Predstavitev
Ta članek bo predstavil koncept modeliranja podatkov, ključnega procesa, ki opisuje, kako se podatki shranjujejo, organizirajo in do njih dostopa znotraj baze podatkov ali podatkovnega sistema. Vključuje pretvorbo resničnih poslovnih potreb v logično in strukturirano obliko, ki jo je mogoče realizirati v bazi podatkov ali skladišču podatkov. Raziskali bomo, kako podatkovno modeliranje ustvari konceptualni okvir za razumevanje odnosov in medsebojnih povezav podatkov znotraj organizacije ali specifične domene. Poleg tega bomo razpravljali o pomembnosti oblikovanja podatkovnih struktur in odnosov za zagotovitev učinkovitega shranjevanja, iskanja in manipulacije podatkov.

Primeri uporabe podatkovnega modeliranja
Modeliranje podatkov je temeljno pri upravljanju in učinkoviti uporabi podatkov v različnih scenarijih. Tukaj je nekaj tipičnih primerov uporabe za modeliranje podatkov, vsak je podrobno razložen:
Pridobivanje podatkov
Pri modeliranju podatkov pridobivanje podatkov vključuje definiranje, kako se podatki zbirajo ali ustvarjajo iz različnih virov. Ta faza vključuje vzpostavitev potrebne podatkovne strukture za shranjevanje vhodnih podatkov, s čimer se zagotovi, da jih je mogoče integrirati in učinkovito shraniti. Z modeliranjem podatkov na tej stopnji lahko organizacije zagotovijo, da so zbrani podatki strukturirani v skladu z njihovimi analitičnimi potrebami in poslovnimi procesi. Pomaga prepoznati vrsto potrebnih podatkov, obliko, v kateri naj bodo, in kako bodo obdelani za nadaljnjo uporabo.
Nalaganje podatkov
Ko so podatki pridobljeni, jih je treba naložiti v ciljni sistem, kot je baza podatkov, podatkovno skladiščeali podatkovno jezero. Modeliranje podatkov igra tukaj ključno vlogo z definiranjem sheme ali strukture, v katero bodo podatki vstavljeni. To vključuje določanje, kako bodo podatki iz različnih virov preslikani v tabele in stolpce baze podatkov, ter nastavitev razmerij med različnimi podatkovnimi entitetami. Pravilno modeliranje podatkov zagotavlja optimalno nalaganje podatkov, kar omogoča učinkovito shranjevanje, dostop in izvajanje poizvedb.
Poslovni izračun
Modeliranje podatkov je sestavni del postavljanja okvirov za poslovne izračune. Ti izračuni ustvarjajo vpoglede, meritve in ključne kazalnike uspešnosti (KPI) iz shranjenih podatkov. Z vzpostavitvijo jasnega podatkovnega modela lahko organizacije definirajo, kako je mogoče podatke iz različnih virov združevati, preoblikovati in analizirati za izvajanje kompleksnih poslovnih izračunov. To zagotavlja, da osnovni podatki podpirajo smiselno in natančno izpeljavo Poslovna inteligenca, ki lahko vodijo odločanje in strateško načrtovanje.
distribucija
Faza distribucije daje obdelane podatke na voljo končnim uporabnikom ali drugim sistemom za analizo, poročanje in odločanje. Modeliranje podatkov na tej stopnji se osredotoča na zagotavljanje, da so podatki strukturirani in oblikovani na načine, ki so dostopni in razumljivi ciljnemu občinstvu. To bi lahko vključevalo modeliranje podatkov v dimenzionalne sheme za uporabo v orodjih poslovne inteligence, ustvarjanje API-jev za programski dostop ali definiranje izvoznih formatov za skupno rabo podatkov. Učinkovito modeliranje podatkov zagotavlja, da se lahko podatki enostavno distribuirajo in uporabljajo na različnih platformah in s strani različnih zainteresiranih strani, kar povečuje njihovo uporabnost in vrednost.
Vsak od teh primerov uporabe ponazarja pomen v celotnem življenjskem ciklu podatkov, od zbiranja in shranjevanja do analize in distribucije. S skrbnim načrtovanjem podatkovnih struktur in odnosov na vsaki stopnji lahko organizacije zagotovijo, da njihova podatkovna arhitektura učinkovito in uspešno podpira njihove operativne in analitične potrebe.
Podatkovni inženirji/modelarji
Podatkovni inženirji in Data Modelers igrajo ključno vlogo pri upravljanju in analizi podatkov, pri čemer vsak prispeva edinstvene veščine in strokovno znanje za izkoriščanje moči podatkov v organizaciji. Razumevanje vlog in odgovornosti drug drugega lahko pomaga razjasniti, kako sodelujeta pri izgradnji in vzdrževanju robustnih podatkovnih infrastruktur.
Podatkovni inženirji
Podatkovni inženirji so odgovorni za načrtovanje, gradnjo in vzdrževanje sistemov in arhitektur, ki omogočajo učinkovito ravnanje s podatki in dostopnost do njih. Njihova vloga pogosto vključuje:
- Gradnja in vzdrževanje podatkovnih cevovodov: Ustvarjajo infrastrukturo za pridobivanje, preoblikovanje in nalaganje podatkov (ETL) iz različnih virov.
- Shranjevanje in upravljanje podatkov: Oblikujejo in izvajajo sisteme podatkovnih baz, podatkovna jezera in druge rešitve za shranjevanje, da so podatki organizirani in dostopni.
- Optimizacija delovanja: Podatkovni inženirji si prizadevajo zagotoviti učinkovito delovanje podatkovnih procesov, pogosto z optimizacijo shranjevanja podatkov in izvajanja poizvedb.
- Sodelovanje z deležniki: Tesno sodelujejo s poslovnimi analitiki, podatkovnimi znanstveniki in drugimi uporabniki, da bi razumeli potrebe po podatkih in implementirali rešitve, ki omogočajo sprejemanje odločitev na podlagi podatkov.
- Zagotavljanje kakovosti in celovitosti podatkov: Izvajajo sisteme in procese za spremljanje, potrjevanje in čiščenje podatkov, s čimer uporabnikom zagotavljajo dostop do zanesljivih in točnih informacij.
Oblikovalci podatkov
Modelerji podatkov se osredotočajo na oblikovanje načrta za sistemi za upravljanje podatkov. Njihovo delo vključuje razumevanje poslovnih zahtev in njihovo prevajanje v podatkovne strukture, ki podpirajo učinkovito shranjevanje, iskanje in analizo podatkov. Ključne odgovornosti vključujejo:
- Razvoj konceptualnih, logičnih in fizičnih podatkovnih modelov: Ustvarjajo modele, ki določajo, kako so podatki povezani in kako bodo shranjeni v bazah podatkov.
- Definiranje podatkovnih entitet in odnosov: Modelerji podatkov identificirajo ključne entitete, ki jih mora podatkovni sistem organizacije predstavljati, in definirajo, kako so te entitete med seboj povezane.
- Zagotavljanje doslednosti in standardizacije podatkov: Vzpostavljajo konvencije o poimenovanju in standarde za podatkovne elemente, da zagotovijo doslednost v celotni organizaciji.
- Sodelovanje s podatkovnimi inženirji in arhitekti: Data Modelers tesno sodelujejo s Data Engineers, da zagotovijo, da podatkovna arhitektura učinkovito podpira zasnovane modele.
- Upravljanje podatkov in strategija: Pogosto igrajo vlogo pri upravljanju podatkov, saj pomagajo opredeliti politike in standarde za upravljanje podatkov v organizaciji.
Čeprav se veščine in naloge podatkovnih inženirjev in oblikovalcev podatkov nekoliko prekrivajo, se obe vlogi dopolnjujeta. Podatkovni inženirji se osredotočajo na izgradnjo in vzdrževanje infrastrukture, ki podpira shranjevanje in dostop do podatkov, medtem ko Data Modelerji oblikujejo strukturo in organizacijo podatkov znotraj teh sistemov. Zagotavljajo, da je podatkovna arhitektura organizacije robustna, razširljiva in usklajena s poslovnimi cilji, kar omogoča učinkovito odločanje na podlagi podatkov.
Ključne komponente podatkovnega modeliranja
Modeliranje podatkov je kritičen proces pri načrtovanju in izvajanju baz podatkov in podatkovnih sistemov, ki so učinkoviti, razširljivi in sposobni izpolniti zahteve različnih aplikacij. Ključne komponente vključujejo entitete, atribute, relacije in ključe. Razumevanje teh komponent je bistveno za ustvarjanje skladnega in funkcionalnega podatkovnega modela.
Subjekti
Entiteta predstavlja stvarni predmet ali koncept, ki ga je mogoče jasno identificirati. V bazi podatkov se entiteta pogosto prevede v tabelo. Entitete se uporabljajo za kategorizacijo informacij, ki jih želimo shraniti. Na primer, v sistemu za upravljanje odnosov s strankami (CRM) tipične entitete lahko vključujejo `Stranka`, `Naročilo` in Product.
Lastnosti
Atributi so lastnosti ali značilnosti entitete. Zagotavljajo podrobnosti o entiteti in jo pomagajo podrobneje opisati. V tabeli baze podatkov atributi predstavljajo stolpce. Za entiteto `Customer` lahko atributi vključujejo `CustomerID`, `Name`, `Address`, `Phone Number` itd. Atributi določajo vrsto podatkov (kot je celo število, niz, datum itd.), shranjenih za vsako entiteto primerek.
Razmerja
Odnosi opisujejo, kako so entitete v sistemu povezane med seboj in predstavljajo njihove interakcije. Obstaja več vrst odnosov:
- Ena proti ena (1:1): Vsak primerek entitete A je povezan z enim in samo enim primerkom entitete B in obratno.
- Ena proti mnogo (1:N): Vsak primerek Entitete A je lahko povezan z nič, enim ali več primerki Entitete B, vendar je vsak primerek Entitete B povezan samo z enim primerkom Entitete A.
- Veliko proti mnogo (M:N): Vsak primerek Entitete A je lahko povezan z nič, enim ali več primerki Entitete B, vsak primerek Entitete B pa je lahko povezan z nič, enim ali več primerki Entitete A.
Relacije so ključne za povezovanje podatkov, shranjenih v različnih entitetah, kar olajša pridobivanje podatkov in poročanje v več tabelah.
Tipke
Ključi so posebni atributi, ki se uporabljajo za edinstveno identifikacijo zapisov v tabeli in vzpostavljanje odnosov med tabelami. Obstaja več vrst ključev:
- Primarni ključ: Stolpec ali niz stolpcev enolično identificira vsak zapis tabele. Dva zapisa ne moreta imeti enake vrednosti primarnega ključa v tabeli.
- Tuji ključ: Stolpec ali niz stolpcev v eni tabeli, ki se sklicuje na primarni ključ druge tabele. Tuji ključi se uporabljajo za vzpostavljanje in uveljavljanje odnosov med tabelami.
- Sestavljeni ključ: Kombinacija dveh ali več stolpcev v tabeli, ki se lahko uporabi za edinstveno identifikacijo vsakega zapisa v tabeli.
- Ključ kandidata: Kateri koli stolpec ali niz stolpcev, ki bi lahko veljal za primarni ključ v tabeli.
Razumevanje in pravilna implementacija teh ključnih komponent sta bistvena za ustvarjanje učinkovitih sistemov za shranjevanje, iskanje in upravljanje podatkov. Pravilno modeliranje podatkov vodi do dobro organiziranih in optimiziranih baz podatkov za zmogljivost in razširljivost, ki podpirajo potrebe tako razvijalcev kot končnih uporabnikov.
Faze podatkovnih modelov
Podatkovno modeliranje se običajno odvija v treh glavnih fazah: konceptualni podatkovni model, logični podatkovni model in fizični podatkovni model. Vsaka faza služi določenemu namenu in nadgrajuje prejšnjo za postopno preoblikovanje abstraktnih idej v konkretno zasnovo baze podatkov. Razumevanje teh faz je ključnega pomena za vsakogar, ki ustvarja ali upravlja podatkovne sisteme.
Konceptualni podatkovni model
Konceptualni podatkovni model je najbolj abstraktna raven podatkovnega modeliranja. Ta faza se osredotoča na definiranje entitet na visoki ravni in odnosov med njimi, ne da bi se spuščali v podrobnosti o tem, kako bodo podatki shranjeni. Primarni cilj je orisati glavne podatkovne objekte, pomembne za poslovno domeno, in njihove interakcije na način, ki ga razumejo netehnični deležniki. Ta model se pogosto uporablja za začetno načrtovanje in komunikacijo, premostitev poslovnih zahtev in tehnično izvedbo.
Ključne značilnosti vključujejo
- Identifikacija pomembnih entitet in njihovih odnosov.
- Na visoki ravni, pogosto z uporabo poslovne terminologije.
- Neodvisno od katerega koli sistema za upravljanje baz podatkov (DBMS) ali tehnologije.
Logični podatkovni model
Logični podatkovni model dodaja več podrobnosti konceptualnemu modelu, določa strukturo podatkovnih elementov in določa odnose med njimi. Vključuje definicijo entitet, atribute vsake entitete, primarne ključe in tuje ključe. Še vedno pa ostaja neodvisen od tehnologije, ki bo uporabljena za izvedbo. Logični model je bolj podroben in strukturiran kot konceptualni model in začne uvajati pravila in omejitve, ki urejajo podatke.
Ključne značilnosti vključujejo
- Podrobna definicija entitet, odnosov in atributov.
- Vključitev primarnih ključev in tujih ključev je potrebna za vzpostavitev odnosov.
- Postopki normalizacije se uporabljajo za zagotovitev celovitosti podatkov in zmanjšanje redundance.
- Še vedno neodvisno od specifične tehnologije DBMS.
Fizični podatkovni model
Fizični podatkovni model je najbolj podrobna faza in vključuje implementacijo podatkovnega modela znotraj določenega sistema za upravljanje baze podatkov. Ta model prevede logični podatkovni model v podrobno shemo, ki jo je mogoče implementirati v zbirko podatkov. Vključuje vse potrebne podrobnosti za izvedbo, kot so tabele, stolpci, tipi podatkov, omejitve, indeksi, sprožilci in druge funkcije, specifične za bazo podatkov.
Ključne značilnosti vključujejo
- Specifično za določeno DBMS in vključuje optimizacijo, specifično za bazo podatkov.
- Podrobne specifikacije tabel, stolpcev, tipov podatkov in omejitev.
- Upoštevanje možnosti fizičnega shranjevanja, strategij indeksiranja in optimizacije delovanja.
Prehod skozi te faze omogoča natančno načrtovanje in načrtovanje podatkovnega sistema, ki je usklajen s poslovnimi zahtevami in optimiziran za delovanje v določenem tehničnem okolju. Konceptualni model zagotavlja, da je celotna struktura usklajena s poslovnimi cilji, logični model premosti vrzel med konceptualnim načrtovanjem in fizično izvedbo, fizični model pa zagotavlja, da je baza podatkov optimizirana za dejansko uporabo.
Primer šolskega nabora podatkov
Entitete: študenti, učitelji in razredi.
Konceptualni podatkovni model
Ta konceptualni podatkovni model opisuje sistem baze podatkov za upravljanje šolskih evidenc, ki vključuje tri primarne entitete: učenca, učitelja in razred. V tem modelu so učenci lahko povezani z več učitelji in razredi, medtem ko lahko učitelji poučujejo več študentov in vodijo različne razrede. Vsak razred sprejme veliko učencev, vendar jih poučuje en sam učitelj. Namen zasnove je poenostaviti razumevanje odnosov med subjekti tako za tehnične kot za netehnične deležnike ter zagotoviti jasen in intuitiven pregled strukture sistema. Začetek s konceptualnim modelom omogoča postopno integracijo podrobnejših elementov in postavlja trdne temelje za razvoj sofisticiranih modelov podatkovnih baz.
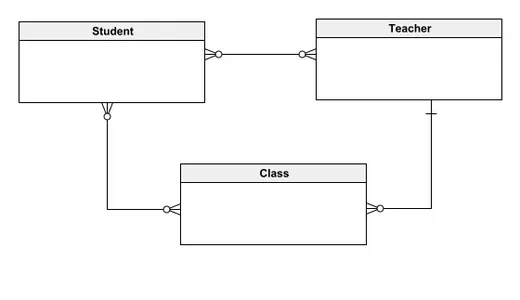
Logični podatkovni model
Logični podatkovni model, ki je zelo priljubljen zaradi svojega ravnovesja med jasnostjo in podrobnostmi, vključuje entitete, relacije, atribute, PRIMARNE KLJUČE in TUJE KLJUČE. Natančno oriše logično napredovanje podatkov v zbirki podatkov in razjasni natančne podrobnosti, kot je sestava ali uporabljeni tipi podatkov. Logični podatkovni model zagotavlja zadostno podlago za razvoj programske opreme za začetek dejanske gradnje baze podatkov.
Če preidemo na prej obravnavani konceptualni podatkovni model, preučimo tipičen logični podatkovni model. Za razliko od svojega konceptualnega predhodnika je ta model obogaten z atributi in primarnimi ključi. Na primer, entiteto študent odlikuje ID študenta kot njen primarni ključ in enolični identifikator, poleg drugih pomembnih atributov, kot sta ime in starost.
Ta pristop se dosledno uporablja v drugih entitetah, kot sta učitelj in razred, pri čemer se ohranjajo odnosi, vzpostavljeni v konceptualnem modelu, vendar se model izboljša s podrobno shemo, ki vključuje atribute in ključne identifikatorje.
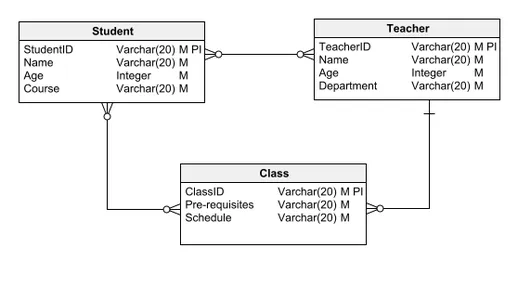
Fizični podatkovni model
Fizični podatkovni model je najbolj podroben med ravnmi abstrakcije, saj vključuje posebnosti, prilagojene izbranemu sistemu za upravljanje baze podatkov, kot je PostgreSQL, Oracle ali MySQL. V tem modelu so entitete prevedene v tabele, atributi pa postanejo stolpci, kar odraža strukturo dejanske baze podatkov. Vsakemu stolpcu je dodeljen določen tip podatkov, na primer INT za cela števila, VARCHAR za nize spremenljivih znakov ali DATE za datume.
Glede na svojo podrobno naravo se fizični podatkovni model poglobi v tehnične podrobnosti, ki so edinstvene za platformo baze podatkov v uporabi. Ti vseobsegajoči vidiki presegajo obseg pregleda na visoki ravni. To vključuje pomisleke, kot so dodeljevanje pomnilnika, strategije indeksiranja in izvedbene omejitve, ki so bistvenega pomena za delovanje in celovitost baze podatkov, vendar so običajno preveč razdrobljeni za predhodno razpravo.

Faze modeliranja podatkov
- Razumeti poslovne zahteve: Sodelujte v podrobnih razpravah z zainteresiranimi stranmi, da boste razumeli poslovni namen baze podatkov. Ključni premisleki vključujejo identifikacijo poslovne domene, potreb po shranjevanju podatkov in težav, ki jih namerava rešiti baza podatkov. Osredotočite se na usklajevanje zasnove baze podatkov s poslovnimi cilji glede zmogljivosti, stroškov in varnosti.
- Sodelovanje ekipe: Tesno sodelujte z drugimi ekipami (npr. oblikovalci UX/UI in razvijalci), da zagotovite, da baza podatkov podpira širšo rešitev. Prilagodite oblike in vrste podatkov, da bodo izpolnili zahteve aplikacij, s poudarkom na sodelovalnem oblikovanju in komunikacijskih veščinah.
- Industrijski standardi finančnega vzvoda: Raziščite obstoječe modele in standarde, da se izognete začetku iz nič. Uporabite najboljše prakse v panogi, da prihranite čas in vire ter se osredotočite na edinstvena prizadevanja na vidike vaše baze podatkov, ki jo razlikujejo od obstoječih modelov.
- Začni modeliranje baze podatkov: Z dobrim razumevanjem poslovnih potreb, vložkov skupine in industrijskih standardov začnite s konceptualnim modeliranjem, pojdite na logično in zaključite s fizičnim modelom. Ta strukturiran pristop zagotavlja celovito razumevanje zahtevanih entitet, atributov in odnosov, kar omogoča nemoteno izvajanje baze podatkov, usklajeno s poslovnimi cilji.
Orodja za modeliranje podatkov so bistvena za načrtovanje, vzdrževanje in razvijanje organizacijskih podatkovnih struktur. Ta orodja ponujajo vrsto funkcionalnosti za podporo celotnega življenjskega cikla načrtovanja baze podatkov in upravljanja. Ključne funkcije, ki jih je treba iskati v orodjih za modeliranje podatkov, vključujejo:
- Gradi podatkovne modele: Olajšajte ustvarjanje konceptualnih, logičnih in fizičnih podatkovnih modelov, ki omogočajo jasno opredelitev entitet, atributov in odnosov. Ta osnovna funkcionalnost podpira začetno in tekoče načrtovanje arhitekture baze podatkov.
- Sodelovanje in osrednji repozitorij: Omogočite članom skupine, da sodelujejo pri načrtovanju in spremembah podatkovnega modela. Osrednji repozitorij zagotavlja, da so najnovejše različice dostopne vsem zainteresiranim stranem, kar spodbuja doslednost in učinkovitost pri razvoju.
- Povratni inženiring: Zagotovite zmožnost uvoza skriptov SQL ali povezovanja z obstoječimi zbirkami podatkov za ustvarjanje podatkovnih modelov. To je še posebej uporabno za razumevanje in dokumentiranje podedovanih sistemov ali integracijo obstoječih baz podatkov.
- Forward Engineering: Omogoča generiranje skriptov SQL ali kode iz podatkovnega modela. Ta funkcija poenostavi izvajanje sprememb v strukturi baze podatkov in zagotavlja, da fizična baza podatkov odraža najnovejši model.
- Podpora za različne vrste baz podatkov: Ponudite združljivost z več sistemi za upravljanje baz podatkov (DBMS), kot so MySQL, PostgreSQL, Oracle, SQL Server in drugi. Ta prilagodljivost zagotavlja uporabo orodja v različnih projektih in tehnoloških okoljih.
- Nadzor različic: Vključite ali integrirajte sisteme za nadzor različic za sledenje spremembam podatkovnih modelov skozi čas. Ta funkcija je ključnega pomena za upravljanje ponovitev strukture baze podatkov in olajšanje povrnitve na prejšnje različice, če je potrebno.
- Izvoz diagramov v različnih formatih: Uporabnikom omogočite izvoz podatkovnih modelov in diagramov v različnih formatih (npr. PDF, PNG, XML), kar olajša skupno rabo in dokumentacijo. To zagotavlja, da lahko tudi netehnične zainteresirane strani pregledajo in razumejo arhitekturo podatkov.
Izbira orodja za modeliranje podatkov s temi funkcijami lahko bistveno izboljša učinkovitost, natančnost in sodelovanje pri prizadevanjih za upravljanje podatkov v organizaciji, s čimer zagotovite, da so baze podatkov dobro oblikovane, posodobljene in usklajene s poslovnimi potrebami.
Urgenca/Studio

Ponuja obsežne zmogljivosti modeliranja in funkcije sodelovanja ter podpira različne platforme baz podatkov.
IBM InfoSphere Data Architect

Zagotavlja robustno okolje za načrtovanje in upravljanje podatkovnih modelov s podporo za integracijo in sinhronizacijo z drugimi izdelki IBM.
Povezava IBM InfoSphere Data Architect
Oracle SQL Developer Data Modeler

Brezplačno orodje, ki podpira naprej in nazaj inženiring, nadzor različic in podporo za več baz podatkov.
Povezava Oracle SQL Developer Data Modeler
PowerDesigner (SAP)

Ponuja obsežne funkcije modeliranja, vključno s podporo za podatke, informacije in arhitekturo podjetja.
Navicat Data Modeler
Znan po svojem uporabniku prijaznem vmesniku in podpori za široko paleto baz podatkov, omogoča naprej in nazaj inženiring.
Ta orodja poenostavijo proces modeliranja podatkov, izboljšajo timsko sodelovanje in zagotovijo združljivost med različnimi sistemi baz podatkov.
Preberite tudi: Vprašanja za intervju za modeliranje podatkov
zaključek
Ta članek se je poglobil v bistveno prakso modeliranja podatkov in poudaril njegovo ključno vlogo pri organiziranju, shranjevanju in dostopu do podatkov v bazah podatkov in podatkovnih sistemih. Z razčlenitvijo procesa na konceptualne, logične in fizične modele smo ponazorili, kako podatkovno modeliranje prevaja poslovne potrebe v strukturirana podatkovna ogrodja, kar omogoča učinkovito ravnanje s podatki in pronicljivo analizo.
Ključni zaključki vključujejo pomen razumevanja poslovnih zahtev, sodelovalno naravo oblikovanja baze podatkov, ki vključuje različne zainteresirane strani, in strateško uporabo orodij za modeliranje podatkov za racionalizacijo razvojnega procesa. Modeliranje podatkov zagotavlja, da so podatkovne strukture optimizirane za trenutne potrebe in zagotavlja razširljivost za prihodnjo rast.
Modeliranje podatkov je v središču učinkovitega upravljanja podatkov, saj organizacijam omogoča, da svoje podatke izkoristijo za strateško odločanje in operativno učinkovitost.
Pogosto zastavljena vprašanja
Ans. Modeliranje podatkov vizualno predstavlja sistemske podatke in opisuje, kako so shranjeni, organizirani in dostopni. Je ključnega pomena za prevajanje poslovnih zahtev v format strukturirane baze podatkov, ki omogoča učinkovito uporabo podatkov.
Ans. Ključni primeri uporabe vključujejo pridobivanje podatkov, nalaganje, poslovne izračune in distribucijo, kar zagotavlja učinkovito zbiranje, shranjevanje in uporabo podatkov za poslovne vpoglede.
Ans. Podatkovni inženirji gradijo in vzdržujejo podatkovno infrastrukturo, medtem ko modelirji podatkov oblikujejo strukturo in organizacijo podatkov v podporo poslovnim ciljem in celovitosti podatkov.
Ans. Proces se premakne od razumevanja poslovnih zahtev do sodelovanja z ekipami, izkoriščanja industrijskih standardov in modeliranja baze podatkov skozi konceptualne, logične in fizične faze.
Ans. Ta orodja olajšajo načrtovanje, sodelovanje in razvoj podatkovnih modelov, podpirajo različne tipe baz podatkov in omogočajo obratno in naprej inženiring za učinkovito upravljanje baz podatkov.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.analyticsvidhya.com/blog/2024/03/data-modeling-demystified-crafting-efficient-databases-for-business-insights/

