Tworzenie solidnych i wielokrotnego użytku potoków uczenia maszynowego (ML) może być złożonym i czasochłonnym procesem. Deweloperzy zwykle testują swoje skrypty przetwarzania i szkolenia lokalnie, ale same potoki są zazwyczaj testowane w chmurze. Tworzenie i uruchamianie pełnego potoku podczas eksperymentów zwiększa niepotrzebne obciążenie i koszty cyklu życia rozwoju. W tym poście szczegółowo opisujemy, jak możesz użyć Tryb lokalny Amazon SageMaker Pipelines do lokalnego uruchamiania potoków ML w celu skrócenia czasu opracowywania i działania potoku przy jednoczesnym obniżeniu kosztów. Gdy potok zostanie w pełni przetestowany lokalnie, możesz go łatwo uruchomić ponownie za pomocą Amazon Sage Maker zarządzanych zasobów z zaledwie kilkoma linijkami zmian w kodzie.
Przegląd cyklu życia ML
Jednym z głównych czynników napędzających nowe innowacje i aplikacje w ML jest dostępność i ilość danych wraz z tańszymi opcjami obliczeniowymi. W kilku dziedzinach ML okazała się zdolna do rozwiązywania problemów wcześniej niemożliwych do rozwiązania za pomocą klasycznych technik big data i technik analitycznych, a zapotrzebowanie na naukę o danych i praktyków ML stale rośnie. Od bardzo wysokiego poziomu cykl życia ML składa się z wielu różnych części, ale budowanie modelu ML zwykle składa się z następujących ogólnych kroków:
- Czyszczenie i przygotowanie danych (inżynieria obiektowa)
- Trening i strojenie modeli
- Ocena modelu
- Wdrażanie modelu (lub transformacja wsadowa)
Na etapie przygotowania danych dane są ładowane, masowane i przekształcane na typ danych wejściowych lub funkcji, których oczekuje model ML. Pisanie skryptów w celu przekształcenia danych jest zazwyczaj procesem iteracyjnym, w którym szybkie pętle sprzężenia zwrotnego są ważne dla przyspieszenia rozwoju. Zwykle nie jest konieczne używanie pełnego zbioru danych podczas testowania skryptów inżynierii funkcji, dlatego możesz użyć funkcja trybu lokalnego przetwarzania SageMaker. Umożliwia to uruchamianie lokalnie i iteracyjne aktualizowanie kodu przy użyciu mniejszego zestawu danych. Gdy końcowy kod jest gotowy, jest przesyłany do zadania przetwarzania zdalnego, które korzysta z pełnego zestawu danych i działa na instancjach zarządzanych przez SageMaker.
Proces opracowywania jest podobny do etapu przygotowania danych zarówno w przypadku szkolenia modelu, jak i etapu oceny modelu. Analitycy danych używają funkcja trybu lokalnego of SageMaker Training, aby szybko iterować lokalnie z mniejszymi zestawami danych przed użyciem wszystkich danych w zarządzanym przez SageMaker klastrze instancji zoptymalizowanych pod kątem ML. Przyspiesza to proces rozwoju i eliminuje koszty uruchamiania instancji ML zarządzanych przez SageMaker podczas eksperymentów.
Wraz ze wzrostem dojrzałości ML organizacji możesz użyć Rurociągi Amazon SageMaker do tworzenia potoków ML, które łączą te kroki, tworząc bardziej złożone przepływy pracy ML, które przetwarzają, trenują i oceniają modele ML. SageMaker Pipelines to w pełni zarządzana usługa do automatyzacji różnych etapów przepływu pracy ML, w tym ładowania danych, transformacji danych, szkolenia i dostrajania modeli oraz wdrażania modeli. Do niedawna można było programować i testować swoje skrypty lokalnie, ale trzeba było testować potoki ML w chmurze. To sprawiło, że iteracja przepływu i formy potoków ML była powolnym i kosztownym procesem. Teraz, dzięki dodanej funkcji trybu lokalnego w SageMaker Pipelines, możesz iterować i testować potoki ML w sposób podobny do testowania i iteracji skryptów przetwarzania i szkolenia. Możesz uruchamiać i testować potoki na komputerze lokalnym, używając niewielkiego podzbioru danych w celu sprawdzenia poprawności składni i funkcji potoku.
Rurociągi SageMaker
SageMaker Pipelines zapewnia w pełni zautomatyzowany sposób uruchamiania prostych lub złożonych przepływów pracy ML. Dzięki SageMaker Pipelines możesz tworzyć przepływy pracy ML za pomocą łatwego w użyciu pakietu Python SDK, a następnie wizualizować i zarządzać przepływem pracy za pomocą Studio Amazon SageMaker. Twoje zespoły analityków danych mogą działać wydajniej i szybciej skalować, przechowując i ponownie wykorzystując kroki przepływu pracy utworzone w SageMaker Pipelines. Możesz również korzystać z gotowych szablonów, które automatyzują tworzenie infrastruktury i repozytorium, aby budować, testować, rejestrować i wdrażać modele w środowisku ML. Te szablony są automatycznie dostępne dla Twojej organizacji i są udostępniane za pomocą Katalog usług AWS produktów.
SageMaker Pipelines zapewnia praktyki ciągłej integracji i ciągłego wdrażania (CI/CD) w ML, takie jak utrzymywanie parzystości między środowiskami programistycznymi i produkcyjnymi, kontrola wersji, testowanie na żądanie i kompleksowa automatyzacja, co pomaga skalować ML w całym organizacja. Praktycy DevOps wiedzą, że niektóre z głównych korzyści płynących z używania technik CI/CD obejmują wzrost produktywności dzięki komponentom wielokrotnego użytku oraz wzrost jakości dzięki zautomatyzowanemu testowaniu, co prowadzi do szybszego zwrotu z inwestycji dla celów biznesowych. Korzyści te są teraz dostępne dla praktyków MLOps dzięki wykorzystaniu SageMaker Pipelines do automatyzacji szkolenia, testowania i wdrażania modeli ML. W trybie lokalnym możesz teraz znacznie szybciej iterować podczas tworzenia skryptów do użycia w potoku. Pamiętaj, że lokalnych instancji potoku nie można wyświetlać ani uruchamiać w środowisku IDE Studio; jednak wkrótce będą dostępne dodatkowe opcje przeglądania lokalnych rurociągów.
SageMaker SDK zapewnia ogólny cel konfiguracja w trybie lokalnym który umożliwia programistom uruchamianie i testowanie obsługiwanych procesorów i estymatorów w ich lokalnym środowisku. Możesz korzystać z trenowania w trybie lokalnym z wieloma obrazami platformy wspieranymi przez AWS (TensorFlow, MXNet, Chainer, PyTorch i Scikit-Learn), a także z obrazami, które sam dostarczasz.
SageMaker Pipelines, który tworzy ukierunkowany wykres acykliczny (DAG) z zaaranżowanych kroków przepływu pracy, obsługuje wiele działań, które są częścią cyklu życia ML. W trybie lokalnym obsługiwane są następujące kroki:
- Przetwarzanie etapów pracy – Uproszczone, zarządzane środowisko SageMaker do uruchamiania obciążeń przetwarzania danych, takich jak inżynieria funkcji, walidacja danych, ocena modeli i interpretacja modeli
- Szkolenie etapów pracy – Iteracyjny proces, który uczy model dokonywania prognoz poprzez prezentację przykładów ze zbioru danych treningowych
- Zadania dostrajania hiperparametrów – Zautomatyzowany sposób oceny i wyboru hiperparametrów, które dają najdokładniejszy model
- Warunkowe kroki uruchamiania – Krok, który zapewnia warunkowy przebieg rozgałęzień w rurociągu
- Krok modelu – Używając argumentów CreateModel, ten krok może stworzyć model do użycia w krokach transformacji lub późniejszego wdrożenia jako punkt końcowy
- Przekształć etapy pracy – Zadanie transformacji wsadowej, które generuje prognozy z dużych zestawów danych i uruchamia wnioskowanie, gdy trwały punkt końcowy nie jest potrzebny
- Nieudane kroki – Krok, który zatrzymuje uruchomienie rurociągu i oznacza go jako nieudany
Omówienie rozwiązania
Nasze rozwiązanie demonstruje podstawowe kroki tworzenia i uruchamiania potoków SageMaker w trybie lokalnym, co oznacza użycie lokalnego procesora, pamięci RAM i zasobów dyskowych do ładowania i uruchamiania kroków przepływu pracy. Twoje lokalne środowisko może działać na laptopie przy użyciu popularnych środowisk IDE, takich jak VSCode lub PyCharm, lub może być hostowane przez SageMaker przy użyciu klasycznych instancji notebooków.
Tryb lokalny umożliwia analitykom danych łączenie kroków, które mogą obejmować zadania przetwarzania, szkolenia i oceny, oraz lokalne uruchamianie całego przepływu pracy. Po zakończeniu testowania lokalnego możesz ponownie uruchomić potok w środowisku zarządzanym przez SageMaker, zastępując LocalPipelineSession obiekt z PipelineSession, co zapewnia spójność cyklu życia ML.
W tym przykładzie notebooka używamy standardowego, publicznie dostępnego zbioru danych, Zbiór danych UCI Machine Learning Abalone. Celem jest wytrenowanie modelu ML w celu określenia wieku ślimaka słuchotkowego na podstawie jego pomiarów fizycznych. W istocie jest to problem regresji.
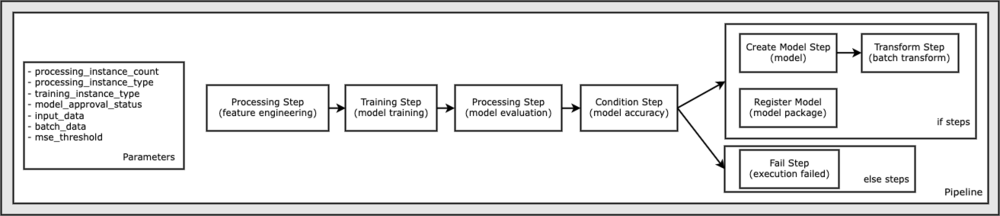
Cały kod wymagany do uruchomienia tego przykładowego notebooka jest dostępny w serwisie GitHub w amazon-sagemaker-przykłady magazyn. W tym przykładzie notesu każdy krok przepływu pracy potoku jest tworzony niezależnie, a następnie połączony w celu utworzenia potoku. Tworzymy następujące kroki:
- Etap przetwarzania (inżynieria funkcji)
- Etap szkolenia (szkolenie modelowe)
- Etap przetwarzania (ocena modelu)
- Krok warunku (dokładność modelu)
- Utwórz krok modelu (model)
- Krok transformacji (przekształcenie wsadowe)
- Zarejestruj krok modelu (pakiet modelu)
- Etap niepowodzenia (uruchomienie nie powiodło się)
Poniższy diagram ilustruje nasz potok.
Wymagania wstępne
Aby kontynuować w tym poście, potrzebujesz:
Po spełnieniu tych wymagań wstępnych możesz uruchomić przykładowy notes zgodnie z opisem w poniższych sekcjach.
Zbuduj swój potok
W tej próbce notebooka używamy Tryb SageMakera dla większości procesów ML, co oznacza, że dostarczamy rzeczywisty kod Pythona (skrypty) do wykonania czynności i przekazujemy referencję do tego kodu. Tryb skryptu zapewnia dużą elastyczność w kontrolowaniu zachowania w ramach przetwarzania SageMaker, umożliwiając dostosowanie kodu przy jednoczesnym korzystaniu z gotowych kontenerów SageMaker, takich jak XGBoost lub Scikit-Learn. Niestandardowy kod jest zapisywany w pliku skryptu Pythona przy użyciu komórek zaczynających się od magicznego polecenia %%writefile, na przykład:
%%writefile code/evaluation.py
Głównym aktywatorem trybu lokalnego jest LocalPipelineSession obiekt, który jest tworzony z zestawu SDK Pythona. Poniższe segmenty kodu pokazują, jak utworzyć potok SageMaker w trybie lokalnym. Chociaż możesz skonfigurować lokalną ścieżkę danych dla wielu kroków lokalnego potoku, Amazon S3 jest domyślną lokalizacją do przechowywania danych wyjściowych przez transformację. Nowa LocalPipelineSession obiekt jest przekazywany do pakietu Python SDK w wielu wywołaniach interfejsu API przepływu pracy SageMaker opisanych w tym poście. Zauważ, że możesz użyć local_pipeline_session zmienna do pobierania odwołań do domyślnego zasobnika S3 i bieżącej nazwy regionu.
Zanim utworzymy poszczególne kroki potoku, ustawiamy kilka parametrów używanych przez potok. Niektóre z tych parametrów są literałami ciągów, podczas gdy inne są tworzone jako specjalne typy wyliczeniowe dostarczane przez zestaw SDK. Wyliczeniowe wpisywanie zapewnia, że do potoku dostarczane są prawidłowe ustawienia, takie jak ten, który jest przekazywany do ConditionLessThanOrEqualTo krok dalej w dół:
mse_threshold = ParameterFloat(name="MseThreshold", default_value=7.0)
Aby utworzyć etap przetwarzania danych, który jest tutaj używany do wykonywania inżynierii funkcji, używamy SKLearnProcessor do załadowania i przekształcenia zbioru danych. Mijamy local_pipeline_session zmienna do konstruktora klasy, która instruuje krok przepływu pracy, aby działał w trybie lokalnym:
Następnie tworzymy nasz pierwszy rzeczywisty krok potoku, a ProcessingStep obiekt importowany z pakietu SageMaker SDK. Argumenty procesora są zwracane z wywołania do SKLearnProcessor metoda run(). Ten krok przepływu pracy jest połączony z innymi krokami pod koniec notatnika, aby wskazać kolejność operacji w potoku.
Następnie dostarczamy kod, aby ustanowić krok szkolenia, najpierw tworząc wystąpienie standardowego estymatora za pomocą SDK SageMaker. Mijamy to samo local_pipeline_session zmienna do estymatora o nazwie xgb_train, jako sagemaker_session argument. Ponieważ chcemy trenować model XGBoost, musimy wygenerować prawidłowy identyfikator URI obrazu, określając następujące parametry, w tym platformę i kilka parametrów wersji:
Opcjonalnie możemy wywołać dodatkowe metody estymatora, na przykład set_hyperparameters(), aby zapewnić ustawienia hiperparametrów dla zadania szkoleniowego. Teraz, gdy mamy skonfigurowany estymator, jesteśmy gotowi do stworzenia właściwego etapu szkolenia. Po raz kolejny importujemy TrainingStep klasa z biblioteki SDK SageMaker:
Następnie budujemy kolejny etap przetwarzania w celu wykonania oceny modelu. Odbywa się to poprzez utworzenie ScriptProcessor instancja i przekazanie local_pipeline_session obiekt jako parametr:
Aby umożliwić wdrożenie wytrenowanego modelu, albo do Punkt końcowy SageMaker w czasie rzeczywistym lub do transformacji wsadowej, musimy utworzyć Model obiektu, przekazując artefakty modelu, odpowiedni identyfikator URI obrazu i opcjonalnie nasz niestandardowy kod wnioskowania. Następnie przekazujemy to Model sprzeciwić się ModelStep, który jest dodawany do lokalnego potoku. Zobacz następujący kod:
Następnie tworzymy krok transformacji wsadowej, w którym przesyłamy zestaw wektorów cech i wykonujemy wnioskowanie. Najpierw musimy stworzyć Transformer obiekt i przekazać local_pipeline_session parametr do niego. Następnie tworzymy TransformStep, przekazując wymagane argumenty i dodaj to do definicji potoku:
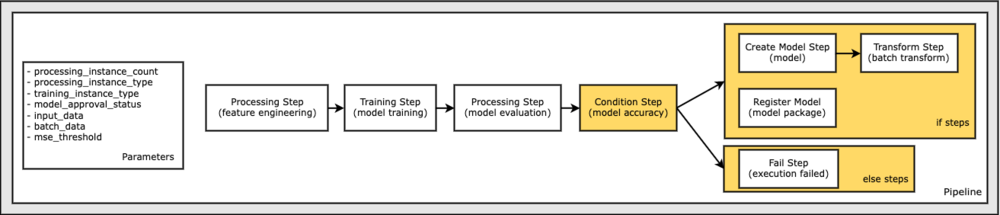
Na koniec chcemy dodać warunek gałęzi do przepływu pracy, aby uruchomić transformację wsadową tylko wtedy, gdy wyniki oceny modelu spełniają nasze kryteria. Możemy wskazać ten warunek, dodając a ConditionStep z określonym typem warunku, np. ConditionLessThanOrEqualTo. Następnie wyliczamy kroki dla dwóch gałęzi, zasadniczo definiując gałęzie if/else lub true/false potoku. Kroki if podane w ConditionStep (krok_utwórz_model, krok_przekształcenie) są uruchamiane za każdym razem, gdy warunek ma wartość True.
Poniższy diagram ilustruje tę gałąź warunkową i powiązane kroki if/else. Uruchamiana jest tylko jedna gałąź na podstawie wyniku kroku oceny modelu w porównaniu z krokiem warunku.
Teraz, gdy mamy zdefiniowane wszystkie nasze kroki i utworzone instancje klas bazowych, możemy połączyć je w potok. Podajemy pewne parametry i, co najważniejsze, definiujemy kolejność działania, po prostu wymieniając kroki w pożądanej kolejności. Zauważ, że TransformStep nie jest wyświetlany tutaj, ponieważ jest celem kroku warunkowego i został dostarczony jako argument kroku do ConditionalStep wcześniej.
Aby uruchomić potok, musisz wywołać dwie metody: pipeline.upsert(), który przesyła potok do usługi bazowej i pipeline.start(), który uruchamia potok. Możesz użyć różnych innych metod, aby zbadać stan uruchomienia, wyświetlić listę kroków potoku i nie tylko. Ponieważ użyliśmy sesji potoku trybu lokalnego, wszystkie te kroki są uruchamiane lokalnie na procesorze. Dane wyjściowe komórki poniżej metody start pokazują dane wyjściowe z potoku:
Powinieneś zobaczyć komunikat na dole danych wyjściowych komórki podobny do następującego:
Pipeline execution d8c3e172-089e-4e7a-ad6d-6d76caf987b7 SUCCEEDED
Przywróć zasoby zarządzane
Po potwierdzeniu, że potok działa bez błędów i jesteśmy zadowoleni z przepływu i formy potoku, możemy odtworzyć potok, ale z zasobami zarządzanymi przez SageMaker i ponownie go uruchomić. Jedyną wymaganą zmianą jest użycie PipelineSession obiekt zamiast LocalPipelineSession:
od sagemaker.workflow.pipeline_context importuj LocalPipelineSessionfrom sagemaker.workflow.pipeline_context import PipelineSession
local_pipeline_session = LocalPipelineSession()pipeline_session = PipelineSession()
Informuje to usługę, aby uruchamiała każdy krok odwołujący się do tego obiektu sesji na zasobach zarządzanych przez SageMaker. Biorąc pod uwagę niewielką zmianę, ilustrujemy tylko wymagane zmiany kodu w następującej komórce kodu, ale ta sama zmiana musiałaby zostać zaimplementowana w każdej komórce za pomocą local_pipeline_session obiekt. Zmiany są jednak identyczne we wszystkich komórkach, ponieważ zastępujemy tylko local_pipeline_session obiekt z pipeline_session obiekt.
Po zastąpieniu wszędzie lokalnego obiektu sesji ponownie tworzymy potok i uruchamiamy go z zasobami zarządzanymi przez SageMaker:
Sprzątać
Jeśli chcesz zachować porządek w środowisku Studio, możesz użyć następujących metod, aby usunąć potok SageMaker i model. Pełny kod można znaleźć w próbce notatnik.
Wnioski
Do niedawna można było używać funkcji trybu lokalnego w SageMaker Processing i SageMaker Training, aby wykonać lokalne iteracje skryptów przetwarzania i szkolenia przed uruchomieniem ich na wszystkich danych za pomocą zasobów zarządzanych przez SageMaker. Dzięki nowej funkcji trybu lokalnego w SageMaker Pipelines praktycy ML mogą teraz stosować tę samą metodę podczas iteracji na swoich potokach ML, łącząc ze sobą różne przepływy pracy ML. Gdy potok jest gotowy do produkcji, uruchomienie go z zasobami zarządzanymi przez SageMaker wymaga tylko kilku linijek zmian w kodzie. Skraca to czas działania potoku podczas opracowywania, co prowadzi do szybszego rozwoju potoku z szybszymi cyklami rozwoju, przy jednoczesnym obniżeniu kosztów zasobów zarządzanych przez SageMaker.
Aby dowiedzieć się więcej, odwiedź Rurociągi Amazon SageMaker or Użyj SageMaker Pipelines, aby wykonywać swoje zadania lokalnie.
O autorach
 Paweł Hargis skupił swoje wysiłki na uczeniu maszynowym w kilku firmach, w tym AWS, Amazon i Hortonworks. Lubi budować rozwiązania technologiczne i uczyć ludzi, jak je wykorzystać. Przed objęciem stanowiska w AWS był głównym architektem Amazon Exports and Expansions, pomagając amazon.com poprawić doświadczenie międzynarodowych klientów. Paul lubi pomagać klientom w rozwijaniu inicjatyw uczenia maszynowego w celu rozwiązywania rzeczywistych problemów.
Paweł Hargis skupił swoje wysiłki na uczeniu maszynowym w kilku firmach, w tym AWS, Amazon i Hortonworks. Lubi budować rozwiązania technologiczne i uczyć ludzi, jak je wykorzystać. Przed objęciem stanowiska w AWS był głównym architektem Amazon Exports and Expansions, pomagając amazon.com poprawić doświadczenie międzynarodowych klientów. Paul lubi pomagać klientom w rozwijaniu inicjatyw uczenia maszynowego w celu rozwiązywania rzeczywistych problemów.
 Niklas Palma jest architektem rozwiązań w AWS w Sztokholmie w Szwecji, gdzie pomaga klientom z krajów skandynawskich odnosić sukcesy w chmurze. Szczególnie pasjonuje się technologiami bezserwerowymi oraz IoT i uczeniem maszynowym. Poza pracą Niklas jest zapalonym narciarzem biegowym i snowboardzistą, a także mistrzem gotowania jajek.
Niklas Palma jest architektem rozwiązań w AWS w Sztokholmie w Szwecji, gdzie pomaga klientom z krajów skandynawskich odnosić sukcesy w chmurze. Szczególnie pasjonuje się technologiami bezserwerowymi oraz IoT i uczeniem maszynowym. Poza pracą Niklas jest zapalonym narciarzem biegowym i snowboardzistą, a także mistrzem gotowania jajek.
 Kirita Thadaki jest architektem ML Solutions pracującym w zespole SageMaker Service SA. Przed dołączeniem do AWS Kirit pracował we wczesnych etapach start-upów AI, a następnie przez pewien czas konsultował się na różnych stanowiskach w badaniach AI, MLOps i przywództwie technicznym.
Kirita Thadaki jest architektem ML Solutions pracującym w zespole SageMaker Service SA. Przed dołączeniem do AWS Kirit pracował we wczesnych etapach start-upów AI, a następnie przez pewien czas konsultował się na różnych stanowiskach w badaniach AI, MLOps i przywództwie technicznym.

