kot je mešanica strokovnjakov (MoE), stranke nenehno iščejo načine za izboljšanje zmogljivosti in natančnosti generativnih aplikacij AI, hkrati pa jim omogočajo učinkovito uporabo širšega nabora zaprtih in odprtokodnih modelov.
Številne tehnike se običajno uporabljajo za izboljšanje natančnosti in učinkovitosti izhoda LLM, kot je natančna nastavitev z parameter učinkovito fino uravnavanje (PEFT), krepitveno učenje iz človeških povratnih informacij (RLHF), in nastopanje destilacija znanja. Vendar pa lahko pri izdelavi generativnih aplikacij umetne inteligence uporabite alternativno rešitev, ki omogoča dinamično vključitev zunanjega znanja in vam omogoča nadzor nad informacijami, uporabljenimi za generiranje, ne da bi bilo treba natančno prilagoditi vaš obstoječi temeljni model. Tu pride na vrsto Retrieval Augmented Generation (RAG), posebej za generativne aplikacije umetne inteligence v nasprotju z dražjimi in robustnimi alternativami natančnega prilagajanja, o katerih smo razpravljali. Če implementirate zapletene aplikacije RAG v svoja vsakodnevna opravila, lahko naletite na običajne izzive s svojimi sistemi RAG, kot so netočno iskanje, vse večja velikost in kompleksnost dokumentov ter prelivanje konteksta, kar lahko znatno vpliva na kakovost in zanesljivost ustvarjenih odgovorov. .
Ta objava obravnava vzorce RAG za izboljšanje natančnosti odziva z uporabo LangChain in orodij, kot je nadrejeni pridobivalnik dokumentov, poleg tehnik, kot je kontekstualno stiskanje, da se razvijalcem omogoči izboljšanje obstoječih generativnih aplikacij AI.
Pregled rešitev
V tem prispevku prikazujemo uporabo generiranja besedila Mixtral-8x7B Instruct v kombinaciji z modelom vdelave BGE Large En za učinkovito izdelavo sistema RAG QnA na prenosnem računalniku Amazon SageMaker z uporabo nadrejenega orodja za pridobivanje dokumentov in tehnike kontekstualnega stiskanja. Naslednji diagram ponazarja arhitekturo te rešitve.
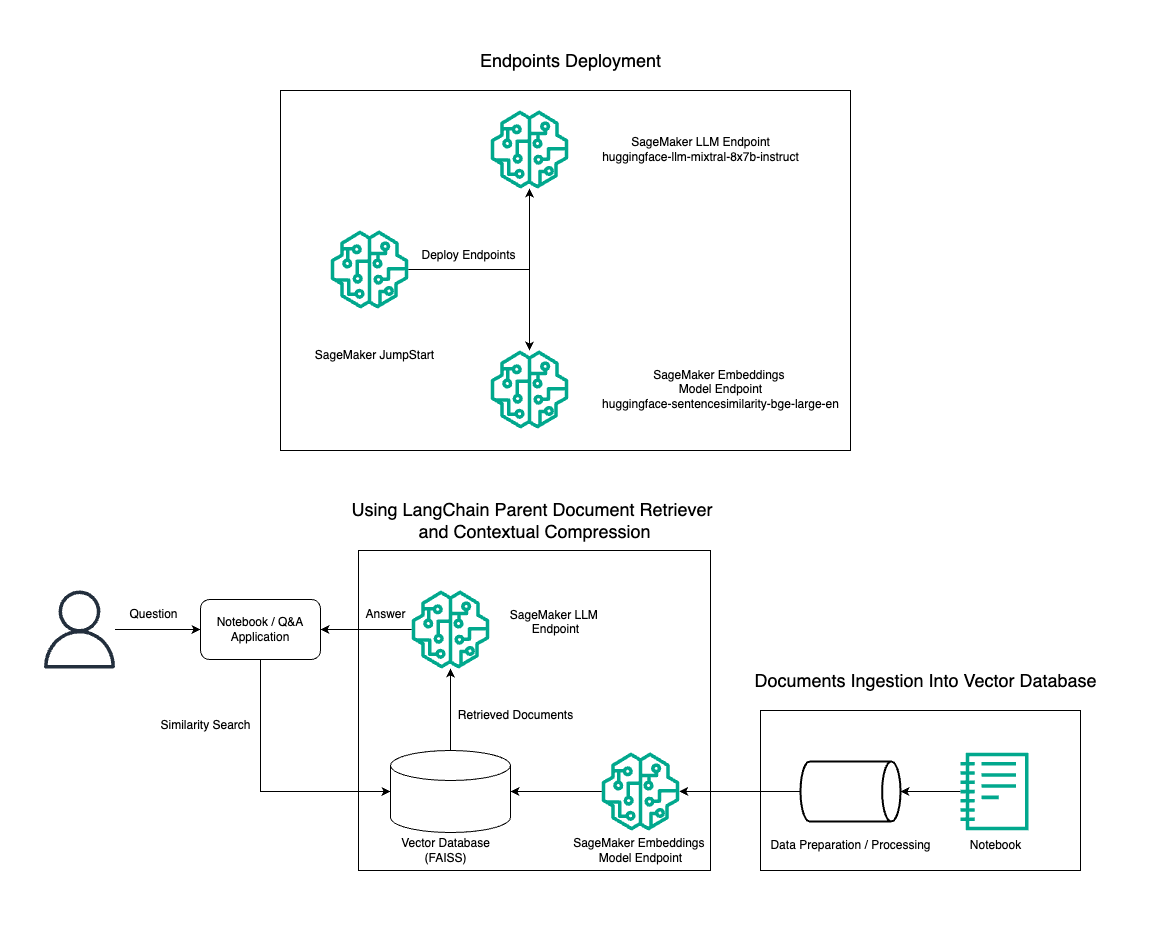
To rešitev lahko uvedete z le nekaj kliki z uporabo Amazon SageMaker JumpStart, popolnoma upravljana platforma, ki ponuja najsodobnejše modele temeljev za različne primere uporabe, kot so pisanje vsebine, ustvarjanje kode, odgovarjanje na vprašanja, pisanje besedil, povzemanje, klasifikacija in iskanje informacij. Zagotavlja zbirko vnaprej usposobljenih modelov, ki jih lahko uvedete hitro in z lahkoto ter pospešite razvoj in uvajanje aplikacij strojnega učenja (ML). Ena od ključnih komponent SageMaker JumpStart je Model Hub, ki ponuja obsežen katalog vnaprej pripravljenih modelov, kot je Mixtral-8x7B, za različne naloge.
Mixtral-8x7B uporablja arhitekturo MoE. Ta arhitektura omogoča, da se različni deli nevronske mreže specializirajo za različne naloge, s čimer se delovna obremenitev učinkovito razdeli med več strokovnjakov. Ta pristop omogoča učinkovito usposabljanje in uvajanje večjih modelov v primerjavi s tradicionalnimi arhitekturami.
Ena od glavnih prednosti arhitekture MoE je njena razširljivost. Z razdelitvijo delovne obremenitve na več strokovnjakov je mogoče modele MoE usposobiti na večjih nizih podatkov in doseči boljšo učinkovitost kot tradicionalni modeli enake velikosti. Poleg tega so lahko modeli MoE učinkovitejši med sklepanjem, ker je treba za dani vnos aktivirati samo podmnožico strokovnjakov.
Za več informacij o Mixtral-8x7B Instruction on AWS glejte Mixtral-8x7B je zdaj na voljo v Amazon SageMaker JumpStart. Model Mixtral-8x7B je na voljo pod permisivno licenco Apache 2.0 za uporabo brez omejitev.
V tej objavi razpravljamo o tem, kako lahko uporabite LangChain za ustvarjanje učinkovitih in učinkovitejših aplikacij RAG. LangChain je odprtokodna knjižnica Python, zasnovana za izdelavo aplikacij z LLM. Zagotavlja modularen in prilagodljiv okvir za kombiniranje LLM z drugimi komponentami, kot so baze znanja, sistemi za iskanje in druga orodja AI, za ustvarjanje zmogljivih in prilagodljivih aplikacij.
Sprehodimo se skozi gradnjo cevovoda RAG na SageMakerju z Mixtral-8x7B. Uporabljamo model generiranja besedila Mixtral-8x7B Instruct z modelom vdelave BGE Large En za ustvarjanje učinkovitega sistema QnA z uporabo RAG na prenosnem računalniku SageMaker. Primerek ml.t3.medium uporabljamo za predstavitev uvajanja LLM-jev prek SageMaker JumpStart, do katerega je mogoče dostopati prek končne točke API-ja, ki jo ustvari SageMaker. Ta nastavitev omogoča raziskovanje, eksperimentiranje in optimizacijo naprednih tehnik RAG z LangChain. Ilustriramo tudi integracijo shrambe FAISS Embedding v potek dela RAG, pri čemer poudarjamo njeno vlogo pri shranjevanju in pridobivanju vdelav za izboljšanje zmogljivosti sistema.
Izvedemo kratek sprehod po prenosnem računalniku SageMaker. Za podrobnejša navodila in navodila po korakih glejte Napredni vzorci RAG z Mixtralom na repo SageMaker Jumpstart GitHub.
Potreba po naprednih vzorcih RAG
Napredni vzorci RAG so bistveni za izboljšanje trenutnih zmogljivosti LLM-jev pri obdelavi, razumevanju in ustvarjanju besedila, podobnega človeku. Ker se velikost in kompleksnost dokumentov povečujeta, lahko predstavljanje več vidikov dokumenta v eni vdelavi povzroči izgubo specifičnosti. Čeprav je bistveno zajeti splošno bistvo dokumenta, je enako pomembno prepoznati in predstaviti različne podkontekste v njem. To je izziv, s katerim se pogosto srečujete pri delu z večjimi dokumenti. Drug izziv pri RAG je, da se pri pridobivanju ne zavedate posebnih poizvedb, ki jih bo obravnaval vaš sistem za shranjevanje dokumentov po zaužitju. To lahko vodi do tega, da so informacije, ki so najbolj pomembne za poizvedbo, zakopane pod besedilom (prelivanje konteksta). Če želite ublažiti napake in izboljšati obstoječo arhitekturo RAG, lahko uporabite napredne vzorce RAG (pridobitelj nadrejenega dokumenta in kontekstualno stiskanje), da zmanjšate napake pri pridobivanju, izboljšate kakovost odgovorov in omogočite obravnavanje kompleksnih vprašanj.
S tehnikami, obravnavanimi v tej objavi, lahko obravnavate ključne izzive, povezane z zunanjim iskanjem in integracijo znanja, kar vaši aplikaciji omogoča natančnejše in kontekstualno ozaveščene odzive.
V naslednjih razdelkih raziskujemo, kako nadrejeni prevzemniki dokumentov in kontekstualno stiskanje vam lahko pomaga pri reševanju nekaterih težav, o katerih smo razpravljali.
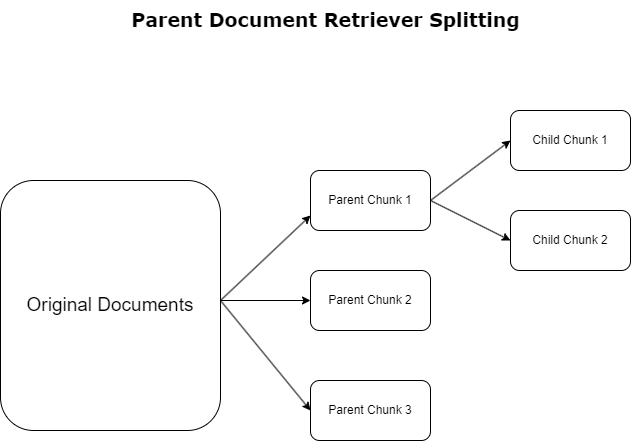
Nadrejeni prevzemnik dokumentov
V prejšnjem razdelku smo izpostavili izzive, s katerimi se srečujejo aplikacije RAG pri obravnavi obsežnih dokumentov. Za reševanje teh izzivov, nadrejeni prevzemniki dokumentov kategorizirati in označiti dohodne dokumente kot dokumenti staršev. Ti dokumenti so znani po svoji izčrpni naravi, vendar se ne uporabljajo neposredno v izvirni obliki za vdelave. Namesto da bi stisnili celoten dokument v eno vdelavo, pridobivalniki nadrejenih dokumentov te nadrejene dokumente razdelijo na otroški dokumenti. Vsak podrejeni dokument zajame različne vidike ali teme iz širšega nadrejenega dokumenta. Po identifikaciji teh podrejenih segmentov so vsakemu dodeljene posamezne vdelave, ki zajamejo njihovo specifično tematsko bistvo (glejte naslednji diagram). Med iskanjem se prikliče nadrejeni dokument. Ta tehnika zagotavlja ciljno usmerjene, a obsežne možnosti iskanja, ki LLM ponuja širšo perspektivo. Pridobevalci nadrejenih dokumentov nudijo LLM-jem dvojno prednost: specifičnost vdelav podrejenih dokumentov za natančno in relevantno pridobivanje informacij, skupaj s priklicem nadrejenih dokumentov za generiranje odziva, kar obogati rezultate LLM-ja s slojevitim in temeljitim kontekstom.
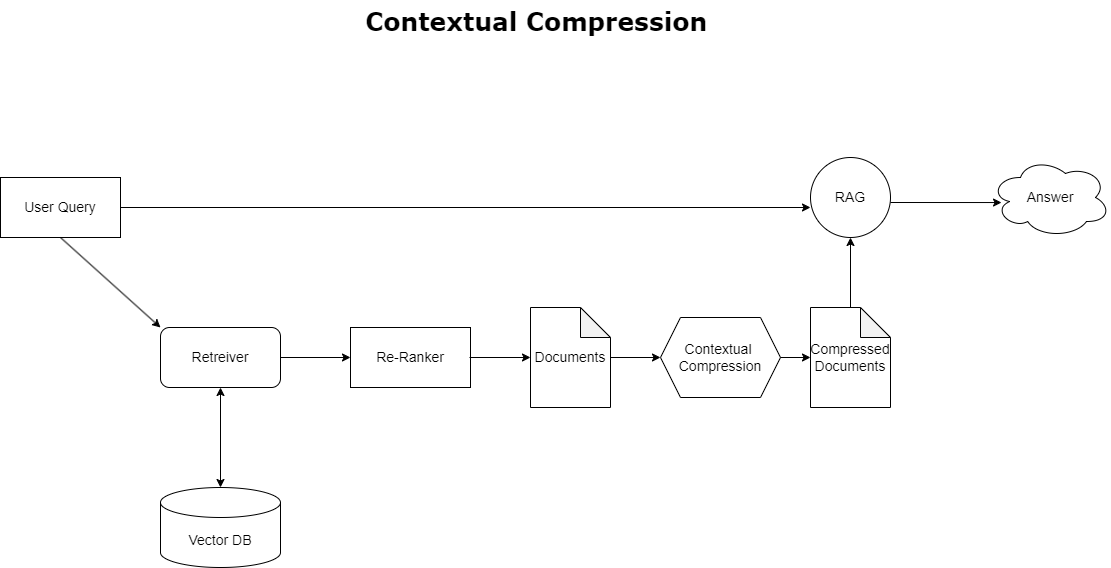
Kontekstualno stiskanje
Za reševanje vprašanja prelivanja konteksta, o katerem smo govorili prej, lahko uporabite kontekstualno stiskanje za stiskanje in filtriranje pridobljenih dokumentov v skladu s kontekstom poizvedbe, tako da se hranijo in obdelujejo le ustrezne informacije. To dosežemo s kombinacijo osnovnega pridobivalnika za začetno pridobivanje dokumentov in kompresorja dokumentov za izboljšanje teh dokumentov tako, da zmanjšamo njihovo vsebino ali jih v celoti izključimo na podlagi ustreznosti, kot je prikazano v naslednjem diagramu. Ta poenostavljeni pristop, ki ga olajša kontekstualni prenosnik stiskanja, močno poveča učinkovitost aplikacije RAG z zagotavljanjem metode za pridobivanje in uporabo samo tistega, kar je bistvenega pomena iz množice informacij. Neposredno se spopada s problemom preobremenjenosti z informacijami in nepomembne obdelave podatkov, kar vodi do izboljšane kakovosti odziva, stroškovno učinkovitejših LLM operacij in bolj gladkega splošnega postopka iskanja. V bistvu je to filter, ki prilagaja informacije poizvedbi, zaradi česar je zelo potrebno orodje za razvijalce, ki želijo optimizirati svoje aplikacije RAG za boljšo zmogljivost in zadovoljstvo uporabnikov.
Predpogoji
Če ste novi v SageMakerju, si oglejte Vodnik za razvoj Amazon SageMaker.
Preden začnete z rešitvijo, ustvarite račun AWS. Ko ustvarite račun AWS, dobite identiteto z enotno prijavo (SSO), ki ima popoln dostop do vseh storitev in virov AWS v računu. Ta identiteta se imenuje račun AWS root uporabnik.
Prijava v Konzola za upravljanje AWS uporaba e-poštnega naslova in gesla, ki ste ju uporabili za ustvarjanje računa, vam omogoča popoln dostop do vseh virov AWS v vašem računu. Močno priporočamo, da za vsakodnevna opravila, tudi skrbniška, ne uporabljate uporabnika root.
Namesto tega se držite najboljše varnostne prakse in AWS upravljanje identitete in dostopa (IAM) in ustvarite skrbniškega uporabnika in skupino. Nato varno zaklenite poverilnice korenskega uporabnika in jih uporabite za izvajanje le nekaj nalog upravljanja računa in storitev.
Model Mixtral-8x7b zahteva primerek ml.g5.48xlarge. SageMaker JumpStart ponuja poenostavljen način dostopa in uvajanja več kot 100 različnih odprtokodnih modelov in temeljnih modelov tretjih oseb. Da bi zaženite končno točko za gostovanje Mixtral-8x7B iz SageMaker JumpStart, boste morda morali zahtevati povečanje kvote storitev za dostop do primerka ml.g5.48xlarge za uporabo končne točke. Ti lahko zahtevajo povečanje kvote storitev preko konzole, Vmesnik ukazne vrstice AWS (AWS CLI) ali API za omogočanje dostopa do teh dodatnih virov.
Nastavite primerek prenosnika SageMaker in namestite odvisnosti
Za začetek ustvarite primerek prenosnika SageMaker in namestite zahtevane odvisnosti. Glejte na GitHub repo da zagotovite uspešno nastavitev. Ko nastavite primerek prenosnega računalnika, lahko razmestite model.
Prenosnik lahko zaženete tudi lokalno v svojem želenem integriranem razvojnem okolju (IDE). Prepričajte se, da imate nameščen Jupyter notebook lab.
Namestite model
Razmestite model Mixtral-8X7B Instruct LLM na SageMaker JumpStart:
Razmestite model vdelave BGE Large En na SageMaker JumpStart:
Nastavite LangChain
Po uvozu vseh potrebnih knjižnic in uvedbi modela Mixtral-8x7B in modela vdelav BGE Large En lahko zdaj nastavite LangChain. Za navodila po korakih glejte GitHub repo.
Priprava podatkov
V tej objavi uporabljamo večletna Amazonova pisma delničarjem kot besedilni korpus za izvajanje QnA. Za podrobnejše korake za pripravo podatkov glejte GitHub repo.
Odgovarjanje na vprašanje
Ko so podatki pripravljeni, lahko uporabite ovoj, ki ga nudi LangChain, ki ovije vektorsko shrambo in sprejme vhodne podatke za LLM. Ta ovoj izvaja naslednje korake:
- Vzemite vprašanje za vnos.
- Ustvarite vdelavo vprašanja.
- Pridobite ustrezne dokumente.
- Dokumente in vprašanje vključite v poziv.
- Prikličite model s pozivom in ustvarite odgovor na berljiv način.
Zdaj, ko je vektorska trgovina na mestu, lahko začnete postavljati vprašanja:
Običajna veriga prinašalca
V prejšnjem scenariju smo raziskali hiter in preprost način, da dobite odgovor na vaše vprašanje glede na kontekst. Zdaj pa si poglejmo bolj prilagodljivo možnost s pomočjo RetrievalQA, kjer lahko s parametrom chain_type prilagodite, kako naj bodo pridobljeni dokumenti dodani v poziv. Če želite nadzirati, koliko ustreznih dokumentov je treba pridobiti, lahko spremenite parameter k v naslednji kodi, da vidite različne rezultate. V mnogih scenarijih boste morda želeli vedeti, katere izvorne dokumente je LLM uporabil za ustvarjanje odgovora. Te dokumente lahko dobite v izhodu z uporabo return_source_documents, ki vrne dokumente, ki so dodani v kontekst poziva LLM. RetrievalQA vam omogoča tudi, da zagotovite predlogo poziva po meri, ki je lahko specifična za model.
Postavimo vprašanje:
Nadrejena veriga za pridobivanje dokumentov
Oglejmo si naprednejšo možnost RAG s pomočjo ParentDocumentRetriever. Pri delu s pridobivanjem dokumentov lahko naletite na kompromis med shranjevanjem majhnih kosov dokumenta za natančne vdelave in večjimi dokumenti za ohranitev več konteksta. Nadrejeni pridobivalnik dokumentov doseže to ravnotežje tako, da razdeli in shrani majhne koščke podatkov.
Uporabljamo a parent_splitter za razdelitev izvirnih dokumentov na večje dele, imenovane nadrejeni dokumenti in a child_splitter za ustvarjanje manjših podrejenih dokumentov iz izvirnih dokumentov:
Podrejeni dokumenti so nato indeksirani v vektorski shrambi z uporabo vdelav. To omogoča učinkovito iskanje ustreznih podrejenih dokumentov na podlagi podobnosti. Za pridobitev ustreznih informacij nadrejeni pridobivalnik dokumentov najprej pridobi podrejene dokumente iz vektorske shrambe. Nato poišče nadrejene ID-je za te podrejene dokumente in vrne ustrezne večje nadrejene dokumente.
Postavimo vprašanje:
Kontekstualna veriga stiskanja
Poglejmo še eno napredno možnost RAG, imenovano kontekstualno stiskanje. Eden od izzivov pri pridobivanju je, da običajno ne vemo, s kakšnimi specifičnimi poizvedbami se bo soočil vaš sistem za shranjevanje dokumentov, ko boste vnesli podatke v sistem. To pomeni, da so lahko informacije, ki so najbolj pomembne za poizvedbo, zakopane v dokumentu z veliko nepomembnega besedila. Posredovanje tega celotnega dokumenta skozi vašo aplikacijo lahko povzroči dražje klice LLM in slabše odzive.
Pridobivalnik s kontekstualnim stiskanjem obravnava izziv pridobivanja ustreznih informacij iz sistema za shranjevanje dokumentov, kjer so lahko ustrezni podatki zakopani v dokumentih, ki vsebujejo veliko besedila. S stiskanjem in filtriranjem pridobljenih dokumentov na podlagi danega konteksta poizvedbe se vrnejo samo najbolj ustrezne informacije.
Za uporabo kontekstualnega pridobivanja stiskanja boste potrebovali:
- Osnovni prinašalec – To je začetni pridobivalnik, ki na podlagi poizvedbe pridobi dokumente iz sistema za shranjevanje
- Kompresor dokumentov – Ta komponenta vzame prvotno pridobljene dokumente in jih skrajša tako, da zmanjša vsebino posameznih dokumentov ali v celoti izpusti nepomembne dokumente, pri čemer uporabi kontekst poizvedbe za določitev ustreznosti
Dodajanje kontekstnega stiskanja z ekstraktorjem verige LLM
Najprej ovijte svoj osnovni prinašalec z a ContextualCompressionRetriever. Dodali boste LLMChainExtractor, ki bo ponovil prvotno vrnjene dokumente in iz vsakega izvlekel samo vsebino, ki je pomembna za poizvedbo.
Inicializirajte verigo z uporabo ContextualCompressionRetriever s LLMChainExtractor in posredujte poziv prek chain_type_kwargs prepir.
Postavimo vprašanje:
Filtrirajte dokumente z verižnim filtrom LLM
O LLMChainFilter je nekoliko enostavnejši, a robustnejši kompresor, ki uporablja verigo LLM, da se odloči, katere od prvotno pridobljenih dokumentov filtrirati in katere vrniti, ne da bi spreminjal vsebino dokumenta:
Inicializirajte verigo z uporabo ContextualCompressionRetriever s LLMChainFilter in posredujte poziv prek chain_type_kwargs prepir.
Postavimo vprašanje:
Primerjaj rezultate
Naslednja tabela primerja rezultate različnih poizvedb glede na tehniko.
| Tehnika | Poizvedba 1 | Poizvedba 2 | Primerjava |
| Kako se je razvil AWS? | Zakaj je Amazon uspešen? | ||
| Regular Retriever Chain Output | AWS (Amazon Web Services) se je iz prvotno nedonosne naložbe razvil v posel z 85 milijardami dolarjev letnega prihodka z visoko dobičkonosnostjo, ki ponuja široko paleto storitev in funkcij ter je postal pomemben del Amazonovega portfelja. Kljub soočanju s skepticizmom in kratkoročnimi težavami je AWS nadaljeval z inovacijami, privabljal nove stranke in selil aktivne stranke ter ponujal prednosti, kot so okretnost, inovativnost, stroškovna učinkovitost in varnost. AWS je prav tako razširil svoje dolgoročne naložbe, vključno z razvojem čipov, da bi zagotovil nove zmogljivosti in spremenil, kar je mogoče za svoje stranke. | Amazon je uspešen zaradi nenehnih inovacij in širitve na nova področja, kot so storitve tehnološke infrastrukture, digitalne bralne naprave, glasovno vodeni osebni pomočniki in novi poslovni modeli, kot je trg tretjih oseb. K njegovemu uspehu prispeva tudi njegova zmožnost hitrega obsega poslovanja, kar je razvidno iz hitre širitve njegovih mrež za dostavo in transport. Poleg tega je Amazonova osredotočenost na optimizacijo in povečanje učinkovitosti v svojih procesih privedla do izboljšav produktivnosti in znižanja stroškov. Primer Amazon Business poudarja zmožnost podjetja, da izkoristi prednosti e-trgovine in logistike v različnih sektorjih. | Na podlagi odgovorov iz navadne verige prinašalcev opazimo, da čeprav zagotavlja dolge odgovore, trpi zaradi prelivanja konteksta in ne omenja nobenih pomembnih podrobnosti iz korpusa v zvezi z odgovorom na dano poizvedbo. Redna veriga iskanja ne more zajeti nians s poglobljenim ali kontekstualnim vpogledom, kar bi lahko izpustilo kritične vidike dokumenta. |
| Parent Document Retriever Izhod | AWS (Amazon Web Services) se je leta 2 začel s prvotno uvedbo storitve Elastic Compute Cloud (EC2006), ki je imela slabe funkcije in je zagotavljala samo eno velikost primerka, v enem podatkovnem centru, v eni regiji sveta, samo z instancami operacijskega sistema Linux. , in brez številnih ključnih funkcij, kot so spremljanje, uravnoteženje obremenitve, samodejno skaliranje ali trajno shranjevanje. Vendar jim je uspeh AWS omogočil, da so hitro ponovili in dodali manjkajoče zmogljivosti, sčasoma pa so se razširili na ponudbo različnih okusov, velikosti in optimizacij računalništva, shranjevanja in mreženja ter razvili lastne čipe (Graviton) za nadaljnje dvigovanje cene in zmogljivosti. . Iterativni inovacijski proces AWS je zahteval znatne naložbe v finančne vire in vire ljudi v 20 letih, pogosto precej pred časom izplačila, da bi izpolnili potrebe strank in izboljšali dolgoročne izkušnje strank, zvestobo in donose za delničarje. | Amazon je uspešen zaradi svoje sposobnosti nenehnega inoviranja, prilagajanja spreminjajočim se tržnim razmeram in zadovoljevanja potreb strank v različnih segmentih trga. To je razvidno iz uspeha Amazon Business, ki je dosegel približno 35 milijard dolarjev letne bruto prodaje z zagotavljanjem izbire, vrednosti in udobja poslovnim strankam. Amazonove naložbe v e-trgovino in logistične zmogljivosti so prav tako omogočile ustvarjanje storitev, kot je Buy with Prime, ki pomaga trgovcem s spletnimi mesti, ki so namenjena neposrednim uporabnikom, pri pretvorbi iz ogledov v nakupe. | Pridobitelj nadrejenega dokumenta se poglobi v posebnosti strategije rasti AWS, vključno s ponavljajočim se postopkom dodajanja novih funkcij na podlagi povratnih informacij strank in podrobnega potovanja od začetne uvedbe s pomanjkljivimi funkcijami do prevladujočega položaja na trgu, hkrati pa zagotavlja odziv, bogat s kontekstom. . Odzivi pokrivajo široko paleto vidikov, od tehničnih inovacij in tržne strategije do organizacijske učinkovitosti in osredotočenosti na stranke, ter zagotavljajo celovit pogled na dejavnike, ki prispevajo k uspehu, skupaj s primeri. To lahko pripišemo ciljanim, a širokim zmožnostim iskanja nadrejenega pridobivalnika dokumentov. |
| LLM Chain Extractor: Kontekstualni izhod stiskanja | AWS se je razvil tako, da se je začel kot majhen projekt znotraj Amazona, ki je zahteval znatne kapitalske naložbe in se soočal s skepticizmom znotraj in zunaj podjetja. Vendar je imel AWS prednost pred potencialnimi konkurenti in je verjel v vrednost, ki jo lahko prinese strankam in Amazonu. AWS se je dolgoročno zavezal, da bo nadaljeval z vlaganjem, kar je privedlo do več kot 3,300 novih funkcij in storitev, uvedenih leta 2022. AWS je preoblikoval način, kako stranke upravljajo svojo tehnološko infrastrukturo, in postal podjetje z 85 milijardami dolarjev letnega prihodka z visoko dobičkonosnostjo. AWS prav tako nenehno izboljšuje svoje ponudbe, kot je izboljšava EC2 z dodatnimi funkcijami in storitvami po njegovi prvi uvedbi. | Na podlagi podanega konteksta lahko Amazonov uspeh pripišemo njegovi strateški širitvi s platforme za prodajo knjig na globalni trg z živahnim ekosistemom prodajalcev tretjih oseb, zgodnjim naložbam v AWS, inovacijam pri uvajanju Kindle in Alexa ter znatni rasti letnih prihodkov od leta 2019 do leta 2022. Ta rast je privedla do razširitve odtisa centrov za dostavo, oblikovanja transportnega omrežja zadnje milje in izgradnje novega omrežja sortirnih centrov, ki so bili optimizirani za produktivnost in zmanjšanje stroškov. | Verižni ekstraktor LLM ohranja ravnovesje med celovitim pokrivanjem ključnih točk in izogibanjem nepotrebni globini. Dinamično se prilagaja kontekstu poizvedbe, tako da je rezultat neposredno relevanten in celovit. |
| Verižni filter LLM: Kontekstualni kompresijski izhod | AWS (Spletne storitve Amazon) so se razvile tako, da so bile na začetku uvedene s slabimi funkcijami, a so se hitro ponavljale na podlagi povratnih informacij strank, da bi dodale potrebne zmogljivosti. Ta pristop je AWS omogočil, da je leta 2 lansiral EC2006 z omejenimi funkcijami in nato nenehno dodajal nove funkcionalnosti, kot so dodatne velikosti primerkov, podatkovni centri, regije, možnosti operacijskega sistema, orodja za spremljanje, uravnoteženje obremenitve, samodejno skaliranje in trajno shranjevanje. Sčasoma se je AWS iz storitve s slabimi funkcijami preoblikoval v več milijard dolarjev vredno podjetje z osredotočanjem na potrebe strank, okretnost, inovativnost, stroškovno učinkovitost in varnost. AWS ima zdaj 85 milijard dolarjev letnega prihodka in vsako leto ponuja več kot 3,300 novih funkcij in storitev, ki skrbijo za širok krog strank od novoustanovljenih podjetij do multinacionalnih podjetij in organizacij javnega sektorja. | Amazon je uspešen zaradi svojih inovativnih poslovnih modelov, nenehnega tehnološkega napredka in strateških organizacijskih sprememb. Podjetje je nenehno motilo tradicionalne industrije z uvajanjem novih zamisli, kot so platforma za e-trgovino za različne izdelke in storitve, tržnica tretjih oseb, infrastrukturne storitve v oblaku (AWS), e-bralnik Kindle in osebni pomočnik Alexa z glasovnim upravljanjem. . Poleg tega je Amazon izvedel strukturne spremembe, da bi izboljšal svojo učinkovitost, kot je reorganizacija svoje mreže dostave v ZDA, da bi zmanjšal stroške in čas dostave, kar je dodatno prispevalo k njegovemu uspehu. | Podobno kot verižni ekstraktor LLM tudi verižni filter LLM zagotavlja, da je rezultat učinkovit za stranke, ki iščejo jedrnate in kontekstualne odgovore, čeprav so zajete ključne točke. |
Če primerjamo te različne tehnike, lahko vidimo, da v kontekstih, kot je opis prehoda AWS iz preproste storitve v zapleteno, več milijard dolarjev vredno organizacijo ali razlaga strateških uspehov Amazona, navadni verigi prinašalcev manjka natančnost, ki jo ponujajo bolj sofisticirane tehnike, kar vodi do manj ciljanih informacij. Čeprav je med obravnavanimi naprednimi tehnikami vidnih zelo malo razlik, so veliko bolj informativne kot običajne verige prinašalcev.
Za stranke v panogah, kot so zdravstvo, telekomunikacije in finančne storitve, ki želijo implementirati RAG v svoje aplikacije, je zaradi omejitev običajne verige pridobivanja pri zagotavljanju natančnosti, izogibanju odvečnosti in učinkovitem stiskanju informacij manj primerna za izpolnjevanje teh potreb v primerjavi z do naprednejših nadrejenih tehnik pridobivanja dokumentov in kontekstnega stiskanja. Te tehnike lahko destilirajo ogromne količine informacij v koncentrirane, učinkovite vpoglede, ki jih potrebujete, hkrati pa pomagajo izboljšati ceno in učinkovitost.
Čiščenje
Ko končate z izvajanjem zvezka, izbrišite vire, ki ste jih ustvarili, da se izognete nastanku stroškov za vire v uporabi:
zaključek
V tej objavi smo predstavili rešitev, ki vam omogoča implementacijo nadrejenega pridobivalnika dokumentov in verižnih tehnik kontekstualnega stiskanja za izboljšanje zmožnosti LLM za obdelavo in ustvarjanje informacij. Te napredne tehnike RAG smo preizkusili z modeloma Mixtral-8x7B Instruct in BGE Large En, ki sta na voljo s SageMaker JumpStart. Raziskali smo tudi uporabo obstojnega pomnilnika za vdelave in dele dokumentov ter integracijo s shrambami podatkov podjetja.
Tehnike, ki smo jih izvedli, ne samo izboljšajo način, na katerega modeli LLM dostopajo do zunanjega znanja in ga vključijo, temveč tudi bistveno izboljšajo kakovost, ustreznost in učinkovitost njihovih rezultatov. S kombiniranjem pridobivanja iz velikih besedilnih korpusov z zmožnostmi generiranja jezika te napredne tehnike RAG omogočajo LLM-jem, da ustvarijo bolj dejanske, koherentne in kontekstu primernejše odzive, kar izboljša njihovo učinkovitost pri različnih nalogah obdelave naravnega jezika.
SageMaker JumpStart je središče te rešitve. S SageMaker JumpStart pridobite dostop do obsežnega izbora odprtokodnih in zaprtokodnih modelov, kar poenostavi postopek začetka uporabe ML in omogoča hitro eksperimentiranje in uvajanje. Če želite začeti uvajati to rešitev, se pomaknite do zvezka v GitHub repo.
O avtorjih
 Niithiyn Vijeaswaran je arhitekt rešitev pri AWS. Njegovo področje osredotočanja so generativni AI in pospeševalniki AI AWS. Po izobrazbi je diplomirani inženir računalništva in bioinformatike. Niithiyn tesno sodeluje z ekipo Generative AI GTM, da omogoči strankam AWS na več frontah in pospeši njihovo sprejemanje generativne umetne inteligence. Je navdušen navijač Dallas Mavericks in uživa v zbiranju superg.
Niithiyn Vijeaswaran je arhitekt rešitev pri AWS. Njegovo področje osredotočanja so generativni AI in pospeševalniki AI AWS. Po izobrazbi je diplomirani inženir računalništva in bioinformatike. Niithiyn tesno sodeluje z ekipo Generative AI GTM, da omogoči strankam AWS na več frontah in pospeši njihovo sprejemanje generativne umetne inteligence. Je navdušen navijač Dallas Mavericks in uživa v zbiranju superg.
 Sebastian Bustillo je arhitekt rešitev pri AWS. Osredotoča se na tehnologije AI/ML z globoko strastjo do generativne AI in računalniških pospeševalnikov. Pri AWS strankam pomaga odkleniti poslovno vrednost prek generativne umetne inteligence. Ko ni v službi, uživa v kuhanju popolne skodelice specialty kave in raziskuje svet s svojo ženo.
Sebastian Bustillo je arhitekt rešitev pri AWS. Osredotoča se na tehnologije AI/ML z globoko strastjo do generativne AI in računalniških pospeševalnikov. Pri AWS strankam pomaga odkleniti poslovno vrednost prek generativne umetne inteligence. Ko ni v službi, uživa v kuhanju popolne skodelice specialty kave in raziskuje svet s svojo ženo.
 Armando Diaz je arhitekt rešitev pri AWS. Osredotoča se na generativno umetno inteligenco, umetno inteligenco/ML in analitiko podatkov. Pri AWS Armando strankam pomaga pri integraciji najsodobnejših generativnih zmogljivosti umetne inteligence v njihove sisteme, s čimer spodbuja inovacije in konkurenčno prednost. Ko ni v službi, rad preživlja čas z ženo in družino, hodi na pohode in potuje po svetu.
Armando Diaz je arhitekt rešitev pri AWS. Osredotoča se na generativno umetno inteligenco, umetno inteligenco/ML in analitiko podatkov. Pri AWS Armando strankam pomaga pri integraciji najsodobnejših generativnih zmogljivosti umetne inteligence v njihove sisteme, s čimer spodbuja inovacije in konkurenčno prednost. Ko ni v službi, rad preživlja čas z ženo in družino, hodi na pohode in potuje po svetu.
 Dr. Farooq Sabir je višji strokovnjak za rešitve za umetno inteligenco in strojno učenje pri AWS. Ima doktorat in magisterij iz elektrotehnike na Univerzi v Teksasu v Austinu in magisterij iz računalništva na Georgia Institute of Technology. Ima več kot 15 let delovnih izkušenj, rad pa tudi poučuje in mentorira študente. Pri AWS strankam pomaga oblikovati in reševati njihove poslovne probleme na področju podatkovne znanosti, strojnega učenja, računalniškega vida, umetne inteligence, numerične optimizacije in sorodnih področij. S sedežem v Dallasu v Teksasu on in njegova družina radi potujejo in se odpravijo na dolga potovanja.
Dr. Farooq Sabir je višji strokovnjak za rešitve za umetno inteligenco in strojno učenje pri AWS. Ima doktorat in magisterij iz elektrotehnike na Univerzi v Teksasu v Austinu in magisterij iz računalništva na Georgia Institute of Technology. Ima več kot 15 let delovnih izkušenj, rad pa tudi poučuje in mentorira študente. Pri AWS strankam pomaga oblikovati in reševati njihove poslovne probleme na področju podatkovne znanosti, strojnega učenja, računalniškega vida, umetne inteligence, numerične optimizacije in sorodnih področij. S sedežem v Dallasu v Teksasu on in njegova družina radi potujejo in se odpravijo na dolga potovanja.
 Marko Punio je arhitekt rešitev, ki se osredotoča na generativno strategijo umetne inteligence, uporabne rešitve umetne inteligence in izvaja raziskave za pomoč strankam pri hiperrazširjanju na AWS. Marco je svetovalec za digitalni izvorni oblak z izkušnjami na področju finančne tehnologije, zdravstva in znanosti o življenju, programske opreme kot storitve in nazadnje v telekomunikacijski industriji. Je kvalificiran tehnolog s strastjo do strojnega učenja, umetne inteligence ter združitev in prevzemov. Marco živi v Seattlu, WA in v prostem času rad piše, bere, telovadi in gradi aplikacije.
Marko Punio je arhitekt rešitev, ki se osredotoča na generativno strategijo umetne inteligence, uporabne rešitve umetne inteligence in izvaja raziskave za pomoč strankam pri hiperrazširjanju na AWS. Marco je svetovalec za digitalni izvorni oblak z izkušnjami na področju finančne tehnologije, zdravstva in znanosti o življenju, programske opreme kot storitve in nazadnje v telekomunikacijski industriji. Je kvalificiran tehnolog s strastjo do strojnega učenja, umetne inteligence ter združitev in prevzemov. Marco živi v Seattlu, WA in v prostem času rad piše, bere, telovadi in gradi aplikacije.
 AJ Dhimine je arhitekt rešitev pri AWS. Specializiran je za generativno umetno inteligenco, brezstrežniško računalništvo in podatkovno analitiko. Je aktiven član/mentor v skupnosti tehničnega področja strojnega učenja in je objavil več znanstvenih člankov o različnih temah AI/ML. Sodeluje s strankami, od novoustanovljenih podjetij do podjetij, pri razvoju generativnih rešitev AI AWSome. Še posebej se navdušuje nad uporabo velikih jezikovnih modelov za napredno podatkovno analitiko in raziskovanjem praktičnih aplikacij, ki obravnavajo izzive v resničnem svetu. Zunaj dela AJ uživa v potovanjih in je trenutno v 53 državah s ciljem obiskati vsako državo na svetu.
AJ Dhimine je arhitekt rešitev pri AWS. Specializiran je za generativno umetno inteligenco, brezstrežniško računalništvo in podatkovno analitiko. Je aktiven član/mentor v skupnosti tehničnega področja strojnega učenja in je objavil več znanstvenih člankov o različnih temah AI/ML. Sodeluje s strankami, od novoustanovljenih podjetij do podjetij, pri razvoju generativnih rešitev AI AWSome. Še posebej se navdušuje nad uporabo velikih jezikovnih modelov za napredno podatkovno analitiko in raziskovanjem praktičnih aplikacij, ki obravnavajo izzive v resničnem svetu. Zunaj dela AJ uživa v potovanjih in je trenutno v 53 državah s ciljem obiskati vsako državo na svetu.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

