„Dane znajdują się w centrum każdej aplikacji, procesu i decyzji biznesowej. Kiedy dane są wykorzystywane do poprawy doświadczeń klientów i stymulowania innowacji, mogą prowadzić do rozwoju firmy”
- Swami Śiwasubramanian, wiceprezes ds. baz danych, analityki i uczenia maszynowego w AWS w Dzięki podejściu zerowego ETL AWS pomaga konstruktorom w realizacji analiz w czasie zbliżonym do rzeczywistego.
Klienci z różnych branż w coraz większym stopniu kierują się danymi i chcą zwiększyć przychody, obniżyć koszty i zoptymalizować swoje operacje biznesowe poprzez wdrożenie analiz danych transakcyjnych w czasie zbliżonym do rzeczywistego, zwiększając w ten sposób elastyczność. W oparciu o potrzeby klientów i ich opinie, AWS inwestuje i stale postępuje w kierunku urzeczywistnienia naszej wizji zerowego ETL, tak aby konstruktorzy mogli bardziej skupić się na tworzeniu wartości z danych, zamiast na przygotowywaniu danych do analizy.
Autonomiczne zerowy ETL integracja z Amazonka Przesunięcie ku czerwieni ułatwia przenoszenie danych z punktu do punktu, aby przygotować je do analityki, sztucznej inteligencji (AI) i uczenia maszynowego (ML) przy użyciu Amazon Redshift na petabajtach danych. W ciągu kilku sekund od zapisania danych transakcyjnych utrzymany Bazy danych AWS, zero-ETL bezproblemowo udostępnia dane w Amazon Redshift, eliminując potrzebę budowania i utrzymywania złożonych potoków danych, które wykonują operacje wyodrębniania, przekształcania i ładowania (ETL).
Aby pomóc Ci skoncentrować się na tworzeniu wartości z danych, zamiast inwestować niezróżnicowany czas i zasoby w budowanie i zarządzanie potokami ETL pomiędzy transakcyjnymi bazami danych a hurtowniami danych, oferujemy ogłosił cztery integracje bazy danych AWS o zerowym ETL z Amazon Redshift na AWS re:Invent 2023:
W tym poście przedstawiamy szczegółowe wskazówki, jak rozpocząć korzystanie z analiz operacyjnych w czasie zbliżonym do rzeczywistego przy użyciu narzędzia Integracja Amazon Aurora PostgreSQL z zerowym ETL z Amazon Redshift.
Omówienie rozwiązania
Aby utworzyć integrację o zerowym ETL, należy określić Wersja zgodna z Amazon Aurora PostgreSQL klaster (kompatybilny z PostgreSQL 15.4 i obsługą zerowego ETL) jako źródło i hurtownia danych Redshift jako cel. Integracja replikuje dane ze źródłowej bazy danych do docelowej hurtowni danych.
Należy utworzyć klastry udostępniane przez Aurora PostgreSQL DB w ramach Środowisko podglądu bazy danych Amazon RDS i przesunięcie ku czerwieni udostępniony klaster w wersji zapoznawczej or bezserwerowa grupa robocza podglądu, w regionie AWS East (Ohio) w USA. W przypadku Amazon Redshift upewnij się, że wybrałeś ścieżkę Preview_2023, aby móc korzystać z integracji z zerowym ETL.
Poniższy diagram ilustruje architekturę zaimplementowaną w tym poście.
Poniżej przedstawiono kroki potrzebne do skonfigurowania integracji z zerowym ETL dla tego rozwiązania. Aby zapoznać się z kompletnymi przewodnikami dla początkujących, zobacz Praca z integracją Aurora o zerowym ETL z Amazon Redshift i Praca z integracjami o zerowym ETL.
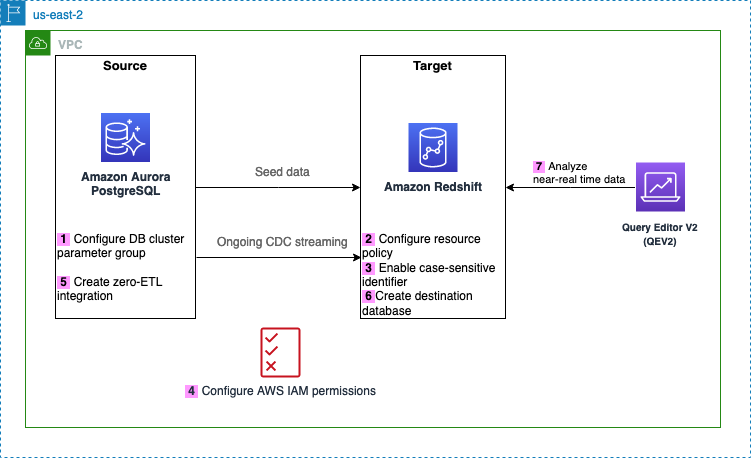
Po kroku 1 możesz także pominąć kroki 2–4 i bezpośrednio rozpocząć tworzenie integracji z zerowym ETL od kroku 5. W takim przypadku Amazon RDS wyświetli komunikat o brakujących konfiguracjach i będziesz mógł wybrać Napraw to dla mnie aby umożliwić Amazon RDS automatyczną konfigurację kroków.
- Skonfiguruj źródło Aurora PostgreSQL za pomocą dostosowanej grupy parametrów klastra DB.
- Skonfiguruj Bezserwerowe Amazon Redshift miejsce docelowe z wymaganą polityką zasobów dla swojej przestrzeni nazw.
- Zaktualizuj grupę roboczą Redshift Serverless, aby włączyć identyfikatory z rozróżnianiem wielkości liter.
- Skonfiguruj wymagane uprawnienia.
- Utwórz integrację zero-ETL.
- Utwórz bazę danych z integracji w Amazon Redshift.
- Rozpocznij analizę danych transakcyjnych w czasie zbliżonym do rzeczywistego.
Skonfiguruj źródło Aurora PostgreSQL za pomocą dostosowanej grupy parametrów klastra DB
W przypadku klastrów Aurora PostgreSQL DB należy utworzyć niestandardową grupę parametrów w pliku Środowisko podglądu bazy danych Amazon RDSw regionie wschodnich Stanów Zjednoczonych (Ohio). Możesz bezpośredni dostęp do środowiska podglądu Amazon RDS.
Aby utworzyć bazę danych Aurora PostgreSQL, wykonaj następujące kroki:
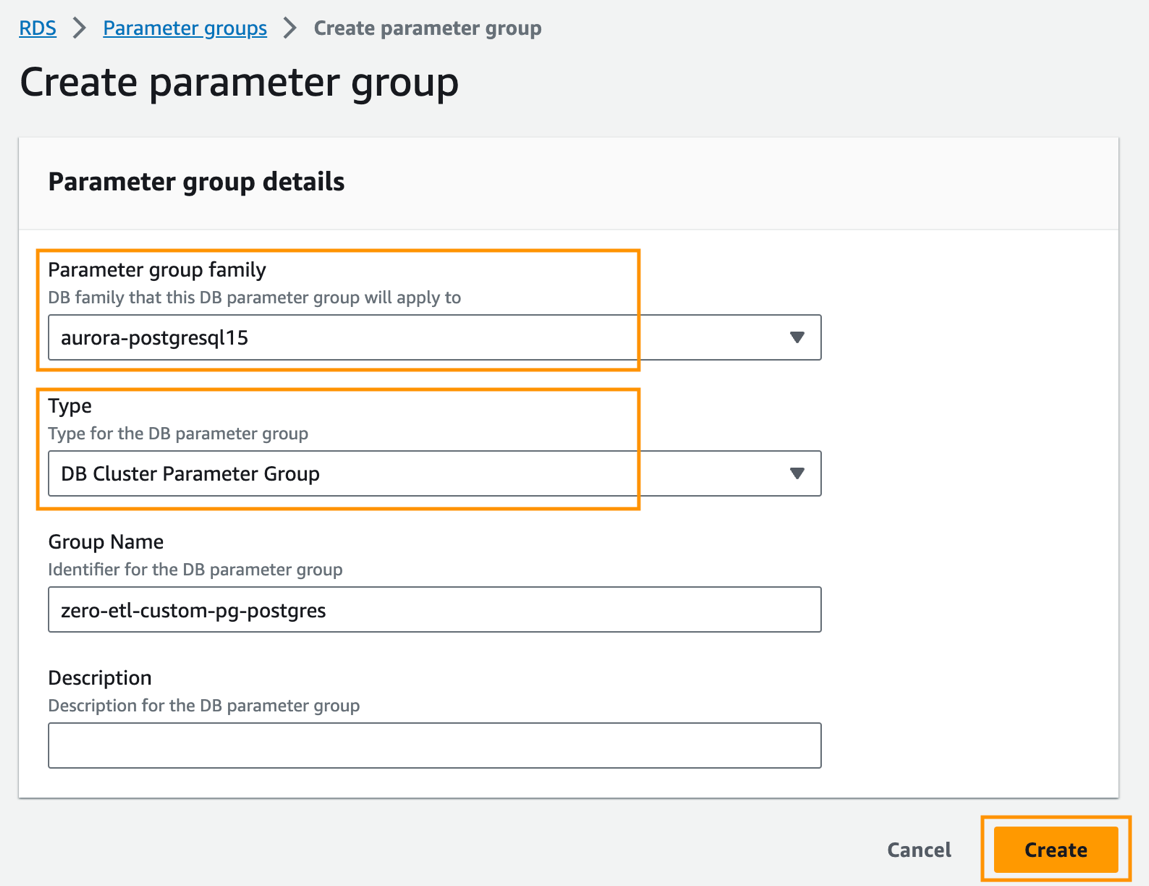
- Na konsoli Amazon RDS wybierz Grupy parametrów w okienku nawigacji.
- Dodaj Utwórz grupę parametrów.
- W razie zamówieenia projektu Rodzina grupy parametrówwybierz
aurora-postgresql15. - W razie zamówieenia projektu Rodzaj Nieruchomościwybierz
DB Cluster Parameter Group. - W razie zamówieenia projektu Nazwa grupywprowadź nazwę (na przykład
zero-etl-custom-pg-postgres). - Dodaj Stwórz.
Integracje Aurora PostgreSQL o zerowym ETL z Amazon Redshift wymagają określonych wartości dla Parametry klastra Aurora DB, co wymaga ulepszonej replikacji logicznej (aurora.enhanced_ological_replication).
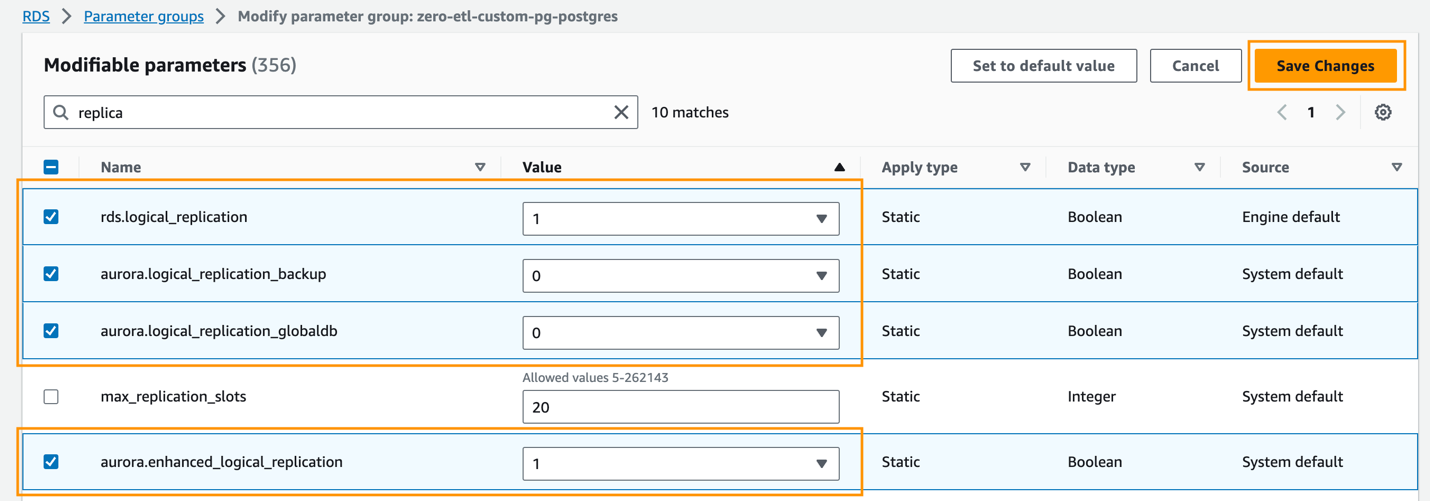
- Na Grupy parametrów wybierz nowo utworzoną grupę parametrów.
- Na Akcje menu, wybierz Edytuj.
- Ustaw następujący kod Aurora PostgreSQL (rodzina aurora-postgresql15) ustawienia parametrów klastra:
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
Włączenie rozszerzonej replikacji logicznej (aurora.enhanced_logiczna_replikacja) automatycznie ustawia parametr REPLICA IDENTITY na FULL, co oznacza, że wszystkie wartości kolumn są zapisywane w dzienniku zapisu z wyprzedzeniem (WAL).
- Dodaj Zapisz zmiany.
- Dodaj Bazy danych w okienku nawigacji, a następnie wybierz Utwórz bazę danych.

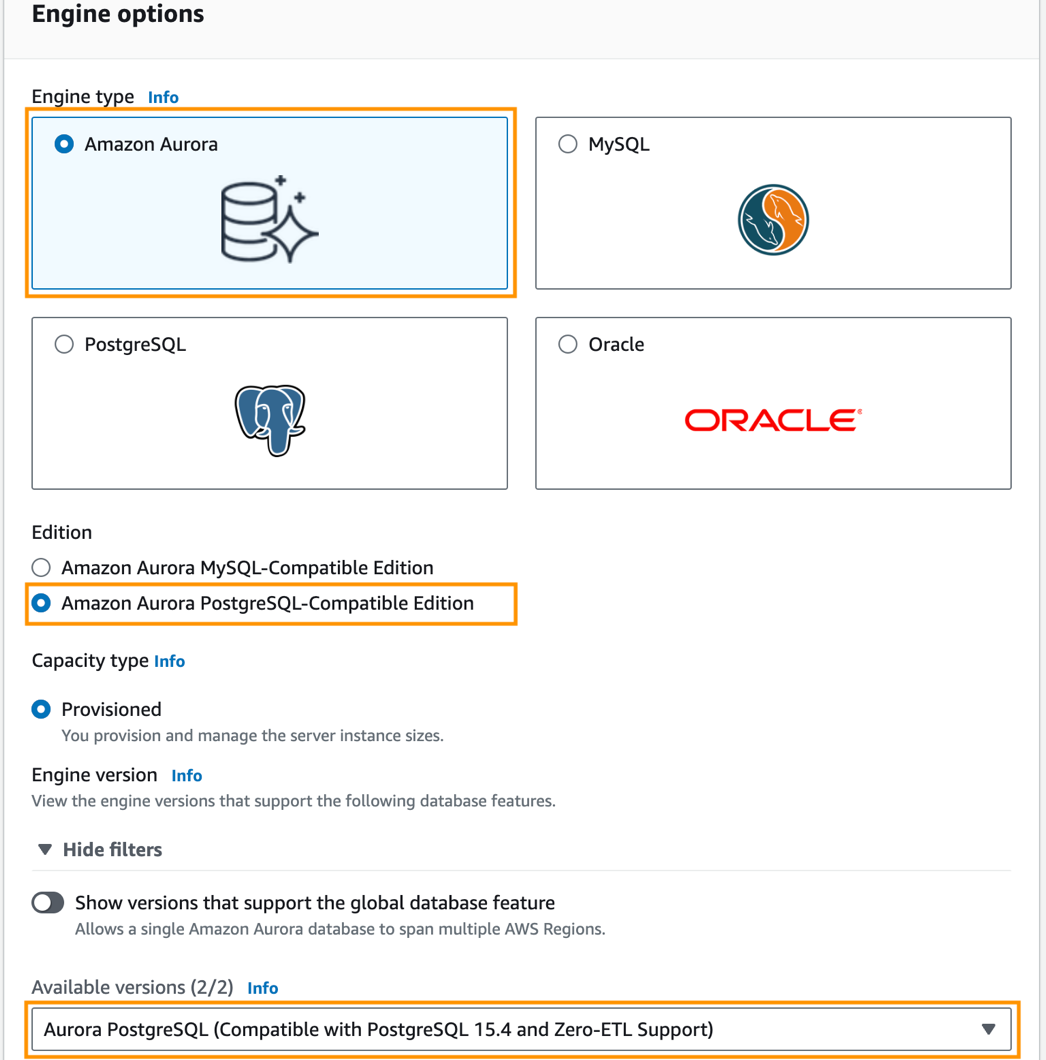
- W razie zamówieenia projektu Typ silnika, Wybierz Amazonka Aurora.
- W razie zamówieenia projektu edycja, Wybierz Wersja zgodna z Amazon Aurora PostgreSQL.
- W razie zamówieenia projektu Dostępne wersjewybierz Aurora PostgreSQL (kompatybilna z PostgreSQL 15.4 i obsługą Zero-ETL).
- W razie zamówieenia projektu Szablony, Wybierz Produkcja.
- W razie zamówieenia projektu Identyfikator klastra bazy danych, wchodzić
zero-etl-source-pg.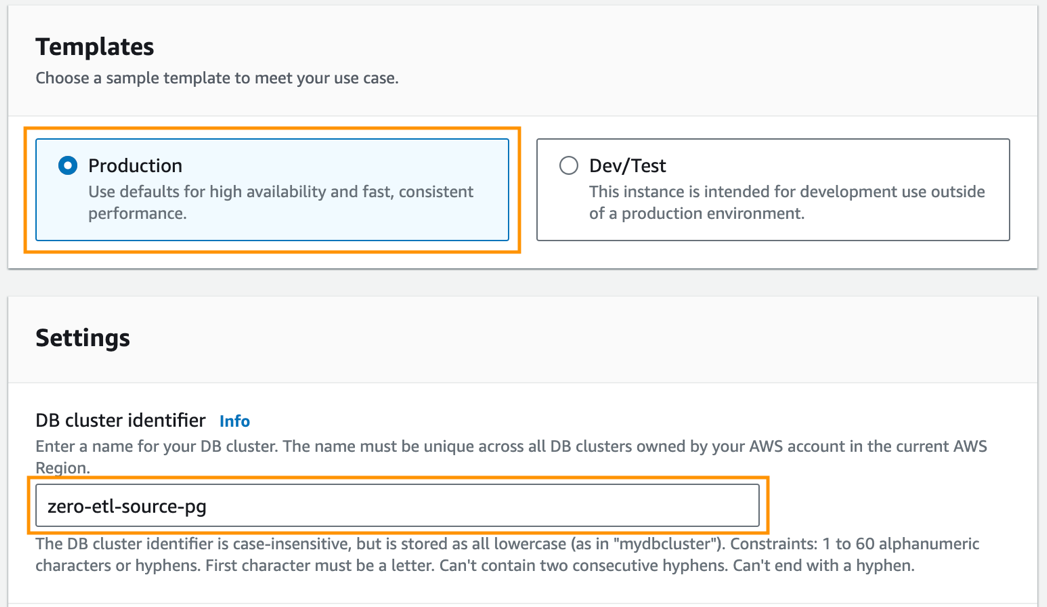
- Pod Ustawienia poświadczeń, wprowadź hasło dla Główne hasło lub skorzystaj z opcji automatycznego wygenerowania hasła.
- W Sekcja konfiguracji instancji, Wybierz Klasy zoptymalizowane pod kątem pamięci.
- Wybierz odpowiedni rozmiar instancji (domyślnie jest to
db.r5.2xlarge).
- Pod Dodatkowa konfiguracja, Dla Grupa parametrów klastra DBwybierz utworzoną wcześniej grupę parametrów (
zero-etl-custom-pg-postgres).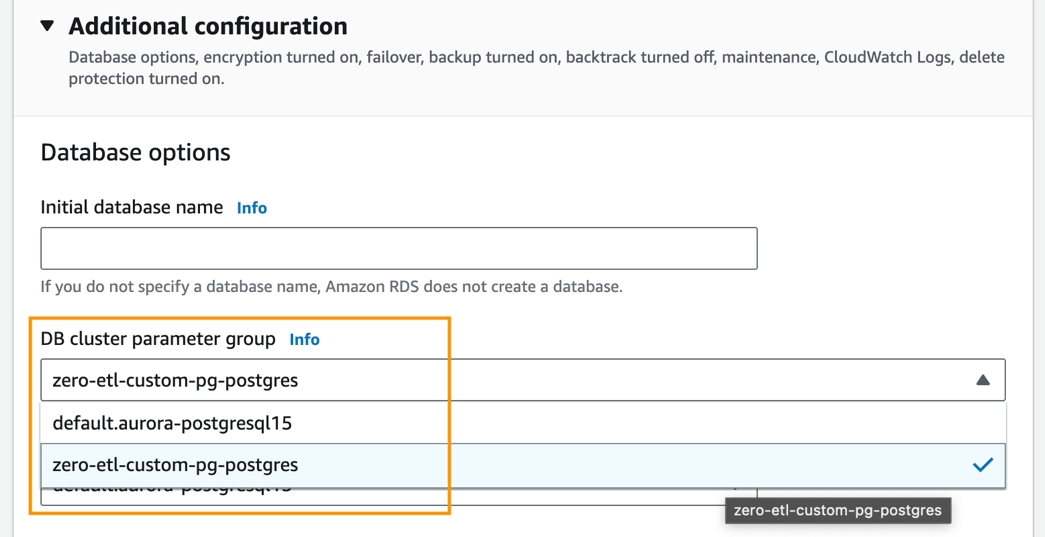
- Dla pozostałych konfiguracji pozostaw ustawienia domyślne.
- Dodaj Utwórz bazę danych.
W ciągu kilku minut powinno to uruchomić klaster Aurora PostgreSQL z jedną instancją piszącą i jedną instancją czytającą, a jego status zmieni się z Tworzenie do Dostępny. Źródłem integracji typu zero-ETL będzie nowo powstały klaster Aurora PostgreSQL.
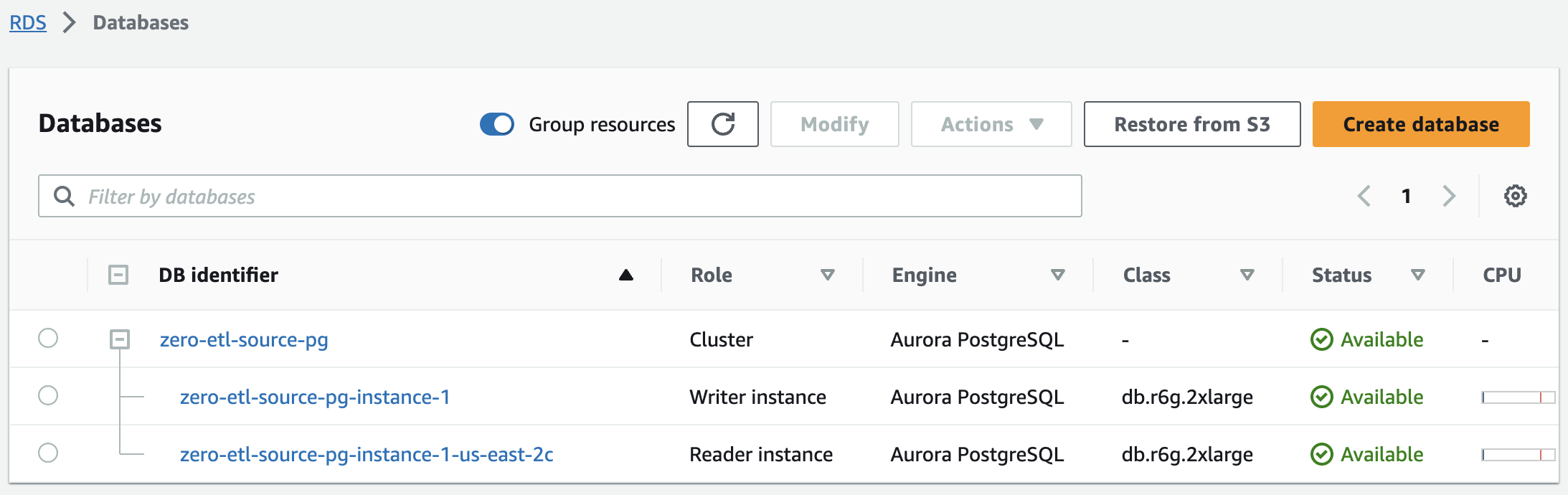
Następnym krokiem jest utworzenie nazwanej bazy danych w Amazon Aurora PostgreSQL na potrzeby integracji zerowej ETL.
Model zasobów PostgreSQL umożliwia tworzenie wielu baz danych w ramach klastra. Dlatego na etapie tworzenia integracji z zerowym ETL musisz określić, której bazy danych chcesz użyć jako źródła integracji.
Konfigurując PostgreSQL, otrzymujesz od razu trzy standardowe bazy danych: szablon0, szablon1 i postgres. Za każdym razem, gdy tworzysz nową bazę danych w PostgreSQL, tak naprawdę opierasz ją na jednej z trzech baz danych w swoim klastrze. Baza danych utworzona podczas tworzenia klastra Aurora PostgreSQL oparta jest na szablonie0. The CREATE DATABASE polecenie działa poprzez kopiowanie istniejącej bazy danych i jeśli nie zostało to wyraźnie określone, domyślnie kopiuje standardowy systemowy szablon bazy danych1. W przypadku nazwanej bazy danych na potrzeby integracji z zerowym ETL baza danych musi zostać utworzona przy użyciu szablonu 1, a nie szablonu 0. Dlatego też, jeśli początkowa nazwa bazy danych zostanie dodana w ramach Dodatkowa konfiguracja, który zostałby utworzony przy użyciu szablonu0 i nie można go użyć do integracji z zerowym ETL.
- Aby utworzyć nową nazwaną bazę danych za pomocą
CREATE DATABASEw nowym klastrze Aurora PostgreSQLzero-etl-source-pgnajpierw pobierz punkt końcowy instancji piszącej klastra PostgreSQL.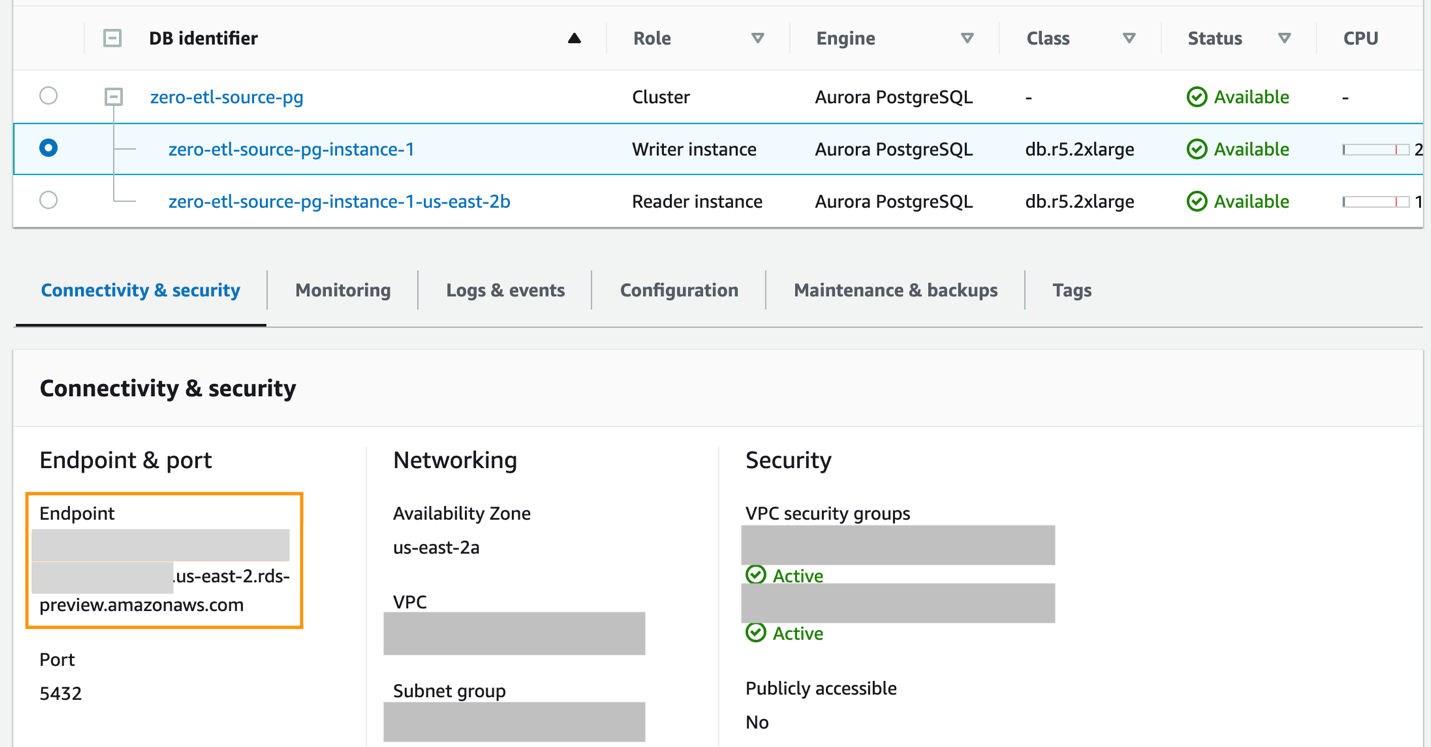
- Z terminala lub za pomocą Chmura AWS, SSH do klastra PostgreSQL i uruchom następujące polecenia, aby zainstalować psql i utworzyć nową bazę danych
zeroetl_db:
Dodawanie template template1 jest opcjonalne, ponieważ domyślnie, jeśli nie jest wspomniane, CREATE DATABASE będzie użyty template1.
Można także połączyć się poprzez klienta i utworzyć bazę danych. Odnosić się do Połącz się z klastrem Aurora PostgreSQL DB aby zapoznać się z opcjami połączenia z klastrem PostgreSQL.
Skonfiguruj Redshift Serverless jako miejsce docelowe
Po utworzeniu klastra źródłowej bazy danych Aurora PostgreSQL należy skonfigurować docelową hurtownię danych Redshift. Hurtownia danych musi spełniać następujące wymagania:
- Utworzono w wersji zapoznawczej (tylko dla źródeł Aurora PostgreSQL)
- Używa typu węzła RA3 (ra3.16xlarge, ra3.4xlarge lub ra3.xlplus) z co najmniej dwoma węzłami lub Redshift Serverless
- Szyfrowane (w przypadku korzystania z udostępnionego klastra)
Na potrzeby tego wpisu tworzymy i konfigurujemy grupę roboczą i przestrzeń nazw Redshift Serverless jako docelową hurtownię danych, wykonując następujące kroki:
- Na konsoli Amazon Redshift wybierz Pulpit nawigacyjny bez serwera w okienku nawigacji.
Ponieważ integracja z zerowym ETL dla Amazon Aurora PostgreSQL z Amazon Redshift została uruchomiona w wersji zapoznawczej (nie do celów produkcyjnych), należy utworzyć docelową hurtownię danych w środowisku podglądu.
- Dodaj Utwórz podgląd grupy roboczej.
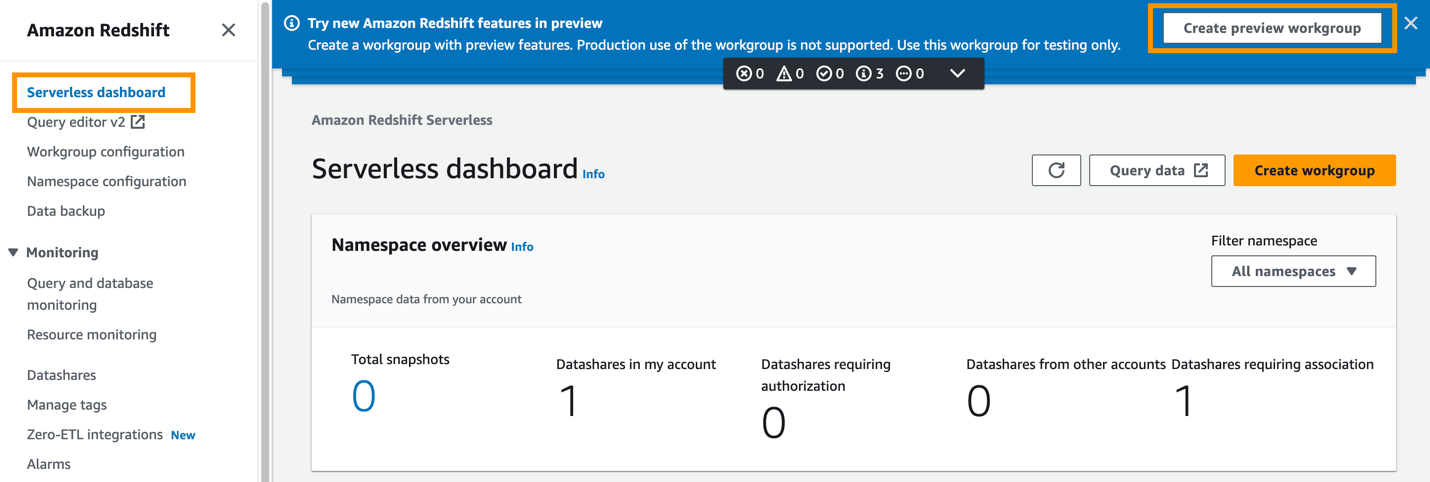
Pierwszym krokiem jest skonfigurowanie grupy roboczej Redshift Serverless.
- W razie zamówieenia projektu Nazwa grupy roboczejwprowadź nazwę (na przykład
zero-etl-target-rs-wg).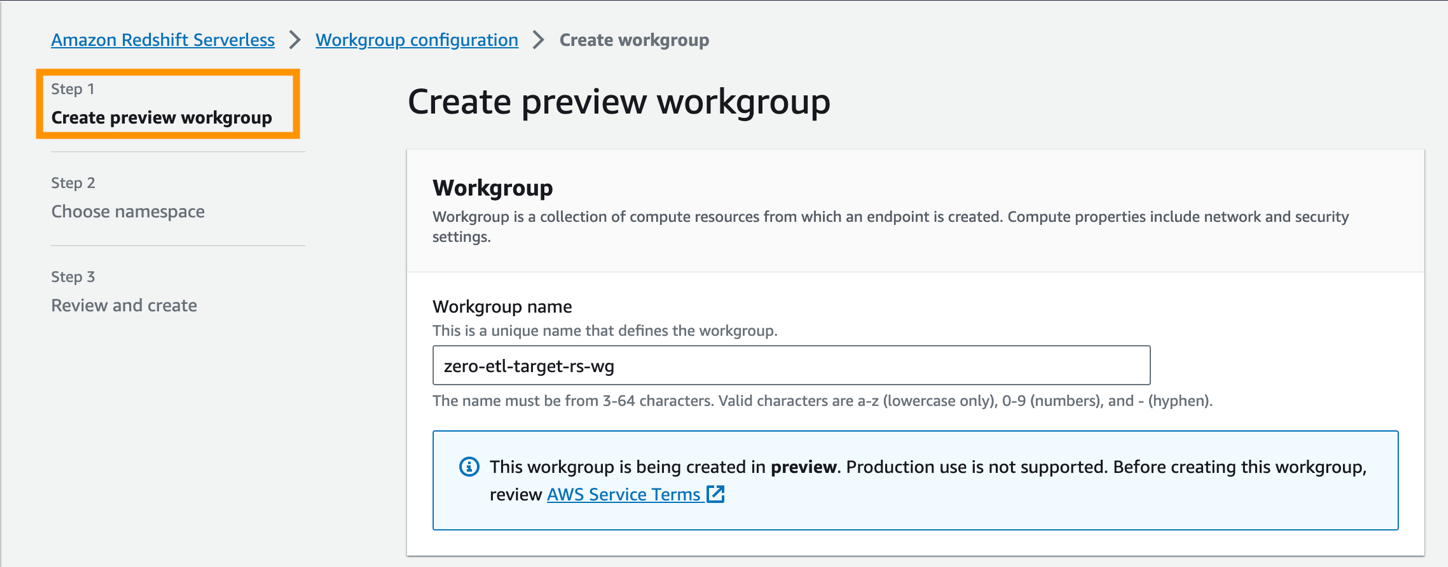
- Dodatkowo możesz wybrać pojemność, aby ograniczyć zasoby obliczeniowe hurtowni danych. Pojemność można konfigurować w przyrostach co 8, od 8 do 512 jednostek RPU. W przypadku tego posta ustaw to na
8RPU. - Dodaj Następna.

Następnie musisz skonfigurować przestrzeń nazw hurtowni danych.
- Wybierz Utwórz nową przestrzeń nazw.
- W razie zamówieenia projektu Przestrzeń nazwwprowadź nazwę (na przykład
zero-etl-target-rs-ns). - Dodaj Następna.
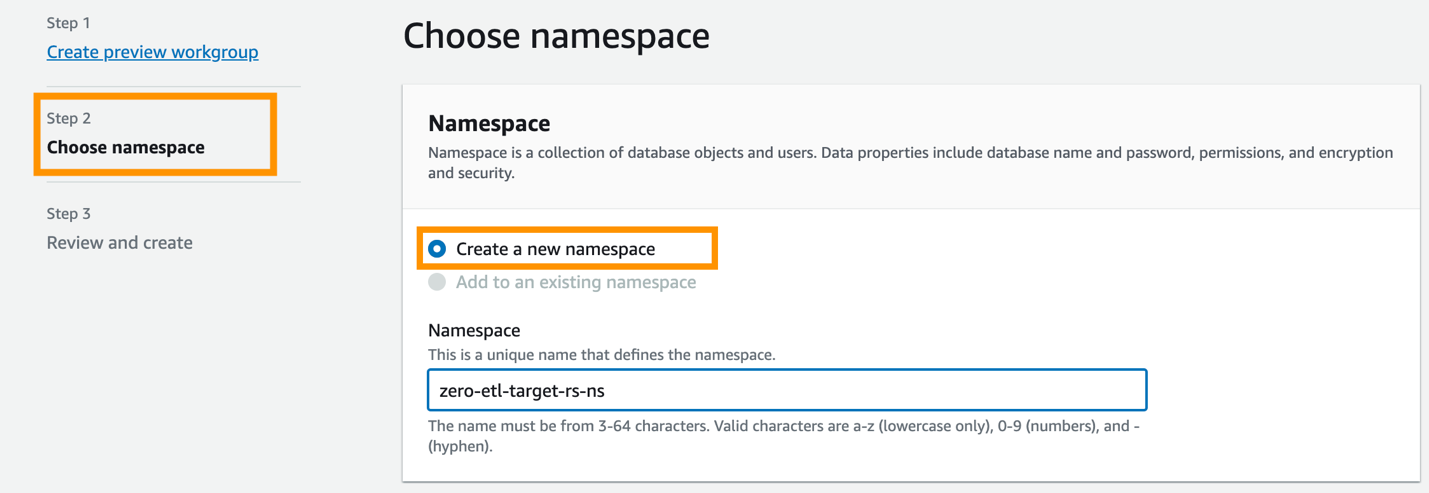
- Dodaj Utwórz grupę roboczą.
- Po utworzeniu grupy roboczej i przestrzeni nazw wybierz Konfiguracje przestrzeni nazw w panelu nawigacji i otwórz konfigurację przestrzeni nazw.
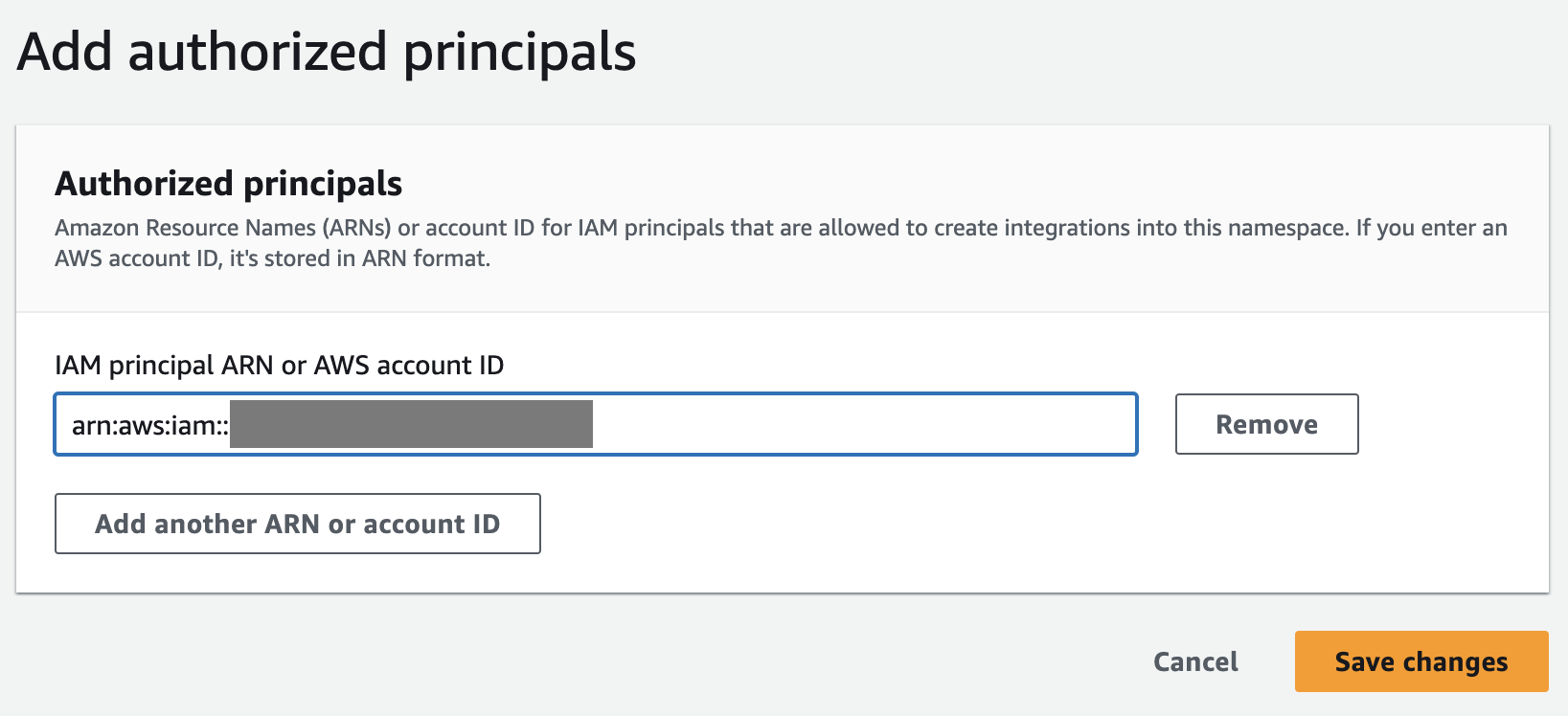
- Na Polityka zasobów kartę, wybierz Dodaj autoryzowane podmioty zabezpieczeń.
Autoryzowany podmiot główny identyfikuje użytkownika lub rolę, która może utworzyć integracje o zerowym ETL z hurtownią danych.

- W razie zamówieenia projektu IAM główny identyfikator konta ARN lub AWS, możesz wprowadzić ARN użytkownika lub roli AWS albo identyfikator konta AWS, któremu chcesz przyznać dostęp w celu tworzenia integracji z zerowym ETL. (Identyfikator konta jest przechowywany jako ARN.)
- Dodaj Zapisz zmiany.
Po skonfigurowaniu autoryzowanego podmiotu zabezpieczeń należy zezwolić źródłowej bazie danych na aktualizację magazynu danych Redshift. Dlatego należy dodać źródłową bazę danych jako autoryzowane źródło integracji do przestrzeni nazw.
- Dodaj Dodaj autoryzowane źródło integracji.
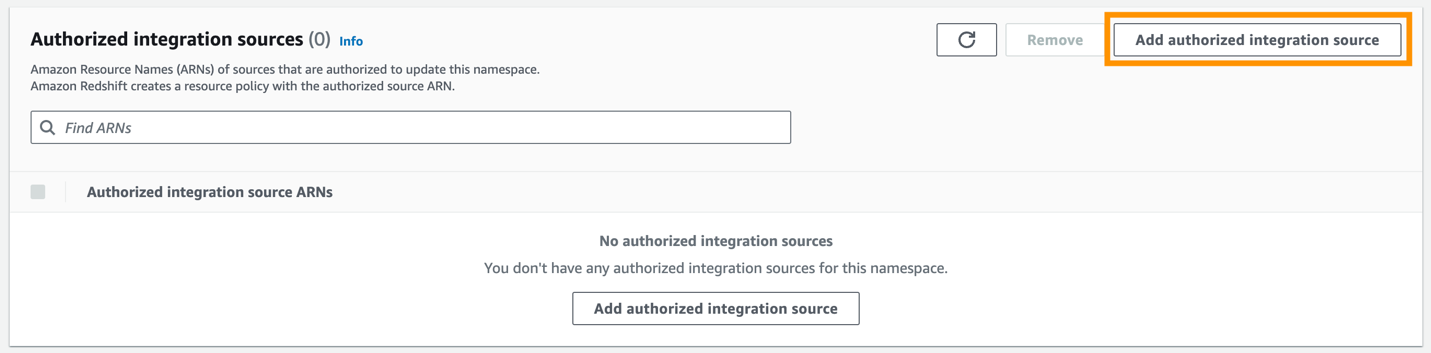
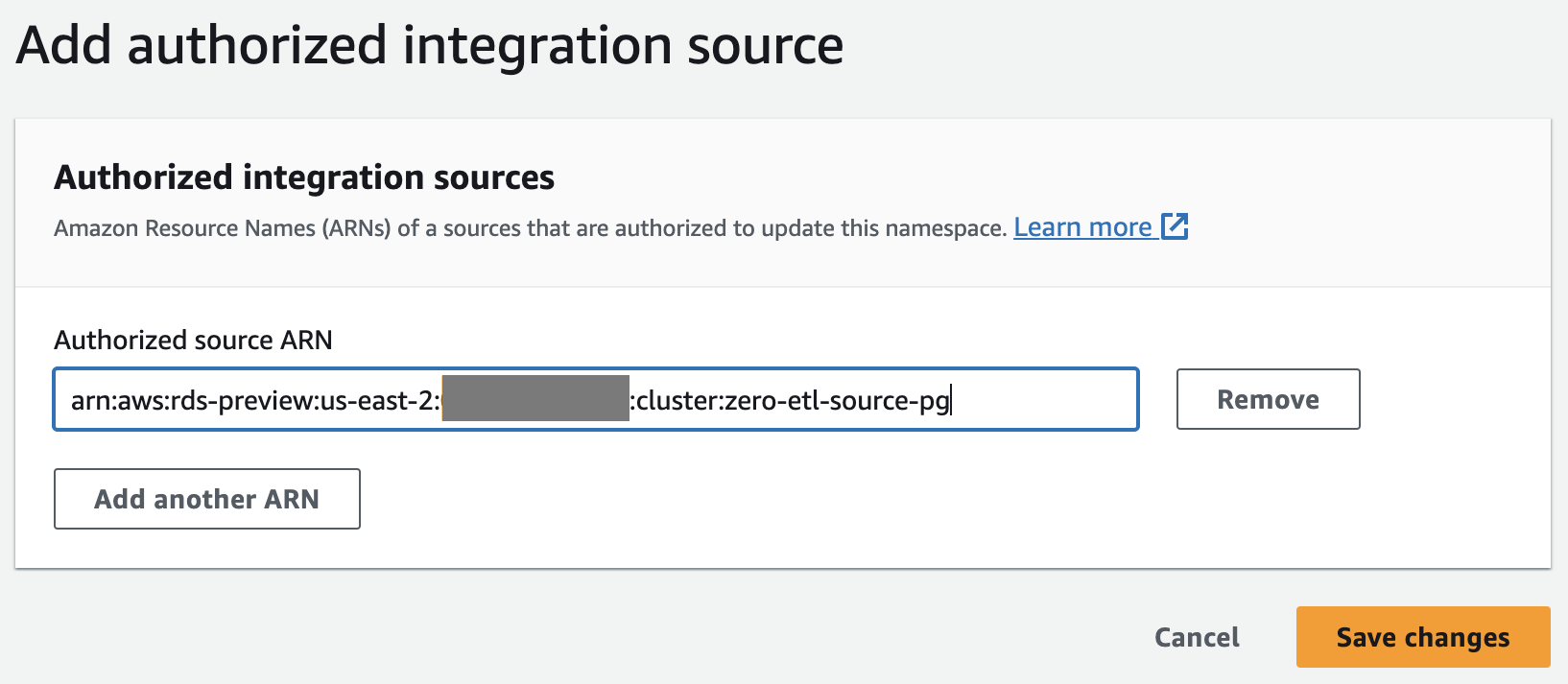
- W razie zamówieenia projektu Autoryzowane źródło ARN, wprowadź ARN klastra Aurora PostgreSQL, ponieważ jest to źródło integracji z zerowym ETL.
Możesz uzyskać ARN klastra Aurora PostgreSQL na konsoli Amazon RDS, systemu Zakładka pod Nazwa zasobu Amazon.
- Dodaj Zapisz zmiany.
Zaktualizuj grupę roboczą Redshift Serverless, aby włączyć identyfikatory z rozróżnianiem wielkości liter
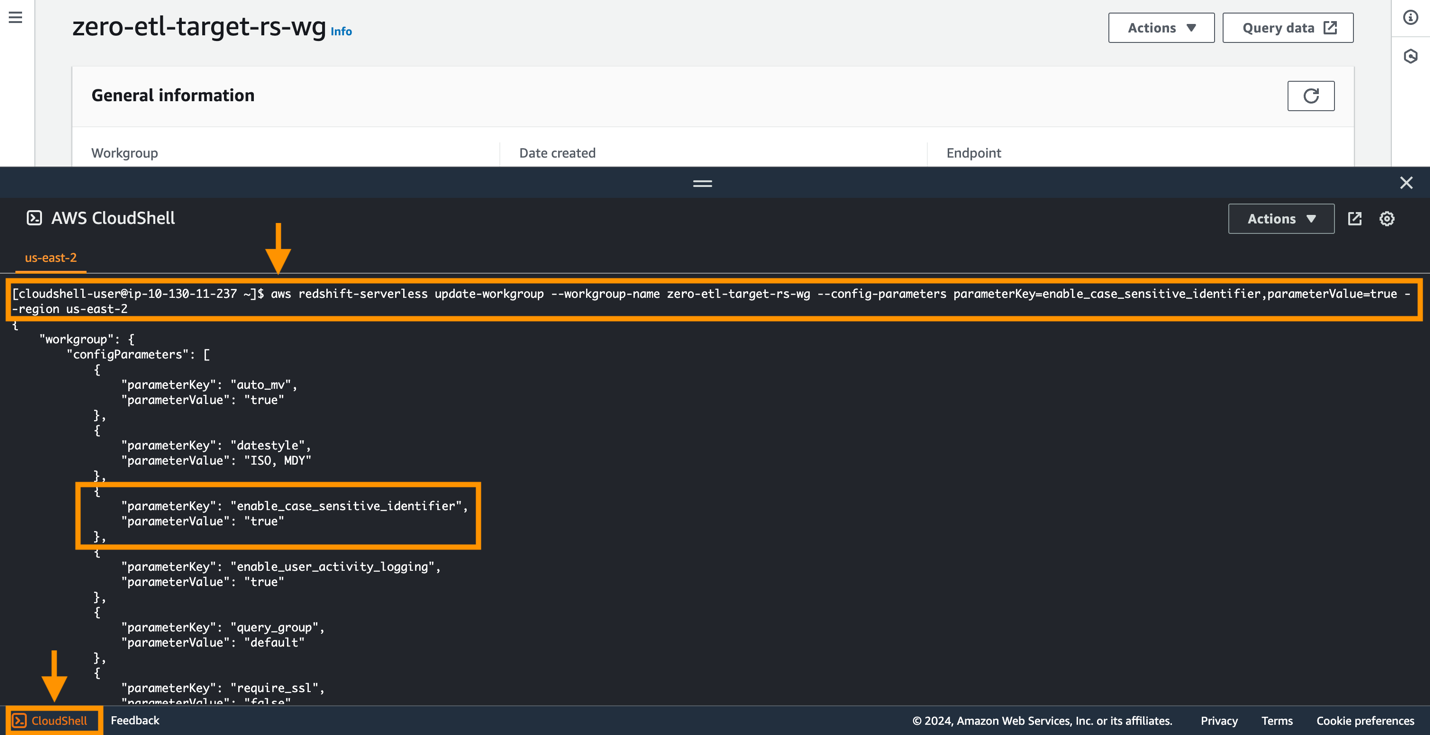
W Amazon Aurora PostgreSQL domyślnie rozróżniana jest wielkość liter, a rozróżnianie wielkości liter jest wyłączone we wszystkich udostępnionych klastrach i grupach roboczych Redshift Serverless. Aby integracja przebiegła pomyślnie, parametr uwzględniania wielkości liter Enable_case_protection_identifier musi być włączona obsługa hurtowni danych.
Aby zmodyfikować enable_case_sensitive_identifier parametru w grupie roboczej Redshift Serverless, należy użyć parametru Interfejs wiersza poleceń AWS (AWS CLI), ponieważ konsola Amazon Redshift nie obsługuje obecnie modyfikowania wartości parametrów Redshift Serverless. Uruchom następujące polecenie, aby zaktualizować parametr:
Prostym sposobem na połączenie się z interfejsem CLI AWS jest użycie CloudShell, czyli powłoki opartej na przeglądarce, która zapewnia dostęp z wiersza poleceń do zasobów i narzędzi AWS bezpośrednio z przeglądarki. Poniższy zrzut ekranu ilustruje sposób uruchomienia polecenia w CloudShell.
Skonfiguruj wymagane uprawnienia
Aby utworzyć integrację typu zero-ETL, użytkownik lub rola muszą mieć dołączony plik polityka oparta na tożsamości z odpowiednim AWS Zarządzanie tożsamością i dostępem (Uprawnienia). Właściciel konta AWS może skonfiguruj wymagane uprawnienia dla użytkowników lub ról, którzy mogą tworzyć integracje o zerowym ETL. Przykładowa zasada umożliwia powiązanemu podmiotowi zabezpieczeń wykonanie następujących czynności:
- Twórz integracje typu zero-ETL dla źródłowego klastra Aurora DB.
- Wyświetl i usuń wszystkie integracje typu zero-ETL.
- Twórz integracje przychodzące do docelowej hurtowni danych. Amazon Redshift ma inny format ARN dla obsługi administracyjnej i bezserwerowej:
- Aprowizowany klaster -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Bezserwerowe -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
To uprawnienie nie jest wymagane, jeśli to samo konto jest właścicielem hurtowni danych Redshift i to konto jest autoryzowanym podmiotem zabezpieczeń dla tej hurtowni danych.
Wykonaj następujące kroki, aby skonfigurować uprawnienia:
- W konsoli IAM wybierz Polityka w okienku nawigacji.
- Dodaj Utwórz politykę.
- Utwórz nową politykę o nazwie rds-integrations, używając następującego kodu JSON. W przypadku wersji zapoznawczej Amazon Aurora PostgreSQL wszystkie ARN i akcje w pliku Środowisko podglądu bazy danych Amazon RDS mieć -preview dołączone do przestrzeni nazw usługi. Dlatego w poniższej polityce zamiast rds należy użyć
rds-preview, Na przykład,rds-preview:CreateIntegration.
- Dołącz utworzoną politykę do uprawnień użytkownika lub roli IAM.
Utwórz integrację zero-ETL
Aby utworzyć integrację typu zero-ETL, wykonaj następujące kroki:
- Na konsoli Amazon RDS wybierz Integracje typu zero-ETL w okienku nawigacji.
- Dodaj Utwórz integrację typu zero-ETL.
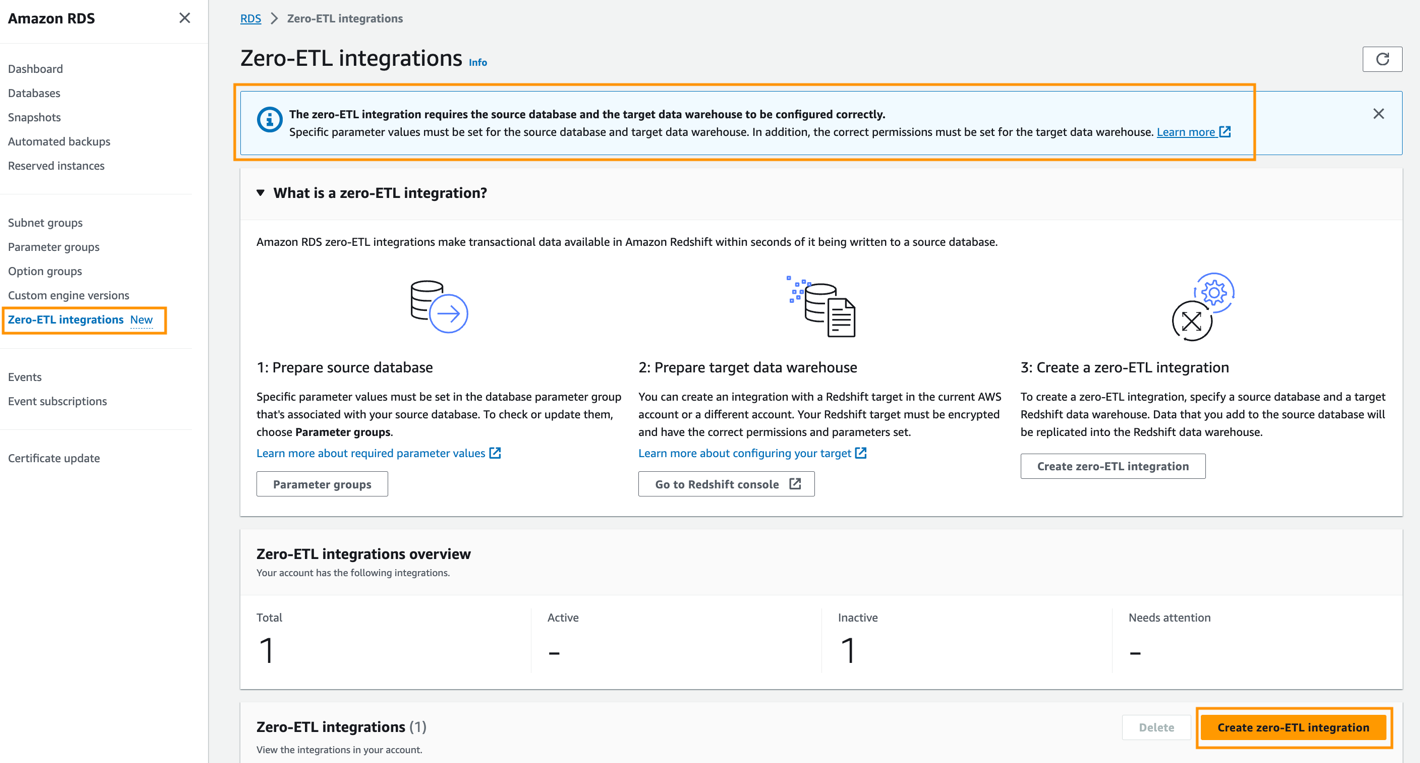
- W razie zamówieenia projektu Identyfikator integracji, wprowadź nazwę, np
zero-etl-demo. - Dodaj Następna.

- W razie zamówieenia projektu Źródłowa baza danychwybierz Przeglądaj bazy danych RDS.
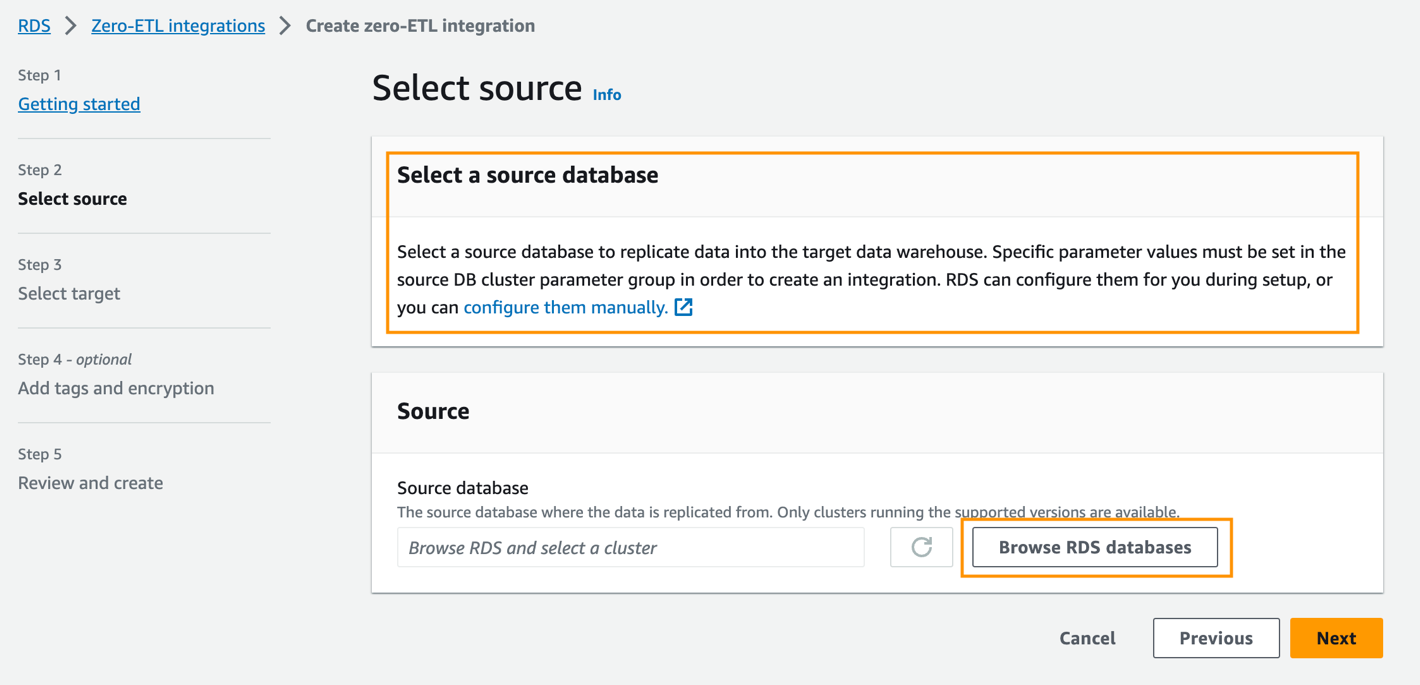
- Wybierz źródłową bazę danych
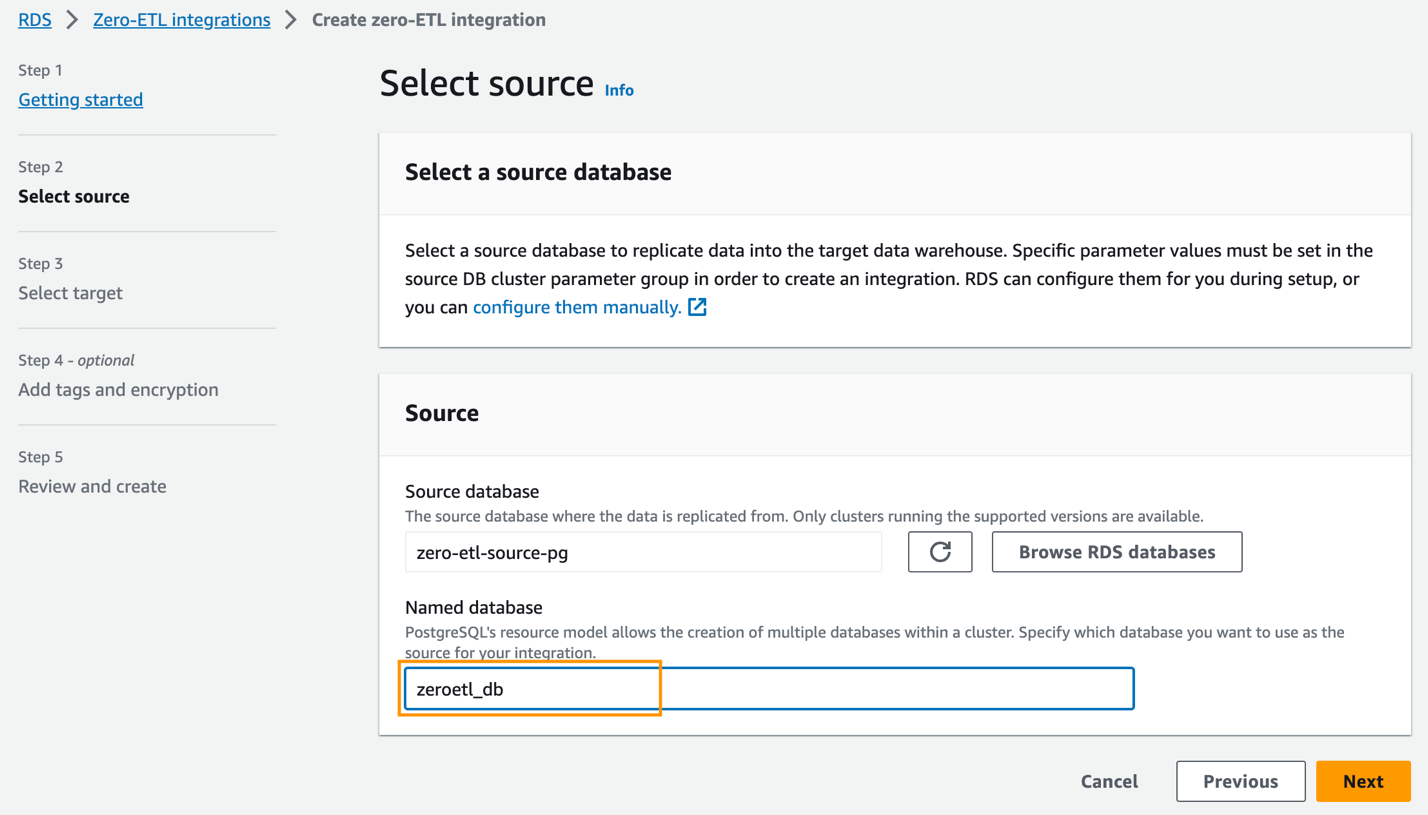
zero-etl-source-pgi wybierz Dodaj. - W razie zamówieenia projektu Nazwana baza danych, wpisz nazwę nowej bazy danych utworzonej w Amazon Aurora PostgreSQL (
zeroetl-db). - Dodaj Następna.
- W Sekcja docelowa, Dla Konto AWS, Wybierz Skorzystaj z rachunku bieżącego.
- W razie zamówieenia projektu Magazyn danych Amazon Redshiftwybierz Przeglądaj hurtownie danych Redshift.

Omawiamy Określ inne konto opcję w dalszej części tej sekcji.
- Wybierz docelową przestrzeń nazw Redshift Serverless (
zero-etl-target-rs-ns) i wybierz Dodaj.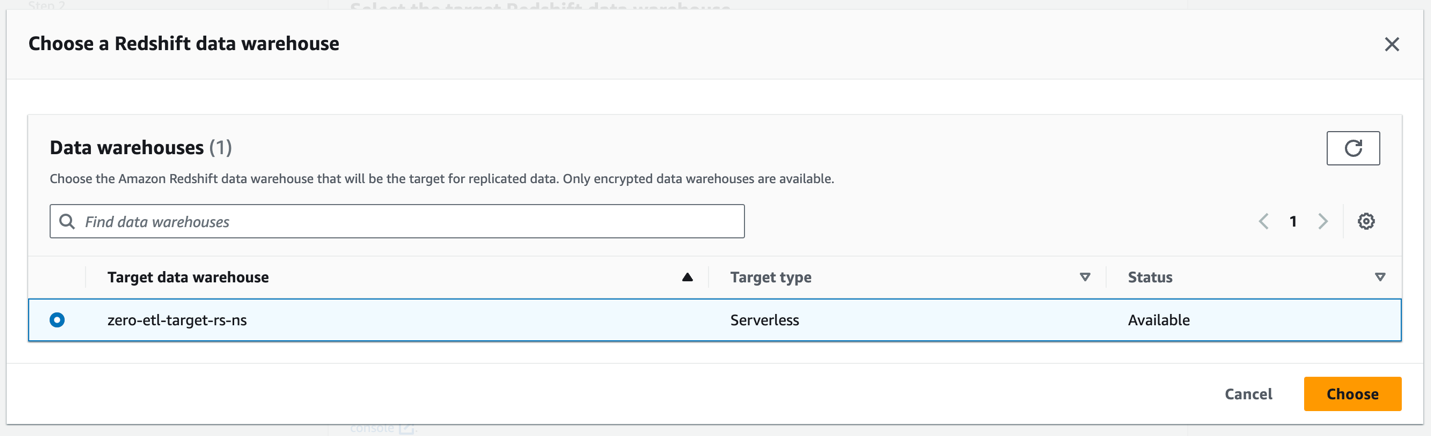
- Dodaj tagi i szyfrowanie, jeśli ma to zastosowanie, i wybierz Dalej.
- Sprawdź nazwę integracji, źródło, cel i inne ustawienia, a następnie wybierz Utwórz integrację typu zero-ETL.
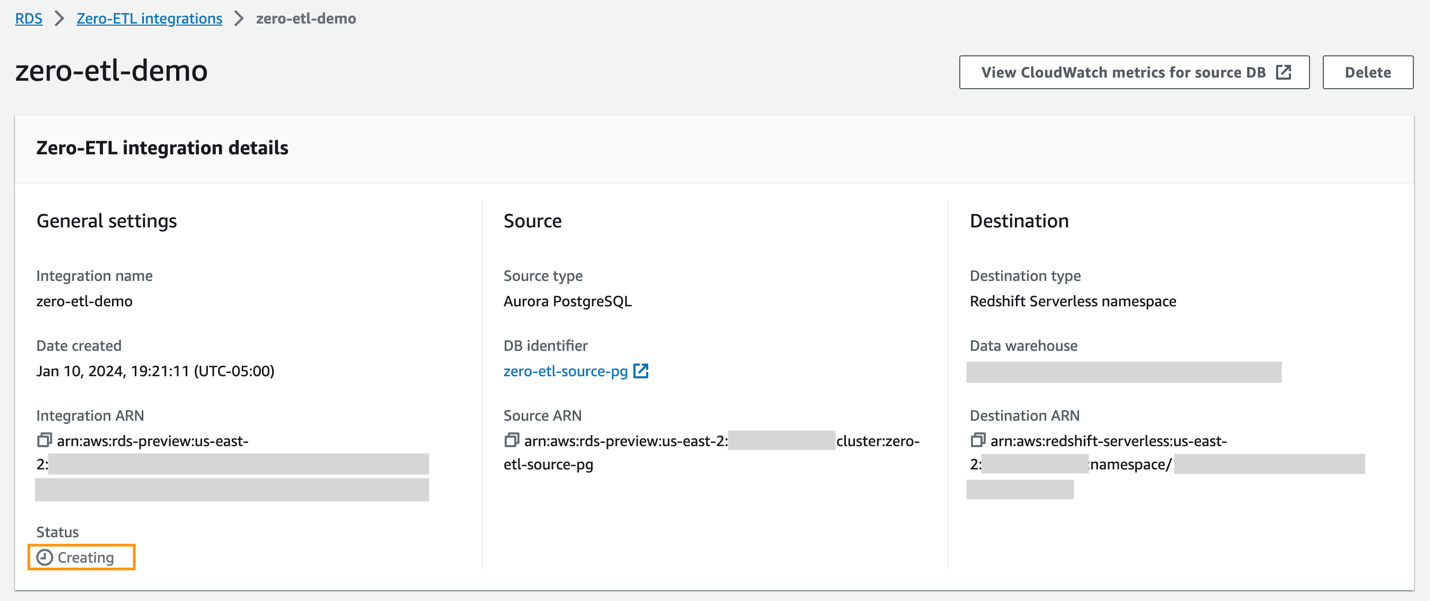
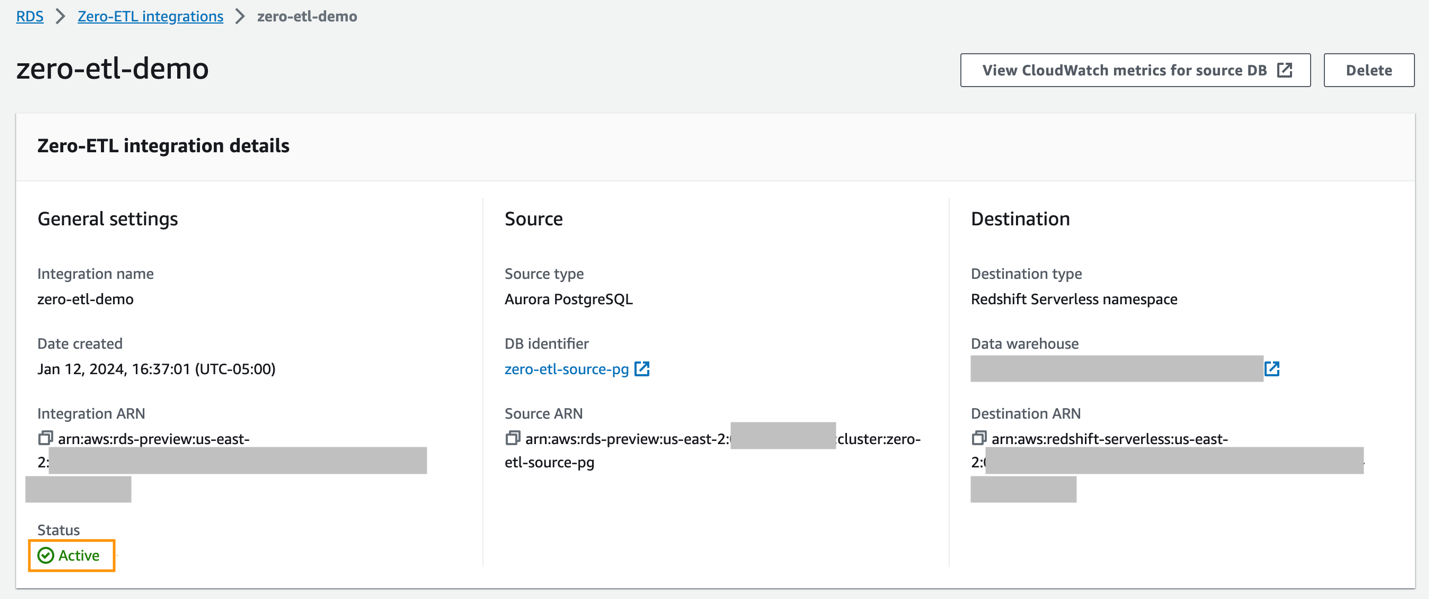
Możesz wybrać integrację na konsoli Amazon RDS, aby zobaczyć szczegóły i monitorować jej postęp. Zmiana statusu z. trwa około 30 minut Tworzenie do Aktywna, w zależności od rozmiaru zbioru danych już dostępnego w źródle.
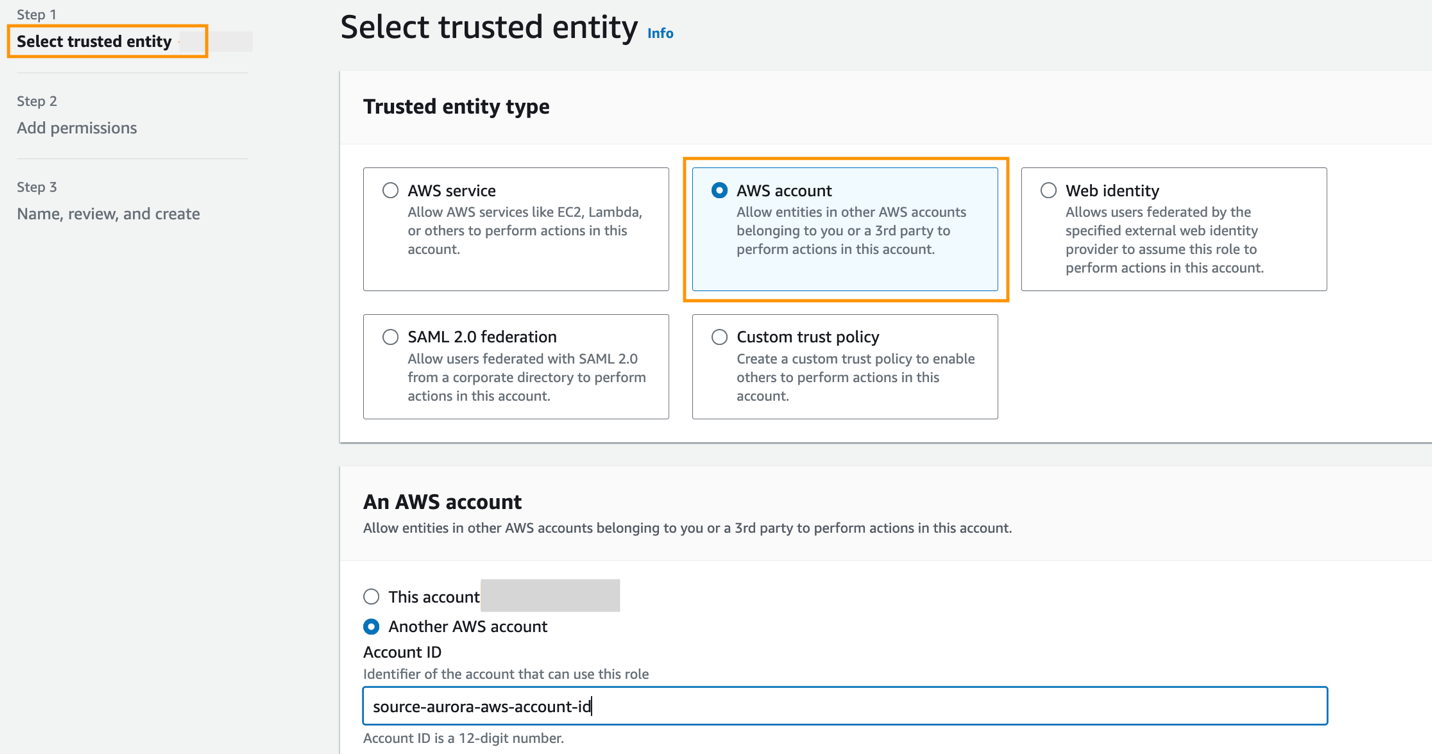
Aby określić docelową hurtownię danych Redshift znajdującą się na innym koncie AWS, musisz utworzyć rolę, która umożliwi użytkownikom bieżącego konta dostęp do zasobów konta docelowego. Aby uzyskać więcej informacji, zobacz Zapewnienie dostępu użytkownikowi IAM na innym koncie AWS, którego jesteś właścicielem.
Utwórz rolę na koncie docelowym z następującymi uprawnieniami:
Rola musi mieć następujące zasady zaufania, które określają identyfikator konta docelowego. Możesz to zrobić, tworząc rolę z zaufanym podmiotem jako identyfikator konta AWS na innym koncie.
Poniższy zrzut ekranu ilustruje tworzenie tego w konsoli IAM.
Następnie, tworząc integrację zerową ETL, dla Określ inne konto, wybierz identyfikator konta docelowego i nazwę utworzonej roli.
Utwórz bazę danych z integracji w Amazon Redshift
Aby utworzyć bazę danych, wykonaj następujące kroki:
- Na pulpicie nawigacyjnym Redshift Serverless przejdź do pliku
zero-etl-target-rs-nsprzestrzeń nazw. - Dodaj Zapytanie o dane aby otworzyć edytor zapytań v2.

- Połącz się z hurtownią danych Redshift Serverless, wybierając Utwórz połączenie.
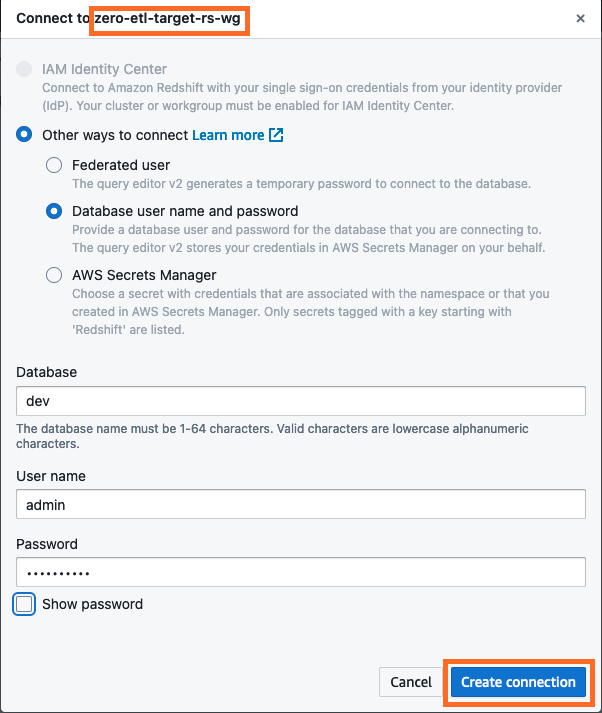
- Uzyskaj
integration_idzsvv_integrationtabela systemowa: - Użyj
integration_idz poprzedniego kroku, aby utworzyć nową bazę danych z integracji. Musisz także dołączyć odwołanie do nazwanej bazy danych w klastrze, którą określiłeś podczas tworzenia integracji.CREATE DATABASE aurora_pg_zetl FROM INTEGRATION '<result from above>' DATABASE zeroetl_db;
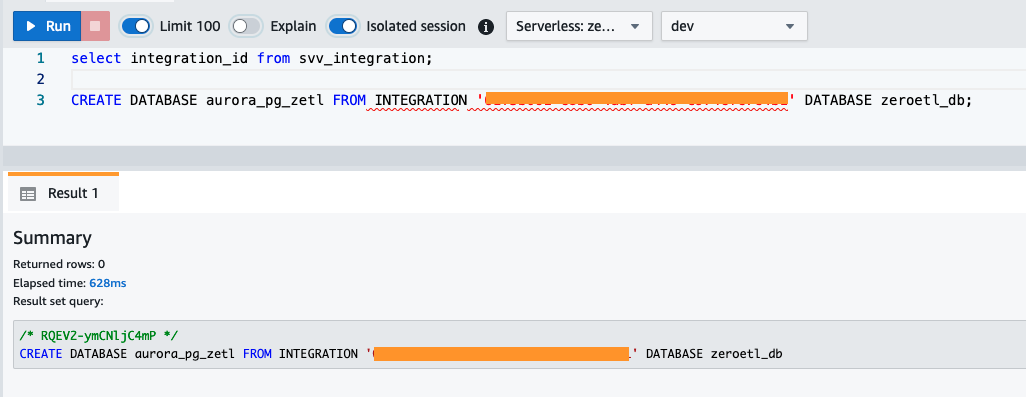
Integracja została zakończona, a cała migawka źródła będzie odzwierciedlać tę samą zawartość, która znajduje się w miejscu docelowym. Bieżące zmiany będą synchronizowane w czasie zbliżonym do rzeczywistego.
Analizuj dane transakcyjne w czasie zbliżonym do rzeczywistego
Teraz możesz rozpocząć analizę danych w czasie zbliżonym do rzeczywistego ze źródła Amazon Aurora PostgreSQL do celu Amazon Redshift:
- Połącz się ze źródłową bazą danych Aurora PostgreSQL. W tym demo używamy Psql aby połączyć się z Amazon Aurora PostgreSQL:

- Utwórz przykładową tabelę z kluczem podstawowym. Upewnij się, że wszystkie tabele, które mają być replikowane ze źródła do celu, mają klucz podstawowy. Tabele bez klucza podstawowego nie mogą być replikowane do miejsca docelowego.
- Wstaw fikcyjne dane do tabeli narodów i sprawdź, czy dane zostały poprawnie załadowane:

Te przykładowe dane powinny teraz zostać zreplikowane w Amazon Redshift.
Przeanalizuj dane źródłowe w miejscu docelowym
Na pulpicie nawigacyjnym Redshift Serverless otwórz edytor zapytań v2 i połącz się z bazą danych aurora_pg_zetl stworzyłeś wcześniej.
Uruchom następujące zapytanie, aby sprawdzić poprawność replikacji danych źródłowych do Amazon Redshift:
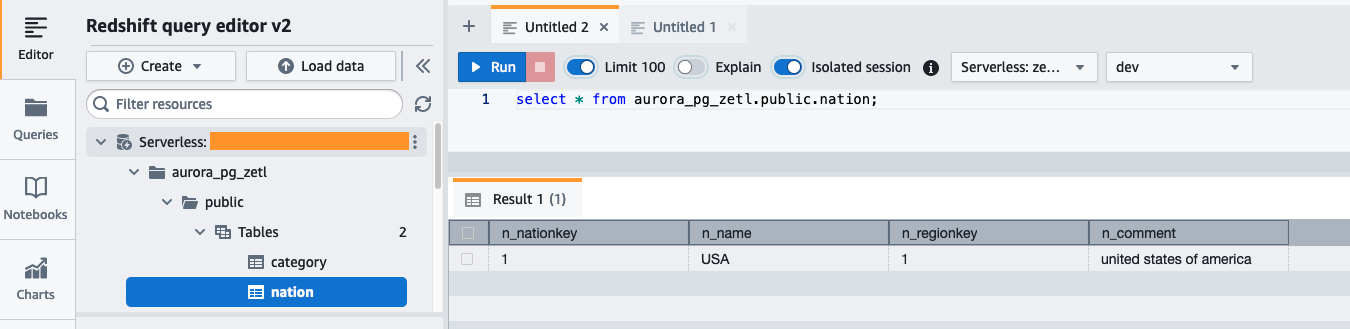
Możesz także użyć następującego zapytania, aby sprawdzić poprawność początkowej migawki lub działania związanego z przechwytywaniem danych o ciągłej zmianie (CDC):
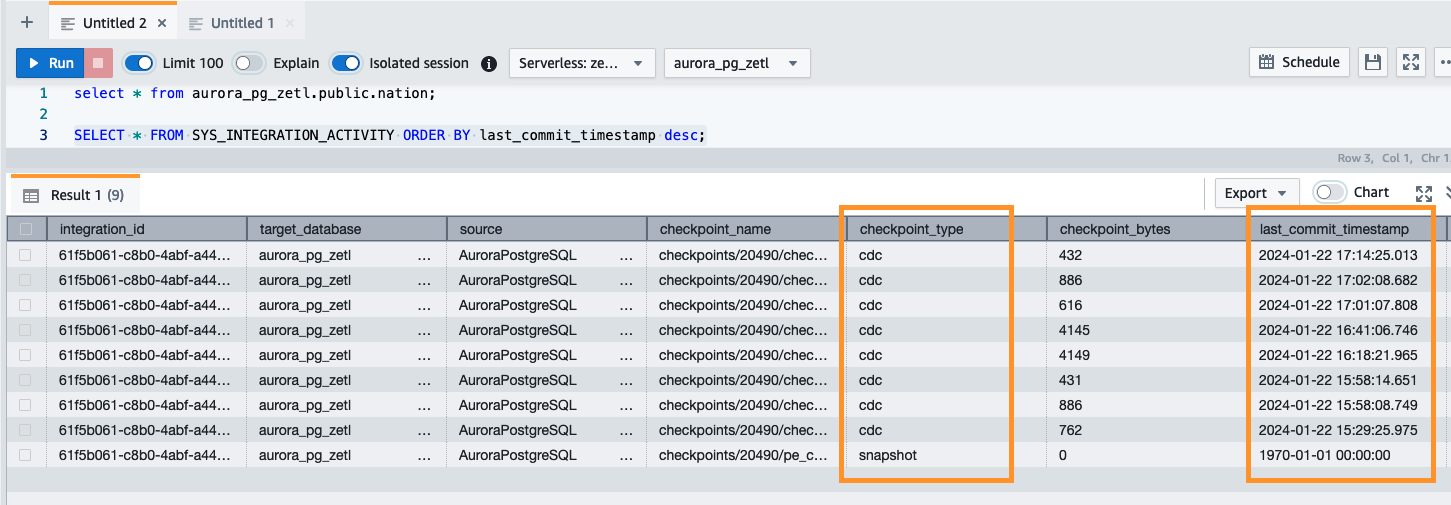
Monitorowanie
Istnieje kilka opcji uzyskania wskaźników dotyczących wydajności i statusu integracji zerowego ETL Aurora PostgreSQL z Amazon Redshift.
Jeśli przejdziesz do konsoli Amazon Redshift, możesz wybrać Integracje typu zero-ETL w panelu nawigacji. Możesz wybrać żądaną integrację z zerowym ETL i wyświetlić ją Amazon Cloud Watch metryki związane z integracją. Te wskaźniki są również dostępne bezpośrednio w CloudWatch.
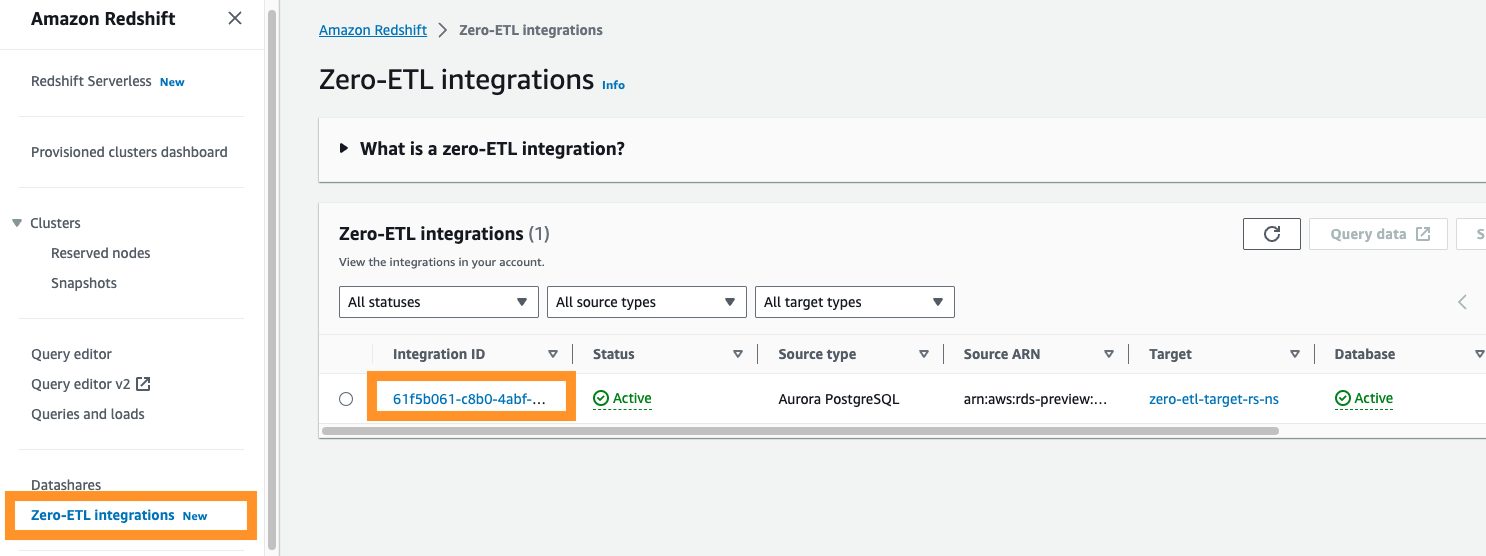
Dla każdej integracji dostępne są dwie zakładki z dostępnymi informacjami:
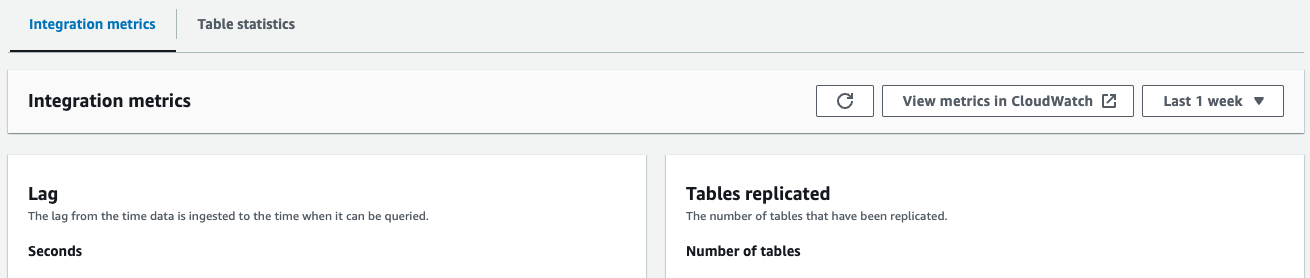
- Metryki integracji – Pokazuje metryki, takie jak liczba pomyślnie zreplikowanych tabel i szczegóły opóźnień
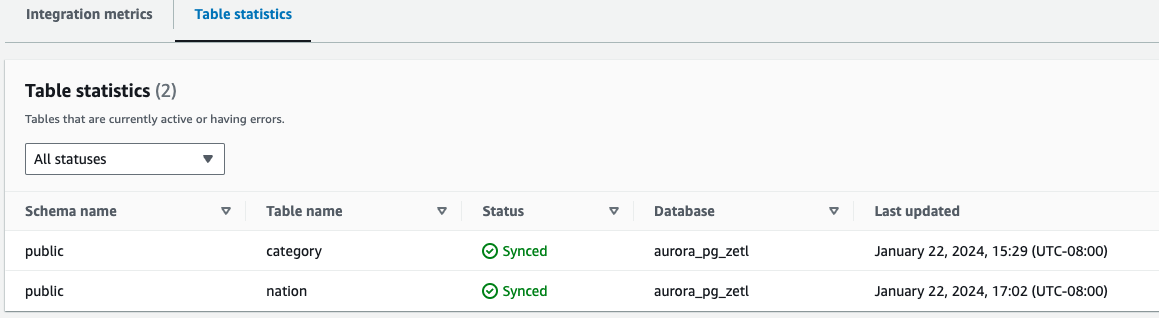
- Statystyki tabeli – Pokazuje szczegółowe informacje na temat każdej tabeli zreplikowanej z Amazon Aurora PostgreSQL do Amazon Redshift
Oprócz metryk CloudWatch możesz wysyłać zapytania dotyczące następujących kwestii widoki systemowe, które dostarczają informacji o integracjach:
Sprzątać
Kiedy usuniesz integrację z zerowym ETL, Twoje dane transakcyjne nie zostaną usunięte z Aurora lub Amazon Redshift, ale Aurora nie będzie wysyłać nowych danych do Amazon Redshift.
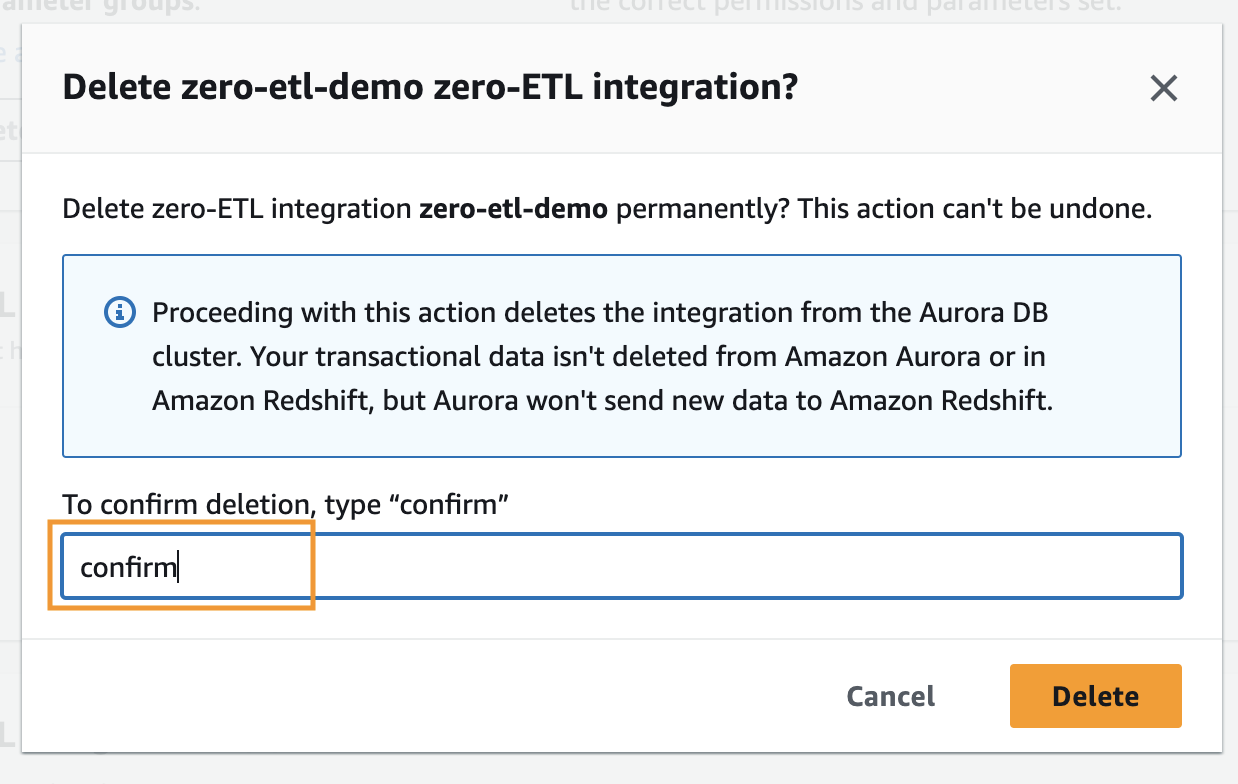
Aby usunąć integrację typu zero-ETL, wykonaj następujące czynności:
- Na konsoli Amazon RDS wybierz Integracje typu zero-ETL w okienku nawigacji.
- Wybierz integrację zero-ETL, którą chcesz usunąć, i wybierz Usuń.

- Aby potwierdzić usunięcie, wpisz potwierdź i wybierz Usuń.
Wnioski
W tym poście wyjaśniliśmy, jak skonfigurować integrację z zerowym ETL z Amazon Aurora PostgreSQL do Amazon Redshift, funkcję, która zmniejsza wysiłek związany z utrzymaniem potoków danych i umożliwia analizę danych transakcyjnych i operacyjnych w czasie zbliżonym do rzeczywistego.
Aby dowiedzieć się więcej na temat integracji zerowej ETL, zobacz Praca z integracją Aurora o zerowym ETL z Amazon Redshift i Ograniczenia.
O autorach
 Raks Khare jest specjalistą ds. analityki w architekturze rozwiązań w AWS z siedzibą w Pensylwanii. Pomaga klientom w architekturze rozwiązań do analityki danych na dużą skalę na platformie AWS.
Raks Khare jest specjalistą ds. analityki w architekturze rozwiązań w AWS z siedzibą w Pensylwanii. Pomaga klientom w architekturze rozwiązań do analityki danych na dużą skalę na platformie AWS.
 Juana Luisa Polo Garzona jest Associate Specialist Solutions Architect w AWS, specjalizującym się w obciążeniach analitycznych. Ma doświadczenie w pomaganiu klientom w projektowaniu, budowaniu i modernizowaniu ich rozwiązań analitycznych w chmurze. Poza pracą lubi podróżować, spędzać czas na świeżym powietrzu i wędrować, a także uczestniczyć w wydarzeniach muzycznych na żywo.
Juana Luisa Polo Garzona jest Associate Specialist Solutions Architect w AWS, specjalizującym się w obciążeniach analitycznych. Ma doświadczenie w pomaganiu klientom w projektowaniu, budowaniu i modernizowaniu ich rozwiązań analitycznych w chmurze. Poza pracą lubi podróżować, spędzać czas na świeżym powietrzu i wędrować, a także uczestniczyć w wydarzeniach muzycznych na żywo.
 Sushmita Barthakur jest starszym architektem rozwiązań w Amazon Web Services i wspiera klientów korporacyjnych w projektowaniu obciążeń w AWS. Dzięki dużemu doświadczeniu w analizie danych i zarządzaniu danymi ma szerokie doświadczenie w pomaganiu klientom w projektowaniu i budowaniu rozwiązań Business Intelligence i Analytics, zarówno lokalnych, jak i w chmurze. Sushmita pochodzi z Tampy na Florydzie i lubi podróżować, czytać i grać w tenisa.
Sushmita Barthakur jest starszym architektem rozwiązań w Amazon Web Services i wspiera klientów korporacyjnych w projektowaniu obciążeń w AWS. Dzięki dużemu doświadczeniu w analizie danych i zarządzaniu danymi ma szerokie doświadczenie w pomaganiu klientom w projektowaniu i budowaniu rozwiązań Business Intelligence i Analytics, zarówno lokalnych, jak i w chmurze. Sushmita pochodzi z Tampy na Florydzie i lubi podróżować, czytać i grać w tenisa.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/achieve-near-real-time-operational-analytics-using-amazon-aurora-postgresql-zero-etl-integration-with-amazon-redshift/

