Krone ponuja pivovarnam, polnilcem pijač in proizvajalcem hrane po vsem svetu posamezne stroje in celotne proizvodne linije. Vsak dan teče na milijone steklenic, pločevink in PET posod skozi linijo Krones. Proizvodne linije so zapleteni sistemi z veliko možnimi napakami, ki lahko zaustavijo linijo in zmanjšajo donos proizvodnje. Krones želi napako odkriti čim prej (včasih še preden se zgodi) in obvestiti operaterje proizvodne linije, da bi povečali zanesljivost in proizvodnjo. Kako torej odkriti napako? Krones svoje linije opremi s senzorji za zbiranje podatkov, ki jih je nato mogoče ovrednotiti glede na pravila. Krones, kot proizvajalec linije, kot tudi upravljavec linije imata možnost ustvariti nadzorna pravila za stroje. Zato lahko polnilci pijač in drugi operaterji določijo lastno mejo napake za linijo. Krones je v preteklosti uporabljal sistem, ki je temeljil na podatkovni bazi časovnih vrst. Glavni izzivi so bili, da je bilo v tem sistemu težko odpraviti napake in tudi poizvedbe so predstavljale trenutno stanje strojev, ne pa tudi prehodov stanj.
Ta objava prikazuje, kako je Krones zgradil pretočno rešitev za spremljanje svojih linij na podlagi Amazon Kinesis in Amazonova upravljana storitev za Apache Flink. Te popolnoma upravljane storitve zmanjšajo kompleksnost gradnje pretočnih aplikacij z Apache Flink. Upravljana storitev za Apache Flink upravlja osnovne komponente Apache Flink, ki zagotavljajo trajno stanje aplikacije, metrike, dnevnike in drugo, Kinesis pa vam omogoča stroškovno učinkovito obdelavo pretočnih podatkov v poljubnem obsegu. Če želite začeti uporabljati svojo aplikacijo Apache Flink, si oglejte GitHub repozitorij za vzorce, ki uporabljajo API-je Java, Python ali SQL Flink.
Pregled rešitve
Kronesov nadzor linij je del Krones Shopfloor smernice sistem. Zagotavlja podporo pri organizaciji, določanju prioritet, vodenju in dokumentiranju vseh aktivnosti v podjetju. Omogoča jim, da obvestijo operaterja, če je stroj ustavljen ali so potrebni materiali, ne glede na to, kje je operater v vrsti. Preizkušena pravila za spremljanje stanja so že vgrajena, lahko pa jih tudi uporabnik definira prek uporabniškega vmesnika. Na primer, če določena podatkovna točka, ki je nadzorovana, krši prag, je lahko v vrstici besedilno sporočilo ali sprožilec za vzdrževalni nalog.
Sistem za spremljanje stanja in vrednotenje pravil je zgrajen na AWS z uporabo analitičnih storitev AWS. Naslednji diagram ponazarja arhitekturo.
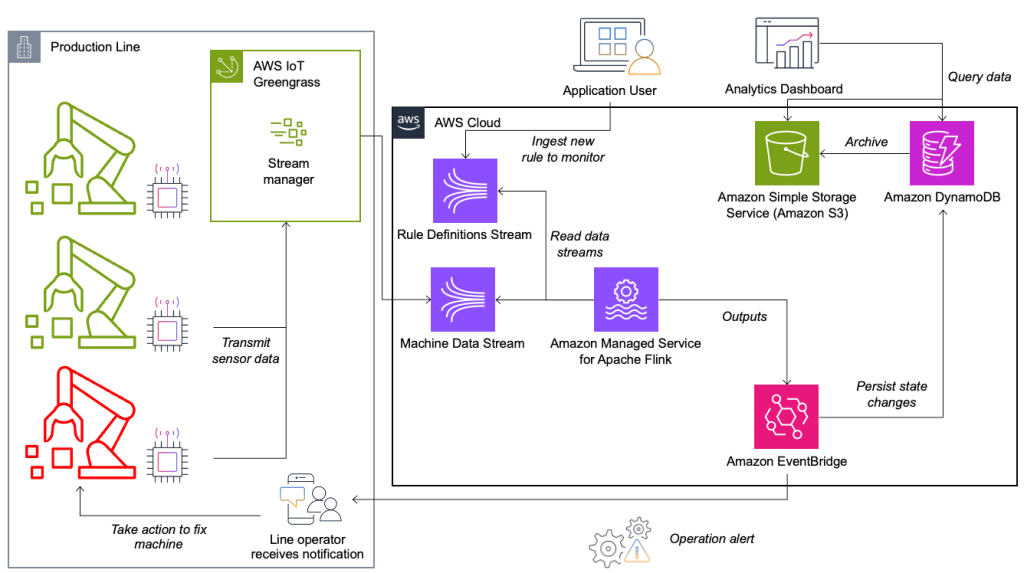
Skoraj vsaka aplikacija za pretakanje podatkov je sestavljena iz petih plasti: vira podatkov, zaužitja toka, shranjevanja toka, obdelave toka in enega ali več ciljev. V naslednjih razdelkih se poglobimo v vsako plast in v podrobnosti delovanja rešitve za spremljanje linij, ki jo je izdelal Krones.
Vir podatkov
Podatke zbira storitev, ki se izvaja na robni napravi, ki bere več protokolov, kot sta Siemens S7 ali OPC/UA. Neobdelani podatki so predhodno obdelani, da se ustvari enotna struktura JSON, ki olajša kasnejšo obdelavo v mehanizmu pravil. Vzorec koristnega tovora, pretvorjenega v JSON, je lahko videti takole:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Zaužitje toka
AWS IoT Zelena trava je odprtokodna storitev interneta stvari (IoT) robnega izvajalnega okolja in storitve v oblaku. To vam omogoča lokalno ukrepanje na podatkih ter združevanje in filtriranje podatkov naprave. AWS IoT Greengrass zagotavlja vnaprej izdelane komponente, ki jih je mogoče namestiti do roba. Rešitev proizvodne linije uporablja komponento stream manager, ki lahko obdeluje podatke in jih prenaša na destinacije AWS, kot je npr AWS IoT Analytics, Preprosta storitev shranjevanja Amazon (Amazon S3) in Kinesis. Upravitelj toka shrani in združi zapise ter jih nato pošlje v podatkovni tok Kinesis.
Shranjevanje toka
Naloga pomnilnika toka je medpomniti sporočila na način, ki je odporen na napake, in jih dati na voljo za uporabo eni ali več potrošniških aplikacij. Da bi to dosegli na AWS, sta najpogostejši tehnologiji Kinesis in Amazonovo pretakanje za Apache Kafka (Amazon MSK). Za shranjevanje naših senzorskih podatkov iz proizvodnih linij Krones izbere Kinesis. Kinesis je storitev pretakanja podatkov brez strežnika, ki deluje v katerem koli obsegu z nizko zakasnitvijo. Drobci znotraj podatkovnega toka Kinesis so enolično identificirano zaporedje podatkovnih zapisov, kjer je tok sestavljen iz enega ali več drobcev. Vsak delček ima 2 MB/s zmogljivosti branja in 1 MB/s zmogljivosti pisanja (z največ 1,000 zapisi/s). Da bi se izognili doseganju teh omejitev, morajo biti podatki čim bolj enakomerno porazdeljeni med drobce. Vsak zapis, ki je poslan Kinesisu, ima particijski ključ, ki se uporablja za združevanje podatkov v delček. Zato želite imeti veliko število particijskih ključev za enakomerno porazdelitev obremenitve. Upravitelj pretoka, ki se izvaja na AWS IoT Greengrass, podpira naključne dodelitve particijskih ključev, kar pomeni, da se vsi zapisi končajo v naključnem razdelku, obremenitev pa je enakomerno porazdeljena. Pomanjkljivost naključnih dodelitev particijskih ključev je, da zapisi niso shranjeni po vrstnem redu v Kinesisu. Razložimo, kako to rešiti v naslednjem razdelku, kjer govorimo o vodnih žigih.
Vodni žigi
A vodni žig je mehanizem, ki se uporablja za sledenje in merjenje poteka časa dogodka v podatkovnem toku. Čas dogodka je časovni žig od trenutka, ko je bil dogodek ustvarjen na izvoru. Vodni žig označuje pravočasen napredek aplikacije za obdelavo toka, zato se vsi dogodki s prejšnjim ali enakim časovnim žigom štejejo za obdelane. Te informacije so bistvene za Flink, da pospeši čas dogodka in sproži ustrezne izračune, kot so ocene oken. Dovoljeni zamik med časom dogodka in vodnim žigom je mogoče konfigurirati tako, da določite, kako dolgo je treba čakati na zakasnele podatke, preden se šteje, da je okno dokončano in se vodni žig premakne naprej.
Krones ima sisteme po vsem svetu in je potreben za obravnavo poznih prihodov zaradi izgub povezave ali drugih omrežnih omejitev. Začeli so s spremljanjem poznih prihodov in nastavitvijo privzete pozne obravnave Flink na največjo vrednost, ki so jo videli v tej metriki. Imeli so težave s časovno sinhronizacijo iz robnih naprav, kar jih je pripeljalo do bolj sofisticiranega načina vodnega žiga. Izdelali so globalni vodni žig za vse pošiljatelje in kot vodni žig uporabili najnižjo vrednost. Časovni žigi so shranjeni v HashMap za vse dohodne dogodke. Ko se vodni žigi občasno oddajajo, se uporabi najmanjša vrednost tega HashMapa. Da bi preprečili zastoj vodnih žigov zaradi manjkajočih podatkov, so konfigurirali an idleTimeOut parameter, ki ignorira časovne žige, ki so starejši od določenega praga. To poveča zakasnitev, vendar zagotavlja močno doslednost podatkov.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Pretočna obdelava
Ko so podatki zbrani iz senzorjev in vneseni v Kinesis, jih mora ovrednotiti mehanizem pravil. Pravilo v tem sistemu predstavlja stanje posamezne metrike (kot je temperatura) ali zbirke meritev. Za razlago metrike se uporabi več kot ena podatkovna točka, kar je izračun s stanjem. V tem razdelku se poglobimo v stanje ključa in stanje oddajanja v Apache Flinku in kako se uporabljata za izdelavo mehanizma pravil Krones.
Nadzor toka in vzorec stanja oddajanja
V Apache Flink, so bili se nanaša na zmožnost sistema za stalno shranjevanje in upravljanje informacij skozi čas in operacije, kar omogoča obdelavo pretočnih podatkov s podporo za izračune s stanjem.
O vzorec stanja oddajanja omogoča porazdelitev stanja na vse vzporedne primerke operaterja. Zato imajo vsi operaterji enako stanje in podatke je mogoče obdelati z uporabo tega istega stanja. Te podatke samo za branje je mogoče zaužiti z uporabo nadzornega toka. Kontrolni tok je običajni tok podatkov, vendar običajno z veliko nižjo hitrostjo prenosa podatkov. Ta vzorec vam omogoča dinamično posodabljanje stanja pri vseh operaterjih, kar uporabniku omogoča, da spremeni stanje in vedenje aplikacije brez potrebe po ponovni umestitvi. Natančneje, porazdelitev stanja poteka z uporabo kontrolnega toka. Z dodajanjem novega zapisa v kontrolni tok vsi operaterji prejmejo to posodobitev in uporabljajo novo stanje za obdelavo novih sporočil.
To omogoča uporabnikom aplikacije Krones, da vnesejo nova pravila v aplikacijo Flink brez ponovnega zagona. To preprečuje izpade in zagotavlja odlično uporabniško izkušnjo, saj se spremembe zgodijo v realnem času. Pravilo pokriva scenarij za odkrivanje odstopanja procesa. Včasih strojnih podatkov ni tako enostavno interpretirati, kot se morda zdi na prvi pogled. Če temperaturni senzor pošilja visoke vrednosti, je to lahko znak napake, lahko pa je tudi posledica tekočega vzdrževalnega postopka. Pomembno je, da meritve postavite v kontekst in filtrirate nekatere vrednosti. To dosežemo s konceptom, imenovanim združevanje.
Združevanje metrik
Združevanje podatkov in meritev vam omogoča, da določite ustreznost vhodnih podatkov in ustvarite natančne rezultate. Sprehodimo se skozi primer na naslednji sliki.
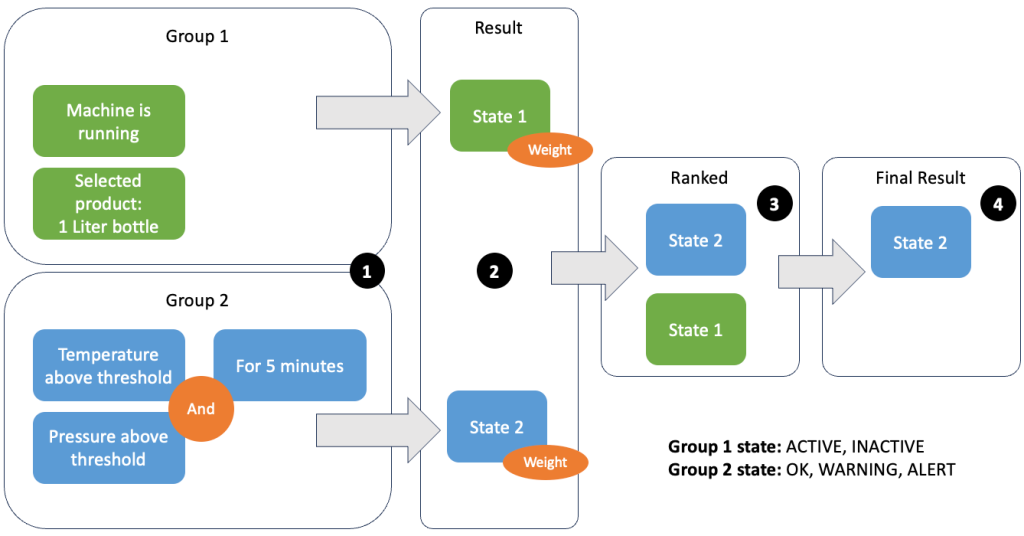
V 1. koraku definiramo dve skupini pogojev. Skupina 1 zbira stanje stroja in kateri izdelek gre skozi linijo. Skupina 2 uporablja vrednost temperaturnih in tlačnih senzorjev. Skupina pogojev ima lahko različna stanja, odvisno od vrednosti, ki jih prejme. V tem primeru skupina 1 prejme podatke, da stroj deluje, in kot izdelek je izbrana litrska plastenka; to daje tej skupini stanje ACTIVE. Skupina 2 ima meritve za temperaturo in tlak; obe metriki sta nad svojimi pragovi več kot 5 minut. Posledica tega je, da je skupina 2 v a WARNING država. To pomeni, da skupina 1 poroča, da je vse v redu, skupina 2 pa ne. V 2. koraku se skupinam dodajo uteži. To je potrebno v nekaterih situacijah, ker lahko skupine poročajo o nasprotujočih si informacijah. V tem scenariju poroča skupina 1 ACTIVE in poročila skupine 2 WARNING, zato sistemu ni jasno, v kakšnem stanju je linija. Po dodajanju uteži je mogoče države razvrstiti, kot je prikazano v 3. koraku. Nazadnje je najvišje uvrščena država izbrana kot zmagovalna, kot je prikazano v 4. koraku.
Ko so pravila ovrednotena in definirano končno stanje stroja, bodo rezultati nadalje obdelani. Izvedeno dejanje je odvisno od konfiguracije pravila; to je lahko obvestilo operaterju linije, da obnovi zaloge materiala, izvede nekaj vzdrževanja ali samo vizualno posodobitev na armaturni plošči. Ta del sistema, ki ocenjuje meritve in pravila ter ukrepa na podlagi rezultatov, se imenuje motor pravila.
Skaliranje mehanizma pravil
Če uporabnikom dovolite, da ustvarijo lastna pravila, ima lahko mehanizem pravil veliko število pravil, ki jih mora oceniti, nekatera pravila pa lahko uporabljajo iste podatke senzorja kot druga pravila. Flink je porazdeljen sistem, ki se vodoravno prilagaja zelo dobro. Če želite tok podatkov razdeliti na več opravil, lahko uporabite keyBy() metoda. To vam omogoča, da tok podatkov razdelite na logičen način in pošljete dele podatkov različnim upraviteljem opravil. To se pogosto naredi z izbiro poljubnega ključa, tako da dobite enakomerno porazdeljeno obremenitev. V tem primeru je Krones dodal a ruleId do podatkovne točke in jo uporabil kot ključ. V nasprotnem primeru bodo podatkovne točke, ki so potrebne, obdelane z drugo nalogo. Podatkovni tok s ključi se lahko uporablja v vseh pravilih tako kot običajna spremenljivka.
Destinacije
Ko pravilo spremeni svoje stanje, se informacije pošljejo v tok Kinesis in nato prek Amazon EventBridge potrošnikom. Eden od potrošnikov ustvari obvestilo o dogodku, ki se prenese v proizvodno linijo in opozori osebje, naj ukrepa. Da bi lahko analizirali spremembe stanja pravila, druga storitev zapiše podatke v Amazon DynamoDB tabela za hiter dostop in TTL je vzpostavljen za prenos dolgoročne zgodovine v Amazon S3 za nadaljnje poročanje.
zaključek
V tej objavi smo vam pokazali, kako je Krones zgradil sistem za spremljanje proizvodne linije v realnem času na AWS. Upravljana storitev za Apache Flink je ekipi Krones omogočila hiter začetek z osredotočanjem na razvoj aplikacij in ne na infrastrukturo. Zmogljivosti Flinka v realnem času so Kronesu omogočile zmanjšanje izpadov strojev za 10 % in povečanje učinkovitosti do 5 %.
Če želite ustvariti lastne aplikacije za pretakanje, si oglejte razpoložljive vzorce na GitHub repozitorij. Če želite svojo aplikacijo Flink razširiti s priključki po meri, glejte Poenostavitev izdelave konektorjev z Apache Flink: Predstavitev Async Sink. Async Sink je na voljo v različici Apache Flink 1.15.1 in novejših.
O avtorjih
 Florian Mair je višji arhitekt rešitev in strokovnjak za pretakanje podatkov pri AWS. Je tehnolog, ki strankam v Evropi pomaga pri uspehu in inovacijah z reševanjem poslovnih izzivov z uporabo storitev AWS Cloud. Poleg tega, da dela kot arhitekt rešitev, je Florian strasten alpinist in se je povzpel na nekatere najvišje gore po Evropi.
Florian Mair je višji arhitekt rešitev in strokovnjak za pretakanje podatkov pri AWS. Je tehnolog, ki strankam v Evropi pomaga pri uspehu in inovacijah z reševanjem poslovnih izzivov z uporabo storitev AWS Cloud. Poleg tega, da dela kot arhitekt rešitev, je Florian strasten alpinist in se je povzpel na nekatere najvišje gore po Evropi.
 Emil Dietl je višji tehnični vodja pri Kronesu, specializiran za podatkovni inženiring, s ključnim področjem v Apache Flink in mikrostoritvah. Njegovo delo pogosto vključuje razvoj in vzdrževanje kritične programske opreme. Zunaj poklicnega življenja zelo ceni preživljanje kakovostnega časa s svojo družino.
Emil Dietl je višji tehnični vodja pri Kronesu, specializiran za podatkovni inženiring, s ključnim področjem v Apache Flink in mikrostoritvah. Njegovo delo pogosto vključuje razvoj in vzdrževanje kritične programske opreme. Zunaj poklicnega življenja zelo ceni preživljanje kakovostnega časa s svojo družino.
 Simon Peyer je arhitekt rešitev pri AWS s sedežem v Švici. Je praktičen delavec in navdušen nad povezovanjem tehnologije in ljudi, ki uporabljajo storitve AWS Cloud. Poseben poudarek mu je na pretoku podatkov in avtomatizaciji. Simon poleg dela uživa v družini, na prostem in v pohodih v gore.
Simon Peyer je arhitekt rešitev pri AWS s sedežem v Švici. Je praktičen delavec in navdušen nad povezovanjem tehnologije in ljudi, ki uporabljajo storitve AWS Cloud. Poseben poudarek mu je na pretoku podatkov in avtomatizaciji. Simon poleg dela uživa v družini, na prostem in v pohodih v gore.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

