Crearea unor conducte robuste și reutilizabile de învățare automată (ML) poate fi un proces complex și consumator de timp. Dezvoltatorii își testează de obicei scripturile de procesare și antrenament la nivel local, dar conductele în sine sunt de obicei testate în cloud. Crearea și rularea unei conducte complete în timpul experimentării adaugă cheltuieli generale și costuri nedorite ciclului de viață al dezvoltării. În această postare, vă detaliem cum puteți utiliza Mod local Amazon SageMaker Pipelines pentru a rula conducte ML la nivel local pentru a reduce atât dezvoltarea conductei, cât și timpul de execuție, reducând în același timp costurile. După ce conducta a fost testată complet la nivel local, o puteți reporni cu ușurință Amazon SageMaker resurse gestionate cu doar câteva linii de modificări de cod.
Prezentare generală a ciclului de viață ML
Unul dintre principalii factori pentru noile inovații și aplicații în ML este disponibilitatea și cantitatea de date, împreună cu opțiuni de calcul mai ieftine. În mai multe domenii, ML s-a dovedit capabil să rezolve probleme nerezolvabile anterior cu tehnicile clasice de big data și analitice, iar cererea pentru știința datelor și practicieni ML crește constant. De la un nivel foarte înalt, ciclul de viață ML constă din multe părți diferite, dar construirea unui model ML constă de obicei din următorii pași generali:
- Curățarea și pregătirea datelor (ingineria caracteristicilor)
- Antrenamentul și tuningul modelului
- Evaluarea modelului
- Implementarea modelului (sau transformarea lotului)
În etapa de pregătire a datelor, datele sunt încărcate, masate și transformate în tipul de intrări sau caracteristici pe care modelul ML se așteaptă. Scrierea scripturilor pentru a transforma datele este de obicei un proces iterativ, în care buclele de feedback rapide sunt importante pentru a accelera dezvoltarea. În mod normal, nu este necesar să folosiți setul complet de date atunci când testați scripturile de inginerie a caracteristicilor, motiv pentru care puteți utiliza caracteristica mod local de procesare SageMaker. Acest lucru vă permite să rulați local și să actualizați codul în mod iterativ, folosind un set de date mai mic. Când codul final este gata, este trimis la jobul de procesare la distanță, care utilizează setul de date complet și rulează pe instanțe gestionate de SageMaker.
Procesul de dezvoltare este similar cu pasul de pregătire a datelor atât pentru pașii de pregătire a modelului, cât și pentru etapele de evaluare a modelului. Oamenii de știință de date folosesc caracteristica mod local de SageMaker Training pentru a repeta rapid cu seturi de date mai mici la nivel local, înainte de a utiliza toate datele dintr-un cluster gestionat de SageMaker de instanțe optimizate ML. Acest lucru accelerează procesul de dezvoltare și elimină costul rulării instanțelor ML gestionate de SageMaker în timpul experimentului.
Pe măsură ce maturitatea ML a unei organizații crește, puteți utiliza Pipelines Amazon SageMaker pentru a crea conducte ML care îmbină acești pași, creând fluxuri de lucru ML mai complexe care procesează, antrenează și evaluează modelele ML. SageMaker Pipelines este un serviciu complet gestionat pentru automatizarea diferiților pași ai fluxului de lucru ML, inclusiv încărcarea datelor, transformarea datelor, instruirea și reglarea modelului și implementarea modelului. Până de curând, ați putea să vă dezvoltați și să testați scripturile la nivel local, dar trebuia să vă testați conductele de ML în cloud. Acest lucru a făcut ca repetarea fluxului și formei conductelor ML să fie un proces lent și costisitor. Acum, cu funcția de mod local adăugată a SageMaker Pipelines, puteți să repetați și să testați conductele ML în mod similar cu modul în care testați și repetați scripturile de procesare și antrenament. Puteți rula și testa conductele pe mașina dvs. locală, folosind un mic subset de date pentru a valida sintaxa și funcționalitățile conductei.
Conducte SageMaker
SageMaker Pipelines oferă o modalitate complet automatizată de a rula fluxuri de lucru ML simple sau complexe. Cu SageMaker Pipelines, puteți crea fluxuri de lucru ML cu un SDK Python ușor de utilizat, apoi puteți vizualiza și gestiona fluxul de lucru folosind Amazon SageMaker Studio. Echipele dvs. de știință a datelor pot fi mai eficiente și pot scala mai rapid prin stocarea și reutilizarea pașilor fluxului de lucru pe care îi creați în SageMaker Pipelines. De asemenea, puteți utiliza șabloane predefinite care automatizează infrastructura și crearea depozitului pentru a construi, testa, înregistra și implementa modele în mediul dumneavoastră ML. Aceste șabloane sunt disponibile automat pentru organizația dvs. și sunt furnizate folosind Catalog de servicii AWS de produse.
SageMaker Pipelines aduce practici de integrare continuă și implementare continuă (CI/CD) în ML, cum ar fi menținerea parității între mediile de dezvoltare și producție, controlul versiunilor, testarea la cerere și automatizarea end-to-end, care vă ajută să scalați ML pe tot parcursul dvs. organizare. Practicienii DevOps știu că unele dintre principalele beneficii ale utilizării tehnicilor CI/CD includ o creștere a productivității prin componente reutilizabile și o creștere a calității prin testare automată, ceea ce duce la un ROI mai rapid pentru obiectivele dvs. de afaceri. Aceste beneficii sunt acum disponibile pentru practicanții MLOps prin utilizarea SageMaker Pipelines pentru a automatiza instruirea, testarea și implementarea modelelor ML. Cu modul local, acum puteți repeta mult mai rapid în timp ce dezvoltați scripturi pentru utilizare într-o conductă. Rețineți că instanțele de conducte locale nu pot fi vizualizate sau rulate în IDE-ul Studio; cu toate acestea, opțiuni suplimentare de vizualizare pentru conductele locale vor fi disponibile în curând.
SDK-ul SageMaker oferă un scop general configurarea modului local care permite dezvoltatorilor să ruleze și să testeze procesoare și estimatori acceptați în mediul lor local. Puteți utiliza formarea în mod local cu mai multe imagini cadru acceptate de AWS (TensorFlow, MXNet, Chainer, PyTorch și Scikit-Learn), precum și imagini pe care le furnizați dvs.
SageMaker Pipelines, care construiește un grafic aciclic direcționat (DAG) al pașilor de flux de lucru orchestrați, acceptă multe activități care fac parte din ciclul de viață ML. În modul local, sunt acceptați următorii pași:
- Procesarea etapelor de lucru – O experiență simplificată și gestionată pe SageMaker pentru a rula sarcini de lucru de procesare a datelor, cum ar fi ingineria caracteristicilor, validarea datelor, evaluarea modelului și interpretarea modelului
- Pașii muncii de formare – Un proces iterativ care învață un model să facă predicții prin prezentarea de exemple dintr-un set de date de antrenament
- Lucrări de reglare a hiperparametrilor – Un mod automat de a evalua și selecta hiperparametrii care produc cel mai precis model
- Pași de rulare condiționată – Un pas care oferă o rulare condiționată a ramurilor într-o conductă
- Pasul modelului – Folosind argumente CreateModel, acest pas poate crea un model pentru utilizare în etapele de transformare sau implementarea ulterioară ca punct final
- Transformați pașii muncii – O lucrare de transformare în lot care generează predicții din seturi mari de date și rulează inferențe atunci când nu este necesar un punct final persistent
- Pași eșuați – Un pas care oprește o rulare a conductei și marchează rularea ca eșuată
Prezentare generală a soluțiilor
Soluția noastră demonstrează pașii esențiali pentru a crea și rula SageMaker Pipelines în modul local, ceea ce înseamnă utilizarea CPU, RAM și resurse locale de disc pentru a încărca și rula pașii fluxului de lucru. Mediul dvs. local ar putea rula pe un laptop, folosind IDE-uri populare, cum ar fi VSCode sau PyCharm, sau ar putea fi găzduit de SageMaker folosind instanțele clasice de notebook.
Modul local permite oamenilor de știință de date să îmbine pașii, care pot include joburi de procesare, instruire și evaluare și să ruleze întregul flux de lucru la nivel local. După ce ați terminat testarea locală, puteți rula din nou conducta într-un mediu gestionat de SageMaker, înlocuind LocalPipelineSession obiect cu PipelineSession, care aduce coerență ciclului de viață ML.
Pentru acest eșantion de notebook, folosim un set de date standard disponibil public, the Set de date UCI Machine Learning Abalone. Scopul este de a antrena un model ML pentru a determina vârsta unui melc de abalone din măsurătorile sale fizice. În esență, aceasta este o problemă de regresie.
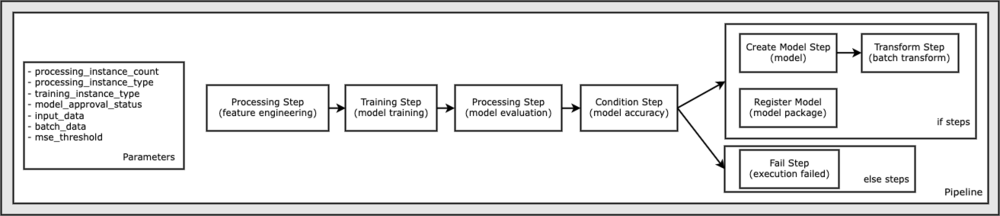
Tot codul necesar pentru a rula acest eșantion de notebook este disponibil pe GitHub în amazon-sagemaker-exemple repertoriu. În acest exemplu de notebook, fiecare pas al fluxului de lucru al conductei este creat independent și apoi conectat împreună pentru a crea conducta. Creăm următorii pași:
- Etapa de procesare (ingineria caracteristicilor)
- Etapa de antrenament (antrenament model)
- Etapa de procesare (evaluarea modelului)
- Etapa condiției (precizia modelului)
- Creați pasul modelului (modelul)
- Etapa de transformare (transformare în lot)
- Înregistrați pasul modelului (pachet model)
- Pas de eșec (execuție eșuată)
Următoarea diagramă ilustrează conducta noastră.
Cerințe preliminare
Pentru a urmări această postare, aveți nevoie de următoarele:
După ce aceste condiții preliminare sunt îndeplinite, puteți rula exemplul de blocnotes așa cum este descris în secțiunile următoare.
Construiește-ți conducta
În acest exemplu de notebook, folosim Modul Script SageMaker pentru majoritatea proceselor ML, ceea ce înseamnă că furnizăm codul Python real (script-urile) pentru a efectua activitatea și a transmite o referință la acest cod. Modul Script oferă o mare flexibilitate pentru a controla comportamentul în cadrul procesării SageMaker, permițându-vă să vă personalizați codul, în timp ce profitați de containerele prefabricate SageMaker, cum ar fi XGBoost sau Scikit-Learn. Codul personalizat este scris într-un fișier script Python folosind celule care încep cu comanda magică %%writefile, precum următorul:
%%writefile code/evaluation.py
Activatorul principal al modului local este LocalPipelineSession obiect, care este instanțiat din SDK-ul Python. Următoarele segmente de cod arată cum să creați o conductă SageMaker în modul local. Deși puteți configura o cale de date locală pentru mulți dintre pașii conductei locale, Amazon S3 este locația implicită pentru a stoca datele rezultate prin transformare. Noul LocalPipelineSession obiectul este transmis SDK-ului Python în multe dintre apelurile API ale fluxului de lucru SageMaker descrise în această postare. Observați că puteți utiliza local_pipeline_session variabilă pentru a prelua referințe la compartimentul implicit S3 și numele actual al regiunii.
Înainte de a crea pașii individuali ai conductei, setăm câțiva parametri utilizați de conductă. Unii dintre acești parametri sunt literali șir, în timp ce alții sunt creați ca tipuri speciale enumerate furnizate de SDK. Tastarea enumerată asigură că setările valide sunt furnizate conductei, cum ar fi aceasta, care este transmisă ConditionLessThanOrEqualTo pas mai jos:
mse_threshold = ParameterFloat(name="MseThreshold", default_value=7.0)
Pentru a crea un pas de procesare a datelor, care este folosit aici pentru a efectua ingineria caracteristicilor, folosim SKLearnProcessor pentru a încărca și transforma setul de date. Trecem pe lângă local_pipeline_session variabilă la constructorul de clasă, care indică pasului fluxului de lucru să ruleze în modul local:
În continuare, creăm primul nostru pas real al conductei, a ProcessingStep obiect, așa cum a fost importat din SDK-ul SageMaker. Argumentele procesorului sunt returnate de la un apel către SKLearnProcessor metoda run(). Acest pas al fluxului de lucru este combinat cu alți pași către sfârșitul notebook-ului pentru a indica ordinea de operare în conductă.
În continuare, oferim cod pentru a stabili un pas de instruire prin instanțierea mai întâi a unui estimator standard folosind SDK-ul SageMaker. Trecem la fel local_pipeline_session variabilă la estimator, numită xgb_train, ca sagemaker_session argument. Deoarece dorim să antrenăm un model XGBoost, trebuie să generăm un URI de imagine valid prin specificarea următorilor parametri, inclusiv cadrul și câțiva parametri de versiune:
Opțional, putem apela metode de estimare suplimentare, de exemplu set_hyperparameters(), pentru a oferi setări de hiperparametri pentru jobul de antrenament. Acum că avem un estimator configurat, suntem gata să creăm pasul propriu-zis de antrenament. Încă o dată, importăm TrainingStep clasa din biblioteca SageMaker SDK:
Apoi, construim un alt pas de procesare pentru a efectua evaluarea modelului. Acest lucru se realizează prin crearea unui ScriptProcessor instanță și trecând de local_pipeline_session obiect ca parametru:
Pentru a permite implementarea modelului instruit, fie la a Punct final în timp real SageMaker sau la o transformare în lot, trebuie să creăm un Model obiect prin transmiterea artefactelor modelului, a URI-ului de imagine adecvat și, opțional, a codului nostru de inferență personalizat. Apoi trecem asta Model obiect la a ModelStep, care se adaugă la conducta locală. Vezi următorul cod:
Apoi, creăm un pas de transformare în lot în care trimitem un set de vectori de caracteristici și efectuăm inferențe. Mai întâi trebuie să creăm un Transformer obiect și trece local_pipeline_session parametru la acesta. Apoi creăm un TransformStep, trecând argumentele necesare și adăugați acest lucru la definiția conductei:
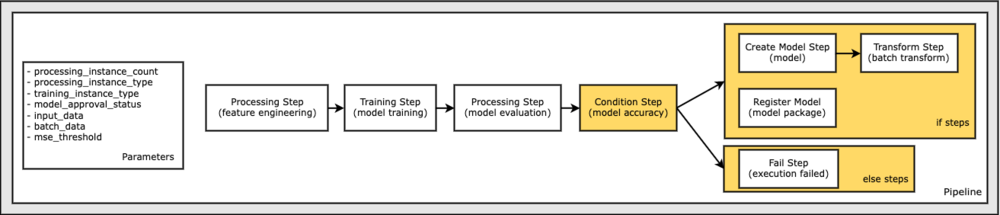
În cele din urmă, dorim să adăugăm o condiție de ramificare în fluxul de lucru, astfel încât să rulăm transformarea lotului doar dacă rezultatele evaluării modelului îndeplinesc criteriile noastre. Putem indica acest condițional adăugând a ConditionStep cu un anumit tip de condiție, cum ar fi ConditionLessThanOrEqualTo. Apoi enumerăm pașii pentru cele două ramuri, definind în esență ramurile if/else sau true/false ale conductei. Pașii if_prevăzuți în ConditionStep (step_create_model, transformare_pas) sunt rulate ori de câte ori condiția se evaluează la True.
Următoarea diagramă ilustrează această ramură condiționată și pașii asociați dacă/altfel. Se rulează o singură ramură, pe baza rezultatului etapei de evaluare a modelului în comparație cu etapa de condiție.
Acum că avem toți pașii noștri definiți și instanțele de clasă subiacente create, le putem combina într-o conductă. Oferim câțiva parametri și definim în mod esențial ordinea de funcționare prin simpla enumerare a pașilor în ordinea dorită. Rețineți că TransformStep nu este afișat aici deoarece este ținta pasului condiționat și a fost furnizat ca argument pentru pasul ConditionalStep mai devreme.
Pentru a rula conducta, trebuie să apelați două metode: pipeline.upsert(), care încarcă conducta în serviciul de bază și pipeline.start(), care începe să ruleze conducta. Puteți utiliza diverse alte metode pentru a interoga starea rulării, a enumera pașii conductei și multe altele. Deoarece am folosit sesiunea pipeline în modul local, toți acești pași sunt executați local pe procesorul dvs. Ieșirea celulei de sub metoda de pornire arată rezultatul din conductă:
Ar trebui să vedeți un mesaj în partea de jos a ieșirii celulei similar cu următorul:
Pipeline execution d8c3e172-089e-4e7a-ad6d-6d76caf987b7 SUCCEEDED
Reveniți la resursele gestionate
După ce am confirmat că conducta funcționează fără erori și suntem mulțumiți de fluxul și forma conductei, putem recrea conducta, dar cu resursele gestionate de SageMaker și să o rulăm din nou. Singura modificare necesară este utilizarea PipelineSession obiect în loc de LocalPipelineSession:
din sagemaker.workflow.pipeline_context import LocalPipelineSessionfrom sagemaker.workflow.pipeline_context import PipelineSession
local_pipeline_session = LocalPipelineSession()pipeline_session = PipelineSession()
Acest lucru informează serviciul să ruleze fiecare pas care face referire la acest obiect de sesiune pe resursele gestionate SageMaker. Având în vedere modificarea mică, ilustrăm doar modificările de cod necesare în următoarea celulă de cod, dar aceeași modificare ar trebui implementată în fiecare celulă folosind local_pipeline_session obiect. Schimbările sunt, totuși, identice în toate celulele, deoarece doar înlocuim local_pipeline_session obiect cu pipeline_session obiect.
După ce obiectul sesiune local a fost înlocuit peste tot, recreăm conducta și o rulăm cu resursele gestionate de SageMaker:
A curăța
Dacă doriți să păstrați mediul Studio ordonat, puteți utiliza următoarele metode pentru a șterge conducta SageMaker și modelul. Codul complet poate fi găsit în eșantion caiet.
Concluzie
Până de curând, puteai folosi caracteristica mod local a SageMaker Processing și SageMaker Training pentru a repeta scripturile de procesare și antrenare la nivel local, înainte de a le rula pe toate datele cu resursele gestionate de SageMaker. Cu noua caracteristică de mod local a SageMaker Pipelines, practicienii ML pot aplica acum aceeași metodă atunci când iterează pe conductele lor ML, îmbinând diferitele fluxuri de lucru ML. Când conducta este gata pentru producție, rularea acestuia cu resurse gestionate SageMaker necesită doar câteva linii de modificări de cod. Acest lucru reduce timpul de rulare a conductei în timpul dezvoltării, ceea ce duce la o dezvoltare mai rapidă a conductei cu cicluri de dezvoltare mai rapide, reducând în același timp costul resurselor gestionate de SageMaker.
Pentru a afla mai multe, vizitați Pipelines Amazon SageMaker or Utilizați SageMaker Pipelines pentru a vă rula joburile la nivel local.
Despre autori
 Paul Hargis și-a concentrat eforturile pe învățarea automată la mai multe companii, inclusiv AWS, Amazon și Hortonworks. Îi place să construiască soluții tehnologice și să-i învețe pe oameni cum să profite la maximum de ele. Înainte de rolul său la AWS, a fost arhitect principal pentru Amazon Exports and Expansions, ajutând amazon.com să îmbunătățească experiența pentru cumpărătorii internaționali. Lui Paul îi place să ajute clienții să-și extindă inițiativele de învățare automată pentru a rezolva problemele din lumea reală.
Paul Hargis și-a concentrat eforturile pe învățarea automată la mai multe companii, inclusiv AWS, Amazon și Hortonworks. Îi place să construiască soluții tehnologice și să-i învețe pe oameni cum să profite la maximum de ele. Înainte de rolul său la AWS, a fost arhitect principal pentru Amazon Exports and Expansions, ajutând amazon.com să îmbunătățească experiența pentru cumpărătorii internaționali. Lui Paul îi place să ajute clienții să-și extindă inițiativele de învățare automată pentru a rezolva problemele din lumea reală.
 Niklas Palm este arhitect de soluții la AWS din Stockholm, Suedia, unde ajută clienții din nordici să aibă succes în cloud. Este deosebit de pasionat de tehnologiile fără server împreună cu IoT și învățarea automată. În afara muncii, Niklas este un amator de schi fond și snowboarder, precum și un cazan principal de ouă.
Niklas Palm este arhitect de soluții la AWS din Stockholm, Suedia, unde ajută clienții din nordici să aibă succes în cloud. Este deosebit de pasionat de tehnologiile fără server împreună cu IoT și învățarea automată. În afara muncii, Niklas este un amator de schi fond și snowboarder, precum și un cazan principal de ouă.
 Kirit Thadaka este un arhitect de soluții ML care lucrează în echipa SageMaker Service SA. Înainte de a se alătura AWS, Kirit a lucrat în startup-uri AI în stadiu incipient, urmat de o perioadă de consultanță în diferite roluri în cercetarea AI, MLOps și conducere tehnică.
Kirit Thadaka este un arhitect de soluții ML care lucrează în echipa SageMaker Service SA. Înainte de a se alătura AWS, Kirit a lucrat în startup-uri AI în stadiu incipient, urmat de o perioadă de consultanță în diferite roluri în cercetarea AI, MLOps și conducere tehnică.

