Coroane oferă fabricilor de bere, îmbuteliatorilor de băuturi și producătorilor de alimente din întreaga lume mașini individuale și linii de producție complete. În fiecare zi, milioane de sticle de sticlă, cutii și containere PET trec printr-o linie Krones. Liniile de producție sunt sisteme complexe cu o mulțime de erori posibile care ar putea bloca linia și scădea randamentul producției. Krones dorește să detecteze defecțiunea cât mai devreme posibil (uneori chiar înainte de a se întâmpla) și să notifice operatorii liniei de producție pentru a crește fiabilitatea și randamentul. Deci, cum să detectăm o defecțiune? Krones își echipează liniile cu senzori pentru colectarea datelor, care pot fi apoi evaluate conform regulilor. Krones, ca producător de linie, precum și operatorul de linie au posibilitatea de a crea reguli de monitorizare pentru mașini. Prin urmare, îmbuteliatorii de băuturi și alți operatori își pot defini propria marjă de eroare pentru linie. În trecut, Krones folosea un sistem bazat pe o bază de date cu serii de timp. Principalele provocări au fost că acest sistem era greu de depanat și, de asemenea, interogările reprezentau starea curentă a mașinilor, dar nu și tranzițiile de stare.
Această postare arată cum Krones a construit o soluție de streaming pentru a-și monitoriza liniile, pe baza Amazon Kinesis și Serviciul gestionat Amazon pentru Apache Flink. Aceste servicii complet gestionate reduc complexitatea construirii de aplicații de streaming cu Apache Flink. Serviciul gestionat pentru Apache Flink gestionează componentele Apache Flink subiacente care oferă o stare durabilă a aplicației, metrici, jurnalele și multe altele, iar Kinesis vă permite să procesați în mod rentabil datele în flux la orice scară. Dacă doriți să începeți cu propria dvs. aplicație Apache Flink, consultați GitHub depozit pentru mostre care utilizează API-urile Java, Python sau SQL ale Flink.
Prezentare generală a soluției
Monitorizarea liniei Krones face parte din Îndrumări pentru atelierul Krones sistem. Oferă suport în organizarea, prioritizarea, managementul și documentarea tuturor activităților din companie. Le permite să anunțe un operator dacă mașina este oprită sau sunt necesare materiale, indiferent unde se află operatorul în linie. Regulile dovedite de monitorizare a stării sunt deja încorporate, dar pot fi și definite de utilizator prin interfața cu utilizatorul. De exemplu, dacă un anumit punct de date care este monitorizat încalcă un prag, poate exista un mesaj text sau declanșare pentru o comandă de întreținere pe linie.
Sistemul de monitorizare a stării și evaluare a regulilor este construit pe AWS, folosind serviciile de analiză AWS. Următoarea diagramă ilustrează arhitectura.
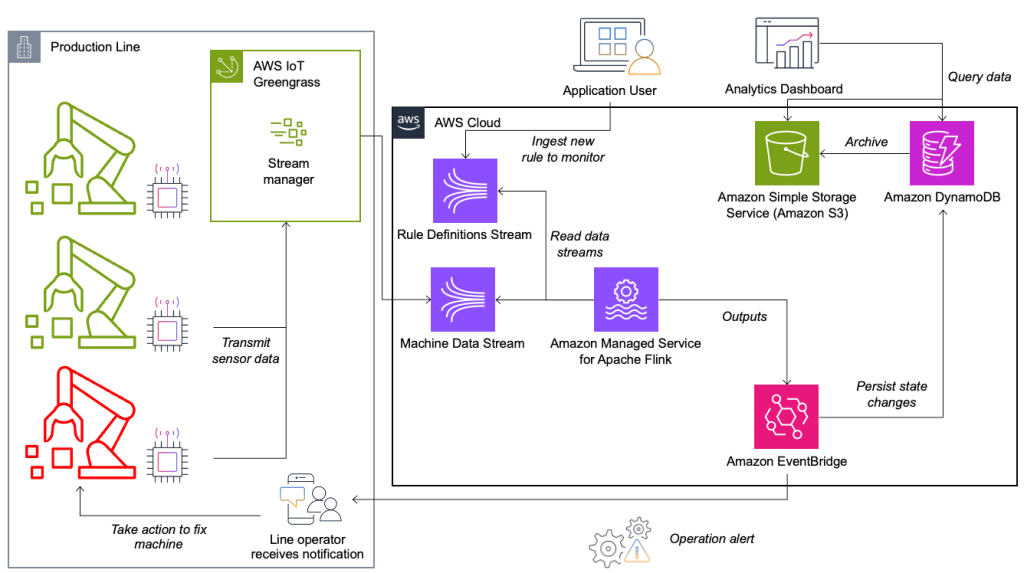
Aproape fiecare aplicație de streaming de date constă din cinci straturi: sursa de date, asimilarea fluxului, stocarea fluxului, procesarea fluxului și una sau mai multe destinații. În secțiunile următoare, ne aprofundăm în fiecare strat și cum funcționează în detaliu soluția de monitorizare a liniilor, construită de Krones.
Sursă de date
Datele sunt colectate de un serviciu care rulează pe un dispozitiv edge care citește mai multe protocoale precum Siemens S7 sau OPC/UA. Datele brute sunt preprocesate pentru a crea o structură JSON unificată, ceea ce facilitează procesarea ulterioară în motorul de reguli. Un exemplu de încărcare utilă convertită în JSON ar putea arăta astfel:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Ingerarea fluxului
AWS IoT Greengrass este un serviciu de execuție și cloud de tip Internet of Things (IoT) cu sursă deschisă. Acest lucru vă permite să acționați asupra datelor la nivel local și să agregați și să filtrați datele dispozitivului. AWS IoT Greengrass oferă componente prefabricate care pot fi implementate la margine. Soluția de linie de producție folosește componenta stream manager, care poate procesa date și le poate transfera către destinații AWS, cum ar fi AWS IoT Analytics, Serviciul Amazon de stocare simplă (Amazon S3) și Kinesis. Managerul de flux memorează și cumulează înregistrările, apoi le trimite la un flux de date Kinesis.
Stocare în flux
Sarcina stocării fluxului este de a stoca mesajele într-un mod tolerant la erori și de a le face disponibile pentru consum pentru una sau mai multe aplicații de consum. Pentru a realiza acest lucru pe AWS, cele mai comune tehnologii sunt Kinesis și Streaming gestionat de Amazon pentru Apache Kafka (Amazon MSK). Pentru stocarea datelor senzorilor noștri de pe liniile de producție, Krones alege Kinesis. Kinesis este un serviciu de streaming de date fără server, care funcționează la orice scară, cu o latență scăzută. Fragmentele dintr-un flux de date Kinesis sunt o secvență de înregistrări de date identificată în mod unic, în care un flux este compus din unul sau mai multe fragmente. Fiecare shard are o capacitate de citire de 2 MB/s și o capacitate de scriere de 1 MB/s (cu maximum 1,000 de înregistrări/s). Pentru a evita atingerea acestor limite, datele ar trebui distribuite între fragmente cât mai uniform posibil. Fiecare înregistrare care este trimisă către Kinesis are o cheie de partiție, care este folosită pentru a grupa datele într-un fragment. Prin urmare, doriți să aveți un număr mare de chei de partiție pentru a distribui sarcina în mod uniform. Managerul de flux care rulează pe AWS IoT Greengrass acceptă alocări aleatorii ale cheilor de partiție, ceea ce înseamnă că toate înregistrările ajung într-un fragment aleatoriu și încărcarea este distribuită uniform. Un dezavantaj al atribuirii aleatoare a cheilor de partiție este că înregistrările nu sunt stocate în ordine în Kinesis. Vă explicăm cum să rezolvați acest lucru în secțiunea următoare, unde vorbim despre filigrane.
filigrane
A filigran este un mecanism folosit pentru a urmări și măsura progresul timpului evenimentului într-un flux de date. Ora evenimentului este marca temporală de la momentul în care evenimentul a fost creat la sursă. Filigranul indică progresul în timp util al aplicației de procesare a fluxului, astfel încât toate evenimentele cu o amprentă temporală anterioară sau egală sunt considerate procesate. Aceste informații sunt esențiale pentru ca Flink să avanseze timpul evenimentului și să declanșeze calcule relevante, cum ar fi evaluările ferestrelor. Decalajul permis între timpul evenimentului și filigranul poate fi configurat pentru a determina cât timp să aștepte datele cu întârziere înainte de a considera o fereastră completă și de a avansa filigranul.
Krones are sisteme pe tot globul și trebuia să facă față sosirilor întârziate din cauza pierderilor de conexiune sau a altor constrângeri de rețea. Ei au început prin a monitoriza sosirile întârziate și a seta gestionarea întârziată a Flink la valoarea maximă pe care au văzut-o în această valoare. Au întâmpinat probleme cu sincronizarea timpului de la dispozitivele de margine, ceea ce i-a condus la un mod mai sofisticat de filigranare. Au construit un filigran global pentru toți expeditorii și au folosit cea mai mică valoare ca filigran. Marcajele de timp sunt stocate într-un HashMap pentru toate evenimentele primite. Când filigranele sunt emise periodic, se folosește cea mai mică valoare a acestui HashMap. Pentru a evita blocarea filigranelor din cauza lipsei datelor, au configurat un idleTimeOut parametru, care ignoră marcajele de timp care sunt mai vechi decât un anumit prag. Acest lucru crește latența, dar oferă o consistență puternică a datelor.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Procesarea fluxurilor
După ce datele sunt colectate de la senzori și ingerate în Kinesis, acestea trebuie evaluate de un motor de reguli. O regulă din acest sistem reprezintă starea unei singure metrici (cum ar fi temperatura) sau a unei colecții de metrici. Pentru a interpreta o metrică, se utilizează mai mult de un punct de date, care este un calcul cu stare. În această secțiune, ne aprofundăm starea cheie și starea de difuzare în Apache Flink și modul în care sunt utilizate pentru a construi motorul de reguli Krones.
Controlați fluxul și modelul de stare de difuzare
În Apache Flink, de stat se referă la capacitatea sistemului de a stoca și gestiona informații în mod persistent în timp și operațiuni, permițând procesarea datelor în flux cu suport pentru calcule cu stare.
model de stare de difuzare permite distribuirea unei stări la toate instanțele paralele ale unui operator. Prin urmare, toți operatorii au aceeași stare și datele pot fi prelucrate folosind aceeași stare. Aceste date numai în citire pot fi ingerate utilizând un flux de control. Un flux de control este un flux de date obișnuit, dar de obicei cu o rată de date mult mai mică. Acest model vă permite să actualizați în mod dinamic starea tuturor operatorilor, permițând utilizatorului să schimbe starea și comportamentul aplicației fără a fi nevoie de o redistribuire. Mai exact, distribuția statului se face prin utilizarea unui flux de control. Prin adăugarea unei noi înregistrări în fluxul de control, toți operatorii primesc această actualizare și folosesc noua stare pentru procesarea noilor mesaje.
Acest lucru permite utilizatorilor aplicației Krones să introducă reguli noi în aplicația Flink fără a o reporni. Acest lucru evită timpul de nefuncționare și oferă utilizatorului o experiență excelentă, deoarece schimbările au loc în timp real. O regulă acoperă un scenariu pentru a detecta o abatere a procesului. Uneori, datele mașinii nu sunt atât de ușor de interpretat pe cât ar părea la prima vedere. Dacă un senzor de temperatură trimite valori ridicate, aceasta poate indica o eroare, dar poate fi și efectul unei proceduri de întreținere în curs. Este important să puneți valorile în context și să filtrați unele valori. Acest lucru se realizează printr-un concept numit grupare.
Gruparea de metrici
Gruparea datelor și a valorilor vă permite să definiți relevanța datelor primite și să obțineți rezultate precise. Să parcurgem exemplul din figura următoare.
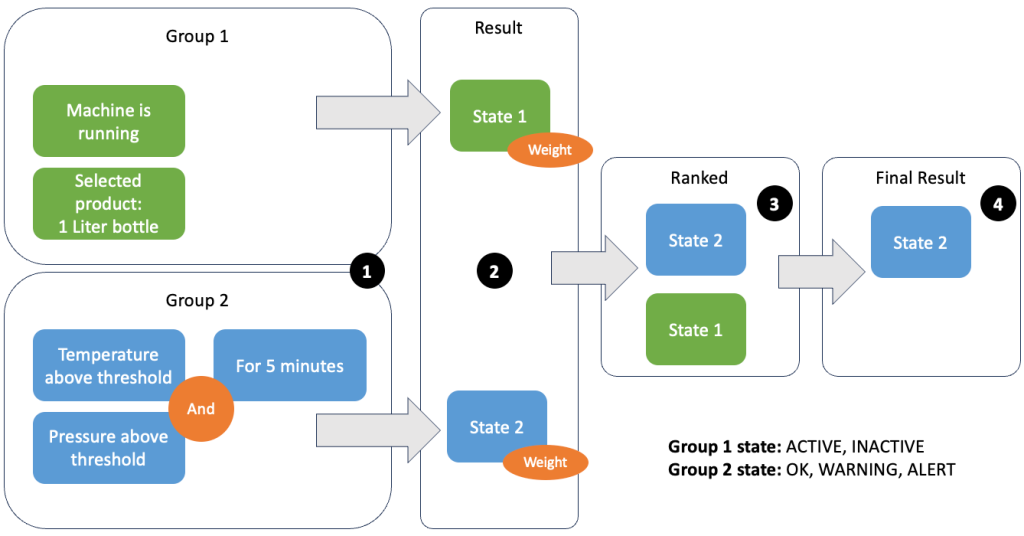
În pasul 1, definim două grupuri de condiții. Grupul 1 colectează starea mașinii și ce produs trece prin linie. Grupa 2 folosește valoarea senzorilor de temperatură și presiune. Un grup de condiții poate avea stări diferite în funcție de valorile pe care le primește. În acest exemplu, grupul 1 primește date că mașina funcționează și sticla de un litru este selectată ca produs; aceasta dă acestui grup statul ACTIVE. Grupa 2 are metrici pentru temperatură și presiune; ambele valori sunt peste pragurile lor pentru mai mult de 5 minute. Astfel, grupul 2 este în a WARNING stat. Aceasta înseamnă că grupul 1 raportează că totul este în regulă, iar grupul 2 nu. În pasul 2, greutățile sunt adăugate la grupuri. Acest lucru este necesar în unele situații, deoarece grupurile pot raporta informații contradictorii. În acest scenariu, grupul 1 raportează ACTIVE și rapoartele grupului 2 WARNING, deci nu este clar pentru sistem care este starea liniei. După adăugarea ponderilor, stările pot fi clasate, așa cum se arată în pasul 3. În sfârșit, starea cu cel mai înalt clasat este aleasă ca cea câștigătoare, așa cum se arată în pasul 4.
După ce regulile sunt evaluate și starea finală a mașinii este definită, rezultatele vor fi procesate în continuare. Acțiunea întreprinsă depinde de configurația regulii; aceasta poate fi o notificare către operatorul de linie pentru a reaproviziona materiale, pentru a face ceva întreținere sau doar o actualizare vizuală a tabloului de bord. Această parte a sistemului, care evaluează valorile și regulile și ia acțiuni pe baza rezultatelor, este denumită a motor de regulă.
Scalarea motorului de reguli
Permițând utilizatorilor să-și construiască propriile reguli, motorul de reguli poate avea un număr mare de reguli pe care trebuie să le evalueze, iar unele reguli pot folosi aceleași date de senzor ca și alte reguli. Flink este un sistem distribuit care se scalează foarte bine pe orizontală. Pentru a distribui un flux de date la mai multe sarcini, puteți utiliza keyBy() metodă. Acest lucru vă permite să partiționați un flux de date într-un mod logic și să trimiteți părți ale datelor către diferiți manageri de activități. Acest lucru se face adesea prin alegerea unei chei arbitrare, astfel încât să obțineți o sarcină distribuită uniform. În acest caz, Krones a adăugat un ruleId la punctul de date și l-a folosit ca cheie. În caz contrar, punctele de date necesare sunt procesate de o altă sarcină. Fluxul de date cu cheie poate fi utilizat în toate regulile la fel ca o variabilă obișnuită.
destinații
Când o regulă își schimbă starea, informația este trimisă către un flux Kinesis și apoi prin intermediul Amazon EventBridge către consumatori. Unul dintre consumatori creează o notificare din eveniment care este transmisă liniei de producție și alertează personalul să acționeze. Pentru a putea analiza modificările stării regulilor, un alt serviciu scrie datele într-un Amazon DynamoDB tabel pentru acces rapid și un TTL este în vigoare pentru a descărca istoricul pe termen lung pe Amazon S3 pentru raportare ulterioară.
Concluzie
În această postare, v-am arătat cum Krones a construit un sistem de monitorizare a liniei de producție în timp real pe AWS. Serviciul gestionat pentru Apache Flink a permis echipei Krones să înceapă rapid, concentrându-se mai degrabă pe dezvoltarea de aplicații decât pe infrastructură. Capacitățile în timp real ale Flink i-au permis lui Krones să reducă timpul de nefuncționare al mașinii cu 10% și să crească eficiența cu până la 5%.
Dacă doriți să vă creați propriile aplicații de streaming, consultați mostrele disponibile pe GitHub depozit. Dacă doriți să extindeți aplicația dvs. Flink cu conectori personalizați, consultați Construirea de conectori cu Apache Flink este mai ușoară: Prezentarea Async Sink. Async Sink este disponibil în Apache Flink versiunea 1.15.1 și ulterioară.
Despre Autori
 Florian Mair este arhitect senior în soluții și expert în fluxul de date la AWS. Este un tehnolog care ajută clienții din Europa să reușească și să inoveze, rezolvând provocările de afaceri folosind serviciile AWS Cloud. Pe lângă faptul că lucrează ca arhitect de soluții, Florian este un alpinist pasionat și a escaladat pe unii dintre cei mai înalți munți din Europa.
Florian Mair este arhitect senior în soluții și expert în fluxul de date la AWS. Este un tehnolog care ajută clienții din Europa să reușească și să inoveze, rezolvând provocările de afaceri folosind serviciile AWS Cloud. Pe lângă faptul că lucrează ca arhitect de soluții, Florian este un alpinist pasionat și a escaladat pe unii dintre cei mai înalți munți din Europa.
 Emil Dietl este Senior Tech Lead la Krones, specializat în inginerie de date, cu un domeniu cheie în Apache Flink și microservicii. Munca lui implică adesea dezvoltarea și întreținerea de software critic pentru misiune. În afara vieții sale profesionale, apreciază profund petrecerea timpului de calitate cu familia sa.
Emil Dietl este Senior Tech Lead la Krones, specializat în inginerie de date, cu un domeniu cheie în Apache Flink și microservicii. Munca lui implică adesea dezvoltarea și întreținerea de software critic pentru misiune. În afara vieții sale profesionale, apreciază profund petrecerea timpului de calitate cu familia sa.
 Simon Peyer este arhitect de soluții la AWS cu sediul în Elveția. Este un practicant și este pasionat de conectarea tehnologiei și a oamenilor care folosesc serviciile AWS Cloud. Un accent special pentru el este transmisia de date și automatizările. Pe lângă muncă, lui Simon îi place familia sa, în aer liber și drumețiile în munți.
Simon Peyer este arhitect de soluții la AWS cu sediul în Elveția. Este un practicant și este pasionat de conectarea tehnologiei și a oamenilor care folosesc serviciile AWS Cloud. Un accent special pentru el este transmisia de date și automatizările. Pe lângă muncă, lui Simon îi place familia sa, în aer liber și drumețiile în munți.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

