W zmieniającym się środowisku produkcyjnym transformacyjna siła sztucznej inteligencji i uczenia maszynowego (ML) jest oczywista, napędzając rewolucję cyfrową, która usprawnia operacje i zwiększa produktywność. Postęp ten stwarza jednak wyjątkowe wyzwania dla przedsiębiorstw korzystających z rozwiązań opartych na danych. Obiekty przemysłowe zmagają się z ogromnymi ilościami nieustrukturyzowanych danych pochodzących z czujników, systemów telemetrycznych i sprzętu rozproszonego po liniach produkcyjnych. Dane w czasie rzeczywistym mają kluczowe znaczenie w zastosowaniach takich jak konserwacja predykcyjna i wykrywanie anomalii, jednak opracowywanie niestandardowych modeli ML dla każdego przypadku zastosowania przemysłowego przy użyciu takich danych szeregów czasowych wymaga od analityków danych znacznej ilości czasu i zasobów, co utrudnia powszechne przyjęcie.
generatywna sztuczna inteligencja przy użyciu dużych, wstępnie wytrenowanych modeli podstawowych (FM), takich jak Claude może szybko generować różnorodne treści, od tekstu konwersacyjnego po kod komputerowy w oparciu o proste podpowiedzi tekstowe, tzw monit o strzał zerowy. Eliminuje to potrzebę ręcznego opracowywania przez analityków danych konkretnych modeli uczenia maszynowego dla każdego przypadku użycia, a tym samym demokratyzuje dostęp do sztucznej inteligencji, z korzyścią nawet dla małych producentów. Pracownicy zyskują produktywność dzięki spostrzeżeniom generowanym przez sztuczną inteligencję, inżynierowie mogą proaktywnie wykrywać anomalie, menedżerowie łańcucha dostaw optymalizują zapasy, a kierownictwo zakładu podejmuje świadome decyzje oparte na danych.
Niemniej jednak samodzielne FM napotykają ograniczenia w obsłudze złożonych danych przemysłowych z ograniczeniami dotyczącymi rozmiaru kontekstu (zwykle mniej niż 200,000 XNUMX tokenów), co stwarza wyzwania. Aby rozwiązać ten problem, możesz wykorzystać zdolność FM do generowania kodu w odpowiedzi na zapytania w języku naturalnym (NLQ). Agenci lubią Pandy AI wchodzą w grę, uruchamiając ten kod na danych szeregów czasowych o wysokiej rozdzielczości i obsługując błędy za pomocą FM. PandasAI to biblioteka języka Python, która dodaje możliwości generatywnej sztucznej inteligencji do pand, popularnego narzędzia do analizy i manipulacji danymi.
Jednak złożone NLQ, takie jak przetwarzanie danych szeregów czasowych, agregacja wielopoziomowa oraz operacje na tabelach przestawnych lub połączonych, mogą dawać niespójną dokładność skryptu Pythona z podpowiedzią zerową.
Aby zwiększyć dokładność generowania kodu, proponujemy konstruowanie dynamiczne monity o wielokrotne strzały dla NLQ. Podpowiadanie wielokrotne zapewnia dodatkowy kontekst FM, pokazując kilka przykładów pożądanych wyników dla podobnych podpowiedzi, zwiększając dokładność i spójność. W tym poście monity wielokrotne są pobierane z osadzania zawierającego pomyślnie wykonany kod Pythona uruchomiony na podobnym typie danych (na przykład dane szeregów czasowych o wysokiej rozdzielczości z urządzeń Internetu rzeczy). Dynamicznie skonstruowany wiersz podpowiedzi zapewnia najbardziej odpowiedni kontekst dla FM i zwiększa możliwości FM w zakresie zaawansowanych obliczeń matematycznych, przetwarzania danych szeregów czasowych i zrozumienia akronimów danych. Ta ulepszona odpowiedź ułatwia pracownikom przedsiębiorstw i zespołom operacyjnym interakcję z danymi i wyciąganie wniosków bez konieczności posiadania rozległych umiejętności w zakresie analityki danych.
Poza analizą danych szeregów czasowych, FM okazują się cenne w różnych zastosowaniach przemysłowych. Zespoły konserwacyjne oceniają stan zasobów i rejestrują obrazy Amazon Rekognitionoparte na podsumowaniach funkcjonalności i analizie przyczyn źródłowych anomalii przy użyciu inteligentnych wyszukiwań Odzyskanie Augmented Generation (SZMATA). Aby uprościć te przepływy pracy, AWS wprowadziło Amazońska skała macierzysta, umożliwiając tworzenie i skalowanie generatywnych aplikacji AI za pomocą najnowocześniejszych, wstępnie przeszkolonych FM, takich jak Klaudiusz v2. Z Bazy wiedzy na temat Amazon Bedrockmożna uprościć proces opracowywania RAG, aby zapewnić pracownikom zakładu dokładniejszą analizę przyczyn źródłowych anomalii. W naszym poście przedstawiono inteligentnego asystenta do zastosowań przemysłowych, obsługiwanego przez Amazon Bedrock, rozwiązującego wyzwania NLQ, generującego podsumowania części na podstawie obrazów i ulepszającego odpowiedzi FM na potrzeby diagnostyki sprzętu za pomocą podejścia RAG.
Omówienie rozwiązania
Poniższy schemat ilustruje architekturę rozwiązania.

Przepływ pracy obejmuje trzy różne przypadki użycia:
Przypadek użycia 1: NLQ z danymi szeregów czasowych
Przepływ pracy dla NLQ z danymi szeregów czasowych składa się z następujących kroków:
- Korzystamy z systemu monitorowania stanu z funkcjami ML do wykrywania anomalii, takich jak Amazon Monitron, do monitorowania stanu urządzeń przemysłowych. Amazon Monitron jest w stanie wykryć potencjalne awarie sprzętu na podstawie pomiarów wibracji i temperatury sprzętu.
- Gromadzimy dane szeregów czasowych poprzez przetwarzanie Amazon Monitron dane przez Strumienie danych Amazon Kinesis i Wąż strażacki Amazon Data, konwertując go do tabelarycznego formatu CSV i zapisując w formacie Usługa Amazon Simple Storage Łyżka (Amazon S3).
- Użytkownik końcowy może rozpocząć czat ze swoimi danymi szeregów czasowych w Amazon S3, wysyłając zapytanie w języku naturalnym do aplikacji Streamlit.
- Aplikacja Streamlit przekazuje zapytania użytkowników do Model osadzania tekstu Amazon Bedrock Titan aby osadzić to zapytanie i przeprowadza wyszukiwanie podobieństwa w pliku Usługa Amazon OpenSearch indeks, który zawiera wcześniejsze kody NLQ i przykładowe kody.
- Po wyszukiwaniu podobieństwa najlepsze podobne przykłady, w tym pytania NLQ, schemat danych i kody Pythona, są wstawiane w niestandardowym wierszu zachęty.
- PandasAI wysyła ten niestandardowy monit do modelu Amazon Bedrock Claude v2.
- Aplikacja wykorzystuje agenta PandasAI do interakcji z modelem Amazon Bedrock Claude v2, generując kod w języku Python na potrzeby analizy danych Amazon Monitron i odpowiedzi NLQ.
- Gdy model Amazon Bedrock Claude v2 zwróci kod Pythona, PandasAI uruchamia zapytanie Pythona na danych Amazon Monitron przesłanych z aplikacji, zbierając dane wyjściowe kodu i uwzględniając wszelkie niezbędne ponowne próby w przypadku nieudanych uruchomień.
- Aplikacja Streamlit zbiera odpowiedzi za pośrednictwem PandasAI i udostępnia je użytkownikom. Jeśli wynik jest zadowalający, użytkownik może oznaczyć go jako pomocny, zapisując wygenerowany przez NLQ i Claude kod Pythona w usłudze OpenSearch.
Przypadek użycia 2: Podsumowanie generowania uszkodzonych części
Nasz przypadek użycia generowania podsumowania składa się z następujących kroków:
- Gdy użytkownik już wie, który zasób przemysłowy wykazuje nietypowe zachowanie, może przesłać obrazy nieprawidłowo działającej części, aby określić, czy coś jest fizycznie nie tak z tą częścią, zgodnie z jej specyfikacją techniczną i warunkami działania.
- Użytkownik może skorzystać z API rozpoznawania Amazon DetectText aby wyodrębnić dane tekstowe z tych obrazów.
- Wyodrębnione dane tekstowe są zawarte w monicie dotyczącym modelu Amazon Bedrock Claude v2, umożliwiając modelowi wygenerowanie 200-wyrazowego podsumowania wadliwie działającej części. Użytkownik może wykorzystać te informacje do przeprowadzenia dalszej kontroli części.
Przypadek użycia 3: Diagnoza przyczyny źródłowej
Nasz przypadek użycia diagnostyki pierwotnej przyczyny składa się z następujących kroków:
- Użytkownik uzyskuje dane przedsiębiorstwa w różnych formatach dokumentów (PDF, TXT itd.) związane z nieprawidłowo działającymi zasobami i przesyła je do segmentu S3.
- Baza wiedzy zawierająca te pliki jest generowana w serwisie Amazon Bedrock z modelem osadzania tekstu Titan i domyślnym magazynem wektorów usługi OpenSearch Service.
- Użytkownik zadaje pytania związane z diagnostyką pierwotnej przyczyny nieprawidłowego działania sprzętu. Odpowiedzi są generowane poprzez bazę wiedzy Amazon Bedrock przy zastosowaniu podejścia RAG.
Wymagania wstępne
Aby móc śledzić ten post, powinieneś spełniać następujące wymagania wstępne:
Wdróż infrastrukturę rozwiązania
Aby skonfigurować zasoby rozwiązania, wykonaj następujące kroki:
- Wdróż Tworzenie chmury AWS szablon opensearchsagemaker.yml, który tworzy kolekcję i indeks usługi OpenSearch, Amazon Sage Maker instancja notebooka i wiadro S3. Możesz nazwać ten stos AWS CloudFormation jako:
genai-sagemaker. - Otwórz instancję notatnika SageMaker w JupyterLab. Znajdziesz następujące informacje GitHub repo już pobrany w tej instancji: odblokowanie-potencjału-generatywnej-AI-w-operacjach-przemysłowych.
- Uruchom notatnik z następującego katalogu w tym repozytorium: odblokowanie-potencjału-generatywnej-AI-w-operacjach-przemysłowych/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Ten notatnik załaduje indeks usługi OpenSearch przy użyciu notatnika SageMaker do przechowywania par klucz-wartość z istniejące 23 przykłady NLQ.
- Prześlij dokumenty z folderu danych dokument części aktywów w repozytorium GitHub do segmentu S3 wymienionego w wynikach stosu CloudFormation.

Następnie tworzysz bazę wiedzy dla dokumentów w Amazon S3.
- Na konsoli Amazon Bedrock wybierz Blog w okienku nawigacji.
- Dodaj Utwórz bazę wiedzy.
- W razie zamówieenia projektu Nazwa bazy wiedzy, Wpisz imię.
- W razie zamówieenia projektu Rola środowiska wykonawczego, Wybierz Utwórz i użyj nowej roli usługi.
- W razie zamówieenia projektu Nazwa źródła danychwprowadź nazwę źródła danych.
- W razie zamówieenia projektu Identyfikator URI S3wprowadź ścieżkę S3 zasobnika, do którego przesłano dokumenty zawierające główną przyczynę.
- Dodaj Następna.
 Model osadzania Titan jest wybierany automatycznie.
Model osadzania Titan jest wybierany automatycznie. - Wybierz Szybko utwórz nowy sklep wektorowy.
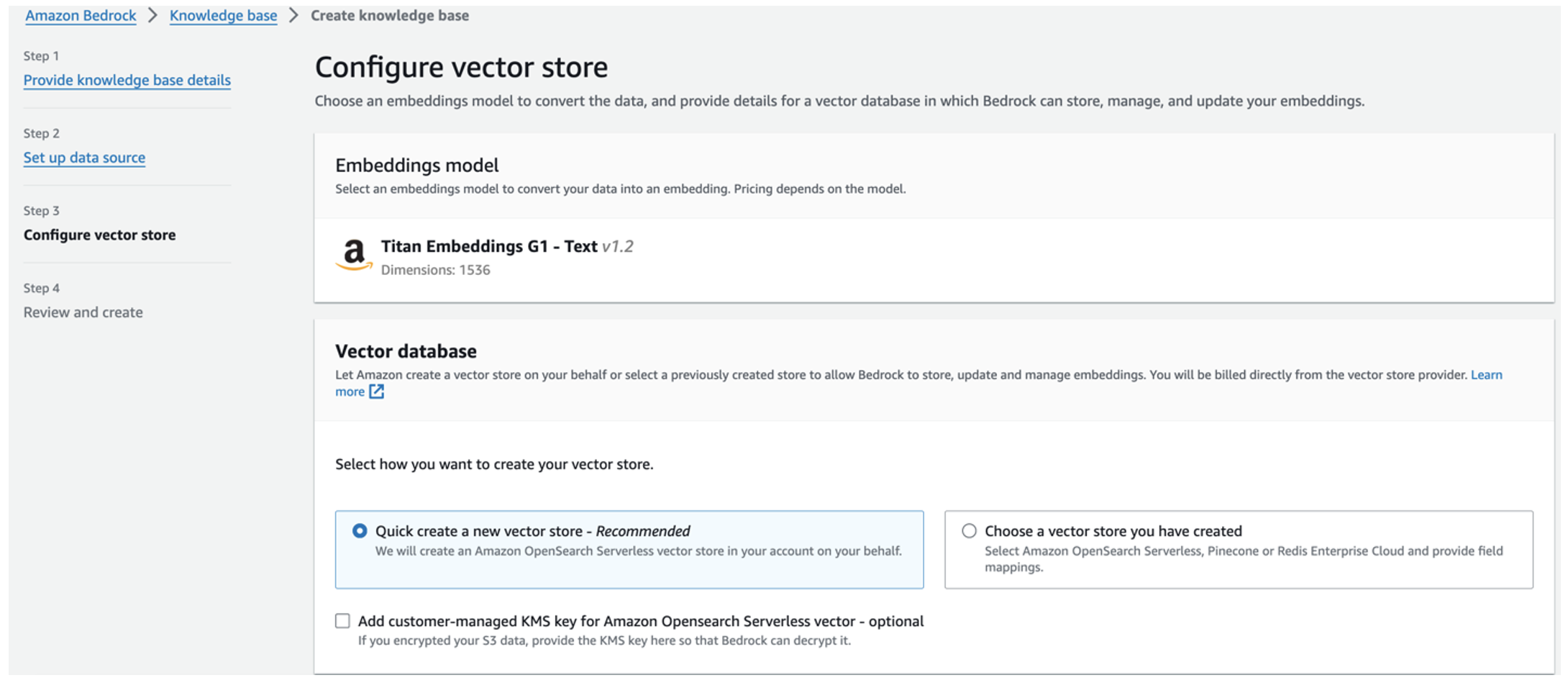
- Przejrzyj swoje ustawienia i stwórz bazę wiedzy, wybierając Utwórz bazę wiedzy.
- Po pomyślnym utworzeniu bazy wiedzy wybierz Sync aby zsynchronizować segment S3 z bazą wiedzy.

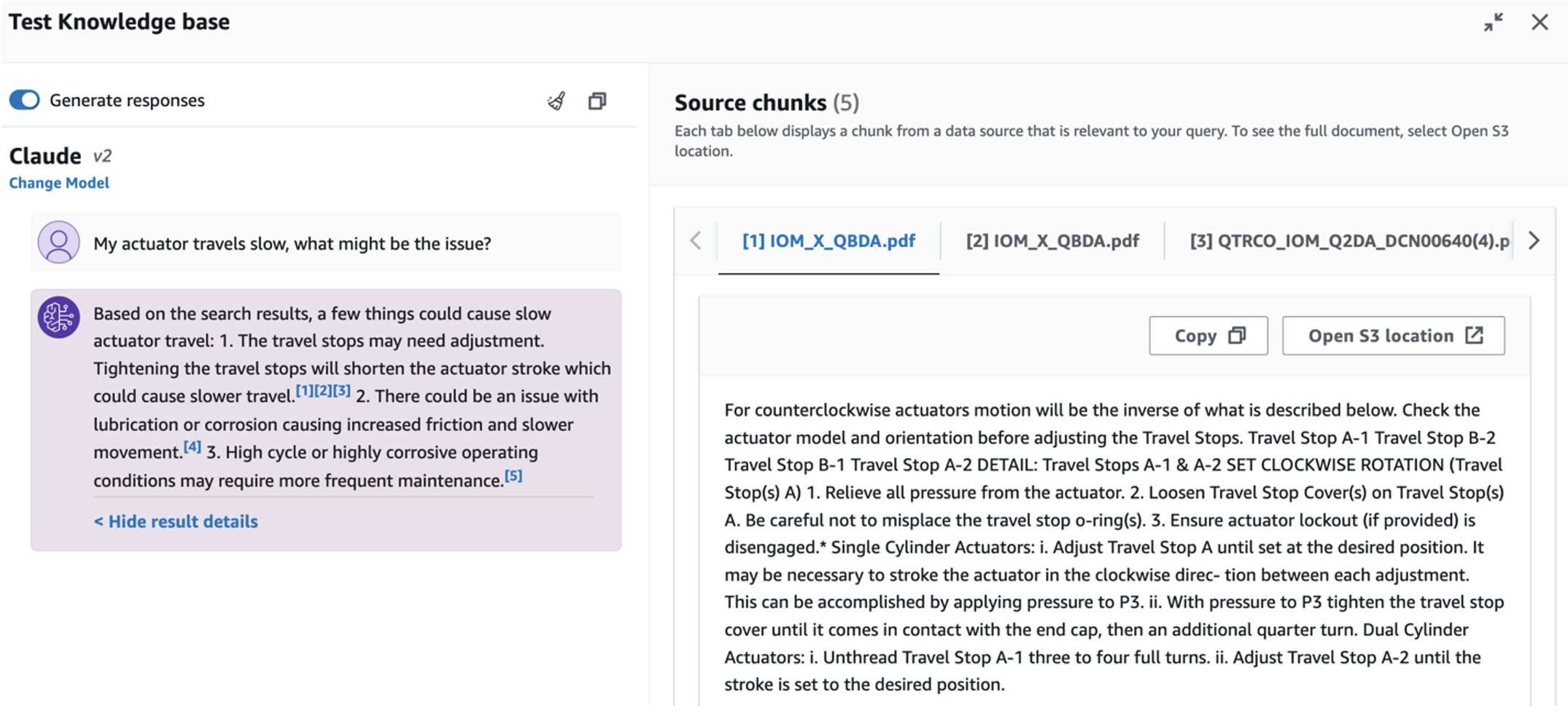
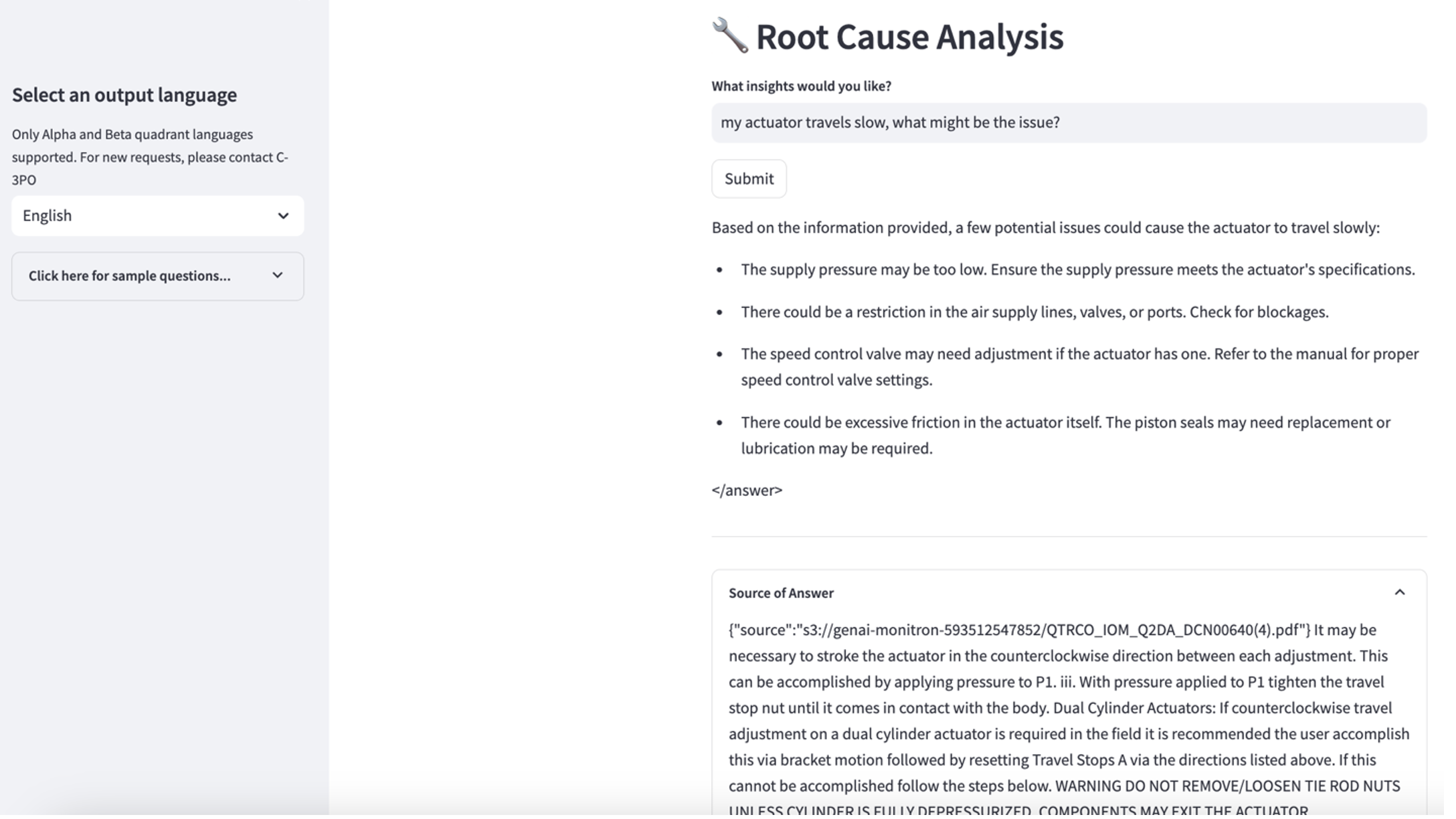
- Po skonfigurowaniu bazy wiedzy możesz przetestować podejście RAG do diagnozowania pierwotnej przyczyny, zadając pytania typu „Mój siłownik pracuje wolno. Co może być przyczyną?”
Następnym krokiem jest wdrożenie aplikacji z wymaganymi pakietami bibliotek na komputerze lub instancji EC2 (Ubuntu Server 22.04 LTS).
- Skonfiguruj swoje poświadczenia AWS za pomocą interfejsu CLI AWS na lokalnym komputerze. Dla uproszczenia możesz użyć tej samej roli administratora, której użyłeś do wdrożenia stosu CloudFormation. Jeśli używasz Amazon EC2, przypisz odpowiednią rolę IAM do instancji.
- Clone GitHub repo:
- Zmień katalog na
unlocking-the-potential-of-generative-ai-in-industrial-operations/srci uruchomsetup.shskrypt w tym folderze, aby zainstalować wymagane pakiety, w tym LangChain i PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Uruchom aplikację Streamlit za pomocą następującego polecenia:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Podaj kolekcję ARN usługi OpenSearch utworzoną w Amazon Bedrock w poprzednim kroku.
Porozmawiaj ze swoim asystentem ds. kondycji zasobów
Po zakończeniu kompleksowego wdrożenia można uzyskać dostęp do aplikacji za pośrednictwem hosta lokalnego na porcie 8501, który otwiera okno przeglądarki z interfejsem internetowym. Jeśli wdrożyłeś aplikację w instancji EC2, zezwól na dostęp do portu 8501 za pośrednictwem reguły ruchu przychodzącego grupy zabezpieczeń. Możesz przechodzić do różnych kart dla różnych zastosowań.
Poznaj przypadek użycia 1
Aby zbadać pierwszy przypadek użycia, wybierz Wgląd w dane i wykres. Rozpocznij od przesłania danych szeregów czasowych. Jeśli nie masz istniejącego pliku danych szeregów czasowych do wykorzystania, możesz przesłać następujący plik przykładowy plik CSV z anonimowymi danymi projektu Amazon Monitron. Jeśli masz już projekt Amazon Monitron, zapoznaj się z Generuj przydatne informacje do zarządzania konserwacją zapobiegawczą za pomocą Amazon Monitron i Amazon Kinesis aby przesyłać strumieniowo dane Amazon Monitron do Amazon S3 i wykorzystywać je w tej aplikacji.
Po zakończeniu przesyłania wpisz zapytanie, aby rozpocząć rozmowę z Twoimi danymi. Dla Twojej wygody lewy pasek boczny zawiera szereg przykładowych pytań. Poniższe zrzuty ekranu ilustrują odpowiedź i kod Pythona wygenerowany przez FM podczas wprowadzania pytania, takiego jak „Powiedz mi unikalną liczbę czujników dla każdej lokalizacji wyświetlanej odpowiednio jako Ostrzeżenie lub Alarm?” (pytanie na poziomie trudnym) lub „W przypadku czujników, dla których sygnał temperatury jest NIEZDROWY, czy możesz obliczyć czas w dniach dla każdego czujnika, który wykazuje nieprawidłowy sygnał wibracji?” (pytanie na poziomie wyzwania). Aplikacja odpowie na Twoje pytanie, a także pokaże skrypt Pythona analizy danych, który przeprowadziła w celu wygenerowania takich wyników.


Jeśli odpowiedź Cię satysfakcjonuje, możesz oznaczyć ją jako Pomocny, zapisując wygenerowany przez NLQ i Claude kod Pythona w indeksie usługi OpenSearch.

Poznaj przypadek użycia 2
Aby poznać drugi przypadek użycia, wybierz opcję Podsumowanie przechwyconego obrazu w aplikacji Streamlit. Możesz przesłać obraz swojego obiektu przemysłowego, a aplikacja wygeneruje 200-wyrazowe podsumowanie jego specyfikacji technicznej i warunków pracy na podstawie informacji o obrazie. Poniższy zrzut ekranu przedstawia podsumowanie wygenerowane na podstawie obrazu napędu silnika pasowego. Aby przetestować tę funkcję, jeśli nie masz odpowiedniego obrazu, możesz skorzystać z poniższych przykładowy obraz.
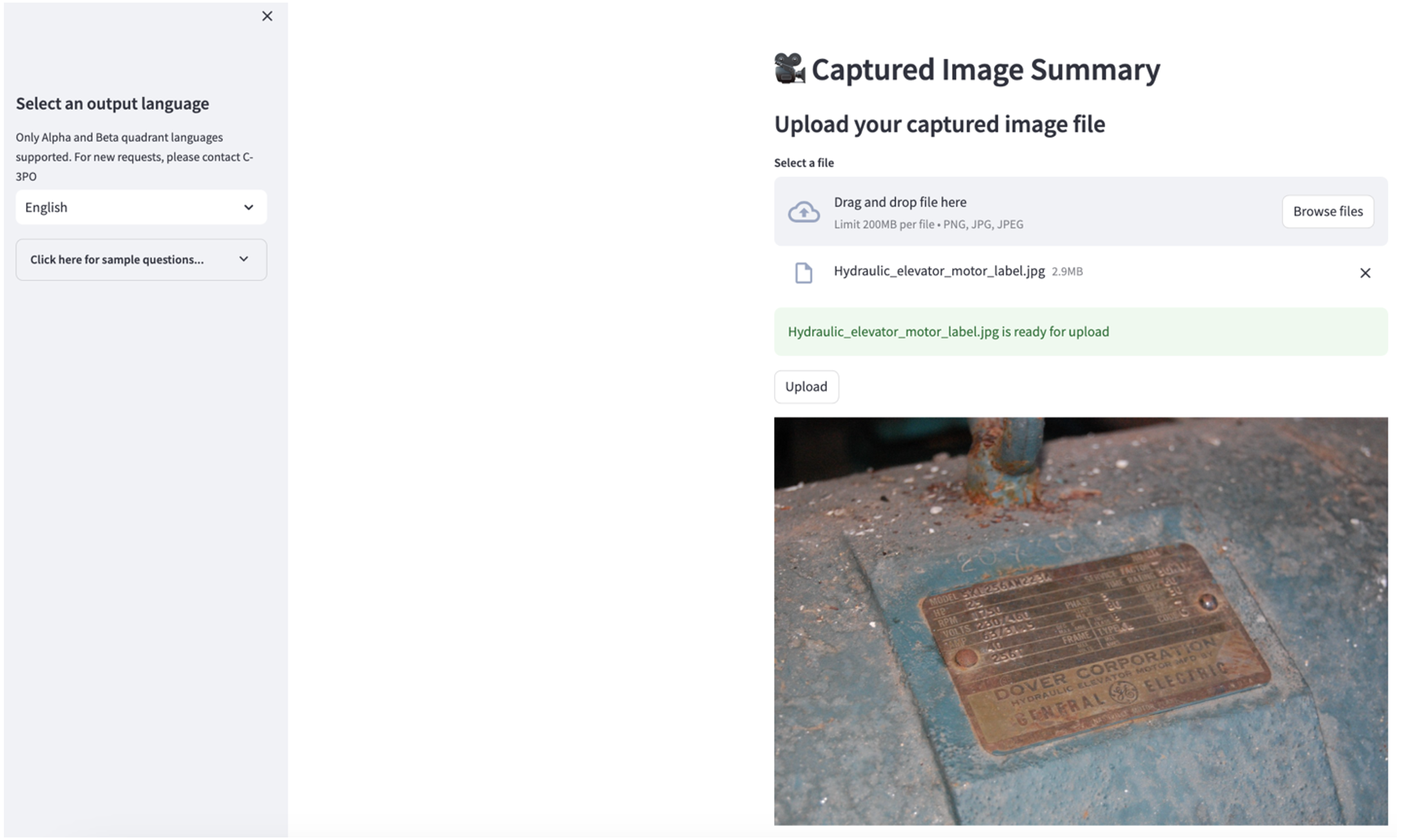
Etykieta silnika windy hydraulicznej” autorstwa Clarence’a Rishera jest objęty licencją CC BY-SA 2.0.

Poznaj przypadek użycia 3
Aby poznać trzeci przypadek użycia, wybierz opcję Diagnoza przyczyny źródłowej patka. Wprowadź zapytanie dotyczące uszkodzonego zasobu przemysłowego, np. „Mój siłownik porusza się wolno. Jaki może być problem?” Jak pokazano na poniższym zrzucie ekranu, aplikacja dostarcza odpowiedź z fragmentem dokumentu źródłowego użytego do wygenerowania odpowiedzi.
Przypadek użycia 1: Szczegóły projektu
W tej sekcji omówimy szczegóły projektu przepływu pracy aplikacji dla pierwszego przypadku użycia.
Niestandardowe szybkie budowanie
Zapytanie użytkownika w języku naturalnym ma różne poziomy trudności: łatwy, trudny i wyzwanie.
Proste pytania mogą obejmować następujące prośby:
- Wybierz unikalne wartości
- Policz liczby całkowite
- Sortuj wartości
W przypadku tych pytań PandasAI może bezpośrednio współdziałać z FM w celu wygenerowania skryptów Pythona do przetworzenia.
Trudne pytania wymagają podstawowych operacji agregacji lub analizy szeregów czasowych, takich jak następujące:
- Wybierz najpierw wartość i pogrupuj wyniki hierarchicznie
- Wykonaj statystyki po wstępnym wyborze rekordu
- Liczba sygnatur czasowych (na przykład min. i maks.)
W przypadku trudnych pytań szybki szablon ze szczegółowymi instrukcjami krok po kroku pomaga FM w udzielaniu dokładnych odpowiedzi.
Pytania na poziomie wyzwania wymagają zaawansowanych obliczeń matematycznych i przetwarzania szeregów czasowych, takich jak następujące:
- Oblicz czas trwania anomalii dla każdego czujnika
- Co miesiąc obliczaj czujniki anomalii dla obiektu
- Porównaj odczyty czujnika w normalnych warunkach i w nietypowych warunkach
W przypadku tych pytań możesz użyć wielu strzałów w niestandardowym monicie, aby zwiększyć dokładność odpowiedzi. Takie wielokrotne ujęcia pokazują przykłady zaawansowanego przetwarzania szeregów czasowych i obliczeń matematycznych oraz zapewnią FM kontekst do wyciągnięcia odpowiednich wniosków na podstawie podobnej analizy. Dynamiczne wstawianie najbardziej odpowiednich przykładów z banku pytań NLQ do podpowiedzi może stanowić wyzwanie. Jednym z rozwiązań jest skonstruowanie osadzonych przykładów pytań NLQ i zapisanie ich w magazynie wektorowym, takim jak OpenSearch Service. Gdy pytanie zostanie wysłane do aplikacji Streamlit, zostanie ono wektoryzowane przez Osadniki Bedrock. N najbardziej odpowiednich osadzonych na to pytanie jest pobieranych za pomocą opensearch_vector_search.similarity_search i wstawiony do szablonu podpowiedzi jako zachęta wielokrotna.
Poniższy diagram ilustruje ten przepływ pracy.
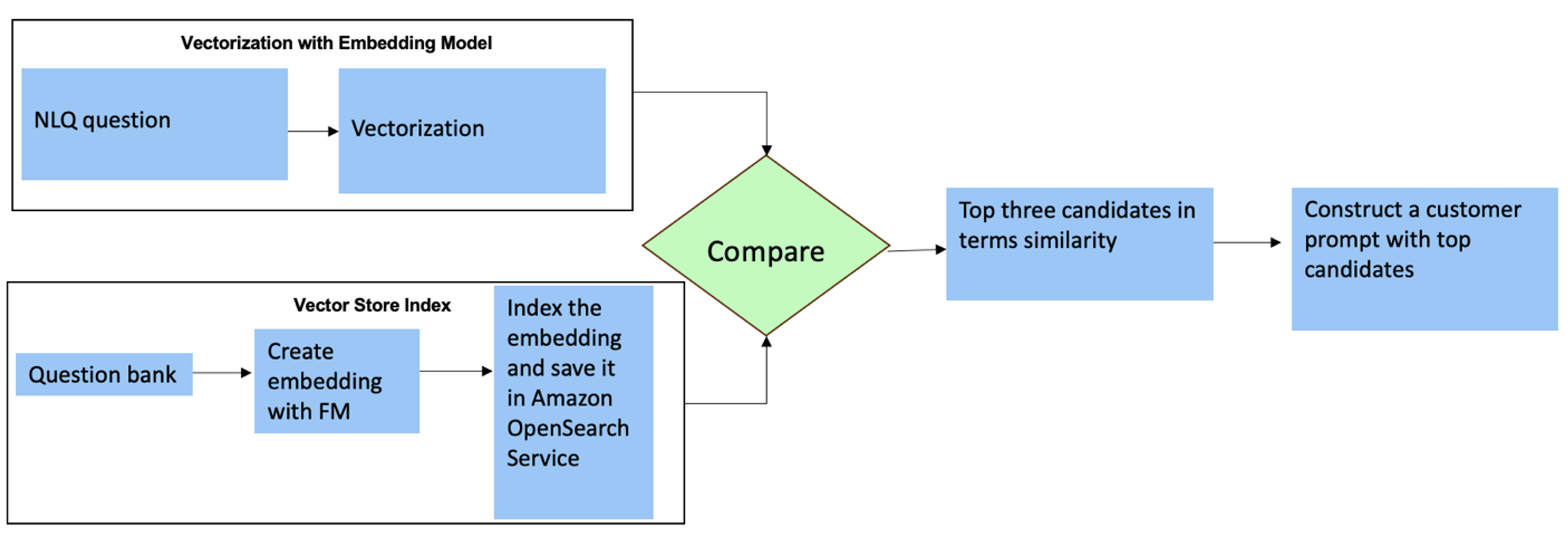
Warstwa osadzająca budowana jest przy użyciu trzech kluczowych narzędzi:
- Model osadzania – Korzystamy z osadzania Amazon Titan dostępnego za pośrednictwem Amazon Bedrock (amazon.titan-embed-text-v1) do generowania numerycznych reprezentacji dokumentów tekstowych.
- Sklep wektorowy – W naszym sklepie wektorowym korzystamy z usługi OpenSearch za pośrednictwem platformy LangChain, usprawniając przechowywanie osadzonych materiałów wygenerowanych na podstawie przykładów NLQ w tym notatniku.
- wskaźnik – Indeks usługi OpenSearch odgrywa kluczową rolę w porównywaniu osadzania danych wejściowych z osadzaniami dokumentów i ułatwianiu wyszukiwania odpowiednich dokumentów. Ponieważ przykładowe kody Pythona zostały zapisane jako plik JSON, zostały zaindeksowane w usłudze OpenSearch jako wektory za pośrednictwem pliku OpenSearchVevtorSearch.fromtexts Wywołanie API.
Ciągłe gromadzenie kontrolowanych przez ludzi przykładów za pośrednictwem Streamlit
Na początku tworzenia aplikacji zaczęliśmy od zaledwie 23 przykładów zapisanych w indeksie usługi OpenSearch jako osadzania. Gdy aplikacja zacznie działać w terenie, użytkownicy zaczną wprowadzać swoje NLQ za pośrednictwem aplikacji. Jednakże ze względu na ograniczoną liczbę przykładów dostępnych w szablonie, niektóre NLQ mogą nie znaleźć podobnych podpowiedzi. Aby stale wzbogacać te osadzania i oferować bardziej trafne podpowiedzi dla użytkowników, możesz użyć aplikacji Streamlit do gromadzenia przykładów kontrolowanych przez ludzi.
W aplikacji temu służy następująca funkcja. Gdy użytkownicy końcowi uznają wyniki za przydatne i dokonają wyboru Pomocny, aplikacja wykonuje następujące kroki:
- Użyj metody wywołania zwrotnego z PandasAI, aby zebrać skrypt Pythona.
- Sformatuj skrypt Pythona, pytanie wejściowe i metadane CSV w ciąg znaków.
- Sprawdź, czy ten przykład NLQ już istnieje w bieżącym indeksie usługi OpenSearch, używając opensearch_vector_search.similarity_search_with_score.
- Jeśli nie ma podobnego przykładu, ten NLQ jest dodawany do indeksu usługi OpenSearch za pomocą opensearch_vector_search.add_texts.
W przypadku wybrania przez użytkownika Niepomocne, nie zostaną podjęte żadne działania. Ten iteracyjny proces zapewnia ciągłe doskonalenie systemu poprzez uwzględnianie przykładów przesłanych przez użytkowników.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Dzięki włączeniu audytu ludzkiego liczba przykładów w usłudze OpenSearch dostępnych do szybkiego osadzania rośnie wraz ze wzrostem wykorzystania aplikacji. Ten rozszerzony zestaw danych do osadzania zapewnia z biegiem czasu większą dokładność wyszukiwania. W szczególności w przypadku trudnych pytań NLQ dokładność odpowiedzi FM osiąga około 90% przy dynamicznym wstawianiu podobnych przykładów w celu skonstruowania niestandardowych podpowiedzi dla każdego pytania NLQ. Stanowi to zauważalny wzrost o 28% w porównaniu ze scenariuszami bez podpowiedzi dotyczących wielu strzałów.
Przypadek użycia 2: Szczegóły projektu
W aplikacji Streamlit Podsumowanie przechwyconego obrazu możesz bezpośrednio przesłać plik obrazu. Spowoduje to inicjowanie interfejsu API Amazon Rekognition (wykryj_tekst API), wyodrębnianie tekstu z etykiety obrazu zawierającej szczegółowe dane techniczne maszyny. Następnie wyodrębnione dane tekstowe są wysyłane do modelu Amazon Bedrock Claude jako kontekst podpowiedzi, w wyniku czego powstaje podsumowanie składające się z 200 słów.
Z punktu widzenia użytkownika najważniejsze jest włączenie funkcji przesyłania strumieniowego dla zadania podsumowania tekstu, ponieważ pozwala użytkownikom czytać podsumowanie wygenerowane przez FM w mniejszych fragmentach, zamiast czekać na cały wynik. Amazon Bedrock ułatwia przesyłanie strumieniowe za pośrednictwem interfejsu API (bedrock_runtime.invoke_model_with_response_stream).
Przypadek użycia 3: Szczegóły projektu
W tym scenariuszu opracowaliśmy aplikację chatbota skupiającą się na analizie przyczyn źródłowych, wykorzystującą podejście RAG. Ten chatbot czerpie z wielu dokumentów związanych z wyposażeniem łożyskowym, aby ułatwić analizę przyczyn źródłowych. Ten chatbot oparty na RAG do analizy głównych przyczyn wykorzystuje bazy wiedzy do generowania reprezentacji tekstu wektorowego lub osadzania. Bazy wiedzy dla Amazon Bedrock to w pełni zarządzana funkcja, która pomaga wdrożyć cały przepływ pracy RAG, od przyjęcia do pobierania i szybkiego rozszerzania, bez konieczności tworzenia niestandardowych integracji ze źródłami danych lub zarządzania przepływami danych i szczegółami implementacji RAG.
Jeśli odpowiedź z bazy wiedzy Amazon Bedrock będzie satysfakcjonująca, możesz zintegrować reakcję na przyczynę pierwotną z bazy wiedzy z aplikacją Streamlit.
Sprzątać
Aby zaoszczędzić koszty, usuń zasoby utworzone w tym poście:
- Usuń bazę wiedzy z Amazon Bedrock.
- Usuń indeks usługi OpenSearch.
- Usuń stos genai-sagemaker CloudFormation.
- Zatrzymaj instancję EC2, jeśli do uruchomienia aplikacji Streamlit użyłeś instancji EC2.
Wnioski
Generacyjne aplikacje AI przekształciły już różne procesy biznesowe, zwiększając produktywność pracowników i zestaw umiejętności. Jednakże ograniczenia FM w obsłudze analizy danych szeregów czasowych utrudniają ich pełne wykorzystanie przez klientów przemysłowych. To ograniczenie utrudnia zastosowanie generatywnej sztucznej inteligencji do dominującego typu danych przetwarzanych codziennie.
W tym poście przedstawiliśmy generatywne rozwiązanie aplikacji AI zaprojektowane, aby złagodzić to wyzwanie dla użytkowników przemysłowych. Ta aplikacja korzysta z agenta open source, PandasAI, w celu wzmocnienia możliwości analizy szeregów czasowych FM. Zamiast wysyłać dane szeregów czasowych bezpośrednio do FM, aplikacja wykorzystuje PandasAI do generowania kodu Pythona do analizy nieustrukturyzowanych danych szeregów czasowych. Aby zwiększyć dokładność generowania kodu w języku Python, zaimplementowano niestandardowy przepływ pracy generowania podpowiedzi z kontrolą człowieka.
Dzięki wglądowi w stan swoich aktywów pracownicy przemysłowi mogą w pełni wykorzystać potencjał generatywnej sztucznej inteligencji w różnych przypadkach użycia, w tym w diagnostyce przyczyn źródłowych i planowaniu wymiany części. Dzięki bazom wiedzy dla Amazon Bedrock rozwiązanie RAG jest łatwe do zbudowania i zarządzania przez programistów.
Zarządzanie danymi i operacjami w przedsiębiorstwie niewątpliwie zmierza w stronę głębszej integracji z generatywną sztuczną inteligencją, umożliwiającą kompleksowy wgląd w stan operacyjny. Ta zmiana, zapoczątkowana przez Amazon Bedrock, jest znacznie wzmocniona przez rosnącą solidność i potencjał LLM, takich jak Amazonka Bedrock Claude 3 w celu dalszego ulepszania rozwiązań. Aby dowiedzieć się więcej, odwiedź konsultację Dokumentacja Amazon Bedrocki zapoznaj się z Warsztaty Amazon Bedrock.
O autorach
 Julia Hu jest starszym architektem rozwiązań AI/ML w Amazon Web Services. Specjalizuje się w generatywnej sztucznej inteligencji, stosowanej nauce danych i architekturze IoT. Obecnie jest częścią zespołu Amazon Q oraz aktywnym członkiem/mentorem społeczności terenowej Machine Learning Technical Field Community. Współpracuje z klientami, od start-upów po przedsiębiorstwa, aby opracowywać generatywne rozwiązania AI AWSome. Jej szczególną pasją jest wykorzystywanie modeli wielkojęzykowych do zaawansowanej analizy danych i odkrywania praktycznych zastosowań, które pozwalają sprostać wyzwaniom świata rzeczywistego.
Julia Hu jest starszym architektem rozwiązań AI/ML w Amazon Web Services. Specjalizuje się w generatywnej sztucznej inteligencji, stosowanej nauce danych i architekturze IoT. Obecnie jest częścią zespołu Amazon Q oraz aktywnym członkiem/mentorem społeczności terenowej Machine Learning Technical Field Community. Współpracuje z klientami, od start-upów po przedsiębiorstwa, aby opracowywać generatywne rozwiązania AI AWSome. Jej szczególną pasją jest wykorzystywanie modeli wielkojęzykowych do zaawansowanej analizy danych i odkrywania praktycznych zastosowań, które pozwalają sprostać wyzwaniom świata rzeczywistego.
 Sudeesh Sasidharan jest starszym architektem rozwiązań w AWS w zespole Energy. Sudeesh uwielbia eksperymentować z nowymi technologiami i budować innowacyjne rozwiązania, które rozwiązują złożone wyzwania biznesowe. Kiedy nie projektuje rozwiązań i nie majstruje przy najnowszych technologiach, można go spotkać na korcie tenisowym pracującego na bekhendzie.
Sudeesh Sasidharan jest starszym architektem rozwiązań w AWS w zespole Energy. Sudeesh uwielbia eksperymentować z nowymi technologiami i budować innowacyjne rozwiązania, które rozwiązują złożone wyzwania biznesowe. Kiedy nie projektuje rozwiązań i nie majstruje przy najnowszych technologiach, można go spotkać na korcie tenisowym pracującego na bekhendzie.
 Neila Desaia jest dyrektorem ds. technologii z ponad 20-letnim doświadczeniem w sztucznej inteligencji (AI), analizie danych, inżynierii oprogramowania i architekturze korporacyjnej. W AWS kieruje zespołem ogólnoświatowych architektów specjalistycznych rozwiązań w zakresie usług AI, którzy pomagają klientom tworzyć innowacyjne rozwiązania oparte na generatywnej sztucznej inteligencji, dzielić się z klientami najlepszymi praktykami i opracowywać plany rozwoju produktów. Na swoich poprzednich stanowiskach w Vestas, Honeywell i Quest Diagnostics Neil piastował kierownicze stanowiska w zakresie opracowywania i wprowadzania na rynek innowacyjnych produktów i usług, które pomogły firmom usprawnić ich działalność, obniżyć koszty i zwiększyć przychody. Pasjonuje się wykorzystaniem technologii do rozwiązywania rzeczywistych problemów i jest myślicielem strategicznym z udokumentowanymi sukcesami.
Neila Desaia jest dyrektorem ds. technologii z ponad 20-letnim doświadczeniem w sztucznej inteligencji (AI), analizie danych, inżynierii oprogramowania i architekturze korporacyjnej. W AWS kieruje zespołem ogólnoświatowych architektów specjalistycznych rozwiązań w zakresie usług AI, którzy pomagają klientom tworzyć innowacyjne rozwiązania oparte na generatywnej sztucznej inteligencji, dzielić się z klientami najlepszymi praktykami i opracowywać plany rozwoju produktów. Na swoich poprzednich stanowiskach w Vestas, Honeywell i Quest Diagnostics Neil piastował kierownicze stanowiska w zakresie opracowywania i wprowadzania na rynek innowacyjnych produktów i usług, które pomogły firmom usprawnić ich działalność, obniżyć koszty i zwiększyć przychody. Pasjonuje się wykorzystaniem technologii do rozwiązywania rzeczywistych problemów i jest myślicielem strategicznym z udokumentowanymi sukcesami.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

