W dzisiejszym krajobrazie indywidualnych interakcji z klientami w celu składania zamówień, dominująca praktyka w dalszym ciągu opiera się na obecności ludzi, nawet w takich miejscach, jak kawiarnie typu drive-thru i lokale typu fast food. To tradycyjne podejście stwarza kilka wyzwań: w dużym stopniu zależy od procesów ręcznych, ma trudności z efektywnym skalowaniem w miarę rosnących wymagań klientów, stwarza ryzyko wystąpienia błędów ludzkich i działa w określonych godzinach dostępności. Ponadto na konkurencyjnych rynkach firmy stosujące wyłącznie procesy ręczne mogą mieć trudności ze świadczeniem wydajnych i konkurencyjnych usług. Pomimo postępu technologicznego model skoncentrowany na człowieku pozostaje głęboko zakorzeniony w przetwarzaniu zamówień, co prowadzi do tych ograniczeń.
Perspektywa wykorzystania technologii do wspomagania realizacji zamówień jeden na jednego istnieje już od jakiegoś czasu. Jednakże istniejące rozwiązania często można podzielić na dwie kategorie: systemy oparte na regułach, które wymagają dużo czasu i wysiłku przy konfiguracji i utrzymaniu, lub systemy sztywne, którym brakuje elastyczności wymaganej do interakcji z klientami na poziomie człowieka. W rezultacie przedsiębiorstwa i organizacje stają przed wyzwaniami związanymi z szybkim i skutecznym wdrażaniem takich rozwiązań. Na szczęście wraz z pojawieniem się generatywna sztuczna inteligencja i duże modele językowe (LLM), możliwe jest teraz tworzenie zautomatyzowanych systemów, które będą w stanie efektywnie obsługiwać język naturalny i działać szybciej.
Amazońska skała macierzysta to w pełni zarządzana usługa, która oferuje wybór wysokowydajnych modeli podstawowych (FM) od wiodących firm zajmujących się sztuczną inteligencją, takich jak AI21 Labs, Anthropic, Cohere, Meta, Stability AI i Amazon za pośrednictwem jednego interfejsu API, wraz z szerokim zestawem funkcji, których potrzebujesz muszą tworzyć generatywne aplikacje AI zapewniające bezpieczeństwo, prywatność i odpowiedzialną sztuczną inteligencję. Oprócz Amazon Bedrock możesz korzystać z innych usług AWS, takich jak Amazon SageMaker JumpStart i Amazonka Lex stworzyć w pełni zautomatyzowanych i łatwo adaptowalnych agentów przetwarzania zamówień w oparciu o generatywną sztuczną inteligencję.
W tym poście pokażemy, jak zbudować agenta przetwarzania zamówień obsługującego mowę, korzystając z Amazon Lex, Amazon Bedrock i AWS Lambda.
Omówienie rozwiązania
Poniższy diagram ilustruje naszą architekturę rozwiązania.
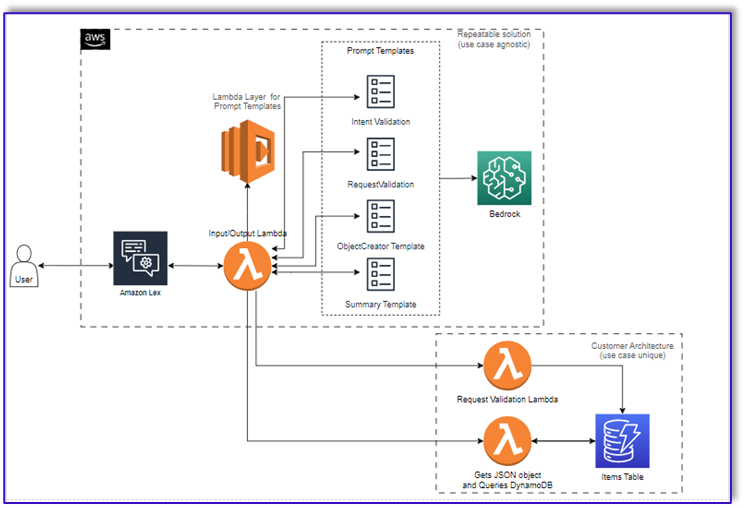
Przepływ pracy składa się z następujących kroków:
- Klient składa zamówienie za pośrednictwem Amazon Lex.
- Bot Amazon Lex interpretuje intencje klienta i uruchamia:
DialogCodeHook.
- Funkcja Lambda pobiera odpowiedni szablon podpowiedzi z warstwy Lambda i formatuje podpowiedzi modelu, dodając dane wejściowe klienta do powiązanego szablonu podpowiedzi.
- Połączenia
RequestValidation Prompt weryfikuje zamówienie z pozycją menu i informuje klienta za pośrednictwem Amazon Lex, czy jest coś, co chce zamówić, a nie jest częścią menu i przedstawia rekomendacje. Monit przeprowadza również wstępną weryfikację kompletności zamówienia.
- Połączenia
ObjectCreator Prompt konwertuje żądania w języku naturalnym na strukturę danych (format JSON).
- Funkcja walidatora klienta Lambda weryfikuje wymagane atrybuty zamówienia i potwierdza, czy dostępne są wszystkie informacje niezbędne do realizacji zamówienia.
- Funkcja Lambda klienta przyjmuje strukturę danych jako dane wejściowe do przetwarzania zamówienia i przekazuje kwotę zamówienia z powrotem do orkiestrującej funkcji Lambda.
- Koordynująca funkcja Lambda wywołuje punkt końcowy Amazon Bedrock LLM w celu wygenerowania końcowego podsumowania zamówienia, obejmującego sumę zamówienia z systemu bazy danych klientów (na przykład Amazon DynamoDB).
- Podsumowanie zamówienia jest przesyłane klientowi za pośrednictwem Amazon Lex. Po potwierdzeniu przez Klienta zamówienia, zamówienie zostanie zrealizowane.
Wymagania wstępne
W tym poście założono, że masz aktywne konto AWS i znasz następujące koncepcje i usługi:
Ponadto, aby uzyskać dostęp do Amazon Bedrock z funkcji Lambda, musisz upewnić się, że środowisko wykonawcze Lambda ma następujące biblioteki:
- boto3>=1.28.57
- awscli>=1.29.57
- botocore>=1.31.57
Można to zrobić za pomocą pliku warstwa lambdy lub używając konkretnego AMI z wymaganymi bibliotekami.
Co więcej, biblioteki te są wymagane podczas wywoływania interfejsu API Amazon Bedrock z poziomu Studio Amazon SageMaker. Można to zrobić, uruchamiając komórkę z następującym kodem:
%pip install --no-build-isolation --force-reinstall
"boto3>=1.28.57"
"awscli>=1.29.57"
"botocore>=1.31.57"
Na koniec tworzysz następującą politykę, a później dołączasz ją do dowolnej roli uzyskującej dostęp do Amazon Bedrock:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}
Utwórz tabelę DynamoDB
W naszym konkretnym scenariuszu utworzyliśmy tabelę DynamoDB jako nasz system bazy danych klientów, ale możesz również z niej skorzystać Usługa relacyjnych baz danych Amazon (Amazon RDS). Wykonaj następujące kroki, aby udostępnić tabelę DynamoDB (lub dostosuj ustawienia zgodnie z potrzebami):
- W konsoli DynamoDB wybierz Stoły w okienku nawigacji.
- Dodaj Utwórz tabelę.
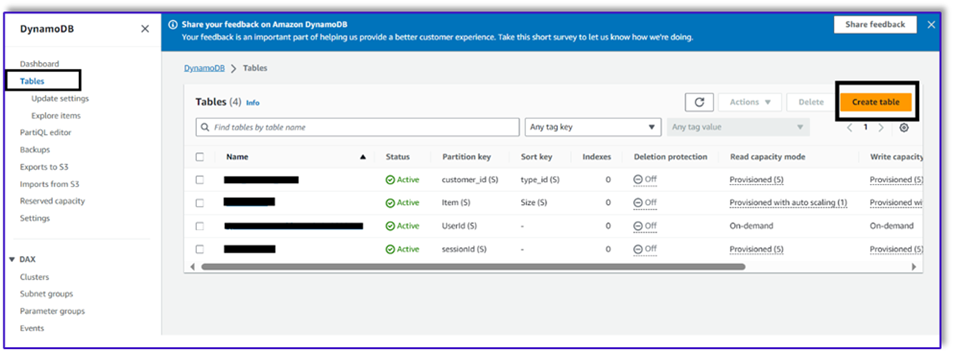
- W razie zamówieenia projektu Nazwa tabeliwprowadź nazwę (na przykład
ItemDetails).
- W razie zamówieenia projektu Klucz partycji, wprowadź klucz (w tym poście używamy
Item).
- W razie zamówieenia projektu Sortuj klucz, wprowadź klucz (w tym poście używamy
Size).
- Dodaj Utwórz tabelę.

Teraz możesz załadować dane do tabeli DynamoDB. W tym poście używamy pliku CSV. Możesz załadować dane do tabeli DynamoDB, używając kodu Pythona w notatniku SageMaker.
Najpierw musimy skonfigurować profil o nazwie dev.
- Otwórz nowy terminal w SageMaker Studio i uruchom następującą komendę:
aws configure --profile dev
To polecenie poprosi Cię o podanie identyfikatora klucza dostępu AWS, tajnego klucza dostępu, domyślnego regionu AWS i formatu wyjściowego.
- Wróć do notatnika SageMaker i napisz kod w Pythonie, aby skonfigurować połączenie z DynamoDB przy użyciu biblioteki Boto3 w Pythonie. Ten fragment kodu tworzy sesję przy użyciu określonego profilu AWS o nazwie dev, a następnie tworzy klienta DynamoDB przy użyciu tej sesji. Poniżej znajduje się przykładowy kod służący do ładowania danych:
%pip install boto3
import boto3
import csv
# Create a session using a profile named 'dev'
session = boto3.Session(profile_name='dev')
# Create a DynamoDB resource using the session
dynamodb = session.resource('dynamodb')
# Specify your DynamoDB table name
table_name = 'your_table_name'
table = dynamodb.Table(table_name)
# Specify the path to your CSV file
csv_file_path = 'path/to/your/file.csv'
# Read CSV file and put items into DynamoDB
with open(csv_file_path, 'r', encoding='utf-8-sig') as csvfile:
csvreader = csv.reader(csvfile)
# Skip the header row
next(csvreader, None)
for row in csvreader:
# Extract values from the CSV row
item = {
'Item': row[0], # Adjust the index based on your CSV structure
'Size': row[1],
'Price': row[2]
}
# Put item into DynamoDB
response = table.put_item(Item=item)
print(f"Item added: {response}")
print(f"CSV data has been loaded into the DynamoDB table: {table_name}")
Alternatywnie można użyć Środowisko pracy NoSQL lub inne narzędzia do szybkiego ładowania danych do tabeli DynamoDB.
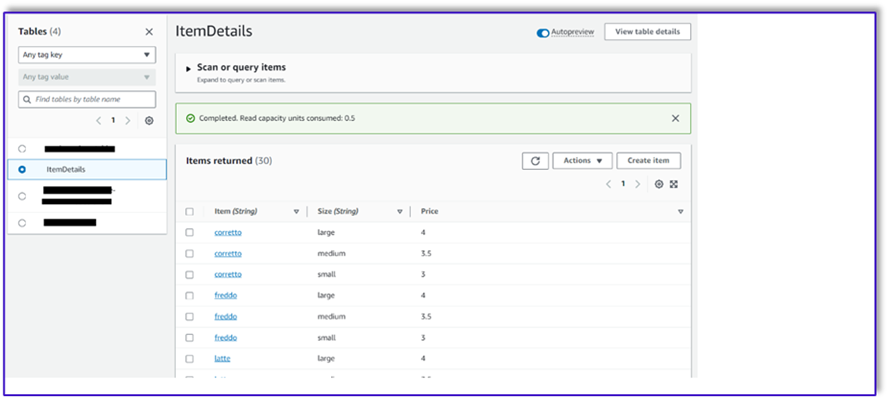
Poniżej znajduje się zrzut ekranu po wstawieniu przykładowych danych do tabeli.
Twórz szablony w notatniku SageMaker, korzystając z interfejsu API wywoływania Amazon Bedrock
Aby utworzyć nasz szablon podpowiedzi dla tego przypadku użycia, używamy Amazon Bedrock. Dostęp do Amazon Bedrock można uzyskać z Konsola zarządzania AWS oraz poprzez wywołania API. W naszym przypadku uzyskujemy dostęp do Amazon Bedrock poprzez API z wygodnego notatnika SageMaker Studio, aby utworzyć nie tylko nasz szablon podpowiedzi, ale także nasz kompletny kod wywołania API, który możemy później wykorzystać w naszej funkcji Lambda.
- Na konsoli SageMaker uzyskaj dostęp do istniejącej domeny SageMaker Studio lub utwórz nową, aby uzyskać dostęp do Amazon Bedrock z notatnika SageMaker.

- Po utworzeniu domeny i użytkownika SageMaker wybierz użytkownika i wybierz Premiera i Studio. Spowoduje to otwarcie środowiska JupyterLab.
- Gdy środowisko JupyterLab będzie gotowe, otwórz nowy notatnik i rozpocznij import niezbędnych bibliotek.
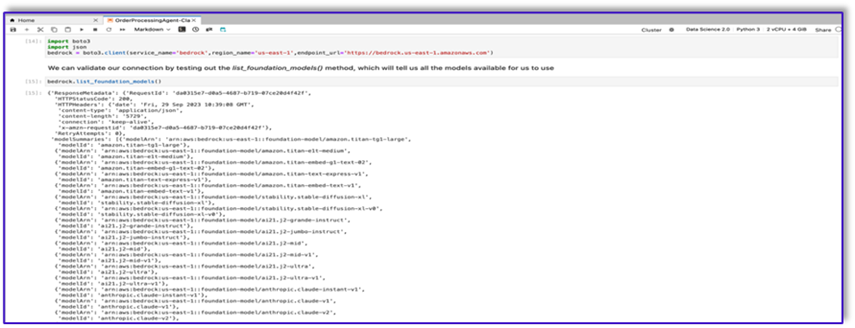
Istnieje wiele FM dostępnych za pośrednictwem pakietu SDK Amazon Bedrock Python. W tym przypadku używamy Claude V2, potężnego modelu podstawowego opracowanego przez Anthropic.
Agent przetwarzający zamówienia potrzebuje kilku różnych szablonów. Może się to zmieniać w zależności od przypadku użycia, ale opracowaliśmy ogólny przepływ pracy, który można zastosować do wielu ustawień. W tym przypadku szablon Amazon Bedrock LLM wykona następujące czynności:
- Zweryfikuj intencje klienta
- Zweryfikuj żądanie
- Utwórz strukturę danych zamówienia
- Przekaż podsumowanie zamówienia klientowi
- Aby wywołać model, utwórz obiekt wykonawczy z poziomu Boto3.

#Model api request parameters
modelId = 'anthropic.claude-v2' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
import boto3
import json
bedrock = boto3.client(service_name='bedrock-runtime')
Zacznijmy od pracy nad szablonem podpowiedzi modułu sprawdzania intencji. Jest to proces iteracyjny, ale dzięki przewodnikowi inżynieryjnemu firmy Anthropic można szybko utworzyć podpowiedzi, które umożliwią wykonanie zadania.
- Utwórz pierwszy szablon podpowiedzi wraz z funkcją narzędziową, która pomoże przygotować treść na wywołania API.
Poniżej znajduje się kod dla pliku Prompt_template_intent_validator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to identify the intent that the human wants to accomplish and respond appropriately. The valid intents are: Greeting,Place Order, Complain, Speak to Someone. Always put your response to the Human within the Response tags. Also add an XML tag to your output identifying the human intent.nHere are some examples:n<example><Conversation> H: hi there.nnA: Hi, how can I help you today?nnH: Yes. I would like a medium mocha please</Conversation>nnA:<intent>Place Order</intent><Response>nGot it.</Response></example>n<example><Conversation> H: hellonnA: Hi, how can I help you today?nnH: my coffee does not taste well can you please re-make it?</Conversation>nnA:<intent>Complain</intent><Response>nOh, I am sorry to hear that. Let me get someone to help you.</Response></example>n<example><Conversation> H: hinnA: Hi, how can I help you today?nnH: I would like to speak to someone else please</Conversation>nnA:<intent>Speak to Someone</intent><Response>nSure, let me get someone to help you.</Response></example>n<example><Conversation> H: howdynnA: Hi, how can I help you today?nnH:can I get a large americano with sugar and 2 mochas with no whipped cream</Conversation>nnA:<intent>Place Order</intent><Response>nSure thing! Please give me a moment.</Response></example>n<example><Conversation> H: hinn</Conversation>nnA:<intent>Greeting</intent><Response>nHi there, how can I help you today?</Response></example>n</instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 1, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"
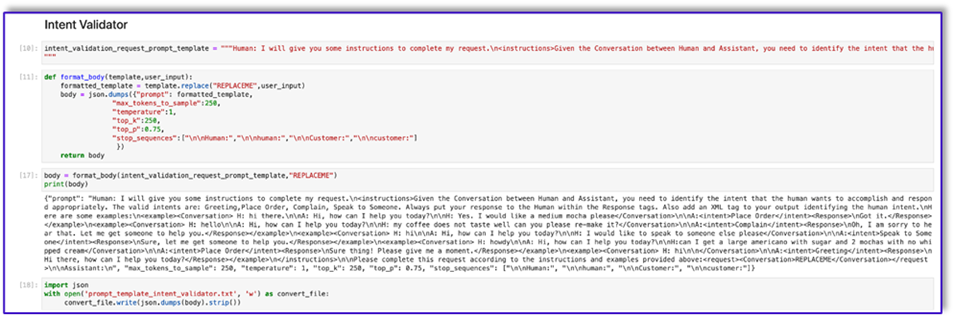

- Zapisz ten szablon w pliku, aby przesłać go do Amazon S3 i w razie potrzeby wywołać funkcję Lambda. Zapisz szablony jako serializowane ciągi znaków JSON w pliku tekstowym. Poprzedni zrzut ekranu pokazuje przykładowy kod, który również to umożliwia.
- Powtórz te same kroki z innymi szablonami.
Poniżej znajdują się zrzuty ekranu innych szablonów i wyniki wywołania Amazon Bedrock przy użyciu niektórych z nich.
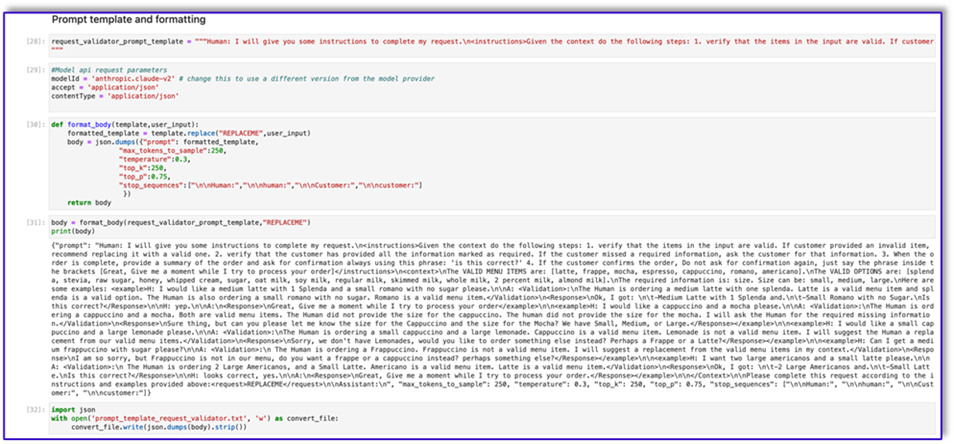
Poniżej znajduje się kod dla pliku Prompt_template_request_validator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the context do the following steps: 1. verify that the items in the input are valid. If customer provided an invalid item, recommend replacing it with a valid one. 2. verify that the customer has provided all the information marked as required. If the customer missed a required information, ask the customer for that information. 3. When the order is complete, provide a summary of the order and ask for confirmation always using this phrase: 'is this correct?' 4. If the customer confirms the order, Do not ask for confirmation again, just say the phrase inside the brackets [Great, Give me a moment while I try to process your order]</instructions>n<context>nThe VALID MENU ITEMS are: [latte, frappe, mocha, espresso, cappuccino, romano, americano].nThe VALID OPTIONS are: [splenda, stevia, raw sugar, honey, whipped cream, sugar, oat milk, soy milk, regular milk, skimmed milk, whole milk, 2 percent milk, almond milk].nThe required information is: size. Size can be: small, medium, large.nHere are some examples: <example>H: I would like a medium latte with 1 Splenda and a small romano with no sugar please.nnA: <Validation>:nThe Human is ordering a medium latte with one splenda. Latte is a valid menu item and splenda is a valid option. The Human is also ordering a small romano with no sugar. Romano is a valid menu item.</Validation>n<Response>nOk, I got: nt-Medium Latte with 1 Splenda and.nt-Small Romano with no Sugar.nIs this correct?</Response>nnH: yep.nnA:n<Response>nGreat, Give me a moment while I try to process your order</example>nn<example>H: I would like a cappuccino and a mocha please.nnA: <Validation>:nThe Human is ordering a cappuccino and a mocha. Both are valid menu items. The Human did not provide the size for the cappuccino. The human did not provide the size for the mocha. I will ask the Human for the required missing information.</Validation>n<Response>nSure thing, but can you please let me know the size for the Cappuccino and the size for the Mocha? We have Small, Medium, or Large.</Response></example>nn<example>H: I would like a small cappuccino and a large lemonade please.nnA: <Validation>:nThe Human is ordering a small cappuccino and a large lemonade. Cappuccino is a valid menu item. Lemonade is not a valid menu item. I will suggest the Human a replacement from our valid menu items.</Validation>n<Response>nSorry, we don't have Lemonades, would you like to order something else instead? Perhaps a Frappe or a Latte?</Response></example>nn<example>H: Can I get a medium frappuccino with sugar please?nnA: <Validation>:n The Human is ordering a Frappuccino. Frappuccino is not a valid menu item. I will suggest a replacement from the valid menu items in my context.</Validation>n<Response>nI am so sorry, but Frappuccino is not in our menu, do you want a frappe or a cappuccino instead? perhaps something else?</Response></example>nn<example>H: I want two large americanos and a small latte please.nnA: <Validation>:n The Human is ordering 2 Large Americanos, and a Small Latte. Americano is a valid menu item. Latte is a valid menu item.</Validation>n<Response>nOk, I got: nt-2 Large Americanos and.nt-Small Latte.nIs this correct?</Response>nnH: looks correct, yes.nnA:n<Response>nGreat, Give me a moment while I try to process your order.</Response></example>nn</Context>nnPlease complete this request according to the instructions and examples provided above:<request>REPLACEME</request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"
Poniżej znajduje się nasza odpowiedź od Amazon Bedrock, w której wykorzystano ten szablon.

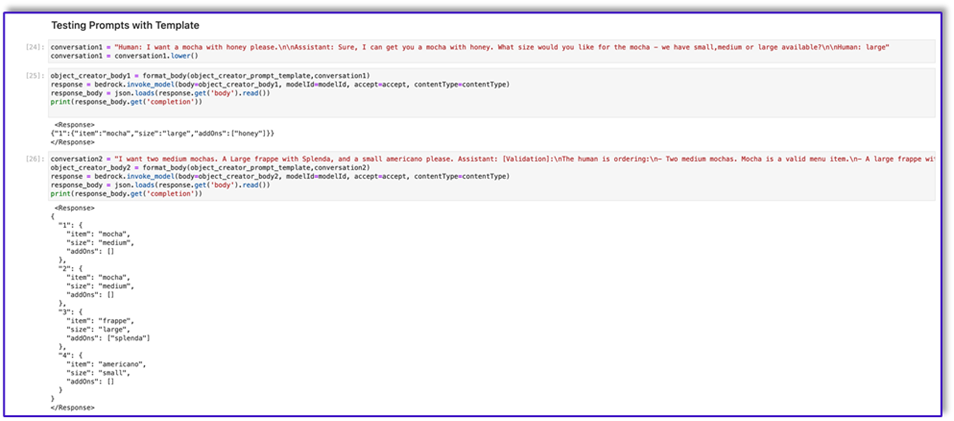
Poniżej znajduje się kod dla prompt_template_object_creator.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to create a json object in Response with the appropriate attributes.nHere are some examples:n<example><Conversation> H: I want a latte.nnA:nCan I have the size?nnH: Medium.nnA: So, a medium latte.nIs this Correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"latte","size":"medium","addOns":[]}}</Response></example>n<example><Conversation> H: I want a large frappe and 2 small americanos with sugar.nnA: Okay, let me confirm:nn1 large frappenn2 small americanos with sugarnnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"frappe","size":"large","addOns":[]},"2":{"item":"americano","size":"small","addOns":["sugar"]},"3":{"item":"americano","size":"small","addOns":["sugar"]}}</Response>n</example>n<example><Conversation> H: I want a medium americano.nnA: Okay, let me confirm:nn1 medium americanonnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"americano","size":"medium","addOns":[]}}</Response></example>n<example><Conversation> H: I want a large latte with oatmilk.nnA: Okay, let me confirm:nnLarge latte with oatmilknnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"latte","size":"large","addOns":["oatmilk"]}}</Response></example>n<example><Conversation> H: I want a small mocha with no whipped cream please.nnA: Okay, let me confirm:nnSmall mocha with no whipped creamnnIs this correct?nnH: Yes.</Conversation>nnA:<Response>{"1":{"item":"mocha","size":"small","addOns":["no whipped cream"]}}</Response>nn</example></instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:"]}"

Poniżej znajduje się kod dla Prompt_template_order_summary.txt:
"{"prompt": "Human: I will give you some instructions to complete my request.n<instructions>Given the Conversation between Human and Assistant, you need to create a summary of the order with bullet points and include the order total.nHere are some examples:n<example><Conversation> H: I want a large frappe and 2 small americanos with sugar.nnA: Okay, let me confirm:nn1 large frappenn2 small americanos with sugarnnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>10.50</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nn1 large frappenn2 small americanos with sugar.nYour Order total is $10.50</Response></example>n<example><Conversation> H: I want a medium americano.nnA: Okay, let me confirm:nn1 medium americanonnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>3.50</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nn1 medium americano.nYour Order total is $3.50</Response></example>n<example><Conversation> H: I want a large latte with oat milk.nnA: Okay, let me confirm:nnLarge latte with oat milknnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>6.75</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nnLarge latte with oat milk.nYour Order total is $6.75</Response></example>n<example><Conversation> H: I want a small mocha with no whipped cream please.nnA: Okay, let me confirm:nnSmall mocha with no whipped creamnnIs this correct?nnH: Yes.</Conversation>nn<OrderTotal>4.25</OrderTotal>nnA:<Response>nHere is a summary of your order along with the total:nnSmall mocha with no whipped cream.nYour Order total is $6.75</Response>nn</example>n</instructions>nnPlease complete this request according to the instructions and examples provided above:<request><Conversation>REPLACEME</Conversation>nn<OrderTotal>REPLACETOTAL</OrderTotal></request>nnAssistant:n", "max_tokens_to_sample": 250, "temperature": 0.3, "top_k": 250, "top_p": 0.75, "stop_sequences": ["nnHuman:", "nnhuman:", "nnCustomer:", "nncustomer:", "[Conversation]"]}"


Jak widać, użyliśmy naszych szablonów podpowiedzi do sprawdzenia pozycji menu, zidentyfikowania brakujących wymaganych informacji, stworzenia struktury danych i podsumowania kolejności. Podstawowe modele dostępne w Amazon Bedrock są bardzo wydajne, dzięki czemu możesz wykonać jeszcze więcej zadań za pomocą tych szablonów.
Zakończyłeś projektowanie podpowiedzi i zapisałeś szablony w plikach tekstowych. Możesz teraz rozpocząć tworzenie bota Amazon Lex i powiązanych funkcji Lambda.
Utwórz warstwę Lambda za pomocą szablonów podpowiedzi
Wykonaj następujące kroki, aby utworzyć warstwę Lambda:
- W SageMaker Studio utwórz nowy folder z podfolderem o nazwie
python.
- Skopiuj pliki podpowiedzi do pliku
python teczka.

- Możesz dodać bibliotekę ZIP do instancji notatnika, uruchamiając następujące polecenie.
!conda install -y -c conda-forge zip
- Teraz uruchom następujące polecenie, aby utworzyć plik ZIP do przesłania do warstwy Lambda.
!zip -r prompt_templates_layer.zip prompt_templates_layer/.
- Po utworzeniu pliku ZIP możesz go pobrać. Przejdź do Lambda, utwórz nową warstwę, przesyłając plik bezpośrednio lub przesyłając najpierw do Amazon S3.
- Następnie dołącz tę nową warstwę do funkcji Lambda orkiestracji.
Teraz pliki szablonów podpowiedzi są przechowywane lokalnie w środowisku wykonawczym Lambda. Przyspieszy to proces podczas uruchamiania bota.
Utwórz warstwę Lambda z wymaganymi bibliotekami
Wykonaj następujące kroki, aby utworzyć warstwę Lambda z wymaganymi bibliotekami:
- Otwieranie Chmura AWS9 środowisku instancji utwórz folder z podfolderem o nazwie
python.
- Otwórz terminal wewnątrz
python teczka.
- Uruchom następujące polecenia z terminala:
pip install “boto3>=1.28.57” -t .
pip install “awscli>=1.29.57" -t .
pip install “botocore>=1.31.57” -t .
- run
cd .. i umieść się w swoim nowym folderze, w którym również masz plik python podfolder.
- Uruchom następujące polecenie:
- Po utworzeniu pliku ZIP możesz go pobrać. Przejdź do Lambda, utwórz nową warstwę, przesyłając plik bezpośrednio lub przesyłając najpierw do Amazon S3.
- Następnie dołącz tę nową warstwę do funkcji Lambda orkiestracji.
Utwórz bota w Amazon Lex v2
W tym przypadku budujemy bota Amazon Lex, który może zapewnić interfejs wejścia/wyjścia dla architektury w celu wywołania Amazon Bedrock za pomocą głosu lub tekstu z dowolnego interfejsu. Ponieważ LLM zajmie się konwersacją tego agenta przetwarzającego zamówienia, a Lambda będzie koordynować przepływ pracy, możesz utworzyć bota z trzema intencjami i bez miejsc.
- Na konsoli Amazon Lex utwórz nowego bota za pomocą metody Utwórz pustego bota.
Teraz możesz dodać intencję z dowolną odpowiednią wypowiedzią początkową, aby użytkownicy końcowi mogli rozpocząć rozmowę z botem. Używamy prostych powitań i dodajemy wstępną odpowiedź bota, aby użytkownicy końcowi mogli przekazać swoje żądania. Tworząc bota, pamiętaj o użyciu haka w kodzie Lambda z intencjami; uruchomi to funkcję Lambda, która zorganizuje przepływ pracy między klientem, Amazon Lex i LLM.
- Dodaj pierwszą intencję, która uruchomi przepływ pracy i użyje szablonu monitu o sprawdzenie intencji, aby wywołać Amazon Bedrock i określić, co klient próbuje osiągnąć. Dodaj kilka prostych wypowiedzi, aby użytkownicy końcowi mogli rozpocząć rozmowę.

Nie musisz używać żadnych slotów ani wstępnego czytania w żadnej z intencji bota. Tak naprawdę nie ma potrzeby dodawania wyrażeń do drugiej lub trzeciej intencji. Dzieje się tak, ponieważ LLM poprowadzi Lambdę przez cały proces.
- Dodaj monit o potwierdzenie. Możesz później dostosować ten komunikat w funkcji Lambda.
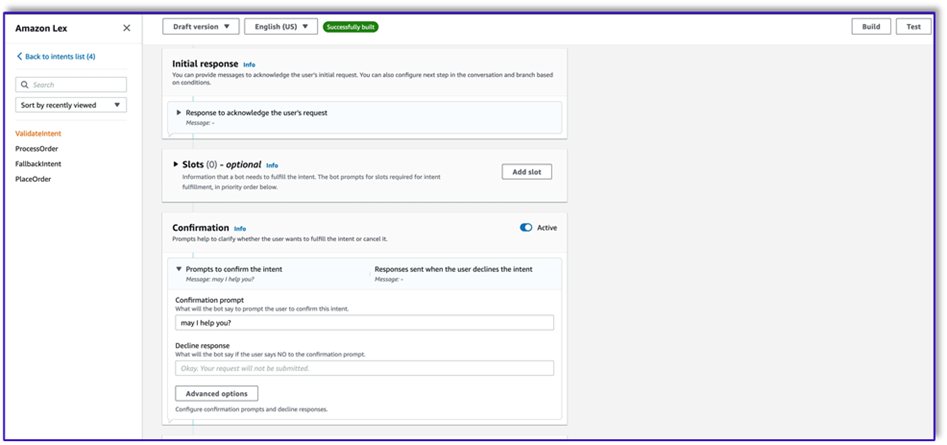
- Pod Kod haczyki, Wybierz Użyj funkcji Lambda do inicjalizacji i sprawdzania poprawności.
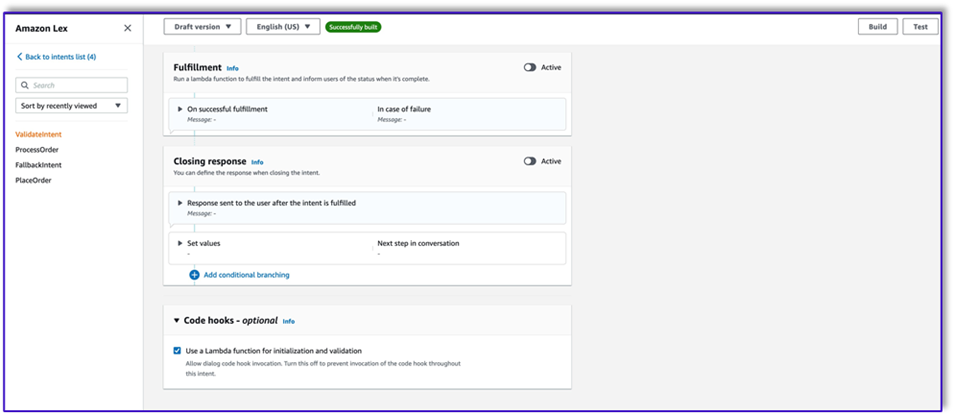
- Stwórz drugą intencję bez wypowiedzi i początkowej odpowiedzi. To jest
PlaceOrder zamiar.
Gdy LLM wykryje, że klient próbuje złożyć zamówienie, funkcja Lambda uruchomi ten zamiar i zweryfikuje żądanie klienta w menu oraz upewni się, że nie brakuje żadnych wymaganych informacji. Pamiętaj, że wszystko to znajduje się w szablonach podpowiedzi, więc możesz dostosować ten przepływ pracy do dowolnego przypadku użycia, zmieniając szablony podpowiedzi.
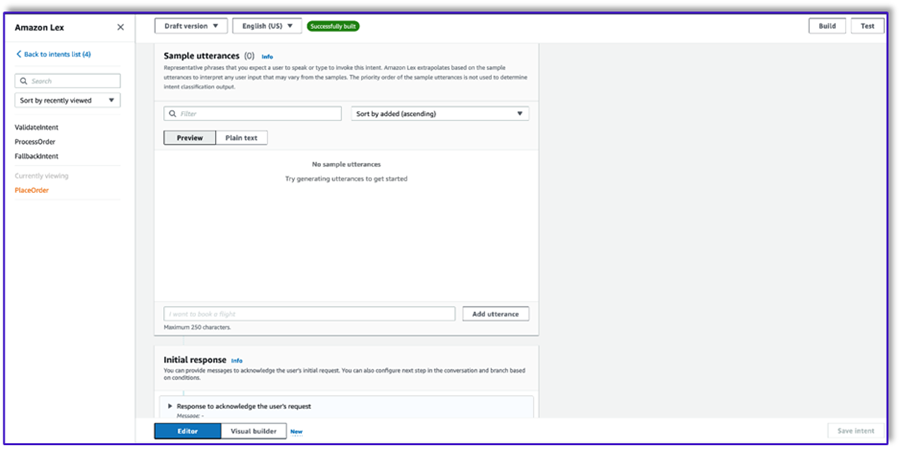
- Nie dodawaj żadnych przedziałów, ale dodaj monit o potwierdzenie i odrzuć odpowiedź.
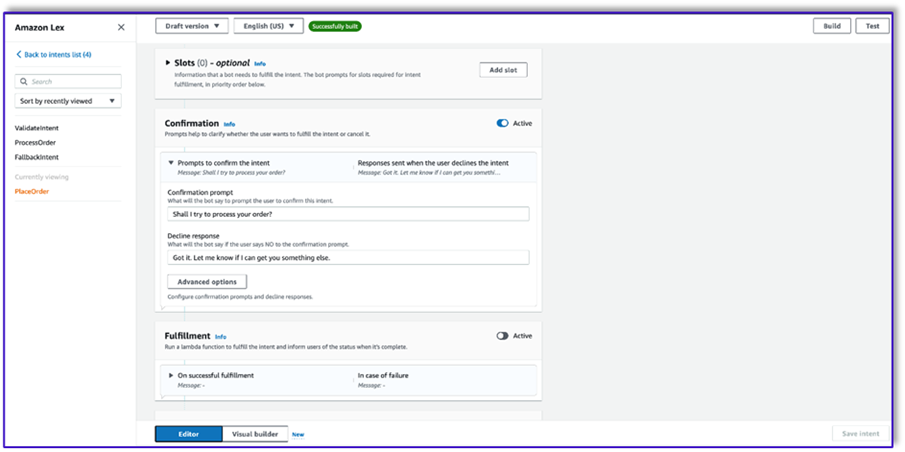
- Wybierz Użyj funkcji Lambda do inicjalizacji i sprawdzania poprawności.

- Utwórz trzecią intencję o nazwie
ProcessOrder bez przykładowych wypowiedzi i bez szczelin.
- Dodaj odpowiedź wstępną, prośbę o potwierdzenie i odpowiedź o odrzuceniu.
Po zatwierdzeniu żądania klienta przez LLM funkcja Lambda uruchamia trzecią i ostatnią intencję realizacji zamówienia. W tym przypadku Lambda użyje szablonu kreatora obiektów do wygenerowania struktury danych JSON zamówienia w celu wysłania zapytania do tabeli DynamoDB, a następnie użyje szablonu podsumowania zamówienia do podsumowania całego zamówienia wraz z sumą, aby Amazon Lex mógł przekazać je klientowi.
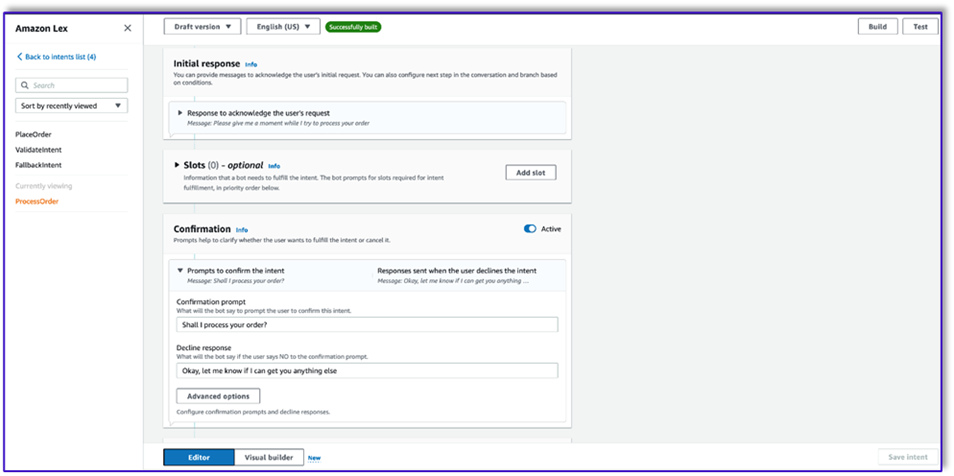
- Wybierz Użyj funkcji Lambda do inicjalizacji i sprawdzania poprawności. Może to wykorzystać dowolną funkcję Lambda do przetworzenia zamówienia po ostatecznym potwierdzeniu przez klienta.

- Po utworzeniu wszystkich trzech intencji przejdź do kreatora wizualizacji dla
ValidateIntent, dodaj krok zamiaru przejścia do celu i podłącz wyjście pozytywnego potwierdzenia do tego kroku.
- Po dodaniu intencji „przejdź do” dokonaj jej edycji i jako nazwę intencji wybierz intencję PlaceOrder.

- Podobnie, aby przejść do kreatora wizualizacji dla
PlaceOrder zamiar i podłącz wyjście pozytywnego potwierdzenia do ProcessOrder zamiar iść do celu. Nie jest wymagana żadna edycja ProcessOrder zamiar.
- Teraz musisz utworzyć funkcję Lambda, która koordynuje działanie Amazon Lex i wywołuje tabelę DynamoDB, jak opisano szczegółowo w następnej sekcji.
Utwórz funkcję Lambda, aby zarządzać botem Amazon Lex
Możesz teraz zbudować funkcję Lambda, która koordynuje bota i przepływ pracy Amazon Lex. Wykonaj następujące kroki:
- Utwórz funkcję Lambda ze standardową polityką wykonywania i pozwól Lambdzie utworzyć dla Ciebie rolę.
- W oknie kodu swojej funkcji dodaj kilka funkcji narzędziowych, które pomogą: sformatuj podpowiedzi, dodając kontekst leksykalny do szablonu, wywołaj API Amazon Bedrock LLM, wyodrębnij żądany tekst z odpowiedzi i nie tylko. Zobacz następujący kod:
import json
import re
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
bedrock = boto3.client(service_name='bedrock-runtime')
def CreatingCustomPromptFromLambdaLayer(object_key,replace_items):
folder_path = '/opt/order_processing_agent_prompt_templates/python/'
try:
file_path = folder_path + object_key
with open(file_path, "r") as file1:
raw_template = file1.read()
# Modify the template with the custom input prompt
#template['inputs'][0].insert(1, {"role": "user", "content": '### Input:n' + user_request})
for key,value in replace_items.items():
value = json.dumps(json.dumps(value).replace('"','')).replace('"','')
raw_template = raw_template.replace(key,value)
modified_prompt = raw_template
return modified_prompt
except Exception as e:
return {
'statusCode': 500,
'body': f'An error occurred: {str(e)}'
}
def CreatingCustomPrompt(object_key,replace_items):
logger.debug('replace_items is: {}'.format(replace_items))
#retrieve user request from intent_request
#we first propmt the model with current order
bucket_name = 'your-bucket-name'
#object_key = 'prompt_template_order_processing.txt'
try:
s3 = boto3.client('s3')
# Retrieve the existing template from S3
response = s3.get_object(Bucket=bucket_name, Key=object_key)
raw_template = response['Body'].read().decode('utf-8')
raw_template = json.loads(raw_template)
logger.debug('raw template is {}'.format(raw_template))
#template_json = json.loads(raw_template)
#logger.debug('template_json is {}'.format(template_json))
#template = json.dumps(template_json)
#logger.debug('template is {}'.format(template))
# Modify the template with the custom input prompt
#template['inputs'][0].insert(1, {"role": "user", "content": '### Input:n' + user_request})
for key,value in replace_items.items():
raw_template = raw_template.replace(key,value)
logger.debug("Replacing: {} nwith: {}".format(key,value))
modified_prompt = json.dumps(raw_template)
logger.debug("Modified template: {}".format(modified_prompt))
logger.debug("Modified template type is: {}".format(print(type(modified_prompt))))
#modified_template_json = json.loads(modified_prompt)
#logger.debug("Modified template json: {}".format(modified_template_json))
return modified_prompt
except Exception as e:
return {
'statusCode': 500,
'body': f'An error occurred: {str(e)}'
}
def validate_intent(intent_request):
logger.debug('starting validate_intent: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
#Preparing validation prompt by adding context to prompt template
object_key = 'prompt_template_intent_validator.txt'
#replace_items = {"REPLACEME":full_context}
#replace_items = {"REPLACEME":dialog_context}
replace_items = {"REPLACEME":dialog_context}
#validation_prompt = CreatingCustomPrompt(object_key,replace_items)
validation_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for request validation
intent_validation_completion = prompt_bedrock(validation_prompt)
intent_validation_completion = re.sub(r'["]','',intent_validation_completion)
#extracting response from response completion and removing some special characters
validation_response = extract_response(intent_validation_completion)
validation_intent = extract_intent(intent_validation_completion)
#business logic depending on intents
if validation_intent == 'Place Order':
return validate_request(intent_request)
elif validation_intent in ['Complain','Speak to Someone']:
##adding session attributes to keep current context
full_context = full_context + 'nn' + intent_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
intent_request['sessionState']['sessionAttributes']['customerIntent'] = validation_intent
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close',validation_response)
if validation_intent == 'Greeting':
##adding session attributes to keep current context
full_context = full_context + 'nn' + intent_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
intent_request['sessionState']['sessionAttributes']['customerIntent'] = validation_intent
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'InProgress','ConfirmIntent',validation_response)
def validate_request(intent_request):
logger.debug('starting validate_request: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
#Preparing validation prompt by adding context to prompt template
object_key = 'prompt_template_request_validator.txt'
replace_items = {"REPLACEME":dialog_context}
#validation_prompt = CreatingCustomPrompt(object_key,replace_items)
validation_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for request validation
request_validation_completion = prompt_bedrock(validation_prompt)
request_validation_completion = re.sub(r'["]','',request_validation_completion)
#extracting response from response completion and removing some special characters
validation_response = extract_response(request_validation_completion)
##adding session attributes to keep current context
full_context = full_context + 'nn' + request_validation_completion
dialog_context = dialog_context + 'nnAssistant: ' + validation_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
return close(intent_request['sessionState']['sessionAttributes'],'PlaceOrder','InProgress','ConfirmIntent',validation_response)
def process_order(intent_request):
logger.debug('starting process_order: {}'.format(intent_request))
#retrieve user request from intent_request
user_request = 'Human: ' + intent_request['inputTranscript'].lower()
#getting current context variable
current_session_attributes = intent_request['sessionState']['sessionAttributes']
if len(current_session_attributes) > 0:
full_context = current_session_attributes['fullContext'] + 'nn' + user_request
dialog_context = current_session_attributes['dialogContext'] + 'nn' + user_request
else:
full_context = user_request
dialog_context = user_request
# Preparing object creator prompt by adding context to prompt template
object_key = 'prompt_template_object_creator.txt'
replace_items = {"REPLACEME":dialog_context}
#object_creator_prompt = CreatingCustomPrompt(object_key,replace_items)
object_creator_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
#Prompting model for object creation
object_creation_completion = prompt_bedrock(object_creator_prompt)
#extracting response from response completion
object_creation_response = extract_response(object_creation_completion)
inputParams = json.loads(object_creation_response)
inputParams = json.dumps(json.dumps(inputParams))
logger.debug('inputParams is: {}'.format(inputParams))
client = boto3.client('lambda')
response = client.invoke(FunctionName = 'arn:aws:lambda:us-east-1:<AccountNumber>:function:aws-blog-order-validator',InvocationType = 'RequestResponse',Payload = inputParams)
responseFromChild = json.load(response['Payload'])
validationResult = responseFromChild['statusCode']
if validationResult == 205:
order_validation_error = responseFromChild['validator_response']
return close(intent_request['sessionState']['sessionAttributes'],'PlaceOrder','InProgress','ConfirmIntent',order_validation_error)
#invokes Order Processing lambda to query DynamoDB table and returns order total
response = client.invoke(FunctionName = 'arn:aws:lambda:us-east-1: <AccountNumber>:function:aws-blog-order-processing',InvocationType = 'RequestResponse',Payload = inputParams)
responseFromChild = json.load(response['Payload'])
orderTotal = responseFromChild['body']
###Prompting the model to summarize the order along with order total
object_key = 'prompt_template_order_summary.txt'
replace_items = {"REPLACEME":dialog_context,"REPLACETOTAL":orderTotal}
#order_summary_prompt = CreatingCustomPrompt(object_key,replace_items)
order_summary_prompt = CreatingCustomPromptFromLambdaLayer(object_key,replace_items)
order_summary_completion = prompt_bedrock(order_summary_prompt)
#extracting response from response completion
order_summary_response = extract_response(order_summary_completion)
order_summary_response = order_summary_response + '. Shall I finalize processing your order?'
##adding session attributes to keep current context
full_context = full_context + 'nn' + order_summary_completion
dialog_context = dialog_context + 'nnAssistant: ' + order_summary_response
intent_request['sessionState']['sessionAttributes']['fullContext'] = full_context
intent_request['sessionState']['sessionAttributes']['dialogContext'] = dialog_context
return close(intent_request['sessionState']['sessionAttributes'],'ProcessOrder','InProgress','ConfirmIntent',order_summary_response)
""" --- Main handler and Workflow functions --- """
def lambda_handler(event, context):
"""
Route the incoming request based on intent.
The JSON body of the request is provided in the event slot.
"""
logger.debug('event is: {}'.format(event))
return dispatch(event)
def dispatch(intent_request):
"""
Called when the user specifies an intent for this bot. If intent is not valid then returns error name
"""
logger.debug('intent_request is: {}'.format(intent_request))
intent_name = intent_request['sessionState']['intent']['name']
confirmation_state = intent_request['sessionState']['intent']['confirmationState']
# Dispatch to your bot's intent handlers
if intent_name == 'ValidateIntent' and confirmation_state == 'None':
return validate_intent(intent_request)
if intent_name == 'PlaceOrder' and confirmation_state == 'None':
return validate_request(intent_request)
elif intent_name == 'PlaceOrder' and confirmation_state == 'Confirmed':
return process_order(intent_request)
elif intent_name == 'PlaceOrder' and confirmation_state == 'Denied':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Got it. Let me know if I can help you with something else.')
elif intent_name == 'PlaceOrder' and confirmation_state not in ['Denied','Confirmed','None']:
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Sorry. I am having trouble completing the request. Let me get someone to help you.')
logger.debug('exiting intent {} here'.format(intent_request['sessionState']['intent']['name']))
elif intent_name == 'ProcessOrder' and confirmation_state == 'None':
return validate_request(intent_request)
elif intent_name == 'ProcessOrder' and confirmation_state == 'Confirmed':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Perfect! Your order has been processed. Please proceed to payment.')
elif intent_name == 'ProcessOrder' and confirmation_state == 'Denied':
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Got it. Let me know if I can help you with something else.')
elif intent_name == 'ProcessOrder' and confirmation_state not in ['Denied','Confirmed','None']:
return close(intent_request['sessionState']['sessionAttributes'],intent_request['sessionState']['intent']['name'],'Fulfilled','Close','Sorry. I am having trouble completing the request. Let me get someone to help you.')
logger.debug('exiting intent {} here'.format(intent_request['sessionState']['intent']['name']))
raise Exception('Intent with name ' + intent_name + ' not supported')
def prompt_bedrock(formatted_template):
logger.debug('prompt bedrock input is:'.format(formatted_template))
body = json.loads(formatted_template)
modelId = 'anthropic.claude-v2' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
response = bedrock.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
response_completion = response_body.get('completion')
logger.debug('response is: {}'.format(response_completion))
#print_ww(response_body.get('completion'))
#print(response_body.get('results')[0].get('outputText'))
return response_completion
#function to extract text between the <Response> and </Response> tags within model completion
def extract_response(response_completion):
if '<Response>' in response_completion:
customer_response = response_completion.replace('<Response>','||').replace('</Response>','').split('||')[1]
logger.debug('modified response is: {}'.format(response_completion))
return customer_response
else:
logger.debug('modified response is: {}'.format(response_completion))
return response_completion
#function to extract text between the <Response> and </Response> tags within model completion
def extract_intent(response_completion):
if '<intent>' in response_completion:
customer_intent = response_completion.replace('<intent>','||').replace('</intent>','||').split('||')[1]
return customer_intent
else:
return customer_intent
def close(session_attributes, intent, fulfillment_state, action_type, message):
#This function prepares the response in the appropiate format for Lex V2
response = {
"sessionState": {
"sessionAttributes":session_attributes,
"dialogAction": {
"type": action_type
},
"intent": {
"name":intent,
"state":fulfillment_state
},
},
"messages":
[{
"contentType":"PlainText",
"content":message,
}]
,
}
return response
- Dołącz do tej funkcji utworzoną wcześniej warstwę Lambda.
- Dodatkowo dołącz warstwę do utworzonych szablonów podpowiedzi.
- W roli wykonawczej Lambda dołącz politykę dostępu do Amazon Bedrock, która została utworzona wcześniej.

Rola wykonawcza Lambda powinna mieć następujące uprawnienia.

Dołącz funkcję Orchestration Lambda do bota Amazon Lex
- Po utworzeniu funkcji w poprzedniej sekcji wróć do konsoli Amazon Lex i przejdź do swojego bota.
- Pod Języki w okienku nawigacji wybierz Angielski.
- W razie zamówieenia projektu Źródło, wybierz bota obsługującego zamówienia.
- W razie zamówieenia projektu Wersja lub alias funkcji lambdawybierz $NAJNOWSZE.
- Dodaj Zapisz.

Utwórz pomocnicze funkcje Lambda
Wykonaj następujące kroki, aby utworzyć dodatkowe funkcje Lambda:
- Utwórz funkcję Lambda, aby wysłać zapytanie do utworzonej wcześniej tabeli DynamoDB:
import json
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# Initialize the DynamoDB client
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('your-table-name')
def calculate_grand_total(input_data):
# Initialize the total price
total_price = 0
try:
# Loop through each item in the input JSON
for item_id, item_data in input_data.items():
item_name = item_data['item'].lower() # Convert item name to lowercase
item_size = item_data['size'].lower() # Convert item size to lowercase
# Query the DynamoDB table for the item based on Item and Size
response = table.get_item(
Key={'Item': item_name,
'Size': item_size}
)
# Check if the item was found in the table
if 'Item' in response:
item = response['Item']
price = float(item['Price'])
total_price += price # Add the item's price to the total
return total_price
except Exception as e:
raise Exception('An error occurred: {}'.format(str(e)))
def lambda_handler(event, context):
try:
# Parse the input JSON from the Lambda event
input_json = json.loads(event)
# Calculate the grand total
grand_total = calculate_grand_total(input_json)
# Return the grand total in the response
return {'statusCode': 200,'body': json.dumps(grand_total)}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps('An error occurred: {}'.format(str(e)))
- Nawiguj do systemu tab w funkcji Lambda i wybierz Uprawnienia.
- Dołącz instrukcję zasad opartą na zasobach, umożliwiającą funkcji Lambda przetwarzania zamówień wywoływanie tej funkcji.
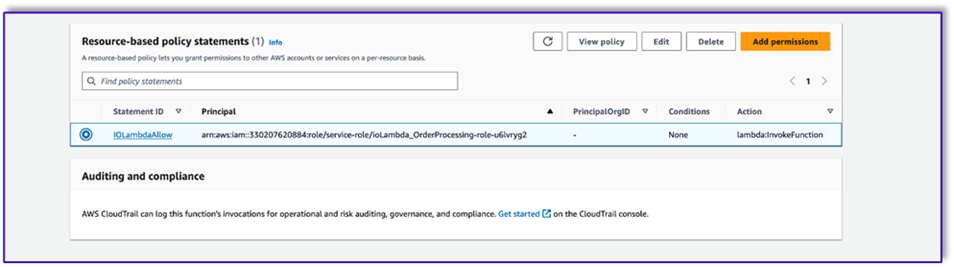
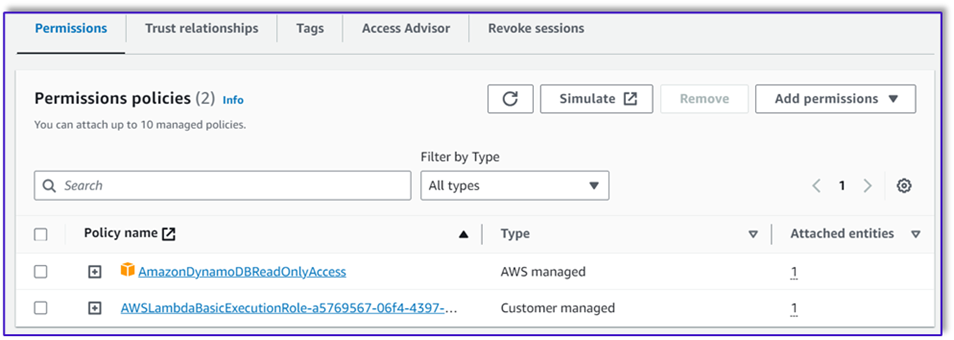
- Przejdź do roli wykonawczej IAM dla tej funkcji Lambda i dodaj politykę dostępu do tabeli DynamoDB.
- Utwórz kolejną funkcję Lambda, aby sprawdzić, czy klient przekazał wszystkie wymagane atrybuty. W poniższym przykładzie sprawdzamy, czy dla zamówienia przechwycono atrybut rozmiaru:
import json
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def lambda_handler(event, context):
# Define customer orders from the input event
customer_orders = json.loads(event)
# Initialize a list to collect error messages
order_errors = {}
missing_size = []
error_messages = []
# Iterate through each order in customer_orders
for order_id, order in customer_orders.items():
if "size" not in order or order["size"] == "":
missing_size.append(order['item'])
order_errors['size'] = missing_size
if order_errors:
items_missing_size = order_errors['size']
error_message = f"could you please provide the size for the following items: {', '.join(items_missing_size)}?"
error_messages.append(error_message)
# Prepare the response message
if error_messages:
response_message = "n".join(error_messages)
return {
'statusCode': 205,
'validator_response': response_message
}
else:
response_message = "Order is validated successfully"
return {
'statusCode': 200,
'validator_response': response_message
}
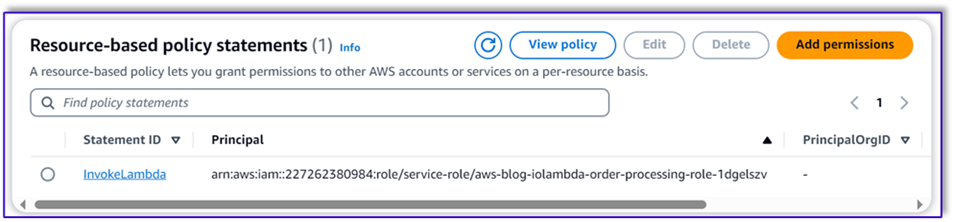
- Nawiguj do systemu tab w funkcji Lambda i wybierz Uprawnienia.
- Dołącz instrukcję zasad opartą na zasobach, umożliwiającą funkcji Lambda przetwarzania zamówień wywoływanie tej funkcji.
Przetestuj rozwiązanie
Teraz możemy przetestować rozwiązanie na przykładowych zamówieniach, które klienci składają za pośrednictwem Amazon Lex.
W naszym pierwszym przykładzie klient poprosił o frappuccino, którego nie ma w menu. Model dokonuje walidacji za pomocą szablonu walidatora zamówień i sugeruje pewne rekomendacje na podstawie menu. Po potwierdzeniu zamówienia Klient otrzymuje informację o kwocie zamówienia i podsumowaniu zamówienia. Zamówienie zostanie zrealizowane na podstawie ostatecznego potwierdzenia przez Klienta.
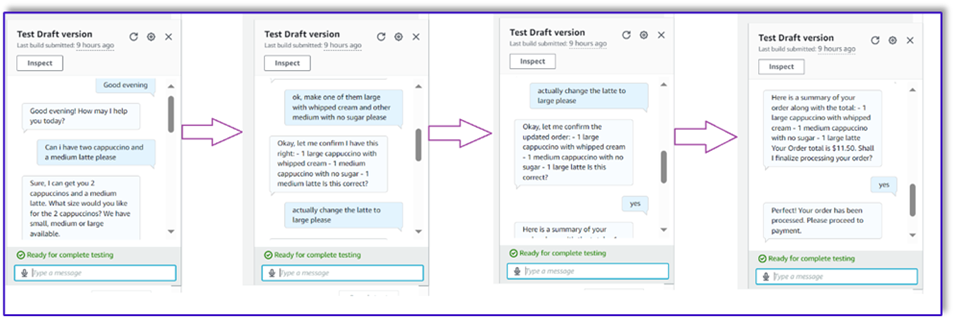
W naszym kolejnym przykładzie klient zamawia duże cappuccino, a następnie zmienia rozmiar z dużego na średni. Model rejestruje wszystkie niezbędne zmiany i prosi klienta o potwierdzenie zamówienia. Model prezentuje sumę zamówienia oraz podsumowanie zamówienia i realizuje zamówienie na podstawie ostatecznego potwierdzenia Klienta.

W naszym ostatnim przykładzie klient złożył zamówienie na wiele artykułów, a w przypadku kilku artykułów brakowało rozmiaru. Model i funkcja Lambda zweryfikują, czy występują wszystkie wymagane atrybuty do realizacji zamówienia, a następnie poproszą klienta o uzupełnienie brakujących informacji. Po uzupełnieniu przez klienta brakujących informacji (w tym przypadku wielkości kawy) wyświetlana jest mu suma zamówienia oraz podsumowanie zamówienia. Zamówienie zostanie zrealizowane na podstawie ostatecznego potwierdzenia przez Klienta.
Ograniczenia LLM
Wyniki LLM są z natury stochastyczne, co oznacza, że wyniki naszego LLM mogą różnić się formatem, a nawet formą nieprawdziwych treści (halucynacji). Dlatego programiści muszą polegać na dobrej logice obsługi błędów w całym kodzie, aby obsłużyć takie scenariusze i uniknąć pogorszenia komfortu użytkownika końcowego.
Sprzątać
Jeśli nie potrzebujesz już tego rozwiązania, możesz usunąć następujące zasoby:
- Funkcje lambda
- Pudełko Amazona Lexa
- Tabela DynamoDB
- Wiadro S3
Dodatkowo zamknij instancję SageMaker Studio, jeśli aplikacja nie jest już potrzebna.
Ocena kosztów
Informacje o cenach głównych usług wykorzystywanych przez to rozwiązanie można znaleźć poniżej:
Pamiętaj, że możesz używać Claude v2 bez konieczności udostępniania, więc ogólne koszty pozostają na minimalnym poziomie. Aby jeszcze bardziej obniżyć koszty, możesz skonfigurować tabelę DynamoDB z ustawieniem na żądanie.
Wnioski
W tym poście pokazano, jak zbudować agenta przetwarzania zamówień AI obsługującego mowę przy użyciu Amazon Lex, Amazon Bedrock i innych usług AWS. Pokazaliśmy, jak szybka inżynieria z potężnym generatywnym modelem sztucznej inteligencji, takim jak Claude, może umożliwić solidne zrozumienie języka naturalnego i przepływ konwersacji na potrzeby przetwarzania zamówień bez konieczności posiadania obszernych danych szkoleniowych.
Architektura rozwiązania wykorzystuje komponenty bezserwerowe, takie jak Lambda, Amazon S3 i DynamoDB, aby umożliwić elastyczną i skalowalną implementację. Przechowywanie szablonów podpowiedzi w Amazon S3 pozwala dostosować rozwiązanie do różnych przypadków użycia.
Kolejne kroki mogą obejmować rozszerzenie możliwości agenta w celu obsługi szerszego zakresu żądań klientów i spraw brzegowych. Szablony podpowiedzi umożliwiają iteracyjne doskonalenie umiejętności agenta. Dodatkowe dostosowania mogą obejmować integrację danych zamówień z systemami zaplecza, takimi jak zapasy, CRM lub POS. Wreszcie agent można udostępnić w różnych punktach kontaktu z klientami, takich jak aplikacje mobilne, punkty typu drive-thru, kioski i inne, korzystając z wielokanałowych możliwości Amazon Lex.
Aby dowiedzieć się więcej, zapoznaj się z następującymi powiązanymi zasobami:
- Wdrażanie i zarządzanie botami wielokanałowymi:
- Szybka inżynieria dla Claude i innych modeli:
- Bezserwerowe wzorce architektoniczne dla skalowalnych asystentów AI:
O autorach
 Mumita Dutta jest architektem rozwiązań partnerskich w Amazon Web Services. Na swoim stanowisku ściśle współpracuje z partnerami w celu opracowania skalowalnych zasobów nadających się do ponownego wykorzystania, które usprawniają wdrożenia w chmurze i zwiększają efektywność operacyjną. Jest członkiem społeczności AI/ML i ekspertem Generative AI w AWS. W wolnym czasie lubi pracować w ogrodzie i jeździć na rowerze.
Mumita Dutta jest architektem rozwiązań partnerskich w Amazon Web Services. Na swoim stanowisku ściśle współpracuje z partnerami w celu opracowania skalowalnych zasobów nadających się do ponownego wykorzystania, które usprawniają wdrożenia w chmurze i zwiększają efektywność operacyjną. Jest członkiem społeczności AI/ML i ekspertem Generative AI w AWS. W wolnym czasie lubi pracować w ogrodzie i jeździć na rowerze.
 Fernando Lammoglii jest architektem rozwiązań partnerskich w Amazon Web Services, blisko współpracującym z partnerami AWS w kierowaniu rozwojem i wdrażaniem najnowocześniejszych rozwiązań AI we wszystkich jednostkach biznesowych. Lider strategiczny posiadający wiedzę specjalistyczną w zakresie architektury chmury, generatywnej sztucznej inteligencji, uczenia maszynowego i analityki danych. Specjalizuje się w realizacji strategii wejścia na rynek i dostarczaniu skutecznych rozwiązań AI dostosowanych do celów organizacji. W wolnym czasie uwielbia spędzać czas z rodziną i podróżować do innych krajów.
Fernando Lammoglii jest architektem rozwiązań partnerskich w Amazon Web Services, blisko współpracującym z partnerami AWS w kierowaniu rozwojem i wdrażaniem najnowocześniejszych rozwiązań AI we wszystkich jednostkach biznesowych. Lider strategiczny posiadający wiedzę specjalistyczną w zakresie architektury chmury, generatywnej sztucznej inteligencji, uczenia maszynowego i analityki danych. Specjalizuje się w realizacji strategii wejścia na rynek i dostarczaniu skutecznych rozwiązań AI dostosowanych do celów organizacji. W wolnym czasie uwielbia spędzać czas z rodziną i podróżować do innych krajów.
 Mitula Patela jest starszym architektem rozwiązań w Amazon Web Services. Pełniąc rolę twórcy technologii chmurowej, współpracuje z klientami, aby zrozumieć ich cele i wyzwania, a także zapewnia wskazówki, jak osiągnąć ich cel dzięki ofercie AWS. Jest członkiem społeczności AI/ML i ambasadorem Generative AI w AWS. W wolnym czasie lubi wędrować i grać w piłkę nożną.
Mitula Patela jest starszym architektem rozwiązań w Amazon Web Services. Pełniąc rolę twórcy technologii chmurowej, współpracuje z klientami, aby zrozumieć ich cele i wyzwania, a także zapewnia wskazówki, jak osiągnąć ich cel dzięki ofercie AWS. Jest członkiem społeczności AI/ML i ambasadorem Generative AI w AWS. W wolnym czasie lubi wędrować i grać w piłkę nożną.

