Сегодня клиенты всех отраслей — будь то финансовые услуги, здравоохранение и биологические науки, путешествия и гостиничный бизнес, средства массовой информации и развлечения, телекоммуникации, программное обеспечение как услуга (SaaS) и даже поставщики проприетарных моделей — используют большие языковые модели (LLM) для создавайте приложения, такие как чат-боты вопросов и ответов (QnA), поисковые системы и базы знаний. Эти генеративный ИИ приложения не только используются для автоматизации существующих бизнес-процессов, но и способны трансформировать опыт клиентов, использующих эти приложения. Благодаря достижениям, достигнутым с помощью LLM, таких как Микстрал-8х7Б Инструкция, производное от таких архитектур, как смесь экспертов (МО)Клиенты постоянно ищут способы повышения производительности и точности генеративных приложений искусственного интеллекта, позволяя им эффективно использовать более широкий спектр моделей с закрытым и открытым исходным кодом.
Для повышения точности и производительности результатов LLM обычно используется ряд методов, например, точная настройка с помощью эффективная точная настройка параметров (PEFT), обучение с подкреплением на основе обратной связи с человеком (RLHF), и выполнение дистилляция знаний. Однако при создании генеративных приложений ИИ вы можете использовать альтернативное решение, которое позволяет динамически включать внешние знания и контролировать информацию, используемую для генерации, без необходимости точной настройки существующей базовой модели. Именно здесь на помощь приходит извлекающая дополненная генерация (RAG), особенно для генеративных приложений искусственного интеллекта, в отличие от более дорогих и надежных альтернатив точной настройки, которые мы обсуждали. Если вы внедряете сложные приложения RAG в свои повседневные задачи, вы можете столкнуться с общими проблемами с вашими системами RAG, такими как неточный поиск, увеличение размера и сложности документов, а также переполнение контекста, что может существенно повлиять на качество и надежность сгенерированных ответов. .
В этом посте обсуждаются шаблоны RAG для повышения точности ответа с использованием LangChain и таких инструментов, как средство извлечения родительских документов, а также такие методы, как контекстное сжатие, чтобы дать разработчикам возможность улучшить существующие генеративные приложения ИИ.
Обзор решения
В этом посте мы демонстрируем использование генерации текста Instruct Mixtral-8x7B в сочетании с моделью внедрения BGE Large En для эффективного построения системы RAG QnA на блокноте Amazon SageMaker с использованием инструмента извлечения родительских документов и техники контекстного сжатия. На следующей диаграмме показана архитектура этого решения.
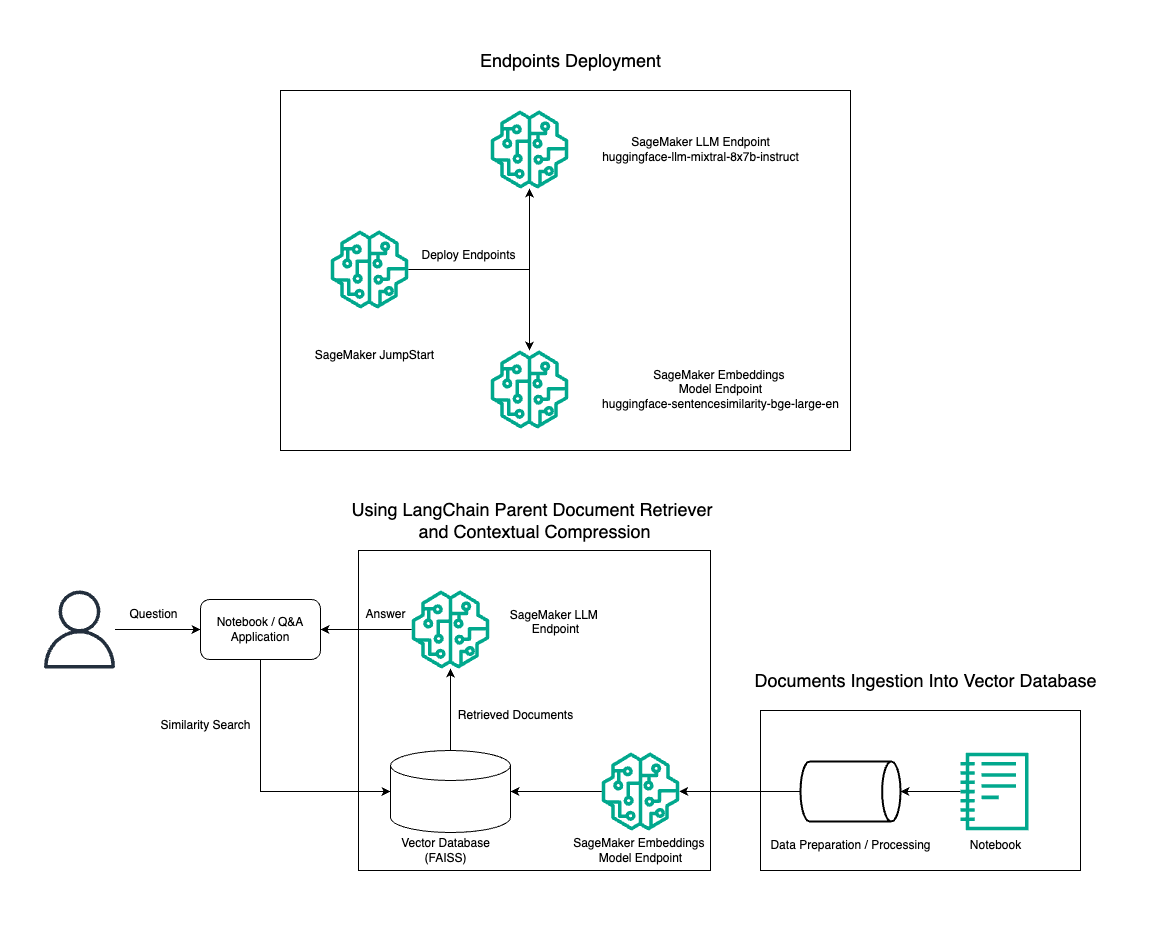
Вы можете развернуть это решение всего за несколько кликов, используя Amazon SageMaker JumpStart, полностью управляемой платформы, предлагающей самые современные базовые модели для различных вариантов использования, таких как написание контента, генерация кода, ответы на вопросы, копирайтинг, обобщение, классификация и поиск информации. Он предоставляет коллекцию предварительно обученных моделей, которые можно быстро и легко развернуть, ускоряя разработку и развертывание приложений машинного обучения (ML). Одним из ключевых компонентов SageMaker JumpStart является Model Hub, который предлагает обширный каталог предварительно обученных моделей, таких как Mixtral-8x7B, для различных задач.
Mixtral-8x7B использует архитектуру MoE. Эта архитектура позволяет различным частям нейронной сети специализироваться на разных задачах, эффективно распределяя рабочую нагрузку между несколькими экспертами. Такой подход позволяет эффективно обучать и развертывать более крупные модели по сравнению с традиционными архитектурами.
Одним из основных преимуществ архитектуры MoE является ее масштабируемость. Распределяя рабочую нагрузку между несколькими экспертами, модели MoE можно обучать на более крупных наборах данных и достигать более высокой производительности, чем традиционные модели того же размера. Кроме того, модели MoE могут быть более эффективными во время вывода, поскольку для получения заданных входных данных необходимо активировать только подмножество экспертов.
Дополнительную информацию об инструкции Mixtral-8x7B на AWS см. Mixtral-8x7B теперь доступен в Amazon SageMaker JumpStart. Модель Mixtral-8x7B доступна по разрешительной лицензии Apache 2.0 для использования без ограничений.
В этом посте мы обсудим, как вы можете использовать Лангчейн для создания эффективных и более действенных приложений RAG. LangChain — это библиотека Python с открытым исходным кодом, предназначенная для создания приложений с помощью LLM. Он обеспечивает модульную и гибкую структуру для объединения LLM с другими компонентами, такими как базы знаний, поисковые системы и другие инструменты искусственного интеллекта, для создания мощных и настраиваемых приложений.
Мы рассмотрим создание конвейера RAG в SageMaker с помощью Mixtral-8x7B. Мы используем модель генерации текста Instruct Mixtral-8x7B с моделью внедрения BGE Large En для создания эффективной системы QnA с использованием RAG на блокноте SageMaker. Мы используем экземпляр ml.t3.medium для демонстрации развертывания LLM через SageMaker JumpStart, доступ к которому можно получить через конечную точку API, созданную SageMaker. Эта установка позволяет исследовать, экспериментировать и оптимизировать передовые методы RAG с помощью LangChain. Мы также иллюстрируем интеграцию хранилища внедрений FAISS в рабочий процесс RAG, подчеркивая его роль в хранении и извлечении внедрений для повышения производительности системы.
Выполняем краткое описание блокнота SageMaker. Более подробные и пошаговые инструкции см. Расширенные шаблоны RAG с Mixtral в репозитории SageMaker Jumpstart на GitHub.
Потребность в расширенных шаблонах RAG
Расширенные шаблоны RAG необходимы для улучшения текущих возможностей LLM в обработке, понимании и создании текста, подобного человеческому. По мере увеличения размера и сложности документов представление нескольких аспектов документа в одном внедрении может привести к потере специфичности. Хотя важно уловить общую суть документа, не менее важно распознавать и представлять различные его подконтексты. Это проблема, с которой вы часто сталкиваетесь при работе с большими документами. Еще одна проблема с RAG заключается в том, что при извлечении вы не знаете о конкретных запросах, которые ваша система хранения документов будет обрабатывать при приеме. Это может привести к тому, что информация, наиболее релевантная для запроса, будет скрыта под текстом (переполнение контекста). Чтобы уменьшить количество сбоев и улучшить существующую архитектуру RAG, вы можете использовать расширенные шаблоны RAG (поиск родительских документов и контекстное сжатие), чтобы уменьшить количество ошибок при поиске, повысить качество ответов и обеспечить обработку сложных вопросов.
С помощью методов, обсуждаемых в этом посте, вы можете решить ключевые проблемы, связанные с поиском и интеграцией внешних знаний, позволяя вашему приложению предоставлять более точные и контекстно-зависимые ответы.
В следующих разделах мы рассмотрим, как средства извлечения родительских документов и контекстное сжатие может помочь вам справиться с некоторыми проблемами, которые мы обсуждали.
Средство извлечения родительских документов
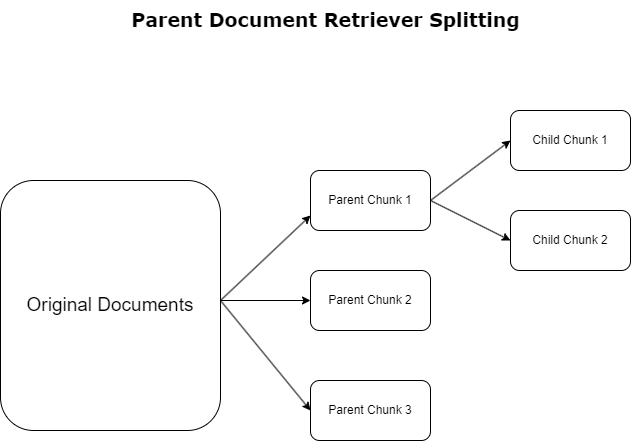
В предыдущем разделе мы выделили проблемы, с которыми сталкиваются приложения RAG при работе с обширными документами. Чтобы решить эти проблемы, средства извлечения родительских документов классифицировать и обозначать входящие документы как родительские документы. Эти документы известны своим всеобъемлющим характером, но не используются напрямую в исходной форме для встраивания. Вместо того, чтобы сжимать весь документ в одно вложение, средства извлечения родительских документов разбивают эти родительские документы на дочерние документы. Каждый дочерний документ отражает отдельные аспекты или темы более широкого родительского документа. После идентификации этих дочерних сегментов каждому из них присваиваются отдельные вложения, отражающие их конкретную тематическую сущность (см. следующую диаграмму). Во время извлечения вызывается родительский документ. Этот метод обеспечивает целевые, но широкие возможности поиска, предоставляя LLM более широкую перспективу. Средства извлечения родительских документов предоставляют LLM двойное преимущество: специфичность вложений дочерних документов для точного и релевантного поиска информации в сочетании с вызовом родительских документов для генерации ответов, что обогащает выходные данные LLM многоуровневым и детальным контекстом.
Контекстное сжатие
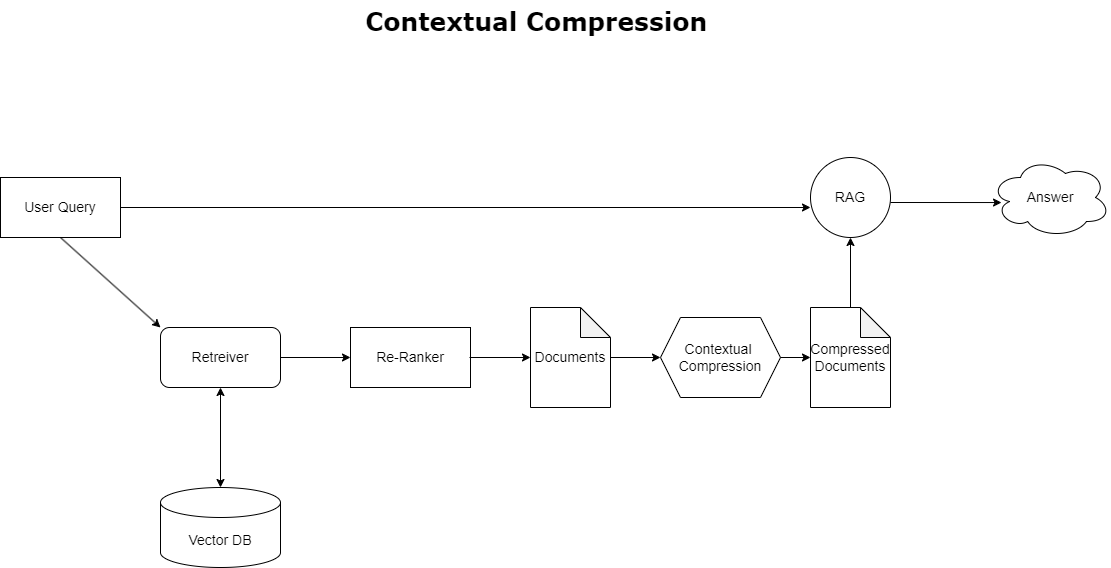
Чтобы решить проблему переполнения контекста, обсуждавшуюся ранее, вы можете использовать контекстное сжатие для сжатия и фильтрации полученных документов в соответствии с контекстом запроса, чтобы сохранялась и обрабатывалась только соответствующая информация. Это достигается за счет комбинации базового средства извлечения документов для первоначальной выборки документов и компрессора документов для уточнения этих документов путем сокращения их содержимого или полного исключения их на основе релевантности, как показано на следующей диаграмме. Этот оптимизированный подход, поддерживаемый средством контекстного сжатия, значительно повышает эффективность приложений RAG, предоставляя метод извлечения и использования только самого важного из массы информации. Он решает проблему информационной перегрузки и ненужной обработки данных, что приводит к повышению качества ответов, более экономичным операциям LLM и более плавному общему процессу поиска. По сути, это фильтр, который адаптирует информацию к текущему запросу, что делает его столь необходимым инструментом для разработчиков, стремящихся оптимизировать свои приложения RAG для повышения производительности и удовлетворенности пользователей.
Предпосылки
Если вы новичок в SageMaker, обратитесь к Руководство по разработке Amazon SageMaker.
Прежде чем приступить к решению, создать учетную запись AWS. Создавая учетную запись AWS, вы получаете удостоверение единого входа (SSO), которое имеет полный доступ ко всем сервисам и ресурсам AWS в учетной записи. Это удостоверение называется учетной записью AWS. пользователь root.
Вход в Консоль управления AWS использование адреса электронной почты и пароля, которые вы использовали для создания учетной записи, дает вам полный доступ ко всем ресурсам AWS в вашей учетной записи. Мы настоятельно рекомендуем вам не использовать пользователя root для повседневных задач, даже административных.
Вместо этого придерживайтесь лучшие практики безопасности in Управление идентификацией и доступом AWS (ИАМ) и создать административного пользователя и группу. Затем надежно заблокируйте учетные данные пользователя root и используйте их только для выполнения нескольких задач по управлению учетными записями и службами.
Для модели Mixtral-8x7b требуется экземпляр ml.g5.48xlarge. SageMaker JumpStart предоставляет упрощенный способ доступа и развертывания более 100 различных базовых моделей с открытым исходным кодом и сторонних производителей. Для того, чтобы запустить конечную точку для размещения Mixtral-8x7B из SageMaker JumpStart, вам может потребоваться запросить увеличение квоты службы для доступа к экземпляру ml.g5.48xlarge для использования в конечной точке. Ты можешь запросить увеличение квоты на обслуживание через консоль, Интерфейс командной строки AWS (AWS CLI) или API, чтобы разрешить доступ к этим дополнительным ресурсам.
Настройте экземпляр блокнота SageMaker и установите зависимости.
Для начала создайте экземпляр блокнота SageMaker и установите необходимые зависимости. Обратитесь к Репо GitHub чтобы обеспечить успешную настройку. После настройки экземпляра блокнота вы можете развернуть модель.
Вы также можете запустить блокнот локально в предпочитаемой вами интегрированной среде разработки (IDE). Убедитесь, что у вас установлена лаборатория Jupyter Notebook.
Развернуть модель
Разверните модель Instruct LLM Mixtral-8X7B в SageMaker JumpStart:
Разверните модель внедрения BGE Large En в SageMaker JumpStart:
Настроить Лангчейн
После импорта всех необходимых библиотек и развертывания модели Mixtral-8x7B и модели внедрения BGE Large En вы можете настроить LangChain. Пошаговые инструкции см. Репо GitHub.
Подготовка данных
В этом посте мы используем письма Amazon акционерам за несколько лет в качестве корпуса текстов для проведения QnA. Более подробные инструкции по подготовке данных см. Репо GitHub.
Ответ на вопрос
После подготовки данных вы можете использовать оболочку, предоставляемую LangChain, которая оборачивает хранилище векторов и принимает входные данные для LLM. Эта оболочка выполняет следующие шаги:
- Возьмите входной вопрос.
- Создайте встраивание вопроса.
- Получите соответствующие документы.
- Включите документы и вопрос в подсказку.
- Вызовите модель с помощью подсказки и сгенерируйте ответ в читаемой форме.
Теперь, когда векторное хранилище готово, вы можете начать задавать вопросы:
Обычная цепь ретривера
В предыдущем сценарии мы рассмотрели быстрый и простой способ получить контекстно-зависимый ответ на ваш вопрос. Теперь давайте рассмотрим более настраиваемый вариант с помощью RetrivalQA, где вы можете настроить способ добавления полученных документов в приглашение с помощью параметра Chain_type. Кроме того, чтобы контролировать, сколько соответствующих документов должно быть получено, вы можете изменить параметр k в следующем коде, чтобы увидеть различные выходные данные. Во многих случаях вам может потребоваться узнать, какие исходные документы LLM использовал для получения ответа. Вы можете получить эти документы на выходе, используя return_source_documents, который возвращает документы, добавленные в контекст приглашения LLM. RetrivalQA также позволяет вам предоставить собственный шаблон подсказки, который может быть специфичным для модели.
Давайте зададим вопрос:
Цепочка получения родительских документов
Давайте рассмотрим более продвинутый вариант RAG с помощью РодительскийДокументРетривер. При работе с поиском документов вы можете столкнуться с компромиссом между хранением небольших фрагментов документа для точного внедрения и более крупными документами для сохранения большего количества контекста. Средство извлечения родительских документов обеспечивает этот баланс, разделяя и сохраняя небольшие фрагменты данных.
Мы используем parent_splitter разделить исходные документы на более крупные части, называемые родительскими документами, и child_splitter для создания дочерних документов меньшего размера из исходных документов:
Дочерние документы затем индексируются в векторном хранилище с использованием внедрений. Это обеспечивает эффективный поиск соответствующих дочерних документов на основе сходства. Чтобы получить соответствующую информацию, средство извлечения родительских документов сначала извлекает дочерние документы из векторного хранилища. Затем он ищет родительские идентификаторы для этих дочерних документов и возвращает соответствующие родительские документы большего размера.
Давайте зададим вопрос:
Контекстная цепочка сжатия
Давайте посмотрим на еще один расширенный вариант RAG под названием контекстное сжатие. Одна из проблем извлечения данных заключается в том, что обычно мы не знаем, с какими конкретными запросами столкнется ваша система хранения документов при загрузке данных в систему. Это означает, что информация, наиболее релевантная запросу, может быть скрыта в документе с большим количеством нерелевантного текста. Передача этого полного документа через ваше приложение может привести к более дорогим звонкам в LLM и худшим ответам.
Средство извлечения контекстного сжатия решает задачу извлечения соответствующей информации из системы хранения документов, где соответствующие данные могут быть скрыты внутри документов, содержащих много текста. Путем сжатия и фильтрации полученных документов на основе заданного контекста запроса возвращается только самая релевантная информация.
Чтобы использовать средство извлечения контекстного сжатия, вам понадобится:
- Базовый ретривер – Это первоначальный поисковик, который извлекает документы из системы хранения на основе запроса.
- Компрессор документов – Этот компонент берет первоначально полученные документы и сокращает их, сокращая содержимое отдельных документов или полностью удаляя ненужные документы, используя контекст запроса для определения релевантности.
Добавление контекстного сжатия с помощью экстрактора цепочки LLM
Сначала оберните вашего базового ретривера ContextualCompressionRetriever. Вы добавите LLMChainExtractor, который будет перебирать первоначально возвращенные документы и извлекать из каждого только то содержимое, которое имеет отношение к запросу.
Инициализируйте цепочку, используя ContextualCompressionRetriever с LLMChainExtractor и передайте приглашение через chain_type_kwargs аргумент.
Давайте зададим вопрос:
Фильтруйте документы с помощью цепного фильтра LLM
Ассоциация LLMChainFilter — это немного более простой, но более надежный компрессор, который использует цепочку LLM для принятия решения, какие из первоначально полученных документов отфильтровать, а какие вернуть, не манипулируя содержимым документа:
Инициализируйте цепочку, используя ContextualCompressionRetriever с LLMChainFilter и передайте приглашение через chain_type_kwargs аргумент.
Давайте зададим вопрос:
Сравнить результаты
В следующей таблице сравниваются результаты различных запросов в зависимости от техники.
| Техника | Запрос 1 | Запрос 2 | сравнение |
| Как развивалась AWS? | Почему Amazon успешен? | ||
| Обычный выход цепи ретривера | AWS (Amazon Web Services) превратилась из первоначально нерентабельной инвестиции в бизнес с годовым доходом в 85 миллиардов долларов, обладающий высокой прибыльностью, предлагающий широкий спектр услуг и функций и становящийся значительной частью портфеля Amazon. Несмотря на скептицизм и краткосрочные препятствия, AWS продолжала внедрять инновации, привлекать новых клиентов и мигрировать активных клиентов, предлагая такие преимущества, как гибкость, инновации, экономическая эффективность и безопасность. AWS также расширила свои долгосрочные инвестиции, включая разработку чипов, чтобы предоставить новые возможности и изменить возможности своих клиентов. | Amazon добилась успеха благодаря постоянным инновациям и расширению в новых областях, таких как услуги технологической инфраструктуры, цифровые устройства чтения, персональные помощники с голосовым управлением и новые бизнес-модели, такие как сторонний рынок. Его способность быстро масштабировать операции, о чем свидетельствует быстрое расширение сети выполнения заказов и транспортировки, также способствует его успеху. Кроме того, внимание Amazon к оптимизации и повышению эффективности своих процессов привело к повышению производительности и снижению затрат. Пример Amazon Business подчеркивает способность компании использовать свои сильные стороны в области электронной коммерции и логистики в различных секторах. | Основываясь на ответах обычной цепочки поиска, мы замечаем, что, хотя она и дает длинные ответы, она страдает от переполнения контекста и не может упомянуть какие-либо важные детали из корпуса, касающиеся ответа на предоставленный запрос. Обычная цепочка поиска не способна уловить нюансы с глубиной или контекстуальным пониманием, потенциально упуская важные аспекты документа. |
| Вывод родительского средства получения документов | AWS (Amazon Web Services) началась с первоначального запуска службы Elastic Compute Cloud (EC2) с ограниченными возможностями в 2006 году, предоставлявшей экземпляр только одного размера в одном центре обработки данных, в одном регионе мира и только с экземплярами операционной системы Linux. и без многих ключевых функций, таких как мониторинг, балансировка нагрузки, автоматическое масштабирование или постоянное хранилище. Однако успех AWS позволил им быстро выполнить итерацию и добавить недостающие возможности, в конечном итоге расширившись, чтобы предложить различные варианты, размеры и оптимизации вычислений, хранения и сети, а также разработать собственные чипы (Graviton) для дальнейшего повышения цены и производительности. . Итеративный инновационный процесс AWS потребовал значительных инвестиций в финансовые и человеческие ресурсы в течение 20 лет, часто задолго до того, как они окупятся, чтобы удовлетворить потребности клиентов и улучшить долгосрочное качество обслуживания клиентов, лояльность и прибыль для акционеров. | Amazon добился успеха благодаря своей способности постоянно внедрять инновации, адаптироваться к меняющимся рыночным условиям и удовлетворять потребности клиентов в различных сегментах рынка. Это очевидно в успехе Amazon Business, годовой валовой объем продаж которого вырос примерно на 35 миллиардов долларов США, обеспечивая выбор, ценность и удобство для бизнес-клиентов. Инвестиции Amazon в электронную коммерцию и логистику также позволили создать такие услуги, как Buy with Prime, которые помогают продавцам с веб-сайтами, ориентированными непосредственно на потребителя, повышать конверсию от просмотров к покупкам. | Средство извлечения родительских документов глубже вникает в специфику стратегии роста AWS, включая итеративный процесс добавления новых функций на основе отзывов клиентов и подробный путь от первоначального запуска с ограниченным набором функций до доминирующего положения на рынке, обеспечивая при этом контекстно-ориентированный ответ. . Ответы охватывают широкий спектр аспектов: от технических инноваций и рыночной стратегии до организационной эффективности и ориентации на клиента, предоставляя целостное представление о факторах, способствующих успеху, а также приводя примеры. Это можно объяснить целевыми, но широкими возможностями поиска родительского средства поиска документов. |
| LLM Chain Extractor: вывод контекстного сжатия | AWS развивалась, начиная с небольшого проекта внутри Amazon, требующего значительных капиталовложений и сталкивающегося со скептицизмом как внутри, так и за пределами компании. Однако AWS имела преимущество перед потенциальными конкурентами и верила в ценность, которую она может принести клиентам и Amazon. AWS взяла на себя долгосрочное обязательство продолжать инвестировать, в результате чего в 3,300 году было запущено более 2022 новых функций и сервисов. AWS изменила способы управления клиентами своей технологической инфраструктурой и стала бизнесом с годовым доходом в 85 миллиардов долларов и высокой рентабельностью. AWS также постоянно совершенствует свои предложения, например, расширяя EC2 дополнительными функциями и сервисами после его первого запуска. | Исходя из представленного контекста, успех Amazon можно объяснить ее стратегическим расширением от платформы для продажи книг до глобального рынка с динамичной экосистемой сторонних продавцов, ранними инвестициями в AWS, инновациями во внедрении Kindle и Alexa, а также значительным ростом. годового дохода с 2019 по 2022 год. Этот рост привел к расширению площади центров выполнения заказов, созданию транспортной сети последней мили и строительству новой сети сортировочных центров, которые были оптимизированы для повышения производительности и снижения затрат. | Экстрактор цепочки LLM поддерживает баланс между всесторонним освещением ключевых моментов и избежанием ненужной глубины. Он динамически адаптируется к контексту запроса, поэтому выходные данные являются непосредственно релевантными и всеобъемлющими. |
| Цепной фильтр LLM: вывод контекстного сжатия | AWS (Amazon Web Services) развивалась путем первоначального запуска малофункционального сервиса, но затем быстрых итераций на основе отзывов клиентов для добавления необходимых возможностей. Такой подход позволил AWS запустить EC2 в 2006 году с ограниченными функциями, а затем постоянно добавлять новые функции, такие как дополнительные размеры экземпляров, центры обработки данных, регионы, параметры операционной системы, инструменты мониторинга, балансировку нагрузки, автоматическое масштабирование и постоянное хранилище. Со временем AWS превратилась из малофункционального сервиса в бизнес с оборотом в несколько миллиардов долларов, сосредоточив внимание на потребностях клиентов, гибкости, инновациях, экономической эффективности и безопасности. В настоящее время AWS имеет годовой доход в размере 85 миллиардов долларов США и предлагает более 3,300 новых функций и услуг каждый год, обслуживая широкий круг клиентов — от стартапов до транснациональных компаний и организаций государственного сектора. | Amazon добилась успеха благодаря своим инновационным бизнес-моделям, постоянному технологическому прогрессу и стратегическим организационным изменениям. Компания постоянно меняет традиционные отрасли, внедряя новые идеи, такие как платформа электронной коммерции для различных продуктов и услуг, сторонний рынок, сервисы облачной инфраструктуры (AWS), электронная книга Kindle и личный помощник Alexa с голосовым управлением. . Кроме того, Amazon внесла структурные изменения для повышения своей эффективности, например, реорганизовала свою сеть выполнения заказов в США, чтобы снизить затраты и сроки доставки, что еще больше способствовало ее успеху. | Подобно экстрактору цепочки LLM, фильтр цепочки LLM гарантирует, что, несмотря на охват ключевых моментов, результат будет эффективным для клиентов, которые ищут краткие и контекстуальные ответы. |
Сравнивая эти различные методы, мы видим, что в таких контекстах, как подробное описание перехода AWS от простого сервиса к сложной организации с многомиллиардным оборотом или объяснение стратегических успехов Amazon, обычной цепочке извлечения не хватает точности, которую предлагают более сложные методы. что приводит к менее целевой информации. Хотя между обсуждаемыми продвинутыми методами видно очень мало различий, они гораздо более информативны, чем обычные ретриверные цепи.
Для клиентов из таких отраслей, как здравоохранение, телекоммуникации и финансовые услуги, которые хотят внедрить RAG в свои приложения, ограничения обычной цепочки извлечения в обеспечении точности, предотвращении избыточности и эффективном сжатии информации делают ее менее подходящей для удовлетворения этих потребностей по сравнению с к более продвинутым методам извлечения родительских документов и методам контекстного сжатия. Эти методы способны превратить огромные объемы информации в концентрированные и эффективные идеи, которые вам нужны, одновременно помогая улучшить соотношение цены и качества.
Убирать
Завершив работу с блокнотом, удалите созданные вами ресурсы, чтобы избежать начисления платы за используемые ресурсы:
Заключение
В этом посте мы представили решение, которое позволяет реализовать методы извлечения родительских документов и цепочки контекстного сжатия, чтобы расширить возможности LLM по обработке и генерации информации. Мы протестировали эти передовые методы RAG на моделях Mixtral-8x7B Instruct и BGE Large En, доступных с помощью SageMaker JumpStart. Мы также изучили возможность использования постоянного хранилища для встраивания и фрагментов документов, а также интеграцию с корпоративными хранилищами данных.
Методы, которые мы использовали, не только улучшают способ доступа к моделям LLM и включения внешних знаний, но также значительно улучшают качество, актуальность и эффективность их результатов. Сочетая извлечение из больших текстовых массивов с возможностями языковой генерации, эти передовые методы RAG позволяют специалистам LLM выдавать более фактические, последовательные и соответствующие контексту ответы, повышая их производительность при выполнении различных задач обработки естественного языка.
SageMaker JumpStart находится в центре этого решения. С помощью SageMaker JumpStart вы получаете доступ к обширному ассортименту моделей с открытым и закрытым исходным кодом, что упрощает процесс начала работы с машинным обучением и позволяет быстро экспериментировать и развертывать. Чтобы начать развертывание этого решения, перейдите к записной книжке в Репо GitHub.
Об авторах
 Ниитийн Виджеасваран — архитектор решений в AWS. Его сферой деятельности являются генеративный искусственный интеллект и ускорители искусственного интеллекта AWS. Он имеет степень бакалавра в области компьютерных наук и биоинформатики. Ниитийн тесно сотрудничает с командой Generative AI GTM, чтобы предоставить клиентам AWS возможности по нескольким направлениям и ускорить внедрение ими генеративного ИИ. Он страстный поклонник команды «Даллас Маверикс» и любит коллекционировать кроссовки.
Ниитийн Виджеасваран — архитектор решений в AWS. Его сферой деятельности являются генеративный искусственный интеллект и ускорители искусственного интеллекта AWS. Он имеет степень бакалавра в области компьютерных наук и биоинформатики. Ниитийн тесно сотрудничает с командой Generative AI GTM, чтобы предоставить клиентам AWS возможности по нескольким направлениям и ускорить внедрение ими генеративного ИИ. Он страстный поклонник команды «Даллас Маверикс» и любит коллекционировать кроссовки.
 Себастьян Бустильо — архитектор решений в AWS. Он специализируется на технологиях искусственного интеллекта и машинного обучения и питает глубокую страсть к генеративному искусственному интеллекту и ускорителям вычислений. В AWS он помогает клиентам раскрыть ценность бизнеса с помощью генеративного искусственного интеллекта. Когда он не на работе, ему нравится заваривать идеальную чашку фирменного кофе и исследовать мир вместе со своей женой.
Себастьян Бустильо — архитектор решений в AWS. Он специализируется на технологиях искусственного интеллекта и машинного обучения и питает глубокую страсть к генеративному искусственному интеллекту и ускорителям вычислений. В AWS он помогает клиентам раскрыть ценность бизнеса с помощью генеративного искусственного интеллекта. Когда он не на работе, ему нравится заваривать идеальную чашку фирменного кофе и исследовать мир вместе со своей женой.
 Армандо Диас — архитектор решений в AWS. Он специализируется на генеративном искусственном интеллекте, искусственном интеллекте и машинном обучении и аналитике данных. В AWS Армандо помогает клиентам интегрировать передовые возможности генеративного искусственного интеллекта в свои системы, способствуя инновациям и конкурентным преимуществам. Когда он не на работе, ему нравится проводить время с женой и семьей, ходить в походы и путешествовать по миру.
Армандо Диас — архитектор решений в AWS. Он специализируется на генеративном искусственном интеллекте, искусственном интеллекте и машинном обучении и аналитике данных. В AWS Армандо помогает клиентам интегрировать передовые возможности генеративного искусственного интеллекта в свои системы, способствуя инновациям и конкурентным преимуществам. Когда он не на работе, ему нравится проводить время с женой и семьей, ходить в походы и путешествовать по миру.
 Доктор Фарук Сабир является старшим специалистом по искусственному интеллекту и машинному обучению, архитектором решений в AWS. Он имеет степень доктора философии и магистра электротехники Техасского университета в Остине и степень магистра компьютерных наук Технологического института Джорджии. Он имеет более чем 15-летний опыт работы, а также любит учить и наставлять студентов колледжей. В AWS он помогает клиентам формулировать и решать их бизнес-задачи в области науки о данных, машинного обучения, компьютерного зрения, искусственного интеллекта, численной оптимизации и смежных областях. Живя в Далласе, штат Техас, он и его семья любят путешествовать и совершать длительные поездки.
Доктор Фарук Сабир является старшим специалистом по искусственному интеллекту и машинному обучению, архитектором решений в AWS. Он имеет степень доктора философии и магистра электротехники Техасского университета в Остине и степень магистра компьютерных наук Технологического института Джорджии. Он имеет более чем 15-летний опыт работы, а также любит учить и наставлять студентов колледжей. В AWS он помогает клиентам формулировать и решать их бизнес-задачи в области науки о данных, машинного обучения, компьютерного зрения, искусственного интеллекта, численной оптимизации и смежных областях. Живя в Далласе, штат Техас, он и его семья любят путешествовать и совершать длительные поездки.
 Марко Пунио — архитектор решений, специализирующийся на генеративной стратегии искусственного интеллекта, прикладных решениях искусственного интеллекта и проведении исследований, помогающих клиентам гипермасштабироваться на AWS. Марко — консультант по цифровым облакам с опытом работы в сфере финансовых технологий, здравоохранения и биологических наук, программного обеспечения как услуги, а с недавнего времени — в телекоммуникациях. Он квалифицированный технолог, увлекающийся машинным обучением, искусственным интеллектом, а также слияниями и поглощениями. Марко живет в Сиэтле, штат Вашингтон, и в свободное время любит писать, читать, заниматься спортом и создавать приложения.
Марко Пунио — архитектор решений, специализирующийся на генеративной стратегии искусственного интеллекта, прикладных решениях искусственного интеллекта и проведении исследований, помогающих клиентам гипермасштабироваться на AWS. Марко — консультант по цифровым облакам с опытом работы в сфере финансовых технологий, здравоохранения и биологических наук, программного обеспечения как услуги, а с недавнего времени — в телекоммуникациях. Он квалифицированный технолог, увлекающийся машинным обучением, искусственным интеллектом, а также слияниями и поглощениями. Марко живет в Сиэтле, штат Вашингтон, и в свободное время любит писать, читать, заниматься спортом и создавать приложения.
 Эй Джей Димин — архитектор решений в AWS. Он специализируется на генеративном искусственном интеллекте, бессерверных вычислениях и анализе данных. Он является активным членом/наставником сообщества технических специалистов по машинному обучению и опубликовал несколько научных статей по различным темам искусственного интеллекта и машинного обучения. Он работает с клиентами, начиная от стартапов и заканчивая предприятиями, над разработкой решений AWSome для генеративного искусственного интеллекта. Он особенно увлечен использованием моделей большого языка для расширенного анализа данных и изучения практических приложений, решающих реальные проблемы. Помимо работы, Эй Джей любит путешествовать и в настоящее время находится в 53 странах с целью посетить все страны мира.
Эй Джей Димин — архитектор решений в AWS. Он специализируется на генеративном искусственном интеллекте, бессерверных вычислениях и анализе данных. Он является активным членом/наставником сообщества технических специалистов по машинному обучению и опубликовал несколько научных статей по различным темам искусственного интеллекта и машинного обучения. Он работает с клиентами, начиная от стартапов и заканчивая предприятиями, над разработкой решений AWSome для генеративного искусственного интеллекта. Он особенно увлечен использованием моделей большого языка для расширенного анализа данных и изучения практических приложений, решающих реальные проблемы. Помимо работы, Эй Джей любит путешествовать и в настоящее время находится в 53 странах с целью посетить все страны мира.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

