
Изображение создано автором с помощью DALL•E 3
Основные выводы
- Chain of Code (CoC) — это новый подход к взаимодействию с языковыми моделями, улучшающий способности к рассуждению за счет сочетания написания кода и выборочной эмуляции кода.
- CoC расширяет возможности языковых моделей при решении логических, арифметических и лингвистических задач, особенно тех, которые требуют сочетания этих навыков.
- С помощью CoC языковые модели пишут код, а также эмулируют его части, которые не могут быть скомпилированы, предлагая уникальный подход к решению сложных проблем.
- CoC показывает эффективность как для крупных, так и для мелких LM.
Основная идея состоит в том, чтобы побудить LM форматировать лингвистические подзадачи в программе как гибкий псевдокод, который компилятор может явно улавливать неопределенное поведение и передавать для моделирования с помощью LM (как «LMulator»).
Постоянно появляются новые методы подсказки, общения и обучения языковой модели (LM), расширяющие возможности рассуждения и производительности LM. Одним из таких явлений является развитие Цепочка кода (CoC), метод, предназначенный для продвижения рассуждений, основанных на коде, в LM. Этот метод представляет собой сочетание традиционного кодирования и инновационной эмуляции выполнения кода LM, что создает мощный инструмент для решения сложных лингвистических и арифметических задач.
CoC отличается своей способностью решать сложные задачи, сочетающие в себе логику, арифметику и языковую обработку, что, как уже давно известно пользователям LM, уже давно является сложной задачей для стандартных LM. Эффективность CoC не ограничивается большими моделями, а распространяется на модели различных размеров, демонстрируя универсальность и широкую применимость в рассуждениях ИИ.
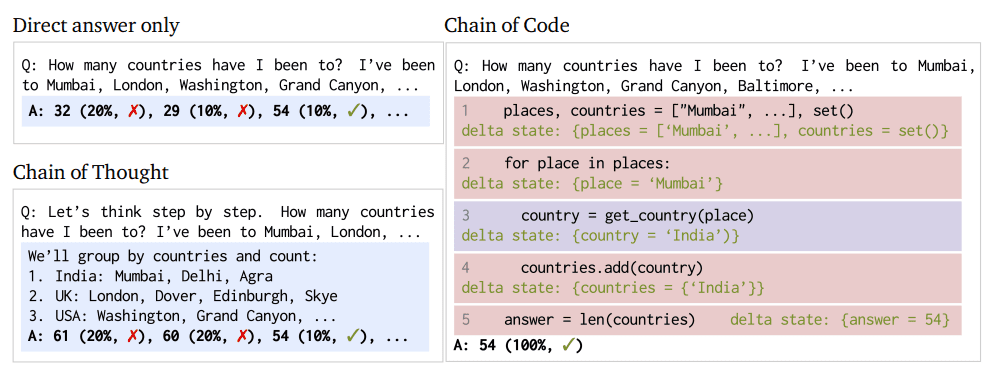
Рисунок 1: Подход «цепочка кода» и сравнение процессов (изображение из бумаги)
CoC — это смена парадигмы функциональности LM; это не простая тактика подсказок, призванная увеличить вероятность получения желаемого ответа от LM. Вместо этого CoC переопределяет подход LM к вышеупомянутым задачам рассуждения.
По своей сути CoC позволяет LM не только писать код, но и эмулировать его части, особенно те аспекты, которые не могут быть выполнены напрямую. Эта двойственность позволяет LM решать более широкий круг задач, сочетая лингвистические нюансы с решением логических и арифметических задач. CoC способен форматировать лингвистические задачи в виде псевдокода и эффективно устранять разрыв между традиционным кодированием и рассуждениями ИИ. Такое соединение позволяет создать гибкую и более эффективную систему для решения сложных проблем. LMulator, основной компонент расширенных возможностей CoC, позволяет моделировать и интерпретировать выходные данные выполнения кода, которые в противном случае не были бы напрямую доступны LM.
CoC продемонстрировал замечательный успех в различных тестах, значительно превосходя существующие подходы, такие как Chain of Thought, особенно в сценариях, требующих сочетания лингвистических и вычислительных рассуждений.
Эксперименты показывают, что Chain of Code превосходит Chain of Thought и другие базовые показатели по ряду тестов; на BIG-Bench Hard Chain of Code достигает 84%, что на 12% больше, чем Chain of Thought.
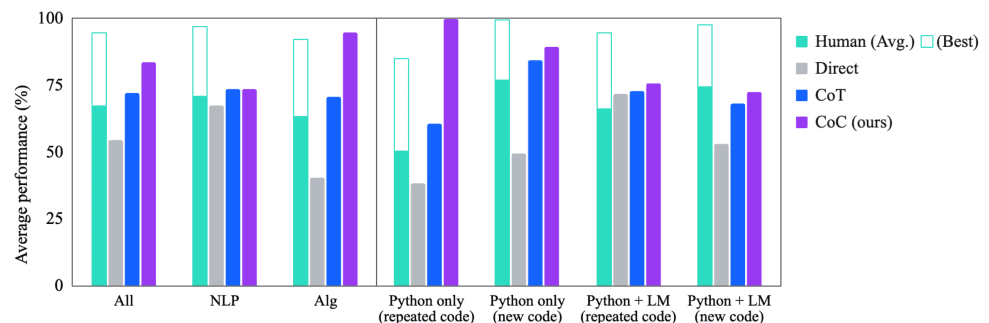
Рисунок 2: Сравнение производительности цепочки кода (изображение с бумаги)
Реализация CoC предполагает особый подход к решению задач, интеграцию процессов кодирования и эмуляции. CoC поощряет LM форматировать сложные логические задачи в виде псевдокода, который затем интерпретируется и решается. Этот процесс включает в себя несколько этапов:
- Определение задач на рассуждение: Определите лингвистическую или арифметическую задачу, требующую рассуждения.
- Написание кода: LM пишет псевдокод или гибкие фрагменты кода, чтобы наметить решение.
- Эмуляция кода: для частей кода, которые не могут быть выполнены напрямую, LM имитирует ожидаемый результат, эффективно моделируя выполнение кода.
- Объединение результатов: LM объединяет результаты как фактического выполнения кода, так и его эмуляции, чтобы сформировать комплексное решение проблемы.
Эти шаги позволяют LM решать более широкий круг рассуждений, «думая кодом», тем самым расширяя свои возможности решения проблем.
LMulator, как часть структуры CoC, может существенно помочь в совершенствовании как кода, так и рассуждений несколькими конкретными способами:
- Идентификация ошибок и моделирование. Когда языковая модель пишет код, который содержит ошибки или неисполняемые части, LMulator может моделировать, как этот код мог бы вести себя в случае его запуска, выявляя логические ошибки, бесконечные циклы или крайние случаи и направляя LM. переосмыслить и скорректировать логику кода.
- Обработка неопределенного поведения. В тех случаях, когда код включает неопределенное или неоднозначное поведение, которое стандартный интерпретатор не может выполнить, LMulator использует понимание контекста и намерений языковой модели, чтобы сделать вывод о том, каким должен быть вывод или поведение, предоставляя обоснованный, смоделированный вывод там, где это традиционно. выполнение потерпит неудачу.
- Улучшение рассуждений в коде. Когда требуется сочетание лингвистических и вычислительных рассуждений, LMulator позволяет языковой модели повторять генерацию собственного кода, моделируя результаты различных подходов, эффективно «рассуждая» с помощью кода, что приводит к более точному и эффективному результату. решения.
- Исследование пограничных случаев: LMulator может исследовать и тестировать, как код обрабатывает пограничные случаи, моделируя различные входные данные, что особенно полезно для обеспечения надежности кода и возможности обработки различных сценариев.
- Цикл обратной связи для обучения. Поскольку LMulator моделирует и выявляет проблемы или потенциальные улучшения в коде, эта обратная связь может использоваться языковой моделью для изучения и совершенствования своего подхода к кодированию и решению проблем, что представляет собой непрерывный процесс обучения, который улучшает возможности кодирования и рассуждения модели с течением времени.
LMulator расширяет возможности языковой модели по написанию, тестированию и совершенствованию кода, предоставляя платформу для моделирования и итеративного улучшения.
Техника CoC — это прогресс в улучшении рассуждений LM. CoC расширяет круг проблем, которые могут решать LM, за счет интеграции написания кода с выборочной эмуляцией кода. Этот подход демонстрирует потенциал ИИ для решения более сложных реальных задач, требующих тонкого мышления. Важно отметить, что CoC доказал свою эффективность как в малых, так и в больших LM, открывая путь для увеличения количества более мелких моделей, потенциально улучшая их способности к рассуждению и приближая их эффективность к эффективности более крупных моделей.
Для более глубокого понимания, полный текст статьи можно найти здесь.
Мэтью Майо (@mattmayo13) имеет степень магистра в области компьютерных наук и диплом о высшем образовании в области интеллектуального анализа данных. Будучи главным редактором KDnuggets, Мэтью стремится сделать доступными сложные концепции науки о данных. Его профессиональные интересы включают обработку естественного языка, алгоритмы машинного обучения и исследование нового искусственного интеллекта. Его миссией является демократизация знаний в сообществе специалистов по обработке и анализу данных. Мэтью занимается программированием с 6 лет.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.kdnuggets.com/enhancing-llm-reasoning-unveiling-chain-of-code-prompting?utm_source=rss&utm_medium=rss&utm_campaign=enhancing-llm-reasoning-unveiling-chain-of-code-prompting

