W miarę rozwoju przedsiębiorstw popyt na adresy IP w sieci korporacyjnej często przewyższa podaż. Sieć organizacji jest często projektowana z pewnymi przewidywaniami przyszłych wymagań, ale w miarę ewolucji przedsiębiorstw ich potrzeby w zakresie technologii informatycznych (IT) przewyższają wcześniej zaprojektowaną sieć. Przedsiębiorstwa mogą stanąć przed wyzwaniem zarządzania ograniczoną pulą adresów IP.
W przypadku obciążeń związanych z inżynierią danych, gdy Klej AWS jest używany w tak ograniczonej konfiguracji sieci, Twój zespół może czasami napotkać przeszkody podczas wykonywania wielu zadań jednocześnie. Dzieje się tak, ponieważ możesz nie mieć wystarczającej liczby adresów IP do obsługi wymaganych połączeń z bazami danych. Aby przezwyciężyć ten niedobór, zespół może uzyskać więcej adresów IP z puli sieci firmowej. Uzyskane adresy IP mogą być unikalne (nienakładające się) lub nakładające się, jeśli adresy IP są ponownie wykorzystywane w sieci firmowej.
W przypadku korzystania z nakładających się adresów IP potrzebne jest dodatkowe zarządzanie siecią w celu ustanowienia łączności. Rozwiązania sieciowe mogą obejmować opcje takie jak prywatne bramy translacji adresów sieciowych (NAT)., Prywatny link AWSlub samodzielnie zarządzane urządzenia NAT do tłumaczenia adresów IP.
W tym poście omówimy dwie strategie skalowania zadań kleju AWS:
- Optymalizacja zużycia adresów IP poprzez odpowiednie dobranie jednostek przetwarzania danych (DPU), wykorzystanie funkcji automatycznego skalowania AWS Glue i precyzyjne dostrojenie zadań.
- Rozszerzanie przepustowości sieci za pomocą dodatkowego zakresu nierutowalnego routingu międzydomenowego (CIDR) z prywatną bramą NAT.
Zanim zagłębimy się w te rozwiązania, pozwól nam zrozumieć, w jaki sposób wykorzystuje się klej AWS Elastyczny interfejs sieciowy (ENI) w celu ustanowienia łączności. Aby umożliwić dostęp do magazynów danych wewnątrz VPC, musisz utworzyć połączenie AWS Glue, które jest podłączone do Twojego VPC. Kiedy zadanie AWS Glue jest uruchamiane w Twoim VPC, zadanie tworzy ENI w skonfigurowanym VPC dla każdego połączenia danych, a to ENI wykorzystuje adres IP w określonym VPC. Te ENI są krótkotrwałe i aktywne do momentu zakończenia zadania.
Przyjrzyjmy się teraz pierwszemu rozwiązaniu, które wyjaśnia optymalizację zużycia adresu IP AWS Glue.
Strategie efektywnego wykorzystania adresów IP
W AWS Glue liczba pracowników wykorzystywanych przez zadanie określa liczbę adresów IP używanych w podsieci VPC. Dzieje się tak, ponieważ każdy proces roboczy wymaga jednego adresu IP, który jest mapowany na jeden ENI. Jeśli nie masz wystarczającego zakresu CIDR przydzielonego do podsieci AWS Glue, możesz zaobserwować błędy wyczerpania adresu IP. Poniżej przedstawiono kilka najlepszych praktyk optymalizacji wykorzystania adresów IP AWS Glue:
- Odpowiednie dobranie jednostek DPU do zadania – AWS Glue to silnik przetwarzania rozproszonego. Działa wydajnie, gdy może wykonywać zadania równolegle. Jeśli zadanie ma więcej niż wymaganą liczbę jednostek DPU, nie zawsze działa szybciej. Znalezienie odpowiedniej liczby DPU zapewni optymalne wykorzystanie adresów IP. Budując obserwowalność w systemie i analizując wydajność zadania, możesz uzyskać wgląd w trendy zużycia ENI, a następnie skonfigurować odpowiednią wydajność w zadaniu dla odpowiedniego rozmiaru. Więcej szczegółów znajdziesz w Monitorowanie planowania wydajności DPU. Interfejs Spark jest pomocnym narzędziem do monitorowania wykorzystania pracowników w zadaniach AWS Glue. Więcej szczegółów znajdziesz w Monitorowanie zadań za pomocą interfejsu internetowego Apache Spark.
- Automatyczne skalowanie kleju AWS – często trudno jest z góry przewidzieć wymagania dotyczące wydajności zadania. Włączenie funkcji automatycznego skalowania w AWS Glue przeniesie część tej odpowiedzialności na AWS. W czasie wykonywania w oparciu o wymagania dotyczące obciążenia zadanie automatycznie skaluje węzły robocze do zdefiniowanej maksymalnej konfiguracji. Jeśli nie ma dodatkowej potrzeby, AWS Glue nie spowoduje nadmiernej liczby pracowników, oszczędzając w ten sposób zasoby i redukując koszty. Funkcja automatycznego skalowania jest dostępna w AWS Glue 3.0 i nowszych wersjach. Aby uzyskać więcej informacji, zobacz Przedstawiamy automatyczne skalowanie kleju AWS: Automatycznie zmieniaj rozmiar bezserwerowych zasobów obliczeniowych w celu obniżenia kosztów dzięki zoptymalizowanemu Apache Spark.
- Optymalizacja na poziomie stanowiska — identyfikuj optymalizacje na poziomie stanowiska za pomocą Metryki zadań klejenia AWS i zastosuj najlepsze praktyki z Najlepsze praktyki dotyczące dostrajania wydajności AWS Glue dla zadań Apache Spark.
Następnie przyjrzyjmy się drugiemu rozwiązaniu, które dotyczy zwiększania przepustowości sieci.
Rozwiązania zwiększające rozmiar sieci (adres IP).
W tej sekcji omówimy bardziej szczegółowo dwa możliwe rozwiązania umożliwiające zwiększenie rozmiaru sieci.
Rozszerz zakresy CIDR VPC o adresy z możliwością routingu
Jednym z rozwiązań jest dodanie większej liczby prywatnych zakresów CIDR IPv4 RFC 1918 do Twojego VPC. Teoretycznie każde konto AWS można przypisać do niektórych lub wszystkich tych adresów CIDR. Twój zespół ds. zarządzania adresami IP (IPAM) często zarządza przydziałem adresów IP, z których każda jednostka biznesowa może korzystać na podstawie RFC1918, aby uniknąć nakładania się adresów IP na wielu kontach AWS lub jednostkach biznesowych. Jeśli bieżący limit adresów IP przydzielony przez zespół IPAM nie jest wystarczający, możesz poprosić o więcej.
Jeśli Twój zespół IPAM wystawi Ci dodatkowy, nienakładający się zakres CIDR, możesz dodać go jako dodatkowy CIDR do istniejącej VPC lub utworzyć z nim nową VPC. Jeśli planujesz utworzyć nową VPC, możesz połączyć VPC za pośrednictwem Komunikacja równorzędna VPC or Bramka tranzytowa AWS.
Jeśli ta dodatkowa wydajność jest wystarczająca do wykonania wszystkich zadań w określonych ramach czasowych, jest to proste i opłacalne rozwiązanie. W przeciwnym razie możesz rozważyć przyjęcie nakładających się adresów IP z prywatną bramą NAT, jak opisano w poniższej sekcji. W przypadku poniższego rozwiązania musisz użyć Transit Gateway do połączenia VPC, ponieważ połączenie równorzędne VPC nie jest możliwe, gdy w tych dwóch VPC zachodzą nakładające się zakresy CIDR.
Skonfiguruj nieroutowalny CIDR z prywatną bramą NAT
Zgodnie z opisem w oficjalnym dokumencie AWS Budowa skalowalnej i bezpiecznej infrastruktury sieciowej AWS Multi-VPC, możesz zwiększyć przepustowość sieci, tworząc podsieć adresów IP niepodlegających routingowi i używając prywatnej bramy NAT znajdującej się w rutowalnej przestrzeni adresów IP (nienakładającej się) w celu kierowania ruchu. Prywatna brama NAT tłumaczy i kieruje ruch pomiędzy nieroutowalnymi adresami IP i rutowalnymi adresami IP. Poniższy diagram przedstawia rozwiązanie w odniesieniu do kleju AWS.
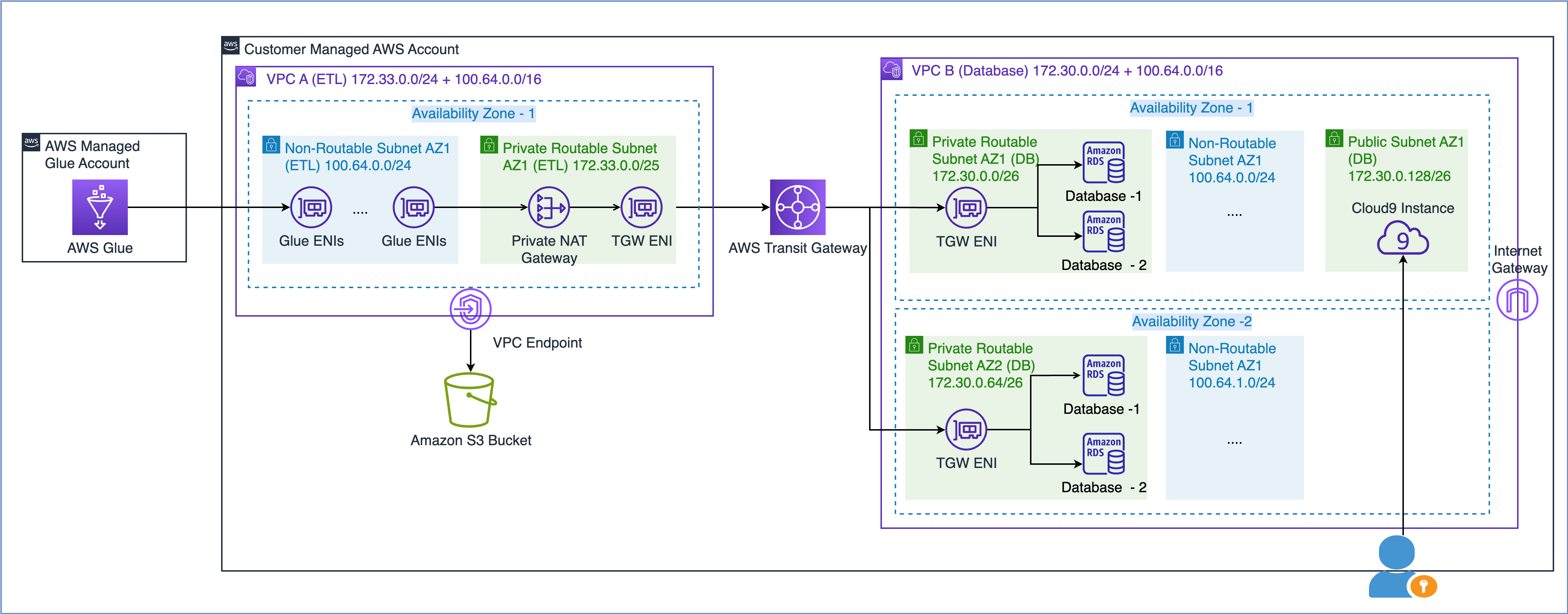
Jak widać na powyższym diagramie, VPC A (ETL) ma dołączone dwa zakresy CIDR. Mniejszy zakres CIDR 172.33.0.0/24 można routować, ponieważ nie jest nigdzie ponownie używany, podczas gdy większy zakres CIDR 100.64.0.0/16 nie podlega trasowaniu, ponieważ jest ponownie używany w bazie danych VPC.
W VPC B (baza danych) hostowaliśmy dwie bazy danych w podsieciach routowalnych 172.30.0.0/26 i 172.30.0.64/26. Te dwie podsieci znajdują się w dwóch oddzielnych strefach dostępności, co zapewnia wysoką dostępność. Mamy także dwie dodatkowe, nieużywane podsieci 100.64.0.0/24 i 100.64.1.0/24, które symulują konfigurację bez możliwości routingu.
Możesz wybrać rozmiar nieroutowalnego zakresu CIDR w oparciu o wymagania dotyczące pojemności. Ponieważ możesz ponownie wykorzystywać adresy IP, możesz w razie potrzeby utworzyć bardzo dużą podsieć. Na przykład maska CIDR o wartości /16 dałaby około 65,000 4 adresów IPvXNUMX. Możesz współpracować z zespołem inżynierów sieci i określić wielkość podsieci.
Krótko mówiąc, możesz skonfigurować zadania AWS Glue tak, aby korzystały zarówno z podsieci routingowych, jak i nierutowalnych w Twojej VPC, aby zmaksymalizować dostępną pulę adresów IP.
Teraz przyjrzyjmy się, w jaki sposób identyfikatory Glue ENI znajdujące się w podsieci niepodlegającej routingowi komunikują się ze źródłami danych w innym VPC.
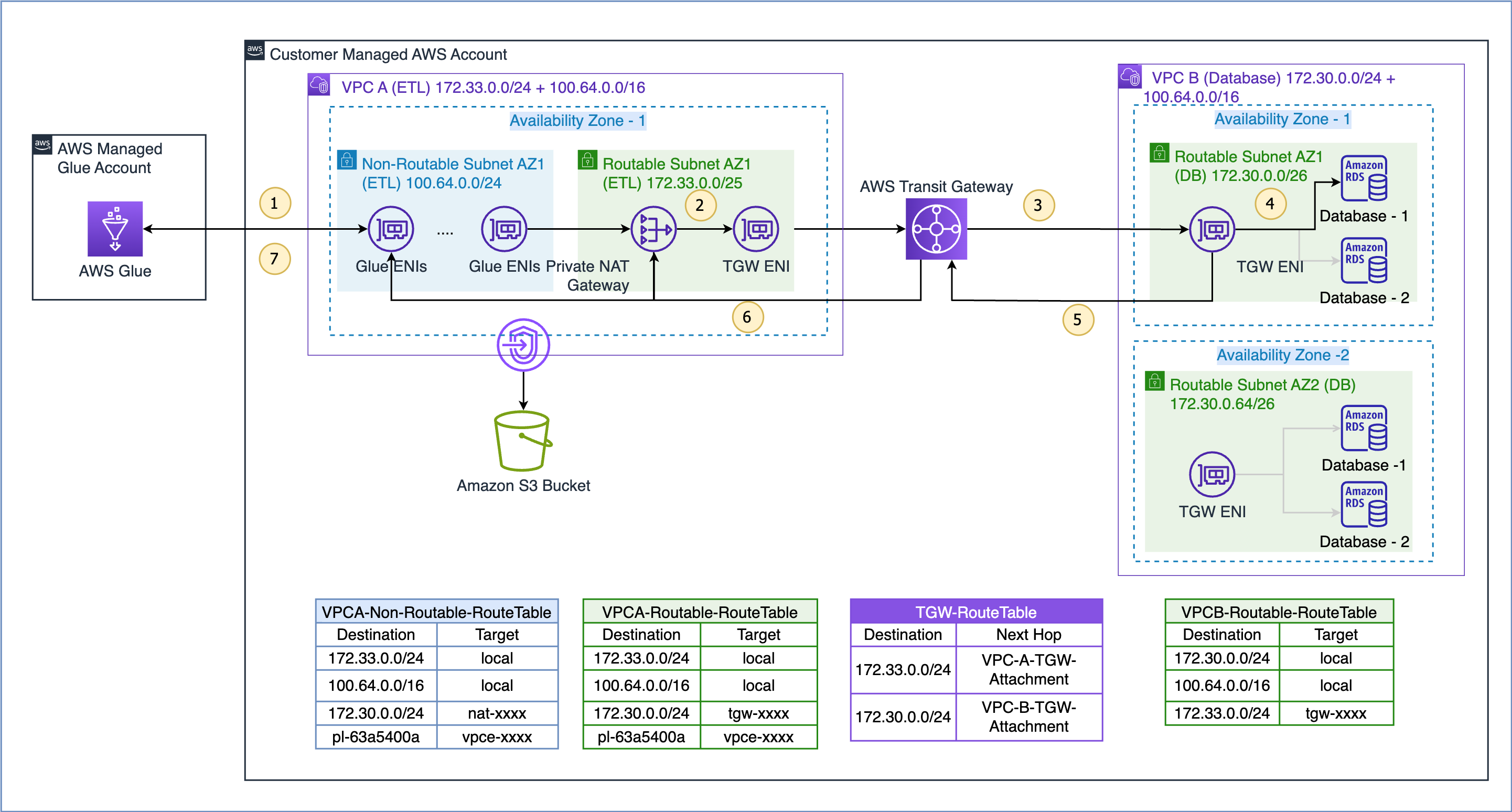
Przepływ danych dla przedstawionego tutaj przypadku użycia jest następujący (odnosząc się do ponumerowanych kroków na powyższym rysunku):
- Kiedy zadanie AWS Glue musi uzyskać dostęp do źródła danych, najpierw używa połączenia AWS Glue w zadaniu i tworzy ENI w nieroutowalnej podsieci 100.64.0.0/24 w VPC A. Później AWS Glue wykorzystuje konfigurację połączenia z bazą danych i próbuje połączyć się z bazą danych w VPC B 172.30.0.0/24.
- Zgodnie z tabelą tras
VPCA-Non-Routable-RouteTableadres docelowy 172.30.0.0/24 jest skonfigurowany dla prywatnej bramy NAT. Żądanie jest wysyłane do bramy NAT, która następnie tłumaczy źródłowy adres IP z adresu IP nierutowalnego na adres IP obsługujący routing. Ruch jest następnie wysyłany do załącznika bramy tranzytowej w VPC A, ponieważ jest powiązany zVPCA-Routable-RouteTabletabela tras w VPC A. - Transit Gateway korzysta z trasy 172.30.0.0/24 i wysyła ruch do załącznika bramy tranzytowej VPC B.
- Brama tranzytowa ENI w VPC B wykorzystuje trasę lokalną VPC B do łączenia się z punktem końcowym bazy danych i wysyłania zapytań do danych.
- Po zakończeniu zapytania odpowiedź jest wysyłana z powrotem do VPC A. Ruch będący odpowiedzią jest kierowany do załącznika bramy tranzytowej w VPC B, następnie Transit Gateway korzysta z trasy 172.33.0.0/24 i wysyła ruch do załącznika bramy tranzytowej VPC A .
- Brama tranzytowa ENI w VPC A wykorzystuje trasę lokalną do przekazywania ruchu do prywatnej bramy NAT, która tłumaczy docelowy adres IP na adres ENI w podsieci nierutowanej.
- Na koniec zadanie AWS Glue odbiera dane i kontynuuje przetwarzanie.
Rozwiązanie prywatnej bramy NAT jest opcją, jeśli potrzebujesz dodatkowych adresów IP, których nie można uzyskać z sieci z routingiem w Twojej organizacji. Czasami każda dodatkowa usługa wiąże się z dodatkowymi kosztami i ten kompromis jest konieczny, aby osiągnąć Twoje cele. Zapoznaj się z sekcją Cennik NAT Gateway na stronie Strona z cennikiem Amazon VPC po więcej informacji.
Wymagania wstępne
Aby ukończyć zapoznanie się z rozwiązaniem prywatnej bramy NAT, potrzebne są następujące elementy:
Wdróż rozwiązanie
Aby wdrożyć rozwiązanie, wykonaj następujące kroki:
- Zaloguj się do konsoli zarządzania AWS.
- Wdróż rozwiązanie klikając
 . Domyślnie ten stos
. Domyślnie ten stos us-east-1, możesz wybrać żądany region. - Kliknij Następny a następnie określ szczegóły stosu. Można zachować parametry wejściowe według wstępnie wypełnionych wartości domyślnych lub zmienić je w razie potrzeby.
- W razie zamówieenia projektu
DatabaseUserPassword, wprowadź wybrane przez siebie hasło alfanumeryczne i zanotuj je do dalszego wykorzystania. - W razie zamówieenia projektu
S3BucketName, wprowadź unikat Usługa Amazon Simple Storage Nazwa segmentu (Amazon S3). W tym wiadrze przechowywany jest skrypt zadania AWS Glue, który zostanie skopiowany z publicznego repozytorium kodu AWS.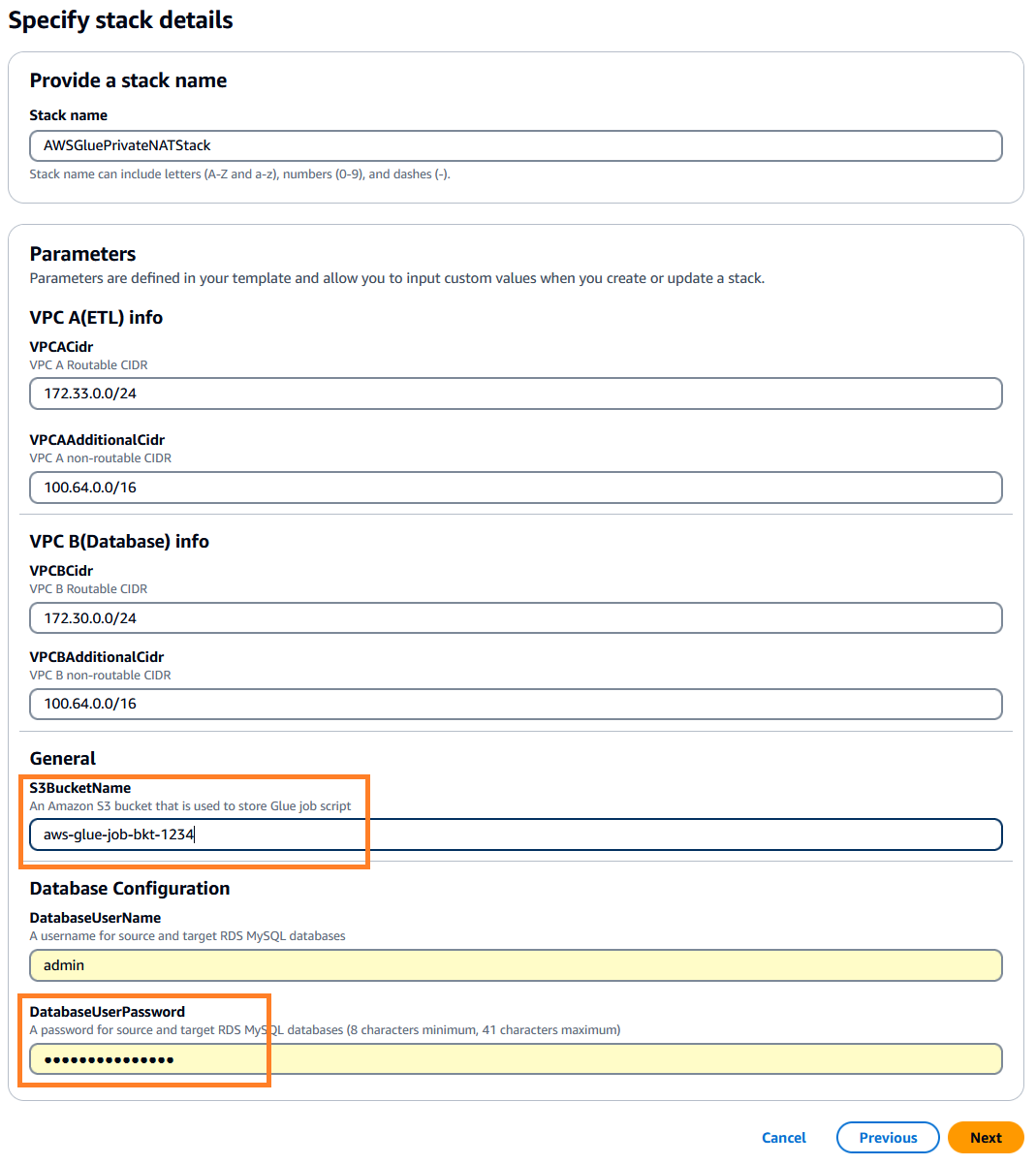
- Kliknij Następny.
- Pozostaw wartości domyślne i kliknij Następny ponownie.
- Przejrzyj szczegóły, potwierdź utworzenie zasobów IAM i kliknij Zatwierdź aby rozpocząć wdrażanie.
Możesz monitorować zdarzenia, aby zobaczyć tworzone zasoby w konsoli AWS CloudFormation. Utworzenie zasobów stosu może zająć około 20 minut.
Po zakończeniu tworzenia stosu przejdź do zakładki Outputs w konsoli AWS CloudFormation i zanotuj następujące wartości do późniejszego wykorzystania:
DBSourceDBTargetSourceCrawlerTargetCrawler
Połącz się z instancją AWS Cloud9
Następnie musimy przygotować źródłowy i docelowy Amazon RDS dla tabel MySQL za pomocą pliku Chmura AWS9 instancja. Wykonaj następujące kroki:
- Na stronie konsoli AWS Cloud9 zlokalizuj plik
aws-glue-cloud9środowisko. - W kolumnie Cloud9 IDE kliknij Otwarte aby uruchomić instancję AWS Cloud9 w nowej przeglądarce internetowej.
Przygotuj źródłową tabelę MySQL
Wykonaj następujące kroki, aby przygotować tabelę źródłową:
- Z terminala AWS Cloud9 zainstaluj klienta MySQL za pomocą następującego polecenia:
sudo yum update -y && sudo yum install -y mysql - Połącz się ze źródłową bazą danych za pomocą następującego polecenia. Zastąp nazwę hosta źródłowego wartością DBSource przechwyconą wcześniej. Po wyświetleniu monitu wprowadź hasło bazy danych określone podczas tworzenia stosu.
mysql -h <Source Hostname> -P 3306 -u admin -p - Uruchom następujące skrypty, aby utworzyć źródło
emptable i załaduj dane testowe:-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - Sprawdź źródło
empzliczyć tabelę za pomocą poniższego zapytania SQL (potrzebujesz tego na późniejszym etapie do weryfikacji).select count(*) from emp; - Uruchom następujące polecenie, aby wyjść z narzędzia klienta MySQL i powrócić do terminala instancji AWS Cloud9:
quit;
Przygotuj docelową tabelę MySQL
Wykonaj następujące kroki, aby przygotować tabelę docelową:
- Połącz się z docelową bazą danych za pomocą następującego polecenia. Zamień docelową nazwę hosta na przechwyconą wcześniej wartość DBtarget. Po wyświetleniu monitu wprowadź hasło bazy danych określone podczas tworzenia stosu.
mysql -h <Target Hostname> -P 3306 -u admin -p - Uruchom następujące skrypty, aby utworzyć element docelowy
emptabela. Ta tabela zostanie załadowana przez zadanie AWS Glue w kolejnym kroku.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
Sprawdź konfigurację sieci (opcjonalnie)
Poniższe kroki są przydatne do zrozumienia bramy NAT, tabel tras i konfiguracji bramy tranzytowej w rozwiązaniu prywatnej bramy NAT. Te komponenty zostały utworzone podczas tworzenia stosu CloudFormation.
- Na stronie konsoli Amazon VPC przejdź do sekcji Wirtualna chmura prywatna i zlokalizuj bramy NAT.
- Wyszukaj bramę NAT z nazwą
Glue-OverlappingCIDR-NATGWi eksploruj go dalej. Jak widać na poniższym zrzucie ekranu, brama NAT została utworzona w VPC A (ETL) w podsieci z możliwością routingu.
- W panelu nawigacyjnym po lewej stronie przejdź do Tabele tras w sekcji wirtualnej chmury prywatnej.
- w szukaniu
VPCA-Non-Routable-RouteTablei eksploruj go dalej. Widać, że tabela tras jest skonfigurowana do tłumaczenia ruchu z nakładających się CIDR przy użyciu bramy NAT.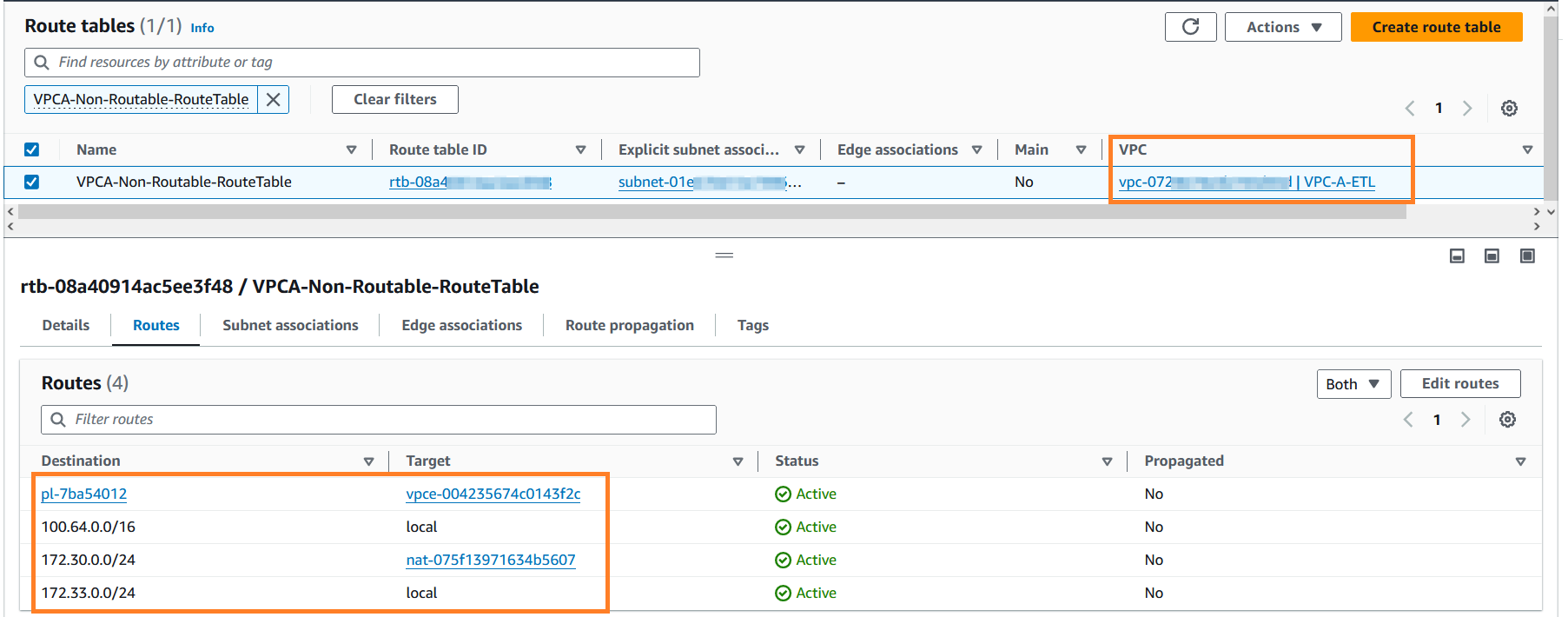
- W panelu nawigacyjnym po lewej stronie przejdź do sekcji Bramy transportu publicznego i kliknij Załączniki bramy transportu publicznego. Wchodzić
VPC-w polu wyszukiwania i zlokalizuj dwa nowo utworzone załączniki dotyczące bramy tranzytowej. - Możesz dokładniej zapoznać się z tymi załącznikami, aby poznać ich konfiguracje.
Uruchom przeszukiwacze AWS Glue
Wykonaj poniższe kroki, aby uruchomić przeszukiwacze AWS Glue, które są wymagane do skatalogowania źródła i celu emp stoły. Jest to krok niezbędny do uruchomienia zadania klejenia AWS.
- Na stronie konsoli kleju AWS, w sekcji Katalog danych w panelu nawigacyjnym kliknij opcję Roboty.
- Zlokalizuj przeszukiwacze źródłowe i docelowe, które zanotowałeś wcześniej.
- Wybierz te roboty i kliknij run aby utworzyć odpowiednie tabele katalogu danych kleju AWS.
- Możesz monitorować roboty indeksujące AWS Glue pod kątem pomyślnego zakończenia. Ukończenie obu robotów może zająć około 3–4 minut. Po zakończeniu status ostatniego uruchomienia zadania zmieni się na Powodzenie, a na podstawie tego uruchomienia zostaną utworzone dwie tabele katalogu kleju AWS.

Uruchom zadanie ETL kleju AWS
Po skonfigurowaniu tabel i wykonaniu wymaganych kroków można teraz uruchomić zadanie kleju AWS utworzone przy użyciu szablonu CloudFormation. To zadanie łączy się ze źródłową bazą danych RDS dla MySQL, wyodrębnia dane i ładuje je do docelowej bazy danych RDS dla MySQL. To zadanie odczytuje dane ze źródłowej tabeli MySQL i ładuje je do docelowej tabeli MySQL przy użyciu rozwiązania prywatnej bramy NAT. Aby uruchomić zadanie klejenia AWS, wykonaj następujące kroki:
- W konsoli AWS Glue kliknij zadania ETL w okienku nawigacji.
- Kliknij pracę
glue-private-nat-job. - Kliknij run na początek.
Poniżej znajduje się skrypt PySpark dla tego zadania ETL:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
W oparciu o konfigurację DPU zadania, AWS Glue tworzy zestaw ENI w podsieci nieroutowalnej, która jest skonfigurowana dla połączenia AWS Glue. Możesz monitorować te ENI na stronie Interfejsy sieciowe w witrynie Elastyczna chmura obliczeniowa Amazon (Amazon EC2) konsola.
Poniższy zrzut ekranu przedstawia 10 identyfikatorów ENI utworzonych dla uruchomienia zadania w celu dopasowania do żądanej liczby pracowników skonfigurowanej w parametrach zadania. Zgodnie z oczekiwaniami, ENI zostały utworzone w nieroutowalnej podsieci VPC A, umożliwiając skalowalność adresów IP. Po zakończeniu zadania te ENI zostaną automatycznie zwolnione przez AWS Glue.
Gdy zadanie klejenia AWS jest uruchomione, możesz monitorować jego status. Po pomyślnym zakończeniu status zadania zmienia się na Następca.
Sprawdź wyniki
Po zakończeniu zadania klejenia AWS połącz się z docelową bazą danych MySQL. Sprawdź, czy docelowa liczba rekordów jest zgodna ze źródłem. Możesz użyć poniższego zapytania SQL w terminalu AWS Cloud9.
USE targetdb;
SELECT count(*) from emp;Na koniec wyjdź z narzędzia klienta MySQL, używając następującego polecenia i wróć do terminala AWS Cloud9: quit;
Możesz teraz potwierdzić, że AWS Glue pomyślnie wykonał zadanie załadowania danych do docelowej bazy danych przy użyciu adresów IP z podsieci nierutowalnej. To kończy kompleksowe testowanie rozwiązania prywatnej bramy NAT.
Sprzątać
Aby uniknąć przyszłych opłat, usuń zasób utworzony za pomocą stosu CloudFormation, wykonując następujące kroki:
- W konsoli AWS CloudFormation kliknij Stosy w panelu nawigacyjnym.
- Wybierz stos
AWSGluePrivateNATStack. - Kliknij Usuń, aby usunąć stos. Po wyświetleniu monitu potwierdź usunięcie stosu.
Wnioski
W tym poście pokazaliśmy, jak można skalować zadania AWS Glue, optymalizując wykorzystanie adresów IP i zwiększając przepustowość sieci za pomocą rozwiązania prywatnej bramy NAT. To dwojakie podejście pomaga odblokować środowisko, które ma ograniczenia pojemności adresu IP. Opcje omówione w sekcji Optymalizacja adresów IP AWS Glue są uzupełnieniem rozwiązań rozszerzania adresów IP i można je iteracyjnie kompilować, aby dostosować platformę danych do dojrzałości.
Dowiedz się więcej o technikach optymalizacji pracy kleju AWS z Monitoruj i optymalizuj koszty AWS Glue dla Apache Spark i Najlepsze praktyki skalowania zadań Apache Spark i partycjonowania danych za pomocą AWS Glue.
O autorach
 Sushantha Kothapally’ego jest architektem rozwiązań w Amazon Web Services obsługującym klientów z branży motoryzacyjnej i produkcyjnej. Jego pasją jest projektowanie rozwiązań technologicznych spełniających cele biznesowe. Jego dużym zainteresowaniem cieszą się architektury bezserwerowe i sterowane zdarzeniami.
Sushantha Kothapally’ego jest architektem rozwiązań w Amazon Web Services obsługującym klientów z branży motoryzacyjnej i produkcyjnej. Jego pasją jest projektowanie rozwiązań technologicznych spełniających cele biznesowe. Jego dużym zainteresowaniem cieszą się architektury bezserwerowe i sterowane zdarzeniami.
 Senthil Kamala Rathinam jest architektem rozwiązań w Amazon Web Services, specjalizującym się w danych i analityce. Pasjonuje się pomaganiem klientom w projektowaniu i budowaniu nowoczesnych platform danych. W wolnym czasie Senthil uwielbia spędzać czas z rodziną i grać w badmintona.
Senthil Kamala Rathinam jest architektem rozwiązań w Amazon Web Services, specjalizującym się w danych i analityce. Pasjonuje się pomaganiem klientom w projektowaniu i budowaniu nowoczesnych platform danych. W wolnym czasie Senthil uwielbia spędzać czas z rodziną i grać w badmintona.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

