Генеративный ИИ открыл большой потенциал в области ИИ. Мы видим множество применений, включая генерацию текста, генерацию кода, обобщение, перевод, чат-боты и многое другое. Одной из таких развивающихся областей является использование обработки естественного языка (NLP) для открытия новых возможностей доступа к данным посредством интуитивно понятных запросов SQL. Вместо того чтобы иметь дело со сложным техническим кодом, бизнес-пользователи и аналитики данных могут задавать вопросы, связанные с данными и аналитикой, простым языком. Основная цель — автоматически генерировать SQL-запросы из текста на естественном языке. Для этого текстовый ввод преобразуется в структурированное представление, и на основе этого представления создается SQL-запрос, который можно использовать для доступа к базе данных.
В этом посте мы знакомим вас с текстом в SQL (Text2SQL) и изучаем варианты использования, проблемы, шаблоны проектирования и лучшие практики. В частности, мы обсуждаем следующее:
- Зачем нам нужен Text2SQL
- Ключевые компоненты для преобразования текста в SQL
- Подскажите инженерные соображения по естественному языку или преобразованию текста в SQL.
- Оптимизации и лучшие практики
- Шаблоны архитектуры
Зачем нам нужен Text2SQL?
Сегодня большой объем данных доступен в традиционных средствах анализа данных, хранилищах данных и базах данных, которые могут быть непростыми для запроса или понимания для большинства членов организации. Основная цель Text2SQL — сделать запросы к базам данных более доступными для нетехнических пользователей, которые могут предоставлять свои запросы на естественном языке.
NLP SQL позволяет бизнес-пользователям анализировать данные и получать ответы, вводя или произнося вопросы на естественном языке, например следующие:
- «Показать общий объем продаж каждого продукта за прошлый месяц»
- «Какие продукты принесли больше дохода?»
- «Какой процент клиентов из каждого региона?»
Коренная порода Амазонки — это полностью управляемый сервис, который предлагает выбор высокопроизводительных базовых моделей (FM) через единый API, что позволяет легко создавать и масштабировать приложения Gen AI. Его можно использовать для генерации SQL-запросов на основе вопросов, аналогичных перечисленным выше, а также для запроса структурированных данных организации и генерации ответов на естественном языке на основе данных ответов на запросы.
Ключевые компоненты для преобразования текста в SQL
Системы преобразования текста в SQL включают несколько этапов преобразования запросов на естественном языке в работоспособный SQL:
- Обработка естественного языка:
- Анализируйте входной запрос пользователя
- Извлеките ключевые элементы и намерения
- Преобразование в структурированный формат
- Генерация SQL:
- Сопоставить извлеченные данные с синтаксисом SQL
- Создайте действительный SQL-запрос
- Запрос к базе данных:
- Запустите SQL-запрос, сгенерированный ИИ, к базе данных.
- Получить результаты
- Возврат результатов пользователю
Одной из замечательных возможностей моделей больших языков (LLM) является генерация кода, включая язык структурированных запросов (SQL), для баз данных. Эти LLM можно использовать для понимания вопроса на естественном языке и создания соответствующего запроса SQL в качестве результата. LLM получат выгоду от внедрения контекстного обучения и настройки параметров по мере предоставления большего количества данных.
На следующей диаграмме показан базовый поток Text2SQL.

Подскажите инженерные соображения по преобразованию естественного языка в SQL
Подсказка имеет решающее значение при использовании LLM для перевода естественного языка в запросы SQL, и при разработке подсказок необходимо учитывать несколько важных моментов.
Эффективный быстрый инжиниринг является ключом к разработке естественного языка для систем SQL. Четкие и понятные подсказки предоставляют более эффективные инструкции для языковой модели. Предоставление контекста, в котором пользователь запрашивает SQL-запрос, а также соответствующих сведений о схеме базы данных, позволяет модели точно преобразовать намерение. Включение нескольких аннотированных примеров подсказок на естественном языке и соответствующих запросов SQL помогает модели создавать выходные данные, соответствующие синтаксису. Кроме того, включение расширенной генерации поиска (RAG), при которой модель извлекает аналогичные примеры во время обработки, еще больше повышает точность отображения. Хорошо продуманные подсказки, которые дают модели достаточные инструкции, контекст, примеры и дополнительные возможности поиска, имеют решающее значение для надежного перевода естественного языка в запросы SQL.
Ниже приведен пример базового приглашения с кодовым представлением базы данных из технического документа. Расширение возможностей преобразования текста в SQL в больших языковых моделях: исследование стратегий быстрого проектирования.
Как показано в этом примере, обучение с помощью нескольких шагов на основе подсказок предоставляет модели несколько аннотированных примеров в самой подсказке. Это демонстрирует целевое сопоставление между естественным языком и SQL для модели. Обычно приглашение содержит около 2–3 пар, показывающих запрос на естественном языке и эквивалентный оператор SQL. Эти несколько примеров помогут модели генерировать синтаксически совместимые SQL-запросы на естественном языке без необходимости использования обширных обучающих данных.
Тонкая настройка или быстрое проектирование
При создании естественного языка для систем SQL мы часто обсуждаем, является ли точная настройка модели правильным методом или эффективное быстрое проектирование — это путь. Оба подхода могут быть рассмотрены и выбраны на основе правильного набора требований:
-
- Тонкая настройка – Базовая модель предварительно обучается на большом общем текстовом корпусе, а затем может использоваться точная настройка на основе инструкций, в котором используются помеченные примеры для повышения производительности предварительно обученной базовой модели на текстовом SQL. Это адаптирует модель к целевой задаче. Точная настройка непосредственно обучает модель выполнению конечной задачи, но требует множества примеров текстового SQL. Вы можете использовать контролируемую точную настройку на основе вашего LLM, чтобы повысить эффективность преобразования текста в SQL. Для этого вы можете использовать несколько наборов данных, таких как Spiders, ВикиSQL, ГНАТЬСЯ, BIRD-SQLили КоSQL.
- Быстрый инжиниринг – Модель обучена заполнять запросы, предназначенные для запроса целевого синтаксиса SQL. При генерации SQL на естественном языке с использованием LLM предоставление четких инструкций в командной строке важно для управления выходными данными модели. В приглашении можно аннотировать различные компоненты, например указывать на столбцы, схему, а затем указывать, какой тип SQL создавать. Они действуют как инструкции, сообщающие модели, как форматировать выходные данные SQL. В следующем приглашении показан пример, в котором вы указываете столбцы таблицы и даете команду создать запрос MySQL:
Эффективный подход к моделям преобразования текста в SQL — сначала начать с базового LLM без какой-либо тонкой настройки для конкретной задачи. Затем можно использовать хорошо продуманные подсказки для адаптации и управления базовой моделью для обработки сопоставления текста в SQL. Такое быстрое проектирование позволяет вам развивать возможности без необходимости тонкой настройки. Если быстрое проектирование базовой модели не обеспечивает достаточной точности, можно затем изучить тонкую настройку на небольшом наборе примеров текстового SQL вместе с дальнейшим быстрым проектированием.
Сочетание точной настройки и быстрого проектирования может потребоваться, если быстрое проектирование только на необработанной предварительно обученной модели не соответствует требованиям. Однако лучше сначала попробовать быстрое проектирование без тонкой настройки, поскольку это позволяет быстро выполнить итерацию без сбора данных. Если это не обеспечивает адекватную производительность, следующим шагом может стать точная настройка наряду с быстрым проектированием. Этот общий подход максимизирует эффективность, но при этом допускает настройку, если чисто методы, основанные на подсказках, недостаточны.
Оптимизация и лучшие практики
Оптимизация и передовой опыт необходимы для повышения эффективности и обеспечения оптимального использования ресурсов, а также достижения правильных результатов наилучшим возможным способом. Эти методы помогают повысить производительность, контролировать затраты и достигать более качественного результата.
При разработке систем преобразования текста в SQL с использованием LLM методы оптимизации могут повысить производительность и эффективность. Ниже приведены некоторые ключевые области, которые следует учитывать:
- Кэширование – Чтобы улучшить задержку, контроль затрат и стандартизацию, вы можете кэшировать проанализированный SQL и распознанные запросы запросов из LLM преобразования текста в SQL. Это позволяет избежать повторной обработки повторяющихся запросов.
- мониторинг – Журналы и показатели, связанные с анализом запросов, распознаванием подсказок, генерацией SQL и результатами SQL, должны собираться для мониторинга системы LLM преобразования текста в SQL. Это обеспечивает наглядность примера оптимизации, обновляющего подсказку или возвращающегося к точной настройке с обновленным набором данных.
- Материализованные представления и таблицы – Материализованные представления могут упростить генерацию SQL и повысить производительность распространенных запросов преобразования текста в SQL. Непосредственный запрос к таблицам может привести к сложному SQL, а также к проблемам с производительностью, включая постоянное создание методов повышения производительности, таких как индексы. Кроме того, вы можете избежать проблем с производительностью, если одна и та же таблица одновременно используется для других областей приложения.
- Обновление данных – Материализованные представления необходимо обновлять по расписанию, чтобы поддерживать актуальность данных для запросов преобразования текста в SQL. Вы можете использовать подходы пакетного или добавочного обновления, чтобы сбалансировать накладные расходы.
- Центральный каталог данных – Создание централизованного каталога данных обеспечивает единую панель обзора источников данных организации и поможет специалистам LLM выбирать подходящие таблицы и схемы для предоставления более точных ответов. Вектор вложения созданные из центрального каталога данных, могут быть переданы в LLM вместе с информацией, запрошенной для генерации соответствующих и точных ответов SQL.
Применяя передовые методы оптимизации, такие как кэширование, мониторинг, материализованные представления, запланированное обновление и центральный каталог, вы можете значительно повысить производительность и эффективность систем преобразования текста в SQL с помощью LLM.
Шаблоны архитектуры
Давайте рассмотрим некоторые архитектурные шаблоны, которые можно реализовать для рабочего процесса преобразования текста в SQL.
Быстрый инжиниринг
На следующей диаграмме показана архитектура генерации запросов с помощью LLM с использованием оперативного проектирования.
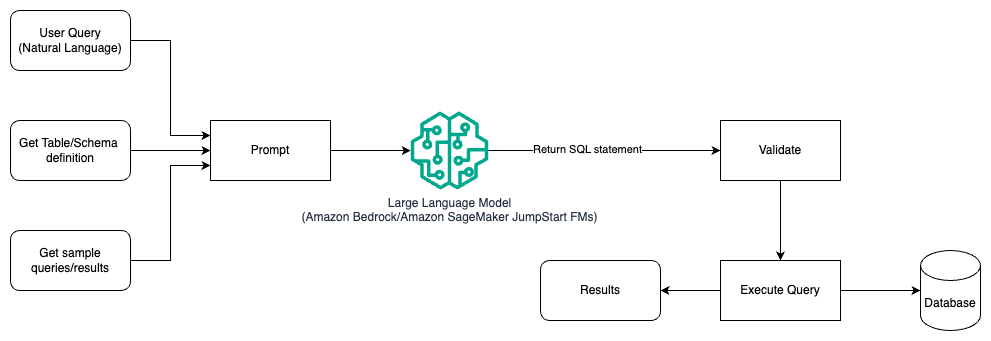
В этом шаблоне пользователь создает пошаговое обучение на основе подсказок, которое предоставляет модели аннотированные примеры в самом подсказке, которая включает сведения о таблице и схеме, а также несколько примеров запросов с их результатами. LLM использует предоставленное приглашение для возврата сгенерированного AI SQL, который проверяется, а затем запускается в базе данных для получения результатов. Это самый простой шаблон для начала использования быстрого проектирования. Для этого вы можете использовать Коренная порода Амазонки or модели фундамента in Amazon SageMaker JumpStart.
В этом шаблоне пользователь создает пошаговое обучение на основе подсказки, которое предоставляет модели аннотированные примеры в самой подсказке, которая включает сведения о таблице и схеме, а также несколько примеров запросов с их результатами. LLM использует предоставленное приглашение для возврата обратно сгенерированного AI SQL, который проверяется и запускается в базе данных для получения результатов. Это самый простой шаблон для начала использования быстрого проектирования. Для этого вы можете использовать Коренная порода Амазонки Это полностью управляемый сервис, который предлагает выбор высокопроизводительных базовых моделей (FM) от ведущих компаний в области ИИ через единый API, а также широкий набор возможностей, необходимых для создания генеративных приложений ИИ с безопасностью, конфиденциальностью и ответственным ИИ. или Модели JumpStart Foundation который предлагает самые современные базовые модели для таких случаев использования, как написание контента, генерация кода, ответы на вопросы, копирайтинг, обобщение, классификация, поиск информации и многое другое.
Оперативное проектирование и тонкая настройка
На следующей диаграмме показана архитектура генерации запросов с помощью LLM с использованием быстрого проектирования и точной настройки.
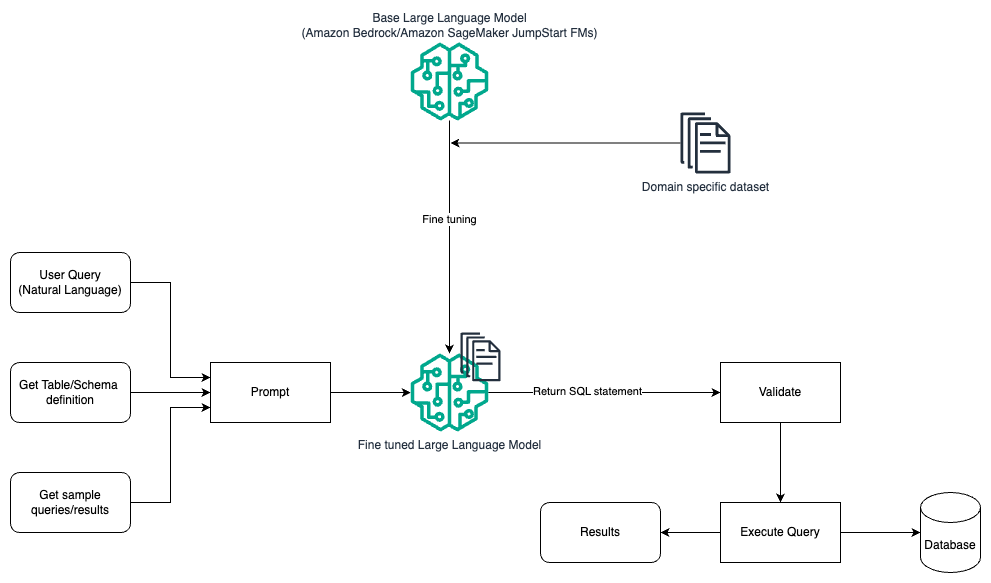
Этот процесс аналогичен предыдущему шаблону, который в основном основан на оперативном проектировании, но с дополнительным потоком тонкой настройки набора данных для конкретной предметной области. Точно настроенный LLM используется для генерации SQL-запросов с минимальным контекстным значением для приглашения. Для этого вы можете использовать SageMaker JumpStart для точной настройки LLM для набора данных, специфичного для предметной области, так же, как вы обучаете и развертываете любую модель в Создатель мудреца Амазонки.
Оперативный инжиниринг и РАГ
На следующей диаграмме показана архитектура генерации запросов с помощью LLM с использованием оперативного проектирования и RAG.
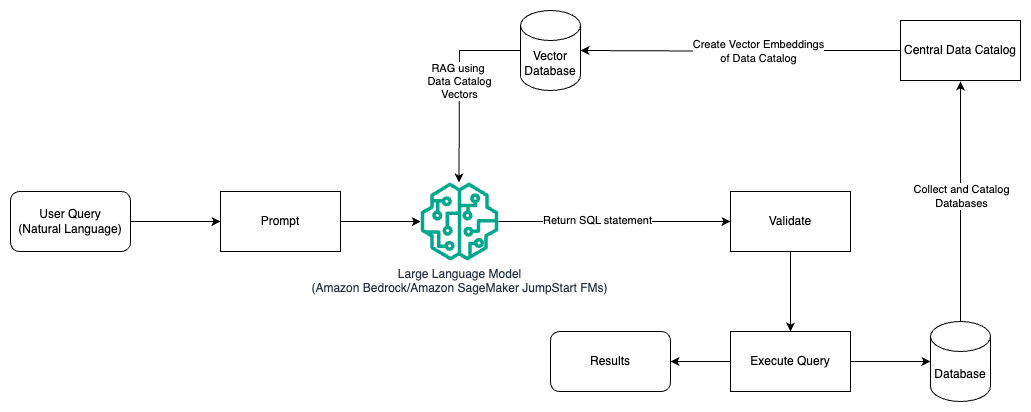
В этом шаблоне мы используем Извлечение дополненной генерации использование хранилищ векторных вложений, например Вложения Amazon Titan or Согласовать Встроить, На Коренная порода Амазонки из центрального каталога данных, например Клей AWS Каталог данных, баз данных внутри организации. Векторные вложения хранятся в векторных базах данных, таких как Векторный движок для Amazon OpenSearch Serverless, Сервис реляционных баз данных Amazon (Amazon RDS) для PostgreSQL с pgvector расширение, или Амазон Кендра. LLM используют векторные внедрения, чтобы быстрее выбирать нужную базу данных, таблицы и столбцы из таблиц при создании SQL-запросов. Использование RAG полезно, когда данные и соответствующая информация, которую LLM необходимо получить, хранятся в нескольких отдельных системах баз данных, и LLM должна иметь возможность искать или запрашивать данные из всех этих различных систем. Именно здесь предоставление векторных вложений централизованного или унифицированного каталога данных в LLM приводит к более точной и полной информации, возвращаемой LLM.
Заключение
В этом посте мы обсудили, как мы можем генерировать ценность из корпоративных данных с использованием естественного языка для генерации SQL. Мы изучили ключевые компоненты, оптимизацию и лучшие практики. Мы также изучили шаблоны архитектуры: от базового оперативного проектирования до тонкой настройки и RAG. Чтобы узнать больше, обратитесь к Коренная порода Амазонки легко создавать и масштабировать генеративные приложения искусственного интеллекта с помощью базовых моделей.
Об авторах
 Рэнди ДеФо является старшим главным архитектором решений в AWS. Он имеет степень MSEE Мичиганского университета, где работал над компьютерным зрением для автономных транспортных средств. Он также имеет степень магистра делового администрирования Университета штата Колорадо. Рэнди занимал различные должности в сфере технологий, от разработки программного обеспечения до управления продуктами. Вошел в пространство больших данных в 2013 году и продолжает исследовать эту область. Он активно работает над проектами в области машинного обучения и выступал на многочисленных конференциях, включая Strata и GlueCon.
Рэнди ДеФо является старшим главным архитектором решений в AWS. Он имеет степень MSEE Мичиганского университета, где работал над компьютерным зрением для автономных транспортных средств. Он также имеет степень магистра делового администрирования Университета штата Колорадо. Рэнди занимал различные должности в сфере технологий, от разработки программного обеспечения до управления продуктами. Вошел в пространство больших данных в 2013 году и продолжает исследовать эту область. Он активно работает над проектами в области машинного обучения и выступал на многочисленных конференциях, включая Strata и GlueCon.
 Нитин Евсевий — старший архитектор корпоративных решений в AWS, имеющий опыт разработки программного обеспечения, архитектуры предприятия и искусственного интеллекта и машинного обучения. Он глубоко увлечен исследованием возможностей генеративного искусственного интеллекта. Он сотрудничает с клиентами, помогая им создавать хорошо спроектированные приложения на платформе AWS, а также занимается решением технологических проблем и помогает им в переходе к облаку.
Нитин Евсевий — старший архитектор корпоративных решений в AWS, имеющий опыт разработки программного обеспечения, архитектуры предприятия и искусственного интеллекта и машинного обучения. Он глубоко увлечен исследованием возможностей генеративного искусственного интеллекта. Он сотрудничает с клиентами, помогая им создавать хорошо спроектированные приложения на платформе AWS, а также занимается решением технологических проблем и помогает им в переходе к облаку.
 Аргья Банерджи — старший архитектор решений в AWS в районе залива Сан-Франциско, который помогает клиентам внедрить и использовать облако AWS. Аргья специализируется на больших данных, озерах данных, потоковой передаче, пакетной аналитике, а также услугах и технологиях AI/ML.
Аргья Банерджи — старший архитектор решений в AWS в районе залива Сан-Франциско, который помогает клиентам внедрить и использовать облако AWS. Аргья специализируется на больших данных, озерах данных, потоковой передаче, пакетной аналитике, а также услугах и технологиях AI/ML.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

