Storitev Amazon OpenSearch je nedavno predstavil družino optimiziranih primerkov OpenSearch (OR1), ki zagotavlja do 30-odstotno izboljšanje cene in zmogljivosti v primerjavi z obstoječimi primerki, optimiziranimi za pomnilnik, v internih merilih uspešnosti in uporablja Preprosta storitev shranjevanja Amazon (Amazon S3), ki zagotavlja 11 9s vzdržljivosti. S to novo družino instanc storitev OpenSearch uporablja inovacije OpenSearch in tehnologije AWS, da si na novo zamisli, kako se podatki indeksirajo in shranjujejo v oblaku.
Danes stranke široko uporabljajo storitev OpenSearch za operativno analitiko zaradi njene zmožnosti vnosa velikih količin podatkov, hkrati pa zagotavljajo bogato in interaktivno analitiko. Da bi zagotovil te prednosti, je OpenSearch zasnovan kot porazdeljen sistem velikega obsega z več neodvisnimi primerki, ki indeksirajo podatke in obdelujejo zahteve. Ko se hitrost podatkov vaše operativne analitike in obseg podatkov povečujeta, se lahko pojavijo ozka grla. Da bi trajnostno podprli velik obseg indeksiranja in zagotovili vzdržljivost, smo zgradili družino primerkov OR1.
V tem prispevku razpravljamo o tem, kako prenovljeni tok podatkov deluje s primerki OR1 in kako lahko zagotovi visoko prepustnost indeksiranja in vzdržljivost z uporabo novega protokola za fizično podvajanje. Prav tako se poglobimo v nekatere izzive, ki smo jih rešili, da bi ohranili pravilnost in celovitost podatkov.
Oblikovanje za visoko zmogljivost z 11 9s vzdržljivosti
Storitev OpenSearch upravlja več deset tisoč gruč OpenSearch. Pridobili smo vpogled v tipične konfiguracije gruč, ki jih stranke uporabljajo za doseganje ciljev visoke prepustnosti in vzdržljivosti. Da bi dosegli večjo prepustnost, se stranke pogosto odločijo, da izpustijo kopije replik, da prihranijo zakasnitev podvajanja; vendar ta konfiguracija povzroči žrtvovanje razpoložljivosti in vzdržljivosti. Druge stranke zahtevajo visoko vzdržljivost in posledično morajo vzdrževati več replik, kar ima za posledico višje operativne stroške.
Družina OpenSearch Optimized Instance zagotavlja dodatno vzdržljivost, hkrati pa ohranja nižje stroške s shranjevanjem kopije podatkov na Amazon S3. Z instancami OR1 lahko konfigurirate več replik kopij za visoko razpoložljivost branja, hkrati pa ohranjate prepustnost indeksiranja.
Naslednji diagram prikazuje potek indeksiranja, ki vključuje posodobitev metapodatkov v OR1
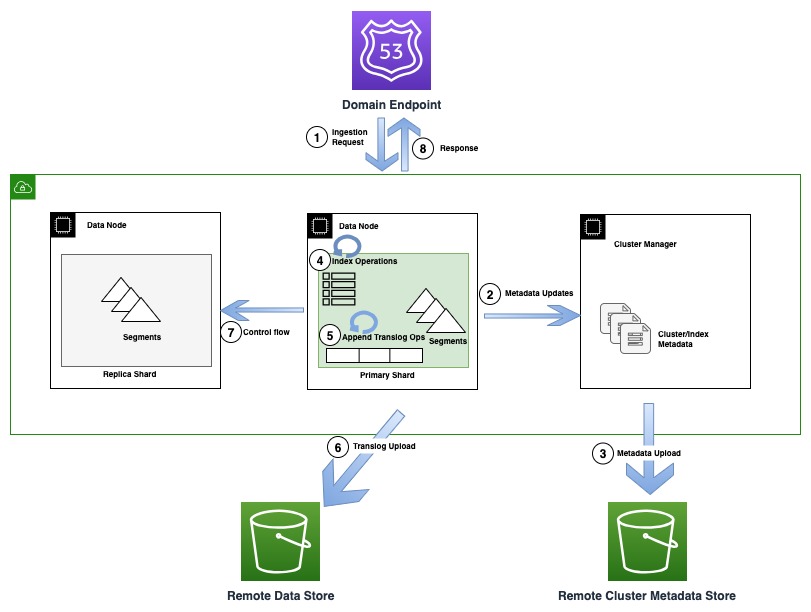
Med operacijami indeksiranja so posamezni dokumenti indeksirani v Lucene in dodani v dnevnik vnaprejšnjega pisanja, znan tudi kot translog. Preden odjemalcu pošljete potrditev, se vse operacije prevajanja ohranijo v oddaljeni shrambi podatkov, ki jo podpira Amazon S3. Če so konfigurirane katere koli replike kopije, primarna kopija izvede preverjanja, da zazna možnost več zapisovalcev (nadzorni tok) na vseh replikah zaradi pravilnosti.
Naslednji diagram prikazuje generiranje segmenta in potek replikacije v primerkih OR1
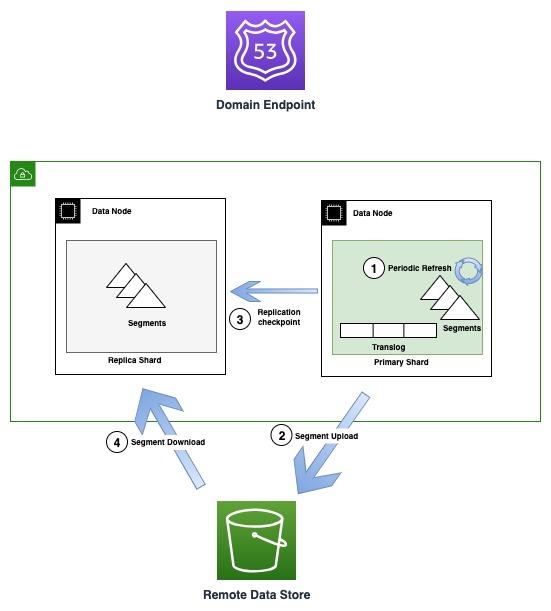
Občasno, ko se ustvarijo nove segmentne datoteke, OR1 kopira te segmente v Amazon S3. Ko je prenos končan, primarni objavi nove kontrolne točke za vse replike in jih obvesti, da je nov segment na voljo za prenos. Kopije replike nato prenesejo novejše segmente in omogočijo iskanje po njih. Ta model ločuje podatkovni tok, ki se zgodi z uporabo storitve Amazon S3, in nadzorni tok (objava kontrolne točke in validacija izrazov), ki se zgodi prek transportne komunikacije med vozlišči.
Naslednji diagram prikazuje potek obnovitve v primerkih OR1
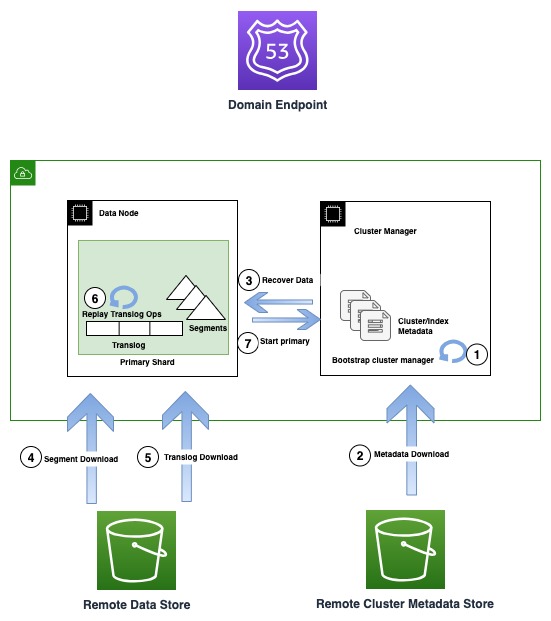
Primerki OR1 ne ohranjajo le podatkov, temveč tudi metapodatke gruče, kot so preslikave indeksov, predloge in nastavitve v Amazon S3. To zagotavlja, da lahko OpenSearch v primeru izgube kvoruma upravljalnika gruč, kar je običajni način napake v nenamenskih nastavitvah upravljalnika gruč, zanesljivo obnovi zadnje potrjene metapodatke.
V primeru okvare infrastrukture lahko domena OpenSearch na koncu izgubi eno ali več vozlišč. V takem primeru nova družina primerkov jamči obnovitev tako metapodatkov gruče kot podatkov indeksa do zadnje potrjene operacije. Ko se nova nadomestna vozlišča pridružijo gruči, notranji mehanizem za obnovitev gruče zažene nov niz vozlišč in nato obnovi najnovejše metapodatke gruče iz oddaljene shrambe metapodatkov gruče. Ko so metapodatki gruče obnovljeni, obnovitveni mehanizem začne hidrirati manjkajoče segmentne podatke in prenesti iz Amazon S3. Nato se ponovno predvajajo vse neobvezne operacije prevajanja, do zadnje potrjene operacije, da se ponovno vzpostavi izgubljena kopija.
Nova oblika ne spremeni načina iskanja. Poizvedbe običajno obdeluje primarni del ali replika za vsak del v indeksu. Morda boste videli daljše zakasnitve (v razponu 10 sekund), preden bodo vse kopije skladne z določeno časovno točko, ker podvajanje podatkov uporablja Amazon S3.
Ključna prednost te arhitekture je, da služi kot temeljni gradnik za prihodnje inovacije, kot je ločevanje bralcev in zapisovalcev, ter pomaga ločevati računalniške in pomnilniške plasti.
Kako redefiniranje strategije podvajanja poveča prepustnost indeksiranja
OpenSearch podpira dve strategiji podvajanja: logično (dokument) in fizično (segment) podvajanje. V primeru logičnega podvajanja se podatki indeksirajo na vseh kopijah neodvisno, kar vodi do redundantnega računanja v gruči. Primerki OR1 uporabljajo novo fizična replikacija model, kjer se podatki indeksirajo samo na primarni kopiji, dodatne kopije pa se ustvarijo s kopiranjem podatkov iz primarne. Pri velikem številu replik kopij vozlišče, ki gosti primarno kopijo, zahteva precejšnjo pasovno širino omrežja, kar podvoji segment na vse kopije. Nove instance OR1 rešujejo to težavo tako, da trajno ohranijo segment za Amazon S3, ki je konfiguriran kot oddaljeno shranjevanje možnost. Pomagajo tudi pri skaliranju replik brez ozkega grla na primarnem.
Ko so segmenti naloženi v Amazon S3, primarni pošlje zahtevo za kontrolno točko in obvesti vse replike, naj prenesejo nove segmente. Kopije replik morajo nato prenesti inkrementalne segmente. Ker ta postopek sprosti računalniške vire na replikah, ki so sicer potrebni za redundantno indeksiranje podatkov in omrežne stroške, ki nastanejo pri primarnih za repliciranje podatkov, lahko gruča poveča prepustnost. V primeru, da replike ne morejo obdelati novo ustvarjenih segmentov zaradi preobremenjenosti ali počasnih omrežnih poti, so replike, ki presegajo točko, označene kot neuspešne, kar preprečuje, da bi vrnile zastarele rezultate.
Zakaj je visoka vzdržljivost dobra ideja, vendar jo je težko narediti dobro
Čeprav so vsi dodeljeni segmenti trajno ohranjeni v Amazonu S3, kadar koli so ustvarjeni, je eden od ključnih izzivov pri doseganju visoke vzdržljivosti sinhrono pisanje vseh neobveznih operacij v dnevnik vnaprejšnjega pisanja na Amazonu S3, preden se zahteva nazaj potrdi odjemalcu, brez žrtvovanja prepustnost. Nova semantika uvaja dodatno omrežno zakasnitev za posamezne zahteve, vendar smo zagotovili, da to ne vpliva na prepustnost, s paketnim združevanjem in praznjenjem zahtev v eni sami niti do določenega intervala, hkrati pa zagotavljamo, da druge niti še naprej indeksirajo zahteve. Posledično lahko dosežete višjo prepustnost z več sočasnimi povezavami odjemalcev z optimalnim razvrščanjem velikih količin.
Drugi izzivi pri načrtovanju zelo vzdržljivega sistema vključujejo ves čas uveljavljanje celovitosti in pravilnosti podatkov. Čeprav so nekateri dogodki, kot so omrežne particije, redki, lahko motijo pravilnost sistema, zato mora biti sistem pripravljen na spopadanje s temi načini napak. Zato smo ob prehodu na nov protokol za replikacijo segmenta uvedli tudi nekaj drugih sprememb protokola, kot je zaznavanje več pisateljev na vsaki replici. Protokol zagotavlja, da izoliran pisatelj ne more potrditi zahteve za pisanje, medtem ko drug na novo povišan primarni, ki temelji na kvorumu upravitelja gruč, hkrati sprejema novejša pisanja.
Nova družina instanc samodejno zazna izgubo primarnega drobca med obnavljanjem podatkov in izvede obsežna preverjanja dosegljivosti omrežja, preden se lahko podatki ponovno hidrirajo iz Amazon S3 in se gruča povrne v zdravo stanje.
Za celovitost podatkov so vse datoteke obsežno seštete, da zagotovimo, da lahko odkrijemo in preprečimo poškodbe omrežja ali datotečnega sistema, ki lahko povzročijo neberljivost podatkov. Poleg tega so vse datoteke, vključno z metapodatki, zasnovane tako, da so nespremenljive, kar zagotavlja dodatno zaščito pred poškodbami in različico za preprečevanje nenamernih spreminjajočih se sprememb.
Ponovno predstavljanje pretoka podatkov
Primerki OR1 hidrirajo kopije neposredno iz Amazona S3, da izvedejo obnovitev izgubljenih drobcev med okvaro infrastrukture. Z uporabo Amazon S3 lahko sprostimo omrežno pasovno širino primarnega vozlišča, prepustnost diska in računanje ter tako zagotovimo bolj brezhibno skaliranje na mestu in modro/zeleno izkušnjo uvajanja z orkestriranjem celotnega procesa z minimalno koordinacijo primarnega vozlišča.
OpenSearch Service zagotavlja samodejno varnostno kopiranje podatkov, imenovano posnetki v urnih intervalih, kar pomeni, da imate v primeru nenamernih sprememb podatkov možnost, da se vrnete na prejšnje časovno stanje. Vendar pa smo pri novi družini primerkov OpenSearch razpravljali o tem, da so podatki že trajno shranjeni v Amazonu S3. Kako torej delujejo posnetki, ko že imamo podatke na Amazon S3?
Z novo družino primerkov posnetki služijo kot kontrolne točke, ki se sklicujejo na že obstoječe podatke segmenta, kakršni obstajajo v določenem trenutku. Zaradi tega so posnetki lažji in hitrejši, ker jim ni treba znova nalagati dodatnih podatkov. Namesto tega naložijo metapodatkovne datoteke, ki zajemajo pogled na segmente v tistem trenutku, kar imenujemo plitvi posnetki. Prednost plitvih posnetkov se razširi na vse operacije, namreč ustvarjanje, brisanje in kloniranje posnetkov. Še vedno imate možnost posnetka neodvisne kopije s ročne posnetke za druge upravne posle.
Povzetek
OpenSearch je odprtokodna programska oprema, ki jo vodi skupnost. Večina temeljnih sprememb, vključno z modelom podvajanja, oddaljenim shranjevanjem in oddaljenimi metapodatki gruče, je bila prispevana k odprtokodnosti; pravzaprav sledimo odprtokodnemu prvemu razvojnemu modelu.
Prizadevanja za izboljšanje prepustnosti in zanesljivosti so neskončen cikel, saj se še naprej učimo in izboljšujemo. Novi primerki, optimizirani za OpenSearch, služijo kot temeljni gradnik, ki utira pot prihodnjim inovacijam. Navdušeni smo, da nadaljujemo s svojimi prizadevanji za izboljšanje zanesljivosti in zmogljivosti ter da vidimo, katere nove in obstoječe rešitve lahko ustvarijo razvijalci z uporabo OpenSearch Service. Upamo, da bo to pripeljalo do globljega razumevanja nove družine primerkov OpenSearch, kako ta ponudba dosega visoko vzdržljivost in boljšo prepustnost ter kako vam lahko pomaga konfigurirati gruče glede na potrebe vašega podjetja.
Če ste navdušeni nad prispevanjem k OpenSearch, odprite a Težava z GitHub in nam sporočite svoje misli. Radi bi slišali tudi o vaših zgodbah o uspehu pri doseganju visoke zmogljivosti in vzdržljivosti v storitvi OpenSearch. Če imate druga vprašanja, pustite komentar.
O avtorjih
 Bukhtawar Khan je glavni inženir, ki dela na Amazon OpenSearch Service. Zanima ga gradnja porazdeljenih in avtonomnih sistemov. Je vzdrževalec in aktiven sodelavec OpenSearch.
Bukhtawar Khan je glavni inženir, ki dela na Amazon OpenSearch Service. Zanima ga gradnja porazdeljenih in avtonomnih sistemov. Je vzdrževalec in aktiven sodelavec OpenSearch.
 Gaurav Bafna je višji programski inženir, ki dela na OpenSearch pri Amazon Web Services. Navdušuje ga reševanje problemov v porazdeljenih sistemih. Je vzdrževalec in aktiven sodelavec OpenSearch.
Gaurav Bafna je višji programski inženir, ki dela na OpenSearch pri Amazon Web Services. Navdušuje ga reševanje problemov v porazdeljenih sistemih. Je vzdrževalec in aktiven sodelavec OpenSearch.
 Sachin ohrovt je višji inženir za razvoj programske opreme pri AWS, ki dela na OpenSearch.
Sachin ohrovt je višji inženir za razvoj programske opreme pri AWS, ki dela na OpenSearch.
 Rohin Bhargava je višji produktni vodja pri ekipi Amazon OpenSearch Service. Njegova strast pri AWS je pomagati strankam najti pravo mešanico storitev AWS za doseganje uspeha pri njihovih poslovnih ciljih.
Rohin Bhargava je višji produktni vodja pri ekipi Amazon OpenSearch Service. Njegova strast pri AWS je pomagati strankam najti pravo mešanico storitev AWS za doseganje uspeha pri njihovih poslovnih ciljih.
 Ranjith Ramachandra je višji inženirski vodja, ki dela na Amazon OpenSearch Service. Navdušen je nad visoko razširljivimi porazdeljenimi sistemi, visoko zmogljivimi in prožnimi sistemi.
Ranjith Ramachandra je višji inženirski vodja, ki dela na Amazon OpenSearch Service. Navdušen je nad visoko razširljivimi porazdeljenimi sistemi, visoko zmogljivimi in prožnimi sistemi.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/

