Amazon Sage Maker wielomodelowe punkty końcowe (MME) to w pełni zarządzana funkcja wnioskowania SageMaker, która umożliwia wdrażanie tysięcy modeli w jednym punkcie końcowym. Wcześniej MME z góry ustalały alokację mocy obliczeniowej procesora do modeli w sposób statyczny, niezależnie od obciążenia ruchem modelu, przy użyciu Serwer wielomodelowy (MMS) jako jego modelowy serwer. W tym poście omawiamy rozwiązanie, w którym MME może dynamicznie dostosowywać moc obliczeniową przypisaną do każdego modelu na podstawie wzorca ruchu modelu. To rozwiązanie umożliwia bardziej efektywne wykorzystanie obliczeń MME i obniżenie kosztów.
MME dynamicznie ładują i rozładowują modele w oparciu o ruch przychodzący do punktu końcowego. Wykorzystując MMS jako serwer modelowy, MME przydzielają każdemu modelowi stałą liczbę pracowników modelowych. Aby uzyskać więcej informacji, zobacz Wzorce hostingu modeli w Amazon SageMaker, część 3: Uruchamianie i optymalizacja wnioskowania o wielu modelach za pomocą wielomodelowych punktów końcowych Amazon SageMaker.
Może to jednak prowadzić do kilku problemów, gdy wzór ruchu jest zmienny. Załóżmy, że masz jeden lub kilka modeli, które generują duży ruch. Możesz skonfigurować MMS tak, aby przydzielał dużą liczbę pracowników dla tych modeli, ale zostanie to przypisane do wszystkich modeli znajdujących się za MME, ponieważ jest to konfiguracja statyczna. Prowadzi to do tego, że duża liczba pracowników korzysta z obliczeń sprzętowych – nawet w modelach bezczynnych. Odwrotny problem może wystąpić, jeśli ustawisz małą wartość liczby pracowników. W popularnych modelach nie będzie wystarczającej liczby pracowników na poziomie serwera modelowego, aby prawidłowo przydzielić wystarczającą ilość sprzętu za punktem końcowym dla tych modeli. Głównym problemem jest to, że trudno pozostać niezależnym od wzorców ruchu, jeśli nie można dynamicznie skalować procesów roboczych na poziomie serwera modelowego w celu przydzielenia niezbędnej ilości mocy obliczeniowej.
Rozwiązanie, które omawiamy w tym poście, wykorzystuje DJLSobsługa jako serwer modelowy, co może pomóc złagodzić niektóre z omawianych przez nas problemów i umożliwić skalowanie według modelu oraz umożliwić MME niezależność od wzorca ruchu.
Architektura MME
MME SageMaker umożliwiają wdrażanie wielu modeli za jednym punktem końcowym wnioskowania, który może zawierać jedną lub więcej instancji. Każda instancja jest zaprojektowana tak, aby ładować i obsługiwać wiele modeli w zależności od jej pamięci i pojemności procesora/GPU. Dzięki tej architekturze firma zajmująca się oprogramowaniem jako usługą (SaaS) może przełamać liniowo rosnące koszty hostingu wielu modeli i osiągnąć ponowne wykorzystanie infrastruktury zgodnie z modelem wielu dzierżawców zastosowanym w innym miejscu stosu aplikacji. Poniższy diagram ilustruje tę architekturę.
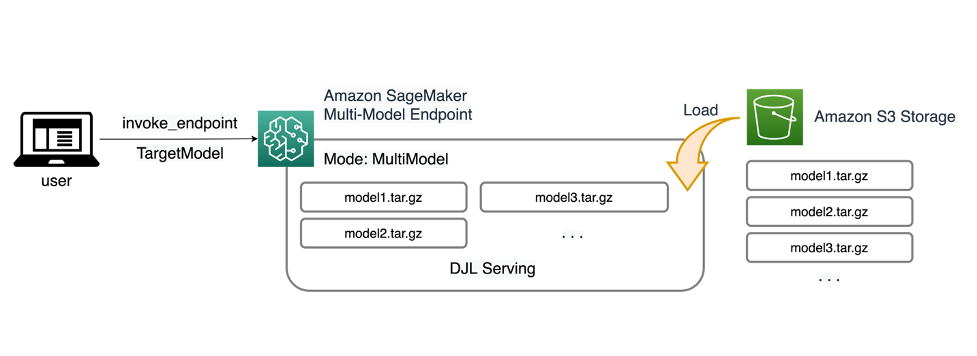
SageMaker MME dynamicznie ładuje modele z Usługa Amazon Simple Storage (Amazon S3) po wywołaniu, zamiast pobierać wszystkie modele przy pierwszym utworzeniu punktu końcowego. W rezultacie początkowe wywołanie modelu może powodować większe opóźnienia w wnioskowaniu niż w przypadku kolejnych wnioskowań, które są zakończone z małym opóźnieniem. Jeśli model jest już załadowany do kontenera po wywołaniu, krok pobierania jest pomijany, a model zwraca wnioski z małym opóźnieniem. Załóżmy na przykład, że masz model, którego używasz tylko kilka razy dziennie. Jest automatycznie ładowany na żądanie, podczas gdy często używane modele są zachowywane w pamięci i wywoływane ze stale niskimi opóźnieniami.
Za każdym MME znajdują się instancje hostujące model, jak pokazano na poniższym diagramie. Te instancje ładują i usuwają wiele modeli do i z pamięci na podstawie wzorców ruchu do modeli.
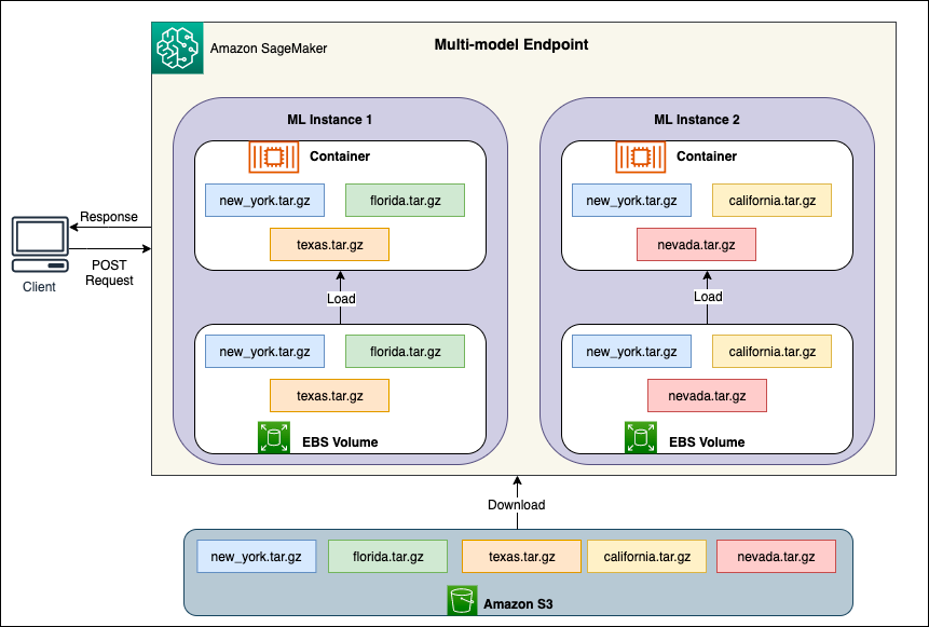
SageMaker w dalszym ciągu kieruje żądania wnioskowania dotyczące modelu do instancji, w której model jest już załadowany, tak aby żądania były obsługiwane z kopii modelu zapisanej w pamięci podręcznej (patrz poniższy diagram, który przedstawia ścieżkę żądania dla pierwszego żądania predykcji w porównaniu z predykcją z pamięci podręcznej ścieżka żądania). Jeśli jednak model otrzyma wiele żądań wywołania i istnieją dodatkowe instancje dla MME, SageMaker przekieruje część żądań do innej instancji, aby uwzględnić wzrost. Aby skorzystać z automatycznego skalowania modelu w SageMaker, upewnij się, że masz konfiguracja automatycznego skalowania instancji udostępnienie dodatkowej pojemności instancji. Skonfiguruj zasady skalowania na poziomie punktu końcowego za pomocą parametrów niestandardowych lub wywołań na minutę (zalecane), aby dodać więcej wystąpień do floty punktów końcowych.

Omówienie serwera modelowego
Serwer modeli to składnik oprogramowania zapewniający środowisko wykonawcze do wdrażania i obsługi modeli uczenia maszynowego (ML). Działa jako interfejs między wytrenowanymi modelami a aplikacjami klienckimi, które chcą przewidywać przy użyciu tych modeli.
Podstawowym celem serwera modeli jest umożliwienie łatwej integracji i wydajnego wdrażania modeli ML w systemach produkcyjnych. Zamiast osadzać model bezpośrednio w aplikacji lub określonej strukturze, serwer modeli zapewnia scentralizowaną platformę, na której można wdrażać, zarządzać i udostępniać wiele modeli.
Serwery modelowe zazwyczaj oferują następujące funkcjonalności:
- Ładowanie modelu – Serwer ładuje wytrenowane modele uczenia maszynowego do pamięci, przygotowując je do obsługi prognoz.
- Interfejs API wnioskowania – Serwer udostępnia interfejs API, który umożliwia aplikacjom klienckim wysyłanie danych wejściowych i odbieranie prognoz z wdrożonych modeli.
- Skalowanie – Serwery modelowe są zaprojektowane do obsługi jednoczesnych żądań od wielu klientów. Zapewniają mechanizmy przetwarzania równoległego i efektywnego zarządzania zasobami, aby zapewnić wysoką przepustowość i niskie opóźnienia.
- Integracja z silnikami backendowymi – Serwery modeli integrują się z platformami zaplecza, takimi jak DeepSpeed i FasterTransformer, w celu partycjonowania dużych modeli i uruchamiania wysoce zoptymalizowanego wnioskowania.
Architektura DJL
Obsługa DJL to wysokowydajny, uniwersalny model serwera o otwartym kodzie źródłowym. DJL Serving jest zbudowany na bazie Djl, biblioteka głębokiego uczenia się napisana w języku programowania Java. Może przyjąć model głębokiego uczenia się, kilka modeli lub przepływów pracy i udostępnić je za pośrednictwem punktu końcowego HTTP. DJL Serving obsługuje wdrażanie modeli z wielu platform, takich jak PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer i innych.
DJL Serving oferuje wiele funkcji, które pozwalają na wdrażanie modeli z wysoką wydajnością:
- Łatwość użycia – DJL Serving może obsługiwać większość modeli od razu po wyjęciu z pudełka. Po prostu przynieś artefakty modelu, a DJL Serving może je hostować.
- Obsługa wielu urządzeń i akceleratorów – DJL Serving obsługuje wdrażanie modeli na procesorze, karcie graficznej i Inferencja AWS.
- Wydajność – DJL Serving uruchamia wielowątkowe wnioskowanie w pojedynczej maszynie JVM, aby zwiększyć przepustowość.
- Dynamiczne dozowanie – DJL Serving obsługuje dynamiczne grupowanie w celu zwiększenia przepustowości.
- Automatyczne skalowanie – DJL Serving automatycznie skaluje pracowników w górę i w dół w zależności od obciążenia ruchem.
- Obsługa wielu silników – DJL Serving może jednocześnie hostować modele przy użyciu różnych frameworków (takich jak PyTorch i TensorFlow).
- Modele zespołów i przepływu pracy – DJL Serving obsługuje wdrażanie złożonych przepływów pracy składających się z wielu modeli i uruchamia część przepływu pracy na procesorze, a część na GPU. Modele w ramach przepływu pracy mogą korzystać z różnych struktur.
W szczególności funkcja automatycznego skalowania w DJL Serving ułatwia zapewnienie odpowiedniego skalowania modeli dla ruchu przychodzącego. Domyślnie DJL Serving określa maksymalną liczbę pracowników dla modelu, która może być obsługiwana w oparciu o dostępny sprzęt (rdzenie procesora, urządzenia GPU). Możesz ustawić dolną i górną granicę dla każdego modelu, aby mieć pewność, że zawsze będzie można obsłużyć minimalny poziom ruchu i że pojedynczy model nie zużyje wszystkich dostępnych zasobów.
DJL Serving korzysta z Netty frontend na pulach wątków roboczych backendu. Frontend wykorzystuje pojedynczą konfigurację Netty z wieloma HttpRequestHandlers. Różne procedury obsługi żądań zapewnią obsługę Interfejs API wnioskowania, Interfejs API zarządzanialub inne interfejsy API dostępne w różnych wtyczkach.
Backend opiera się na Menedżer obciążenia roboczego (WLM). WLM obsługuje wiele wątków roboczych dla każdego modelu wraz z grupowaniem i kierowaniem żądań do nich. Gdy udostępnianych jest wiele modeli, WLM najpierw sprawdza wielkość kolejki żądań wnioskowania dla każdego modelu. Jeśli rozmiar kolejki jest większy niż dwukrotność rozmiaru partii modelu, WLM zwiększa liczbę procesów roboczych przypisanych do tego modelu.
Omówienie rozwiązania
Implementacja DJL z MME różni się od domyślnej konfiguracji MMS. W przypadku DJL Serving with MME kompresujemy następujące pliki w formacie model.tar.gz, którego oczekuje SageMaker Inference:
- model.joblib – W przypadku tej implementacji bezpośrednio przesyłamy metadane modelu do archiwum tar. W tym przypadku współpracujemy z
.joblibplik, więc udostępniamy ten plik w naszym archiwum, aby mógł go odczytać nasz skrypt wnioskowujący. Jeśli artefakt jest zbyt duży, możesz także wypchnąć go do Amazon S3 i wskazać go w konfiguracji obsługi zdefiniowanej dla DJL. - serwowanie.właściwości – Tutaj możesz skonfigurować dowolny model związany z serwerem zmienne środowiskowe. Siła DJL polega na tym, że możesz go skonfigurować
minWorkersimaxWorkersdla każdego modelu archiwum. Umożliwia to skalowanie każdego modelu w górę i w dół na poziomie serwera modelowego. Na przykład, jeśli pojedynczy model odbiera większość ruchu dla MME, serwer modelu będzie dynamicznie skalował procesy robocze. W tym przykładzie nie konfigurujemy tych zmiennych i pozwalamy DJL określić niezbędną liczbę pracowników w zależności od naszego wzorca ruchu. - model.py – To jest skrypt wnioskowania dla dowolnego niestandardowego przetwarzania wstępnego lub końcowego, które chcesz wdrożyć. Model.py oczekuje, że logika będzie domyślnie hermetyzowana w metodzie uchwytu.
- wymagania.txt (opcjonalnie) – Domyślnie DJL jest instalowany z PyTorch, ale wszelkie dodatkowe potrzebne zależności można tutaj umieścić.
W tym przykładzie prezentujemy moc DJL z MME, biorąc przykładowy model SKLearn. Przeprowadzamy zadanie szkoleniowe z tym modelem, a następnie tworzymy 1,000 kopii artefaktu tego modelu, aby wesprzeć nasze MME. Następnie pokażemy, jak DJL może dynamicznie skalować się, aby obsłużyć dowolny typ ruchu, jaki może odbierać Twoje MME. Może to obejmować równomierny rozkład ruchu we wszystkich modelach lub nawet kilka popularnych modeli, na które przypada większość ruchu. Cały kod znajdziesz poniżej GitHub repo.
Wymagania wstępne
W tym przykładzie używamy instancji notatnika SageMaker z jądrem conda_python3 i instancją ml.c5.xlarge. Aby wykonać testy obciążeniowe, możesz użyć pliku Elastyczna chmura obliczeniowa Amazon (Amazon EC2) lub większa instancja notatnika SageMaker. W tym przykładzie skalujemy do ponad tysiąca transakcji na sekundę (TPS), dlatego sugerujemy testowanie na cięższej instancji EC2, takiej jak ml.c5.18xlarge, aby mieć więcej mocy obliczeniowej do pracy.
Utwórz artefakt modelu
Najpierw musimy utworzyć artefakt modelu i dane, których użyjemy w tym przykładzie. W tym przypadku generujemy sztuczne dane za pomocą NumPy i trenujemy przy użyciu modelu regresji liniowej SKLearn z następującym fragmentem kodu:
Po uruchomieniu poprzedniego kodu powinieneś mieć plik model.joblib plik utworzony w środowisku lokalnym.
Wyciągnij obraz Dockera DJL
Obraz Dockera djl-inference:0.23.0-cpu-full-v1.0 to nasz kontener obsługujący DJL użyty w tym przykładzie. Możesz dostosować następujący adres URL w zależności od regionu:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
Opcjonalnie możesz także użyć tego obrazu jako obrazu podstawowego i rozszerzyć go, aby zbudować na nim własny obraz platformy Docker Rejestr elastycznego pojemnika Amazon (Amazon ECR) z innymi potrzebnymi zależnościami.
Utwórz plik modelu
Najpierw tworzymy plik o nazwie serving.properties. To instruuje DJLServing, aby używał silnika Pythona. Definiujemy także max_idle_time pracownika wynosi 600 sekund. Dzięki temu zmniejszanie liczby pracowników przypadających na model zajmie nam więcej czasu. Nie dostosowujemy się minWorkers i maxWorkers które możemy zdefiniować i pozwalamy DJL dynamicznie obliczać liczbę potrzebnych pracowników w zależności od ruchu odbieranego przez każdy model. Właściwości serwowania są pokazane w następujący sposób. Aby zobaczyć pełną listę opcji konfiguracyjnych, zobacz Konfiguracja silnika.
Następnie tworzymy plik model.py, który definiuje ładowanie modelu i logikę wnioskowania. W przypadku MME każdy plik model.py jest specyficzny dla modelu. Modele są przechowywane we własnych ścieżkach w magazynie modeli (zwykle /opt/ml/model/). Podczas ładowania modeli zostaną one załadowane pod ścieżką magazynu modeli w ich własnym katalogu. Pełny przykład model.py w tym demo można zobaczyć w pliku GitHub repo.
Tworzymy model.tar.gz plik zawierający nasz model (model.joblib), model.py, serving.properties:
W celach demonstracyjnych wykonujemy 1,000 kopii tego samego model.tar.gz plik reprezentujący dużą liczbę modeli, które mają być hostowane. W środowisku produkcyjnym musisz utworzyć plik model.tar.gz plik dla każdego ze swoich modeli.
Na koniec przesyłamy te modele do Amazon S3.
Stwórz model SageMakera
Teraz tworzymy Model SageMakera. Do utworzenia modelu SageMaker używamy zdefiniowanego wcześniej obrazu ECR i artefaktu modelu z poprzedniego kroku. W konfiguracji modelu konfigurujemy Tryb jako MultiModel. To informuje DJLServing, że tworzymy MME.
Utwórz punkt końcowy SageMaker
W tym demo używamy 20 instancji ml.c5d.18xlarge do skalowania do TPS w zakresie tysięcy. W razie potrzeby pamiętaj o zwiększeniu limitu typu instancji, aby osiągnąć docelowy poziom TPS.
Testowanie obciążenia
W chwili pisania tego tekstu było to wewnętrzne narzędzie do testowania obciążenia SageMaker Polecający wnioskowanie Amazon SageMaker nie obsługuje natywnie testowania MME. Dlatego korzystamy z narzędzia Python typu open source Szarańcza. Locust jest prosty w konfiguracji i może śledzić wskaźniki, takie jak TPS i kompleksowe opóźnienia. Aby uzyskać pełne zrozumienie sposobu konfiguracji za pomocą SageMaker, zobacz Najlepsze praktyki testowania obciążenia punktów końcowych wnioskowania Amazon SageMaker w czasie rzeczywistym.
W tym przypadku mamy trzy różne wzorce ruchu, które chcemy symulować za pomocą MME, więc mamy następujące trzy skrypty Pythona, które pasują do każdego wzorca. Naszym celem jest tutaj udowodnienie, że niezależnie od tego, jaki jest nasz wzorzec ruchu, możemy osiągnąć ten sam docelowy TPS i odpowiednio go skalować.
Możemy określić wagę w naszym skrypcie Locust, aby przypisać ruch do różnych części naszych modeli. Na przykład w naszym pojedynczym gorącym modelu wdrażamy dwie metody w następujący sposób:
Każdej metodzie możemy wówczas przypisać określoną wagę, czyli wtedy, gdy dana metoda otrzyma określony procent ruchu:
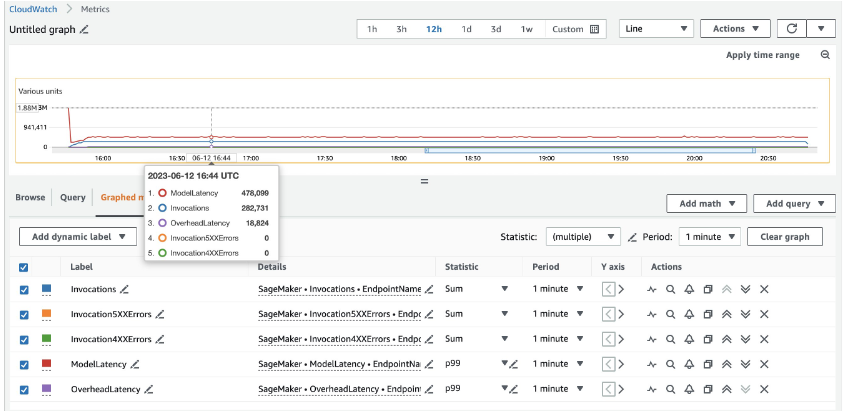
W przypadku 20 instancji ml.c5d.18xlarge widzimy następujące metryki wywołań na stronie Amazon Cloud Watch konsola. Wartości te pozostają dość spójne we wszystkich trzech wzorcach ruchu. Aby lepiej zrozumieć metryki CloudWatch dotyczące wnioskowania w czasie rzeczywistym SageMaker i MME, zobacz Metryki wywołań punktów końcowych SageMaker.
Pozostałe skrypty Locust można znaleźć w pliku katalog locust-utils w repozytorium GitHub.
Podsumowanie
W tym poście omówiliśmy, w jaki sposób MME może dynamicznie dostosowywać moc obliczeniową przypisaną do każdego modelu w oparciu o wzorzec ruchu w modelu. Ta nowo uruchomiona funkcja jest dostępna we wszystkich regionach AWS, w których dostępny jest SageMaker. Należy pamiętać, że w momencie ogłoszenia obsługiwane są tylko instancje procesora. Aby dowiedzieć się więcej, zob Obsługiwane algorytmy, struktury i instancje.
O autorach
 Ram Vegiraju jest architektem ML w zespole SageMaker Service. Koncentruje się na pomaganiu klientom w budowaniu i optymalizowaniu ich rozwiązań AI/ML w Amazon SageMaker. W wolnym czasie uwielbia podróżować i pisać.
Ram Vegiraju jest architektem ML w zespole SageMaker Service. Koncentruje się na pomaganiu klientom w budowaniu i optymalizowaniu ich rozwiązań AI/ML w Amazon SageMaker. W wolnym czasie uwielbia podróżować i pisać.
 Qingwei Li jest specjalistą ds. uczenia maszynowego w Amazon Web Services. Uzyskał stopień doktora. w badaniach operacyjnych po tym, jak złamał konto grantu naukowego swojego doradcy i nie przekazał obiecanej nagrody Nobla. Obecnie pomaga klientom z branży usług finansowych i ubezpieczeniowych budować rozwiązania machine learning na AWS. W wolnym czasie lubi czytać i uczyć.
Qingwei Li jest specjalistą ds. uczenia maszynowego w Amazon Web Services. Uzyskał stopień doktora. w badaniach operacyjnych po tym, jak złamał konto grantu naukowego swojego doradcy i nie przekazał obiecanej nagrody Nobla. Obecnie pomaga klientom z branży usług finansowych i ubezpieczeniowych budować rozwiązania machine learning na AWS. W wolnym czasie lubi czytać i uczyć.
 Jamesa Wu jest starszym architektem rozwiązań AI/ML w AWS. pomaganie klientom w projektowaniu i budowaniu rozwiązań AI/ML. Praca Jamesa obejmuje szeroki zakres przypadków użycia ML, ze szczególnym uwzględnieniem wizji komputerowej, głębokiego uczenia i skalowania ML w całym przedsiębiorstwie. Przed dołączeniem do AWS James był architektem, programistą i liderem technologicznym przez ponad 10 lat, w tym 6 lat w inżynierii i 4 lata w branży marketingowej i reklamowej.
Jamesa Wu jest starszym architektem rozwiązań AI/ML w AWS. pomaganie klientom w projektowaniu i budowaniu rozwiązań AI/ML. Praca Jamesa obejmuje szeroki zakres przypadków użycia ML, ze szczególnym uwzględnieniem wizji komputerowej, głębokiego uczenia i skalowania ML w całym przedsiębiorstwie. Przed dołączeniem do AWS James był architektem, programistą i liderem technologicznym przez ponad 10 lat, w tym 6 lat w inżynierii i 4 lata w branży marketingowej i reklamowej.
 Saurabha Trikande jest starszym menedżerem produktu w firmie Amazon SageMaker Inference. Pasjonuje go praca z klientami i motywuje go cel, jakim jest demokratyzacja uczenia maszynowego. Koncentruje się na podstawowych wyzwaniach związanych z wdrażaniem złożonych aplikacji ML, wielodostępnych modeli ML, optymalizacji kosztów oraz zwiększaniem dostępności wdrażania modeli uczenia głębokiego. W wolnym czasie Saurabh lubi wędrować, poznawać innowacyjne technologie, śledzić TechCrunch i spędzać czas z rodziną.
Saurabha Trikande jest starszym menedżerem produktu w firmie Amazon SageMaker Inference. Pasjonuje go praca z klientami i motywuje go cel, jakim jest demokratyzacja uczenia maszynowego. Koncentruje się na podstawowych wyzwaniach związanych z wdrażaniem złożonych aplikacji ML, wielodostępnych modeli ML, optymalizacji kosztów oraz zwiększaniem dostępności wdrażania modeli uczenia głębokiego. W wolnym czasie Saurabh lubi wędrować, poznawać innowacyjne technologie, śledzić TechCrunch i spędzać czas z rodziną.
 Xu Denga jest menedżerem inżynierem oprogramowania w zespole SageMaker. Koncentruje się na pomaganiu klientom w budowaniu i optymalizacji ich doświadczeń związanych z wnioskowaniem AI/ML w Amazon SageMaker. W wolnym czasie uwielbia podróżować i jeździć na snowboardzie.
Xu Denga jest menedżerem inżynierem oprogramowania w zespole SageMaker. Koncentruje się na pomaganiu klientom w budowaniu i optymalizacji ich doświadczeń związanych z wnioskowaniem AI/ML w Amazon SageMaker. W wolnym czasie uwielbia podróżować i jeździć na snowboardzie.
 Siddhartha Venkatesana jest inżynierem oprogramowania w AWS Deep Learning. Obecnie koncentruje się na budowaniu rozwiązań do wnioskowania na dużych modelach. Przed AWS pracował w Amazon Grocery org, budując nowe funkcje płatności dla klientów na całym świecie. Poza pracą lubi jeździć na nartach, spędzać czas na świeżym powietrzu i oglądać sport.
Siddhartha Venkatesana jest inżynierem oprogramowania w AWS Deep Learning. Obecnie koncentruje się na budowaniu rozwiązań do wnioskowania na dużych modelach. Przed AWS pracował w Amazon Grocery org, budując nowe funkcje płatności dla klientów na całym świecie. Poza pracą lubi jeździć na nartach, spędzać czas na świeżym powietrzu i oglądać sport.
 Rohitha Nallamaddiego jest inżynierem rozwoju oprogramowania w AWS. Pracuje nad optymalizacją obciążeń związanych z uczeniem głębokim na procesorach graficznych, budowaniem wysokowydajnych rozwiązań do wnioskowania i obsługi ML. Wcześniej pracował przy budowaniu mikroserwisów w oparciu o AWS dla biznesu Amazon F3. Poza pracą lubi grać i oglądać sport.
Rohitha Nallamaddiego jest inżynierem rozwoju oprogramowania w AWS. Pracuje nad optymalizacją obciążeń związanych z uczeniem głębokim na procesorach graficznych, budowaniem wysokowydajnych rozwiązań do wnioskowania i obsługi ML. Wcześniej pracował przy budowaniu mikroserwisów w oparciu o AWS dla biznesu Amazon F3. Poza pracą lubi grać i oglądać sport.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

