Programming processors is becoming more complicated as more and different types of processing elements are included in the same architecture.
While systems architects may revel in the number of options available for improving power, performance, and area, the challenge of programming functionality and making it all work together is turning out to be a major challenge. It involves multiple programming tools, models, and approaches from various IP providers.
“In any kind of edge inference product, whether it’s a Nest camera, a camera in an automotive application, or even a laptop, there will basically be three types of functional software, largely coming from three different types of developers — data scientists, embedded CPU developers, and DSP developers,” said Steve Roddy, chief marketing officer at Quadric.
And depending on where they sit in the development process, their approaches may look very different. “The data scientists spend their time in Python, in training for frameworks, and doing things at mathematical abstraction levels,” Roddy said. “PyTorch is very high level, abstracted, interpreted, with not much care given to efficiency of implementation, because all they care about is gain functions in math, and accuracy in models, etc. What comes out of there are PyTorch models, ONNX code, and Python code, which is embedded in the PyTorch model. Embedded developers are a completely different personality type. They work with more traditional tool sets that could be the CPU vendors’ tools, or Arm toolkits, or something generic like Microsoft Visual Studio for C/C++ development. And no matter which CPU it is, you’re going to get the vendor’s version of a development studio for that particular chip, and it will come with pre-built things like RTOS code and driver code. If you’re buying a chip-level solution from a particular vendor, it will have the drivers for the DDR, and the PCI interfaces, and so forth.”
Consider application programming for an iPhone, for example, which is highly abstracted. “There’s a developer kit for the iPhone developers that has lots of other software stacked on top,” he said. “But for the most part, it’s an embedded thing. Someone’s writing C code, someone’s pulling in an operating system, whether it be Zephyr or Microsoft OS or something of that nature. And what do they produce? They produce C code, sometimes assembly code depending upon the quality of the compiler. The DSP developer, who is also an algorithm developer, is often mathematician-oriented, and uses tools like MATLAB, or perhaps a Visual Studio. Three levels of code are created here. Python-like data science code, DSP, C++, and embedded code.”
Through the lens of an Android developer, Ronan Naughton, director of product management, Client Line of Business at Arm said, “A typical software engineer might be developing a mobile app for deployment to multiple platforms. In this case, they’ll be looking for the lowest maintenance overhead, seamless portability and high performance which can be provided by the ubiquity of the Arm CPU and supporting toolchains.”
In an Android environment, programming for CPU enables the widest possible choice of tools.
“For example,” Naughton noted, “a good vectorizing compiler such as LLVM or GCC can target multiple CPU and OS targets. There is a rich ecosystem of libraries for function specific tasks such as Arm Compute Library for ML. Alternatively, developers can target the Instruction Set Architecture itself with intrinsics such as the Arm C Language Extensions.”
Beneath all of that is a conventional architecture, consisting of an NPU, DSP, and CPU, with all the steps needed to land on the target host CPU. All or most of those are using some form of runtime application.
“If you’re running your machine learning code, the CPU is actively involved in each inference, in each iteration, each pass through that machine learning graph orchestrating the whole thing,” Roddy noted.
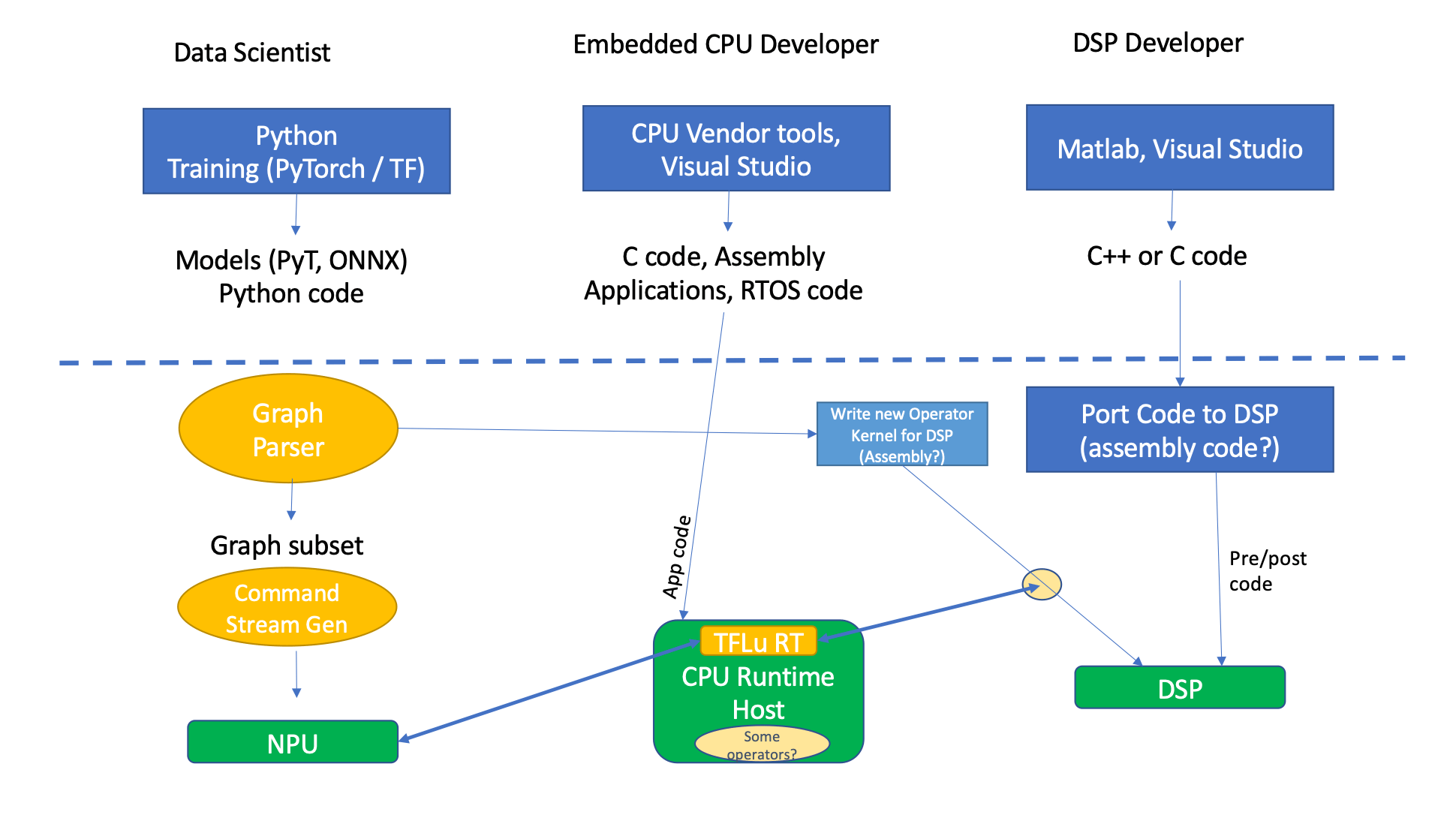
Fig. 1: Tool/code flow for conventional NPU+DSP+CPU. Source: Quadric.io
How to program DSPs, CPUs and NPUs will vary depending on applications, use cases, system architectures, and environments. That will determine how to optimization the code to achieve the best performance for a particular application or use model.
“On a CPU, most compilers can optimize code extremely well, but when programming DSPs or NPUs, especially to parallelize code, a lot of work has to be done by the software engineer because all compilers fail,” said Andy Heinig, head of department for efficient electronics at Fraunhofer IIS’ Engineering of Adaptive Systems Division. “This means that the more parallel work is to be done on the hardware, the more work has to be done manually by the software engineer. And most of the work is required in low-level programming.”
While there is some overlap, there also are some basic differences between these different processing elements. “A CPU is a general-purpose architecture, and thus supports wide range of usages, operating systems, development tools, libraries, and many programming languages from traditional low-level C to high level C++, Python, Web applications and Java,” said Guy Ben Haim, product manager at Synopsys. “DSP applications usually run on an optimized real-time system, so programming DSP processors requires using low-level languages (e.g., assembly, C), DSP libraries, and specific compilers/profilers to allow data parallelism, performance tuning, and codes-size optimizations. Unlike general-purpose CPUs, but similar to DSPs, the NPU architecture is also dedicated to accelerating specific tasks, in this case to accelerate AI/ML applications.”
A DSP architecture can process data from multiple sensors in parallel. And while traditional CPU or DSP programming relies on a program or an algorithm with a set of rules to process data, AI learns from data and improves its performance over time.
“AI uses high-level frameworks such as PyTorch and TensorFlow to create, train, and deploy models,” Ben Haim explained. “Neural network models are inspired by the architecture of neurons in the human brain and consist of mathematical representations of a system that can make predictions or decisions based on the input data.”
There are other differences, as well. In addition to programming with high-level languages like C and C++, said Pulin Desai, group director, product marketing and management for Tensilica Vision and AI DSPs at Cadence, “DSPs and CPUs also utilize various libraries like math lib, fp lib. DSPs also have a specific lib for the specific vertical they may be addressing to perform a special-purpose application. DSPs and CPUs also work with high-level languages like OpenCL and Halide, which customers use to develop their applications.”
NPU programming is done in a completely different environment using AI training frameworks. Those, in turn, generate neural network code in TensorFlow and PyTorch, and the network is further compiled for the specific hardware using a neural network compiler.”
“Neural networks aren’t ‘programmed.’ They are trained,’” noted Gordon Cooper, product manager at Synopsys. “DSPs and CPUs are programmed in a more traditional way. Code is written in C/C++. Then you need an IDE and debugger to test and edit the code.”
How programming models work
So for CPUs and DSPs, designers will program in C or C++, but they may call a specific lib api. “For vision, for example, code may call OpenCV API calls,” Desai said.


Fig. 2: Comparison of embedded software development on DSPs/CPUs vs. NPUs. Source: Cadence
Most of the time, the work to optimize the code is done by hand, Fraunhofer’s Heinig said. “High-level programming models often fail when it comes to using hardware in parallel. But, of course, it is possible to use libraries with basic highly optimized functions.”
Developing an AI model is very different. Several steps are required. “First is identification and preparation,” said Synopsys’ Ben Haim. “After identifying the problem suitable to be solved by AI, it is important to select the right model and gather the data that will be used in the process. Second is model training. Training the model means using large amounts of training data to optimize the model, improve performance and ensure accuracy. Third is inference. The AI model is deployed in a production environment and used to make quick conclusions, predictions and inferences based on the available data.”
There are other differences, as well. Most DSPs are vector processors, with an architecture tuned for the efficient processing of an array of data in parallel. “To efficiently use the hardware, data needs to be vectorized,” said Markus Willems, senior product manager at Synopsys. “An optimizing compiler can apply some degree of auto-vectorization when starting from scalar code. Yet for the vast majority of use cases, getting to optimal results takes a programmer to write the code in a vectorized way, using dedicated vector data types.”
Willems suggested that to leverage the full power of the instruction-set, intrinsics are commonly used. “Different to plain assembly coding, an intrinsic leaves the register allocation to the compiler, which allows for code reuse and portability.”
In addition, for most DSP algorithms, the design starts in MATLAB to analyze the functional performance (i.e., to check if the algorithm solves the problem). For a growing number of DSPs, there is a direct path to map MATLAB algorithms to vectorized DSP code, using the MATLAB embedded coder, and processor-specific DSP libraries.
But to fully utilize the processor, Heinig said it is necessary to co-optimize hardware and software. “Otherwise, you will fail with a solution because you may realize too late that the designed hardware does not fit the problem specification very well. This is especially true if you want to execute more and more operations in parallel.”
For an SoC architect, it starts with what is going to be the target market and target applications as that will drive the hardware and software architecture.
“It is always a challenge when choosing between programmability and fixed hardware,” Desai explained. “Decisions are driven by cost (area of the SoC), power, performance, time-to-market, and future-proofing. If you know your target application and want to optimize the power and area, fixed hardware is best. [One example is an H.264 decoder.] Neural networks are constantly changing, so programmability is must, but an architecture where some of the functions are in fixed functions (hardware accelerator, such as an NPU) and some are in programmable CPUs or DSPs is the best for AI.”
Partitioning the processing
All of this is made more complicated because different designers/programmers may be responsible for the various code.
“We are talking about inference applications, but we are also talking about a systems company making a system,” said Desai. “And because an SoC is general-purpose, there may be AI developers who will develop a specific neural network to solve a specific problem — for example, a noise reduction network to reduce noise for a microphone, people-detection network for security camera, etc. This network needs to be converted to a code that can run on the SoC, so you will have programmers who know how to use the tools to convert the neural network to code that can be launched on a SoC with a CPU/DSP/NPU. However, if it is a real-time application, you will also need system software engineers who know how to work with real-time OSes, processor-level system software, etc. Also, there may be high-level software developers who may develop a GUI or user interface if this is a consumer device.”
For an NPU, there are several considerations. “First, the NPU must be designed to accelerate AI workloads,” said Ben Haim. “The AI/NN workloads consist of deep learning algorithms, which require heavy mathematical and multiple matrix multiplications in many layers, and so parallel architecture is needed.”
He explained one of the key characteristics of a good NPU is the ability to process the data and complete the operations quickly, with performance measured in TOPS/MACs. “The typical semiconductor tradeoff between power/performance/area (cost) is very much relevant in the case of NPU design, as well. For autonomous automotive usages, the latency of the NPU is critical, especially when it is a matter of life and death deciding when to step on the car brakes. That is also related to the functional safety design considerations. Design teams also must consider the NPU design to be compliant with the safety requirements.”
Another key consideration for programmers is the development and programming tools.
“It is not enough to build a great NPU without the appropriate software development tools that will be able to easily import the NN/AI models from popular AI frameworks, compile, optimize it, and automatically take advantage of the NPU architecture including the memory design considerations,” he said. “It is also important to provide a way to check the accuracy of the model, as well as simulation tools, so programmers can start software development and verification much before the hardware exists. This is an important consideration for time-to-market.”
Cooper agreed. “NPUs are closer to custom accelerators than a DSP, or especially a GPU or CPU, which are completely flexible. You might not choose to add an NPU unless you have a strong need for NN performance for a significant amount of time. We have customers who only need a little bit of AI use a vector DSP for the DSP performance, and reconfigure it to process AI when needed assuring maximum flexibility of their die real-estate. This is fine, but will not be as power- or area-efficient as a dedicated NPU.”
Finally, programming challenges come in when trying to determine what subset of the graph fits on the NPU, and what doesn’t. [See left side of figure 1, above]
“If it doesn’t, it has to run someplace else, so the code has to be split,” said Quadric’s Roddy said. “Along with this is a secondary command stream generator or linked list generator that gets stored in memory, and the NPU knows enough to go fetch its commands. While this part is pretty straightforward, what about all the bits that don’t run on the system? Where should those operators run? Is there an efficient implementation of that machine learning operator that already exists? If so, is it over here on the DSP, or is it over on the CPU if it doesn’t exist? Someone has to go create a new version of that. You’re doing this on a DSP because you want it to be highly performant. Now you have to code that on the DSP, and lots of DSPs lack good tools, particularly ones that have been built specifically for machine learning. General versions of DSPs — audio DSPs or basic general-purpose DSPs — may have two MAC, or quad MAC type of things. The kind of DSPs that have been built for machine learning will be very wide DSPs. Extra wide DSPs can be a good target for very wide activations and normalizations and the type of things that happen in data science but they’re novel and therefore may not have solid compilers.”
Conclusion
In the past, these programming worlds have been separate disciplines. But as AI computing increasingly is included in and on devices, and as systems become increasingly heterogeneous, software developers will need to at least be much more aware of what is happening in other areas.
Ultimately, this could become the driver for a single hardware/software architecture that allows engineering teams to write and run complex C++ code without having to partition between two or three types of processors. But there is a lot of work to be done between now and then if this is to happen. And it isn’t entirely clear, given the speed at which AI and hardware architectures are evolving, whether that architecture will still be relevant by the time it is ready.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- EVM Finance. Unified Interface for Decentralized Finance. Access Here.
- Quantum Media Group. IR/PR Amplified. Access Here.
- PlatoAiStream. Web3 Data Intelligence. Knowledge Amplified. Access Here.
- Source: https://semiengineering.com/programming-processors-in-heterogeneous-architectures/

