Predstavitev
V središču znanost o podatkih laže statistika, ki obstaja že stoletja, vendar je v današnji digitalni dobi bistveno bistvena. Zakaj? Ker so osnovni statistični koncepti hrbtenica Analiza podatkov, kar nam omogoča, da razumemo ogromno dnevno ustvarjenih podatkov. To je kot pogovor s podatki, kjer nam statistika pomaga postavljati prava vprašanja in razumeti zgodbe, ki jih poskušajo povedati podatki.
Od napovedovanja prihodnjih trendov in sprejemanja odločitev na podlagi podatkov do testiranja hipotez in merjenja uspešnosti je statistika orodje, ki daje moč vpogledom v odločitve, ki temeljijo na podatkih. Je most med neobdelanimi podatki in uporabnimi vpogledi, zaradi česar je nepogrešljiv del podatkovne znanosti.
V tem članku sem zbral 15 najboljših temeljnih statističnih konceptov, ki bi jih moral poznati vsak začetnik podatkovne znanosti!

Kazalo
1. Statistično vzorčenje in zbiranje podatkov
Naučili se bomo nekaj osnovnih statističnih konceptov, vendar je nujno razumevanje, od kod prihajajo naši podatki in kako jih zbiramo, preden se potopimo globoko v ocean podatkov. Tu pridejo v poštev populacije, vzorci in različne tehnike vzorčenja.
Predstavljajte si, da želimo vedeti povprečno višino ljudi v mestu. Praktično je izmeriti vse, zato vzamemo manjšo skupino (vzorec), ki predstavlja večjo populacijo. Trik je v tem, kako izberemo ta vzorec. Tehnike, kot je naključno, stratificirano ali skupinsko vzorčenje, zagotavljajo dobro zastopanost našega vzorca, kar zmanjšuje pristranskost in naredi naše ugotovitve zanesljivejše.
Z razumevanjem populacij in vzorcev lahko samozavestno razširimo svoje vpoglede iz vzorca na celotno populacijo in sprejemamo odločitve na podlagi informacij, ne da bi morali anketirati vse.
2. Vrste podatkov in merilne lestvice
Podatki so različnih okusov in poznavanje vrste podatkov, s katerimi imate opravka, je ključnega pomena za izbiro pravih statističnih orodij in tehnik.
Kvantitativni in kvalitativni podatki
- Kvantitativni podatki: Pri tej vrsti podatkov gre le za številke. Je merljiv in se lahko uporablja za matematične izračune. Kvantitativni podatki nam povedo, »koliko« ali »koliko«, na primer število uporabnikov, ki obiščejo spletno mesto, ali temperatura v mestu. Je preprost in objektiven ter zagotavlja jasno sliko s pomočjo številskih vrednosti.
- Kvalitativni podatki: Nasprotno pa kvalitativni podatki obravnavajo značilnosti in opise. Gre za "katero vrsto" ali "katero kategorijo". Razmišljajte o tem kot o podatkih, ki opisujejo lastnosti ali lastnosti, kot je barva avtomobila ali žanr knjige. Ti podatki so subjektivni, temeljijo na opazovanjih in ne na meritvah.
Štiri merilne lestvice
- Nazivna lestvica: To je najpreprostejša oblika merjenja, ki se uporablja za kategorizacijo podatkov brez posebnega vrstnega reda. Primeri vključujejo vrste kuhinje, krvne skupine ali narodnost. Gre za označevanje brez kvantitativne vrednosti.
- Ordinalna lestvica: Podatke lahko tukaj razvrstite ali razvrstite, vendar intervali med vrednostmi niso definirani. Pomislite na anketo o zadovoljstvu z možnostmi, kot so zadovoljni, nevtralni in nezadovoljni. Pove nam vrstni red, ne pa tudi razdalje med uvrstitvami.
- Intervalna lestvica: Intervalne lestvice razvrstijo podatke in kvantificirajo razliko med vnosi. Vendar dejanske ničelne točke ni. Dober primer je temperatura v Celziju; razlika med 10°C in 20°C je enaka kot med 20°C in 30°C, vendar 0°C ne pomeni odsotnosti temperature.
- Lestvica razmerja: Najbolj informativna lestvica ima vse lastnosti intervalne lestvice plus smiselno ničelno točko, kar omogoča natančno primerjavo magnitud. Primeri vključujejo težo, višino in dohodek. Tukaj lahko rečemo, da je nekaj dvakrat več kot drugo.
3. Opisna statistika
Predstavljajte opisna statistika kot vaš prvi zmenek s svojimi podatki. Gre za spoznavanje osnov, širokih potez, ki opisujejo tisto, kar je pred vami. Opisna statistika ima dve glavni vrsti: osrednjo težnjo in merila variabilnosti.
Mere centralne tendence: Ti so kot težišče podatkov. Dajo nam eno samo vrednost, tipično ali reprezentativno za naš nabor podatkov.
Pomeni: Povprečje se izračuna tako, da seštejejo vse vrednosti in delijo s številom vrednosti. To je kot splošna ocena restavracije na podlagi vseh ocen. Matematična formula za povprečje je podana spodaj:

Mediana: Srednja vrednost, ko so podatki razvrščeni od najmanjšega do največjega. Če je število opazovanj sodo, je to povprečje dveh srednjih števil. Uporablja se za iskanje središča mostu.
Če je n sodo, je mediana povprečje dveh osrednjih števil.
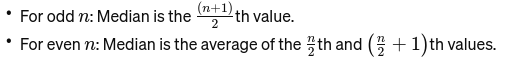
Način: To je najpogostejša vrednost v nizu podatkov. Predstavljajte si to kot najbolj priljubljeno jed v restavraciji.
Mere variabilnosti: Medtem ko nas mere osrednje tendence pripeljejo v središče, nam mere variabilnosti povedo o širjenju ali disperziji.
Območje: Razlika med najvišjo in najnižjo vrednostjo. Daje osnovno predstavo o namazu.
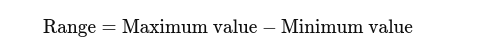
Varianca: Meri, kako daleč je vsako število v nizu od povprečja in s tem od vseh drugih števil v nizu. Za vzorec se izračuna kot:
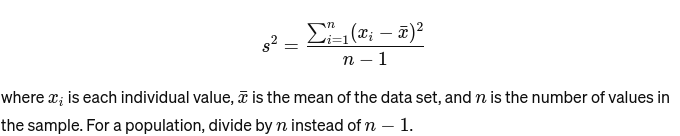
Standardni odklon: Kvadratni koren variance je merilo povprečne oddaljenosti od povprečja. To je kot ocenjevanje skladnosti velikosti pekovske torte. Predstavljen je kot:
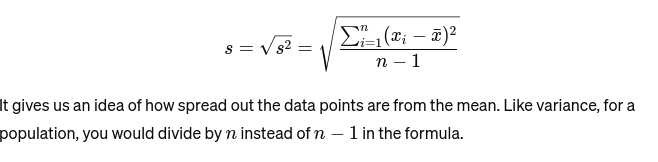
Preden preidemo na naslednji osnovni koncept statistike, je tukaj a Priročnik za statistično analizo za začetnike za vas!
4. Vizualizacija podatkov
Vizualizacija podatkov je umetnost in znanost pripovedovanja zgodb s podatki. Zapletene rezultate naše analize spremeni v nekaj oprijemljivega in razumljivega. To je ključnega pomena za raziskovalno analizo podatkov, kjer je cilj odkriti vzorce, korelacije in vpoglede iz podatkov, ne da bi še naredili uradne zaključke.
- Grafi in grafikoni: Začenši z osnovami, palični grafikoni, linijski grafi in tortni grafikoni zagotavljajo temeljne vpoglede v podatke. So ABC vizualizacije podatkov, bistvenega pomena za vsakega pripovedovalca podatkov.
Spodaj imamo primer paličnega grafikona (levo) in črtnega grafikona (desno).
- Napredne vizualizacije: Ko se potapljamo globlje, toplotni zemljevidi, diagrami razpršitve in histogrami omogočajo bolj niansirano analizo. Ta orodja pomagajo prepoznati trende, porazdelitve in odstopanja.
Spodaj je primer razpršenega grafa in histograma

Vizualizacije povezujejo neobdelane podatke in človeško spoznanje, kar nam omogoča hitro interpretacijo in razumevanje zapletenih podatkovnih nizov.
5. Osnove verjetnosti
Verjetnost je slovnica jezika statistike. Gre za možnost ali verjetnost, da se dogodki zgodijo. Razumevanje konceptov v verjetnosti je bistvenega pomena za razlago statističnih rezultatov in napovedovanje.
- Neodvisni in odvisni dogodki:
- Neodvisni dogodki: Izid enega dogodka ne vpliva na izid drugega. Podobno kot pri vrženju kovanca, pridobivanje glav ob enem metu ne spremeni kvote za naslednji met.
- Odvisni dogodki: Rezultat enega dogodka vpliva na rezultat drugega. Na primer, če povlečete karto iz kompleta in je ne zamenjate, se spremenijo vaše možnosti, da povlečete drugo določeno karto.
Verjetnost zagotavlja osnovo za sklepanje o podatkih in je ključnega pomena za razumevanje statistične pomembnosti in preizkušanja hipotez.
6. Skupne verjetnostne porazdelitve
Verjetnostne porazdelitve so kot različne vrste v statističnem ekosistemu, vsaka prilagojena svoji niši aplikacij.
- Običajna porazdelitev: Za to porazdelitev, ki jo zaradi svoje oblike pogosto imenujemo zvonasta krivulja, sta značilna povprečje in standardni odklon. To je običajna predpostavka v številnih statističnih testih, ker so številne spremenljivke v resničnem svetu naravno porazdeljene na ta način.
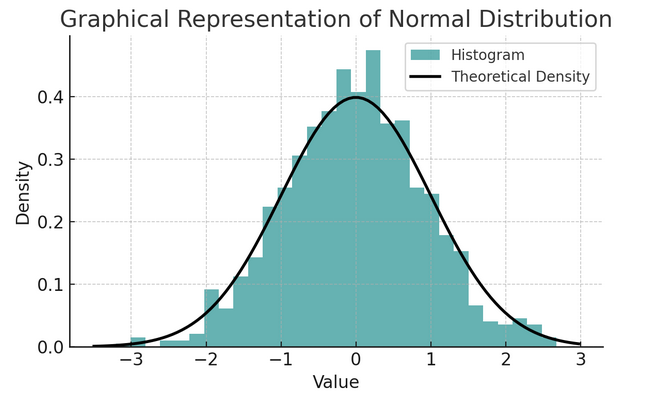
Niz pravil, znanih kot empirično pravilo ali pravilo 68-95-99.7, povzema značilnosti normalne porazdelitve, ki opisuje, kako se podatki porazdelijo okoli povprečja.
68-95-99.7 pravilo (empirično pravilo)
To pravilo velja za popolnoma normalno porazdelitev in opisuje naslednje:
- 68% podatkov spada znotraj enega standardnega odklona (σ) od povprečja (μ).
- 95% podatkov sodi znotraj dveh standardnih odklonov povprečja.
- približno 99.7% podatkov sodi znotraj treh standardnih odklonov povprečja.
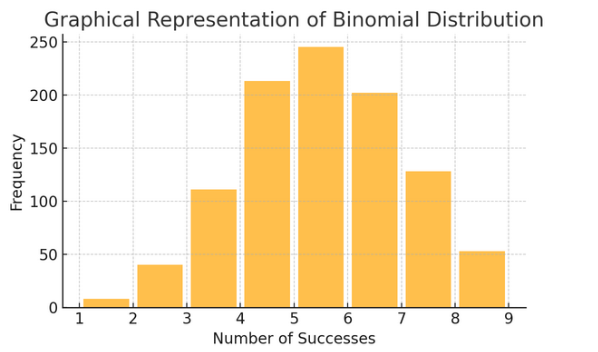
Binomska porazdelitev: Ta porazdelitev velja za situacije z dvema izidoma (na primer uspeh ali neuspeh), ki se večkrat ponovita. Pomaga modelirati dogodke, kot je metanje kovanca ali opravljanje testa drži/ne drži.
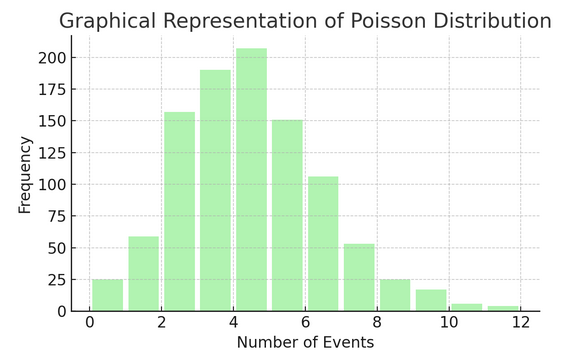
Poissonova porazdelitev šteje, kolikokrat se nekaj zgodi v določenem intervalu ali prostoru. Idealen je za situacije, ko se dogodki dogajajo neodvisno in nenehno, na primer dnevna e-poštna sporočila, ki jih prejemate.
Vsaka distribucija ima svoj niz formul in značilnosti, izbira prave pa je odvisna od narave vaših podatkov in tega, kar poskušate ugotoviti. Razumevanje teh porazdelitev omogoča statistikom in podatkovnim znanstvenikom modeliranje pojavov v resničnem svetu in natančno napovedovanje prihodnjih dogodkov.
7. Preizkušanje hipotez
Pomisli testiranje hipotez kot detektivsko delo v statistiki. To je metoda za preizkušanje, ali je lahko določena teorija o naših podatkih resnična. Ta proces se začne z dvema nasprotujočima si hipotezama:
- Ničelna hipoteza (H0): To je privzeta predpostavka, ki nakazuje, da obstaja učinek ali razlika. Piše: "Tu ni nič novega."
- Al "alternativna hipoteza (H1 ali Ha): To izziva status quo in predlaga učinek ali razliko. Trdi: "Nekaj se zanimivo dogaja."
Primer: Preizkušanje, ali nov dietni program vodi do izgube teže v primerjavi z neupoštevanjem nobene diete.
- Ničelna hipoteza (H0): Nov dietni program ne vodi do hujšanja (ni razlike v hujšanju med tistimi, ki se držijo novega dietnega programa, in tistimi, ki se ne).
- Alternativna hipoteza (H1): Nov dietni program vodi v hujšanje (razlika v hujšanju med tistimi, ki se ga držijo in tistimi, ki se ga ne držijo).
Preizkušanje hipotez vključuje izbiro med tema dvema na podlagi dokazov (naši podatki).
Stopnje napak in pomembnosti tipa I in II:
- Napaka tipa I: To se zgodi, ko nepravilno zavrnemo ničelno hipotezo. Obsodi nedolžnega človeka.
- Napaka tipa II: To se zgodi, ko ne zavrnemo napačne ničelne hipoteze. Pusti krivca na prostost.
- Raven pomembnosti (α): To je prag za odločitev, koliko dokazov je dovolj za zavrnitev ničelne hipoteze. Pogosto je nastavljen na 5 % (0.05), kar kaže na 5 % tveganje za napako tipa I.
8. Intervali zaupanja
Intervali zaupanja podajajo razpon vrednosti, znotraj katerega pričakujemo, da bo veljaven populacijski parameter (na primer povprečje ali delež) padel z določeno stopnjo zaupanja (običajno 95 %). To je kot napovedovanje končnega rezultata športne ekipe z mejo napake; pravimo: "95 % smo prepričani, da bo pravi rezultat znotraj tega razpona."
Konstruiranje in interpretacija intervalov zaupanja nam pomaga razumeti natančnost naših ocen. Širši kot je interval, manj natančna je naša ocena in obratno.
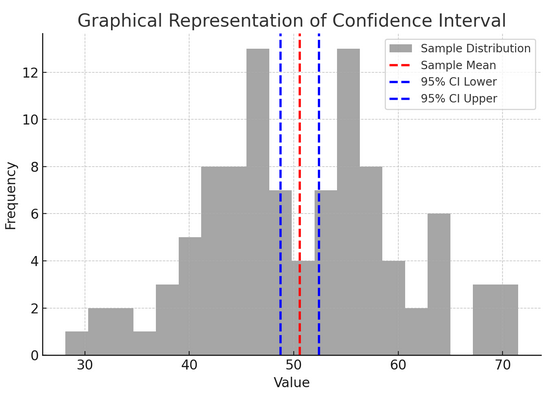
Zgornja slika ponazarja koncept intervala zaupanja (CI) v statistiki z uporabo vzorčne porazdelitve in njenega 95-odstotnega intervala zaupanja okoli vzorčne sredine.
Tukaj je razčlenitev kritičnih komponent na sliki:
- Porazdelitev vzorca (siv histogram): To predstavlja porazdelitev 100 podatkovnih točk, naključno ustvarjenih iz normalne porazdelitve s povprečjem 50 in standardnim odklonom 10. Histogram vizualno prikazuje, kako so podatkovne točke porazdeljene okoli povprečja.
- Povprečna vrednost vzorca (rdeča črtkana črta): Ta vrstica označuje srednjo (povprečno) vrednost vzorčnih podatkov. Služi kot točkovna ocena, okoli katere sestavimo interval zaupanja. V tem primeru predstavlja povprečje vseh vzorčnih vrednosti.
- 95-odstotni interval zaupanja (modre črtkane črte): Ti dve črti označujeta spodnjo in zgornjo mejo 95-odstotnega intervala zaupanja okoli povprečja vzorca. Interval se izračuna z uporabo standardne napake povprečja (SEM) in ocene Z, ki ustreza želeni stopnji zaupanja (1.96 za 95-odstotno zaupanje). Interval zaupanja kaže, da smo 95-odstotno prepričani, da je povprečje populacije znotraj tega razpona.
9. Korelacija in vzročna zveza
Korelacija in vzročna zveza se pogosto mešajo, vendar so različni:
- Korelacija: Označuje odnos ali povezavo med dvema spremenljivkama. Ko se ena spremeni, se tudi druga nagiba k spremembi. Korelacija se meri s korelacijskim koeficientom v razponu od -1 do 1. Vrednost, ki je bližja 1 ali -1, pomeni močno povezavo, medtem ko 0 pomeni, da ni vezi.
- Vzročnost: Pomeni, da spremembe ene spremenljivke neposredno povzročijo spremembe druge. Je bolj robustna trditev kot korelacija in zahteva strogo testiranje.
Samo zato, ker sta dve spremenljivki povezani, še ne pomeni, da ena povzroča drugo. To je klasičen primer, ko "korelacije" ne zamenjujemo z "vzročno zvezo".
10. Preprosta linearna regresija
Enostavno linearne regresije je način za modeliranje razmerja med dvema spremenljivkama s prilagajanjem linearne enačbe opazovanim podatkom. Ena spremenljivka se obravnava kot pojasnjevalna spremenljivka (neodvisna), druga pa je odvisna spremenljivka.
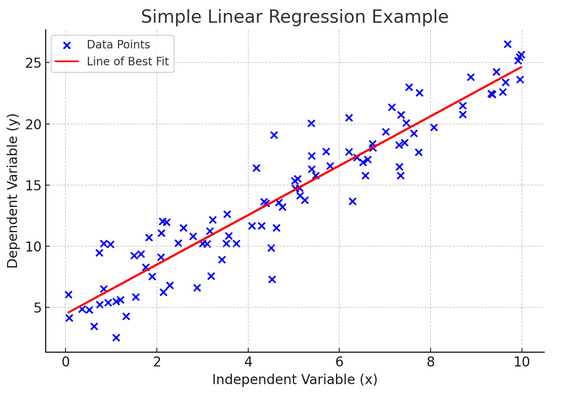
Preprosta linearna regresija nam pomaga razumeti, kako spremembe neodvisne spremenljivke vplivajo na odvisno spremenljivko. Je zmogljivo orodje za napovedovanje in je osnova za mnoge druge kompleksne statistične modele. Z analizo razmerja med dvema spremenljivkama lahko naredimo informirane napovedi o tem, kako bosta medsebojno delovala.
Preprosta linearna regresija predpostavlja linearno razmerje med neodvisno spremenljivko (razlagalno spremenljivko) in odvisno spremenljivko. Če razmerje med tema dvema spremenljivkama ni linearno, se lahko kršijo predpostavke preproste linearne regresije, kar lahko povzroči netočne napovedi ali interpretacije. Zato je pred uporabo preproste linearne regresije bistveno preveriti linearno razmerje v podatkih.
11. Večkratna linearna regresija
Večkratno linearno regresijo si predstavljajte kot razširitev preproste linearne regresije. Kljub temu, namesto da bi poskušali napovedati izid z enim vitezom v sijočem oklepu (napovedovalec), imate celotno ekipo. To je kot nadgradnja košarkarske igre ena na ena v celotno skupinsko delo, kjer vsak igralec (napovedovalec) prinaša edinstvene sposobnosti. Ideja je videti, kako več spremenljivk skupaj vpliva na en rezultat.
Vendar pa z večjo ekipo prihaja izziv upravljanja odnosov, znan kot multikolinearnost. Pojavi se, ko so napovedovalci preblizu drug drugemu in si delijo podobne informacije. Predstavljajte si dva košarkarja, ki nenehno poskušata izvesti isti udarec; drug drugemu so lahko v napoto. Zaradi regresije je težko videti edinstven prispevek vsakega napovedovalca, kar bi lahko izkrivilo naše razumevanje, katere spremenljivke so pomembne.
12. Logistična regresija
Medtem ko linearna regresija napoveduje stalne rezultate (kot so temperatura ali cene), logistična regresija se uporablja, ko je rezultat dokončen (na primer da/ne, zmaga/poraz). Predstavljajte si, da poskušate napovedati, ali bo ekipa zmagala ali izgubila na podlagi različnih dejavnikov; logistična regresija je vaša strategija.
Preoblikuje linearno enačbo tako, da njen rezultat pade med 0 in 1, kar predstavlja verjetnost pripadnosti določeni kategoriji. Kot bi imeli čarobno lečo, ki pretvarja neprekinjene rezultate v jasen pogled »to ali ono«, kar nam omogoča napovedovanje kategoričnih rezultatov.
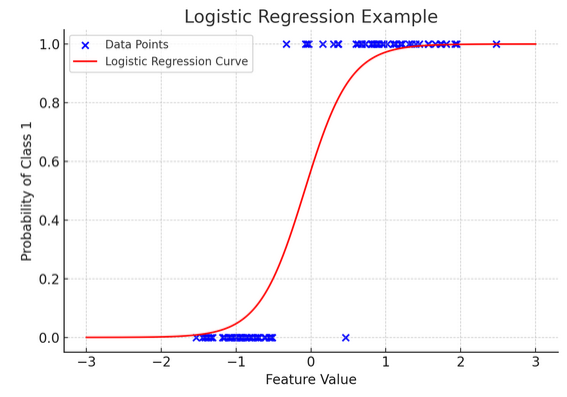
Grafični prikaz ponazarja primer logistične regresije, uporabljene za nabor sintetičnih binarnih klasifikacijskih podatkov. Modre pike predstavljajo podatkovne točke, njihov položaj vzdolž osi x označuje vrednost funkcije, os y pa kategorijo (0 ali 1). Rdeča krivulja predstavlja napoved modela logistične regresije glede verjetnosti pripadnosti razredu 1 (npr. »zmaga«) za različne vrednosti značilnosti. Kot lahko vidite, krivulja gladko prehaja iz verjetnosti razreda 0 v razred 1, kar dokazuje sposobnost modela za napovedovanje kategoričnih rezultatov na podlagi osnovne neprekinjene značilnosti.
Formula za logistično regresijo je podana z:

Ta formula uporablja logistično funkcijo za pretvorbo izhoda linearne enačbe v verjetnost med 0 in 1. Ta transformacija nam omogoča interpretacijo izhodov kot verjetnosti pripadnosti določeni kategoriji na podlagi vrednosti neodvisne spremenljivke xx.
13. ANOVA in test hi-kvadrat
ANOVA (analiza variance) in Hi-kvadrat testi so kot detektivi v svetu statistike, ki nam pomagajo razrešiti različne skrivnosti. jazt nam omogoča, da primerjamo povprečja v več skupinah, da ugotovimo, ali je vsaj ena statistično drugačna. Predstavljajte si to kot okušanje vzorcev iz več serij piškotov, da ugotovite, ali ima katera serija bistveno drugačen okus.
Po drugi strani pa se test hi-kvadrat uporablja za kategorične podatke. Pomaga nam razumeti, ali obstaja pomembna povezava med dvema kategoričnima spremenljivkama. Na primer, ali obstaja povezava med najljubšo zvrstjo glasbe osebe in njeno starostno skupino? Hi-kvadrat test pomaga odgovoriti na taka vprašanja.
14. Centralni mejni izrek in njegov pomen v podatkovni znanosti
O Centralni mejni izrek (CLT) je temeljno statistično načelo, ki se zdi skoraj čarobno. Pove nam, da če vzamete dovolj vzorcev iz populacije in izračunate njihove srednje vrednosti, bodo te srednje vrednosti oblikovale normalno porazdelitev (zvonasto krivuljo), ne glede na prvotno porazdelitev populacije. To je neverjetno močno, saj nam omogoča sklepanje o populacijah, tudi če ne poznamo njihove natančne porazdelitve.
V podatkovni znanosti CLT podpira številne tehnike, ki nam omogočajo uporabo orodij, zasnovanih za normalno porazdeljene podatke, tudi če naši podatki sprva ne izpolnjujejo teh meril. To je kot bi našli univerzalni adapter za statistične metode, s čimer bi številna zmogljiva orodja postala uporabna v več situacijah.
15. Kompromis pristranskosti in variance
In napovedno modeliranje in strojno učenjeje kompromis pristranskosti je ključen koncept, ki poudarja napetost med dvema glavnima vrstama napak, zaradi katerih se lahko naši modeli pokvarijo. Pristranskost se nanaša na napake iz preveč poenostavljenih modelov, ki ne zajamejo dobro osnovnih trendov. Predstavljajte si, da poskušate postaviti ravno črto skozi zakrivljeno cesto; zgrešil boš cilj. Nasprotno pa odstopanja iz preveč zapletenih modelov zajamejo šum v podatkih, kot da bi šlo za dejanski vzorec – kot bi sledili vsakemu zasuku in zavili na neravni poti, misleč, da je to pot naprej.
Umetnost je v uravnoteženju teh dveh, da se zmanjša skupna napaka, pri iskanju najboljše točke, kjer je vaš model ravno pravšnji – dovolj zapleten, da zajame natančne vzorce, a dovolj preprost, da prezre naključni šum. To je kot uglaševanje kitare; ne bo zvenelo pravilno, če bo pretesno ali ohlapno. Kompromis pristranskosti in variance gre za iskanje popolnega ravnovesja med tema dvema. Kompromis pristranskosti in variance je bistvo prilagajanja naših statističnih modelov, da bodo kar najbolje delovali pri natančnem napovedovanju rezultatov.
zaključek
Od statističnega vzorčenja do kompromisa pristranskosti in variance, ta načela niso le akademski pojmi, ampak bistvena orodja za pronicljivo analizo podatkov. Prizadevne podatkovne znanstvenike opremijo z veščinami za spreminjanje ogromnih podatkov v uporabne vpoglede, pri čemer poudarjajo statistiko kot hrbtenico odločanja, ki temelji na podatkih, in inovacije v digitalni dobi.
Ali smo zamudili kakšen osnovni koncept statistike? Sporočite nam v spodnjem oddelku za komentarje.
raziskovati statistični vodnik od konca do konca da znanost o podatkih ve o temi!
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

