Krones поставляет пивоварням, предприятиям по розливу напитков и производителям продуктов питания по всему миру отдельные машины и комплексные производственные линии. Ежедневно через линию Krones проходят миллионы стеклянных бутылок, банок и ПЭТ-контейнеров. Производственные линии представляют собой сложные системы с множеством возможных ошибок, которые могут привести к остановке линии и снижению производительности. Кронес хочет обнаружить неисправность как можно раньше (иногда даже до того, как она произойдет) и уведомить операторов производственных линий, чтобы повысить надежность и производительность. Так как же обнаружить неисправность? Krones оснащает свои линии датчиками для сбора данных, которые затем можно оценить на соответствие правилам. Krones как производитель линии, а также оператор линии имеют возможность создавать правила мониторинга для машин. Таким образом, производители напитков и другие операторы могут сами определять погрешность линии. В прошлом Кронес использовал систему, основанную на базе данных временных рядов. Основные проблемы заключались в том, что эту систему было сложно отлаживать, а также запросы отражали текущее состояние машин, а не переходы состояний.
В этом посте показано, как компания Krones создала решение потоковой передачи для мониторинга своих линий на основе Амазонка Кинезис и Управляемый сервис Amazon для Apache Flink. Эти полностью управляемые сервисы упрощают создание потоковых приложений с помощью Apache Flink. Управляемая служба для Apache Flink управляет базовыми компонентами Apache Flink, которые обеспечивают надежное состояние приложения, метрики, журналы и многое другое, а Kinesis позволяет экономично обрабатывать потоковые данные в любом масштабе. Если вы хотите начать работу с собственным приложением Apache Flink, ознакомьтесь с Репозиторий GitHub для примеров с использованием API-интерфейсов Java, Python или SQL Flink.
Обзор решения
Мониторинг линии Krones является частью Руководство для цехов Krones система. Он обеспечивает поддержку в организации, расстановке приоритетов, управлении и документировании всех видов деятельности в компании. Это позволяет им уведомлять оператора, если машина остановлена или требуются материалы, независимо от того, где оператор находится на линии. Проверенные правила мониторинга состояния уже встроены, но их также можно определить пользователем через пользовательский интерфейс. Например, если определенная отслеживаемая точка данных нарушает пороговое значение, на линии может появиться текстовое сообщение или триггер для заказа на техническое обслуживание.
Система мониторинга состояния и оценки правил построена на AWS с использованием аналитических сервисов AWS. Следующая диаграмма иллюстрирует архитектуру.
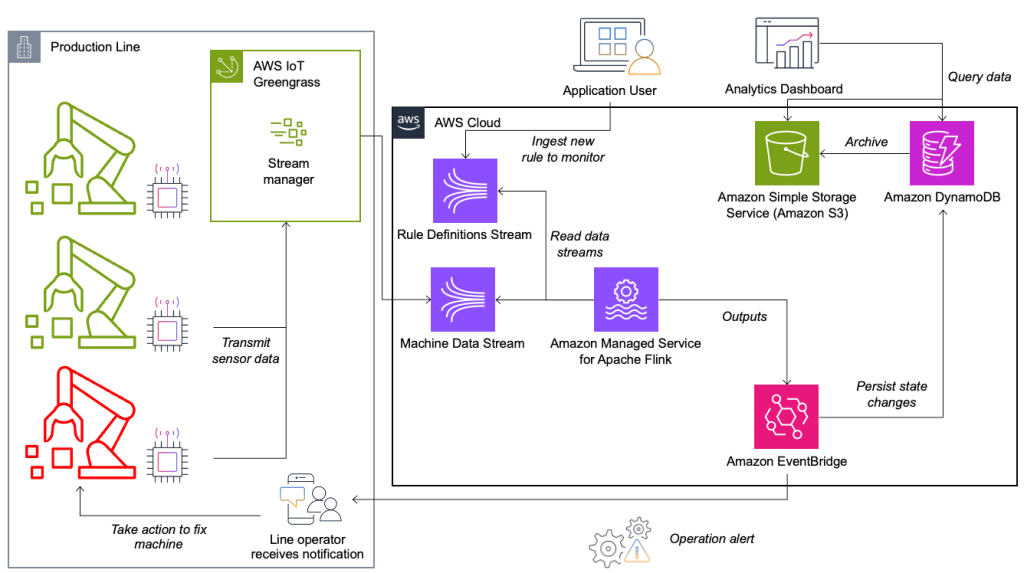
Почти каждое приложение потоковой передачи данных состоит из пяти уровней: источник данных, прием потока, хранилище потока, обработка потока и один или несколько пунктов назначения. В следующих разделах мы более подробно рассмотрим каждый уровень и то, как работает решение для мониторинга линий, созданное Krones.
Источник данных
Данные собираются службой, работающей на периферийном устройстве и считывающей несколько протоколов, таких как Siemens S7 или OPC/UA. Необработанные данные предварительно обрабатываются для создания унифицированной структуры JSON, что упрощает последующую обработку в обработчике правил. Пример полезных данных, преобразованных в JSON, может выглядеть следующим образом:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Прием потока
AWS IoT Greengrass — это пограничная среда выполнения и облачный сервис Интернета вещей (IoT) с открытым исходным кодом. Это позволяет вам работать с данными локально, а также объединять и фильтровать данные устройств. AWS IoT Greengrass предоставляет готовые компоненты, которые можно развернуть на периферии. Решение производственной линии использует компонент диспетчера потоков, который может обрабатывать данные и передавать их в пункты назначения AWS, например Аналитика Интернета вещей AWS, Простой сервис хранения Amazon (Amazon S3) и Kinesis. Диспетчер потоков буферизует и объединяет записи, а затем отправляет их в поток данных Kinesis.
Хранилище потоков
Задача потокового хранилища состоит в том, чтобы буферизовать сообщения отказоустойчивым способом и сделать их доступными для использования одним или несколькими потребительскими приложениями. Для достижения этой цели на AWS наиболее распространенными технологиями являются Kinesis и Amazon Managed Streaming для Apache Kafka (Амазонка МСК). Для хранения данных датчиков производственных линий компания Krones выбирает Kinesis. Kinesis — это бессерверная служба потоковой передачи данных, которая работает в любом масштабе с низкой задержкой. Шарды в потоке данных Kinesis — это уникально идентифицируемая последовательность записей данных, где поток состоит из одного или нескольких сегментов. Каждый сегмент имеет скорость чтения 2 МБ/с и скорость записи 1 МБ/с (максимум 1,000 записей/с). Чтобы избежать превышения этих ограничений, данные должны быть распределены между осколками как можно более равномерно. Каждая запись, отправляемая в Kinesis, имеет ключ раздела, который используется для группировки данных в сегмент. Поэтому вам нужно иметь большое количество ключей разделов, чтобы равномерно распределить нагрузку. Менеджер потоков, работающий на AWS IoT Greengrass, поддерживает случайное назначение ключей разделов. Это означает, что все записи попадают в случайный сегмент и нагрузка распределяется равномерно. Недостаток случайного назначения ключей раздела заключается в том, что записи в Kinesis не сохраняются по порядку. Мы объясним, как решить эту проблему, в следующем разделе, где поговорим о водяных знаках.
Водяные знаки
A водяной знак — это механизм, используемый для отслеживания и измерения хода событий в потоке данных. Время события — это временная метка момента создания события в источнике. Водяной знак указывает на своевременный прогресс приложения обработки потока, поэтому все события с более ранней или равной временной меткой считаются обработанными. Эта информация необходима Flink для опережения времени события и запуска соответствующих вычислений, таких как оценка окон. Допустимую задержку между временем события и водяным знаком можно настроить, чтобы определить, как долго ждать поздних данных, прежде чем считать окно завершенным и продвигать водяной знак.
У Krones есть системы по всему миру, и ей необходимо обрабатывать опоздания из-за потери соединения или других сетевых ограничений. Они начали с отслеживания опозданий и установки по умолчанию обработки опозданий Flink на максимальное значение, которое они видели в этом показателе. У них возникли проблемы с синхронизацией времени с периферийными устройствами, что привело их к более сложному способу нанесения водяных знаков. Они создали глобальный водяной знак для всех отправителей и использовали в качестве водяного знака наименьшее значение. Временные метки хранятся в HashMap для всех входящих событий. Когда водяные знаки создаются периодически, используется наименьшее значение этого HashMap. Чтобы избежать остановки водяных знаков из-за отсутствия данных, они настроили idleTimeOut параметр, который игнорирует временные метки старше определенного порога. Это увеличивает задержку, но обеспечивает надежную согласованность данных.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Обработка потока
После того как данные собираются с датчиков и передаются в Kinesis, их необходимо оценить с помощью механизма правил. Правило в этой системе представляет состояние одной метрики (например, температуры) или набора метрик. Для интерпретации метрики используется более одной точки данных, что представляет собой расчет с отслеживанием состояния. В этом разделе мы более подробно рассмотрим состояние ключей и состояние трансляции в Apache Flink, а также то, как они используются для создания механизма правил Krones.
Поток управления и шаблон состояния трансляции
В Apache Flink, состояние относится к способности системы хранить и управлять информацией постоянно во времени и операциях, что позволяет обрабатывать потоковые данные с поддержкой вычислений с отслеживанием состояния.
Ассоциация шаблон состояния трансляции позволяет распространять состояние на все параллельные экземпляры оператора. Следовательно, все операторы имеют одно и то же состояние, и данные могут обрабатываться с использованием этого же состояния. Эти данные, доступные только для чтения, могут быть приняты с помощью потока управления. Поток управления — это обычный поток данных, но обычно с гораздо более низкой скоростью передачи данных. Этот шаблон позволяет динамически обновлять состояние всех операторов, позволяя пользователю изменять состояние и поведение приложения без необходимости повторного развертывания. Точнее, распределение состояния осуществляется с помощью потока управления. Добавляя новую запись в поток управления, все операторы получают это обновление и используют новое состояние для обработки новых сообщений.
Это позволяет пользователям приложения Krones добавлять новые правила в приложение Flink, не перезапуская его. Это позволяет избежать простоев и обеспечивает удобство работы пользователей, поскольку изменения происходят в режиме реального времени. Правило охватывает сценарий, чтобы обнаружить отклонение процесса. Иногда машинные данные не так легко интерпретировать, как может показаться на первый взгляд. Если датчик температуры отправляет высокие значения, это может указывать на ошибку, а также быть следствием продолжающейся процедуры технического обслуживания. Важно поместить метрики в контекст и отфильтровать некоторые значения. Это достигается с помощью концепции под названием группировка.
Группировка метрик
Группировка данных и метрик позволяет определить актуальность входящих данных и получить точные результаты. Давайте рассмотрим пример на следующем рисунке.
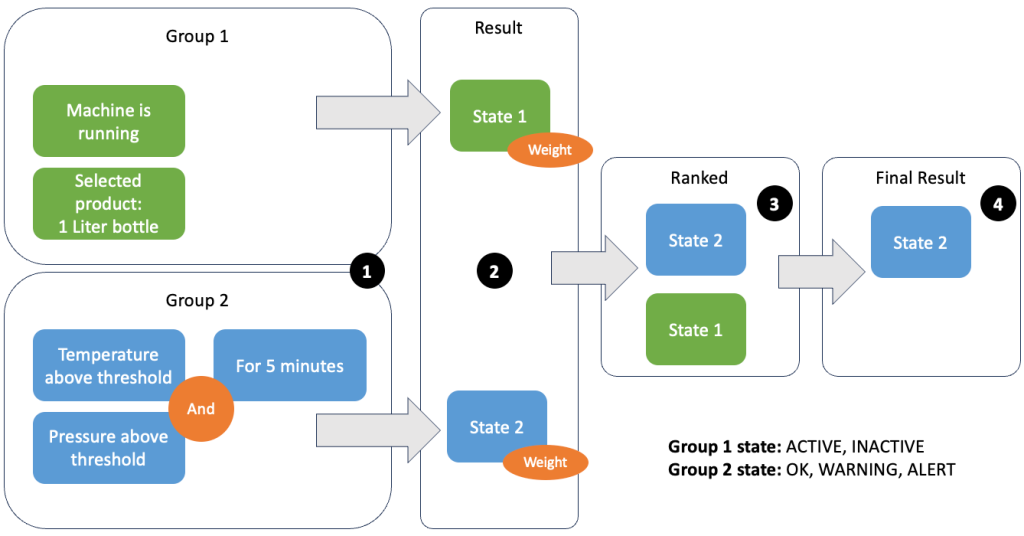
На шаге 1 мы определяем две группы условий. Группа 1 собирает информацию о состоянии машины и о том, какой продукт проходит через линию. Группа 2 использует значения датчиков температуры и давления. Группа условий может иметь разные состояния в зависимости от получаемых ею значений. В этом примере группа 1 получает данные о том, что машина работает, а в качестве продукта выбрана литровая бутылка; это дает этой группе состояние ACTIVE. Группа 2 имеет показатели температуры и давления; оба показателя превышают свои пороговые значения более 5 минут. В результате группа 2 оказывается в WARNING состояние. Это означает, что группа 1 сообщает, что все в порядке, а группа 2 — нет. На шаге 2 к группам добавляются веса. Это необходимо в некоторых ситуациях, поскольку группы могут сообщать противоречивую информацию. В этом сценарии группа 1 сообщает ACTIVE и отчеты группы 2 WARNING, поэтому системе неясно, в каком состоянии находится линия. После добавления весов штаты можно ранжировать, как показано на шаге 3. Наконец, штат с самым высоким рейтингом выбирается в качестве победителя, как показано на шаге 4.
После оценки правил и определения окончательного состояния машины результаты будут обработаны дальше. Предпринятое действие зависит от конфигурации правила; это может быть уведомление оператору линии о необходимости пополнения запасов материалов, проведения технического обслуживания или просто визуальное обновление на информационной панели. Эта часть системы, которая оценивает метрики и правила и предпринимает действия на основе результатов, называется механизм правил.
Масштабирование механизма правил
Позволяя пользователям создавать свои собственные правила, обработчик правил может иметь большое количество правил, которые ему необходимо оценить, а некоторые правила могут использовать те же данные датчиков, что и другие правила. Flink — это распределенная система, которая очень хорошо масштабируется по горизонтали. Чтобы распределить поток данных по нескольким задачам, можно использовать команду keyBy() метод. Это позволяет логически разбить поток данных и отправить части данных разным менеджерам задач. Часто это делается путем выбора произвольного ключа, чтобы получить равномерно распределенную нагрузку. В данном случае Кронес добавил ruleId к точке данных и использовал ее в качестве ключа. В противном случае необходимые точки данных обрабатываются другой задачей. Поток данных с ключом можно использовать во всех правилах, как обычную переменную.
Направления
Когда правило меняет свое состояние, информация отправляется в поток Kinesis, а затем через Amazon EventBridge потребителям. Один из потребителей создает уведомление о событии, которое передается на производственную линию и предупреждает персонал о необходимости действовать. Чтобы иметь возможность анализировать изменения состояния правила, другой сервис записывает данные в Amazon DynamoDB таблица для быстрого доступа и TTL для выгрузки долгосрочной истории в Amazon S3 для дальнейшей отчетности.
Заключение
В этом посте мы показали вам, как Krones создала систему мониторинга производственной линии в реальном времени на AWS. Управляемый сервис для Apache Flink позволил команде Krones быстро приступить к работе, сосредоточившись на разработке приложений, а не на инфраструктуре. Возможности Flink в режиме реального времени позволили компании Krones сократить время простоя оборудования на 10 % и повысить эффективность до 5 %.
Если вы хотите создавать собственные приложения потоковой передачи, ознакомьтесь с доступными примерами на сайте Репозиторий GitHub. Если вы хотите расширить свое приложение Flink с помощью пользовательских соединителей, см. Упрощение создания соединителей с помощью Apache Flink: введение в асинхронный приемник. Async Sink доступен в Apache Flink версии 1.15.1 и более поздних версиях.
Об авторах
 Флориан Майр — старший архитектор решений и эксперт по потоковой передаче данных в AWS. Он технолог, который помогает клиентам в Европе добиваться успеха и внедрять инновации, решая бизнес-задачи с помощью облачных сервисов AWS. Помимо работы архитектором решений, Флориан является страстным альпинистом и покорил одни из самых высоких гор Европы.
Флориан Майр — старший архитектор решений и эксперт по потоковой передаче данных в AWS. Он технолог, который помогает клиентам в Европе добиваться успеха и внедрять инновации, решая бизнес-задачи с помощью облачных сервисов AWS. Помимо работы архитектором решений, Флориан является страстным альпинистом и покорил одни из самых высоких гор Европы.
 Эмиль Дитль — старший технический руководитель компании Krones, специализирующийся на разработке данных, ключевой областью деятельности которого является Apache Flink и микросервисы. Его работа часто связана с разработкой и обслуживанием критически важного программного обеспечения. Вне своей профессиональной жизни он глубоко ценит времяпровождение со своей семьей.
Эмиль Дитль — старший технический руководитель компании Krones, специализирующийся на разработке данных, ключевой областью деятельности которого является Apache Flink и микросервисы. Его работа часто связана с разработкой и обслуживанием критически важного программного обеспечения. Вне своей профессиональной жизни он глубоко ценит времяпровождение со своей семьей.
 Саймон Пейер — архитектор решений в AWS в Швейцарии. Он практичный деятель и увлечен объединением технологий и людей, использующих облачные сервисы AWS. Особое внимание он уделяет потоковой передаче данных и автоматизации. Помимо работы, Саймон любит свою семью, природу и походы в горы.
Саймон Пейер — архитектор решений в AWS в Швейцарии. Он практичный деятель и увлечен объединением технологий и людей, использующих облачные сервисы AWS. Особое внимание он уделяет потоковой передаче данных и автоматизации. Помимо работы, Саймон любит свою семью, природу и походы в горы.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

