Амазонка Redshift — это самое быстрое, наиболее широко используемое, полностью управляемое облачное хранилище данных объемом в петабайты. Десятки тысяч клиентов используют Amazon Redshift для ежедневной обработки эксабайтов данных, чтобы повысить эффективность своих аналитических рабочих нагрузок. Инженеры по данным, аналитики данных и специалисты по данным хотят использовать эти данные для выполнения аналитических рабочих нагрузок, таких как бизнес-аналитика (BI), прогнозная аналитика, машинное обучение (ML) и потоковая аналитика в реальном времени.
информатика Интеллектуальное облако управления данными™ (IDMC) — это основанная на ИИ, управляемая метаданными, персонализированная облачная платформа, предоставляющая специалистам по данным комплексные и целостные возможности управления облачными данными для обнаружения, каталогизации, приема, очистки, интеграции, управления, защиты, подготовить и мастер-данные. Загрузчик данных Informatica для Amazon Redshift, доступно на Консоль управления AWS, — это бесплатная бессерверная служба IDMC, которая обеспечивает беспрепятственную загрузку данных в Amazon Redshift.
Клиентам необходимо быстро и масштабно передавать данные из различных хранилищ данных, включая локальные и устаревшие системы, сторонние приложения и сервисы AWS, такие как Сервис реляционной базы данных Amazon (Амазон РДС), Amazon DynamoDB, и более. Вам также необходимо простое, удобное и облачное решение для быстрого подключения новых источников данных или анализа последних данных для получения полезных сведений. Теперь с Informatica Data Loader для Amazon Redshift вы можете безопасно подключаться и загружать данные в Amazon Redshift в любом масштабе с помощью простого интерфейса с подсказками. Доступ к Informatica Data Loader можно получить непосредственно из консоли Amazon Redshift.
В этом посте представлены пошаговые инструкции по загрузке данных в Amazon Redshift с помощью Informatica Data Loader.
Обзор решения
Вы можете получить доступ к Informatica Data Loader непосредственно из панели навигации в консоли Amazon Redshift. Этот процесс следует аналогичному рабочему процессу, который пользователи Amazon Redshift уже используют для доступа к редактору запросов Amazon Redshift для создания и организации SQL-запросов или создания общих ресурсов для обмена оперативными данными в режиме только для чтения между кластерами.
Для этого сообщения мы используем учетную запись разработчика Salesforce в качестве источника данных. Инструкции по импорту примера набора данных см. Импорт образцов данных учетной записи. Вы можете использовать более 30 готовых коннекторов, поддерживаемых службами Informatica, для подключения к выбранному вами источнику данных.
Мы используем Informatica Data Loader для выбора и загрузки подмножества объектов Salesforce в Amazon Redshift в три простых шага:
- Подключиться к источнику данных.
- Подключитесь к целевому источнику данных.
- Запланируйте или запустите загрузку данных.
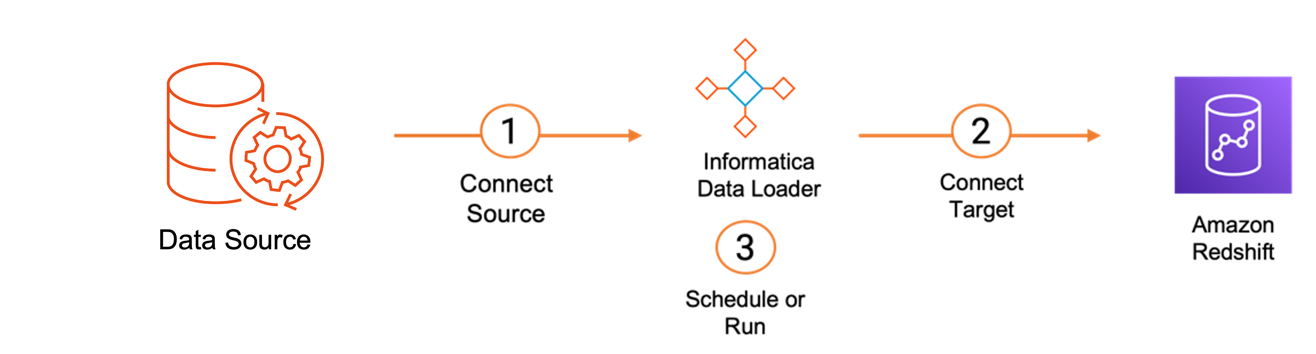
В дополнение к фильтрации на уровне объектов служба также поддерживает полную и добавочную загрузку, сбор данных об изменениях (CDC), фильтрацию на основе столбцов и строк, а также изменения схемы. После загрузки данных вы можете выполнить запрос и создать визуализацию с помощью Amazon Redshift Query Editor версии 2.0.
Предпосылки
Выполните следующие предварительные условия:
- Создайте кластер или рабочую группу Amazon Redshift. Для получения дополнительной информации см. Создание кластера в VPC or Amazon Redshift без сервера.
- Убедитесь, что к кластеру можно получить доступ из Informatica Data Loader. Для частного кластера добавьте правило входа в группу безопасности, прикрепленную к вашему кластеру, чтобы разрешить трафик от Informatica Data Loader. Разрешить IP-адрес для доступа к кластеру из Informatica Data Loader. Дополнительные сведения о добавлении правил в Эластичное вычислительное облако Amazon (Amazon EC2) группа безопасности, см. Разрешите входящий трафик для ваших инстансов Linux.
- Создать Простой сервис хранения Amazon (Amazon S3) в том же регионе, что и кластер Amazon Redshift. Загрузчик данных Informatica поместит данные в эту корзину перед загрузкой данных в кластер. Ссылаться на Создание ведра Больше подробностей. Запишите идентификатор ключа доступа и секретный ключ доступа для пользователя с разрешением на запись в промежуточную корзину S3.
- Если у вас нет учетной записи Salesforce, вы можете зарегистрируйте бесплатную учетную запись разработчика.
Теперь, когда вы выполнили предварительные условия, давайте начнем.
Запустите Informatica Data Loader из консоли Amazon Redshift.
Чтобы запустить Informatica Data Loader, выполните следующие шаги:
- На консоли Amazon Redshift в разделе Интеграция партнеров AWS в панели навигации выберите Загрузчик данных Informatica.
- Во всплывающем окне Создать интеграцию с Informatica, выберите Полная интеграция с Informatica.
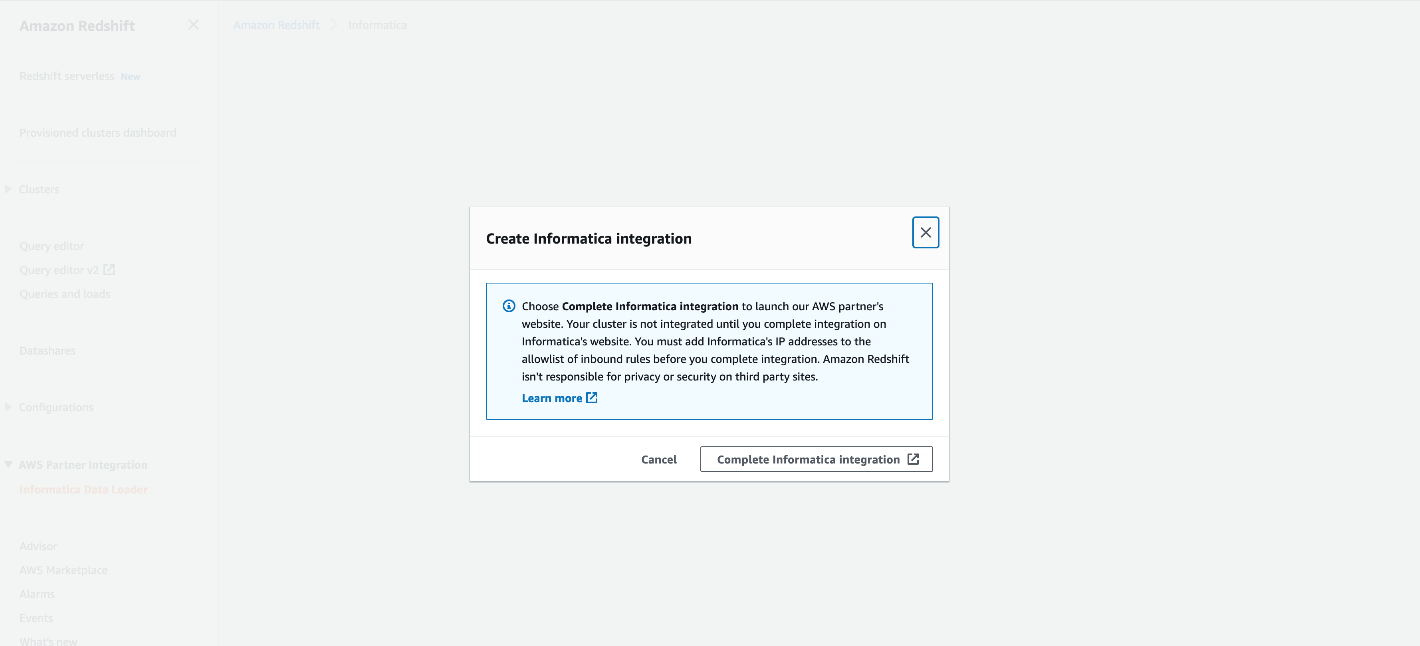 Если вы впервые получаете доступ к бесплатному загрузчику данных Informatica, вы будете перенаправлены на загрузчик данных Informatica для Amazon Redshift, чтобы зарегистрироваться бесплатно. Для регистрации вам нужен только ваш адрес электронной почты.
Если вы впервые получаете доступ к бесплатному загрузчику данных Informatica, вы будете перенаправлены на загрузчик данных Informatica для Amazon Redshift, чтобы зарегистрироваться бесплатно. Для регистрации вам нужен только ваш адрес электронной почты. - После регистрации вы можете войти в свою учетную запись Informatica.
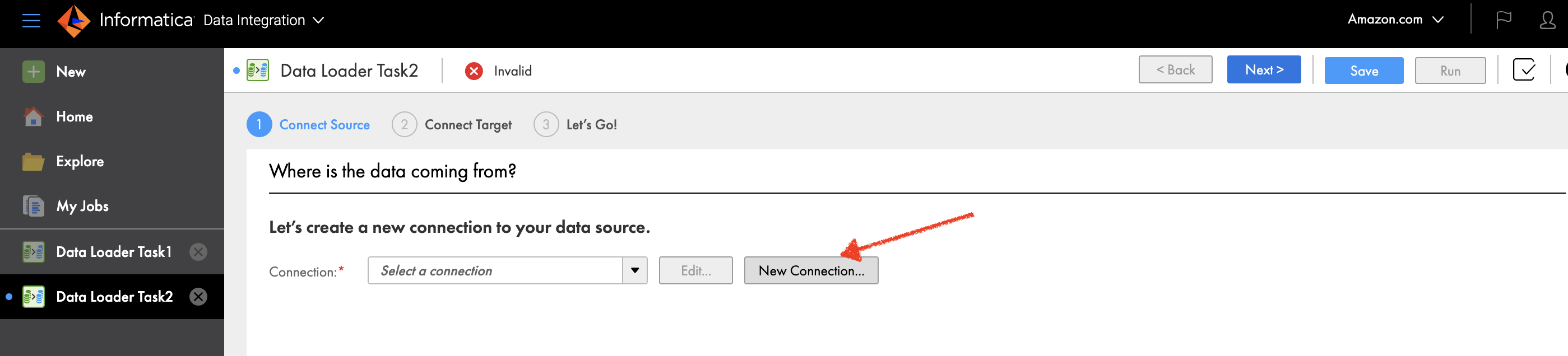
Подключиться к источнику данных
Чтобы подключиться к источнику данных, выполните следующие действия:
- В консоли Informatica Data Loader выберите Новые в навигационной панели.
- Выберите Новое соединение.
- Выберите Salesforce как исходное соединение.
- Выберите Продолжить.

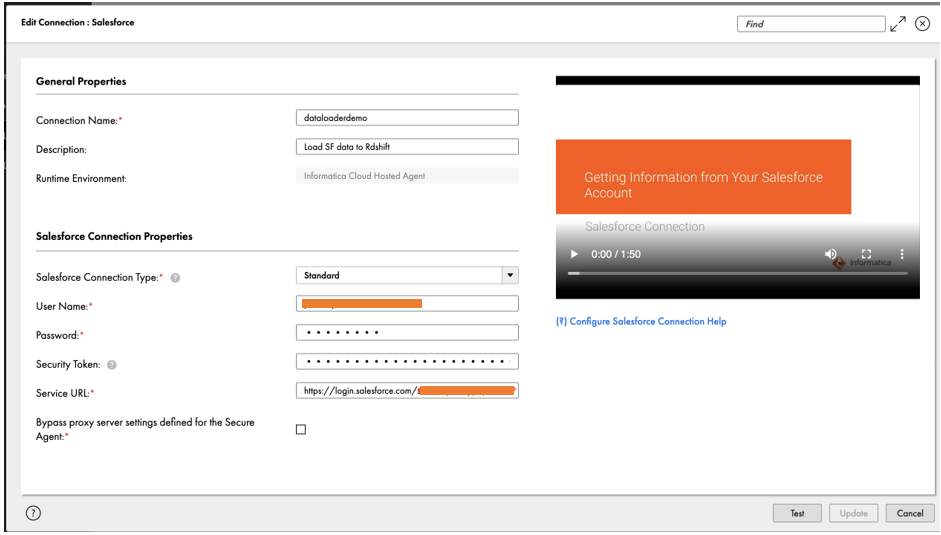
- Под Общие свойства, введите имя для вашего подключения и необязательное описание.
- Под Свойства подключения Salesforce¸ введите учетные данные для своей учетной записи Salesforce и маркер безопасности. Эти параметры могут различаться в зависимости от типа источника, типа подключения и метода проверки подлинности. В качестве руководства вы можете использовать встроенное справочное видео по настройке подключения.
- Запишите имя соединения
Salesforce_Source_Connection. - Выберите Пусконаладка для проверки соединения.
- Выберите Добавить , чтобы сохранить сведения о подключении и продолжить настройку загрузчика данных. Теперь, когда вы подключились к источнику данных Salesforce, вы загружаете информацию об учетной записи примера в Amazon Redshift. Для этого поста мы загружаем объект Account, содержащий среди прочих полей информацию о типе клиента и платежном штате или провинции.
- Убедитесь, что
Salesforce_Source_Connectionтолько что созданный, выбран как Связь. - Чтобы отфильтровать объект «Учетная запись» в Salesforce, выберите Включите некоторые под Определить объект.
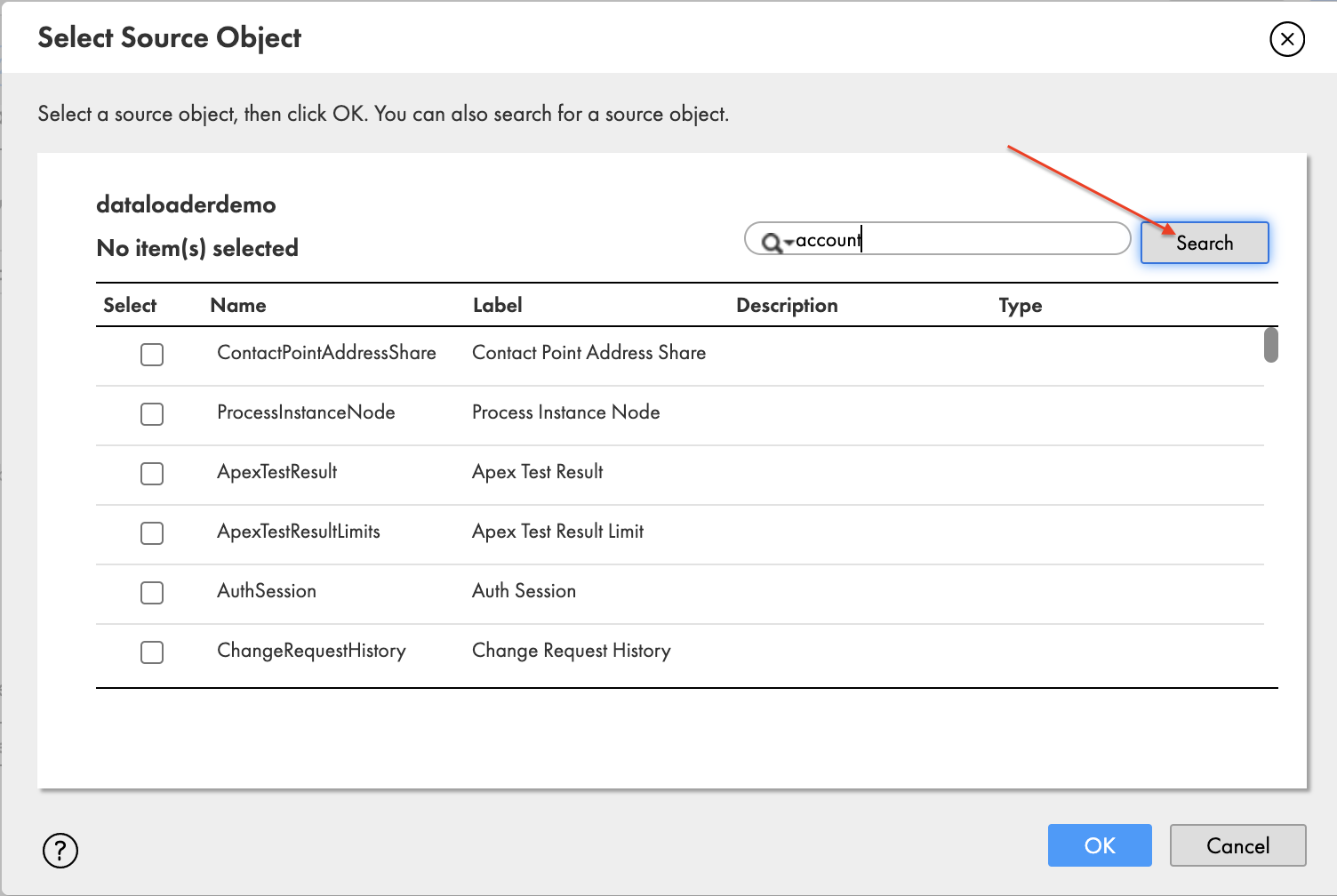
- Нажмите знак «плюс», чтобы выбрать учетную запись исходного объекта.
- Во всплывающем окне Выберите исходный объект, найдите учетную запись и выберите Поиск.
- Выберите Учетная запись , а затем выбрать OK.
- Для этого поста остальные следующие настройки оставлены со значениями по умолчанию:
- Исключить поля – Исключить исходные поля из исходных данных.
- Определить фильтр – Фильтрация строк из исходных данных на основе одного или нескольких заданных фильтров.
- Определить первичные ключи – Конфигурация для указания или обнаружения столбца первичного ключа в источнике данных.
- Определить поля водяных знаков – Конфигурация для указания или обнаружения столбца водяного знака в источнике данных.

Подключиться к целевому источнику данных
Чтобы подключиться к целевому источнику данных (Amazon Redshift), выполните следующие действия:
- В загрузчике данных Informatica выберите Подключить цель.
- Выберите Новое соединение.
- Что касается Связь, выберите Красное смещение (Amazon Redshift v2).
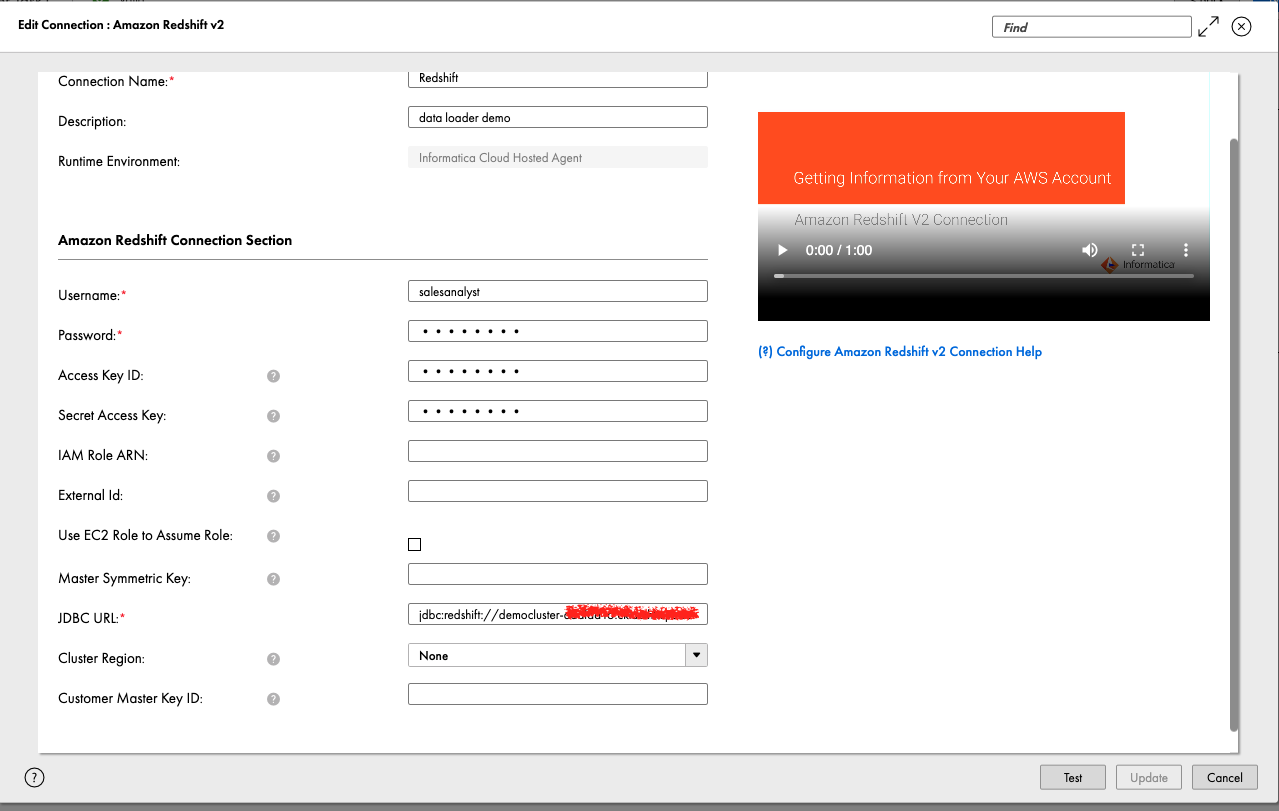
- Укажите имя подключения и необязательное описание.
- Под Раздел подключения к Amazon Redshift, введите идентификатор ключа доступа, секретный ключ доступа и URL-адрес JDBC или подготовленный кластер или бессерверную рабочую группу.
- Выберите Пусконаладка для проверки подключения.
- После успешного подключения выберите Добавить.
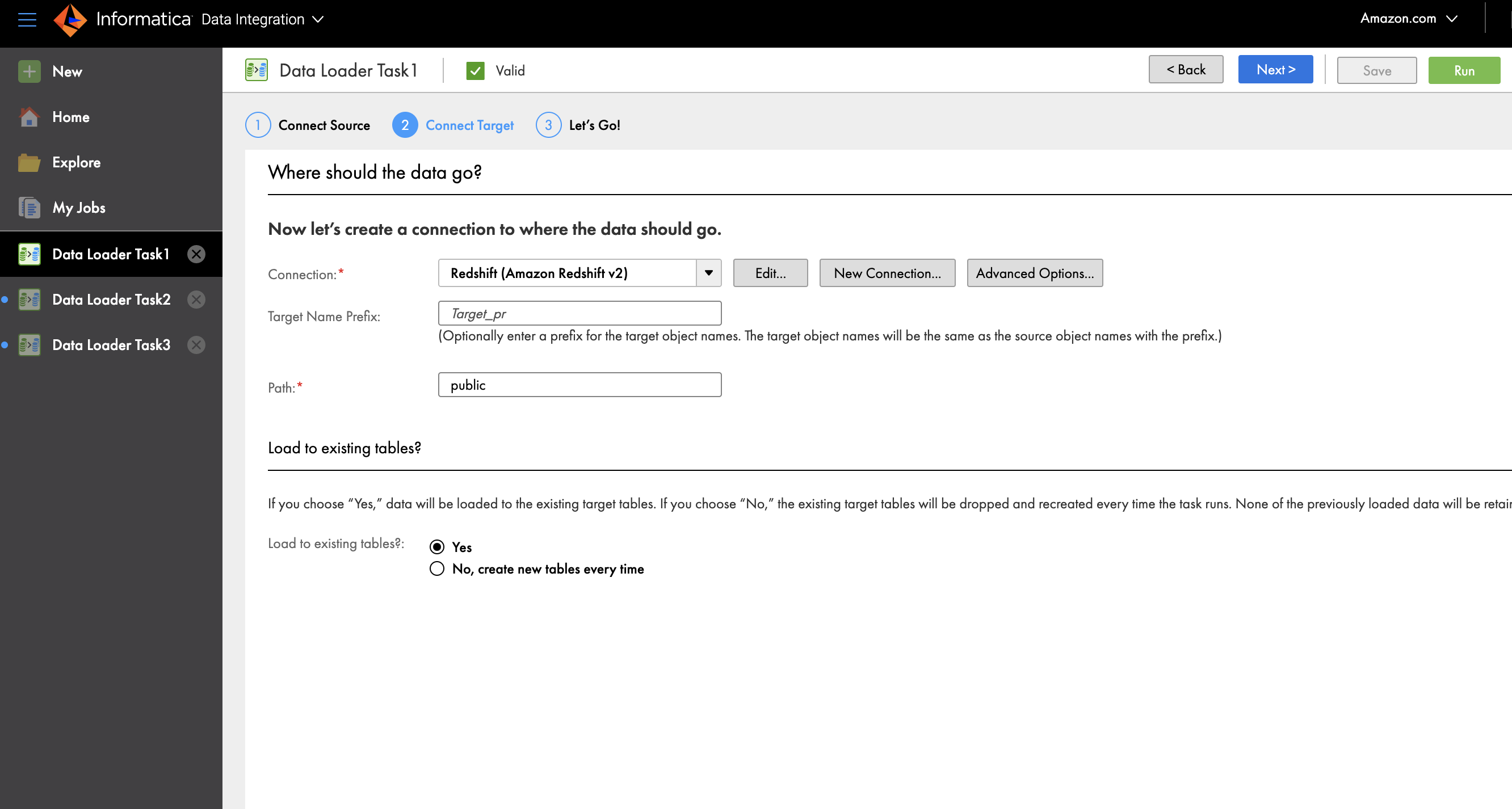
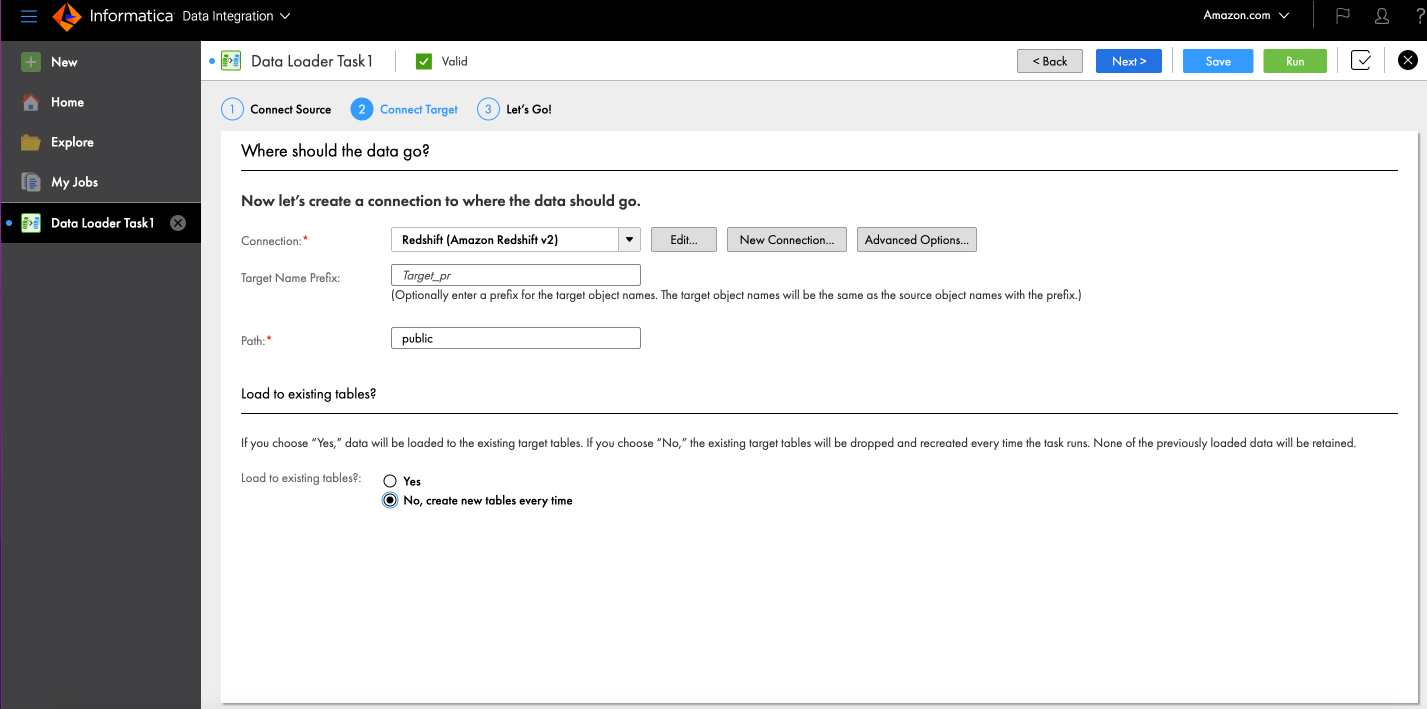
- По желанию, для Префикс имени цели, введите префикс, к которому должно быть добавлено имя объекта.
- Что касается Path, введите общедоступное имя схемы в Amazon Redshift, куда вы хотите загрузить данные.
- Что касается Загрузить в существующие таблицы, наведите на Нет, каждый раз создавать новые таблицы.
- Выберите Дополнительные параметры чтобы ввести имя промежуточной корзины S3.
- Выберите OK.
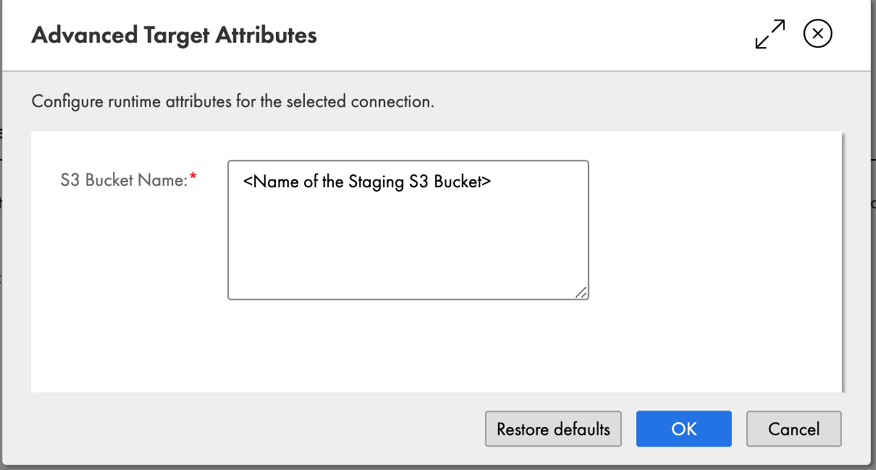
Теперь вы успешно подключились к целевому кластеру Amazon Redshift.
Запланировать или запустить загрузку данных
Вы можете запустить загрузку данных, выбрав Run или расширить Назначить раздел, чтобы запланировать его.
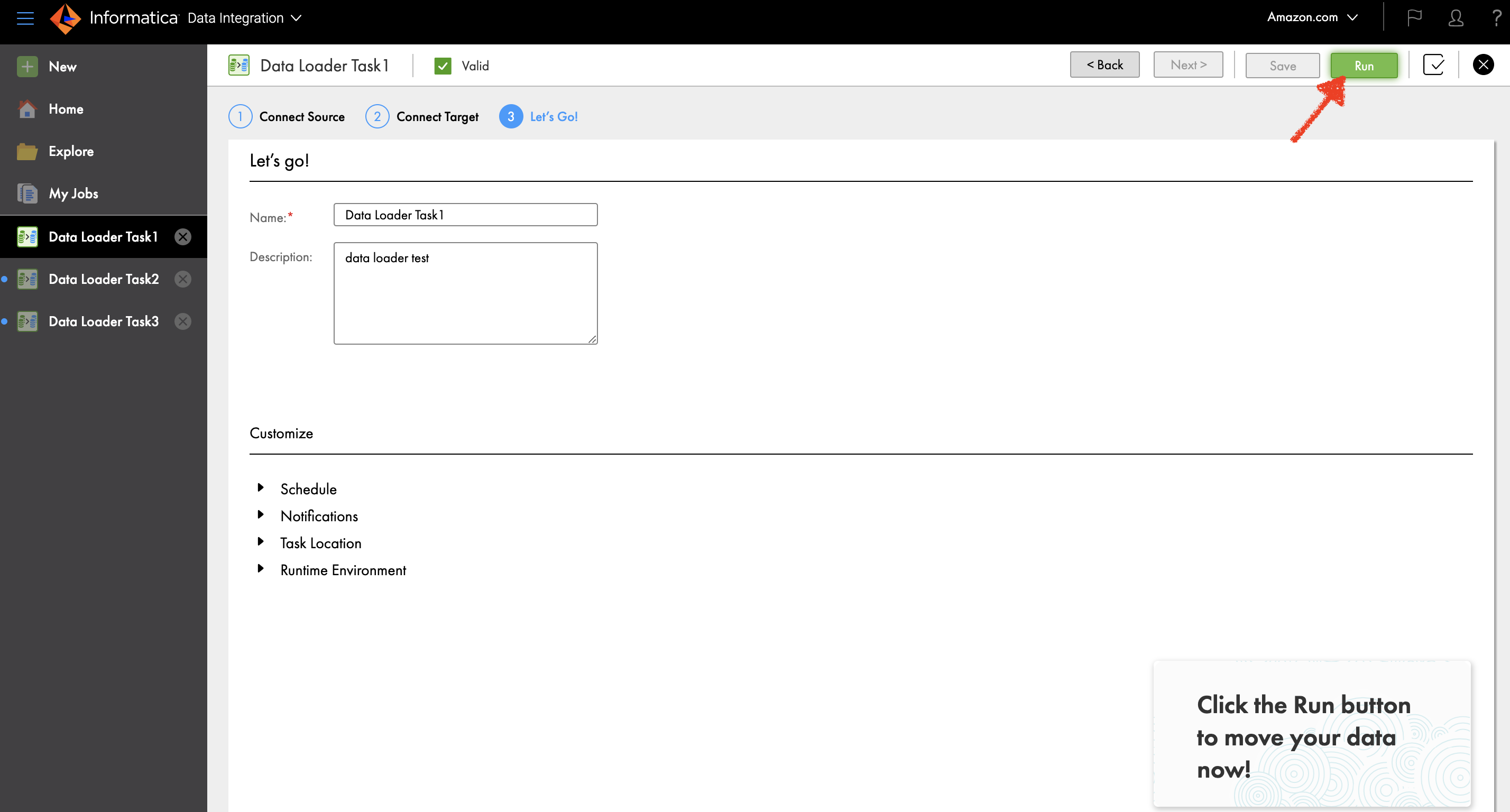
Вы также можете отслеживать статус задания на Мои вакансии стр.

Когда ваш статус работы изменится на Success, вы можете вернуться в консоль Amazon Redshift и открыть Query Editor V2.
В редакторе запросов Amazon Redshift версии 2.0 вы можете проверить загруженные данные, выполнив следующий запрос:
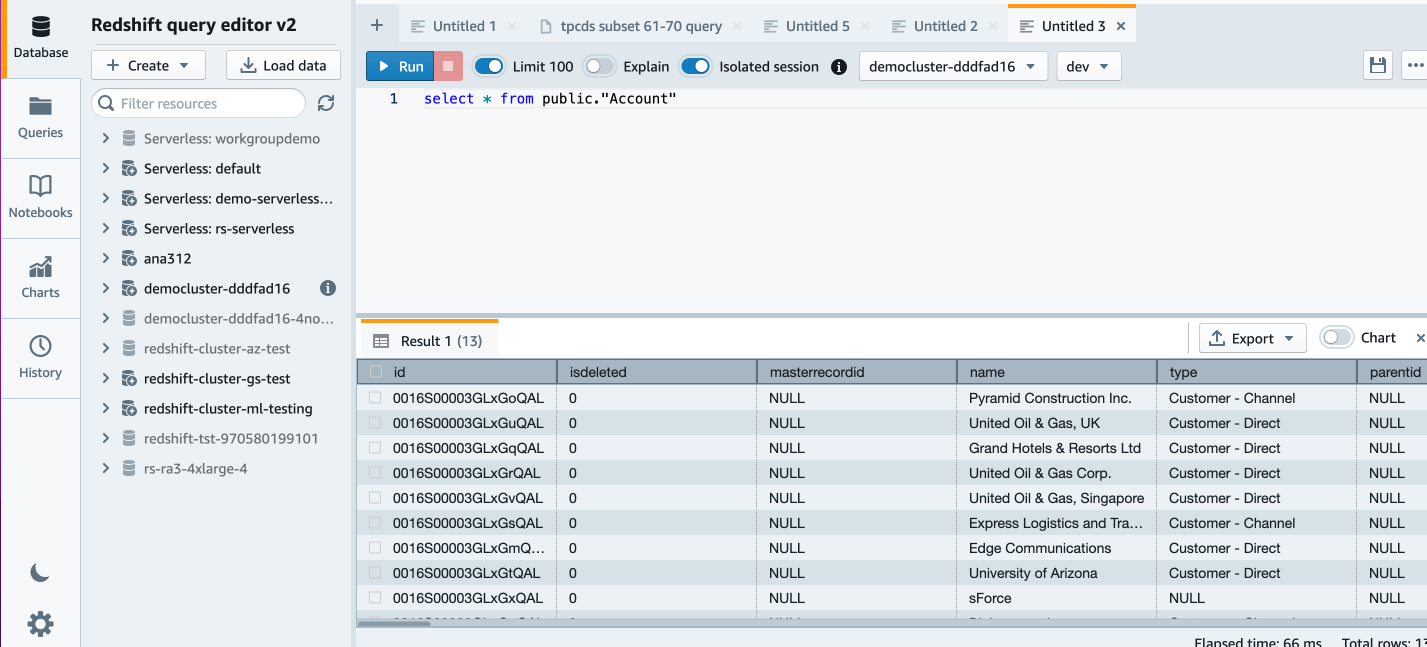
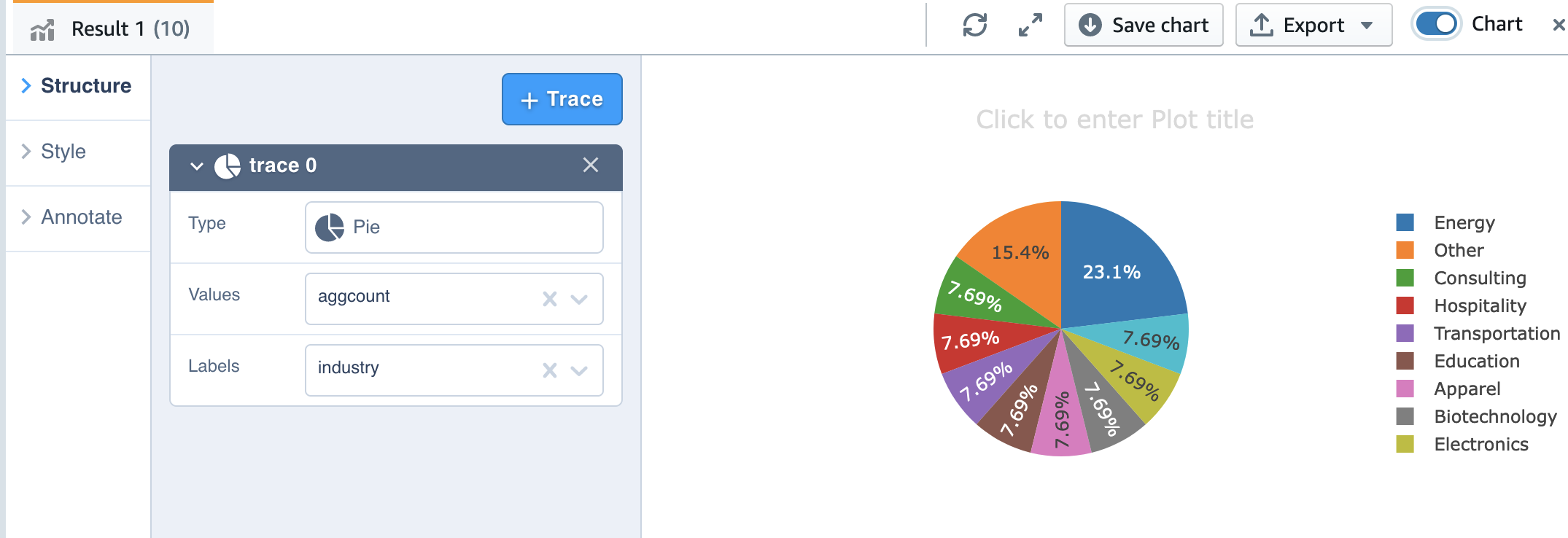
Теперь мы можем сделать еще один анализ. Давайте посмотрим на учетную запись клиента по отраслям:
Кроме того, мы можем использовать возможности построения диаграмм редактора запросов версии 2 для визуализации.
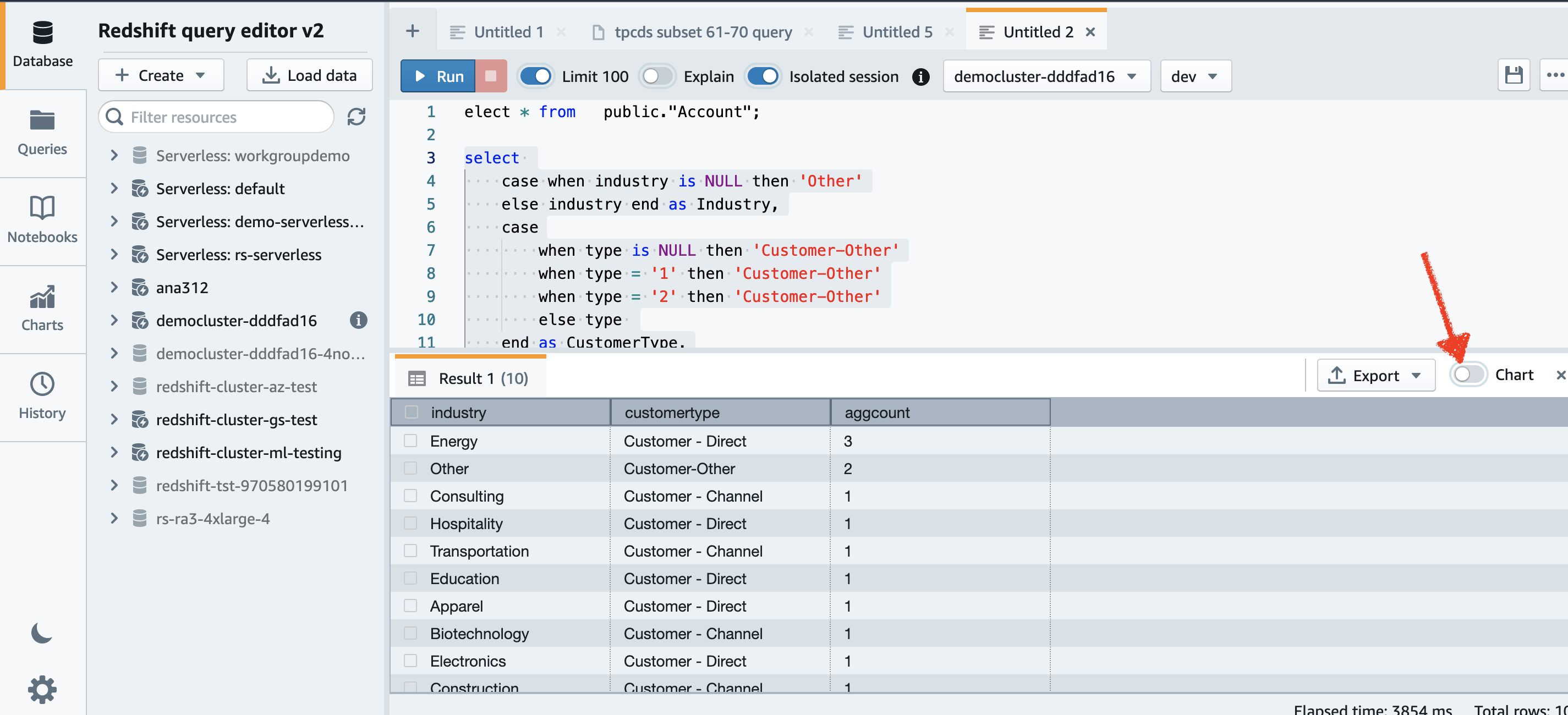
Просто выберите тип диаграммы, а также значение и метку, которую вы хотите отобразить.
Заключение
В публикации демонстрируется встроенная консоль Amazon Redshift для загрузки данных с помощью Informatica Data Loader и выполнения запросов к данным с помощью редактора запросов Amazon Redshift. С помощью Informatica Data Loader клиенты Amazon Redshift могут быстро подключать новые источники данных, выполнив три простых шага, и своевременно добавлять данные в нужном масштабе для принятия решений на основе данных.
Вы можете подписаться на Загрузчик данных Informatica для Amazon Redshift и начните загружать данные в Amazon Redshift.
Об авторах
 Дипак Рамешварапу является директором по управлению продуктами в Informatica. Он является руководителем продукта со стратегическим акцентом на новых функциях и запуске продуктов, стратегической дорожной карте продукта, искусственном интеллекте / машинном обучении, интеграции облачных данных, а также лидерстве в области проектирования и интеграции данных. Он имеет 20-летний опыт создания лучших в своем классе продуктов и решений для комплексного управления данными.
Дипак Рамешварапу является директором по управлению продуктами в Informatica. Он является руководителем продукта со стратегическим акцентом на новых функциях и запуске продуктов, стратегической дорожной карте продукта, искусственном интеллекте / машинном обучении, интеграции облачных данных, а также лидерстве в области проектирования и интеграции данных. Он имеет 20-летний опыт создания лучших в своем классе продуктов и решений для комплексного управления данными.
 Раджив Шринивасан является директором технического альянса экосистемы Informatica. Он возглавляет стратегическое техническое партнерство с AWS, чтобы предоставить клиентам необходимые инновационные решения и возможности. Наряду с одержимостью клиентами, у него есть страсть к данным и облачным технологиям, а также к езде на своем Harley.
Раджив Шринивасан является директором технического альянса экосистемы Informatica. Он возглавляет стратегическое техническое партнерство с AWS, чтобы предоставить клиентам необходимые инновационные решения и возможности. Наряду с одержимостью клиентами, у него есть страсть к данным и облачным технологиям, а также к езде на своем Harley.
 Михаил Йитаев — менеджер по продукту Amazon Redshift из Нью-Йорка. Он работает с клиентами и инженерными группами над созданием новых функций, которые позволяют инженерам и аналитикам данных упростить загрузку данных, управление ресурсами хранилища данных и выполнение запросов к своим данным. Он поддерживает клиентов AWS уже более 3 лет, занимаясь маркетингом и управлением продуктами.
Михаил Йитаев — менеджер по продукту Amazon Redshift из Нью-Йорка. Он работает с клиентами и инженерными группами над созданием новых функций, которые позволяют инженерам и аналитикам данных упростить загрузку данных, управление ресурсами хранилища данных и выполнение запросов к своим данным. Он поддерживает клиентов AWS уже более 3 лет, занимаясь маркетингом и управлением продуктами.
 Фил Бейтс является старшим специалистом по аналитике, архитектором решений в AWS. Он имеет более чем 25-летний опыт внедрения решений для крупномасштабных хранилищ данных. Он увлечен тем, что помогает клиентам в их переходе к облаку и использует возможности машинного обучения в их хранилище данных.
Фил Бейтс является старшим специалистом по аналитике, архитектором решений в AWS. Он имеет более чем 25-летний опыт внедрения решений для крупномасштабных хранилищ данных. Он увлечен тем, что помогает клиентам в их переходе к облаку и использует возможности машинного обучения в их хранилище данных.
 Вэйфан Лян является старшим архитектором партнерских решений в AWS. Он тесно сотрудничает с ведущими партнерами AWS по программному обеспечению для стратегической аналитики данных, чтобы обеспечить интеграцию продуктов, построить оптимизированную архитектуру, разработать долгосрочную стратегию и обеспечить передовые идеи. Внедряя инновации вместе с партнерами, Weifan стремится помочь клиентам ускорить получение бизнес-результатов с помощью цифровой трансформации на базе облачных технологий.
Вэйфан Лян является старшим архитектором партнерских решений в AWS. Он тесно сотрудничает с ведущими партнерами AWS по программному обеспечению для стратегической аналитики данных, чтобы обеспечить интеграцию продуктов, построить оптимизированную архитектуру, разработать долгосрочную стратегию и обеспечить передовые идеи. Внедряя инновации вместе с партнерами, Weifan стремится помочь клиентам ускорить получение бизнес-результатов с помощью цифровой трансформации на базе облачных технологий.
- Коинсмарт. Лучшая в Европе биржа биткойнов и криптовалют.Кликните сюда
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/simplify-data-loading-on-the-amazon-redshift-console-with-informatica-data-loader/

