În era datelor, organizațiile folosesc din ce în ce mai mult lacurile de date pentru a stoca și analiza cantități mari de date structurate și nestructurate. Lacurile de date oferă un depozit centralizat pentru date din diverse surse, permițând organizațiilor să deblocheze informații valoroase și să conducă luarea deciziilor bazate pe date. Cu toate acestea, pe măsură ce volumele de date continuă să crească, optimizarea aspectului și organizării datelor devine crucială pentru interogări și analize eficiente.
Una dintre provocările cheie ale lacurilor de date este potențialul de performanță lentă a interogărilor, în special atunci când se lucrează cu seturi de date mari. Acest lucru poate fi atribuit unor factori precum aspectul ineficient al datelor, care are ca rezultat scanarea excesivă a datelor și utilizarea ineficientă a resurselor de calcul. Pentru a face față acestei provocări, practicile obișnuite precum partiționarea și compartimentarea pot îmbunătăți semnificativ performanța interogărilor și pot reduce costurile de calcul.
partiţionarea este o tehnică care împarte un set mare de date în părți mai mici, mai ușor de gestionat, pe baza unor criterii specifice, cum ar fi data, regiunea sau categoria de produs. Prin partiționarea datelor, interogările analitice din aval pot sări peste partițiile irelevante, reducând cantitatea de date care trebuie scanate și procesate. Puteți utiliza coloanele de partiții din clauza WHERE din interogări pentru a scana numai partițiile specifice de care are nevoie interogarea dvs. Acest lucru poate duce la durate de execuție a interogărilor mai rapide și la o utilizare mai eficientă a resurselor. Funcționează bine mai ales când coloanele cu cardinalitate scăzută sunt alese ca cheie.
Ce se întâmplă dacă ai o coloană cu cardinalitate ridicată pe care uneori trebuie să o filtrezi după clienți VIP? Fiecare client este de obicei identificat cu un ID, care poate fi milioane. Partiționarea nu este potrivită pentru coloane cu cardinalitate atât de mare, deoarece ajungeți cu fișiere mici, filtrare lentă a partițiilor și Serviciul Amazon de stocare simplă Costul API (Amazon S3) (se creează un prefix S3 pe valoarea coloanei partiției). Deși puteți utiliza partiționarea cu o cheie naturală, cum ar fi orașul sau statul, pentru a restrânge setul de date într-o anumită măsură, este totuși necesar să interogați între partițiile bazate pe dată dacă datele sunt serii cronologice.
Aici e locul găleată intră în joc. Bucketing se asigură că toate rândurile cu aceleași valori ale uneia sau mai multor coloane ajung în același fișier. În loc de un fișier pe valoare, cum ar fi partiționarea, o funcție hash este utilizată pentru a distribui valorile în mod egal într-un număr fix de fișiere. Prin organizarea datelor în acest fel, puteți efectua o filtrare eficientă, deoarece trebuie procesate doar gălețile relevante, reducând și mai mult cheltuielile de calcul.
Există mai multe opțiuni pentru implementarea bucketing-ului pe AWS. O abordare este folosirea Amazon Atena Instrucțiunea CREATE TABLE AS SELECT (CTAS), care vă permite să creați un tabel grupat direct dintr-o interogare. Alternativ, puteți utiliza AWS Adeziv pentru Apache Spark, care oferă suport încorporat pentru configurațiile de compartimentare în timpul procesului de transformare a datelor. AWS Glue vă permite să definiți parametrii de compartimentare, cum ar fi numărul de compartimente și coloanele pe care trebuie să grupați, oferind un aspect de date optimizat pentru interogări eficiente cu Athena.
În această postare, discutăm despre cum să implementăm bucketing pe lacurile de date AWS, inclusiv utilizarea declarației Athena CTAS și AWS Glue pentru Apache Spark. De asemenea, acoperim găleți pentru mesele Apache Iceberg.
Exemplu de caz de utilizare
În această postare, utilizați un set de date public, the Baza de date integrată a suprafețelor NOAA. Analiștii de date execută interogări unice pentru date în ultimii 5 ani prin Athena. Majoritatea interogărilor sunt pentru anumite stații cu anumite tipuri de rapoarte. Interogările trebuie finalizate în 10 secunde, iar costul trebuie optimizat cu atenție. În acest scenariu, sunteți un inginer de date responsabil pentru optimizarea performanței interogărilor și a costurilor.
De exemplu, dacă un analist dorește să recupereze date pentru o anumită stație (de exemplu, ID-ul stației 123456) cu un anumit tip de raport (de exemplu, CRN01), interogarea poate arăta ca următoarea interogare:
În cazul bazei de date integrate de suprafață NOAA, station_id coloana este probabil să aibă o cardinalitate mare, cu numeroși identificatori unici de stație. Pe de altă parte, cel report_type coloana poate avea o cardinalitate relativ scăzută, cu un set limitat de tipuri de rapoarte. Având în vedere acest scenariu, ar fi o idee bună să partiți datele prin report_type și găleată-l pe lângă station_id.
Cu această strategie de partiționare și compartimentare, Athena poate elimina mai întâi partițiile pentru tipurile de rapoarte irelevante și apoi poate scana numai compartimentele din partiția relevantă care se potrivesc cu ID-ul stației specificate, reducând semnificativ cantitatea de date procesate și accelerând timpul de execuție a interogărilor. Această abordare nu numai că îndeplinește cerința de performanță a interogării, dar ajută și la optimizarea costurilor prin reducerea la minimum a cantității de date scanate și facturate pentru fiecare interogare.
În această postare, examinăm modul în care performanța interogărilor este afectată de aspectul datelor, în special de compartimentarea. De asemenea, comparăm trei moduri diferite de a realiza clapeta. Următorul tabel reprezintă condițiile pentru crearea tabelelor.
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | glue_bucketed | athena_bucketed_iceberg |
| Format | CSV | parchet | parchet | parchet | parchet |
| Comprimare | N / A | Vioi | Vioi | Vioi | Vioi |
| Creat prin | N / A | Athena CTAS | Athena CTAS | Lipici ETL | Athena CTAS cu Iceberg |
| Motor | N / A | Trino | Trino | Apache Spark | Apache Iceberg |
| Este compartimentat? | Da, dar cu alt mod | Da | Da | Da | Da |
| Este găleată? | Nu | Nu | Da | Da | Da |
noaa_remote_original este împărțită de year coloana, dar nu de către report_type coloană. Acest rând reprezintă dacă tabelul este partiționat de coloanele reale care sunt utilizate în interogări.
Tabelul de referință
Pentru această postare, creați mai multe tabele cu condiții diferite: unele fără bucketing și altele cu bucketing, pentru a prezenta caracteristicile de performanță ale bucketing. Mai întâi, să creăm un tabel original folosind datele NOAA. În pașii următori, ingerați date din acest tabel pentru a crea tabele de testare.
Există mai multe moduri de a defini o definiție de tabel: rularea DDL, un crawler AWS Glue, API-ul AWS Glue Data Catalog și așa mai departe. În acest pas, rulați DDL prin consola Athena.
Parcurgeți următorii pași pentru a crea "bucketing_blog"."noaa_remote_original" tabel din Catalogul de date:
- Deschide consola Athena.
- În editorul de interogări, rulați următorul DDL pentru a crea o nouă bază de date AWS Glue:
- Pentru Baza de date în Date, alege
bucketing_blogpentru a seta baza de date curentă. - Rulați următorul DDL pentru a crea tabelul original:
Deoarece datele sursă au câmpuri citate, folosim OpenCSVSerde în loc de implicit LazySimpleSerde.
Aceste fișiere CSV au un rând de antet, pe care îi spunem Athenei să o săriască prin adăugare skip.header.line.count și setați valoarea la 1.
Pentru mai multe detalii, consultați OpenCSVSerDe pentru procesarea CSV.
- Rulați următorul DDL pentru a adăuga partiții. Adăugăm partiții numai pentru 5 ani din 124 de ani, în funcție de cerințele cazului de utilizare:
- Rulați următorul DML pentru a verifica dacă puteți interoga cu succes datele:
Acum sunteți gata să începeți să interogați tabelul original pentru a examina performanța de bază.
- Rulați o interogare pe tabelul inițial pentru a evalua performanța interogării ca punct de referință. Următoarea interogare selectează înregistrări pentru cinci stații specifice cu tip de raport
CRN05: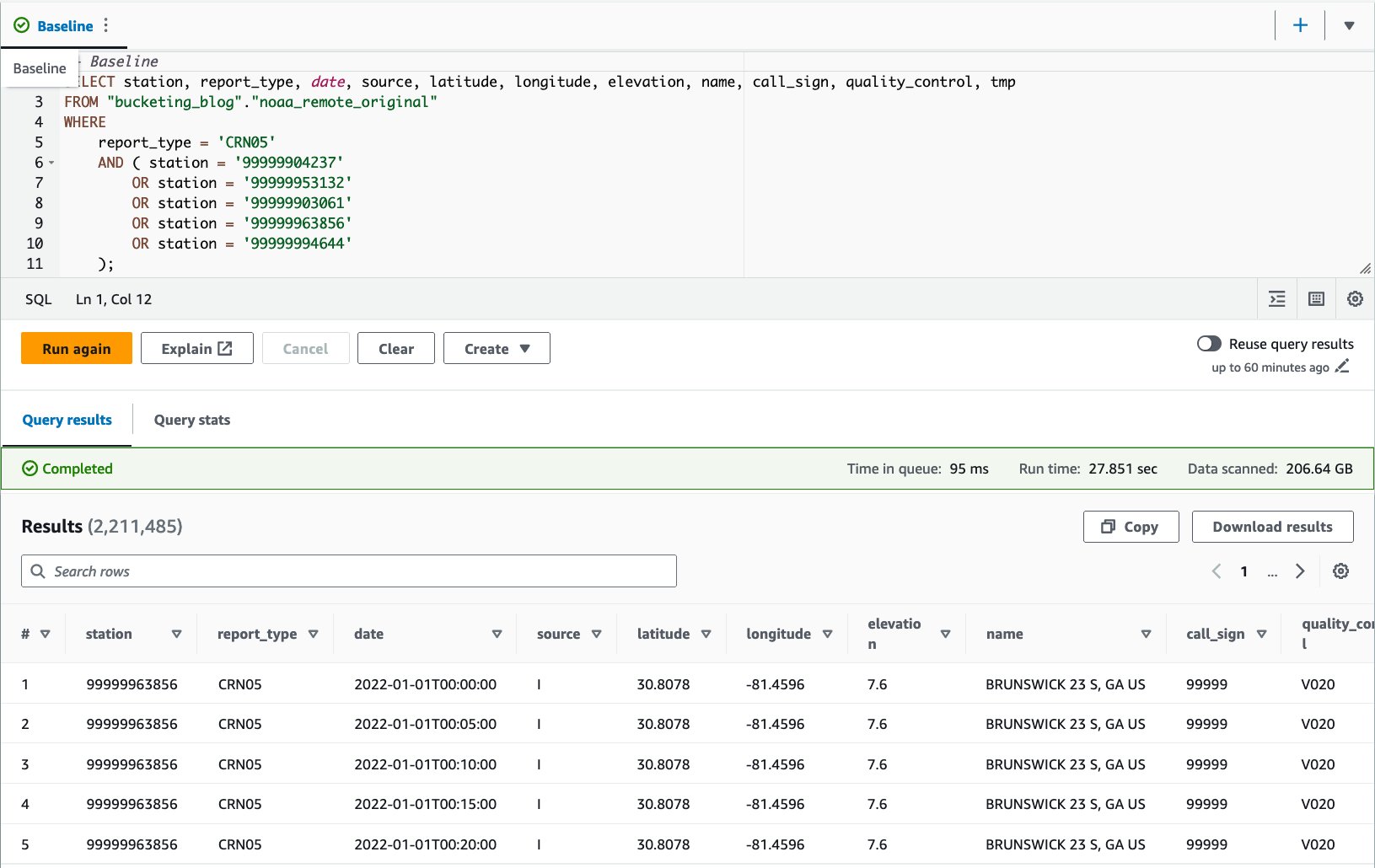
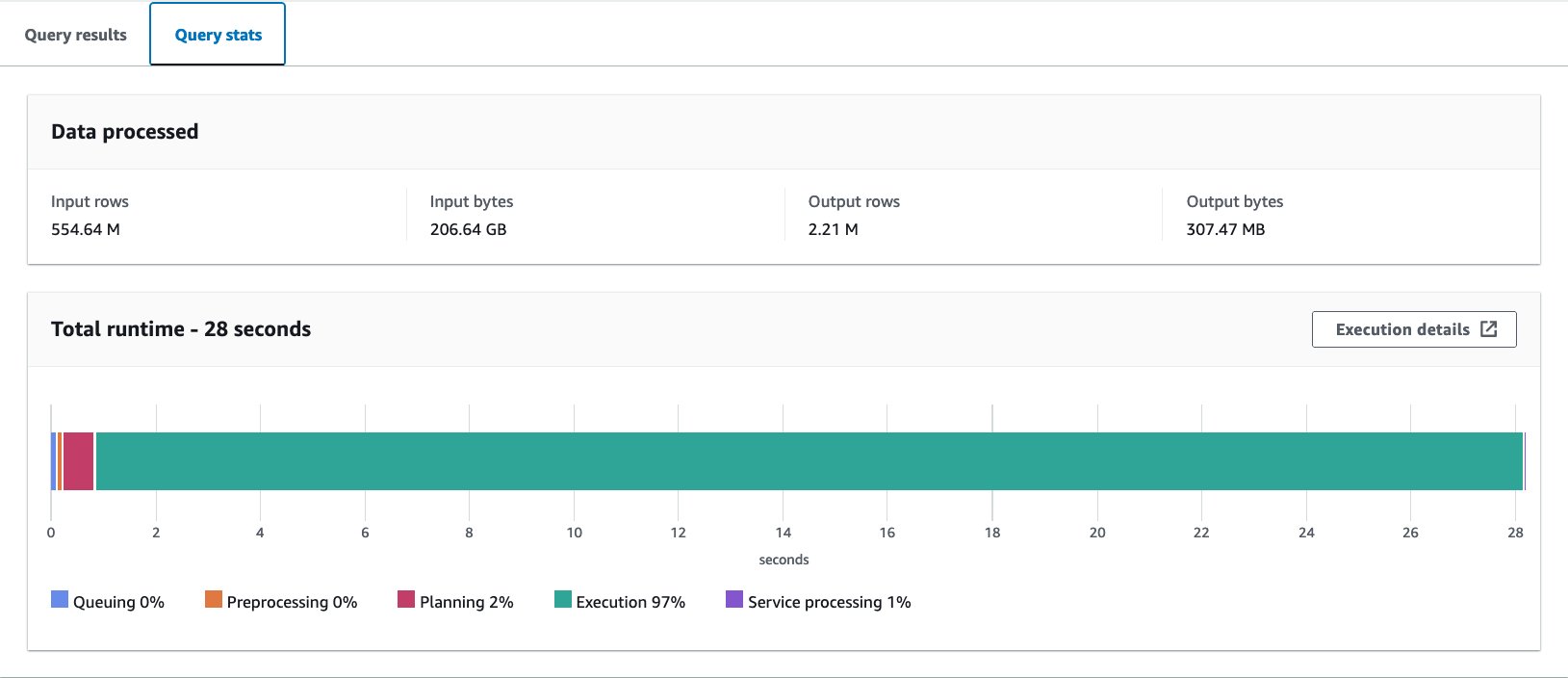
Am executat această interogare de 10 ori. Durata medie de rulare a interogărilor pentru 10 interogări este de 27.6 secunde, ceea ce este mult mai mare decât ținta noastră de 10 secunde, iar 155.75 GB de date sunt scanate pentru a returna 1.65 milioane de înregistrări. Aceasta este performanța de bază a tabelului brut original. Este timpul să începeți să optimizați aspectul datelor din această linie de bază.
Apoi, creați tabele cu condiții diferite față de originalul: unul fără compartimentare și unul cu compartimentare și le comparați.
Optimizați aspectul datelor folosind Athena CTAS
În această secțiune, folosim o interogare Athena CTAS pentru a optimiza aspectul datelor și formatul acesteia.
Mai întâi, să creăm un tabel cu partiționare, dar fără compartimentare. Noul tabel este împărțit după coloană report_type deoarece majoritatea interogărilor așteptate folosesc această coloană în clauza WHERE, iar obiectele sunt stocate ca Parquet cu compresie Snappy.
- Deschideți editorul de interogări Athena.
- Rulați următoarea interogare, furnizând propriul dvs. bucket S3 și prefix:
Datele dvs. ar trebui să arate ca următoarele capturi de ecran.
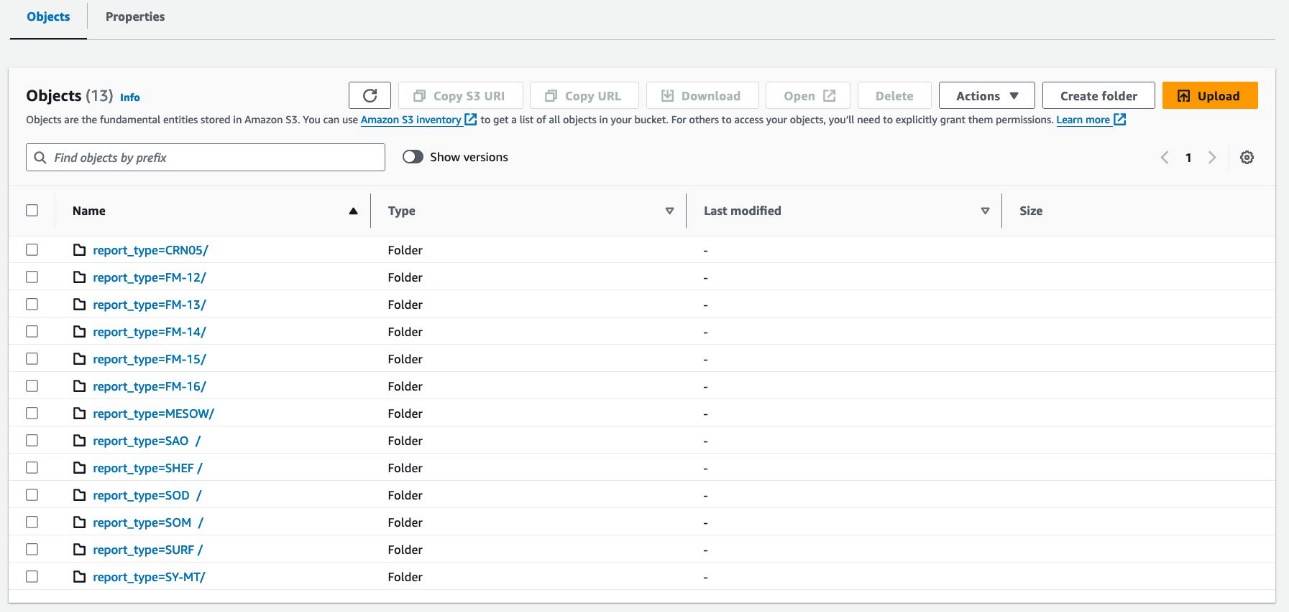
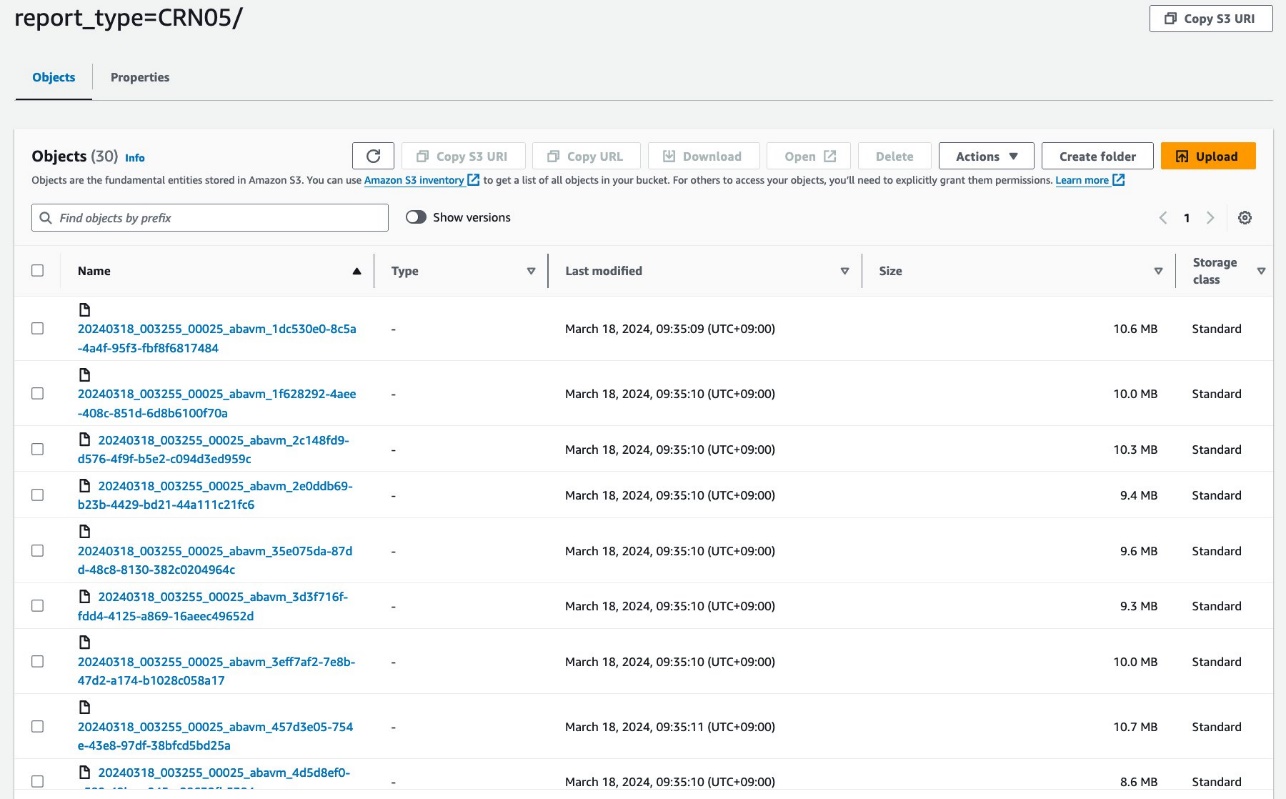
Există 30 de fișiere sub partiție.
Apoi, creați un tabel cu compartimentare în stil Hive. Numărul de găleți trebuie reglat cu atenție prin experimente pentru propriul caz de utilizare. În general, cu cât aveți mai multe găleți, cu atât granularitatea este mai mică, ceea ce ar putea duce la o performanță mai bună. Pe de altă parte, prea multe fișiere mici pot introduce ineficiență în planificarea și procesarea interogărilor. De asemenea, compartimentarea funcționează numai dacă interogați câteva valori ale cheii de compartimentare. Cu cât adăugați mai multe valori la interogarea dvs., cu atât este mai probabil să ajungeți să citiți toate compartimentele.
Următoarea este interogarea de bază pentru optimizare:
În acest exemplu, tabelul va fi împărțit în 16 găleți de o coloană cu cardinalitate ridicată (station), care ar trebui să fie utilizat pentru clauza WHERE din interogare. Toate celelalte condiții rămân aceleași. Interogarea de bază are cinci valori în ID-ul stației și vă așteptați ca interogările să aibă cel mult în jurul acestui număr, ceea ce este suficient de puțin decât numărul de compartimente, deci 16 ar trebui să funcționeze bine. Este posibil să specificați un număr mai mare de compartimente, dar CTAS nu poate fi utilizat dacă numărul total de partiții depășește 100.
- Rulați următoarea interogare:
Interogarea creează obiecte S3 organizate așa cum se arată în următoarele capturi de ecran.

Aspectul la nivel de tabel arată exact același între athena_non_bucketed și athena_bucketed: există 13 partiții în fiecare tabel. Diferența este numărul de obiecte de sub partiții. Există 16 obiecte (găleți) pe partiție, de aproximativ 10–25 MB fiecare în acest caz. Numărul de compartimente este constant la valoarea specificată, indiferent de cantitatea de date, dar dimensiunea compartimentului depinde de cantitatea de date.
Acum sunteți gata să interogați fiecare tabel pentru a evalua performanța interogărilor. Interogarea va selecta înregistrări cu cinci stații specifice și tip de raport CRN05 în ultimii 5 ani. Deși nu puteți vedea ce date ale unei anumite stații se află în ce găleată, acestea au fost calculate și localizate corect de către Athena.
- Interogați tabelul negrupat cu următoarea instrucțiune:

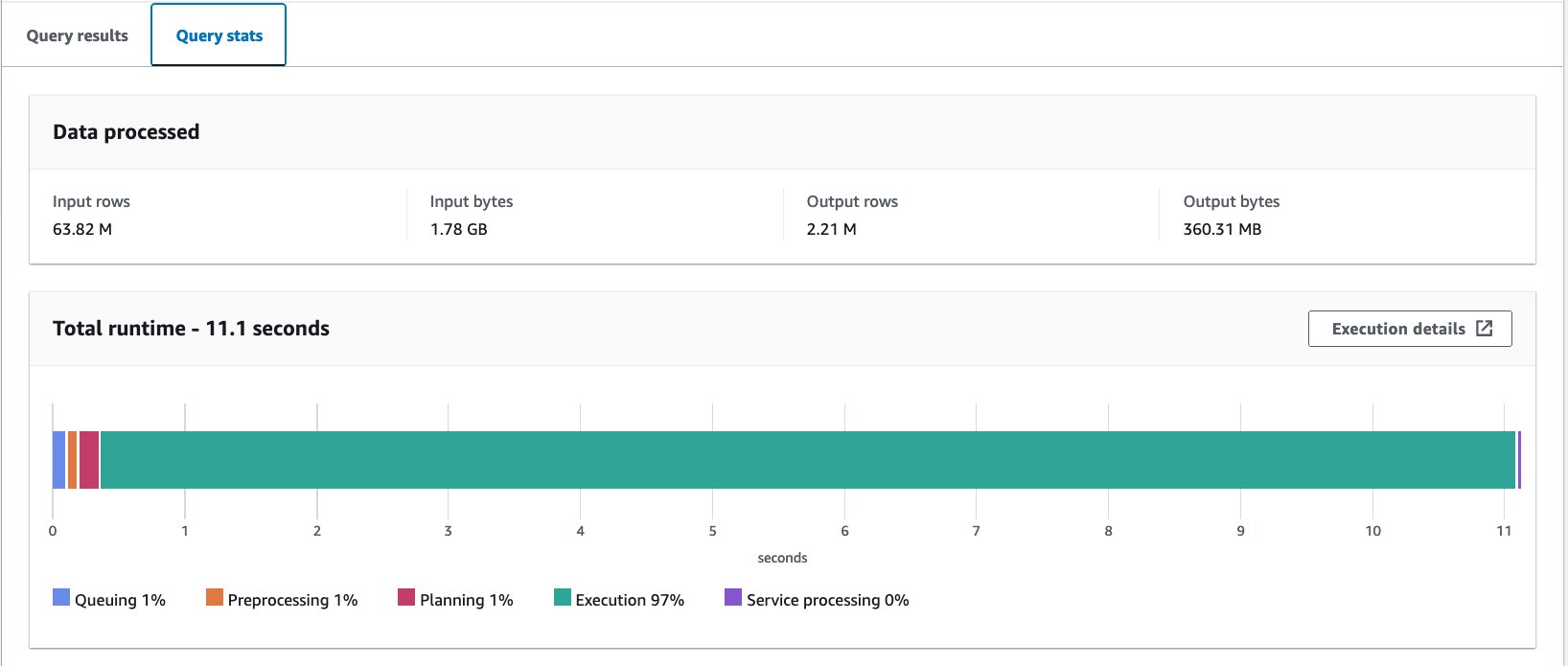
Am executat această interogare de 10 ori. Durata medie de rulare a celor 10 interogări este de 10.95 secunde, iar 358 MB de date sunt scanate pentru a returna 2.21 milioane de înregistrări. Atât durata de rulare, cât și dimensiunea scanării au fost reduse semnificativ, deoarece ați partiționat datele și acum puteți citi doar o partiție în care sunt omise 12 partiții din 13. În plus, cantitatea de date scanate a scăzut de la 206 GB la 360 MB, ceea ce reprezintă o reducere de 99.8%. Acest lucru nu se datorează doar partiționării, ci și din cauza schimbării formatului său la Parquet și compresiei cu Snappy.
- Interogați tabelul grupat cu următoarea declarație:
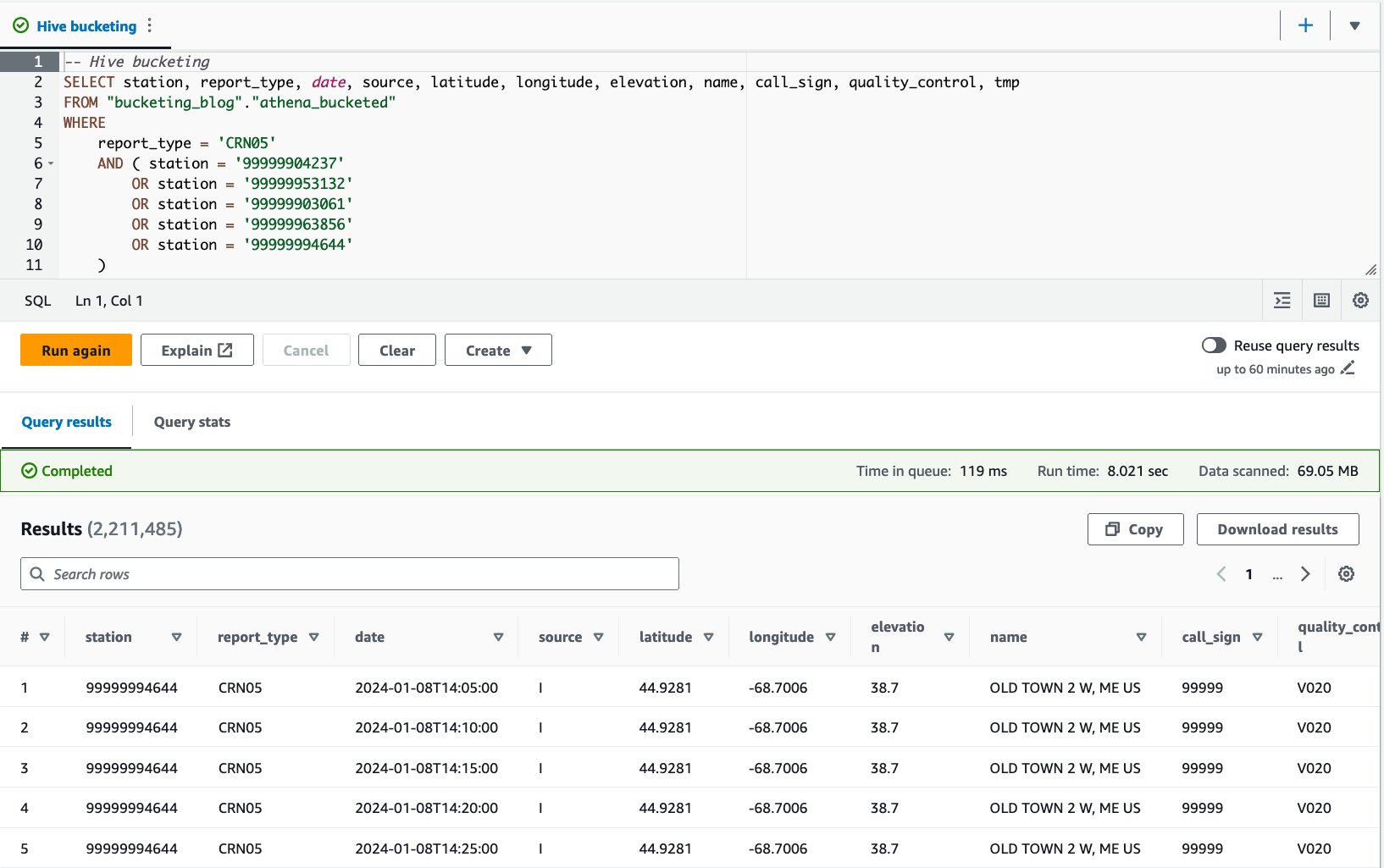
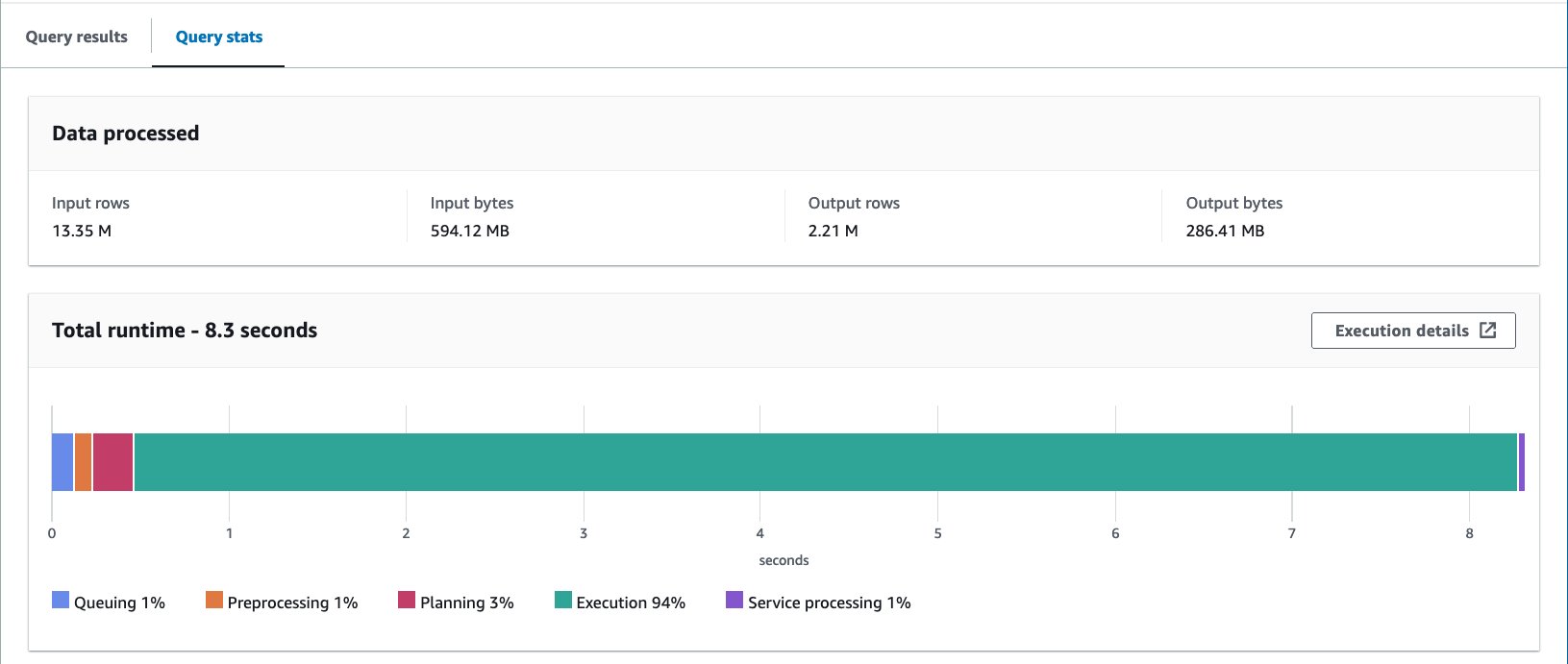
Am executat această interogare de 10 ori. Durata medie de rulare a celor 10 interogări este de 7.82 secunde, iar 69 MB de date sunt scanate pentru a returna 2.21 milioane de înregistrări. Aceasta înseamnă o reducere a duratei medii de rulare de la 10.95 la 7.82 secunde (-29%) și o reducere dramatică a datelor scanate de la 358 MB la 69 MB (-81%) pentru a returna același număr de înregistrări în comparație cu tabelul fără compartimente. . În acest caz, atât timpul de rulare, cât și datele scanate au fost îmbunătățite prin bucketing. Aceasta înseamnă că gruparea a contribuit nu numai la performanță, ci și la reducerea costurilor.
Considerații
După cum sa menționat mai devreme, dimensionați cu atenție grupul pentru a maximiza performanța interogării. Bucketing-ul funcționează numai dacă interogați câteva valori ale cheii de bucketing. Luați în considerare crearea mai multor compartimente decât numărul de valori așteptat în interogarea reală.
În plus, o interogare Athena CTAS este limitată pentru a crea până la 100 de partiții simultan. Dacă aveți nevoie de un număr mare de partiții, poate doriți să utilizați AWS Glue Extragere, transformare și încărcare (ETL), deși există o soluție pentru a împărți în mai multe instrucțiuni SQL.
Optimizați aspectul datelor folosind AWS Glue ETL
Apache Spark este un cadru de procesare distribuită open source care permite ETL flexibil cu PySpark, Scala și Spark SQL. Vă permite să partiționați și să grupați datele în funcție de cerințele dvs. Spark are mai multe opțiuni de reglare pentru a accelera lucrările. Puteți automatiza și monitoriza fără efort lucrările Spark. În această secțiune, folosim joburi AWS Glue ETL pentru a rula codul Spark pentru a optimiza aspectul datelor.
Spre deosebire de compartimentarea Athena, AWS Glue ETL utilizează compartimentarea bazată pe Spark ca algoritm de compartimentare. Tot ce trebuie să faceți este să adăugați următoarea proprietate a tabelului pe tabel: bucketing_format = 'spark'. Pentru detalii despre această proprietate a tabelului, consultați Compartimentare și găleată în Athena.
Parcurgeți următorii pași pentru a crea un tabel cu compartimentare prin AWS Glue ETL:
- Pe consola AWS Glue, alegeți Locuri de muncă ETL în panoul de navigare.
- Alege Creați loc de muncă Și alegeți ETL vizual.
- În Adăugați noduri, alege Catalogul de date AWS Glue pentru Surse.
- Pentru Baza de date, alege
bucketing_blog. - Pentru Tabel, alege
noaa_remote_original. - În Adăugați noduri, alege Schimbați schema pentru transformări.
- În Adăugați noduri, alege Transformare personalizată pentru transformări.
- Pentru Nume si Prenume, introduce
ToS3WithBucketing. - Pentru Părinții nodului, alege Schimbați schema.
- Pentru Bloc de cod, introduceți următorul fragment de cod:
Următoarea captură de ecran arată jobul creat folosind AWS Glue Studio pentru a genera un tabel și date.
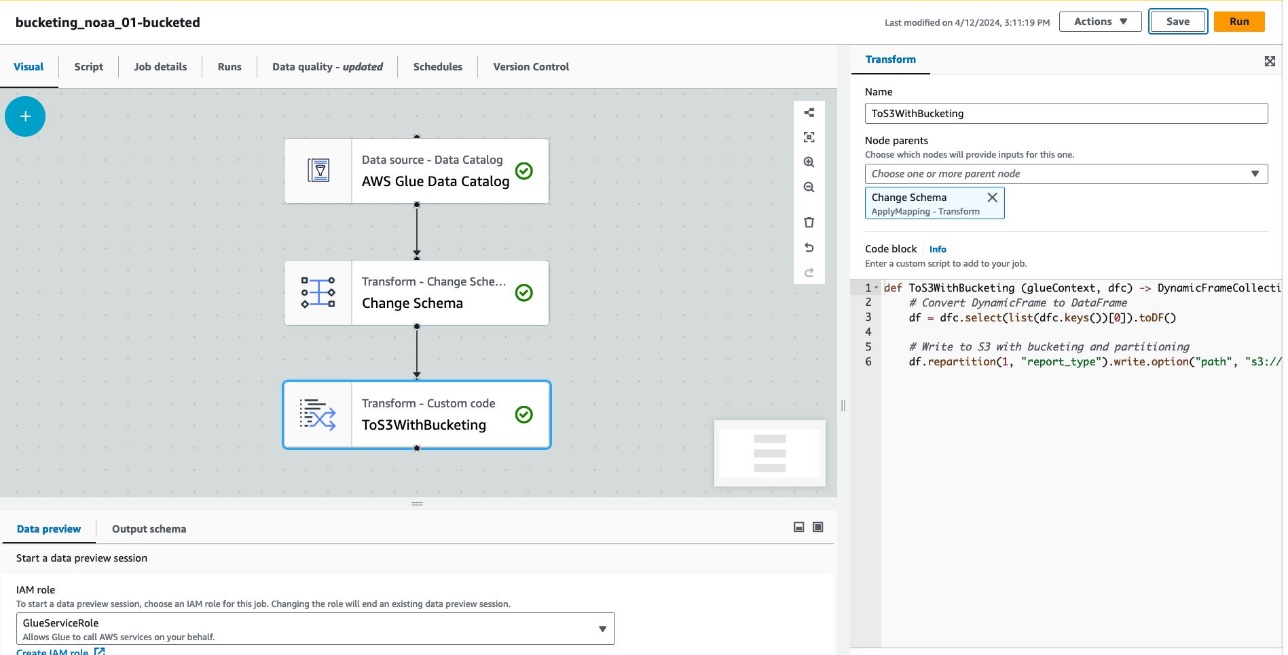
Fiecare nod reprezintă următoarele:
- Catalogul de date AWS Glue nodul încarcă
noaa_remote_originaltabel din Catalogul de date - Schimbați schema node se asigură că încarcă coloanele înregistrate în Catalogul de date
- ToS3WithBucketing node scrie date pe Amazon S3 atât cu partiționare, cât și cu compartimentare bazată pe Spark
Lucrarea a fost creată cu succes în editorul vizual.
- În Detaliile postului, Pentru Rolul IAM, Alegeti Gestionarea identității și accesului AWS (IAM) pentru acest loc de muncă.
- Pentru Tip muncitor, alege G.8X.
- Pentru Numărul de muncitori solicitat, introduceți 5.
- Alege Economisiți, Apoi alegeți Alerga.
După acești pași, tabelul glue_bucketed. a fost creat.
- Alege Mese în panoul de navigare și alegeți tabelul
glue_bucketed. - Pe Acţiuni meniu, alegeți Editați tabelul în Administrare.
- În Proprietățile tabelului secțiune, pentru a alege Adăuga.
- Adăugați o pereche de chei cu cheie
bucketing_formatși scânteie de valoare.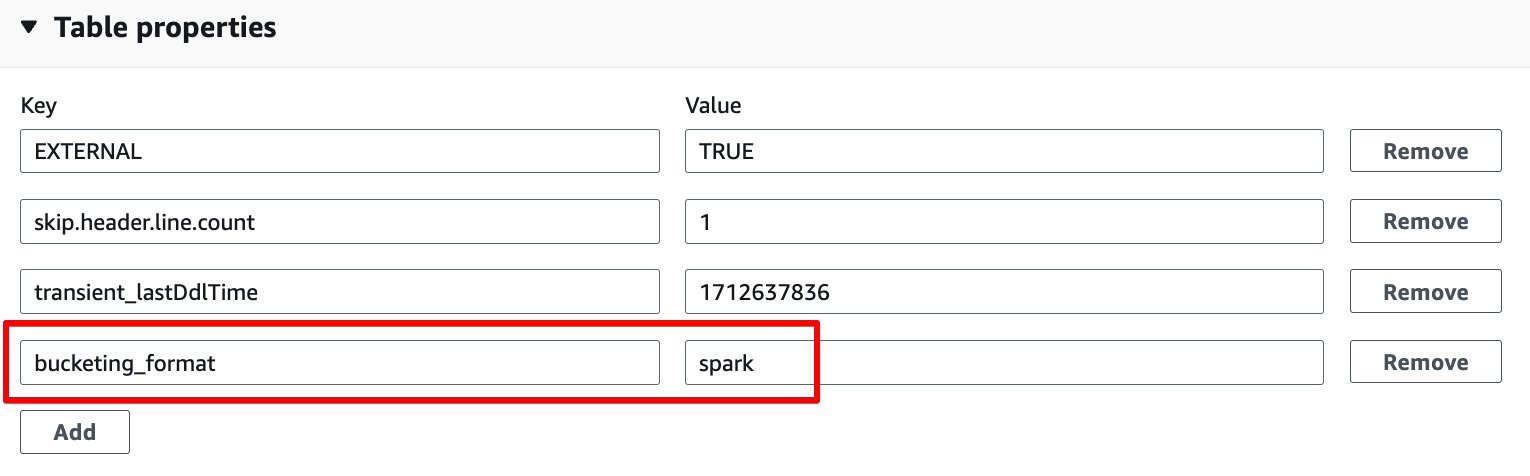
- Alege Economisiți.
Acum este timpul să interogați tabelele.
- Interogați tabelul grupat cu următoarea declarație:

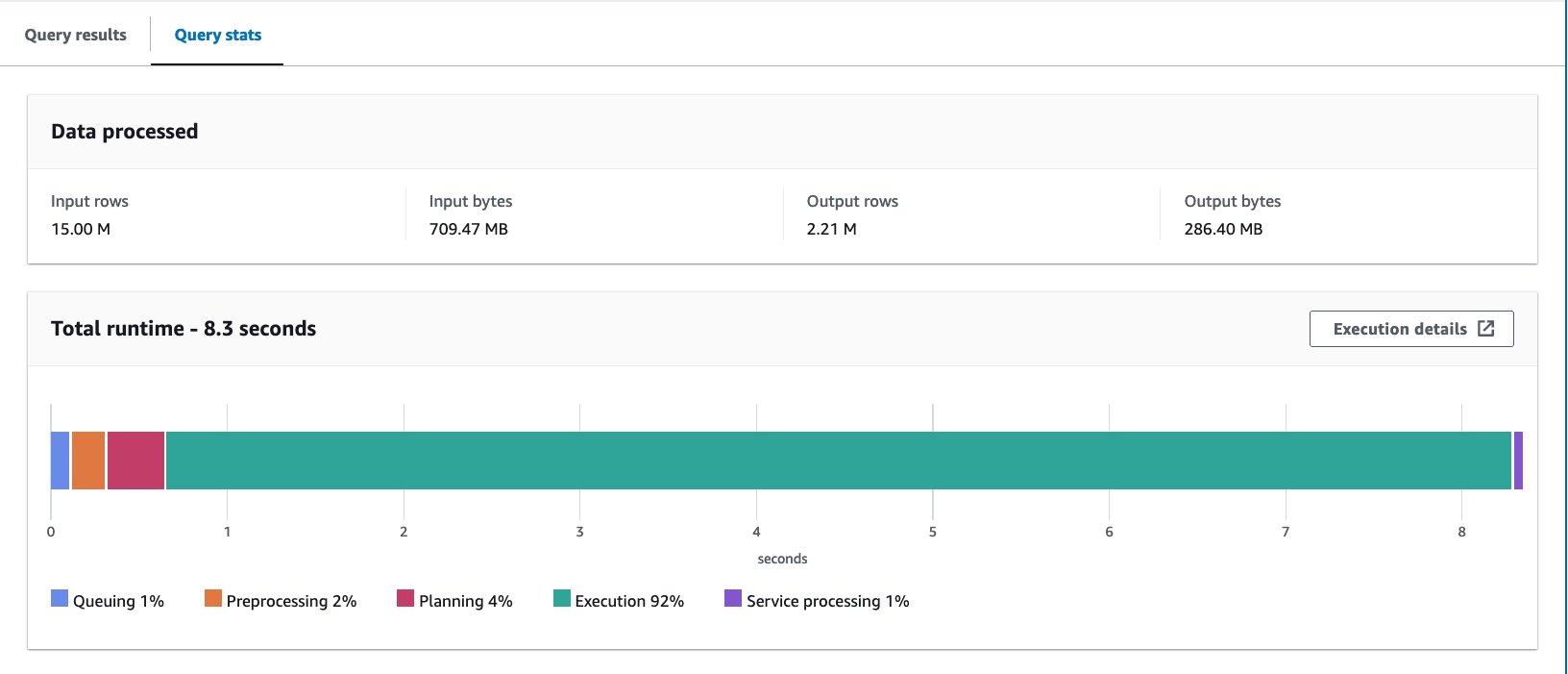
Am rulat interogarea de 10 ori. Durata medie de rulare a celor 10 interogări este de 7.09 secunde, iar 88 MB de date sunt scanate pentru a returna 2.21 milioane de înregistrări. În acest caz, atât timpul de rulare, cât și datele scanate au fost îmbunătățite prin bucketing. Aceasta înseamnă că gruparea a contribuit nu numai la performanță, ci și la reducerea costurilor.
Motivul pentru octeții mai mari scanați în comparație cu exemplul Athena CTAS este că valorile au fost distribuite diferit în acest tabel. În tabelul cu compartimente AWS Glue, valorile au fost distribuite pe cinci fișiere. În tabelul Athena CTAS, valorile au fost distribuite pe patru fișiere. Rețineți că rândurile sunt distribuite în găleți folosind o funcție hash. Algoritmul Spark bucketing folosește o funcție hash diferită de Hive și, în acest caz, a dus la o distribuție diferită între fișiere.
Considerații
Lipici DynamicFrame nu acceptă bucketing în mod nativ. Trebuie să utilizați Spark DataFrame în loc de DynamicFrame pentru a găzdui tabele.
Pentru informații despre reglarea fină a performanței AWS Glue ETL, consultați Cele mai bune practici pentru reglarea performanței AWS Glue pentru joburile Apache Spark.
Optimizați aspectul datelor Iceberg cu partiționare ascunsă
Apache Iceberg este un format de tabel deschis de înaltă performanță pentru tabele analitice uriașe, aducând fiabilitatea și simplitatea tabelelor SQL pentru datele mari. Recent, a existat o cerere uriașă de utilizare a tabelelor Apache Iceberg pentru a obține capabilități avansate, cum ar fi tranzacția ACID, interogarea călătoriei în timp și multe altele.
În Iceberg, gruparea funcționează diferit decât metoda tabelului Hive pe care am văzut-o până acum. În Iceberg, compartimentarea este un subset al partiționării și poate fi aplicată folosind transformarea partiției bucket. Modul în care îl utilizați și rezultatul final sunt similare cu gruparea în tabelele Hive. Pentru mai multe detalii despre transformările de găleată Iceberg, consultați Detalii privind transformarea găleții.
Urmați pașii următori:
- Deschideți editorul de interogări Athena.
- Rulați următoarea interogare pentru a crea un tabel Iceberg cu partiționare ascunsă împreună cu compartimentare:
Datele dvs. ar trebui să arate ca următoarea captură de ecran.

Există două foldere: data și metadata. Detaliază până la data.
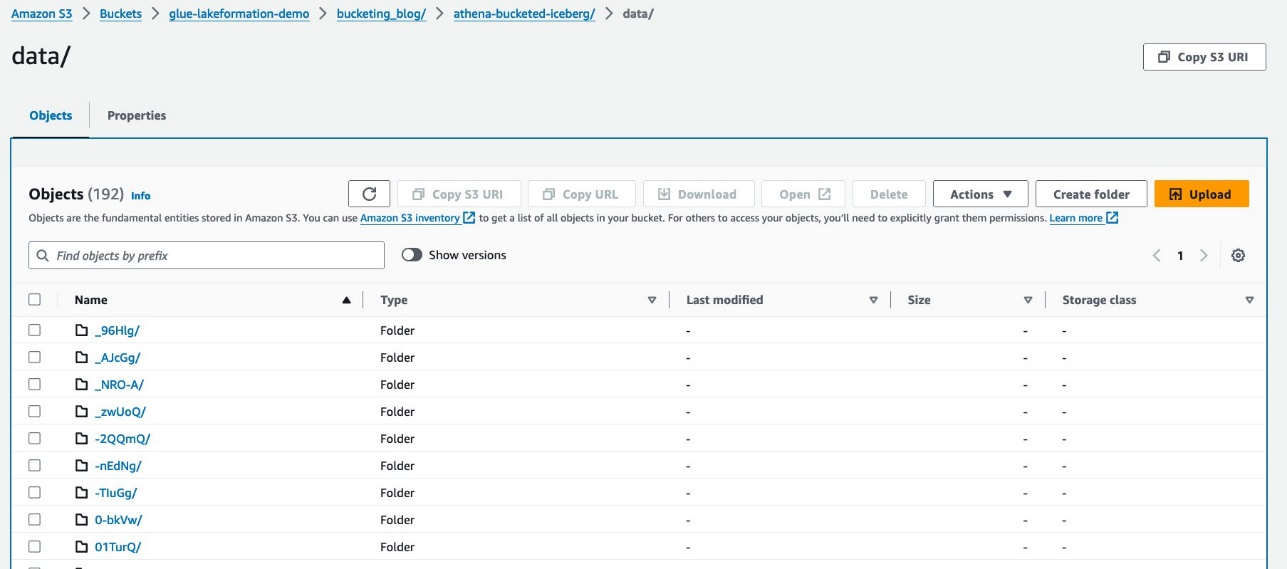
Vedeți prefixe aleatorii sub data pliant. Alegeți primul pentru a vedea detaliile acestuia.
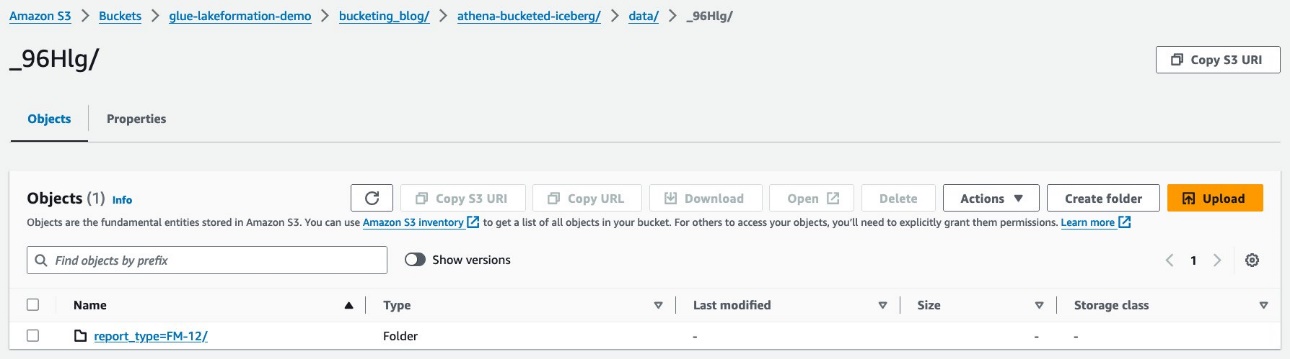
Veți vedea partiția de nivel superior bazată pe report_type coloană. Detaliați până la următorul nivel.

Vedeți partiția de al doilea nivel, găleată cu station coloana.
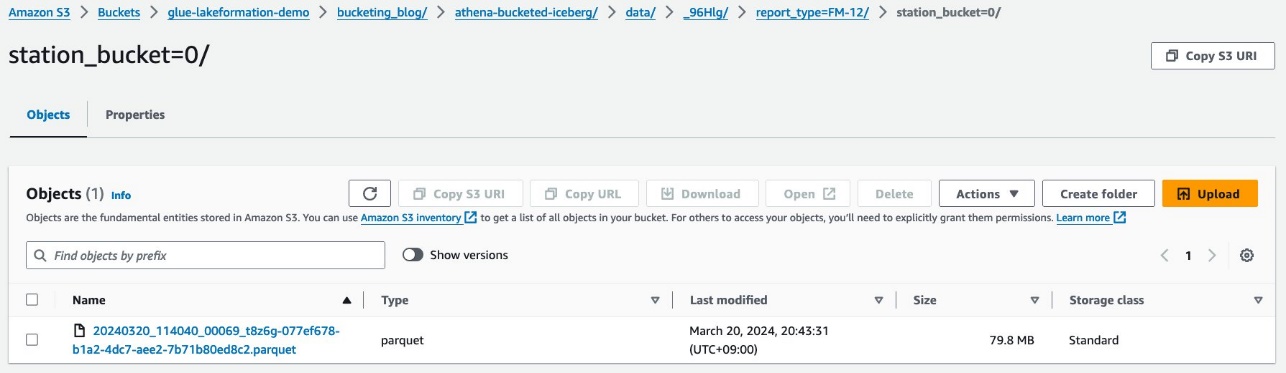
Fișierele de date Parquet există sub aceste foldere.
- Interogați tabelul grupat cu următoarea declarație:
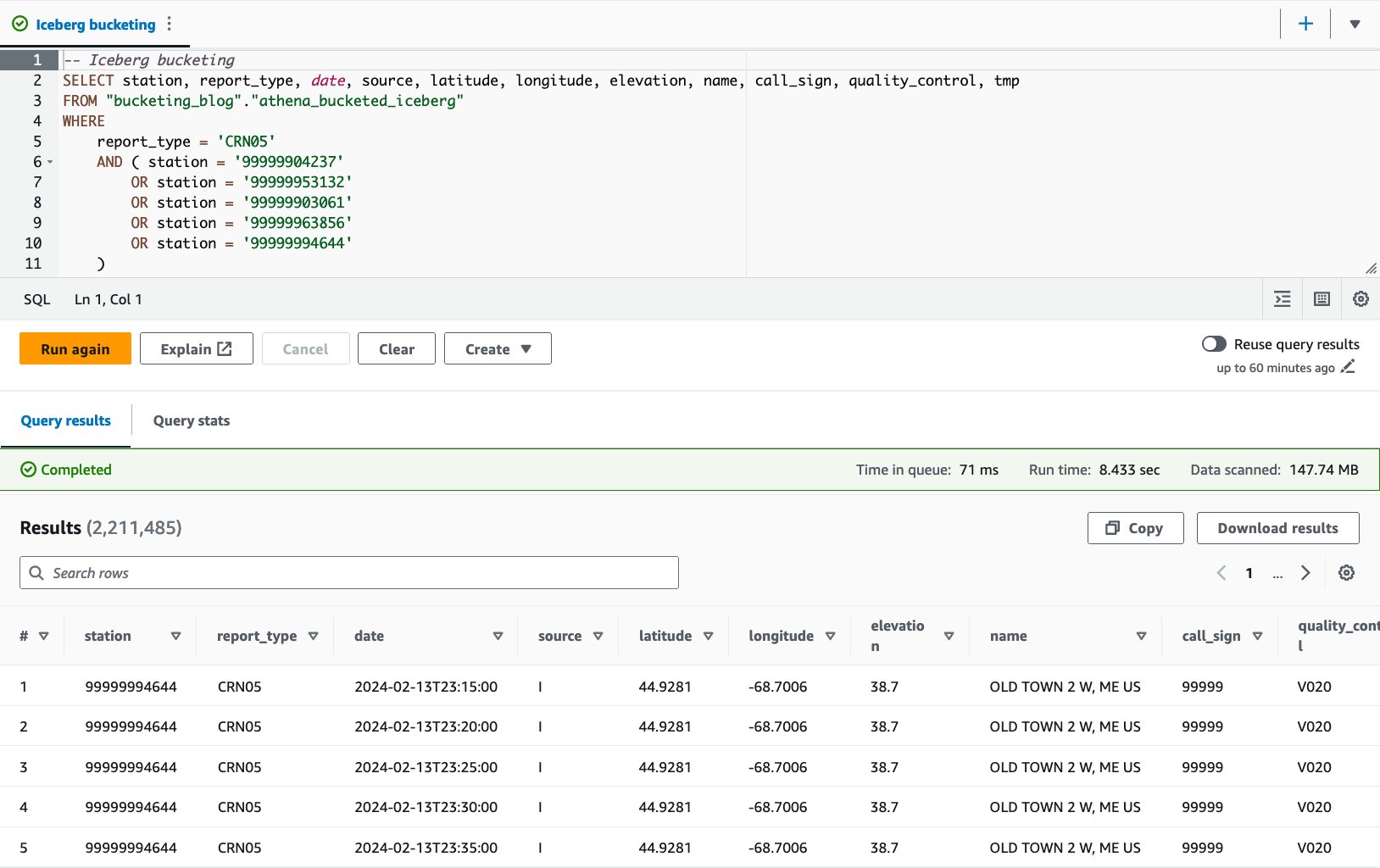
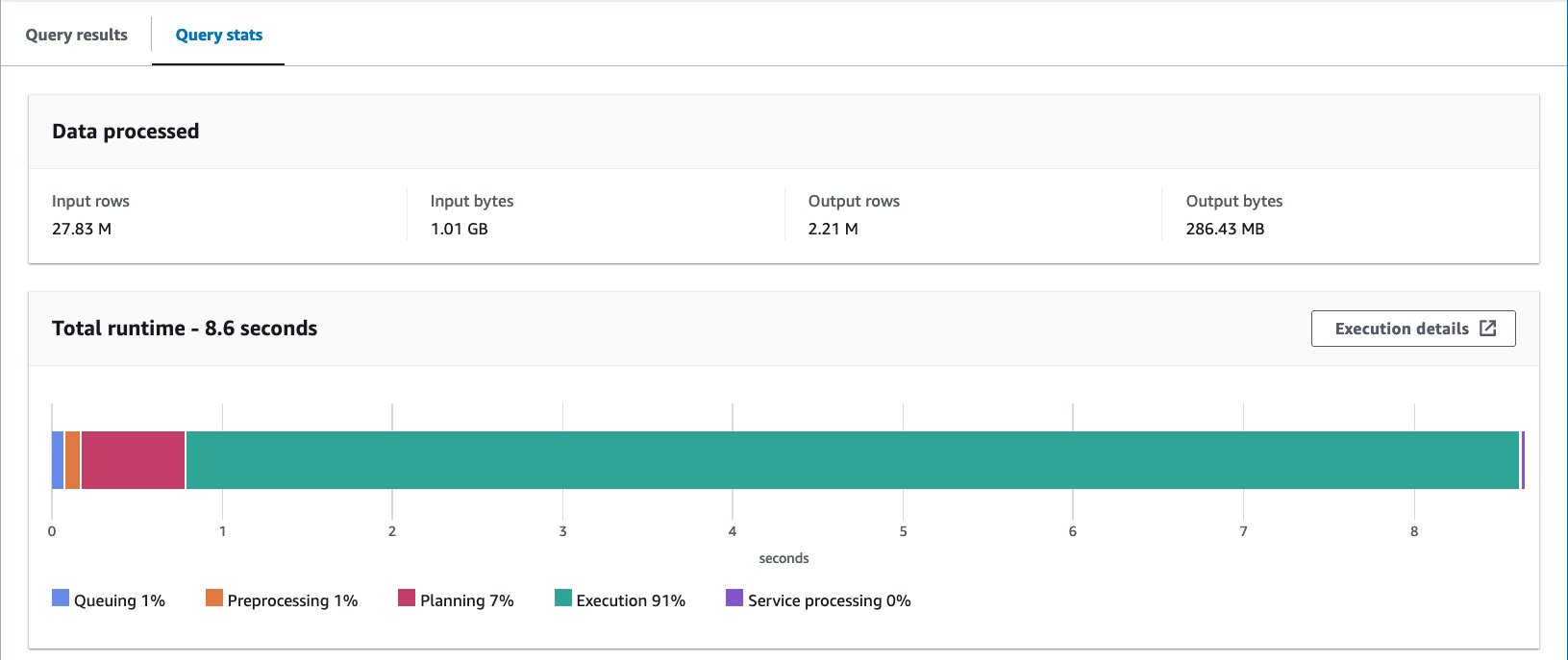
Cu tabelul Iceberg-bucketed, durata medie de rulare a celor 10 interogări este de 8.03 secunde, iar 148 MB de date sunt scanate pentru a returna 2.21 milioane de înregistrări. Acest lucru este mai puțin eficient decât găzduirea cu AWS Glue sau Athena, dar având în vedere beneficiile diferitelor caracteristici ale lui Iceberg, este într-un interval acceptabil.
REZULTATE
Următorul tabel rezumă toate rezultatele.
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | glue_bucketed | athena_bucketed_iceberg |
| Format | CSV | parchet | parchet | parchet | Aisberg (parchet) |
| Comprimare | N / A | Vioi | Vioi | Vioi | Vioi |
| Creat prin | N / A | Athena CTAS | Athena CTAS | Lipici ETL | Athena CTAS cu Iceberg |
| Motor | N / A | Trino | Trino | Apache Spark | Apache Iceberg |
| Dimensiunea tabelului (GB) | 155.8 | 5.0 | 5.0 | 5.8 | 5.0 |
| Numărul de obiecte S3 | 53360 | 376 | 192 | 192 | 195 |
| Este compartimentat? | Da, dar cu alt mod | Da | Da | Da | Da |
| Este găleată? | Nu | Nu | Da | Da | Da |
| Format de găleată | N / A | N / A | Stup | Scânteie | Aisberg |
| Numărul de găleți | N / A | N / A | 16 | 16 | 16 |
| Timp mediu de rulare (sec) | 29.178 | 10.950 | 7.815 | 7.089 | 8.030 |
| Dimensiunea scanată (MB) | 206640.0 | 358.6 | 69.1 | 87.8 | 147.7 |
cu athena_bucketed, glue_bucketed, și athena_bucketed_iceberg, ați reușit să îndepliniți obiectivul de latență de 10 secunde. Cu bucketing, ați observat o reducere cu 25–40% a timpului de rulare și o reducere cu 60–85% a dimensiunii scanării, ceea ce poate contribui atât la latența, cât și la optimizarea costurilor.
După cum puteți vedea din rezultat, deși partiționarea contribuie în mod semnificativ la reducerea atât a timpului de rulare, cât și a dimensiunii scanării, compartimentarea poate contribui și la reducerea acestora în continuare.
Athena CTAS este suficient de simplu și de rapid pentru a finaliza procesul de gătire. AWS Glue ETL este mai flexibil și mai scalabil pentru a realiza cazuri de utilizare avansate. Puteți alege oricare dintre metode în funcție de cerințele dvs. și de cazul dvs. de utilizare, deoarece puteți profita de compartimentare prin oricare dintre opțiuni.
Concluzie
În această postare, am demonstrat cum să optimizați aspectul datelor din tabel cu partiționare și compartimentare prin Athena CTAS și AWS Glue ETL. Am arătat că gruparea contribuie la accelerarea latenței interogărilor și la reducerea dimensiunii scanării pentru a optimiza și mai mult costurile. Am discutat, de asemenea, despre compartimentarea pentru tabelele Iceberg prin partiționare ascunsă.
Distribuirea unei singure tehnici pentru a optimiza aspectul datelor prin reducerea scanării datelor. Pentru optimizarea întregului aspect al datelor, vă recomandăm să luați în considerare alte opțiuni, cum ar fi partiționarea, utilizarea formatului de fișier în coloană și compresia împreună cu compartimentarea. Acest lucru poate permite datelor dvs. să îmbunătățească și mai mult performanța interogărilor.
Bucketing fericit!
Despre Autori
 Takeshi Nakatani este consultant principal de date mari în echipa de servicii profesionale din Tokyo. Are 26 de ani de experiență în industria IT, cu experiență în arhitectura infrastructurii de date. În zilele lui libere, poate fi toboșar rock sau motociclist.
Takeshi Nakatani este consultant principal de date mari în echipa de servicii profesionale din Tokyo. Are 26 de ani de experiență în industria IT, cu experiență în arhitectura infrastructurii de date. În zilele lui libere, poate fi toboșar rock sau motociclist.
 Noritaka Sekiyama este arhitect principal de date mari în echipa AWS Glue. El este responsabil pentru construirea de artefacte software pentru a ajuta clienții. În timpul liber, îi place să meargă cu bicicleta cu bicicleta de drum.
Noritaka Sekiyama este arhitect principal de date mari în echipa AWS Glue. El este responsabil pentru construirea de artefacte software pentru a ajuta clienții. În timpul liber, îi place să meargă cu bicicleta cu bicicleta de drum.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/optimize-data-layout-by-bucketing-with-amazon-athena-and-aws-glue-to-accelerate-downstream-queries/

