Mnoga podjetja selijo svoje lokalne podatkovne shrambe v AWS Cloud. Med selitvijo podatkov je ključna zahteva preverjanje vseh podatkov, ki so bili premaknjeni iz vira v cilj. To preverjanje veljavnosti podatkov je kritičen korak in če se ne izvede pravilno, lahko povzroči neuspeh celotnega projekta. Vendar je lahko razvijanje rešitev po meri za določanje točnosti selitve s primerjavo podatkov med virom in ciljem pogosto zamudno.
V tej objavi se korak za korakom sprehodimo skozi postopek preverjanja velikih naborov podatkov po selitvi z uporabo konfiguracijskega orodja z Amazonski EMR in odprtokodno knjižnico Apache Griffin. Griffin je odprtokodna rešitev za kakovost podatkov za velike podatke, ki podpira paketni in pretočni način.
V današnjem okolju, ki temelji na podatkih, kjer se organizacije ukvarjajo s petabajti podatkov, postaja potreba po avtomatiziranih ogrodjih za preverjanje podatkov vse bolj kritična. Postopki ročnega potrjevanja niso le dolgotrajni, temveč tudi nagnjeni k napakam, zlasti pri obravnavi velikih količin podatkov. Samodejni okviri za preverjanje veljavnosti podatkov ponujajo poenostavljeno rešitev z učinkovito primerjavo velikih naborov podatkov, prepoznavanjem neskladij in zagotavljanjem točnosti podatkov v velikem obsegu. S takšnimi okviri lahko organizacije prihranijo dragocen čas in vire, hkrati pa ohranijo zaupanje v celovitost svojih podatkov, s čimer omogočijo sprejemanje odločitev na podlagi informacij in izboljšajo splošno operativno učinkovitost.
Naslednje so izjemne lastnosti tega ogrodja:
- Uporablja ogrodje, ki temelji na konfiguraciji
- Ponuja funkcijo plug-and-play za brezhibno integracijo
- Izvede primerjavo štetja, da ugotovi morebitna odstopanja
- Izvaja robustne postopke potrjevanja podatkov
- Zagotavlja kakovost podatkov s sistematičnimi pregledi
- Omogoča dostop do datoteke, ki vsebuje neujemajoče se zapise za poglobljeno analizo
- Ustvari izčrpna poročila za vpoglede in sledenje
Pregled rešitev
Ta rešitev uporablja naslednje storitve:
- Preprosta storitev shranjevanja Amazon (Amazon S3) ali Hadoop Distributed File System (HDFS) kot vir in cilj.
- Amazonski EMR za zagon skripta PySpark. Za preverjanje podatkov med tabelami Hadoop, ustvarjenimi prek HDFS ali Amazon S3, uporabljamo ovoj Python na vrhu Griffina.
- AWS lepilo katalogizirati tehnično tabelo, v kateri so shranjeni rezultati opravila Griffin.
- Amazonska Atena za poizvedbo izhodne tabele za preverjanje rezultatov.
Uporabljamo tabele, ki hranijo štetje za vsako izvorno in ciljno tabelo, prav tako pa ustvarjamo datoteke, ki prikazujejo razliko med zapisi med izvorom in ciljem.
Naslednji diagram prikazuje arhitekturo rešitev.
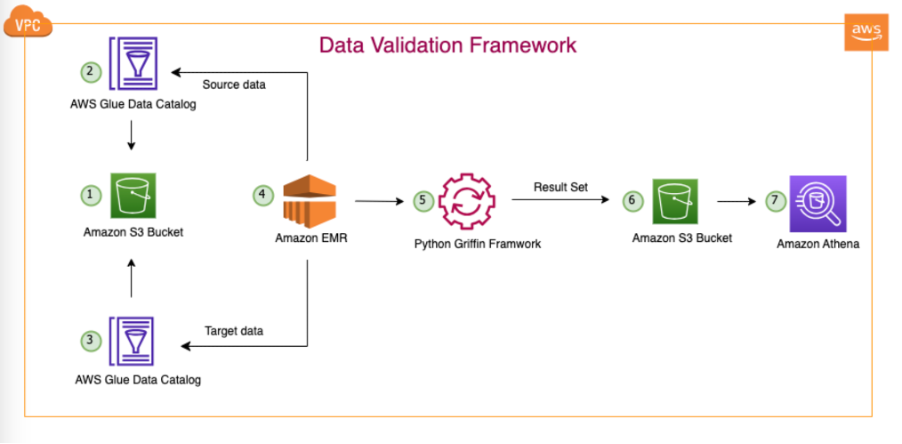
V predstavljeni arhitekturi in našem tipičnem primeru uporabe podatkovnega jezera se naši podatki nahajajo v Amazonu S3 ali pa se preselijo iz lokala v Amazon S3 z orodji za podvajanje, kot je AWS DataSync or Storitev za selitev baze podatkov AWS (AWS DMS). Čeprav je ta rešitev zasnovana za brezhibno interakcijo s Hive Metastore in AWS Glue Data Catalog, v tej objavi kot primer uporabljamo Data Catalog.
To ogrodje deluje znotraj Amazon EMR in samodejno izvaja načrtovane naloge na dnevni osnovi, glede na opredeljeno pogostost. Ustvari in objavi poročila v Amazon S3, ki so nato dostopna prek Athene. Pomembna značilnost tega ogrodja je njegova zmožnost zaznavanja neujemanja števila in neskladja podatkov, poleg tega pa ustvari datoteko v Amazonu S3, ki vsebuje celotne zapise, ki se ne ujemajo, kar olajša nadaljnjo analizo.
V tem primeru uporabljamo tri tabele v zbirki podatkov na mestu uporabe za preverjanje med virom in ciljem: balance_sheet, covidin survery_financial_report.
Predpogoji
Preden začnete, se prepričajte, da imate naslednje pogoje:
Uvedite rešitev
Da bi vam olajšali začetek, smo ustvarili predlogo CloudFormation, ki samodejno konfigurira in uvede rešitev namesto vas. Izvedite naslednje korake:
- V svojem računu AWS ustvarite vedro S3, imenovano
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(navedite svoj ID računa AWS in regijo AWS). - Razpakirajte naslednje datoteka v vaš lokalni sistem.
- Ko razpakirate datoteko v lokalni sistem, spremenite tistemu, ki ste ga ustvarili v svojem računu (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) v naslednjih datotekah:bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- Naložite vse mape in datoteke v lokalni mapi v vedro S3:
- Zaženite naslednje Predloga za oblikovanje v oblaku v vašem računu.
Predloga CloudFormation ustvari bazo podatkov, imenovano griffin_datavalidation_blog in iskalnik AWS Glue crawler griffin_data_validation_blog na vrhu podatkovne mape v datoteki .zip.
- Izberite Naslednji.
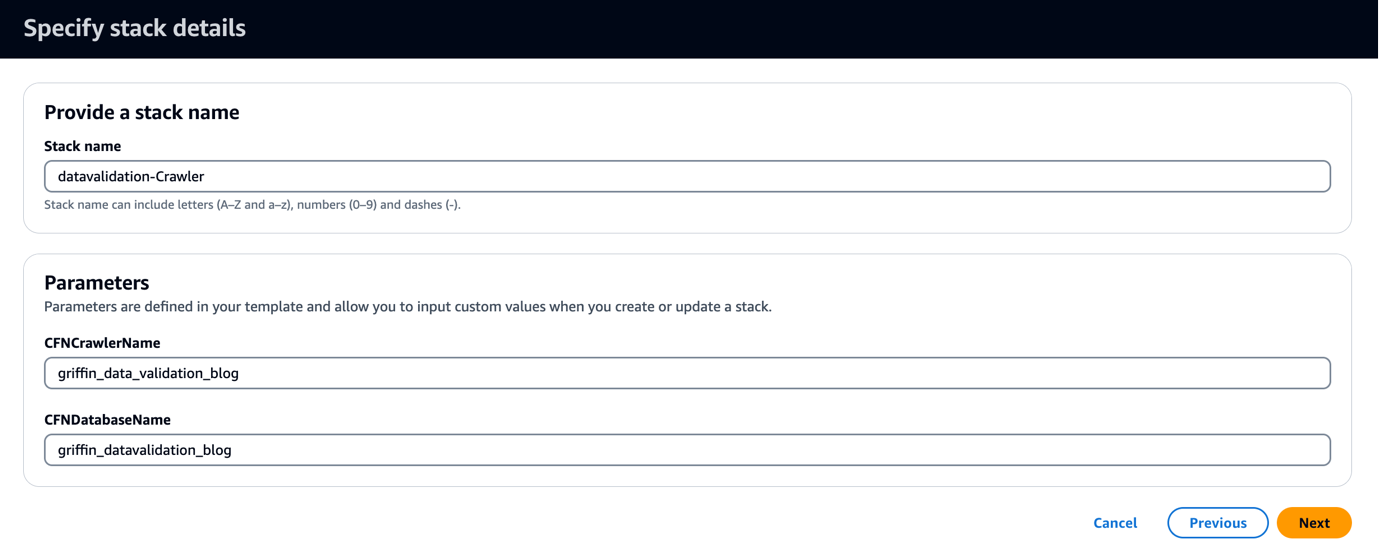
- Izberite Naslednji še enkrat.
- o pregled stran, izberite Zavedam se, da AWS CloudFormation lahko ustvari vire IAM z imeni po meri.
- Izberite Ustvari sklad.
Ti lahko ogled izhodov sklada o Konzola za upravljanje AWS ali z uporabo naslednjega ukaza AWS CLI:
- Zaženite pajka AWS Glue in preverite, ali je bilo v podatkovnem katalogu ustvarjenih šest tabel.
- Zaženite naslednje Predloga za oblikovanje v oblaku v vašem računu.
Ta predloga ustvari gručo EMR z zagonskim skriptom za kopiranje datotek JAR in artefaktov, povezanih z Griffinom. Izvaja tudi tri korake EMR:
- Ustvarite dve tabeli Athena in dva pogleda Athena, da si ogledate validacijsko matriko, ki jo izdela ogrodje Griffin
- Zaženite preverjanje števila za vse tri tabele, da primerjate izvorno in ciljno tabelo
- Izvedite preverjanja na ravni zapisov in stolpcev za vse tri tabele za primerjavo med izvorno in ciljno tabelo
- za SubnetID, vnesite svoj podomrežni ID.
- Izberite Naslednji.
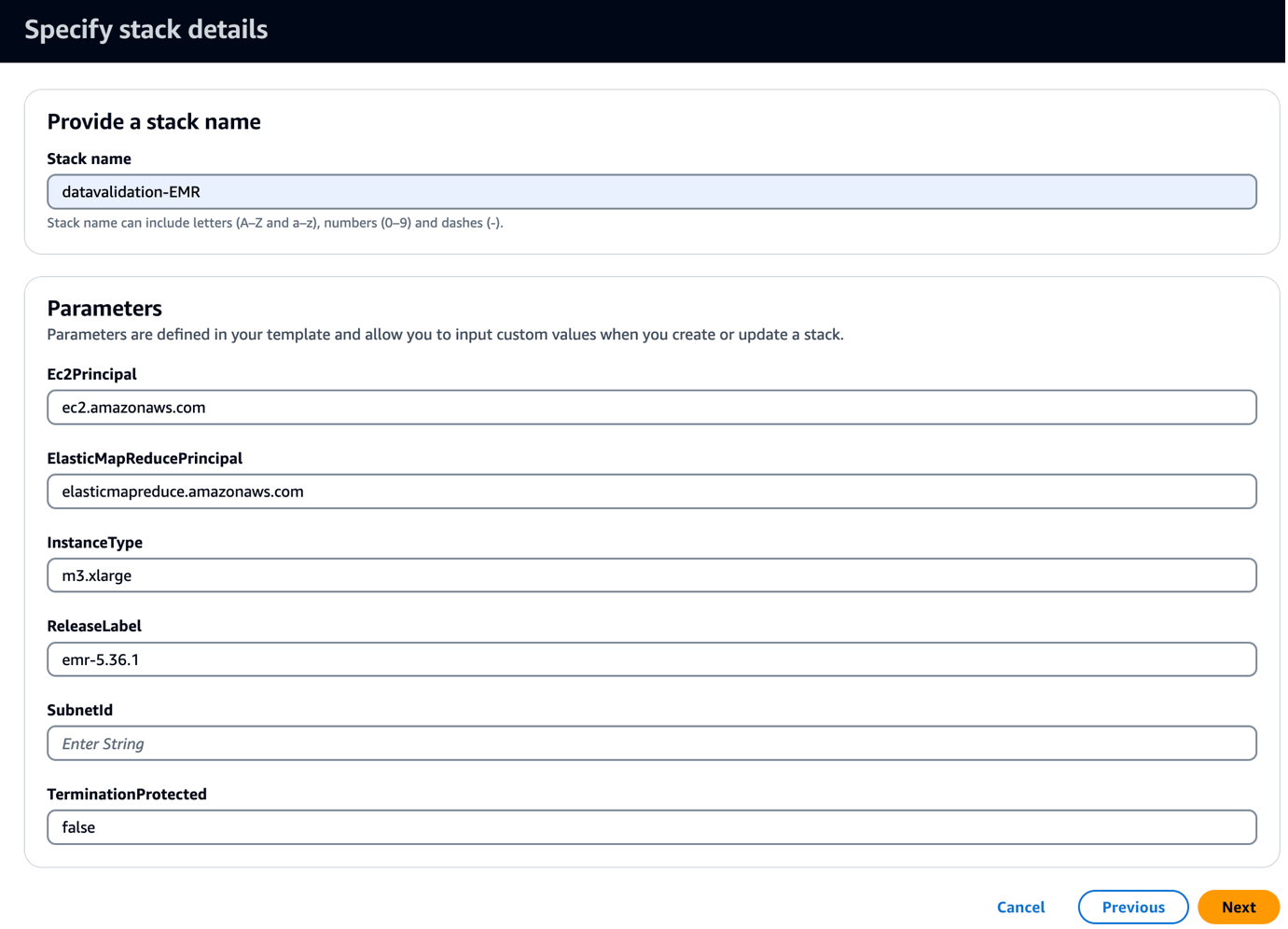
- Izberite Naslednji še enkrat.
- o pregled stran, izberite Zavedam se, da AWS CloudFormation lahko ustvari vire IAM z imeni po meri.
- Izberite Ustvari sklad.
Izhode sklada si lahko ogledate na konzoli ali z uporabo naslednjega ukaza AWS CLI:
Razmestitev traja približno 5 minut. Ko je sklad končan, bi morali videti EMRCluster vir zagnan in na voljo v vašem računu.
Ko je gruča EMR zagnana, izvaja naslednje korake kot del zagona po gruči:
- Bootstrap dejanje – Namesti datoteko Griffin JAR in imenike za to ogrodje. Prenese tudi vzorčne podatkovne datoteke za uporabo v naslednjem koraku.
- Athena_Table_Creation – Ustvari tabele v Atheni za branje poročil o rezultatih.
- Count_Validation – Zažene opravilo za primerjavo števila podatkov med izvornimi in ciljnimi podatki iz tabele Data Catalog in shrani rezultate v vedro S3, ki bo prebrano prek tabele Athena.
- natančnost – Zažene opravilo za primerjavo podatkovnih vrstic med izvornimi in ciljnimi podatki iz tabele Data Catalog in shrani rezultate v vedro S3, ki bo prebrano prek tabele Athena.
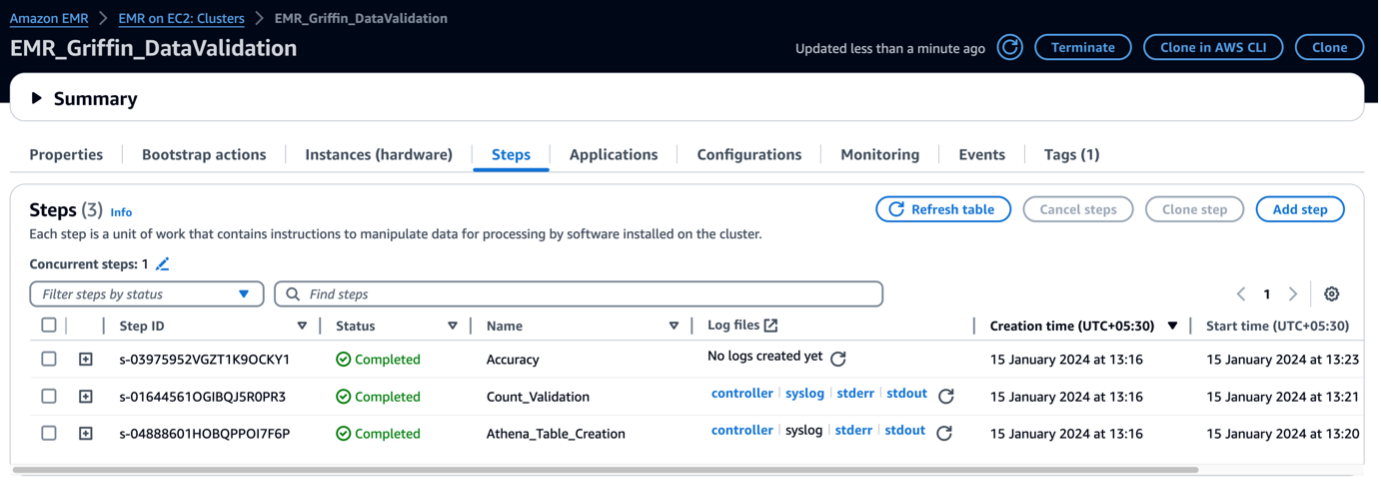
Ko so koraki EMR končani, je vaša primerjava tabel končana in pripravljena za samodejno ogled v Atheni. Za validacijo ni potreben ročni poseg.
Preverjanje podatkov s Python Griffin
Ko je vaša gruča EMR pripravljena in so vsa opravila dokončana, to pomeni, da sta validacija števila in validacija podatkov končana. Rezultati so bili shranjeni v Amazon S3 in poleg tega je že ustvarjena tabela Athena. Za ogled rezultatov lahko poizvedujete po tabelah Athena, kot je prikazano na naslednjem posnetku zaslona.
Naslednji posnetek zaslona prikazuje rezultate štetja za vse tabele.
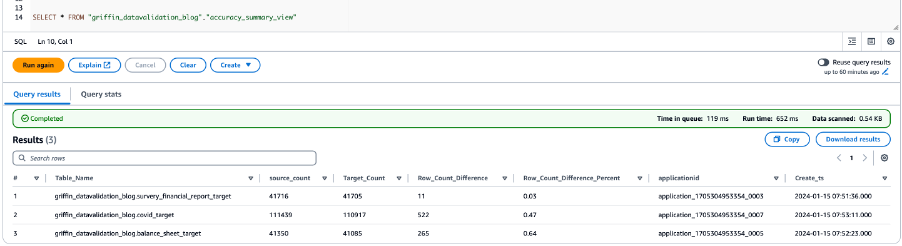
Naslednji posnetek zaslona prikazuje rezultate točnosti podatkov za vse tabele.
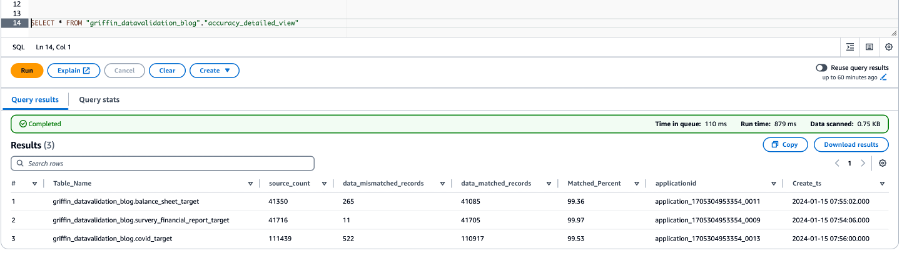
Naslednji posnetek zaslona prikazuje datoteke, ustvarjene za vsako tabelo z neujemajočimi se zapisi. Posamezne mape se ustvarijo za vsako tabelo neposredno iz opravila.
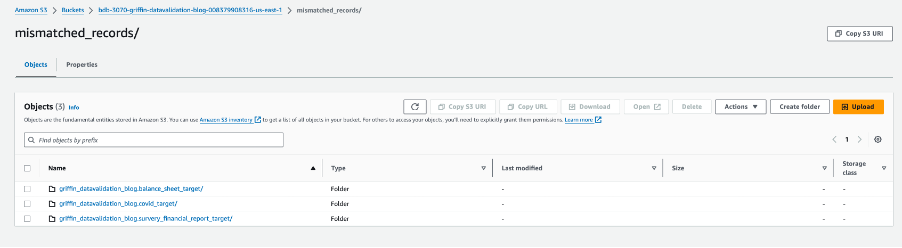
Vsaka mapa tabele vsebuje imenik za vsak dan izvajanja opravila.
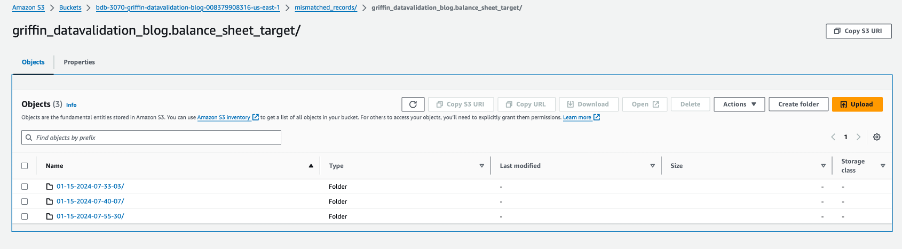
V tem določenem datumu je datoteka z imenom __missRecords vsebuje zapise, ki se ne ujemajo.

Naslednji posnetek zaslona prikazuje vsebino __missRecords Datoteka.

Čiščenje
Da bi se izognili dodatnim stroškom, izvedite naslednje korake za čiščenje virov, ko končate z rešitvijo:
- Izbrišite bazo podatkov AWS Glue
griffin_datavalidation_blogin spustite bazo podatkovgriffin_datavalidation_blogkaskada. - Izbrišite predpone in predmete, ki ste jih ustvarili iz vedra
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - Izbrišite sklad CloudFormation, kar odstrani vaše dodatne vire.
zaključek
Ta objava je pokazala, kako lahko uporabite Python Griffin za pospešitev postopka preverjanja podatkov po selitvi. Python Griffin vam pomaga izračunati štetje ter preverjanje veljavnosti na ravni vrstic in stolpcev, pri čemer identificira neujemajoče se zapise brez pisanja kode.
Za več informacij o primerih uporabe kakovosti podatkov glejte Začetek uporabe AWS Glue Data Quality iz kataloga AWS Glue Data Catalog in Kakovost podatkov AWS Glue.
O avtorjih
 Dipal Mahajan služi kot vodilni svetovalec pri Amazon Web Services in zagotavlja strokovne smernice globalnim strankam pri razvoju zelo varnih, razširljivih, zanesljivih in stroškovno učinkovitih aplikacij v oblaku. Z bogatimi izkušnjami na področju razvoja programske opreme, arhitekture in analitike v različnih sektorjih, kot so finance, telekomunikacije, maloprodaja in zdravstvo, prinaša neprecenljive vpoglede v svojo vlogo. Poleg poklicne sfere Dipal uživa v raziskovanju novih destinacij, saj je obiskal že 14 od 30 držav na njegovem seznamu želja.
Dipal Mahajan služi kot vodilni svetovalec pri Amazon Web Services in zagotavlja strokovne smernice globalnim strankam pri razvoju zelo varnih, razširljivih, zanesljivih in stroškovno učinkovitih aplikacij v oblaku. Z bogatimi izkušnjami na področju razvoja programske opreme, arhitekture in analitike v različnih sektorjih, kot so finance, telekomunikacije, maloprodaja in zdravstvo, prinaša neprecenljive vpoglede v svojo vlogo. Poleg poklicne sfere Dipal uživa v raziskovanju novih destinacij, saj je obiskal že 14 od 30 držav na njegovem seznamu želja.
 Akhil je vodilni svetovalec pri AWS Professional Services. Strankam pomaga pri načrtovanju in izgradnji razširljivih rešitev za analizo podatkov ter pri selitvi podatkovnih cevovodov in podatkovnih skladišč v AWS. V prostem času rad potuje, igra igrice in gleda filme.
Akhil je vodilni svetovalec pri AWS Professional Services. Strankam pomaga pri načrtovanju in izgradnji razširljivih rešitev za analizo podatkov ter pri selitvi podatkovnih cevovodov in podatkovnih skladišč v AWS. V prostem času rad potuje, igra igrice in gleda filme.
 Ramesh Raghupathy je višji podatkovni arhitekt pri WWCO ProServe pri AWS. Sodeluje s strankami AWS pri načrtovanju, uvajanju in selitvi v podatkovna skladišča in podatkovna jezera v oblaku AWS. Medtem ko ni v službi, Ramesh uživa v potovanjih, preživljanju časa z družino in jogi.
Ramesh Raghupathy je višji podatkovni arhitekt pri WWCO ProServe pri AWS. Sodeluje s strankami AWS pri načrtovanju, uvajanju in selitvi v podatkovna skladišča in podatkovna jezera v oblaku AWS. Medtem ko ni v službi, Ramesh uživa v potovanjih, preživljanju časa z družino in jogi.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/

