Am introdus recent o nouă capacitate în Amazon SageMaker Python SDK care le permite oamenilor de știință de date să își execute codul de învățare automată (ML) creat în mediul lor de dezvoltare integrat (IDE) și notebook-uri preferate, împreună cu dependențele de rulare asociate ca Amazon SageMaker locuri de muncă de formare cu modificări minime de cod pentru experimentarea făcută local. Oamenii de știință de date efectuează de obicei mai multe iterații de experimentare în procesarea datelor și modele de antrenament în timp ce lucrează la orice problemă ML. Ei doresc să ruleze acest cod ML și să efectueze experimentarea cu ușurință de utilizare și modificare minimă a codului. Instruire pentru modele Amazon SageMaker îi ajută pe oamenii de știință de date să desfășoare joburi de formare la scară largă gestionate complet pe infrastructura de calcul a AWS. SageMaker Training ajută, de asemenea, cercetătorii de date cu instrumente avansate, cum ar fi Debugger Amazon SageMaker și Profiler pentru a-și depana și analiza joburile de formare pe scară largă.
Pentru clienții cu bugete mici, echipe mici și termene strânse, fiecare concept nou și fiecare linie de cod rescrisă pentru a rula pe SageMaker îi face mai puțin productivi în ceea ce privește sarcinile lor de bază, și anume procesarea datelor și formarea modelelor ML. Ei doresc să scrie cod o singură dată în cadrul ales de ei și să poată trece fără probleme de la rularea codului în notebook-uri sau laptop-uri la rularea codului la scară folosind capabilitățile SageMaker.
Cu această nouă capacitate a SDK-ului SageMaker Python, oamenii de știință de date își pot integra codul ML pe platforma SageMaker Training în câteva minute. Trebuie doar să adăugați o singură linie de cod la codul dvs. ML, iar SageMaker vă înțelege în mod inteligent codul împreună cu seturile de date și configurarea mediului de lucru și îl rulează ca un job de instruire SageMaker. Apoi puteți profita de capacitățile cheie ale platformei SageMaker Training, cum ar fi capacitatea de a scala cu ușurință locurile de muncă și alte instrumente asociate, cum ar fi Debugger și Profiler. În această versiune, puteți rula codul Python local de învățare automată (ML) ca un job de instruire Amazon SageMaker cu un singur nod sau mai multe joburi paralele. Joburile de instruire distribuite (pe mai multe noduri) nu sunt acceptate de funcțiile de la distanță.
În această postare, vă arătăm cum să utilizați această nouă capacitate pentru a rula cod ML local ca un job de instruire SageMaker.
Prezentare generală a soluțiilor
Acum puteți rula codul dvs. ML scris în IDE sau notebook-ul dvs. ca un job de instruire SageMaker prin adnotarea funcției, care acționează ca un punct de intrare în baza de cod a utilizatorului, cu un simplu decorator. La invocare, această capacitate realizează automat un instantaneu al tuturor variabilelor, funcțiilor, pachetelor, variabilelor de mediu și altor cerințe de rulare asociate din codul dvs. ML, le serializează și le trimite ca un job de instruire SageMaker. Se integrează cu cel anunțat recent Caracteristica SageMaker Python SDK pentru setarea valorilor implicite pentru parametri. Această capacitate simplifică constructele SageMaker pe care trebuie să le învățați pentru a putea rula cod folosind SageMaker Training. Oamenii de știință de date își pot scrie, depana și repeta codul în orice IDE preferat (cum ar fi Amazon SageMaker Studio, notebook-uri, VS Code sau PyCharm). Când ești gata, poți să adnotați funcția dvs. Python cu @remote decorator și rulați-l ca un job SageMaker la scară.
Această capacitate ia obiecte Python open-source familiare ca argumente și rezultate. În plus, nu trebuie să înțelegeți gestionarea ciclului de viață al containerului și puteți pur și simplu să vă rulați încărcăturile de lucru în diferite contexte de calcul (cum ar fi un IDE local, Studio sau joburi de antrenament) cu cheltuieli de configurare minime. Pentru a rula orice cod local ca job SageMaker Training, această capacitate deduce configurațiile necesare pentru a rula joburi, cum ar fi Gestionarea identității și accesului AWS (IAM), cheia de criptare și configurația rețelei, din setările Studio sau IDE (care pot fi setările implicite) și le transmite platformei în mod implicit. Aveți flexibilitatea de a vă personaliza timpul de execuție în infrastructura gestionată SageMaker utilizând configurația dedusă sau de a le înlocui la nivel de SDK, transmițându-le ca argumente decoratorului.
Această nouă capacitate a SDK-ului SageMaker Python transformă codul dvs. ML într-un mediu de spațiu de lucru existent și orice cod de procesare a datelor și seturi de date asociate într-un job de instruire SageMaker. Această capacitate caută codul ML împachetat în interiorul unui @remote decorator și îl traduce automat într-o lucrare care rulează fie în Studio, fie într-un IDE local, cum ar fi PyCharm.
În secțiunile următoare, vom parcurge caracteristicile acestei noi capacități și cum să lansăm funcțiile Python ca joburi SageMaker Training.
Cerințe preliminare
Pentru a utiliza această nouă capacitate SageMaker Python SDK și a rula codul asociat cu această postare, aveți nevoie de următoarele cerințe preliminare:
- Un cont AWS care va conține toate resursele dvs. AWS
- Un rol IAM pentru a accesa SageMaker
- Acces la Studio sau la o instanță de notebook SageMaker sau la un IDE cum ar fi PyCharm
Utilizați SDK-ul de la blocnotesurile Studio și SageMaker
Puteți folosi această capacitate din Studio lansând un blocnotes și împachetând codul cu a @remote decorator în interiorul caietului. Mai întâi trebuie să importați funcția de la distanță folosind următorul cod:
from sagemaker.remote_function import remoteCând utilizați funcția de decorator, această capacitate va interpreta automat funcția codului dvs. și o va rula ca un job de instruire SageMaker.
De asemenea, puteți utiliza această capacitate dintr-o instanță de notebook SageMaker. Mai întâi trebuie să porniți o instanță de notebook, să deschideți Jupyter sau Jupyter Lab pe ea și să lansați un notebook. Apoi importați funcția de la distanță așa cum se arată în codul precedent și împachetați codul cu @remote decorator. Includem un exemplu despre cum să utilizați funcția de decorator și setările asociate mai târziu în această postare.
Utilizați SDK-ul din mediul dvs. local
De asemenea, puteți utiliza această capacitate din IDE-ul dvs. local. Ca o condiție prealabilă, trebuie să aveți Interfața liniei de comandă AWS (AWS CLI), SageMaker Python SDK și SDK AWS pentru Python (Boto3) instalat în mediul dvs. local. Trebuie să importați aceste biblioteci în codul dvs., să setați sesiunea SageMaker, să specificați setările și să vă decorați funcția cu @remote decorator. În următorul exemplu de cod, rulăm o funcție simplă de împărțire ca un job de instruire SageMaker:
import boto3
import sagemaker
from sagemaker.remote_function import remote sm_session = sagemaker.Session(boto_session=boto3.session.Session(region_name="us-west-2"))
settings = dict(
sagemaker_session=sm_session,
role=<IAM_ROLE_NAME>
instance_type="ml.m5.xlarge",
)
@remote(**settings)
def divide(x, y):
return x / y
if __name__ == "__main__":
print(divide(2, 3.0))Putem folosi o metodologie similară pentru a rula funcții avansate ca joburi de instruire, așa cum se arată în secțiunea următoare.
Lansați Python funcționează ca joburi SageMaker
Noua caracteristică SageMaker Python SDK vă permite să rulați funcții Python ca Locuri de munca SageMaker Training. Orice cod Python, cod de antrenament ML dezvoltat de oamenii de știință de date folosind IDE-urile locale preferate (PyCharm, VS Code), notebook-uri SageMaker sau notebook-uri Studio pot fi lansate ca un job SageMaker gestionat.
În încărcările de lucru ML care utilizează această capacitate, seturile de date asociate, dependențele și setările mediului de spațiu de lucru sunt serializate folosind codul ML și rulează ca un job SageMaker sincron și asincron.
Puteți adăuga a @remote adnotare de decorator la orice cod Python, inclusiv o funcție locală de procesare sau antrenament ML, pentru a-l lansa ca job gestionat SageMaker Training, profitând astfel de beneficiile de scară, performanță și costuri ale SageMaker. Acest lucru poate fi realizat cu modificări minime de cod prin adăugarea unui decorator la codul funcției Python. Invocarea la funcția decorată este rulată sincron, iar rularea funcției așteaptă până când lucrarea SageMaker este finalizată.
În exemplul următor, folosim @remote decorator pentru a lansa lucrări SageMaker în modul decorator folosind o instanță ml.m5.large. SageMaker folosește joburi de instruire pentru a lansa această funcție ca job gestionat.
from sagemaker.remote_function import remote
from numpy as np @remote(instance_type="ml.m5.large")
def matrix_multiply(a, b): return np.matmul(a, b) a = np.array([[1, 0], [0, 1]])
b = np.array([1, 2]) assert matrix_multiply(a, b) == np.array([1,2])De asemenea, puteți utiliza modul decorator pentru a lansa joburi SageMaker, pachete Python și dependențe. Puteți include variabile de mediu, cum ar fi VPC, subrețele și grupuri de securitate pentru a lansa joburi de instruire SageMaker în environment.yml fişier. Acest lucru le permite inginerilor și administratorilor ML să configureze aceste variabile de mediu, astfel încât oamenii de știință de date să se poată concentra pe construirea modelelor ML și să itereze mai rapid. Vezi următorul cod:
from sagemaker.remote_function import remote @remote(instance_type="ml.g4dn.xlarge",dependencies = "./environment.yml")
def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
... <TRUCNATED>
return os.path.join(s3_output_path, model_dir), eval_resultPoți să folosești RemoteExecutor pentru a lansa funcțiile Python ca joburi SageMaker în mod asincron. Executorul sondajează asincron joburile SageMaker Training pentru a actualiza starea jobului. The RemoteExecutor clasa este o implementare a concurente.future.Executor, care este utilizat pentru a trimite joburi SageMaker Training în mod asincron. Vezi următorul cod:
from sagemaker.remote_function import RemoteExecutor def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
...<TRUNCATED>
return os.path.join(s3_output_path, model_dir), eval_result with RemoteExecutor(instance_type="ml.g4dn.xlarge", dependencies = './requirements.txt') as e:
future = e.submit(train_hf_model, train_input_path,test_input_path,s3_output_path,
epochs, train_batch_size, eval_batch_size,warmup_steps,learning_rate)Personalizați mediul de rulare
Modul decorator și RemoteExecutor vă permit să definiți și să personalizați mediile de rulare pentru jobul SageMaker. Dependențele de rulare, inclusiv pachetele Python și variabilele de mediu pentru joburile SageMaker, pot fi specificate pentru a personaliza timpul de rulare. Pentru a rula codul Python local ca joburi gestionate de SageMaker, pachetul Python și dependențele trebuie să fie disponibile pentru SageMaker. Inginerii ML sau administratorii de știință a datelor pot configura configurații de rețea și securitate, cum ar fi VPC, subrețele și grupuri de securitate pentru joburi SageMaker, astfel încât oamenii de știință de date să poată utiliza aceste configurații gestionate central în timp ce lansează joburi SageMaker. Puteți folosi fie a requirements.txt dosar sau a Conda environment.yaml fișier.
Când dependențele sunt definite cu requirements.txt, pachetele vor fi instalate folosind pip în timpul de execuție a jobului. Dacă imaginea folosită pentru rularea jobului vine cu medii Conda, pachetele vor fi instalate în mediul Conda declarat a fi utilizat pentru joburi. Următorul cod arată un exemplu requirements.txt fișier:
datasets
transformers
torch
scikit-learn
s3fs==0.4.2
sagemaker>=2.148.0Îți poți trece Conda environment.yaml fișier pentru a crea mediul Conda în care ați dori să ruleze codul în timpul activității de instruire. Dacă imaginea utilizată pentru rularea jobului declară un mediu Conda în care să ruleze codul, vom actualiza mediul Conda declarat cu specificația dată. Următorul cod este un exemplu de a Conda environment.yaml fișier:
name: sagemaker_example
channels: - conda-forge
dependencies: - python=3.10 - pandas - pip: - sagemakerAlternativ, puteți seta dependencies=”auto_capture” pentru a permite SDK-ului SageMaker Python să captureze dependențele instalate în mediul activ Conda. Trebuie să aveți un mediu Conda activ pentru auto_capture a munci. Rețineți că există condiții prealabile pentru auto_capture a munci; vă recomandăm să transmiteți dependențele dvs. ca a requirement.txt or Conda environment.yml fișier așa cum este descris în secțiunea anterioară.
Pentru mai multe detalii, consultați Rulați codul local ca un loc de muncă SageMaker Training.
Configurații pentru joburile SageMaker
Setările legate de infrastructură pot fi descărcate într-un fișier de configurare pe care utilizatorii administratori l-ar putea ajuta să îl configureze. Trebuie să-l configurați o singură dată. Setările de infrastructură acoperă configurația rețelei, rolurile IAM, Serviciul Amazon de stocare simplă (Amazon S3) folder pentru date de intrare, ieșire și etichete. A se referi la Configurarea și utilizarea setărilor implicite cu SageMaker Python SDK pentru mai multe detalii.
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
Dependencies: path/to/requirements.txt
EnvironmentVariables: {"EnvVarKey": "EnvVarValue"}
ImageUri: 366666666666.dkr.ecr.us-west-2.amazonaws.com/my-image:latest
InstanceType: ml.m5.large
RoleArn: arn:aws:iam::366666666666:role/MyRole
S3KmsKeyId: somekmskeyid
S3RootUri: s3://my-bucket/my-project
SecurityGroupIds:
- sg123
Subnets:
- subnet-1234
Tags:
- {"Key": "someTagKey", "Value": "someTagValue"}
VolumeKmsKeyId: somekmskeyidPunerea în aplicare
Modelele de învățare profundă, cum ar fi PyTorch sau TensorFlow, pot fi, de asemenea, rulate în Studio, rulând codul ca un job de antrenament în blocnotes. Pentru a prezenta această capacitate în Studio, puteți clona acest depozit în Studio și puteți rula blocnotesul situat în GitHub repertoriu.
Acest exemplu demonstrează un caz de utilizare pentru clasificarea textului binar de la capăt la capăt. Folosim transformatoarele Hugging Face și biblioteca de seturi de date pentru a regla fin un transformator pre-antrenat pe clasificarea textului binar. În special, modelul pre-antrenat va fi reglat cu ajutorul Setul de date IMDb.
Când clonați depozitul, ar trebui să găsiți următoarele fișiere:
- config.yaml – Majoritatea argumentelor decoratorului pot fi descărcate în fișierul de configurare pentru a separa setările legate de infrastructură de baza de cod
- huggingface.ipynb – Acesta conține codul pentru a antrena un model HuggingFace pre-antrenat, care va fi reglat cu ajutorul setului de date IMDB
- cerințe.txt – Acest fișier conține toate dependențele pentru a rula funcția care va fi folosită în acest notebook pentru a rula codul și a rula antrenamentul de la distanță într-o instanță GPU ca job de antrenament
Când deschideți notebook-ul, vi se va solicita să configurați mediul notebook. Puteți selecta imaginea Data Science 3.0 cu nucleul Python 3 și ml.m5.large ca tip de instanță de lansare rapidă pentru rularea codului notebook-ului. Acest tip de instanță este semnificativ mai rapid în învârtirea unui mediu.
Lucrarea de instruire va fi rulată într-o instanță ml.g4dn.xlarge așa cum este definită în config.yaml fișier:
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
# role arn is not required if in SageMaker Notebook instance or SageMaker Studio
# Uncomment the following line and replace with the right execution role if in a local IDE
# RoleArn: <IAM_ROLE_ARN>
InstanceType: ml.g4dn.xlarge
Dependencies: ./requirements.txt requirements.txt dependențele de fișiere pentru a rula funcția de antrenare a modelului Hugging Face includ următoarele:
datasets
transformers
torch
scikit-learn
# lock s3fs to this specific version as more recent ones introduce dependency on aiobotocore, which is not compatible with botocore
s3fs==0.4.2
sagemaker>=2.148.0,<3Notebook-ul Hugging Face arată cum să rulați antrenamentul de la distanță prin intermediul @remote funcția, care este rulată sincron. Prin urmare, funcția rulată pentru antrenamentul modelului va aștepta până la finalizarea sarcinii de instruire SageMaker. Antrenamentul va fi rulat de la distanță cu o instanță GPU în care tipul instanței este definit în fișierul de configurare precedent.
După ce rulați jobul de antrenament, puteți rula restul celulelor din blocnotes pentru a inspecta valorile de evaluare și a clasifica textul pe modelul nostru antrenat.
De asemenea, puteți vedea starea jobului de antrenament care a fost declanșat de la distanță în instanța GPU pe tabloul de bord SageMaker navigând înapoi la consola SageMaker.
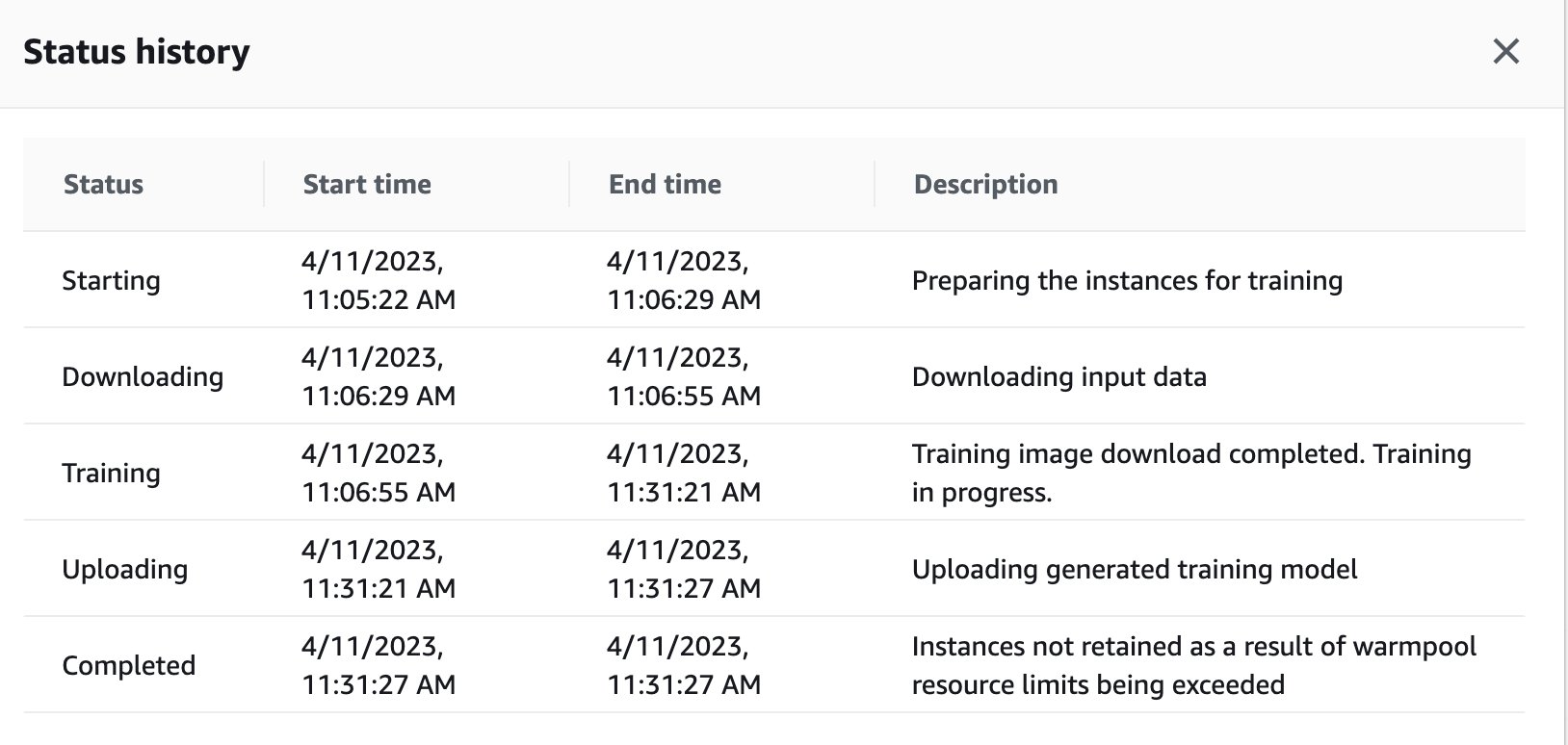
Imediat ce munca de instruire este finalizată, acesta continuă să ruleze instrucțiunile din caiet pentru evaluare și clasificare. Lucrări similare pot fi antrenate și rulate prin intermediul funcției de executare la distanță încorporată în notebook-urile Studio pentru a efectua rulările asincron.
Integrare cu experimentele SageMaker în cadrul unei funcții @remote
Puteți trece numele experimentului, numele executării și alți parametri în funcția de la distanță pentru a crea o rulare de experimente SageMaker. Următorul exemplu de cod importă numele experimentului, numele rulării și parametrii de înregistrat pentru fiecare rulare:
from sagemaker.remote_function import remote
from sagemaker.experiments.run import Run
# Define your remote function
@remote
def train(value_1, value_2, exp_name, run_name):
...
...
#Creates the experiment
with Run( experiment_name=exp_name, run_name=run_name, sagemaker_session=sagemaker_session
) as run:
...
...
#Define values for the parameters to log
run.log_parameter("param_1", value_1)
run.log_parameter("param_2", value_2)
...
...
#Define metrics to log
run.log_metric("metric_a", 0.5)
run.log_metric("metric_b", 0.1) # Invoke your remote function
train(1.0, 2.0, "my-exp-name", "my-run-name") În exemplul precedent, parametrii p1 și p2 sunt înregistrate în timp într-o buclă de antrenament. Parametrii comuni pot include dimensiunea lotului sau epocile. În exemplu, valorile A și B sunt înregistrate pentru o rulare în timp în interiorul unei bucle de antrenament. Valorile comune pot include acuratețea sau pierderea. Pentru mai multe informații, consultați Creați un experiment Amazon SageMaker.
Concluzie
În această postare, am introdus o nouă capacitate SageMaker Python SDK care le permite oamenilor de știință de date să ruleze codul ML în IDE-ul lor preferat ca joburi de formare SageMaker. Am discutat despre cerințele necesare pentru a utiliza această capacitate împreună cu caracteristicile sale. De asemenea, am arătat cum să utilizați această capacitate în Studio, instanțele de notebook SageMaker și IDE-ul dvs. local. În plus, am oferit exemple de cod pentru a demonstra cum să utilizați această capacitate. Ca pas următor, vă recomandăm să încercați această capacitate în IDE sau SageMaker, urmând exemple de cod la care se face referire în această postare.
Despre Autori
 Dipankar Patro este inginer de dezvoltare software la AWS SageMaker, inovând și construind soluții MLOps pentru a ajuta clienții să adopte soluții AI/ML la scară. Are un MS în Informatică și domeniile sale de interes sunt securitatea computerelor, sistemele distribuite și AI/ML.
Dipankar Patro este inginer de dezvoltare software la AWS SageMaker, inovând și construind soluții MLOps pentru a ajuta clienții să adopte soluții AI/ML la scară. Are un MS în Informatică și domeniile sale de interes sunt securitatea computerelor, sistemele distribuite și AI/ML.
 Farooq Sabir este arhitect senior de soluții specializat în inteligență artificială și învățare automată la AWS. El deține diplome de doctorat și master în inginerie electrică de la Universitatea din Texas din Austin și un master în informatică de la Georgia Institute of Technology. Are peste 15 ani de experiență în muncă și, de asemenea, îi place să predea și să îndrume studenții. La AWS, el îi ajută pe clienți să-și formuleze și să-și rezolve problemele de afaceri în știința datelor, învățarea automată, viziunea computerizată, inteligența artificială, optimizarea numerică și domeniile conexe. Cu sediul în Dallas, Texas, lui și familia lui le place să călătorească și să plece în călătorii lungi.
Farooq Sabir este arhitect senior de soluții specializat în inteligență artificială și învățare automată la AWS. El deține diplome de doctorat și master în inginerie electrică de la Universitatea din Texas din Austin și un master în informatică de la Georgia Institute of Technology. Are peste 15 ani de experiență în muncă și, de asemenea, îi place să predea și să îndrume studenții. La AWS, el îi ajută pe clienți să-și formuleze și să-și rezolve problemele de afaceri în știința datelor, învățarea automată, viziunea computerizată, inteligența artificială, optimizarea numerică și domeniile conexe. Cu sediul în Dallas, Texas, lui și familia lui le place să călătorească și să plece în călătorii lungi.
 Manoj Ravi este Senior Product Manager pentru Amazon SageMaker. Este pasionat de construirea de produse AI de ultimă generație și lucrează la software și instrumente pentru a facilita învățarea automată la scară largă pentru clienți. El deține un MBA de la Haas School of Business și un masterat în managementul sistemelor informaționale de la Universitatea Carnegie Mellon. În timpul liber, lui Manoj îi place să joace tenis și să facă fotografie de peisaj.
Manoj Ravi este Senior Product Manager pentru Amazon SageMaker. Este pasionat de construirea de produse AI de ultimă generație și lucrează la software și instrumente pentru a facilita învățarea automată la scară largă pentru clienți. El deține un MBA de la Haas School of Business și un masterat în managementul sistemelor informaționale de la Universitatea Carnegie Mellon. În timpul liber, lui Manoj îi place să joace tenis și să facă fotografie de peisaj.
 Shikhar Kwatra este arhitect specializat în soluții AI/ML la Amazon Web Services, lucrând cu un integrator global de sisteme de top. El a câștigat titlul de unul dintre cei mai tineri inventatori indieni, cu peste 500 de brevete în domeniile AI/ML și IoT. Shikhar ajută la arhitectura, construirea și menținerea unor medii cloud scalabile și rentabile pentru organizație și sprijină partenerul GSI în construirea de soluții strategice pentru industrie pe AWS. Lui Shikhar îi place să cânte la chitară, să compună muzică și să practice mindfulness în timpul său liber.
Shikhar Kwatra este arhitect specializat în soluții AI/ML la Amazon Web Services, lucrând cu un integrator global de sisteme de top. El a câștigat titlul de unul dintre cei mai tineri inventatori indieni, cu peste 500 de brevete în domeniile AI/ML și IoT. Shikhar ajută la arhitectura, construirea și menținerea unor medii cloud scalabile și rentabile pentru organizație și sprijină partenerul GSI în construirea de soluții strategice pentru industrie pe AWS. Lui Shikhar îi place să cânte la chitară, să compună muzică și să practice mindfulness în timpul său liber.
 Vikram Elango este un arhitect specialist în soluții AI/ML la AWS, cu sediul în Virginia, SUA. În prezent, el se concentrează pe AI generativă, LLM, inginerie promptă, optimizare a inferenței modelelor mari și scalarea ML în cadrul întreprinderilor. Vikram îi ajută pe clienții din industria financiară și de asigurări cu design și conducere gândită să construiască și să implementeze aplicații de învățare automată la scară. În timpul liber, îi place să călătorească, să facă drumeții, să gătească și să campeze.
Vikram Elango este un arhitect specialist în soluții AI/ML la AWS, cu sediul în Virginia, SUA. În prezent, el se concentrează pe AI generativă, LLM, inginerie promptă, optimizare a inferenței modelelor mari și scalarea ML în cadrul întreprinderilor. Vikram îi ajută pe clienții din industria financiară și de asigurări cu design și conducere gândită să construiască și să implementeze aplicații de învățare automată la scară. În timpul liber, îi place să călătorească, să facă drumeții, să gătească și să campeze.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Mintând viitorul cu Adryenn Ashley. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/run-your-local-machine-learning-code-as-amazon-sagemaker-training-jobs-with-minimal-code-changes/

