Студия Amazon SageMaker предоставляет полностью управляемое решение для специалистов по данным, позволяющее интерактивно создавать, обучать и развертывать модели машинного обучения (ML). В процессе работы над задачами ML специалисты по обработке данных обычно начинают рабочий процесс с обнаружения соответствующих источников данных и подключения к ним. Затем они используют SQL для исследования, анализа, визуализации и интеграции данных из различных источников, прежде чем использовать их в обучении и выводах ML. Раньше специалистам по данным часто приходилось манипулировать несколькими инструментами для поддержки SQL в своем рабочем процессе, что снижало производительность.
Мы рады сообщить, что блокноты JupyterLab в SageMaker Studio теперь оснащены встроенной поддержкой SQL. Ученые, работающие с данными, теперь могут:
- Подключайтесь к популярным службам передачи данных, включая Амазонка Афина, Амазонка Redshift, Зона данных Amazonи Снежинка прямо в блокнотах.
- Просмотр и поиск баз данных, схем, таблиц и представлений, а также предварительный просмотр данных в интерфейсе записной книжки.
- Смешайте код SQL и Python в одной записной книжке для эффективного исследования и преобразования данных для использования в проектах машинного обучения.
- Используйте функции повышения производительности разработчиков, такие как завершение команд SQL, помощь в форматировании кода и подсветка синтаксиса, чтобы ускорить разработку кода и повысить общую производительность разработчиков.
Кроме того, администраторы могут безопасно управлять подключениями к этим службам данных, что позволяет ученым, работающим с данными, получать доступ к авторизованным данным без необходимости управлять учетными данными вручную.
В этом посте мы покажем вам настройку этой функции в SageMaker Studio и познакомим вас с различными возможностями этой функции. Затем мы покажем, как можно улучшить работу с SQL на ноутбуке, используя возможности преобразования текста в SQL, предоставляемые расширенными моделями больших языков (LLM), для написания сложных SQL-запросов с использованием текста на естественном языке в качестве входных данных. Наконец, чтобы дать возможность более широкой аудитории пользователей генерировать запросы SQL на основе ввода на естественном языке в своих записных книжках, мы покажем вам, как развернуть эти модели преобразования текста в SQL с помощью Создатель мудреца Амазонки конечные точки.
Обзор решения
Благодаря интеграции SQL с блокнотом SageMaker Studio JupyterLab вы теперь можете подключаться к популярным источникам данных, таким как Snowflake, Athena, Amazon Redshift и Amazon DataZone. Эта новая функция позволяет выполнять различные функции.
Например, вы можете визуально исследовать источники данных, такие как базы данных, таблицы и схемы, непосредственно из вашей экосистемы JupyterLab. Если среда вашего блокнота работает под управлением SageMaker Distribution 1.6 или более поздней версии, найдите новый виджет в левой части интерфейса JupyterLab. Это дополнение улучшает доступность данных и управление ими в вашей среде разработки.
Если вы в настоящее время не используете предлагаемый дистрибутив SageMaker (1.5 или более раннюю версию) или не используете пользовательскую среду, обратитесь к приложению для получения дополнительной информации.
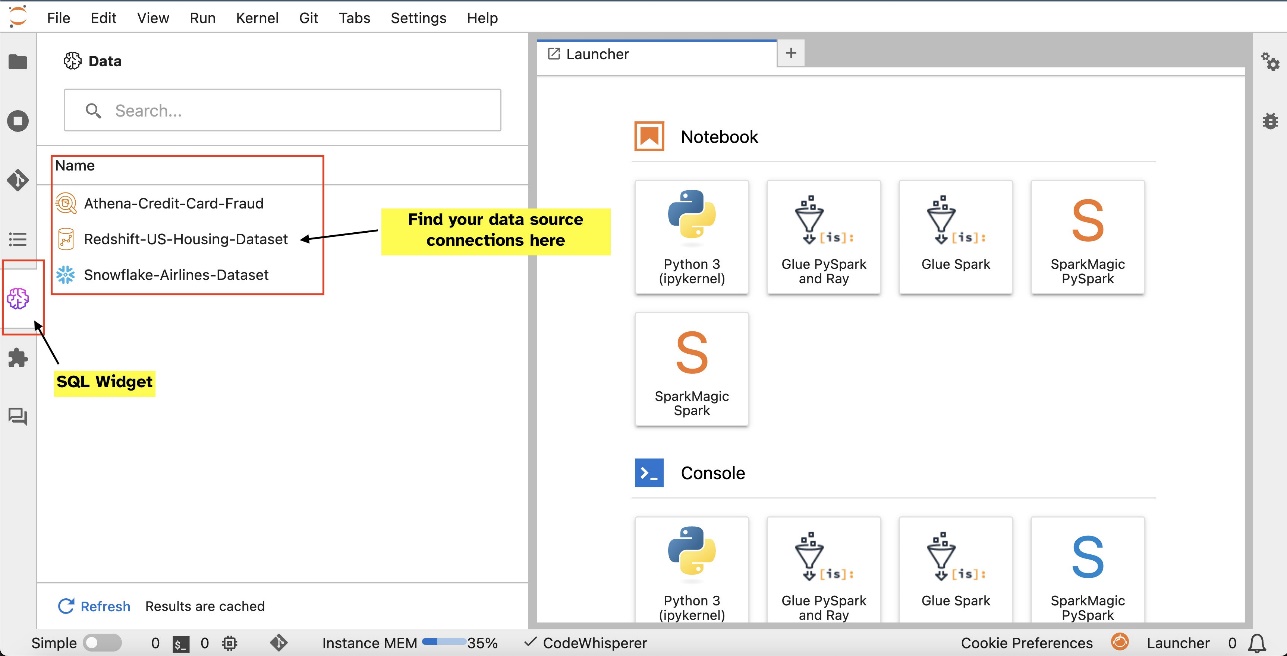
После настройки соединений (показано в следующем разделе) вы можете составить список подключений к данным, просматривать базы данных и таблицы, а также проверять схемы.
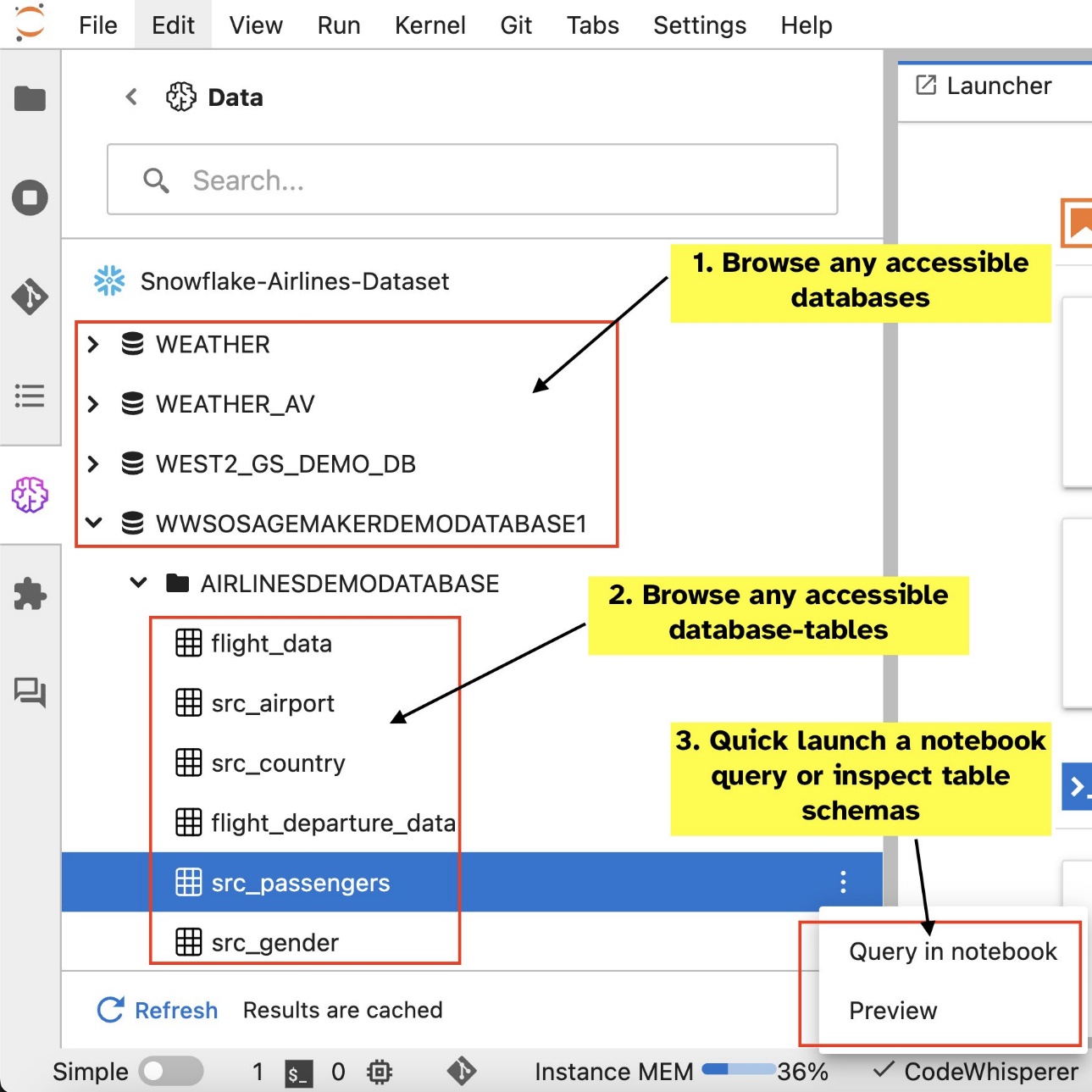
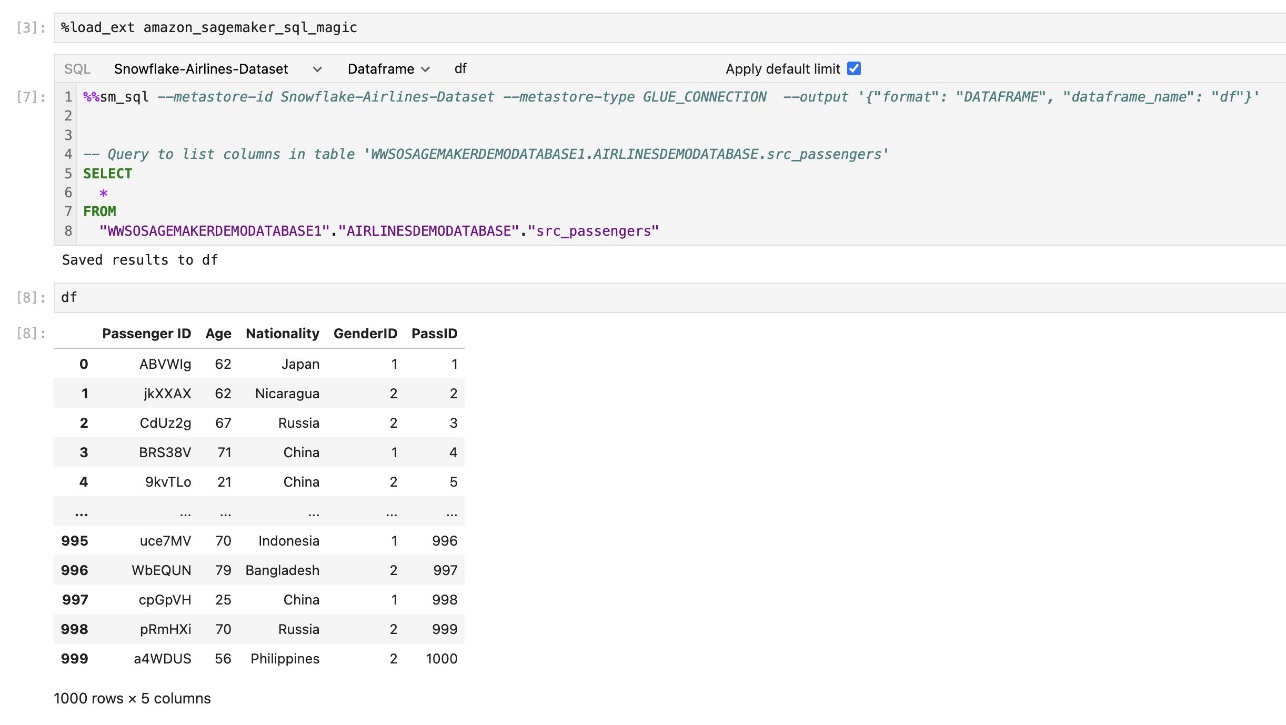
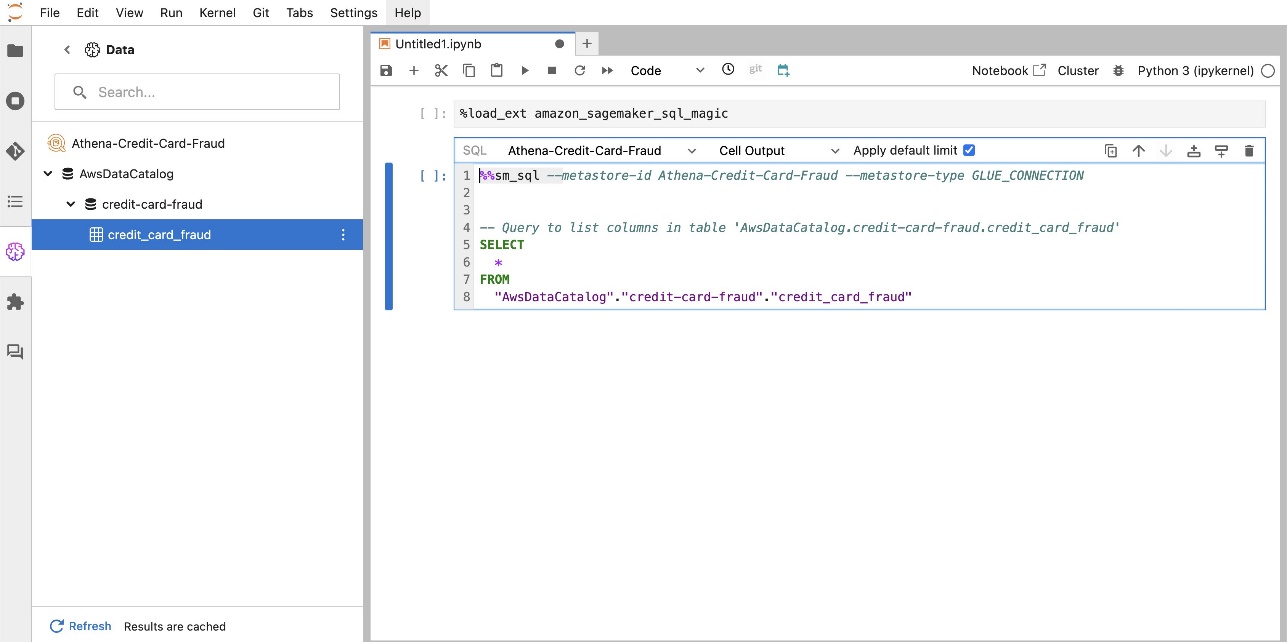
Встроенное расширение SQL SageMaker Studio JupyterLab также позволяет выполнять SQL-запросы непосредственно из записной книжки. Блокноты Jupyter могут различать код SQL и Python с помощью %%sm_sql волшебная команда, которую необходимо разместить вверху любой ячейки, содержащей код SQL. Эта команда сигнализирует JupyterLab, что следующие инструкции являются командами SQL, а не кодом Python. Результаты запроса могут отображаться непосредственно в блокноте, что облегчает интеграцию рабочих процессов SQL и Python в анализ данных.
Вывод запроса можно отобразить визуально в виде HTML-таблиц, как показано на следующем снимке экрана.

Их также можно записать в Панды DataFrame.
Предпосылки
Чтобы использовать SQL-интерфейс записной книжки SageMaker Studio, убедитесь, что вы выполнили следующие предварительные требования:
- SageMaker Studio V2 – Убедитесь, что вы используете самую последнюю версию вашего Домен SageMaker Studio и профили пользователей. Если вы в настоящее время используете SageMaker Studio Classic, см. Миграция с Amazon SageMaker Studio Classic.
- Роль IAM – Для SageMaker требуется Управление идентификацией и доступом AWS (IAM) роль, которая будет назначена домену SageMaker Studio или профилю пользователя для эффективного управления разрешениями. Обновление роли выполнения может потребоваться для включения просмотра данных и функции запуска SQL. Следующий пример политики позволяет пользователям предоставлять, перечислять и запускать Клей AWS, Афина, Простой сервис хранения Amazon (Амазон С3), Менеджер секретов AWSи ресурсы Amazon Redshift:
- JupyterLab Пространство – Вам необходим доступ к обновленной версии SageMaker Studio и JupyterLab Space с Распространение SageMaker v1.6 или более поздние версии образа. Если вы используете пользовательские образы для JupyterLab Spaces или более ранних версий дистрибутива SageMaker (1.5 или ниже), обратитесь к приложению за инструкциями по установке необходимых пакетов и модулей для включения этой функции в ваших средах. Чтобы узнать больше о пространствах SageMaker Studio JupyterLab, см. Повысьте производительность в Amazon SageMaker Studio: представляем JupyterLab Spaces и инструменты генеративного искусственного интеллекта.
- Учетные данные для доступа к источнику данных – Для этой функции блокнота SageMaker Studio требуется имя пользователя и пароль для доступа к таким источникам данных, как Snowflake и Amazon Redshift. Создайте доступ на основе имени пользователя и пароля к этим источникам данных, если у вас его еще нет. Доступ к Snowflake на основе OAuth не поддерживается на момент написания этой статьи.
- Загрузить магию SQL – Прежде чем запускать SQL-запросы из ячейки записной книжки Jupyter, необходимо загрузить магическое расширение SQL. Используйте команду
%load_ext amazon_sagemaker_sql_magicчтобы включить эту функцию. Кроме того, вы можете запустить%sm_sql?Команда для просмотра полного списка поддерживаемых параметров запроса из ячейки SQL. Эти параметры включают, среди прочего, установку лимита запросов по умолчанию в 1,000, выполнение полного извлечения и внедрение параметров запроса. Эта настройка позволяет гибко и эффективно манипулировать данными SQL непосредственно в среде вашего ноутбука.
Создание подключений к базе данных
Встроенные возможности просмотра и выполнения SQL в SageMaker Studio расширяются за счет соединений AWS Glue. Соединение AWS Glue — это объект каталога данных AWS Glue, в котором хранятся важные данные, такие как учетные данные для входа, строки URI и информация виртуального частного облака (VPC) для конкретных хранилищ данных. Эти соединения используются сканерами, заданиями и конечными точками разработки AWS Glue для доступа к различным типам хранилищ данных. Вы можете использовать эти соединения как для исходных, так и для целевых данных и даже повторно использовать одно и то же соединение для нескольких сканеров или заданий извлечения, преобразования и загрузки (ETL).
Чтобы изучить источники данных SQL на левой панели SageMaker Studio, сначала необходимо создать объекты подключения AWS Glue. Эти соединения облегчают доступ к различным источникам данных и позволяют исследовать элементы их схематических данных.
В следующих разделах мы рассмотрим процесс создания коннекторов AWS Glue для SQL. Это позволит вам получать доступ, просматривать и исследовать наборы данных в различных хранилищах данных. Более подробную информацию о соединениях AWS Glue см. Подключение к данным.
Создание соединения AWS Glue
Единственный способ перенести источники данных в SageMaker Studio — использовать соединения AWS Glue. Вам необходимо создать соединения AWS Glue с определенными типами соединений. На момент написания этой статьи единственным поддерживаемым механизмом создания этих соединений является использование Интерфейс командной строки AWS (Интерфейс командной строки AWS).
JSON-файл определения соединения
При подключении к различным источникам данных в AWS Glue необходимо сначала создать файл JSON, определяющий свойства соединения, называемый файл определения соединения. Этот файл имеет решающее значение для установления соединения AWS Glue и должен содержать все необходимые конфигурации для доступа к источнику данных. В целях обеспечения безопасности рекомендуется использовать Secrets Manager для безопасного хранения конфиденциальной информации, такой как пароли. Между тем, другими свойствами соединения можно управлять напрямую через соединения AWS Glue. Такой подход гарантирует защиту конфиденциальных учетных данных, сохраняя при этом доступность и управляемость конфигурации подключения.
Ниже приведен пример определения соединения в формате JSON:
При настройке подключений AWS Glue для источников данных необходимо следовать нескольким важным рекомендациям, чтобы обеспечить как функциональность, так и безопасность:
- Стрингификация свойств – В рамках
PythonPropertiesключ, убедитесь, что все свойства строковые пары ключ-значение. Крайне важно правильно избегать двойных кавычек, используя при необходимости символ обратной косой черты (). Это помогает поддерживать правильный формат и избегать синтаксических ошибок в JSON. - Обработка конфиденциальной информации – Хотя можно включить все свойства соединения в
PythonProperties, желательно не включать конфиденциальные данные, такие как пароли, непосредственно в эти свойства. Вместо этого используйте Secrets Manager для обработки конфиденциальной информации. Этот подход защищает ваши конфиденциальные данные, храня их в контролируемой и зашифрованной среде, вдали от основных файлов конфигурации.
Создайте соединение AWS Glue с помощью интерфейса командной строки AWS.
После включения всех необходимых полей в JSON-файл определения соединения вы готовы установить соединение AWS Glue для вашего источника данных с помощью интерфейса командной строки AWS и следующей команды:
Эта команда инициирует новое соединение AWS Glue на основе спецификаций, подробно описанных в вашем файле JSON. Ниже приводится краткое описание компонентов команды:
- -область – Здесь указывается регион AWS, в котором будет создано соединение AWS Glue. Крайне важно выбрать регион, в котором расположены ваши источники данных и другие службы, чтобы минимизировать задержку и соответствовать требованиям к размещению данных.
- –cli-input-json файл:///путь/к/файлу/соединение/определение/file.json – Этот параметр указывает интерфейсу командной строки AWS прочитать входную конфигурацию из локального файла, который содержит определение вашего соединения в формате JSON.
У вас должна быть возможность создавать соединения AWS Glue с помощью предыдущей команды AWS CLI из терминала Studio JupyterLab. На Файл Меню, выберите Новые и Терминал.

Если же линия индикатора create-connection Команда выполняется успешно, вы должны увидеть свой источник данных в списке на панели браузера SQL. Если вы не видите свой источник данных в списке, выберите обновление для обновления кеша.

Создание соединения «Снежинка»
В этом разделе мы сосредоточимся на интеграции источника данных Snowflake с SageMaker Studio. Создание учетных записей, баз данных и хранилищ Snowflake выходит за рамки этой статьи. Чтобы начать работу со Snowflake, обратитесь к Руководство пользователя снежинки. В этом посте мы сосредоточимся на создании JSON-файла определения Snowflake и установлении соединения с источником данных Snowflake с помощью AWS Glue.
Создайте секрет Секретного менеджера
Вы можете подключиться к своей учетной записи Snowflake, используя идентификатор пользователя и пароль или используя закрытые ключи. Чтобы подключиться с помощью идентификатора пользователя и пароля, вам необходимо надежно сохранить свои учетные данные в Secrets Manager. Как упоминалось ранее, хотя эту информацию можно встроить в PythonProperties, не рекомендуется хранить конфиденциальную информацию в текстовом формате. Всегда убедитесь, что конфиденциальные данные обрабатываются безопасно, чтобы избежать потенциальных угроз безопасности.
Чтобы сохранить информацию в Secrets Manager, выполните следующие действия:
- На консоли диспетчера секретов выберите Храните новый секрет.
- Что касается Секретный тип, выберите Другой тип секрета.
- Для пары ключ-значение выберите Простой текст и введите следующее:
- Введите имя для своего секрета, например
sm-sql-snowflake-secret. - Остальные настройки оставьте по умолчанию или настройте при необходимости.
- Создайте секрет.
Создайте соединение AWS Glue для Snowflake.
Как обсуждалось ранее, соединения AWS Glue необходимы для доступа к любому соединению из SageMaker Studio. Вы можете найти список все поддерживаемые свойства соединения для Snowflake. Ниже приведен пример определения соединения JSON для Snowflake. Замените значения заполнителей соответствующими значениями перед сохранением на диск:
Чтобы создать объект подключения AWS Glue для источника данных Snowflake, используйте следующую команду:
Эта команда создает новое соединение с источником данных Snowflake на панели браузера SQL, которое можно просматривать, и вы можете выполнять к нему запросы SQL из ячейки записной книжки JupyterLab.
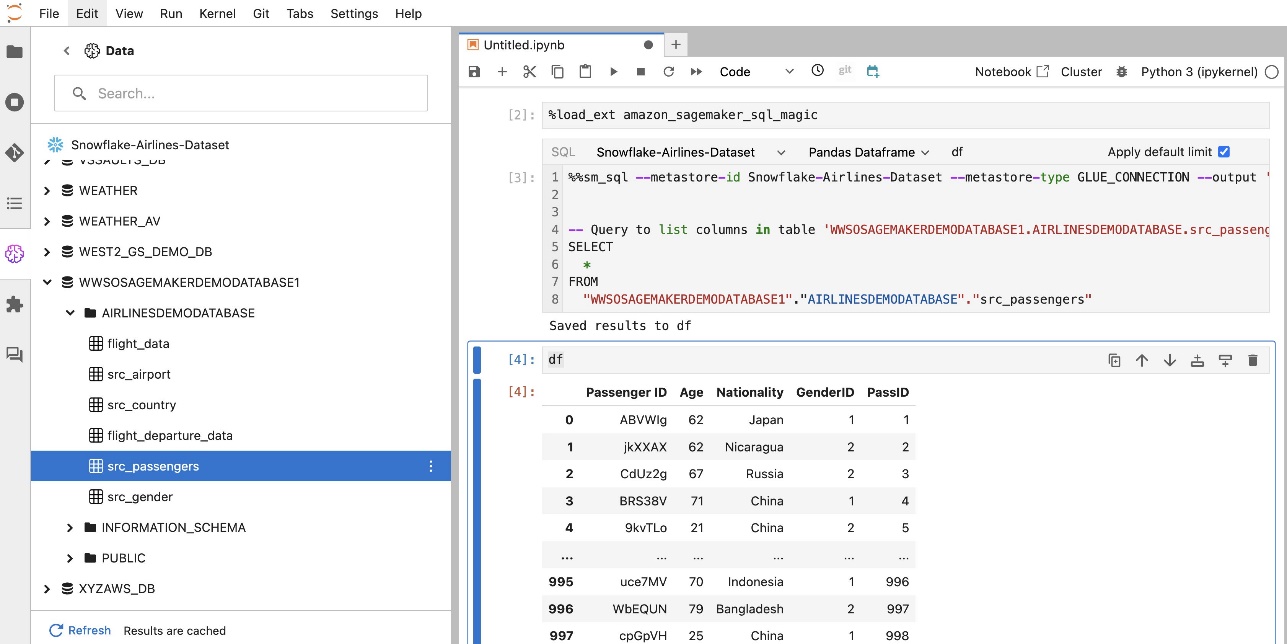
Создание подключения к Amazon Redshift
Amazon Redshift — это полностью управляемый сервис хранилища данных объемом в петабайты, который упрощает и снижает затраты на анализ всех ваших данных с использованием стандартного SQL. Процедура создания подключения Amazon Redshift во многом повторяет процедуру создания подключения Snowflake.
Создайте секрет Секретного менеджера
Как и в случае с установкой Snowflake, для подключения к Amazon Redshift с использованием идентификатора пользователя и пароля вам необходимо надежно хранить секретную информацию в Secrets Manager. Выполните следующие шаги:
- На консоли диспетчера секретов выберите Храните новый секрет.
- Что касается Секретный тип, выберите Учетные данные для кластера Amazon Redshift.
- Введите учетные данные, используемые для входа в систему для доступа к Amazon Redshift в качестве источника данных.
- Выберите кластер Redshift, связанный с секретами.
- Введите имя секрета, например
sm-sql-redshift-secret. - Остальные настройки оставьте по умолчанию или настройте при необходимости.
- Создайте секрет.
Выполнив эти шаги, вы убедитесь, что ваши учетные данные для подключения обрабатываются безопасно, используя надежные функции безопасности AWS для эффективного управления конфиденциальными данными.
Создайте соединение AWS Glue для Amazon Redshift.
Чтобы настроить соединение с Amazon Redshift с использованием определения JSON, заполните необходимые поля и сохраните на диск следующую конфигурацию JSON:
Чтобы создать объект подключения AWS Glue для источника данных Redshift, используйте следующую команду AWS CLI:
Эта команда создает соединение в AWS Glue, связанное с вашим источником данных Redshift. Если команда будет выполнена успешно, вы сможете увидеть свой источник данных Redshift в блокноте SageMaker Studio JupyterLab, готовый к выполнению запросов SQL и выполнению анализа данных.

Создать соединение с Афиной
Athena — это полностью управляемый сервис SQL-запросов от AWS, который позволяет анализировать данные, хранящиеся в Amazon S3, с использованием стандартного SQL. Чтобы настроить соединение Athena в качестве источника данных в браузере SQL записной книжки JupyterLab, вам необходимо создать образец определения соединения Athena в формате JSON. Следующая структура JSON настраивает необходимые данные для подключения к Athena, определяя каталог данных, промежуточный каталог S3 и регион:
Чтобы создать объект подключения AWS Glue для источника данных Athena, используйте следующую команду AWS CLI:
Если команда выполнена успешно, вы сможете получить доступ к каталогу данных и таблицам Athena непосредственно из браузера SQL в своем блокноте SageMaker Studio JupyterLab.
Запрос данных из нескольких источников
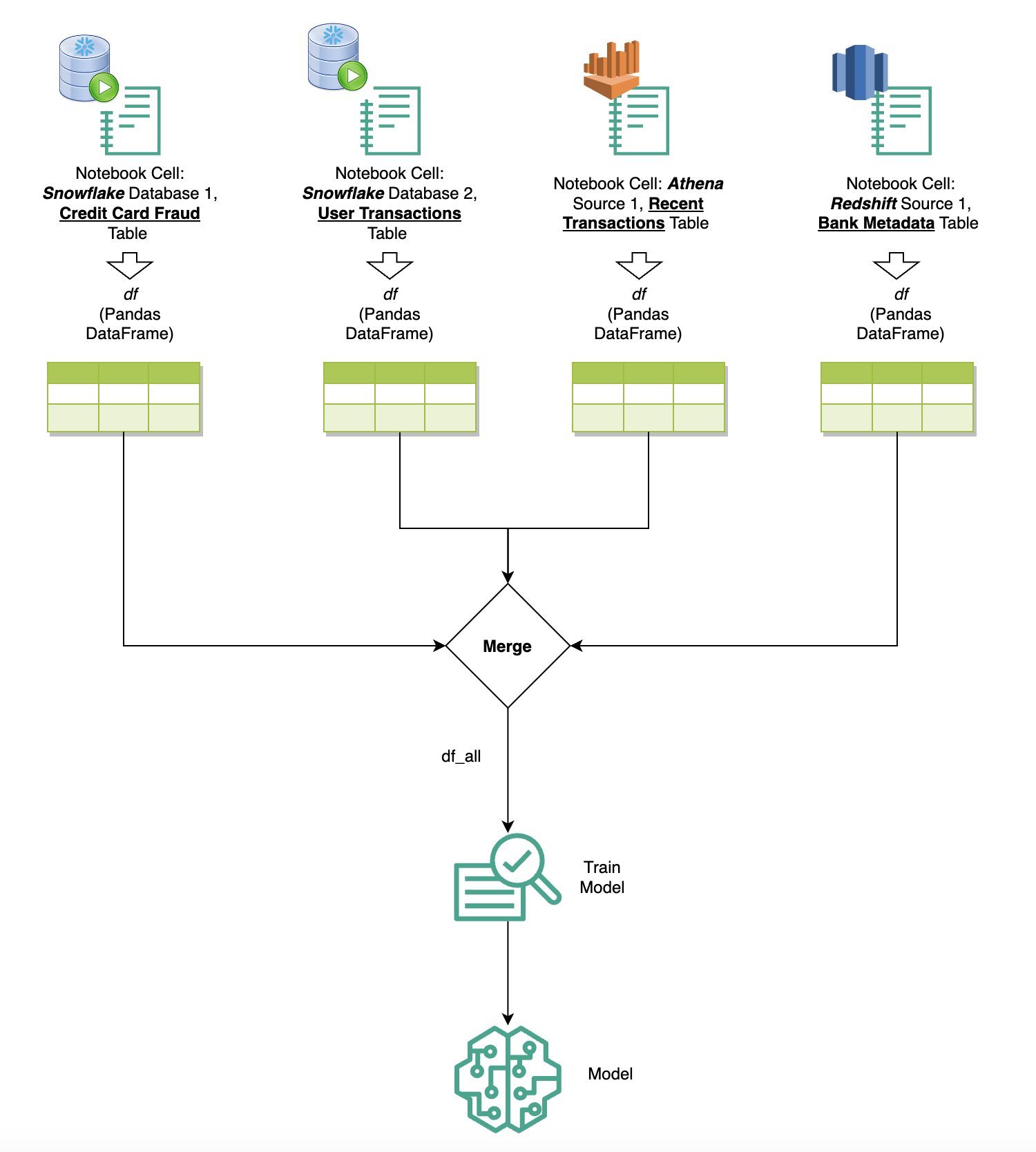
Если у вас есть несколько источников данных, интегрированных в SageMaker Studio через встроенный браузер SQL и функцию SQL записной книжки, вы можете быстро выполнять запросы и легко переключаться между серверными модулями источников данных в последующих ячейках записной книжки. Эта возможность обеспечивает плавный переход между различными базами данных или источниками данных во время рабочего процесса анализа.
Вы можете выполнять запросы к разнообразной коллекции серверных источников данных и переносить результаты непосредственно в пространство Python для дальнейшего анализа или визуализации. Этому способствует %%sm_sql волшебная команда доступна в блокнотах SageMaker Studio. Чтобы вывести результаты вашего SQL-запроса в DataFrame pandas, есть два варианта:
- На панели инструментов ячейки записной книжки выберите тип вывода. DataFrame и назовите свою переменную DataFrame
- Добавьте следующий параметр в свой
%%sm_sqlкоманда:
На следующей диаграмме показан этот рабочий процесс и показано, как можно легко выполнять запросы к различным источникам в последующих ячейках записной книжки, а также обучать модель SageMaker с помощью обучающих заданий или непосредственно в записной книжке с использованием локальных вычислений. Кроме того, на диаграмме показано, как встроенная интеграция SageMaker Studio с SQL упрощает процессы извлечения и построения непосредственно в знакомой среде ячейки блокнота JupyterLab.
Текст в SQL: использование естественного языка для улучшения разработки запросов
SQL — сложный язык, требующий понимания баз данных, таблиц, синтаксиса и метаданных. Сегодня генеративный искусственный интеллект (ИИ) позволяет вам писать сложные SQL-запросы, не требуя глубоких знаний SQL. Развитие LLM существенно повлияло на генерацию SQL на основе обработки естественного языка (NLP), что позволяет создавать точные SQL-запросы на основе описаний естественного языка — метод, называемый Text-to-SQL. Однако важно признать существенные различия между человеческим языком и SQL. Человеческий язык иногда может быть двусмысленным или неточным, тогда как SQL структурирован, явен и однозначен. Преодоление этого разрыва и точное преобразование естественного языка в запросы SQL может представлять собой сложную задачу. При наличии соответствующих подсказок специалисты LLM могут помочь преодолеть этот разрыв, понимая смысл человеческого языка и соответствующим образом генерируя точные SQL-запросы.
С выпуском функции SQL-запросов в блокноте SageMaker Studio SageMaker Studio упрощает проверку баз данных и схем, а также создание, запуск и отладку SQL-запросов, даже не выходя из интегрированной среды разработки блокнота Jupyter. В этом разделе рассматривается, как возможности преобразования текста в SQL в расширенных LLM могут облегчить создание SQL-запросов с использованием естественного языка в блокнотах Jupyter. Мы используем передовую модель Text-to-SQL. defog/sqlcoder-7b-2 в сочетании с Jupyter AI, генеративным помощником искусственного интеллекта, специально разработанным для ноутбуков Jupyter, для создания сложных SQL-запросов на естественном языке. Используя эту продвинутую модель, мы можем легко и эффективно создавать сложные SQL-запросы, используя естественный язык, тем самым расширяя возможности SQL в ноутбуках.
Прототипирование ноутбука с помощью Hugging Face Hub
Чтобы начать прототипирование, вам необходимо следующее:
- Код GitHub – Код, представленный в этом разделе, доступен в следующих Репо GitHub и, ссылаясь на пример тетради.
- JupyterLab Пространство – Необходим доступ к пространству SageMaker Studio JupyterLab Space, поддерживаемому экземплярами на базе графического процессора. Для
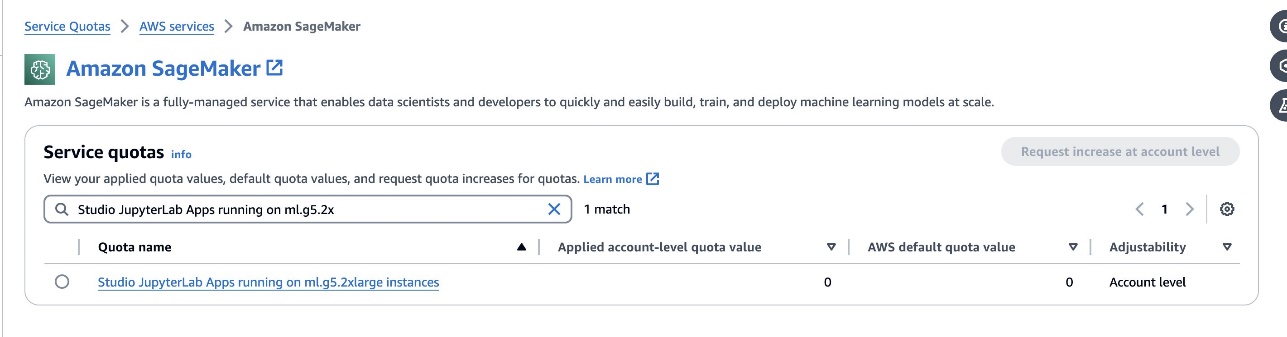
defog/sqlcoder-7b-2Модель рекомендуется использовать модель с параметрами 7B и экземпляром ml.g5.2xlarge. Альтернативы, такие какdefog/sqlcoder-70b-alphа илиdefog/sqlcoder-34b-alphaтакже пригодны для преобразования естественного языка в SQL, но для прототипирования могут потребоваться более крупные типы экземпляров. Убедитесь, что у вас есть квота для запуска экземпляра с поддержкой графического процессора. Для этого перейдите в консоль Service Quotas, выполните поиск SageMaker и выполните поискStudio JupyterLab Apps running on <instance type>.
Запустите новое пространство JupyterLab Space с поддержкой графического процессора из вашей студии SageMaker. Рекомендуется создать новое пространство JupyterLab с объемом памяти не менее 75 ГБ. Магазин эластичных блоков Amazon (Amazon EBS) хранилище для модели с параметрами 7B.

- Обниматься Face Hub – Если ваш домен SageMaker Studio имеет доступ к загрузке моделей из Обниматься Face Hub, вы можете использовать
AutoModelForCausalLMкласс от обнимающее лицо/трансформеры для автоматической загрузки моделей и закрепления их на локальных графических процессорах. Вес модели будет храниться в кеше вашего локального компьютера. См. следующий код:
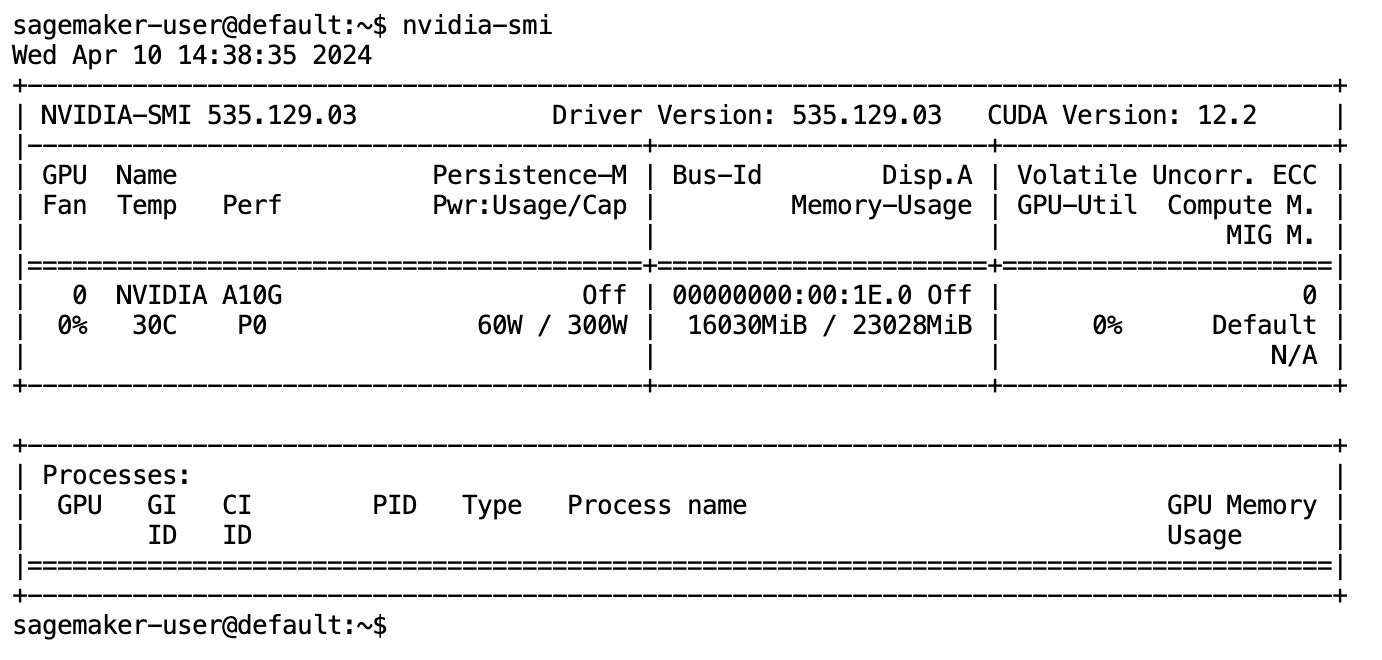
После того, как модель будет полностью загружена и загружена в память, вы должны заметить увеличение использования графического процессора на вашем локальном компьютере. Это указывает на то, что модель активно использует ресурсы графического процессора для вычислительных задач. Вы можете проверить это в своем собственном пространстве JupyterLab, запустив nvidia-smi (для одноразового показа) или nvidia-smi —loop=1 (повторять каждую секунду) с вашего терминала JupyterLab.
Модели преобразования текста в SQL превосходно понимают намерения и контекст запроса пользователя, даже если используемый язык является разговорным или неоднозначным. Этот процесс включает в себя перевод входных данных на естественном языке в правильные элементы схемы базы данных, такие как имена таблиц, имена столбцов и условия. Однако готовая модель преобразования текста в SQL по своей сути не будет знать структуру вашего хранилища данных, конкретные схемы базы данных или сможет точно интерпретировать содержимое таблицы, основываясь исключительно на именах столбцов. Чтобы эффективно использовать эти модели для создания практичных и эффективных SQL-запросов на естественном языке, необходимо адаптировать модель генерации текста SQL к вашей конкретной схеме базы данных хранилища. Эта адаптация осуществляется за счет использования LLM подсказки. Ниже приведен рекомендуемый шаблон приглашения для модели преобразования текста в SQL defog/sqlcoder-7b-2, разделенный на четыре части:
- Сложность задачи – В этом разделе должна быть указана задача высокого уровня, которую должна выполнить модель. Он должен включать тип серверной части базы данных (например, Amazon RDS, PostgreSQL или Amazon Redshift), чтобы модель учитывала любые нюансы синтаксических различий, которые могут повлиять на создание окончательного SQL-запроса.
- инструкции – В этом разделе должны быть определены границы задач и осведомленность о предметной области для модели, а также могут быть включены несколько примеров, которые помогут модели генерировать точно настроенные SQL-запросы.
- Схема базы данных – В этом разделе должны быть подробно описаны схемы базы данных хранилища, очерчены связи между таблицами и столбцами, чтобы помочь модели понять структуру базы данных.
- Ответ – Этот раздел зарезервирован для модели для вывода ответа на запрос SQL на ввод на естественном языке.
Пример схемы базы данных и приглашения, используемых в этом разделе, доступен в Репозиторий GitHub.
Оперативное проектирование – это не просто формулирование вопросов или утверждений; это тонкое искусство и наука, которые существенно влияют на качество взаимодействия с моделью ИИ. То, как вы создаете подсказку, может существенно повлиять на характер и полезность ответа ИИ. Этот навык имеет решающее значение для максимизации потенциала взаимодействия ИИ, особенно в сложных задачах, требующих специального понимания и подробных ответов.
Важно иметь возможность быстро построить и протестировать ответ модели на заданный запрос и оптимизировать запрос на основе ответа. Блокноты JupyterLab предоставляют возможность мгновенно получать обратную связь от модели, работающей на локальных вычислениях, оптимизировать подсказку и дополнительно настраивать ответ модели или полностью изменять модель. В этом посте мы используем ноутбук SageMaker Studio JupyterLab с графическим процессором NVIDIA A5.2G 10 ГБ ml.g24xlarge для выполнения вывода модели Text-to-SQL на ноутбуке и интерактивного построения приглашения модели до тех пор, пока ответ модели не будет достаточно настроен для обеспечения ответы, которые можно выполнить непосредственно в ячейках SQL JupyterLab. Чтобы выполнить вывод модели и одновременно выполнить потоковую передачу ответов модели, мы используем комбинацию model.generate и TextIteratorStreamer как определено в следующем коде:
Вывод модели можно украсить магией SageMaker SQL. %%sm_sql ..., что позволяет блокноту JupyterLab идентифицировать ячейку как ячейку SQL.
Размещение моделей преобразования текста в SQL в качестве конечных точек SageMaker
В конце этапа прототипирования мы выбрали предпочтительный LLM Text-to-SQL, эффективный формат подсказки и подходящий тип экземпляра для размещения модели (либо с одним графическим процессором, либо с несколькими графическими процессорами). SageMaker упрощает масштабируемое размещение пользовательских моделей за счет использования конечных точек SageMaker. Эти конечные точки могут быть определены в соответствии с конкретными критериями, что позволяет использовать LLM в качестве конечных точек. Эта возможность позволяет масштабировать решение для более широкой аудитории, позволяя пользователям генерировать SQL-запросы на основе входных данных на естественном языке с использованием пользовательских размещенных LLM. Следующая диаграмма иллюстрирует эту архитектуру.

Чтобы разместить свой LLM в качестве конечной точки SageMaker, вы создаете несколько артефактов.
Первый артефакт — это веса моделей. Обслуживание глубокой библиотеки Java SageMaker (DJL) контейнеры позволяют настраивать конфигурации через мета-файл. обслуживающие.свойства файл, который позволяет вам указать, как получать модели — либо непосредственно из Hugging Face Hub, либо путем загрузки артефактов модели с Amazon S3. Если вы укажете model_id=defog/sqlcoder-7b-2, DJL Serving попытается загрузить эту модель напрямую из Hugging Face Hub. Однако вы можете взимать плату за входящий/исходящий сетевой трафик каждый раз, когда конечная точка развертывается или эластично масштабируется. Чтобы избежать этих расходов и потенциально ускорить загрузку артефактов модели, рекомендуется пропустить использование model_id in serving.properties и сохранять веса модели как артефакты S3 и указывать их только с помощью s3url=s3://path/to/model/bin.
Сохранение модели (с ее токенизатором) на диск и загрузка ее на Amazon S3 можно выполнить всего с помощью нескольких строк кода:
Вы также используете файл подсказки базы данных. В этой настройке приглашение базы данных состоит из Task, Instructions, Database Schemaкачества Answer sections. Для текущей архитектуры мы выделяем отдельный файл подсказки для каждой схемы базы данных. Однако существует возможность расширить эту настройку, включив в нее несколько баз данных в файл приглашения, что позволяет модели выполнять составные соединения между базами данных на одном сервере. На этапе прототипирования мы сохраняем приглашение базы данных в виде текстового файла с именем <Database-Glue-Connection-Name>.prompt, Где Database-Glue-Connection-Name соответствует имени соединения, отображаемому в вашей среде JupyterLab. Например, этот пост относится к соединению Snowflake с именем Airlines_Dataset, поэтому файл приглашения базы данных называется Airlines_Dataset.prompt. Затем этот файл сохраняется на Amazon S3, а затем считывается и кэшируется нашей логикой обслуживания модели.
Более того, эта архитектура позволяет любым авторизованным пользователям этой конечной точки определять, хранить и генерировать запросы SQL на естественном языке без необходимости многократного повторного развертывания модели. Мы используем следующие пример запроса базы данных для демонстрации функциональности преобразования текста в SQL.
Далее вы создаете логику службы собственной модели. В этом разделе вы описываете пользовательскую логику вывода с именем модель.py. Этот скрипт предназначен для оптимизации производительности и интеграции наших сервисов преобразования текста в SQL:
- Определите логику кэширования файла подсказки базы данных. – Чтобы минимизировать задержку, мы реализуем специальную логику для загрузки и кэширования файлов подсказок базы данных. Этот механизм гарантирует, что подсказки будут легко доступны, сокращая накладные расходы, связанные с частыми загрузками.
- Определите логику вывода пользовательской модели – Чтобы повысить скорость вывода, наша модель преобразования текста в SQL загружается в формате точности float16, а затем преобразуется в модель DeepSpeed. Этот шаг позволяет провести более эффективные вычисления. Кроме того, в рамках этой логики вы указываете, какие параметры пользователи могут настраивать во время вызовов вывода, чтобы адаптировать функциональность в соответствии со своими потребностями.
- Определите пользовательскую логику ввода и вывода – Создание четких и настраиваемых форматов ввода/вывода имеет важное значение для плавной интеграции с последующими приложениями. Одним из таких приложений является JupyterAI, о котором мы поговорим в следующем разделе.
Кроме того, мы включаем serving.properties файл, который действует как файл глобальной конфигурации для моделей, размещенных с использованием службы DJL. Для получения дополнительной информации см. Конфигурации и настройки.
Наконец, вы также можете включить requirements.txt файл, чтобы определить дополнительные модули, необходимые для вывода, и упаковать все в архив для развертывания.
Смотрите следующий код:
Интегрируйте свою конечную точку с помощником искусственного интеллекта SageMaker Studio Jupyter.
Юпитер ИИ — это инструмент с открытым исходным кодом, который переносит генеративный искусственный интеллект в ноутбуки Jupyter и предлагает надежную и удобную платформу для изучения моделей генеративного искусственного интеллекта. Он повышает производительность в JupyterLab и блокнотах Jupyter, предоставляя такие функции, как магия %%ai для создания генеративной игровой площадки ИИ внутри блокнотов, собственный пользовательский интерфейс чата в JupyterLab для взаимодействия с ИИ в качестве диалогового помощника, а также поддержку широкого спектра LLM от такие поставщики, как Амазонка Титан, AI21, Anthropic, Cohere и Hugging Face или управляемые сервисы, такие как Коренная порода Амазонки и конечные точки SageMaker. В этом посте мы используем готовую интеграцию Jupyter AI с конечными точками SageMaker, чтобы реализовать возможность преобразования текста в SQL в блокноты JupyterLab. Инструмент Jupyter AI предварительно установлен во всех пространствах JupyterLab Spaces SageMaker Studio при поддержке Образы дистрибутива SageMaker; конечным пользователям не требуется выполнять какие-либо дополнительные настройки, чтобы начать использовать расширение Jupyter AI для интеграции с конечной точкой, размещенной на SageMaker. В этом разделе мы обсудим два способа использования интегрированного инструмента Jupyter AI.
Jupyter AI внутри ноутбука с помощью магии
Юпитер ИИ %%ai Команда Magic позволяет превратить блокноты JupyterLab SageMaker Studio в воспроизводимую генеративную среду искусственного интеллекта. Чтобы начать использовать магию ИИ, убедитесь, что вы загрузили расширение jupyter_ai_magics для использования. %%ai магия, и дополнительно загрузить amazon_sagemaker_sql_magic использовать %%sm_sql магия:
Чтобы выполнить вызов конечной точки SageMaker из записной книжки с помощью %%ai магическую команду, укажите следующие параметры и структурируйте команду следующим образом:
- –имя-региона – Укажите регион, в котором развернута ваша конечная точка. Это гарантирует, что запрос будет направлен в правильное географическое местоположение.
- --request-схема – Включить схему входных данных. Эта схема описывает ожидаемый формат и типы входных данных, которые необходимы вашей модели для обработки запроса.
- –путь-ответа – Определите путь внутри объекта ответа, где расположены выходные данные вашей модели. Этот путь используется для извлечения соответствующих данных из ответа, возвращаемого вашей моделью.
- -ф (необязательно) - Это форматировщик вывода флаг, указывающий тип выходных данных, возвращаемых моделью. В контексте блокнота Jupyter, если выходные данные представляют собой код, этот флаг должен быть установлен соответствующим образом для форматирования выходных данных как исполняемого кода в верхней части ячейки блокнота Jupyter, за которым следует область ввода свободного текста для взаимодействия с пользователем.
Например, команда в ячейке блокнота Jupyter может выглядеть следующим образом:
Окно чата Jupyter AI
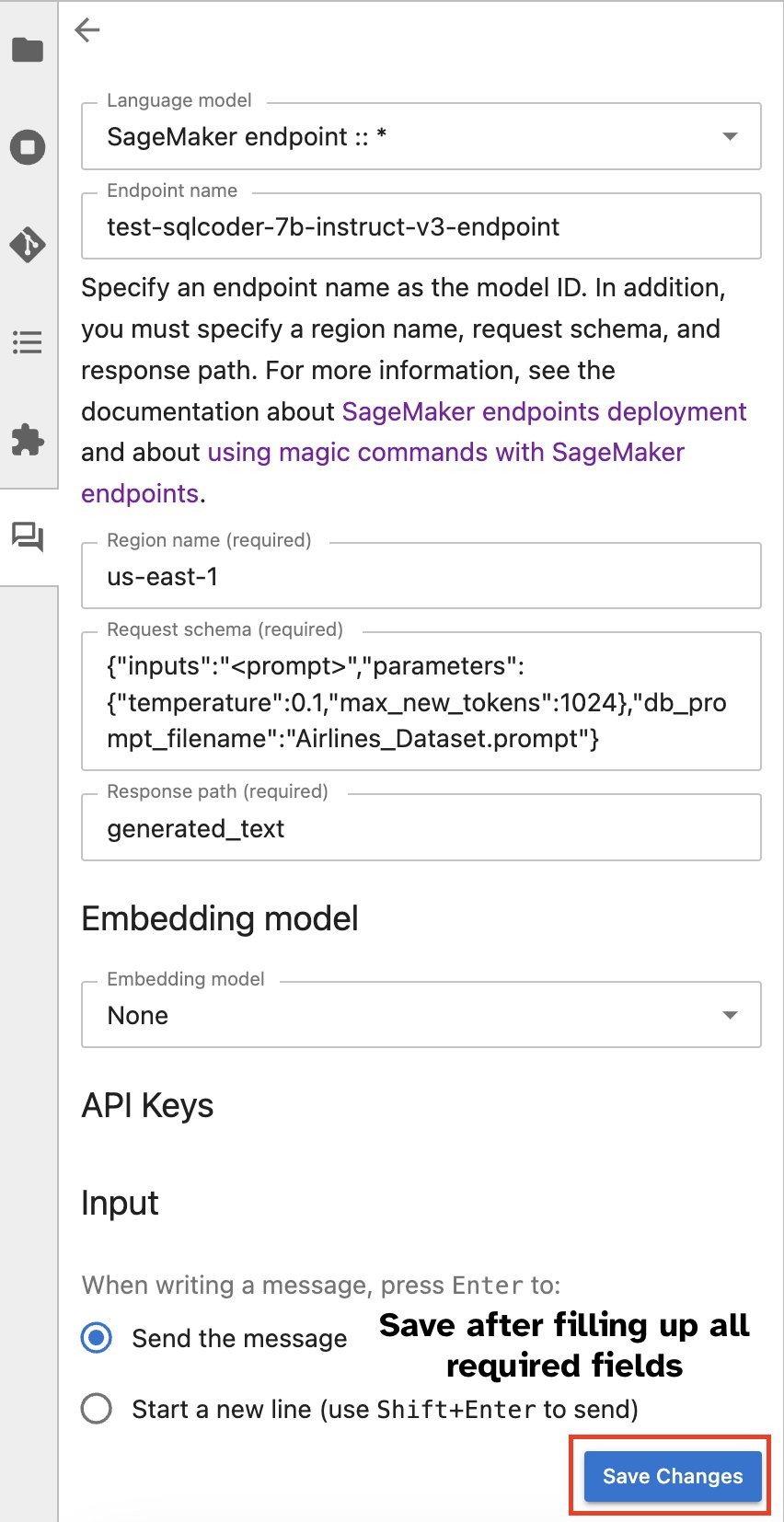
Альтернативно вы можете взаимодействовать с конечными точками SageMaker через встроенный пользовательский интерфейс, упрощая процесс создания запросов или участия в диалоге. Прежде чем начать общение с конечной точкой SageMaker, настройте соответствующие параметры в Jupyter AI для конечной точки SageMaker, как показано на следующем снимке экрана.
 |
 |
Заключение
SageMaker Studio теперь упрощает и оптимизирует рабочий процесс специалиста по данным, интегрируя поддержку SQL в блокноты JupyterLab. Это позволяет специалистам по данным сосредоточиться на своих задачах без необходимости управлять несколькими инструментами. Кроме того, новая встроенная интеграция SQL в SageMaker Studio позволяет специалистам по обработке данных легко генерировать SQL-запросы, используя в качестве входных данных текст на естественном языке, тем самым ускоряя рабочий процесс.
Мы рекомендуем вам изучить эти функции в SageMaker Studio. Для получения дополнительной информации см. Подготовьте данные с помощью SQL в Studio.
Приложение
Включите браузер SQL и ячейку SQL записной книжки в пользовательских средах.
Если вы не используете образ дистрибутива SageMaker или используете образы дистрибутива 1.5 или ниже, выполните следующие команды, чтобы включить функцию просмотра SQL в вашей среде JupyterLab:
Переместите виджет браузера SQL
Виджеты JupyterLab допускают перемещение. В зависимости от ваших предпочтений вы можете переместить виджеты в любую сторону панели виджетов JupyterLab. Если вы предпочитаете, вы можете переместить виджет SQL на противоположную сторону (справа налево) боковой панели, просто щелкнув правой кнопкой мыши значок виджета и выбрав Переключить боковую панель.
 |
 |
Об авторах
 Пранав Мурти — специалист по архитектуре решений AI/ML в AWS. Он специализируется на оказании помощи клиентам в создании, обучении, развертывании и переносе рабочих нагрузок машинного обучения (ML) в SageMaker. Ранее он работал в полупроводниковой промышленности, разрабатывая модели большого компьютерного зрения (CV) и обработки естественного языка (NLP) для улучшения полупроводниковых процессов с использованием современных методов машинного обучения. В свободное время любит играть в шахматы и путешествовать. Вы можете найти Пранав на LinkedIn.
Пранав Мурти — специалист по архитектуре решений AI/ML в AWS. Он специализируется на оказании помощи клиентам в создании, обучении, развертывании и переносе рабочих нагрузок машинного обучения (ML) в SageMaker. Ранее он работал в полупроводниковой промышленности, разрабатывая модели большого компьютерного зрения (CV) и обработки естественного языка (NLP) для улучшения полупроводниковых процессов с использованием современных методов машинного обучения. В свободное время любит играть в шахматы и путешествовать. Вы можете найти Пранав на LinkedIn.
 Варун Шах — инженер-программист, работающий над Amazon SageMaker Studio в Amazon Web Services. Он занимается созданием интерактивных решений машинного обучения, которые упрощают обработку и подготовку данных. В свободное время Варун любит активный отдых, в том числе пешие походы и катание на лыжах, и всегда готов открывать для себя новые интересные места.
Варун Шах — инженер-программист, работающий над Amazon SageMaker Studio в Amazon Web Services. Он занимается созданием интерактивных решений машинного обучения, которые упрощают обработку и подготовку данных. В свободное время Варун любит активный отдых, в том числе пешие походы и катание на лыжах, и всегда готов открывать для себя новые интересные места.
 Сумедха Свами является главным менеджером по продукту в Amazon Web Services, где он возглавляет команду SageMaker Studio в ее миссии по разработке предпочтительной среды разработки для анализа данных и машинного обучения. Последние 15 лет он посвятил созданию потребительских и корпоративных продуктов на основе машинного обучения.
Сумедха Свами является главным менеджером по продукту в Amazon Web Services, где он возглавляет команду SageMaker Studio в ее миссии по разработке предпочтительной среды разработки для анализа данных и машинного обучения. Последние 15 лет он посвятил созданию потребительских и корпоративных продуктов на основе машинного обучения.
 Боско Альбукерке является старшим архитектором партнерских решений в AWS и имеет более чем 20-летний опыт работы с базами данных и аналитическими продуктами от поставщиков корпоративных баз данных и облачных провайдеров. Он помогал технологическим компаниям разрабатывать и внедрять решения и продукты для анализа данных.
Боско Альбукерке является старшим архитектором партнерских решений в AWS и имеет более чем 20-летний опыт работы с базами данных и аналитическими продуктами от поставщиков корпоративных баз данных и облачных провайдеров. Он помогал технологическим компаниям разрабатывать и внедрять решения и продукты для анализа данных.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

