Сервис Amazon OpenSearch недавно представило семейство OpenSearch Optimized Instance (OR1), которое обеспечивает улучшение цены и производительности до 30 % по сравнению с существующими экземплярами, оптимизированными для памяти, во внутренних тестах и использует Простой сервис хранения Amazon (Amazon S3), чтобы обеспечить долговечность 11 девяток. В этом новом семействе экземпляров OpenSearch Service использует инновации OpenSearch и технологии AWS, чтобы по-новому взглянуть на то, как данные индексируются и хранятся в облаке.
Сегодня клиенты широко используют службу OpenSearch для оперативной аналитики из-за ее способности обрабатывать большие объемы данных, а также предоставлять богатую и интерактивную аналитику. Чтобы обеспечить эти преимущества, OpenSearch спроектирован как крупномасштабная распределенная система с несколькими независимыми экземплярами, индексирующими данные и обрабатывающими запросы. По мере роста скорости и объема данных операционной аналитики могут возникнуть узкие места. Чтобы устойчиво поддерживать большие объемы индексирования и обеспечивать надежность, мы создали семейство инстансов OR1.
В этом посте мы обсудим, как обновленный поток данных работает с экземплярами OR1 и как он может обеспечить высокую пропускную способность и надежность индексации с использованием нового протокола физической репликации. Мы также углубимся в некоторые проблемы, которые мы решили для обеспечения правильности и целостности данных.
Проектирование для высокой производительности и долговечности на 11 девяток.
Служба OpenSearch управляет десятками тысяч кластеров OpenSearch. Мы получили представление о типичных конфигурациях кластеров, которые клиенты используют для достижения целей высокой пропускной способности и надежности. Чтобы добиться более высокой пропускной способности, клиенты часто предпочитают удалять копии реплик, чтобы сэкономить на задержке репликации; однако такая конфигурация приводит к снижению доступности и долговечности. Другим клиентам требуется высокая надежность и, как следствие, необходимо поддерживать несколько копий реплик, что приводит к более высоким эксплуатационным расходам для них.
Семейство OpenSearch Optimized Instance обеспечивает дополнительную надежность и одновременно снижает затраты за счет хранения копии данных на Amazon S3. С помощью экземпляров OR1 вы можете настроить несколько копий реплик для обеспечения высокой доступности чтения, сохраняя при этом пропускную способность индексирования.
На следующей диаграмме показан процесс индексирования, включающий обновление метаданных в OR1.
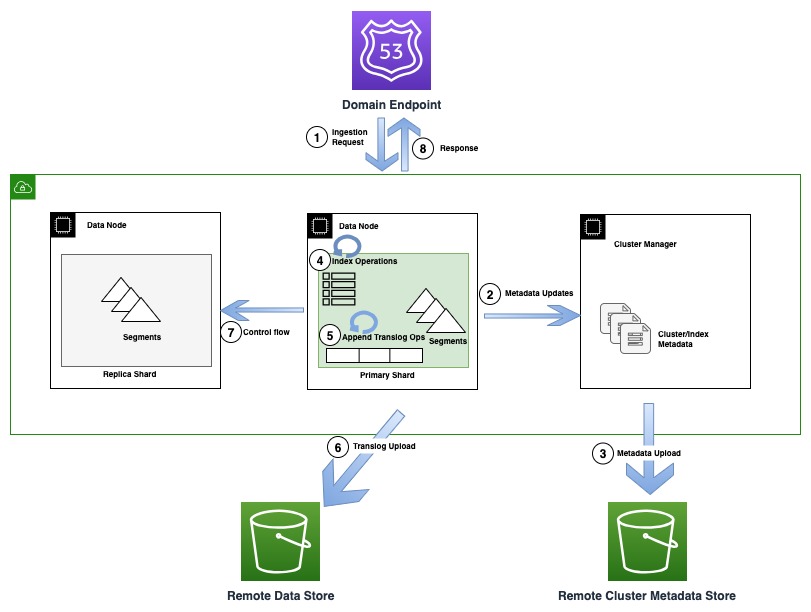
Во время операций индексирования отдельные документы индексируются в Lucene, а также добавляются в журнал упреждающей записи, также известный как транслог. Прежде чем отправить подтверждение клиенту, все операции транслогирования сохраняются в удаленном хранилище данных, поддерживаемом Amazon S3. Если настроены какие-либо копии реплик, основная копия выполняет проверки, чтобы обнаружить возможность использования нескольких устройств записи (поток управления) на всех копиях реплик в целях корректности.
На следующей диаграмме показан процесс создания и репликации сегментов в экземплярах OR1.
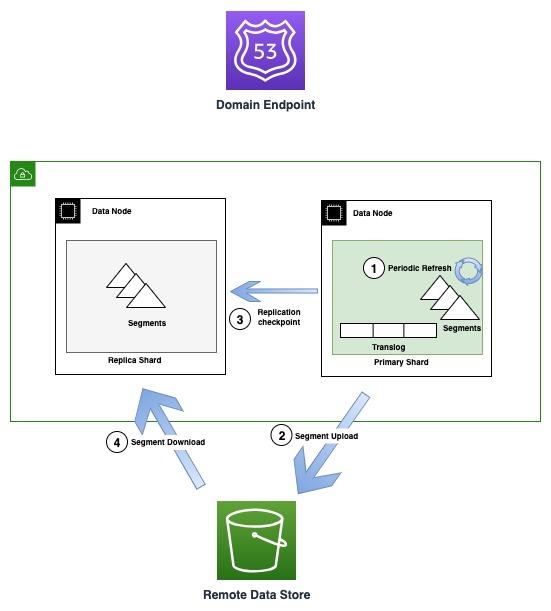
Периодически по мере создания новых файлов сегментов OR1 копирует эти сегменты в Amazon S3. Когда передача завершена, первичный сервер публикует новые контрольные точки для всех копий реплик, уведомляя их о том, что новый сегмент доступен для загрузки. Копии реплик впоследствии загружают новые сегменты и делают их доступными для поиска. Эта модель отделяет поток данных, который происходит при использовании Amazon S3, и поток управления (публикация контрольных точек и проверка условий), который происходит через транспортную связь между узлами.
На следующей диаграмме показан процесс восстановления в экземплярах OR1.
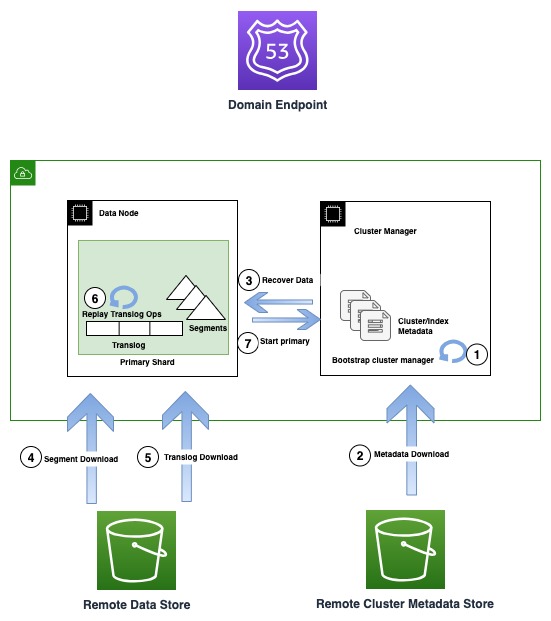
В экземплярах OR1 сохраняются не только данные, но и метаданные кластера, такие как сопоставления индексов, шаблоны и настройки в Amazon S3. Это гарантирует, что в случае потери кворума менеджера кластера, что является распространенным режимом сбоя в установках невыделенного менеджера кластера, OpenSearch сможет надежно восстановить последние подтвержденные метаданные.
В случае сбоя инфраструктуры домен OpenSearch может потерять один или несколько узлов. В таком случае новое семейство экземпляров гарантирует восстановление как метаданных кластера, так и данных индекса вплоть до последней подтвержденной операции. Когда к кластеру присоединяются новые заменяющие узлы, внутренний механизм восстановления кластера загружает новый набор узлов, а затем восстанавливает последние метаданные кластера из хранилища метаданных удаленного кластера. После восстановления метаданных кластера механизм восстановления начинает гидратировать отсутствующие данные сегмента и транслогировать их из Amazon S3. Затем все незафиксированные операции транслогирования, вплоть до последней подтвержденной операции, воспроизводятся, чтобы восстановить утерянную копию.
Новый дизайн не меняет способ работы поиска. Запросы обычно обрабатываются либо основным сегментом, либо репликой для каждого сегмента в индексе. Вы можете увидеть более длительные задержки (в диапазоне 10 секунд), прежде чем все копии будут согласованы с определенным моментом времени, поскольку репликация данных использует Amazon S3.
Ключевое преимущество этой архитектуры заключается в том, что она служит фундаментом для будущих инноваций, таких как разделение устройств чтения и записи, а также помогает разделить уровни вычислений и хранения.
Как переопределение стратегии репликации повышает производительность индексации
OpenSearch поддерживает две стратегии репликации: логическую (документ) и физическую (сегментную) репликацию. В случае логической репликации данные индексируются на всех копиях независимо, что приводит к избыточным вычислениям в кластере. Экземпляры OR1 используют новый физическая репликация модель, в которой данные индексируются только в основной копии, а дополнительные копии создаются путем копирования данных из основной. При большом количестве копий реплик узлу, на котором размещена основная копия, требуется значительная пропускная способность сети, реплицирующая сегмент на все копии. Новые экземпляры OR1 решают эту проблему, надолго сохраняя сегмент в Amazon S3, который настроен как удаленное хранилище вариант. Они также помогают масштабировать реплики без возникновения узких мест на первичном сервере.
После загрузки сегментов в Amazon S3 первичный сервер отправляет запрос контрольной точки, уведомляя все реплики о необходимости загрузки новых сегментов. Затем копиям реплик необходимо загрузить дополнительные сегменты. Поскольку этот процесс высвобождает вычислительные ресурсы на репликах, которые в противном случае необходимы для избыточной индексации данных и сетевых издержек, возникающих на первичных серверах для репликации данных, кластер может обеспечить большую пропускную способность. Если реплики не могут обрабатывать вновь созданные сегменты из-за перегрузки или медленных сетевых путей, реплики за пределами точки помечаются как неудавшиеся, чтобы они не возвращали устаревшие результаты.
Почему высокая долговечность — это хорошая идея, но трудно добиться успеха
Несмотря на то, что все зафиксированные сегменты надолго сохраняются в Amazon S3 при каждом их создании, одной из ключевых проблем в достижении высокой надежности является синхронная запись всех незафиксированных операций в журнал упреждающей записи на Amazon S3 перед подтверждением обратного запроса клиенту без ущерба для пропускная способность. Новая семантика вводит дополнительную задержку в сети для отдельных запросов, но мы добились того, чтобы это не повлияло на пропускную способность, — это пакетирование и слив запросов в одном потоке в течение определенного интервала, при этом гарантируя, что другие потоки продолжают индексировать. Запросы. В результате вы можете повысить пропускную способность за счет большего количества одновременных клиентских подключений за счет оптимального пакетирования массовых полезных данных.
Другие проблемы при разработке высоконадежной системы включают постоянное обеспечение целостности и правильности данных. Хотя некоторые события, такие как сетевые разделы, случаются редко, они могут нарушить корректность системы, и поэтому система должна быть готова справиться с этими режимами сбоев. Поэтому при переходе на новый протокол репликации сегментов мы также внесли несколько других изменений в протокол, например обнаружение нескольких устройств записи в каждой реплике. Протокол гарантирует, что изолированный модуль записи не сможет подтвердить запрос на запись, в то время как другой недавно повышенный основной сервер, основанный на кворуме менеджера кластера, одновременно принимает новые записи.
Новое семейство инстансов автоматически обнаруживает потерю основного сегмента при восстановлении данных и выполняет тщательные проверки доступности сети, прежде чем данные будут повторно гидратированы из Amazon S3 и кластер будет возвращен в работоспособное состояние.
Для обеспечения целостности данных все файлы тщательно проверяются контрольной суммой, чтобы мы могли обнаружить и предотвратить повреждение сети или файловой системы, которое может привести к нечитаемости данных. Более того, все файлы, включая метаданные, разработаны так, чтобы быть неизменяемыми, что обеспечивает дополнительную безопасность от повреждений, и имеют версии, предотвращающие случайные мутирующие изменения.
Переосмысление потоков данных
Экземпляры OR1 гидратируют копии непосредственно из Amazon S3, чтобы выполнить восстановление потерянных фрагментов во время сбоя инфраструктуры. Используя Amazon S3, мы можем освободить пропускную способность сети, дисковую и вычислительную мощность основного узла и, следовательно, обеспечить более плавное масштабирование на месте и сине-зеленое развертывание за счет оркестровки всего процесса с минимальной координацией основного узла.
Служба OpenSearch обеспечивает автоматическое резервное копирование данных, называемое моментальные снимки с ежечасными интервалами, что означает, что в случае случайного изменения данных у вас есть возможность вернуться к состоянию на предыдущий момент времени. Однако мы обсудили, что в новом семействе экземпляров OpenSearch данные уже надежно сохраняются на Amazon S3. Так как же работают снимки, если данные уже есть в Amazon S3?
В новом семействе экземпляров снимки служат контрольными точками, ссылаясь на уже существующие данные сегмента в том виде, в котором они существуют в определенный момент времени. Это делает снимки более легкими и быстрыми, поскольку им не нужно повторно загружать какие-либо дополнительные данные. Вместо этого они загружают файлы метаданных, которые фиксируют представление сегментов на данный момент времени, что мы называем мелкие снимки. Преимущество неглубоких снимков распространяется на все операции, а именно на создание, удаление и клонирование снимков. У вас все еще есть возможность сделать снимок независимой копии с помощью снимки вручную для других административных операций.
Обзор
OpenSearch — это программное обеспечение с открытым исходным кодом, управляемое сообществом. Большинство фундаментальных изменений, включая модель репликации, удаленное хранилище и метаданные удаленного кластера, были внесены в открытый исходный код; Фактически, мы следуем модели разработки с открытым исходным кодом.
Усилия по повышению производительности и надежности — это бесконечный цикл, поскольку мы продолжаем учиться и совершенствоваться. Новые экземпляры, оптимизированные для OpenSearch, служат фундаментом для будущих инноваций. Мы рады продолжить наши усилия по повышению надежности и производительности, а также посмотреть, какие новые и существующие решения смогут создать разработчики с помощью OpenSearch Service. Мы надеемся, что это приведет к более глубокому пониманию нового семейства экземпляров OpenSearch, того, как это предложение обеспечивает высокую надежность и лучшую пропускную способность, а также как оно может помочь вам настроить кластеры в соответствии с потребностями вашего бизнеса.
Если вы хотите внести свой вклад в OpenSearch, откройте Проблема с GitHub и дайте нам знать ваши мысли. Мы также хотели бы услышать о ваших историях успеха в достижении высокой пропускной способности и надежности службы OpenSearch. Если у вас есть другие вопросы, пожалуйста, оставьте комментарий.
Об авторах
 Бухтавар Хан — главный инженер, работающий над Amazon OpenSearch Service. Он заинтересован в построении распределенных и автономных систем. Он поддерживает и активно участвует в OpenSearch.
Бухтавар Хан — главный инженер, работающий над Amazon OpenSearch Service. Он заинтересован в построении распределенных и автономных систем. Он поддерживает и активно участвует в OpenSearch.
 Гаурав Бафна — старший инженер-программист, работающий над OpenSearch в Amazon Web Services. Он увлечен решением проблем в распределенных системах. Он поддерживает и активно участвует в OpenSearch.
Гаурав Бафна — старший инженер-программист, работающий над OpenSearch в Amazon Web Services. Он увлечен решением проблем в распределенных системах. Он поддерживает и активно участвует в OpenSearch.
 Сачин Кале — старший инженер по разработке программного обеспечения в AWS, работающий над OpenSearch.
Сачин Кале — старший инженер по разработке программного обеспечения в AWS, работающий над OpenSearch.
 Рохин Бхаргава является старшим менеджером по продукту в команде Amazon OpenSearch Service. Его страстью в AWS является помощь клиентам в подборе правильного сочетания сервисов AWS для достижения успеха в достижении их бизнес-целей.
Рохин Бхаргава является старшим менеджером по продукту в команде Amazon OpenSearch Service. Его страстью в AWS является помощь клиентам в подборе правильного сочетания сервисов AWS для достижения успеха в достижении их бизнес-целей.
 Ранджит Рамачандра — старший инженер-менеджер, работающий над Amazon OpenSearch Service. Он увлечен высокомасштабируемыми распределенными системами, высокой производительностью и отказоустойчивостью.
Ранджит Рамачандра — старший инженер-менеджер, работающий над Amazon OpenSearch Service. Он увлечен высокомасштабируемыми распределенными системами, высокой производительностью и отказоустойчивостью.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/

