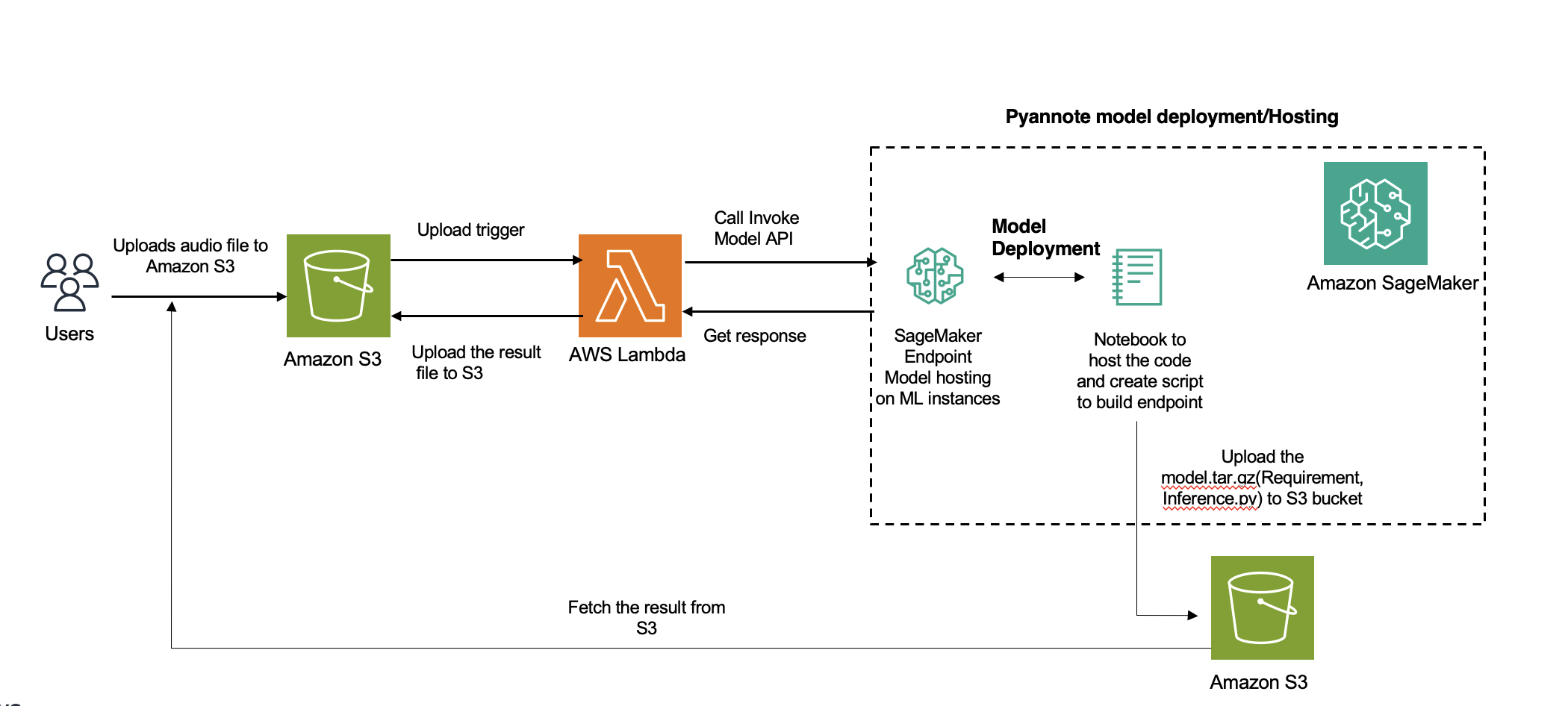
Диаризация говорящего, важный процесс аудиоанализа, сегментирует аудиофайл на основе личности говорящего. В этом посте рассматривается интеграция PyAnnote от Hugging Face для ведения дневника говорящих с Создатель мудреца Амазонки асинхронные конечные точки.
Мы предоставляем подробное руководство по развертыванию решений сегментации и кластеризации динамиков с помощью SageMaker в облаке AWS. Вы можете использовать это решение для приложений, работающих с аудиозаписями с несколькими динамиками (более 100).
Обзор решения
Amazon транскрибировать — это популярный сервис для дневникирования выступающих в AWS. Однако для неподдерживаемых языков вы можете использовать другие модели (в нашем случае PyAnnote), которые будут развернуты в SageMaker для вывода. Для коротких аудиофайлов, вывод которых занимает до 60 секунд, вы можете использовать вывод в реальном времени. В течение более 60 секунд асинхронный следует использовать умозаключение. Дополнительным преимуществом асинхронного вывода является экономия средств за счет автоматического масштабирования числа экземпляров до нуля, когда нет запросов для обработки.
Обнимая лицо — популярный центр с открытым исходным кодом для моделей машинного обучения (ML). У AWS и Hugging Face есть партнерство это обеспечивает плавную интеграцию SageMaker с набором контейнеров глубокого обучения (DLC) AWS для обучения и вывода в PyTorch или TensorFlow, а также с оценщиками и предикторами Hugging Face для SageMaker Python SDK. Функции и возможности SageMaker помогают разработчикам и специалистам по обработке данных с легкостью начать работу с обработкой естественного языка (NLP) на AWS.
Интеграция этого решения включает использование предварительно обученной модели диаризации говорящего Hugging Face с использованием Библиотека PyAnnote. PyAnnote — это набор инструментов с открытым исходным кодом, написанный на Python для ведения дневника докладчиков. Эта модель, обученная на примере набора аудиоданных, обеспечивает эффективное разделение динамиков в аудиофайлах. Модель развертывается в SageMaker в качестве асинхронной конечной точки, обеспечивая эффективную и масштабируемую обработку задач диаризации.
Для этого поста мы используем следующий аудиофайл.
Стерео или многоканальные аудиофайлы автоматически микшируются в моно путем усреднения каналов. Аудиофайлы, сэмплированные с другой частотой, автоматически преобразуются в 16 кГц при загрузке.
Убедитесь, что в учетной записи AWS имеется квота сервиса для размещения конечной точки SageMaker для экземпляра ml.g5.2xlarge.
Создайте функцию модели для доступа к дневнику говорящего PyAnnote из Hugging Face.
Вы можете использовать Hugging Face Hub для доступа к нужным предварительно обученным Модель диаризации докладчика PyAnnote. Тот же сценарий используется для загрузки файла модели при создании конечной точки SageMaker.
Смотрите следующий код:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
Упакуйте код модели
Подготовьте необходимые файлы, такие как inference.py, которые содержат код вывода:
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data[turn] = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=["start", "end", "speaker"])
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
Подготовить requirements.txt файл, который содержит необходимые библиотеки Python, необходимые для выполнения вывода:
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
Наконец, сожмите inference.py и требования.txt и сохраните их как model.tar.gz:
!tar zcvf model.tar.gz *
Настройка модели SageMaker
Определите ресурс модели SageMaker, указав URI изображения и расположение данных модели в Простой сервис хранения Amazon (S3) и роль SageMaker:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client("iam")
role = iam.get_role(RoleName="sagemaker_execution_role")["Role"]["Arn"]
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
Загрузите модель на Amazon S3.
Загрузите заархивированный файл модели PyAnnote Hugging Face в корзину S3:
Настройте асинхронную конечную точку для развертывания модели в SageMaker, используя предоставленную конфигурацию асинхронного вывода:
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
Проверьте конечную точку
Оцените функциональность конечной точки, отправив аудиофайл для диаризации и получив выходные данные JSON, хранящиеся в указанном пути вывода S3:
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
Для масштабного развертывания этого решения мы предлагаем использовать AWS Lambda, Amazon Простая служба уведомлений (Amazon SNS) или Простой сервис очередей Amazon (Амазонка SQS). Эти сервисы предназначены для масштабируемости, архитектуры, управляемой событиями, и эффективного использования ресурсов. Они могут помочь отделить процесс асинхронного вывода от обработки результатов, позволяя масштабировать каждый компонент независимо и более эффективно обрабатывать пакеты запросов на вывод.
Итоги
Вывод модели сохраняется по адресу s3://sagemaker-xxxx /async_inference/output/. Вывод показывает, что аудиозапись была разделена на три столбца:
Старт (время начала в секундах)
Конец (время окончания в секундах)
Динамик (маркировка динамика)
Следующий код показывает пример наших результатов:
Вы можете установить нулевую политику масштабирования, задав для MinCapacity значение 0; асинхронный вывод позволяет автоматически масштабировать до нуля без каких-либо запросов. Вам не нужно удалять конечную точку, она Весы с нуля, когда это необходимо снова, сокращая затраты, когда они не используются. См. следующий код:
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
Если вы хотите удалить конечную точку, используйте следующий код:
Решение может эффективно обрабатывать несколько или большие аудиофайлы.
В этом примере для демонстрации используется один экземпляр. Если вы хотите использовать это решение для сотен или тысяч видео и использовать асинхронную конечную точку для обработки нескольких экземпляров, вы можете использовать политика автоматического масштабирования, который рассчитан на большое количество исходных документов. Автоматическое масштабирование динамически регулирует количество экземпляров, предоставляемых для модели, в ответ на изменения рабочей нагрузки.
Решение оптимизирует ресурсы и снижает нагрузку на систему, отделяя длительные задачи от вывода в реальном времени.
Заключение
В этом посте мы представили простой подход к развертыванию модели диалога говорящего Hugging Face в SageMaker с использованием сценариев Python. Использование асинхронной конечной точки обеспечивает эффективные и масштабируемые средства для предоставления прогнозов диаризации как услуги, беспрепятственно обрабатывая одновременные запросы.
Начните сегодня с асинхронной записи динамиков для ваших аудиопроектов. Если у вас есть какие-либо вопросы по поводу запуска и запуска собственной конечной точки асинхронного диаризации, обращайтесь в комментарии.
Об авторах
Санджай Тивари — специалист по архитектуре решений AI/ML, который проводит свое время, работая со стратегическими клиентами, чтобы определить бизнес-требования, проводить сеансы L300 для конкретных случаев использования и разрабатывать приложения и услуги AI/ML, которые являются масштабируемыми, надежными и производительными. Он помог запустить и масштабировать сервис Amazon SageMaker на базе искусственного интеллекта и машинного обучения и реализовал несколько проверок концепции с использованием сервисов Amazon AI. Он также разработал платформу расширенной аналитики в рамках процесса цифровой трансформации.
Киран Чаллапалли — разработчик глубоких технологий в государственном секторе AWS. У него более 8 лет опыта работы в области искусственного интеллекта и машинного обучения и 23 года общего опыта разработки и продаж программного обеспечения. Киран помогает предприятиям государственного сектора по всей Индии исследовать и совместно создавать облачные решения, использующие технологии искусственного интеллекта, машинного обучения и генеративного искусственного интеллекта, включая большие языковые модели.

 Санджай Тивари — специалист по архитектуре решений AI/ML, который проводит свое время, работая со стратегическими клиентами, чтобы определить бизнес-требования, проводить сеансы L300 для конкретных случаев использования и разрабатывать приложения и услуги AI/ML, которые являются масштабируемыми, надежными и производительными. Он помог запустить и масштабировать сервис Amazon SageMaker на базе искусственного интеллекта и машинного обучения и реализовал несколько проверок концепции с использованием сервисов Amazon AI. Он также разработал платформу расширенной аналитики в рамках процесса цифровой трансформации.
Санджай Тивари — специалист по архитектуре решений AI/ML, который проводит свое время, работая со стратегическими клиентами, чтобы определить бизнес-требования, проводить сеансы L300 для конкретных случаев использования и разрабатывать приложения и услуги AI/ML, которые являются масштабируемыми, надежными и производительными. Он помог запустить и масштабировать сервис Amazon SageMaker на базе искусственного интеллекта и машинного обучения и реализовал несколько проверок концепции с использованием сервисов Amazon AI. Он также разработал платформу расширенной аналитики в рамках процесса цифровой трансформации. Киран Чаллапалли — разработчик глубоких технологий в государственном секторе AWS. У него более 8 лет опыта работы в области искусственного интеллекта и машинного обучения и 23 года общего опыта разработки и продаж программного обеспечения. Киран помогает предприятиям государственного сектора по всей Индии исследовать и совместно создавать облачные решения, использующие технологии искусственного интеллекта, машинного обучения и генеративного искусственного интеллекта, включая большие языковые модели.
Киран Чаллапалли — разработчик глубоких технологий в государственном секторе AWS. У него более 8 лет опыта работы в области искусственного интеллекта и машинного обучения и 23 года общего опыта разработки и продаж программного обеспечения. Киран помогает предприятиям государственного сектора по всей Индии исследовать и совместно создавать облачные решения, использующие технологии искусственного интеллекта, машинного обучения и генеративного искусственного интеллекта, включая большие языковые модели.
