Большие языковые модели (LLM) обычно обучаются на больших общедоступных наборах данных, не зависящих от предметной области. Например, Лама Меты модели обучаются на таких наборах данных, как CommonCrawl, C4, Википедия и ArXiv. Эти наборы данных охватывают широкий спектр тем и областей. Хотя полученные модели дают удивительно хорошие результаты для общих задач, таких как генерация текста и распознавание объектов, есть свидетельства того, что модели, обученные с использованием наборов данных для конкретной предметной области, могут еще больше повысить производительность LLM. Например, данные обучения, используемые для BloombergGPT составляет 51% документов, специфичных для предметной области, включая финансовые новости, отчеты и другие финансовые материалы. Полученный LLM превосходит LLM, обученный на наборах данных, не связанных с предметной областью, при тестировании на задачах, специфичных для финансов. Авторы BloombergGPT пришли к выводу, что их модель превосходит все другие модели, протестированные для четырех из пяти финансовых задач. Модель показала еще более высокие результаты при тестировании на выполнение внутренних финансовых задач Bloomberg с большим отрывом — на целых 60 пунктов лучше (из 100). Хотя вы можете узнать больше о результатах комплексной оценки в бумаги, следующий образец, полученный из BloombergGPT Статья может дать вам представление о преимуществах обучения LLM с использованием данных, специфичных для финансовой сферы. Как показано в примере, модель BloombergGPT дала правильные ответы, в то время как другие модели, не зависящие от предметной области, испытывали затруднения:
В этом посте представлено руководство по обучению LLM специально для финансовой сферы. Мы охватываем следующие ключевые направления:
- Сбор и подготовка данных – Руководство по поиску и обработке соответствующих финансовых данных для эффективного обучения моделей.
- Постоянное предварительное обучение или тонкая настройка – Когда использовать каждый метод для оптимизации производительности вашего LLM
- Эффективное постоянное предварительное обучение – Стратегии по оптимизации непрерывного процесса предварительной подготовки, экономия времени и ресурсов.
В этом посте объединен опыт группы прикладных научных исследований Amazon Finance Technology и всемирной группы специалистов AWS по глобальной финансовой индустрии. Часть контента основана на статье Эффективное непрерывное предварительное обучение для построения моделей большого языка для конкретной предметной области.
Сбор и подготовка финансовых данных
Непрерывное предварительное обучение предметной области требует крупномасштабного высококачественного набора данных, специфичного для предметной области. Ниже приведены основные шаги по курированию набора данных предметной области:
- Определите источники данных – Потенциальные источники данных для корпуса доменов включают открытый Интернет, Википедию, книги, социальные сети и внутренние документы.
- Фильтры данных домена – Поскольку конечной целью является курирование корпуса предметной области, вам может потребоваться применить дополнительные шаги для фильтрации образцов, не имеющих отношения к целевому домену. Это уменьшает бесполезный корпус для постоянного предварительного обучения и снижает стоимость обучения.
- предварительная обработка – Вы можете рассмотреть ряд шагов предварительной обработки для улучшения качества данных и эффективности обучения. Например, некоторые источники данных могут содержать значительное количество зашумленных токенов; Дедупликация считается полезным шагом для улучшения качества данных и снижения затрат на обучение.
Для разработки финансовых программ LLM вы можете использовать два важных источника данных: News CommonCrawl и документы SEC. Документ SEC — это финансовый отчет или другой официальный документ, подаваемый в Комиссию по ценным бумагам и биржам США (SEC). Публичные компании обязаны регулярно подавать различные документы. Это создает большое количество документов на протяжении многих лет. News CommonCrawl — это набор данных, выпущенный CommonCrawl в 2016 году. Он содержит новостные статьи с новостных сайтов со всего мира.
Новости CommonCrawl доступен на Простой сервис хранения Amazon (Amazon S3) в commoncrawl ведро в crawl-data/CC-NEWS/. Вы можете получить списки файлов, используя Интерфейс командной строки AWS (AWS CLI) и следующую команду:
In Эффективное непрерывное предварительное обучение для построения моделей большого языка для конкретной предметной области, авторы используют подход на основе URL-адресов и ключевых слов для фильтрации статей финансовых новостей от общих новостей. В частности, авторы ведут список важных финансовых новостных агентств и набор ключевых слов, связанных с финансовыми новостями. Мы определяем статью как финансовые новости, если она взята из финансовых новостных агентств или в URL-адресе присутствуют какие-либо ключевые слова. Этот простой, но эффективный подход позволяет вам идентифицировать финансовые новости не только из финансовых новостных агентств, но и из финансовых разделов обычных новостных агентств.
Документы SEC доступны онлайн через базу данных EDGAR (электронный сбор, анализ и поиск данных) SEC, которая обеспечивает открытый доступ к данным. Вы можете очистить файлы напрямую из EDGAR или использовать API в Создатель мудреца Амазонки с помощью нескольких строк кода, на любой период времени и для большого количества тикеров (т. е. идентификатора, присвоенного SEC). Чтобы узнать больше, обратитесь к Получение документов SEC.
В следующей таблице приведены основные сведения об обоих источниках данных.
| . | Новости CommonCrawl | Подача документов в SEC |
| Покрытие | 2016-2022 | 1993-2022 |
| Размер | 25.8 миллиардов слов | 5.1 миллиардов слов |
Авторы проходят несколько дополнительных этапов предварительной обработки, прежде чем данные будут переданы в алгоритм обучения. Во-первых, мы отмечаем, что документы SEC содержат зашумленный текст из-за удаления таблиц и рисунков, поэтому авторы удаляют короткие предложения, которые считаются подписями к таблицам или рисункам. Во-вторых, мы применяем алгоритм хеширования, чувствительный к местонахождению, для дедупликации новых статей и документов. Для документов SEC мы дедуплицируем на уровне раздела, а не на уровне документа. Наконец, мы объединяем документы в длинную строку, маркируем ее и разбиваем токенизацию на части максимальной входной длины, поддерживаемой обучаемой моделью. Это повышает эффективность непрерывного предварительного обучения и снижает стоимость обучения.
Постоянное предварительное обучение или тонкая настройка
Большинство доступных программ LLM предназначены для общего назначения и не имеют возможностей для конкретной предметной области. LLM в области домена показали значительную эффективность в медицинской, финансовой или научной областях. Для получения LLM знаний по конкретной предметной области существует четыре метода: обучение с нуля, постоянное предварительное обучение, точная настройка инструкций по задачам предметной области и поисковая дополненная генерация (RAG).
В традиционных моделях точная настройка обычно используется для создания моделей конкретной задачи для предметной области. Это означает поддержку нескольких моделей для нескольких задач, таких как извлечение сущностей, классификация намерений, анализ настроений или ответы на вопросы. С появлением LLM необходимость поддерживать отдельные модели стала устаревшей благодаря использованию таких методов, как контекстное обучение или подсказки. Это экономит усилия, необходимые для поддержки набора моделей для связанных, но различных задач.
Интуитивно понятно, что вы можете обучать LLM с нуля, используя данные для конкретной предметной области. Хотя большая часть работы по созданию предметных LLM сосредоточена на обучении с нуля, это непомерно дорого. Например, модель GPT-4 стоит более $ 100 миллионов тренировать. Эти модели обучаются на сочетании данных открытого домена и данных предметной области. Непрерывное предварительное обучение может помочь моделям приобрести знания, специфичные для предметной области, без затрат на предварительное обучение с нуля, поскольку вы предварительно обучаете существующий LLM с открытым доменом только на данных предметной области.
При точной настройке инструкций для задачи вы не можете заставить модель приобретать знания предметной области, поскольку LLM получает только информацию предметной области, содержащуюся в наборе данных тонкой настройки инструкций. Если не используется очень большой набор данных для точной настройки инструкций, этого недостаточно для приобретения знаний в предметной области. Поиск высококачественных наборов данных инструкций обычно является сложной задачей и является причиной использования LLM в первую очередь. Кроме того, точная настройка инструкций для одной задачи может повлиять на производительность других задач (как показано на рис. эта бумага). Однако точная настройка инструкций более рентабельна, чем любой из вариантов предварительного обучения.
На следующем рисунке сравнивается традиционная точная настройка для конкретной задачи. по сравнению с парадигмой контекстного обучения с LLM.
 RAG — это наиболее эффективный способ помочь LLM генерировать ответы, основанные на предметной области. Хотя он может помочь модели генерировать ответы, предоставляя факты из предметной области в качестве вспомогательной информации, он не приобретает язык, специфичный для предметной области, поскольку LLM по-прежнему полагается на стиль языка, не относящийся к предметной области, для генерации ответов.
RAG — это наиболее эффективный способ помочь LLM генерировать ответы, основанные на предметной области. Хотя он может помочь модели генерировать ответы, предоставляя факты из предметной области в качестве вспомогательной информации, он не приобретает язык, специфичный для предметной области, поскольку LLM по-прежнему полагается на стиль языка, не относящийся к предметной области, для генерации ответов.
Постоянное предварительное обучение представляет собой золотую середину между предварительным обучением и тонкой настройкой инструкций с точки зрения затрат, а также является сильной альтернативой приобретению специфичных для предметной области знаний и стиля. Он может предоставить общую модель, на основе которой может быть выполнена дальнейшая точная настройка инструкций на ограниченных данных команд. Непрерывное предварительное обучение может быть экономически эффективной стратегией для специализированных областей, где набор последующих задач велик или неизвестен, а данные настройки помеченных инструкций ограничены. В других сценариях более подходящей может оказаться точная настройка инструкций или RAG.
Дополнительные сведения о точной настройке, RAG и обучении модели см. Точная настройка модели фундамента, Поисковая дополненная генерация (RAG)качества Обучите модель с помощью Amazon SageMaker, соответственно. В этом посте мы сосредоточимся на эффективной постоянной предварительной тренировке.
Методика эффективной постоянной предварительной подготовки
Непрерывная предварительная подготовка состоит из следующей методики:
- Адаптивное к предметной области непрерывное предварительное обучение (DACP) – В газете Эффективное непрерывное предварительное обучение для построения моделей большого языка для конкретной предметной области, авторы постоянно предварительно обучают набор языковых моделей Pythia на финансовом корпусе, чтобы адаптировать его к финансовой сфере. Цель состоит в том, чтобы создать финансовые LLM путем подачи данных из всей финансовой сферы в модель с открытым исходным кодом. Поскольку обучающий корпус содержит все тщательно подобранные наборы данных в предметной области, полученная модель должна приобретать знания, специфичные для финансов, и тем самым становиться универсальной моделью для различных финансовых задач. В результате получаются модели FinPythia.
- Постоянное предварительное обучение с адаптацией к задачам (TACP) – Авторы предварительно обучают модели на помеченных и немаркированных данных задач, чтобы адаптировать их для конкретных задач. В определенных обстоятельствах разработчики могут предпочесть модели, обеспечивающие более высокую производительность при выполнении группы задач внутри предметной области, а не универсальную модель предметной области. TACP разработан как непрерывное предварительное обучение, направленное на повышение производительности при выполнении целевых задач без требований к маркированным данным. В частности, авторы постоянно предварительно обучают модели с открытым исходным кодом на токенах задач (без меток). Основное ограничение TACP заключается в создании LLM для конкретных задач вместо базовых LLM из-за использования исключительно немаркированных данных задачи для обучения. Хотя DACP использует гораздо больший корпус, он непомерно дорог. Чтобы сбалансировать эти ограничения, авторы предлагают два подхода, которые направлены на создание базовых LLM для конкретной предметной области, сохраняя при этом превосходную производительность при выполнении целевых задач:
- Эффективный DACP, аналогичный задачам (ETS-DACP) – Авторы предлагают выбрать подмножество финансового корпуса, которое очень похоже на данные задачи, используя встраивание сходства. Это подмножество используется для непрерывной предварительной подготовки, чтобы сделать ее более эффективной. В частности, авторы постоянно предварительно обучают LLM с открытым исходным кодом на небольшом корпусе, извлеченном из финансового корпуса, который близок к целевым задачам в распространении. Это может помочь повысить производительность задач, поскольку мы применяем эту модель для распределения токенов задач, несмотря на то, что помеченные данные не требуются.
- Эффективный DACP, независимый от задач (ETA-DACP) – Авторы предлагают использовать такие метрики, как недоумение и энтропия типа токена, которые не требуют данных задачи для выбора образцов из финансового корпуса для эффективного непрерывного предварительного обучения. Этот подход предназначен для сценариев, в которых данные задачи недоступны или где предпочтительны более универсальные модели предметной области для более широкой предметной области. Авторы используют два измерения для выбора образцов данных, которые важны для получения информации о предметной области из подмножества данных предметной области перед обучением: новизна и разнообразие. Новизна, измеряемая недоумением, зафиксированным целевой моделью, относится к информации, которая ранее не была доступна LLM. Данные с высокой новизной указывают на новые знания для LLM, и такие данные считаются более трудными для изучения. Это обновляет общие знания LLM с помощью интенсивных знаний предметной области во время постоянного предварительного обучения. Разнообразие, с другой стороны, отражает разнообразие распределения типов токенов в корпусе предметной области, что было задокументировано как полезная функция в исследованиях обучения по учебной программе по языковому моделированию.
На следующем рисунке сравнивается пример ETS-DACP (слева) и ETA-DACP (справа).

Мы применяем две схемы выборки для активного отбора точек данных из курируемого финансового массива: жесткая выборка и мягкая выборка. Первое делается путем сначала ранжирования финансового корпуса по соответствующим показателям, а затем выбора лучших выборок, где k заранее определяется в соответствии с бюджетом обучения. В последнем случае авторы назначают веса выборки для каждой точки данных в соответствии со значениями метрики, а затем случайным образом выбирают k точек данных, чтобы уложиться в бюджет обучения.
Результат и анализ
Авторы оценивают полученные финансовые LLM по ряду финансовых задач, чтобы исследовать эффективность постоянного предварительного обучения:
- Банк финансовых фраз – Задача классификации настроений по финансовым новостям.
- ФиКА СА – Задача классификации настроений на основе аспектов на основе финансовых новостей и заголовков.
- Headline – Задача двоичной классификации, определяющая, содержит ли заголовок о финансовой организации определенную информацию.
- ЧПО – Задача извлечения названной финансовой организации на основе раздела оценки кредитного риска в отчетах SEC. Слова в этом задании помечены буквами PER, LOC, ORG и MISC.
Поскольку финансовые LLM представляют собой точно настроенные инструкции, авторы оценивают модели в пятиэтапном режиме для каждой задачи в целях обеспечения надежности. В среднем FinPythia 5B превосходит Pythia 6.9B на 6.9 % в четырех задачах, что демонстрирует эффективность непрерывного предварительного обучения для конкретной предметной области. Для модели 10B улучшение менее существенное, но производительность все равно увеличивается в среднем на 1%.
На следующем рисунке показана разница в производительности до и после DACP на обеих моделях.

На следующем рисунке показаны два качественных примера, созданных Pythia 6.9B и FinPythia 6.9B. На два вопроса, связанных с финансами, касающихся менеджера инвестора и финансового условия, Pythia 6.9B не понимает термин или не распознает имя, тогда как FinPythia 6.9B правильно генерирует подробные ответы. Качественные примеры демонстрируют, что постоянное предварительное обучение позволяет магистрантам приобретать знания в предметной области в ходе процесса.

В следующей таблице сравниваются различные эффективные подходы к непрерывной предварительной тренировке. ETA-DACP-ppl — это ETA-DACP, основанный на недоумении (новизне), а ETA-DACP-ent основан на энтропии (разнообразии). ETS-DACP-com аналогичен DACP с выбором данных путем усреднения всех трех показателей. Ниже приведены некоторые выводы из результатов:
- Методы отбора данных эффективны – Они превосходят стандартную непрерывную предварительную подготовку, имея всего 10% тренировочных данных. Эффективное непрерывное предварительное обучение, включая Task-Similar DACP (ETS-DACP), Task-Agnostic DACP на основе энтропии (ESA-DACP-ent) и Task-Similar DACP на основе всех трех показателей (ETS-DACP-com), превосходит стандартный DACP в среднем, несмотря на то, что они обучают лишь 10% финансового корпуса.
- Выбор данных с учетом задач лучше всего работает при исследовании небольших языковых моделей. – ETS-DACP фиксирует лучшую среднюю производительность среди всех методов и на основе всех трех показателей фиксирует вторую лучшую производительность задачи. Это говорит о том, что использование немаркированных данных задачи по-прежнему является эффективным подходом к повышению производительности задач в случае LLM.
- Выбор данных, не зависящий от задачи, занимает второе место – ESA-DACP-ent следует за эффективностью подхода к выбору данных с учетом задач, подразумевая, что мы все еще можем повысить производительность задач, активно отбирая высококачественные образцы, не привязанные к конкретным задачам. Это открывает путь к созданию финансовых LLM для всей области, обеспечивая при этом превосходную производительность задач.
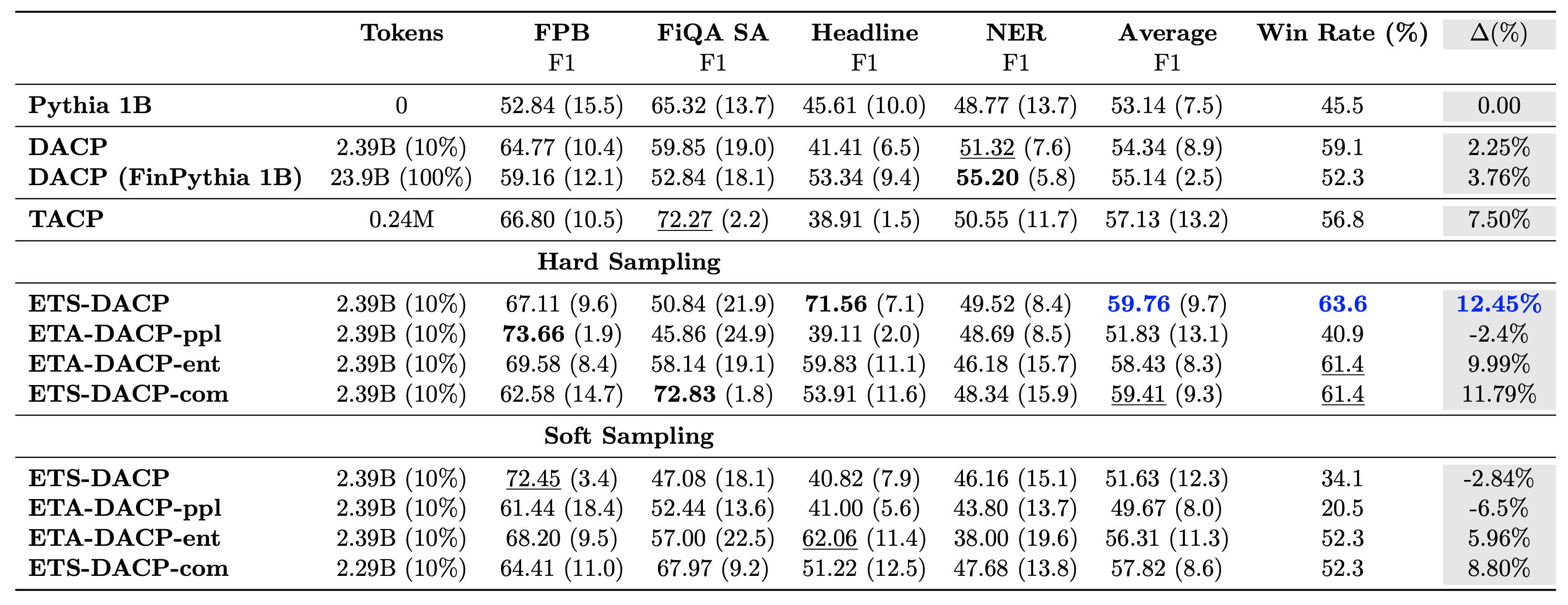
Один из важнейших вопросов, касающихся постоянного предварительного обучения, заключается в том, влияет ли оно негативно на производительность при выполнении задач, не относящихся к предметной области. Авторы также оценивают модель с постоянным предварительным обучением на четырех широко используемых общих задачах: ARC, MMLU, TruthQA и HellaSwag, которые измеряют способность отвечать на вопросы, рассуждать и завершать их. Авторы обнаружили, что постоянное предварительное обучение не оказывает негативного влияния на производительность вне предметной области. Для получения более подробной информации см. Эффективное непрерывное предварительное обучение для построения моделей большого языка для конкретной предметной области.
Заключение
В этом посте содержится информация о сборе данных и стратегиях непрерывного предварительного обучения для обучения LLM в финансовой сфере. Вы можете начать обучение своих собственных LLM для решения финансовых задач, используя Обучение работе с Amazon SageMaker or Коренная порода Амазонки прямо сейчас
Об авторах
 Юн Се — учёный-прикладник в Amazon FinTech. Он занимается разработкой больших языковых моделей и приложений генеративного искусственного интеллекта для финансов.
Юн Се — учёный-прикладник в Amazon FinTech. Он занимается разработкой больших языковых моделей и приложений генеративного искусственного интеллекта для финансов.
 Каран Аггарвал — старший научный сотрудник Amazon FinTech, специализирующийся на генеративном искусственном интеллекте для финансовых целей. Каран имеет большой опыт в анализе временных рядов и НЛП, с особым интересом к обучению на ограниченных размеченных данных.
Каран Аггарвал — старший научный сотрудник Amazon FinTech, специализирующийся на генеративном искусственном интеллекте для финансовых целей. Каран имеет большой опыт в анализе временных рядов и НЛП, с особым интересом к обучению на ограниченных размеченных данных.
 Айтзаз Ахмад — менеджер по прикладным наукам в Amazon, где он возглавляет группу ученых, разрабатывающих различные приложения машинного обучения и генеративного искусственного интеллекта в финансах. Его исследовательские интересы связаны с НЛП, генеративным искусственным интеллектом и агентами LLM. Он получил степень доктора электротехники в Техасском университете A&M.
Айтзаз Ахмад — менеджер по прикладным наукам в Amazon, где он возглавляет группу ученых, разрабатывающих различные приложения машинного обучения и генеративного искусственного интеллекта в финансах. Его исследовательские интересы связаны с НЛП, генеративным искусственным интеллектом и агентами LLM. Он получил степень доктора электротехники в Техасском университете A&M.
 Цинвэй Ли — специалист по машинному обучению в Amazon Web Services. Он получил докторскую степень. в области исследования операций после того, как он сломал счет гранта на исследования своего советника и не смог выплатить обещанную Нобелевскую премию. В настоящее время он помогает клиентам из сферы финансовых услуг создавать решения машинного обучения на AWS.
Цинвэй Ли — специалист по машинному обучению в Amazon Web Services. Он получил докторскую степень. в области исследования операций после того, как он сломал счет гранта на исследования своего советника и не смог выплатить обещанную Нобелевскую премию. В настоящее время он помогает клиентам из сферы финансовых услуг создавать решения машинного обучения на AWS.
 Рагвендер Арни возглавляет группу по работе с клиентами (CAT) в AWS Industries. CAT — это глобальная межфункциональная команда, состоящая из облачных архитекторов, инженеров-программистов, специалистов по обработке данных, а также экспертов и дизайнеров в области искусственного интеллекта и машинного обучения, которая занимается внедрением инноваций посредством усовершенствованного прототипирования и обеспечивает совершенство эксплуатации облака благодаря специализированным техническим знаниям.
Рагвендер Арни возглавляет группу по работе с клиентами (CAT) в AWS Industries. CAT — это глобальная межфункциональная команда, состоящая из облачных архитекторов, инженеров-программистов, специалистов по обработке данных, а также экспертов и дизайнеров в области искусственного интеллекта и машинного обучения, которая занимается внедрением инноваций посредством усовершенствованного прототипирования и обеспечивает совершенство эксплуатации облака благодаря специализированным техническим знаниям.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

