Этот пост написан в соавторстве с Сантошем Вадди и Нандой Кишоре Татикондой из BigBasket.
BigBasket — крупнейший в Индии интернет-магазин продуктов питания и продуктов. Они работают по нескольким каналам электронной коммерции, таким как быстрая торговля, интервальная доставка и ежедневная подписка. Вы также можете покупать в их физических магазинах и торговых автоматах. Они предлагают большой ассортимент, насчитывающий более 50,000 1,000 товаров 500 брендов, и работают более чем в 10 городах. BigBasket обслуживает более XNUMX миллионов клиентов.
В этом посте мы обсудим, как BigBasket использовал Создатель мудреца Амазонки обучить свою модель компьютерного зрения идентификации товаров повседневного спроса (FMCG), что помогло им сократить время обучения примерно на 50 % и сократить расходы на 20 %.
Проблемы клиентов
Сегодня большинство супермаркетов и обычных магазинов в Индии предоставляют возможность ручной оплаты на кассе. Это имеет две проблемы:
- Это требует дополнительной рабочей силы, весовых этикеток и постоянного обучения сотрудников магазина по мере их масштабирования.
- В большинстве магазинов кассовый прилавок отличается от прилавков для взвешивания, что усложняет путь покупателя к покупке. Покупатели часто теряют наклейку с указанием веса и вынуждены возвращаться к стойкам взвешивания, чтобы забрать ее снова, прежде чем приступить к оформлению заказа.
Процесс самостоятельной оплаты
BigBasket представила в своих физических магазинах систему контроля на основе искусственного интеллекта, которая использует камеры для уникального различения товаров. На следующем рисунке представлен обзор процесса оформления заказа.
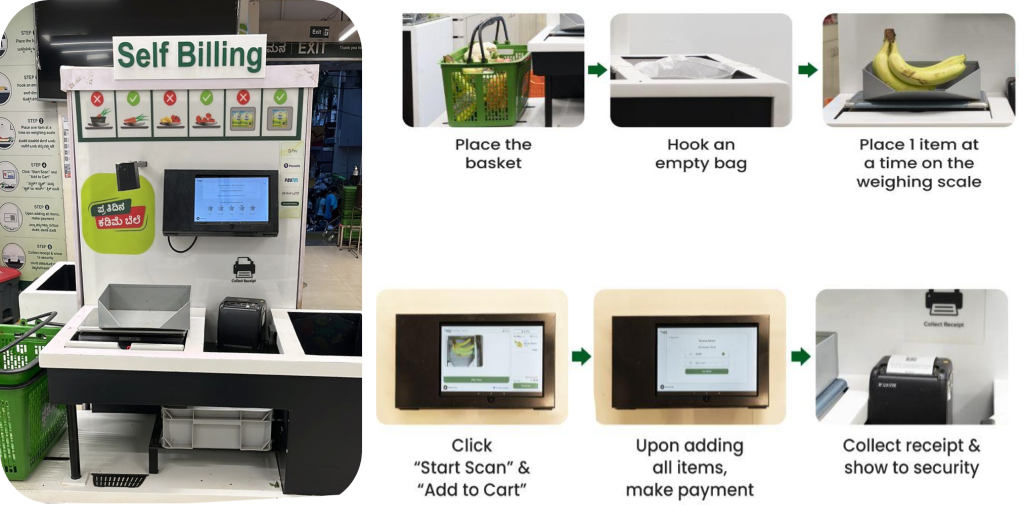
Команда BigBasket использовала собственные алгоритмы машинного обучения с открытым исходным кодом для распознавания объектов компьютерного зрения, чтобы обеспечить работу касс с поддержкой искусственного интеллекта на своих предприятиях. Фрешо (физические) магазины. При эксплуатации существующей установки мы столкнулись со следующими проблемами:
- В связи с постоянным появлением новых продуктов модель компьютерного зрения должна была постоянно включать информацию о новых продуктах. Системе необходимо было обрабатывать большой каталог, насчитывающий более 12,000 600 единиц хранения запасов (SKU), при этом новые SKU постоянно добавлялись со скоростью более XNUMX в месяц.
- Чтобы идти в ногу с новыми продуктами, каждый месяц производилась новая модель с использованием последних данных обучения. Частое обучение моделей адаптации к новым продуктам было дорогостоящим и отнимало много времени.
- BigBasket также хотела сократить время цикла обучения, чтобы сократить время выхода на рынок. Из-за увеличения количества SKU время, затрачиваемое моделью, увеличивалось линейно, что влияло на время ее выхода на рынок, поскольку частота обучения была очень высокой и занимала много времени.
- Увеличение данных для обучения модели и ручное управление полным циклом обучения приводило к значительным накладным расходам. BigBasket использовала стороннюю платформу, что повлекло за собой значительные затраты.
Обзор решения
Мы рекомендовали компании BigBasket перепроектировать существующее решение для обнаружения и классификации товаров повседневного спроса с помощью SageMaker, чтобы решить эти проблемы. Прежде чем перейти к полномасштабному производству, BigBasket опробовала пилотную версию SageMaker, чтобы оценить показатели производительности, стоимости и удобства.
Их целью было усовершенствовать существующую модель машинного обучения (ML) компьютерного зрения для обнаружения SKU. Мы использовали архитектуру сверточной нейронной сети (CNN) с Реснет152 для классификации изображений. Для обучения модели был оценен значительный набор данных, содержащий около 300 изображений на каждый SKU, в результате чего общее количество обучающих изображений составило более 4 миллионов. Для некоторых SKU мы расширили данные, чтобы охватить более широкий диапазон условий окружающей среды.
Следующая диаграмма иллюстрирует архитектуру решения.

Весь процесс можно свести к следующим этапам высокого уровня:
- Выполняйте очистку, аннотирование и увеличение данных.
- Хранить данные в Простой сервис хранения Amazon (Amazon S3) ведро.
- Используйте SageMaker и Amazon FSx для блеска для эффективного увеличения данных.
- Разделите данные на обучающие, проверочные и тестовые наборы. Мы использовали FSx для Lustre и Сервис реляционной базы данных Amazon (Amazon RDS) для быстрого параллельного доступа к данным.
- Используйте индивидуальный PyTorch Контейнер Docker, включая другие библиотеки с открытым исходным кодом.
- Используйте Параллелизм распределенных данных SageMaker (SMDDP) для ускоренного распределенного обучения.
- Метрики обучения модели журнала.
- Скопируйте окончательную модель в корзину S3.
BigBasket б/у Блокноты SageMaker обучить свои модели машинного обучения и смогли легко перенести существующие PyTorch с открытым исходным кодом и другие зависимости с открытым исходным кодом в контейнер SageMaker PyTorch и беспрепятственно запустить конвейер. Это было первое преимущество, замеченное командой BigBasket, поскольку практически не требовалось вносить какие-либо изменения в код, чтобы сделать его совместимым для работы в среде SageMaker.
Модельная сеть состоит из архитектуры ResNet 152, за которой следуют полностью связанные уровни. Мы заморозили низкоуровневые векторные слои и сохранили веса, полученные в результате трансферного обучения из модели ImageNet. Общее количество параметров модели составило 66 миллионов, включая 23 миллиона обучаемых параметров. Этот подход, основанный на переносе обучения, помог им использовать меньше изображений во время обучения, а также обеспечил более быструю сходимость и сократил общее время обучения.
Построение и обучение модели внутри Студия Amazon SageMaker предоставил интегрированную среду разработки (IDE) со всем необходимым для подготовки, построения, обучения и настройки моделей. Дополнение обучающих данных с помощью таких методов, как обрезка, поворот и переворачивание изображений, помогло улучшить данные обучения модели и точность модели.
Обучение модели было ускорено на 50 % за счет использования библиотеки SMDDP, включающей оптимизированные алгоритмы связи, разработанные специально для инфраструктуры AWS. Чтобы повысить производительность чтения/записи данных во время обучения модели и увеличения данных, мы использовали FSx для Lustre для обеспечения высокой производительности.
Начальный размер обучающих данных составлял более 1.5 ТБ. Мы использовали два Эластичное вычислительное облако Amazon (Амазон EC2) p4d.24 большие экземпляры с 8 графическими процессорами и 40 ГБ графической памяти. Для распределенного обучения SageMaker инстансы должны находиться в одном регионе и зоне доступности AWS. Кроме того, данные обучения, хранящиеся в корзине S3, должны находиться в одной зоне доступности. Эта архитектура также позволяет BigBasket перейти на другие типы экземпляров или добавить больше экземпляров к текущей архитектуре, чтобы удовлетворить любой значительный рост данных или добиться дальнейшего сокращения времени обучения.
Как библиотека SMDDP помогла сократить время, стоимость и сложность обучения
При традиционном обучении с распределенными данными платформа обучения присваивает ранги графическим процессорам (работникам) и создает копию вашей модели на каждом графическом процессоре. Во время каждой итерации обучения глобальный пакет данных делится на части (осколки пакета), и часть распределяется между каждым работником. Затем каждый рабочий процесс выполняет прямой и обратный проходы, определенные в сценарии обучения на каждом графическом процессоре. Наконец, веса и градиенты моделей из разных реплик модели синхронизируются в конце итерации посредством коллективной операции связи, называемой AllReduce. После того как каждый рабочий процесс и графический процессор получат синхронизированную копию модели, начинается следующая итерация.
Библиотека SMDDP — это библиотека коллективного общения, которая повышает производительность процесса параллельного обучения распределенных данных. Библиотека SMDDP снижает затраты на связь при выполнении ключевых операций коллективной связи, таких как AllReduce. Его реализация AllReduce предназначена для инфраструктуры AWS и может ускорить обучение за счет перекрытия операции AllReduce с обратным проходом. Этот подход обеспечивает почти линейную эффективность масштабирования и более высокую скорость обучения за счет оптимизации операций ядра между центральными и графическими процессорами.
Обратите внимание на следующие расчеты:
- Размер глобального пакета равен (количество узлов в кластере) * (количество графических процессоров на узел) * (на сегмент пакета).
- Пакетный осколок (небольшой пакет) — это подмножество набора данных, назначенное каждому графическому процессору (работнику) на итерацию.
BigBasket использовала библиотеку SMDDP, чтобы сократить общее время обучения. С помощью FSx для Lustre мы снизили пропускную способность чтения/записи данных во время обучения модели и увеличения данных. Благодаря параллелизму данных BigBasket смог провести обучение почти на 50 % быстрее и на 20 % дешевле по сравнению с другими альтернативами, обеспечив наилучшую производительность на AWS. SageMaker автоматически закрывает конвейер обучения после завершения. Проект завершился успешно, время обучения в AWS сократилось на 50 % (4.5 дня в AWS по сравнению с 9 днями на их устаревшей платформе).
На момент написания этой статьи BigBasket уже более 6 месяцев эксплуатирует комплексное решение и масштабирует систему, обслуживая новые города, и каждый месяц мы добавляем новые магазины.
«Наше партнерство с AWS по переходу к распределенному обучению с использованием их предложения SMDDP стало большой победой. Это не только сократило время нашего обучения на 50 %, но и обошлось на 20 % дешевле. В ходе всего нашего партнерства AWS установила планку заинтересованности клиентов и достижения результатов, работая с нами на протяжении всего пути к реализации обещанных преимуществ».
– Кешав Кумар, руководитель технического отдела BigBasket.
Заключение
В этом посте мы обсудили, как BigBasket использовала SageMaker для обучения своей модели компьютерного зрения идентификации продуктов FMCG. Внедрение автоматизированной системы самообслуживания на базе искусственного интеллекта обеспечивает улучшение качества обслуживания розничных клиентов благодаря инновациям, исключая при этом человеческие ошибки в процессе оформления заказа. Ускорение внедрения новых продуктов с помощью распределенного обучения SageMaker сокращает время и затраты на внедрение SKU. Интеграция FSx для Lustre обеспечивает быстрый параллельный доступ к данным для эффективного переобучения модели с использованием сотен новых SKU ежемесячно. В целом, это решение для самообслуживания на основе искусственного интеллекта обеспечивает улучшенный опыт покупок без ошибок при оформлении заказа. Автоматизация и инновации изменили их операции розничной торговли и регистрации.
SageMaker предоставляет комплексные возможности машинного обучения, развертывания и мониторинга, такие как среда блокнотов SageMaker Studio для написания кода, сбора данных, маркировки данных, обучения модели, настройки модели, развертывания, мониторинга и многого другого. Если ваш бизнес сталкивается с какой-либо из проблем, описанных в этом посте, и хочет сэкономить время на выходе на рынок и снизить затраты, обратитесь к команде по работе с клиентами AWS в вашем регионе и начните работу с SageMaker.
Об авторах
 Сантош Вадди является главным инженером в BigBasket и обладает более чем десятилетним опытом решения проблем искусственного интеллекта. Имея большой опыт работы в области компьютерного зрения, науки о данных и глубокого обучения, он получил степень аспиранта ИИТ Бомбея. Сантош является автором известных публикаций IEEE и, как опытный автор технических блогов, он также внес значительный вклад в разработку решений компьютерного зрения во время своего пребывания в Samsung.
Сантош Вадди является главным инженером в BigBasket и обладает более чем десятилетним опытом решения проблем искусственного интеллекта. Имея большой опыт работы в области компьютерного зрения, науки о данных и глубокого обучения, он получил степень аспиранта ИИТ Бомбея. Сантош является автором известных публикаций IEEE и, как опытный автор технических блогов, он также внес значительный вклад в разработку решений компьютерного зрения во время своего пребывания в Samsung.
 Нанда Кишоре Татиконда — технический менеджер, возглавляющий отдел разработки данных и аналитики в BigBasket. Нанда разработал несколько приложений для обнаружения аномалий и имеет патент, поданный в аналогичной области. Он работал над созданием приложений корпоративного уровня, созданием платформ данных в нескольких организациях и платформ отчетности для оптимизации решений, основанных на данных. Нанда имеет более чем 18-летний опыт работы с Java/J2EE, технологиями Spring и платформами больших данных с использованием Hadoop и Apache Spark.
Нанда Кишоре Татиконда — технический менеджер, возглавляющий отдел разработки данных и аналитики в BigBasket. Нанда разработал несколько приложений для обнаружения аномалий и имеет патент, поданный в аналогичной области. Он работал над созданием приложений корпоративного уровня, созданием платформ данных в нескольких организациях и платформ отчетности для оптимизации решений, основанных на данных. Нанда имеет более чем 18-летний опыт работы с Java/J2EE, технологиями Spring и платформами больших данных с использованием Hadoop и Apache Spark.
 Судханшу Ненависть является главным специалистом по искусственному интеллекту и машинному обучению в AWS и работает с клиентами, консультируя их по вопросам MLOps и генеративного искусственного интеллекта. На своей предыдущей должности он концептуализировал, создавал и руководил командами по созданию фундаментальной платформы искусственного интеллекта и геймификации с открытым исходным кодом, а также успешно коммерциализировал ее с более чем 100 клиентами. Судханшу имеет на своем счету пару патентов; написал 2 книги, несколько статей и блогов; и представил свою точку зрения на различных форумах. Он был идейным лидером и оратором и работает в отрасли почти 25 лет. Он работал с клиентами из списка Fortune 1000 по всему миру, а в последнее время работает с местными цифровыми клиентами в Индии.
Судханшу Ненависть является главным специалистом по искусственному интеллекту и машинному обучению в AWS и работает с клиентами, консультируя их по вопросам MLOps и генеративного искусственного интеллекта. На своей предыдущей должности он концептуализировал, создавал и руководил командами по созданию фундаментальной платформы искусственного интеллекта и геймификации с открытым исходным кодом, а также успешно коммерциализировал ее с более чем 100 клиентами. Судханшу имеет на своем счету пару патентов; написал 2 книги, несколько статей и блогов; и представил свою точку зрения на различных форумах. Он был идейным лидером и оратором и работает в отрасли почти 25 лет. Он работал с клиентами из списка Fortune 1000 по всему миру, а в последнее время работает с местными цифровыми клиентами в Индии.
 Аюш Кумар является архитектором решений в AWS. Он работает с широким кругом клиентов AWS, помогая им внедрять новейшие современные приложения и быстрее внедрять инновации с помощью облачных технологий. Вы увидите, как он экспериментирует на кухне в свободное время.
Аюш Кумар является архитектором решений в AWS. Он работает с широким кругом клиентов AWS, помогая им внедрять новейшие современные приложения и быстрее внедрять инновации с помощью облачных технологий. Вы увидите, как он экспериментирует на кухне в свободное время.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

