Изображение по автору
Csvkit является королем табличных данных. Он имеет набор инструментов, которые можно использовать для преобразования файлов CSV, управления данными и выполнения анализа данных.
Вы можете установить csvkit используя пип.
$ pip install csvkitПример 1
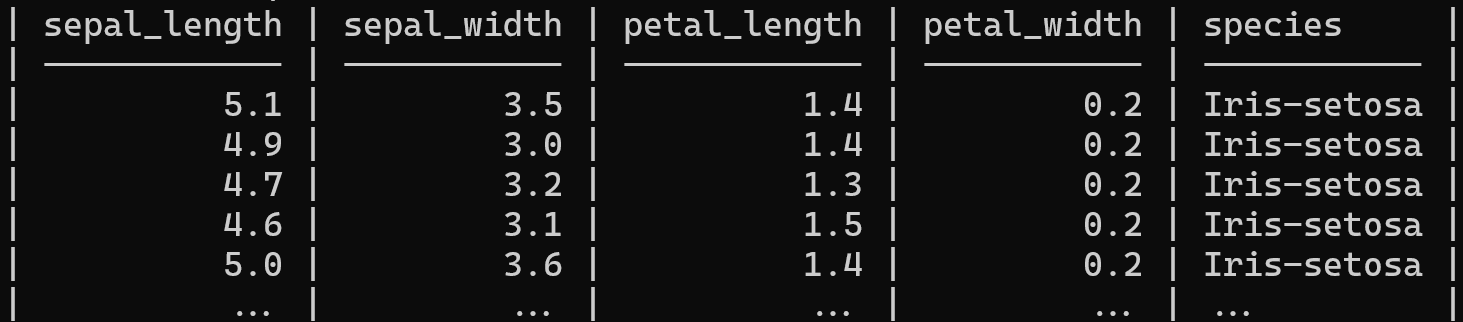
В этом примере мы будем использовать csvcut для выбора только двух столбцов и использовать csvlook для отображения результатов в табличном формате.
csvcut -c sepal_length,species iris.csv | csvlook --max-rows 5
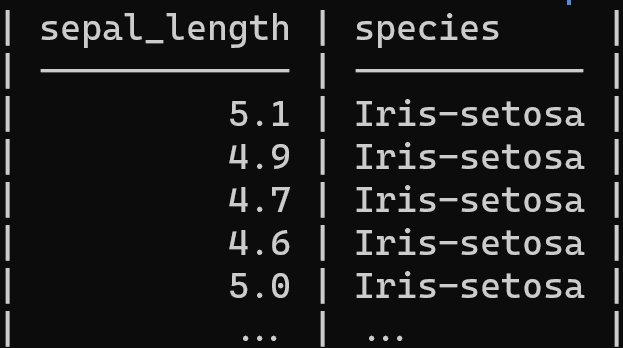
Примечание: вы можете ограничить количество строк с помощью аргумента --max-rows
Пример 2
Мы преобразуем файл CSV в файл JSON, используя csvjson.
csvjson iris.csv > iris.json
Примечание: csvkit также предоставляет нам инструменты для преобразования Excel в CSV и JSON в CSV.
Пример 3
Мы также можем выполнить анализ данных в файле CSV с помощью SQL-запроса. Для Csvsql требуется SQL-запрос и путь к файлу CSV. Результаты можно отобразить или сохранить в формате CSV.
csvsql --query "select * from iris where species like 'Iris-setosa'" iris.csv | csvlook --max-rows 5
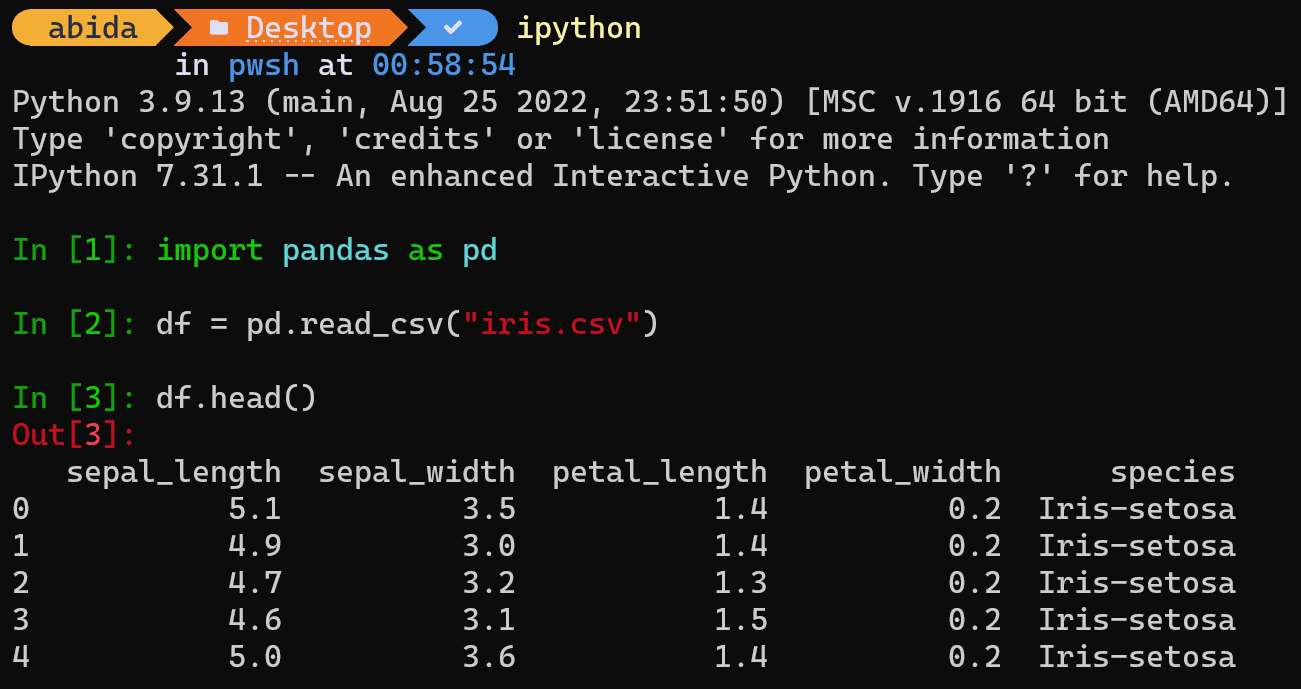
IPython — это интерактивная оболочка Python, которая привносит в ваш терминал некоторые функции блокнота Jupyter. Это позволяет быстрее тестировать идеи без создания файла Python.
Установите ipython с помощью установки pip.
$ pip install ipython
Примечание: Ipython также поставляется с Anaconda и Jupyter Notebook. Таким образом, в большинстве случаев вам не нужно его устанавливать.
После установки просто введите ipython в терминале и начните выполнять анализ данных так же, как в блокнотах Jupyter. Это легко и быстро.
завить обозначает URL-адрес клиента и представляет собой инструмент CLI для передачи данных на сервер и с сервера с использованием URL-адресов. Вы можете использовать его для ограничения скорости, регистрации ошибок, отображения прогресса и проверки конечных точек.
В этом примере мы загружаем данные машинного обучения из Калифорнийского университета и сохраняем их в виде файла CSV.
curl -o blood.csv https://archive.ics.uci.edu/ml/machine-learning-databases/blood-transfusion/transfusion.data
Вывод:
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed
100 12843 100 12843 0 0 7772 0 0:00:01 0:00:01 --:--:-- 7769
Вы можете использовать cURL для доступа к API с помощью токенов, push-файлов и автоматизации конвейеров данных.
Awk — это терминальный язык сценариев, который мы можем использовать для управления данными и выполнения анализа данных. Это не требует жалоб. Мы можем использовать переменные, числовые функции, строковые функции и логические операторы для написания сценария любого типа.
В примере мы отображаем первый и последний столбцы CSV-файла и показываем последние 10 строк. $1 в сценарии означает первые столбцы. Вы также можете изменить его на $3, чтобы отобразить 3-й столбец. $NF представляет последние столбцы.
awk -F "," '{print $1 " | " $NF}' iris.csv | tail

Каггл API позволяет загружать все виды наборов данных с веб-сайта Kaggle. Кроме того, вы можете обновлять свой общедоступный набор данных, отправлять файл на конкурс, а также запускать Jupyter Notebook и управлять им. Это суперинструмент командной строки.
Установите Kaggle API, используя pip.
$ pip install kaggle
После этого перейдите на Kaggle веб-сайт и получить свои учетные данные. Вы можете следить этой Руководство по настройке имени пользователя и закрытого ключа.
export KAGGLE_USERNAME=kingabzpro
export KAGGLE_KEY=xxxxxxxxxxxxxxПример 1
После настройки аутентификации вы можете искать случайные наборы данных. В нашем случае мы используем Обзор тенденций в сфере занятости набор данных.
Изображение из Обзор тенденций в сфере занятости
Вы можете запустить скрипт загрузки с помощью -d аргумент USERNAME/DATASET.
$ kaggle datasets download -d revathyta/survey-on-employment-trends
Или,
Вы можете просто получить команду API, нажав на три точки и выбрав опцию «Копировать команду API».
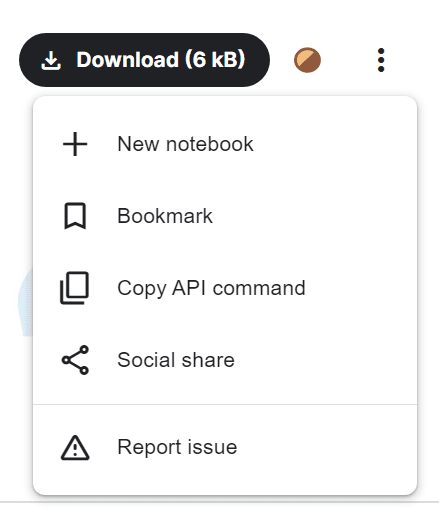
Изображение из Обзор тенденций в сфере занятости
Он загрузит набор данных в виде zip-файла. Вы также можете передать скрипт с помощью unzip команда для извлечения данных.
Downloading survey-on-employment-trends.zip to C:Usersabida 0%| | 0.00/6.22k [00:00<?, ?B/s] 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 6.22k/6.22k [00:00<?, ?B/s]Пример 2
Чтобы создать набор данных и поделиться им в Kaggle, вам нужно сначала инициировать файл метаданных, указав путь к набору данных.
$ kaggle datasets init -p /work/Kaggle/World-Vaccine-Progress
После этого создайте набор данных и отправьте файл на сервер Kaggle.
$ kaggle datasets create -p /work/Kaggle/World-Vaccine-Progress
Вы также можете обновить свой набор данных с помощью version команда. Требуется путь к файлу и сообщение. Так же, как git.
$ kaggle datasets version -p /work/Kaggle/World-Vaccine-Progress -m "second version"
Вы также можете ознакомиться с моим проектом Панель обновлений вакцин который успешно реализовал Kaggle API для регулярного обновления набора данных.
Я использую так много замечательных инструментов CLI, которые повысили мою производительность и помогли автоматизировать большую часть моей работы. Вы даже можете создать свой собственный инструмент командной строки в Python, используя click или argparse.
В этой статье мы узнали об инструментах CLI для загрузки набора данных, управления им, выполнения анализа, запуска сценариев и создания отчетов.
Я фанат Kaalgle API и csvkit. Я регулярно использую его для автоматизации своих записных книжек и анализа. Если вы хотите узнать, как использовать инструменты командной строки в своем рабочем процессе обработки данных, прочтите Наука о данных в командной строке бронируйте онлайн бесплатно.
Абид Али Аван (@ 1abidaliawan) — сертифицированный специалист по анализу данных, который любит создавать модели машинного обучения. В настоящее время он занимается созданием контента и ведением технических блогов по технологиям машинного обучения и обработки данных. Абид имеет степень магистра в области управления технологиями и степень бакалавра в области телекоммуникаций. Его видение состоит в том, чтобы создать продукт искусственного интеллекта с использованием графовой нейронной сети для студентов, борющихся с психическими заболеваниями.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.kdnuggets.com/2023/03/5-command-line-tools-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=5-more-command-line-tools-for-data-science

