Predstavitev
V današnjem digitalnem okolju je spoštovanje predpisov Know Your Customer (KYC) najpomembnejše za podjetja, ki delujejo v okviru finančnih storitev, spletnih tržnic in drugih sektorjev, ki zahtevajo identifikacijo uporabnikov. Tradicionalno so procesi KYC temeljili na ročnem preverjanju dokumentov, kar je zamuden pristop, ki je nagnjen k napakam. Ta vodnik se poglobi v to, kako lahko Amazon Rekognition, zmogljiva storitev umetne inteligence v oblaku podjetja AWS, specializirana za prepoznavanje in analizo obrazov, spremeni vašo spletno strategijo KYC in jo spremeni v poenostavljen, varen in stroškovno učinkovit postopek.

Učni cilji
- Razumeti pomen predpisov Know Your Customer (KYC) v različnih panogah in izzive, povezane s postopki ročnega preverjanja.
- Raziščite zmogljivosti storitve Amazon Rekognition kot storitve umetne inteligence v oblaku, specializirane za prepoznavanje in analizo obrazov.
- Naučite se korakov pri izvajanju preverjanja identitete z uporabo Amazon Rekognition, vključno z vključitvijo uporabnika, izvlečenje besedila, zaznavanje živahnosti, analiza obraza in ujemanje obrazov.
- Razumeti pomen izkoriščanja preverjanja identitete na podlagi umetne inteligence za izboljšanje varnostnih ukrepov, poenostavitev postopkov preverjanja pristnosti uporabnikov in izboljšanje uporabniške izkušnje.
Ta članek je bil objavljen kot del Blogaton podatkovne znanosti.
Kazalo
Razumevanje izzivov KYC
Predpisi KYC zahtevajo, da podjetja preverijo identiteto svojih uporabnikov ublažiti goljufije, pranje denarja in drugi finančni kriminal. To preverjanje običajno vključuje zbiranje in potrjevanje identifikacijskih dokumentov, ki jih je izdal državni organ. Čeprav so ti predpisi bistveni za ohranjanje varnega finančnega ekosistema, procesi ročnega preverjanja povzročajo izzive:
- Vpliv pandemije: Med pandemijo se je finančni sektor soočal s precejšnjimi izzivi pri pridobivanju novih strank, saj je bilo gibanje omejeno. Zato ročno množično preverjanje ni mogoče. Z uvedbo spletnega KYC je torej vaše podjetje pripravljeno na takšne prihodnje dogodke.
- Človeške napake: Ročno preverjanje je dovzetno za napake, kar lahko omogoči goljufivim registracijam, da se izmuznejo skozi razpoke.
- Upravljanje ID-jev: Ker je dokumentacija tiskana kopija, je upravljanje le-te vedno večji izziv. Kopije se lahko izgubijo, zažgejo, ukradejo, zlorabijo itd.
Kaj je Amazon Rekognition?
Amazon Rekognition je zmogljiva storitev za analizo slik in videa, ki jo ponuja Amazon Web Services (AWS). Uporablja napredne algoritme strojnega učenja za analizo vizualne vsebine v slikah in videoposnetkih, kar razvijalcem omogoča pridobivanje dragocenih vpogledov in izvajanje različnih nalog, kot so zaznavanje predmetov, prepoznavanje obraza in preverjanje identitete. Spodnji poenostavljeni diagram daje dobro predstavo o vključenih funkcijah in storitvah.
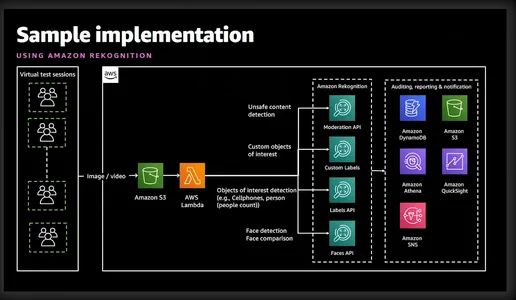
Preverjanje identitete z Amazon Rekognition
Preden vas popeljem k implementaciji, naj vam predstavim idejo na visoki ravni in korake, ki so vključeni v implementacijo preverjanja identitete za naš spletni KYC.
- Uvajanje uporabnika: Ta postopek bo specifičen za podjetje. Vendar bo podjetje potrebovalo najmanj ime, srednje ime, priimek, datum rojstva, datum veljavnosti osebne izkaznice in fotografijo velikosti potnega lista. Vse te podatke lahko zberete tako, da uporabnika prosite, da naloži sliko osebne izkaznice.
- Izvleček besedila: Storitev AWS Texttract lahko lepo izvleče vse zgornje podatke iz naložene osebne izkaznice. Poleg tega lahko poizvedujemo tudi po Texttractu, da pridobimo določene informacije iz osebne izkaznice.
- Živahnost in prepoznavanje obraza: Za zagotovitev, da je uporabnik, ki poskuša opraviti svoj KYC, aktiven na zaslonu in v živo, ko se začne seja liveness. Amazon Rekognition lahko natančno zazna in primerja obraze v slikah ali video tokovih.
- Analiza obraza: Ko je obraz zajet, nudi podroben vpogled v lastnosti obraza, kot so starost, spol, čustva in obrazne točke. Ne le to, preveril bo tudi, ali ima uporabnik sončna očala ali če je njegov obraz prekrit z drugimi predmeti.
- Ujemanje obrazov: Po preverjanju Liveness lahko izvedemo ujemanje obrazov, da preverimo identiteto posameznikov na podlagi referenčnih slik, pridobljenih iz nacionalne osebne izkaznice, in trenutne slike iz seje Liveness.
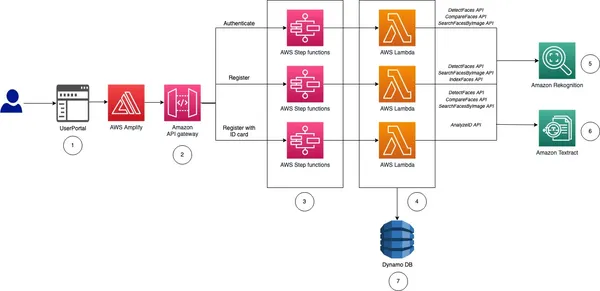
Kot lahko vidite, Rekognition olajša hitro registracijo uporabnika z analizo zajetega selfija in njegovo primerjavo z osebnim dokumentom, ki ga je izdal državni organ, ki ga je naložil uporabnik. Zmožnosti zaznavanja živahnosti znotraj Rekognition pomagajo preprečiti poskuse ponarejanja, tako da uporabnike pozovejo, naj izvedejo določena dejanja, kot je mežikanje ali obračanje glave. To zagotavlja, da je uporabnik, ki se registrira, resnična oseba in ne spretno prikrita fotografija ali globok ponaredek. Ta avtomatiziran postopek bistveno skrajša čas vkrcanja in izboljša uporabniško izkušnjo. Prepoznavanje odpravlja možnost človeške napake, ki je del ročnega preverjanja. Poleg tega algoritmi za prepoznavanje obraza dosegajo visoke stopnje natančnosti, kar zagotavlja zanesljivo preverjanje identitete.
Vem, da ste zdaj zelo navdušeni, da ga vidite v akciji, zato pojdimo takoj k temu.
Implementacija preverjanja identitete: avtomatizirana rešitev KYC
1. korak: Nastavitev računa AWS
Preden začnete, se prepričajte, da imate aktiven račun AWS. Za račun AWS se lahko prijavite na spletnem mestu AWS, če tega še niste storili. Ko se prijavite, aktivirajte storitve Rekognition. AWS ponuja obsežno dokumentacijo in vadnice za olajšanje tega postopka.
2. korak: Nastavitev dovoljenj IAM
Če želite uporabljati Python ali AWS CLI, je ta korak obvezen. Poskrbeti morate za dovoljenje za dostop do Rekognition, S3 in Texttract. To lahko storite s konzole.
3. korak: Naložite nacionalno ID uporabnika
To bom prikazal s pomočjo CLI, Pythona in grafičnega vmesnika. Če iščete kodo za grafični vmesnik, potem je AWS naložil lepo primer na git. Ta članek je uporabil isto kodo za prikaz grafičnega vmesnika.
aws textract analyze-id --document-pages
'{"S3Object":{"Bucket":"bucketARN","Name":"id.jpg"}}'"IdentityDocuments": [
{
"DocumentIndex": 1,
"IdentityDocumentFields": [
{
"Type": {
"Text": "FIRST_NAME"
},
"ValueDetection": {
"Text": "xyz",
"Confidence": 93.61839294433594
}
},
{
"Type": {
"Text": "LAST_NAME"
},
"ValueDetection": {
"Text": "abc",
"Confidence": 96.3537826538086
}
},
{
"Type": {
"Text": "MIDDLE_NAME"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16631317138672
}
},
{
"Type": {
"Text": "SUFFIX"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16964721679688
}
},
{
"Type": {
"Text": "CITY_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.17261505126953
}
},
{
"Type": {
"Text": "ZIP_CODE_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.17854309082031
}
},
{
"Type": {
"Text": "STATE_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.15782165527344
}
},
{
"Type": {
"Text": "STATE_NAME"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16664123535156
}
},
{
"Type": {
"Text": "DOCUMENT_NUMBER"
},
"ValueDetection": {
"Text": "123456",
"Confidence": 95.29527282714844
}
},
{
"Type": {
"Text": "EXPIRATION_DATE"
},
"ValueDetection": {
"Text": "22 OCT 2024",
"NormalizedValue": {
"Value": "2024-10-22T00:00:00",
"ValueType": "Date"
},
"Confidence": 95.7198486328125
}
},
{
"Type": {
"Text": "DATE_OF_BIRTH"
},
"ValueDetection": {
"Text": "1 SEP 1994",
"NormalizedValue": {
"Value": "1994-09-01T00:00:00",
"ValueType": "Date"
},
"Confidence": 97.41930389404297
}
},
{
"Type": {
"Text": "DATE_OF_ISSUE"
},
"ValueDetection": {
"Text": "23 OCT 2004",
"NormalizedValue": {
"Value": "2004-10-23T00:00:00",
"ValueType": "Date"
},
"Confidence": 96.1384506225586
}
},
{
"Type": {
"Text": "ID_TYPE"
},
"ValueDetection": {
"Text": "PASSPORT",
"Confidence": 98.65157318115234
}
}Zgornji ukaz uporablja ukaz AWS Texttract analysis-id za pridobivanje informacij iz slike, ki je že naložena v S3. Izhodni JSON vsebuje tudi omejevalne okvirje, zato sem ga skrajšal, da prikažem samo ključne informacije. Kot lahko vidite, je izluščil vse zahtevane informacije skupaj s stopnjo zaupanja besedilne vrednosti.
Uporaba funkcij Python
textract_client = boto3.client('textract', region_name='us-east-1')
def analyze_id(document_file_name)->dict:
if document_file_name is not None:
with open(document_file_name, "rb") as document_file:
idcard_bytes = document_file.read()
'''
Analyze the image using Amazon Textract.
'''
try:
response = textract_client.analyze_id(
DocumentPages=[
{'Bytes': idcard_bytes},
])
return response
except textract_client.exceptions.UnsupportedDocumentException:
logger.error('User %s provided an invalid document.' % inputRequest.user_id)
raise InvalidImageError('UnsupportedDocument')
except textract_client.exceptions.DocumentTooLargeException:
logger.error('User %s provided document too large.' % inputRequest.user_id)
raise InvalidImageError('DocumentTooLarge')
except textract_client.exceptions.ProvisionedThroughputExceededException:
logger.error('Textract throughput exceeded.')
raise InvalidImageError('ProvisionedThroughputExceeded')
except textract_client.exceptions.ThrottlingException:
logger.error('Textract throughput exceeded.')
raise InvalidImageError('ThrottlingException')
except textract_client.exceptions.InternalServerError:
logger.error('Textract Internal Server Error.')
raise InvalidImageError('ProvisionedThroughputExceeded')
result = analyze_id('id.jpeg')
print(result) # print raw outputUporaba grafičnega vmesnika
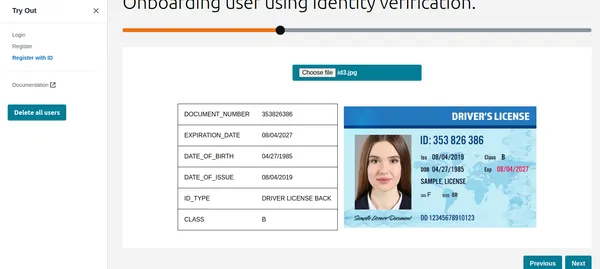

Kot lahko vidite, je Texttract pridobil vse ustrezne informacije in prikazuje tudi vrsto ID-ja. Te podatke je mogoče uporabiti za registracijo stranke ali uporabnika. Pred tem pa opravimo preverjanje Liveness, da preverimo, ali gre za resnično osebo.
Preverjanje živahnosti
Ko uporabnik klikne na začetek preverjanja na spodnji sliki, bo najprej zaznal obraz in če je na zaslonu samo en obraz, bo začel sejo Liveness. Zaradi zasebnosti ne morem prikazati celotne seje Liveness. Vendar lahko to preverite demo video povezava. Seja Liveness bo zagotovila rezultate v % zaupanja. Nastavimo lahko tudi prag, pod katerim seja Liveness ne bo uspela. Za kritične aplikacije, kot je ta, je treba ohraniti prag na 95 %.
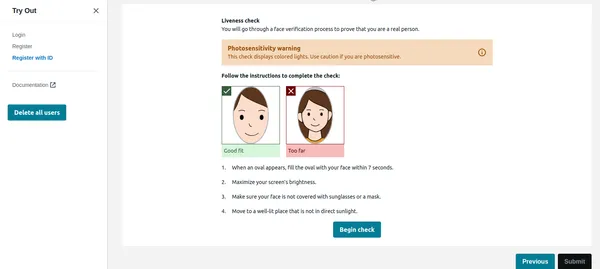
Poleg zaupanja bo seansa Liveness zagotovila tudi čustva in tujke, zaznane na obrazu. Če ima uporabnik sončna očala ali kaže izraze, kot je jeza itd., lahko aplikacija zavrne sliko.
Koda Python
rek_client = boto3.client('rekognition', region_name='us-east-1')
sessionid = rek_client.create_face_liveness_session(Settings={'AuditImagesLimit':1,
'OutputConfig': {"S3Bucket": 'IMAGE_BUCKET_NAME'}})
session = rek_client.get_face_liveness_session_results(
SessionId=sessionid)
Primerjava obrazov
Ko uporabnik uspešno zaključi sejo Liveness, mora aplikacija primerjati obraz z obrazom, zaznanim iz ID-ja. To je najbolj kritičen del naše aplikacije. Ne želimo registrirati uporabnika, katerega obraz se ne ujema z ID-jem. Obraz, zaznan iz naloženega ID-ja, je že shranjen v S3 s kodo, ki bo delovala kot referenčna slika. Podobno je obraz iz seje liveness shranjen tudi v S3. Najprej preverimo implementacijo CLI.
ukaz CLI
aws rekognition compare-faces
--source-image '{"S3Object":{"Bucket":"imagebucket","Name":"reference.jpg"}}'
--target-image '{"S3Object":{"Bucket":"imagebucket","Name":"liveness.jpg"}}'
--similarity-threshold 0.9
izhod
{
"UnmatchedFaces": [],
"FaceMatches": [
{
"Face": {
"BoundingBox": {
"Width": 0.12368916720151901,
"Top": 0.16007372736930847,
"Left": 0.5901257991790771,
"Height": 0.25140416622161865
},
"Confidence": 99.0,
"Pose": {
"Yaw": -3.7351467609405518,
"Roll": -0.10309021919965744,
"Pitch": 0.8637830018997192
},
"Quality": {
"Sharpness": 95.51618957519531,
"Brightness": 65.29893493652344
},
"Landmarks": [
{
"Y": 0.26721030473709106,
"X": 0.6204193830490112,
"Type": "eyeLeft"
},
{
"Y": 0.26831310987472534,
"X": 0.6776827573776245,
"Type": "eyeRight"
},
{
"Y": 0.3514654338359833,
"X": 0.6241428852081299,
"Type": "mouthLeft"
},
{
"Y": 0.35258132219314575,
"X": 0.6713621020317078,
"Type": "mouthRight"
},
{
"Y": 0.3140771687030792,
"X": 0.6428444981575012,
"Type": "nose"
}
]
},
"Similarity": 100.0
}
],
"SourceImageFace": {
"BoundingBox": {
"Width": 0.12368916720151901,
"Top": 0.16007372736930847,
"Left": 0.5901257991790771,
"Height": 0.25140416622161865
},
"Confidence": 99.0
}
}
Kot lahko vidite zgoraj, je pokazalo, da ni neprimerljivega obraza in da se obraz ujema z 99-odstotno stopnjo zaupanja. Kot dodaten izhod je vrnil tudi omejevalne okvirje. Zdaj pa si poglejmo implementacijo Pythona.
Koda Python
rek_client = boto3.client('rekognition', region_name='us-east-1')
response = rek_client.compare_faces(
SimilarityThreshold=0.9,
SourceImage={
'S3Object': {
'Bucket': bucket,
'Name': idcard_name
}
},
TargetImage={
'S3Object': {
'Bucket': bucket,
'Name': name
}
})
if len(response['FaceMatches']) == 0:
IsMatch = 'False'
Reason = 'Property FaceMatches is empty.'
facenotMatch = False
for match in response['FaceMatches']:
similarity:float = match['Similarity']
if similarity > 0.9:
IsMatch = True,
Reason = 'All checks passed.'
else:
facenotMatch = True
Zgornja koda bo primerjala obraz, zaznan iz osebne izkaznice, in sejo Liveness, pri čemer bo prag ohranil na 90 %. Če se obraz ujema, bo spremenljivka IsMatch nastavljena na True. Tako lahko s samo enim klicem funkcije primerjamo oba obraza, oba sta že naložena v vedro S3.
Tako lahko končno registriramo veljavnega uporabnika in dokončamo njegov KYC. Kot lahko vidite, je to popolnoma avtomatizirano in ga sproži uporabnik, pri čemer ni vključena nobena druga oseba. Postopek je tudi skrajšal vkrcanje uporabnika v primerjavi s trenutnim ročnim postopkom.
4. korak: Poizvedite dokument, kot je GPT
Všeč mi je bila ena od zelo uporabnih funkcij Texttracta, saj lahko postavite posebna vprašanja, na primer »Kaj je številka identitete«. Naj vam pokažem, kako to storite z uporabo AWS CLI.
aws textract analyze-document --document '{"S3Object":{"Bucket":"ARN","Name":"id.jpg"}}'
--feature-types '["QUERIES"]' --queries-config '{"Queries":[{"Text":"What is the Identity No"}]}'Upoštevajte, da sem prej uporabljal funkcijo analy-id, zdaj pa sem za poizvedbo po dokumentu uporabil analy-document. To je zelo uporabno, če so v osebni izkaznici določena polja, ki jih funkcija analiziraj-id ne ekstrahira. Funkcija analize ID-ja deluje dobro za vse osebne izkaznice v ZDA, dobro pa deluje tudi z osebnimi izkaznicami indijske vlade. Kljub temu, če nekatera polja niso ekstrahirana, lahko uporabite funkcijo poizvedbe.
AWS uporablja storitev cognito za upravljanje identitete uporabnika, ID-ja uporabnika in ID-jev obrazov, shranjenih v DynamoDB. Vzorčna koda AWS tudi primerja slike iz obstoječe baze podatkov, tako da se isti uporabnik ne more znova registrirati z drugim ID-jem ali uporabniškim imenom. Ta vrsta validacije je nujna za robusten avtomatiziran sistem KYC.
zaključek
Če sprejmete AWS Rekognition for Automated Self KYC, lahko svoj postopek vključevanja uporabnika spremenite iz težavne ovire v gladko in varno izkušnjo. Amazon Rekognition ponuja robustno rešitev za implementacijo sistemov za preverjanje identitete z naprednimi zmogljivostmi prepoznavanja obraza. Z izkoriščanjem njegovih funkcij lahko razvijalci izboljšajo varnostne ukrepe, poenostavijo postopke preverjanja pristnosti uporabnikov in zagotovijo brezhibno uporabniško izkušnjo v različnih aplikacijah in panogah.
Z zgoraj navedenim izčrpnim vodnikom ste dobro opremljeni, da se podate na pot učinkovitega izvajanja preverjanja identitete z uporabo Amazon Rekognition. Izkoristite moč preverjanja identitete na podlagi umetne inteligence in odklenite nove možnosti na področju upravljanja digitalne identitete.
Ključni izdelki
- Amazon Rekognition ponuja napredne zmožnosti prepoznavanja in analize obraza, kar omogoča poenostavljene in varne postopke preverjanja identitete.
- Omogoča avtomatizirano vključitev uporabnika tako, da pridobi bistvene podatke iz osebnih izkaznic, ki jih je izdal državni organ, in izvede preverjanje stanja.
- Koraki implementacije vključujejo nastavitev storitev AWS, konfiguracijo dovoljenj IAM in uporabo funkcij Python ali grafičnih vmesnikov za ekstrakcijo besedila in primerjave obrazov.
- Preverjanja živosti v realnem času povečujejo varnost, saj zagotavljajo, da so uporabniki prisotni med preverjanjem, medtem ko primerjave obrazov potrdijo identiteto glede na referenčne slike.
Mediji, prikazani v tem članku, niso v lasti Analytics Vidhya in se uporabljajo po lastni presoji avtorja.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.analyticsvidhya.com/blog/2024/03/how-to-implement-identity-verification-using-amazon-rekognition/

