Predstavitev
Retrieval Augmented-Generation (RAG) je svet prevzel Storm že od svojega začetka. RAG je tisto, kar je potrebno, da veliki jezikovni modeli (LLM) zagotovijo ali ustvarijo natančne in dejanske odgovore. Factuality LLMs rešujemo z RAG, kjer poskušamo LLM dati kontekst, ki je kontekstualno podoben uporabniški poizvedbi, tako da bo LLM deloval s tem kontekstom in ustvaril dejansko pravilen odgovor. To naredimo tako, da naše podatke in uporabniško poizvedbo predstavimo v obliki vdelanih vektorjev in izvedemo kosinusno podobnost. Vendar je težava v tem, da vsi tradicionalni pristopi predstavljajo podatke v eni sami vdelavi, kar morda ni idealno za vedno. sistemi za iskanje. V tem priročniku si bomo ogledali ColBERT, ki izvaja iskanje z večjo natančnostjo kot tradicionalni modeli dvokodirnikov.
Učni cilji
- Razumeti, kako iskanje v RAG deluje na visoki ravni.
- Razumeti omejitve posamezne vdelave pri pridobivanju.
- Izboljšajte kontekst iskanja z vdelavami žetonov ColBERT.
- Naučite se, kako pozna interakcija ColBERT izboljša iskanje.
- Spoznajte, kako delati s ColBERT za natančno iskanje.
Ta članek je bil objavljen kot del Blogaton podatkovne znanosti.
Kazalo
Kaj je RAG?
Čeprav so LLM-ji sposobni ustvariti smiselno in slovnično pravilno besedilo, imajo ti LLM-ji težavo, imenovano halucinacije. Halucinacije pri LLM je koncept, kjer LLM-ji samozavestno ustvarijo napačne odgovore, to pomeni, da si izmislijo napačne odgovore na način, da verjamemo, da so resnični. To je velik problem od uvedbe LLM. Te halucinacije vodijo do nepravilnih in dejansko napačnih odgovorov. Zato je bila uvedena razširjena generacija pridobivanja.
V RAG vzamemo seznam dokumentov/kosov dokumentov in kodiramo te besedilne dokumente v numerično predstavitev, imenovano vektorske vdelave, kjer posamezna vektorska vdelava predstavlja en kos dokumenta in jih shrani v bazo podatkov, imenovano vektorska trgovina. Modeli, ki so potrebni za kodiranje teh kosov v vdelave, se imenujejo modeli kodiranja ali dvojni kodirniki. Ti kodirniki so usposobljeni za velik korpus podatkov, zaradi česar so dovolj zmogljivi za kodiranje delov dokumentov v eni vektorski vdelani predstavitvi.
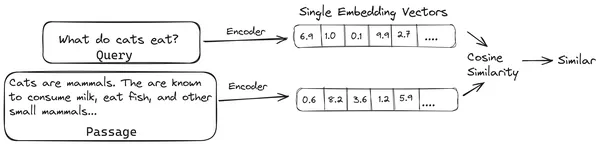
Zdaj, ko uporabnik postavi poizvedbo LLM-ju, damo to poizvedbo istemu kodirniku, da ustvari eno vdelavo vektorja. Ta vdelava se nato uporabi za izračun ocene podobnosti z različnimi drugimi vektorskimi vdelavami delov dokumenta, da se pridobi najbolj relevanten del dokumenta. LLM prejme najustreznejši kos ali seznam najrelevantnejših kosov skupaj z uporabniško poizvedbo. LLM nato prejme te dodatne kontekstualne informacije in nato ustvari odgovor, ki je usklajen s kontekstom, prejetim iz uporabniške poizvedbe. To zagotavlja, da je vsebina, ki jo ustvari LLM, dejanska in da je po potrebi mogoče izslediti nazaj.
Težava s tradicionalnimi bi-kodirniki
Težava s tradicionalnimi modeli kodirnikov, kot je all-miniLM, OpenAI model vdelave in drugi modeli kodirnikov je, da stisnejo celotno besedilo v en sam vektorski vdelani prikaz. Te predstavitve z enim samim vektorjem so uporabne, ker pomagajo pri učinkovitem in hitrem iskanju podobnih dokumentov. Težava pa je v kontekstualnosti med poizvedbo in dokumentom. Vdelava enega samega vektorja morda ne bo zadostovala za shranjevanje kontekstualnih informacij o kosu dokumenta, kar ustvarja informacijsko ozko grlo.
Predstavljajte si, da je 500 besed stisnjenih v en sam vektor velikosti 782. Morda ne bo dovolj, da predstavite tak kos z eno samo vdelavo vektorja, kar v večini primerov daje slabše rezultate pri iskanju. Enotna vektorska predstavitev lahko tudi odpove v primerih kompleksnih poizvedb ali dokumentov. Ena taka rešitev bi bila predstavitev kosa dokumenta ali poizvedbe kot seznama vdelanih vektorjev namesto enega vdelanega vektorja, tukaj nastopi ColBERT.
Kaj je ColBERT?
ColBERT (Contextual Late Interactions BERT) je dvojni kodirnik, ki predstavlja besedilo v predstavitvi vdelave z več vektorji. Vzame poizvedbo ali kos dokumenta / majhen dokument in ustvari vektorske vdelave na ravni žetona. To pomeni, da vsak žeton dobi svojo lastno vdelavo vektorja, poizvedba/dokument pa je kodiran v seznam vdelav vektorja na ravni žetona. Vdelave na ravni žetonov so ustvarjene iz vnaprej usposobljenega BERTI model od tod tudi ime BERT.
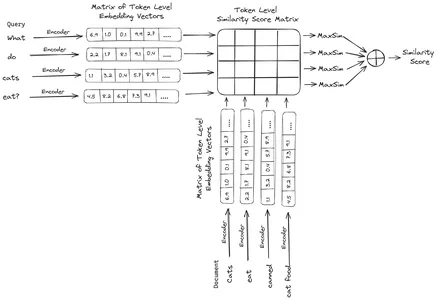
Ti se nato shranijo v vektorsko zbirko podatkov. Zdaj, ko pride poizvedba, se zanjo ustvari seznam vdelav na ravni žetona, nato pa se izvede množenje matrike med uporabniško poizvedbo in vsakim dokumentom, kar povzroči matriko, ki vsebuje rezultate podobnosti. Splošna podobnost se doseže tako, da se za vsak žeton poizvedbe vzame vsota največje podobnosti med žetoni dokumenta. Formula za to je vidna na spodnji sliki:
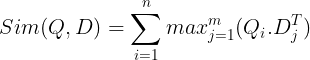
Tukaj v zgornji enačbi vidimo, da naredimo pikčasti produkt med matriko žetonov poizvedbe (ki vsebuje N vdelav vektorjev na ravni žetonov) in matriko transpozicije žetonov dokumentov (ki vsebuje M vdelav vektorjev na ravni žetonov), nato pa vzamemo največjo podobnost prekrižajte žetone dokumenta za vsak žeton poizvedbe. Nato vzamemo vsoto vseh teh največjih podobnosti, ki nam da končno oceno podobnosti med dokumentom in poizvedbo. Razlog, zakaj to ustvari učinkovito in natančno iskanje, je, da imamo tukaj interakcijo na ravni žetona, ki daje prostor za več kontekstualnega razumevanja med poizvedbo in dokumentom.
Zakaj ime ColBERT?
Ker izračunavamo seznam vdelanih vektorjev pred samim seboj in to operacijo MaxSim (največja podobnost) izvajamo samo med sklepanjem modela, kar imenujemo korak pozne interakcije, in ker dobivamo več kontekstualnih informacij prek interakcij na ravni žetona, se imenuje kontekstualno pozne interakcije. Zato ime Kontekstualne pozne interakcije BERTI ali ColBERT. Te izračune je mogoče izvajati vzporedno, zato jih je mogoče učinkovito izračunati. Nazadnje, ena skrb je prostor, kar pomeni, da potrebuje veliko prostora za shranjevanje tega seznama vdelav vektorjev na ravni žetonov. Ta težava je bila rešena v ColBERTv2, kjer so vdelave stisnjene s tehniko, imenovano rezidualno stiskanje, s čimer se optimizira uporabljeni prostor.
Praktični ColBERT s primerom
V tem razdelku bomo spoznali ColBERT in celo preverili, kako deluje v primerjavi z običajnim modelom vdelave.
1. korak: Prenesite knjižnice
Začeli bomo s prenosom naslednje knjižnice:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Ta knjižnica nam omogoča delo z najsodobnejšimi (SOTA) metodami iskanja, kot je ColBERT, na način, ki je enostaven za uporabo. Zagotavlja možnosti za ustvarjanje indeksov nad nabori podatkov, poizvedovanje po njih in nam celo omogoča usposabljanje modela ColBERT na naših podatkih.
- LangChain: Ta knjižnica nam bo omogočila delo z odprtokodnimi modeli vdelave, da bomo lahko preizkusili, kako dobro delujejo drugi modeli vdelave v primerjavi s ColBERT.
- langchain_openai: Namesti LangChain odvisnosti za OpenAI. Delali bomo celo z modelom OpenAI Embedding, da bi preverili njegovo delovanje v primerjavi s ColBERT.
- ChromaDB: Ta knjižnica nam bo omogočila ustvarjanje vektorske shrambe v našem okolju, tako da bomo lahko shranili vdelave, ki smo jih ustvarili v naših podatkih, in kasneje izvedli semantično iskanje med poizvedbo in shranjenimi vdelavami.
- einops: Ta knjižnica je potrebna za učinkovito množenje tenzorskih matrik.
- stavčni transformatorji in tiktoken so potrebni za pravilno delovanje odprtokodnih vdelanih modelov.
2. korak: Prenesite vnaprej pripravljen model
V naslednjem koraku bomo prenesli vnaprej pripravljen model ColBERT. Za to bo koda
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Najprej uvozimo razred RAGPretrainedModel iz knjižnice RAGatouille.
- Nato pokličemo .from_pretrained() in damo ime modela, tj. »colbert-ir/colbertv2.0«.
Zagon zgornje kode bo ustvaril primerek modela ColBERT RAG. Zdaj pa prenesimo stran Wikipedije in izvedimo iskanje z nje. Za to bo koda:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille je opremljen s priročno funkcijo, imenovano get_wikipedia_page, ki sprejme niz in pridobi ustrezno stran Wikipedije. Tukaj prenesemo vsebino Wikipedije o Elonu Musku in jo shranimo v spremenljiv dokument. Natisnimo število besed v dokumentu in prvih nekaj vrstic dokumenta.
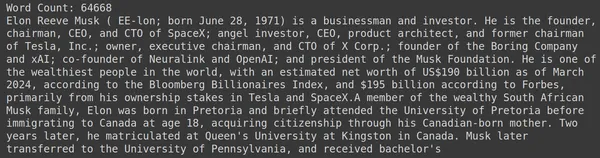
Tukaj lahko vidimo rezultat na sliki. Vidimo lahko, da je na strani Wikipedije Elona Muska skupaj 64,668 besed.
3. korak: Indeksiranje
Zdaj bomo ustvarili indeks tega dokumenta.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Tukaj pokličemo .index() RAG za indeksiranje našega dokumenta. K temu posredujemo naslednje:
- zbirka: To je seznam dokumentov, ki jih želimo indeksirati. Tukaj imamo le en dokument, torej seznam enega samega dokumenta.
- document_ids: Vsak dokument pričakuje edinstven ID dokumenta. Tukaj mu posredujemo ime elon_musk, ker dokument govori o Elonu Musku.
- dokument_metapodatki: Vsak dokument ima svoje metapodatke. To je spet seznam slovarjev, kjer vsak slovar vsebuje metapodatke para ključ-vrednost za določen dokument.
- ime_indeksa: Ime indeksa, ki ga ustvarjamo. Poimenujmo ga Elon2.
- max_document_size: To je podobno velikosti kosa. Določimo, koliko naj obsega vsak kos dokumenta. Tukaj mu dajemo vrednost 256. Če ne podamo nobene vrednosti, bo 256 vzeta kot privzeta velikost kosa.
- split_documents: To je logična vrednost, kjer True označuje, da želimo razdeliti naš dokument glede na dano velikost kosa, False pa označuje, da želimo celoten dokument shraniti kot en kos.
Zagon zgornje kode bo razdelil naš dokument v velikosti 256 na kos, nato pa jih bo vdelal prek modela ColBERT, ki bo izdelal seznam vdelav vektorjev na ravni žetona za vsak kos in jih nazadnje shranil v indeks. Ta korak bo trajal nekaj časa in ga je mogoče pospešiti, če imate GPE. Na koncu ustvari imenik, kjer je shranjen naš indeks. Tukaj bo imenik ».ragatouille/colbert/indexes/Elon2«
4. korak: Splošna poizvedba
Zdaj bomo začeli z iskanjem. Za to bo koda
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Tukaj najprej pokličemo metodo .search() objekta RAG
- Temu podamo spremenljivke, ki vključujejo ime poizvedbe, k (število dokumentov za pridobitev) in ime indeksa za iskanje
- Tukaj ponujamo poizvedbo "Katera podjetja je našel Elon Musk?". Dobljeni rezultat bo v obliki seznama slovarja, ki vsebuje ključe, kot so content, score, rank, document_id, passage_id in document_metadata
- Zato delamo s spodnjo kodo za tiskanje pridobljenih dokumentov na čist način
- Tukaj pregledamo seznam slovarjev in natisnemo vsebino dokumentov
Zagon kode bo dal naslednje rezultate:
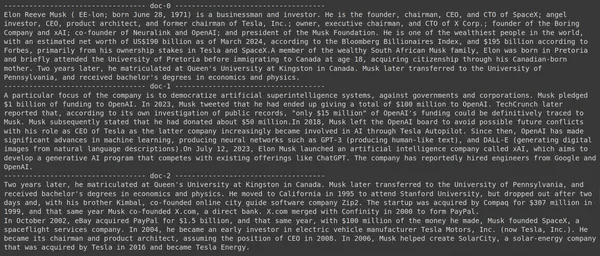
Na sliki lahko vidimo, da prvi in zadnji dokument v celoti pokrivata različna podjetja, ki jih je ustanovil Elon Musk. ColBERT je lahko pravilno pridobil ustrezne dele, potrebne za odgovor na poizvedbo.
5. korak: Posebna poizvedba
Zdaj pa pojdimo še korak dlje in mu postavimo konkretno vprašanje.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])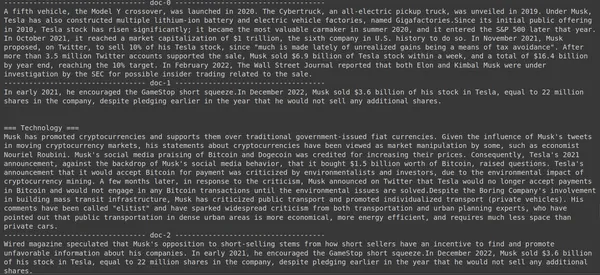
Tukaj v zgornji kodi postavljamo zelo specifično vprašanje o tem, koliko zalog v vrednosti Tesla Elon je bilo prodanih v mesecu decembru 2022. Rezultate lahko vidimo tukaj. Dokument 1 vsebuje odgovor na vprašanje. Elon je prodal svoje delnice v Tesli v vrednosti 3.6 milijarde dolarjev. Ponovno je ColBERT uspel uspešno pridobiti ustrezen kos za dano poizvedbo.
6. korak: Preizkušanje drugih modelov
Poskusimo zdaj isto vprašanje z drugimi odprtokodnimi in zaprtimi modeli vdelave:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Začnemo tako, da najprej prenesemo model prek razreda AutoModel iz knjižnice Transformers.
- Nato shranimo model_name in model_kwargs v njihovih ustreznih spremenljivkah.
- Za delo s tem modelom v LangChainu uvozimo HuggingFaceEmbeddings iz LangChain in mu dajte ime modela in model_kwargs.
Če zaženete to kodo, boste prenesli in naložili vdelani model Jina, da bomo lahko delali z njim
7. korak: Ustvarite vdelave
Zdaj moramo začeti razdeliti naš dokument in nato iz njega ustvariti vdelave ter jih shraniti v vektorsko shrambo Chroma. Za to delamo z naslednjo kodo:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Začnemo z uvozom Chroma in RecursiveCharacterTextSplitter iz knjižnice LangChain
- Nato instanciramo text_splitter tako, da pokličemo .from_tiktoken_encoder RecursiveCharacterTextSplitter in mu posredujemo chunk_size in chunk_overlap
- Tu bomo uporabili isto velikost chunk_size, ki smo jo posredovali ColBERT-u
- Nato pokličemo metodo .split_text() tega text_splitterja in ji damo dokument, ki vsebuje informacije Wikipedije o Elonu Musku. Nato razdeli dokument glede na dano velikost kosov in na koncu se seznam kosov dokumentov shrani v spremenljivke razdelitve
- Na koncu pokličemo funkcijo .from_texts() razreda Chroma, da ustvarimo vektorsko shrambo. Tej funkciji podamo razdelitve, model vdelave in collection_name
- Zdaj iz njega ustvarimo retriever s klicem funkcije .as_retriever() objekta vektorske shrambe. Za vrednost k damo 3
Zagon te kode bo vzel naš dokument, ga razdelil na manjše dokumente velikosti 256 na kos, nato pa te manjše kose vdelal z modelom za vdelavo Jina in te vdelane vektorje shranil v shrambo vektorjev chroma.
8. korak: Ustvarjanje Retrieverja
Nazadnje iz njega ustvarimo prinašalca. Zdaj bomo izvedli vektorsko iskanje in preverili rezultate.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)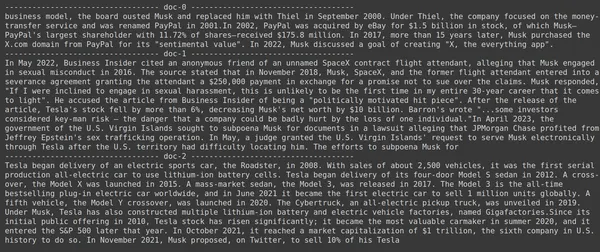
- Pokličemo funkcijo .get_relevent_documents() objekta pridobivanja in ji damo isto poizvedbo.
- Nato lepo natisnemo prve 3 najdene dokumente.
- Na sliki lahko vidimo, da je Jina Embedder kljub temu, da je priljubljen model vdelave, iskanje za našo poizvedbo slabo. Ni uspelo pridobiti pravilnih kosov dokumenta.
Jasno lahko opazimo razliko med Jina, modelom vdelave, ki predstavlja vsak kos kot eno vdelavo vektorja, in modelom ColBERT, ki predstavlja vsak kos kot seznam vdelanih vektorjev na ravni žetona. ColBERT v tem primeru očitno prekaša.
9. korak: Preizkušanje modela vdelave OpenAI
Zdaj pa poskusimo uporabiti zaprtokodni model vdelave, kot je model vdelave OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Tukaj je koda zelo podobna tisti, ki smo jo pravkar napisali
- Edina razlika je, da posredujemo ključ OpenAI API za nastavitev spremenljivke okolja.
- Nato ustvarimo primerek modela OpenAI Embedding tako, da ga uvozimo iz LangChaina.
- Med ustvarjanjem imena zbirke podamo drugo ime zbirke, tako da so vdelave iz modela vdelave OpenAI shranjene v drugi zbirki.
Zagon te kode bo ponovno vzel naše dokumente, jih razdelil na manjše dokumente velikosti 256 in jih nato vdelal v enojno vektorsko vdelano predstavitev z modelom vdelave OpenAI in na koncu shranil te vdelave v Chroma Vector Store. Zdaj pa poskusimo pridobiti ustrezne dokumente za drugo vprašanje.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)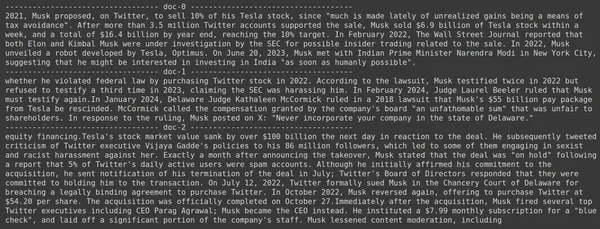
- Vidimo, da odgovora, ki ga pričakujemo, ni mogoče najti v pridobljenih kosih.
- Prvi del vsebuje informacije o delnicah Tesle v letu 2022, vendar ne govori o tem, da bi jih Elon prodal.
- Enako lahko opazimo pri preostalih dveh delih dokumentov, kjer so informacije o Tesli in njenih delnicah, vendar to niso informacije, ki jih pričakujemo.
- Zgoraj pridobljeni kosi ne bodo zagotovili konteksta za LLM za odgovor na poizvedbo, ki smo jo posredovali.
Tudi tukaj lahko vidimo jasno razliko med predstavitvijo vdelave z enim vektorjem in predstavitvijo z več vektorji. Predstavitve z več vdelavami jasno zajamejo zapletene poizvedbe, kar povzroči natančnejše iskanje.
zaključek
Skratka, ColBERT dokazuje pomemben napredek v zmogljivosti iskanja v primerjavi s tradicionalnimi modeli dvokodirnikov, tako da predstavlja besedilo kot večvektorske vdelave na ravni žetona. Ta pristop omogoča bolj niansirano kontekstualno razumevanje med poizvedbami in dokumenti, kar vodi do natančnejših rezultatov iskanja in blaži vprašanje halucinacij, ki so običajno opažene pri LLM.
Ključni izdelki
- RAG obravnava problem halucinacij pri LLM z zagotavljanjem kontekstualnih informacij za ustvarjanje dejanskega odgovora.
- Tradicionalni dvojni kodirniki trpijo zaradi informacijskega ozkega grla zaradi stiskanja celotnih besedil v posamezne vektorske vdelave, zaradi česar je natančnost iskanja nižja.
- ColBERT s svojo predstavitvijo vdelave na ravni žetona omogoča boljše kontekstualno razumevanje med poizvedbami in dokumenti, kar vodi do izboljšane zmogljivosti iskanja.
- Korak pozne interakcije v ColBERT v kombinaciji z interakcijami na ravni žetonov poveča natančnost priklica z upoštevanjem kontekstualnih nians.
- ColBERTv2 optimizira prostor za shranjevanje s preostalim stiskanjem, hkrati pa ohranja učinkovitost iskanja.
- Praktični poskusi dokazujejo superiornost ColBERT-a v zmogljivosti iskanja v primerjavi s tradicionalnimi in odprtokodnimi modeli vdelave, kot sta Jina in OpenAI Embedding.
Pogosto zastavljena vprašanja
A. Tradicionalni dvojni kodirniki stisnejo celotna besedila v posamezne vektorske vdelave, pri čemer lahko izgubijo kontekstualne informacije. To omejuje njihovo učinkovitost pri nalogah iskanja, zlasti pri kompleksnih poizvedbah ali dokumentih.
A. ColBERT (Contextual Late Interactions BERT) je model dvojnega kodirnika, ki predstavlja besedilo z vdelavami vektorjev na ravni žetonov. Omogoča bolj niansirano kontekstualno razumevanje med poizvedbami in dokumenti, kar izboljša natančnost iskanja.
A. ColBERT generira vdelave na ravni žetonov za poizvedbe in dokumente, izvaja matrično množenje za izračun rezultatov podobnosti in nato izbere najbolj ustrezne informacije na podlagi največje podobnosti med žetoni. To omogoča učinkovito iskanje s kontekstualnim razumevanjem.
A. ColBERTv2 optimizira prostor z metodo rezidualnega stiskanja, s čimer zmanjša zahteve za shranjevanje za vdelave na ravni žetonov, hkrati pa ohranja natančnost pridobivanja.
A. Za preprosto delo s ColBERT lahko uporabite knjižnice, kot je RAGatouille. Z indeksiranjem dokumentov in poizvedb lahko izvajate učinkovite naloge iskanja in ustvarite natančne odgovore, usklajene s kontekstom.
Mediji, prikazani v tem članku, niso v lasti Analytics Vidhya in se uporabljajo po lastni presoji avtorja.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

