Wprowadzenie
W tym artykule zostanie przedstawiona koncepcja modelowania danych – kluczowego procesu opisującego sposób przechowywania, organizacji i dostępu do danych w bazie danych lub systemie danych. Polega na przekształceniu rzeczywistych potrzeb biznesowych w logiczny i ustrukturyzowany format, który można zrealizować w bazie danych lub hurtowni danych. Zbadamy, w jaki sposób modelowanie danych tworzy ramy koncepcyjne umożliwiające zrozumienie relacji i wzajemnych powiązań danych w organizacji lub określonej domenie. Ponadto omówimy znaczenie projektowania struktur i relacji danych w celu zapewnienia wydajnego przechowywania, wyszukiwania i manipulowania danymi.

Przypadki użycia modelowania danych
Modelowanie danych ma fundamentalne znaczenie dla skutecznego zarządzania danymi i ich wykorzystywania w różnych scenariuszach. Oto kilka typowych przypadków użycia modelowania danych, każdy szczegółowo wyjaśniony:
Gromadzenie danych
W modelowaniu danych pozyskiwanie danych polega na określeniu sposobu gromadzenia lub generowania danych z różnych źródeł. Ta faza obejmuje ustalenie niezbędnej struktury danych do przechowywania przychodzących danych, zapewniając ich skuteczną integrację i przechowywanie. Modelując dane na tym etapie, organizacje mogą mieć pewność, że zebrane dane będą uporządkowane tak, aby odpowiadały ich potrzebom analitycznym i procesom biznesowym. Pomaga określić rodzaj potrzebnych danych, format, w jakim powinny być oraz sposób, w jaki będą przetwarzane do dalszego wykorzystania.
Ładowanie danych
Po pobraniu danych należy je załadować do systemu docelowego, np. bazy danych, hurtownia danychlub jezioro danych. Kluczową rolę odgrywa tu modelowanie danych poprzez zdefiniowanie schematu lub struktury, do której dane zostaną wstawione. Obejmuje to określenie sposobu, w jaki dane z różnych źródeł będą mapowane na tabele i kolumny bazy danych oraz konfigurowanie relacji między różnymi jednostkami danych. Właściwe modelowanie danych zapewnia optymalne ładowanie danych, ułatwiając wydajne przechowywanie, dostęp i wydajność zapytań.
Kalkulacja biznesowa
Modelowanie danych jest integralną częścią tworzenia ram obliczeń biznesowych. Obliczenia te generują szczegółowe informacje, metryki i kluczowe wskaźniki wydajności (KPI) na podstawie przechowywanych danych. Ustanawiając przejrzysty model danych, organizacje mogą określić, w jaki sposób dane z różnych źródeł mogą być agregowane, przekształcane i analizowane w celu wykonywania złożonych obliczeń biznesowych. Gwarantuje to, że dane bazowe wspierają wyprowadzenie znaczących i dokładnych business intelligence, które mogą pomóc w podejmowaniu decyzji i planowaniu strategicznym.
Dystrybucja
Faza dystrybucji udostępnia przetworzone dane użytkownikom końcowym lub innym systemom w celu analizy, raportowania i podejmowania decyzji. Modelowanie danych na tym etapie koncentruje się na zapewnieniu, że dane są uporządkowane i sformatowane w sposób dostępny i zrozumiały dla docelowej grupy odbiorców. Może to obejmować modelowanie danych w schematy wymiarowe do wykorzystania w narzędziach analizy biznesowej, tworzenie interfejsów API umożliwiających dostęp programowy lub definiowanie formatów eksportu do udostępniania danych. Skuteczne modelowanie danych gwarantuje, że dane mogą być łatwo dystrybuowane i wykorzystywane na różnych platformach i przez różnych interesariuszy, zwiększając ich użyteczność i wartość.
Każdy z tych przypadków użycia ilustruje znaczenie w całym cyklu życia danych, od gromadzenia i przechowywania po analizę i dystrybucję. Starannie projektując struktury danych i relacje na każdym etapie, organizacje mogą mieć pewność, że ich architektura danych skutecznie i efektywnie wspiera ich potrzeby operacyjne i analityczne.
Inżynierowie danych/modelerzy
Inżynierowie danych oraz modelarze danych odgrywają kluczową rolę w zarządzaniu i analizie danych, a każdy z nich wnosi unikalne umiejętności i wiedzę specjalistyczną, aby wykorzystać moc danych w organizacji. Wzajemne zrozumienie ról i obowiązków innych osób może pomóc w wyjaśnieniu, w jaki sposób współpracują przy tworzeniu i utrzymywaniu solidnych infrastruktur danych.
Inżynierowie danych
Inżynierowie danych są odpowiedzialni za projektowanie, budowę i utrzymanie systemów i architektur, które pozwalają na efektywną obsługę i dostępność danych. Ich rola często polega na:
- Budowanie i utrzymywanie potoków danych: Tworzą infrastrukturę do wydobywania, przekształcania i ładowania danych (ETL) z różnych źródeł.
- Przechowywanie i zarządzanie danymi: Projektują i wdrażają systemy baz danych, jeziora danych i inne rozwiązania do przechowywania danych, aby zapewnić porządek i dostępność danych.
- Optymalizacja wydajności: Inżynierowie danych pracują nad zapewnieniem wydajnego działania procesów danych, często poprzez optymalizację przechowywania danych i wykonywania zapytań.
- Współpraca z interesariuszami: Ściśle współpracują z analitykami biznesowymi, analitykami danych i innymi użytkownikami, aby zrozumieć potrzeby w zakresie danych i wdrożyć rozwiązania umożliwiające podejmowanie decyzji w oparciu o dane.
- Zapewnienie jakości i integralności danych: Wdrażają systemy i procesy monitorowania, walidacji i czyszczenia danych, zapewniając użytkownikom dostęp do rzetelnych i dokładnych informacji.
Modelarze danych
Osoby zajmujące się modelowaniem danych skupiają się na projektowaniu planu systemy zarządzania danymi. Ich praca polega na zrozumieniu wymagań biznesowych i przełożeniu ich na struktury danych, które wspierają wydajne przechowywanie, wyszukiwanie i analizę danych. Kluczowe obowiązki obejmują:
- Opracowywanie koncepcyjnych, logicznych i fizycznych modeli danych: Tworzą modele, które definiują, w jaki sposób dane są ze sobą powiązane i w jaki sposób będą przechowywane w bazach danych.
- Definiowanie jednostek danych i relacji: Osoby zajmujące się modelowaniem danych identyfikują kluczowe encje, które system danych organizacji musi reprezentować, i definiują, w jaki sposób te encje są ze sobą powiązane.
- Zapewnienie spójności i standaryzacji danych: Ustalają konwencje nazewnictwa i standardy elementów danych, aby zapewnić spójność w całej organizacji.
- Współpraca z inżynierami i architektami danych: Modelarze danych ściśle współpracują z inżynierami danych, aby zapewnić, że architektura danych skutecznie wspiera zaprojektowane modele.
- Zarządzanie danymi i strategia: Często odgrywają rolę w zarządzaniu danymi, pomagając zdefiniować zasady i standardy zarządzania danymi w organizacji.
Chociaż umiejętności i zadania inżynierów danych i modelarzy danych w pewnym stopniu się pokrywają, te dwie role się uzupełniają. Inżynierowie danych skupiają się na budowaniu i utrzymywaniu infrastruktury obsługującej przechowywanie i dostęp do danych, natomiast inżynierowie danych projektują strukturę i organizację danych w tych systemach. Zapewniają, że architektura danych organizacji jest solidna, skalowalna i zgodna z celami biznesowymi, umożliwiając skuteczne podejmowanie decyzji w oparciu o dane.
Kluczowe elementy modelowania danych
Modelowanie danych to krytyczny proces w projektowaniu i wdrażaniu baz danych i systemów danych, które są wydajne, skalowalne i zdolne do spełnienia wymagań różnych aplikacji. Kluczowe komponenty obejmują encje, atrybuty, relacje i klucze. Zrozumienie tych komponentów jest niezbędne do stworzenia spójnego i funkcjonalnego modelu danych.
podmioty
Jednostka reprezentuje obiekt lub koncepcję świata rzeczywistego, którą można wyraźnie zidentyfikować. W bazie danych jednostka często przekłada się na tabelę. Jednostki służą do kategoryzowania informacji, które chcemy przechowywać. Na przykład w systemie zarządzania relacjami z klientami (CRM) typowe encje mogą obejmować „Klient”, „Zamówienie” i Product.
Atrybuty
Atrybuty to właściwości lub cechy jednostki. Podają szczegółowe informacje na temat podmiotu, pomagając w jego pełniejszym opisaniu. W tabeli bazy danych atrybuty reprezentują kolumny. W przypadku encji „Klient” atrybuty mogą obejmować „Identyfikator klienta”, „Nazwa”, „Adres”, „Numer telefonu” itp. Atrybuty definiują typ danych (takich jak liczba całkowita, ciąg znaków, data itp.) przechowywanych dla każdej encji instancja.
Relacje
Relacje opisują, w jaki sposób jednostki w systemie są ze sobą połączone, reprezentując ich interakcje. Istnieje kilka typów relacji:
- Jeden na jednego (1:1): Każda instancja Bytu A jest powiązana z jedną i tylko jedną instancją Bytu B i odwrotnie.
- Jeden do wielu (1:N): Każde wystąpienie Bytu A może być powiązane z zerem, jednym lub wieloma wystąpieniami Bytu B, ale każde wystąpienie Bytu B jest powiązane tylko z jednym wystąpieniem Bytu A.
- Wiele do wielu (M:N): Każde wystąpienie Bytu A może być powiązane z zerem, jednym lub wieloma wystąpieniami Bytu B, a każde wystąpienie Bytu B może być powiązane z zerem, jednym lub wieloma wystąpieniami Bytu A.
Relacje są kluczowe dla łączenia danych przechowywanych w różnych jednostkach, ułatwiając wyszukiwanie danych i raportowanie w wielu tabelach.
Klucze
Klucze to specyficzne atrybuty używane do jednoznacznej identyfikacji rekordów w tabeli i ustanawiania relacji między tabelami. Istnieje kilka rodzajów kluczy:
- Główny klucz: Kolumna lub zestaw kolumn jednoznacznie identyfikuje każdy rekord tabeli. Żadne dwa rekordy nie mogą mieć tej samej wartości klucza podstawowego w tabeli.
- Klucz obcy: Kolumna lub zestaw kolumn w jednej tabeli, która odwołuje się do klucza podstawowego innej tabeli. Klucze obce służą do ustanawiania i egzekwowania relacji między tabelami.
- Klucz złożony: Kombinacja dwóch lub więcej kolumn w tabeli, której można użyć do jednoznacznej identyfikacji każdego rekordu w tabeli.
- Klucz kandydata: Dowolna kolumna lub zestaw kolumn, który może kwalifikować się jako klucz podstawowy w tabeli.
Zrozumienie i prawidłowe wdrożenie tych kluczowych komponentów ma fundamentalne znaczenie dla stworzenia skutecznych systemów przechowywania, wyszukiwania i zarządzania danymi. Właściwe modelowanie danych prowadzi do dobrze zorganizowanych i zoptymalizowanych baz danych pod kątem wydajności i skalowalności, obsługując potrzeby zarówno programistów, jak i użytkowników końcowych.
Fazy modeli danych
Modelowanie danych zazwyczaj przebiega w trzech głównych fazach: koncepcyjny model danych, logiczny model danych i fizyczny model danych. Każda faza służy konkretnemu celowi i opiera się na poprzedniej, aby stopniowo przekształcać abstrakcyjne pomysły w konkretny projekt bazy danych. Zrozumienie tych faz ma kluczowe znaczenie dla każdego, kto tworzy systemy danych lub zarządza nimi.
Konceptualny model danych
Konceptualny model danych jest najbardziej abstrakcyjnym poziomem modelowania danych. Ta faza skupia się na zdefiniowaniu jednostek wysokiego poziomu i relacji między nimi, bez wchodzenia w szczegóły dotyczące sposobu przechowywania danych. Podstawowym celem jest przedstawienie głównych obiektów danych istotnych dla domeny biznesowej i ich interakcji w sposób zrozumiały dla interesariuszy nietechnicznych. Model ten jest często używany do wstępnego planowania i komunikacji, łącząc wymagania biznesowe i wdrożenie techniczne.
Kluczowe cechy obejmują
- Identyfikacja ważnych bytów i ich powiązań.
- Wysoki poziom, często posługujący się terminologią biznesową.
- Niezależny od jakiegokolwiek systemu zarządzania bazami danych (DBMS) lub technologii.
Logiczny model danych
Logiczny model danych dodaje więcej szczegółów do modelu koncepcyjnego, określając strukturę elementów danych i ustalając relacje między nimi. Zawiera definicję encji, atrybutów każdej encji, kluczy podstawowych i kluczy obcych. Jednak nadal pozostaje ona niezależna od technologii, jaka zostanie zastosowana przy realizacji. Model logiczny jest bardziej szczegółowy i uporządkowany niż model koncepcyjny oraz zaczyna wprowadzać reguły i ograniczenia rządzące danymi.
Kluczowe cechy obejmują
- Szczegółowa definicja jednostek, relacji i atrybutów.
- Do nawiązania relacji konieczne jest uwzględnienie kluczy podstawowych i kluczy obcych.
- Aby zapewnić integralność danych i zmniejszyć redundancję, stosowane są procesy normalizacyjne.
- Nadal niezależny od konkretnej technologii DBMS.
Fizyczny model danych
Fizyczny model danych jest najbardziej szczegółową fazą i obejmuje wdrożenie modelu danych w ramach określonego systemu zarządzania bazą danych. Model ten przekłada logiczny model danych na szczegółowy schemat, który można zaimplementować w bazie danych. Zawiera wszystkie szczegóły niezbędne do implementacji, takie jak tabele, kolumny, typy danych, ograniczenia, indeksy, wyzwalacze i inne funkcje specyficzne dla bazy danych.
Kluczowe cechy obejmują
- Specyficzne dla konkretnego systemu DBMS i obejmuje optymalizację specyficzną dla bazy danych.
- Szczegółowe specyfikacje tabel, kolumn, typów danych i ograniczeń.
- Uwzględnienie opcji pamięci fizycznej, strategii indeksowania i optymalizacji wydajności.
Przejście przez te fazy umożliwia skrupulatne planowanie i projektowanie systemu danych dostosowanego do wymagań biznesowych i zoptymalizowanego pod kątem wydajności w określonym środowisku technicznym. Model koncepcyjny gwarantuje, że ogólna struktura jest zgodna z celami biznesowymi, model logiczny wypełnia lukę pomiędzy planowaniem koncepcyjnym a fizycznym wdrożeniem, a model fizyczny zapewnia optymalizację bazy danych pod kątem rzeczywistego wykorzystania.
Przykładowy zbiór danych szkoły
Podmioty: uczniowie, nauczyciele i klasy.
Konceptualny model danych
Ten koncepcyjny model danych przedstawia system baz danych do zarządzania dokumentacją szkolną, składający się z trzech głównych jednostek: ucznia, nauczyciela i klasy. W tym modelu uczniowie mogą być powiązani z wieloma nauczycielami i klasami, natomiast nauczyciele mogą uczyć wielu uczniów i prowadzić różne zajęcia. Każda klasa może pomieścić wielu uczniów, ale uczy ją jeden nauczyciel. Projekt ma na celu uproszczenie zrozumienia relacji między podmiotami zarówno dla interesariuszy technicznych, jak i nietechnicznych, zapewniając jasny i intuicyjny przegląd struktury systemu. Rozpoczęcie od modelu koncepcyjnego pozwala na stopniową integrację bardziej szczegółowych elementów, kładąc solidną podstawę do opracowania wyrafinowanych modeli baz danych.
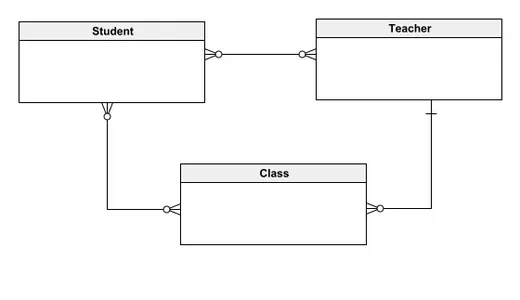
Logiczny model danych
Logiczny model danych, bardzo preferowany ze względu na równowagę między przejrzystością a szczegółowością, zawiera encje, relacje, atrybuty, KLUCZE PODSTAWOWE i KLUCZE OBCE. Skrupulatnie opisuje logiczny postęp danych w bazie danych, wyjaśniając szczegółowe szczegóły, takie jak ich skład lub wykorzystywane typy danych. Logiczny model danych zapewnia wystarczającą podstawę do opracowania oprogramowania, aby rozpocząć faktyczną budowę bazy danych.
Wychodząc od omówionego wcześniej koncepcyjnego modelu danych, przyjrzyjmy się typowemu logicznemu modelowi danych. W odróżnieniu od swojego koncepcyjnego poprzednika, model ten wzbogacony jest o atrybuty i klucze podstawowe. Na przykład jednostka Student wyróżnia się identyfikatorem StudentID będącym kluczem podstawowym i unikalnym identyfikatorem, a także innymi istotnymi atrybutami, takimi jak imię i wiek.
To podejście jest konsekwentnie stosowane w innych jednostkach, takich jak Nauczyciel i Klasa, zachowując relacje ustanowione w modelu koncepcyjnym, a jednocześnie wzbogacając model o szczegółowy schemat obejmujący atrybuty i kluczowe identyfikatory.
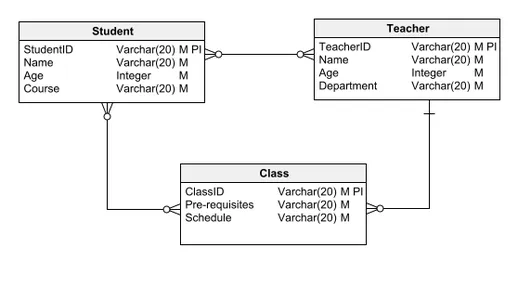
Fizyczny model danych
Fizyczny model danych jest najbardziej szczegółowy spośród poziomów abstrakcji i uwzględnia specyfikę dostosowaną do wybranego systemu zarządzania bazami danych, takiego jak PostgreSQL, Oracle czy MySQL. W tym modelu jednostki są tłumaczone na tabele, a atrybuty stają się kolumnami, odzwierciedlając strukturę rzeczywistej bazy danych. Każdej kolumnie przypisany jest określony typ danych, na przykład INT w przypadku liczb całkowitych, VARCHAR w przypadku zmiennych ciągów znaków lub DATE w przypadku dat.
Biorąc pod uwagę jego szczegółowy charakter, fizyczny model danych uwzględnia szczegóły techniczne charakterystyczne dla używanej platformy baz danych. Te kompleksowe aspekty wykraczają poza zakres ogólnego przeglądu. Obejmuje to kwestie takie jak alokacja pamięci, strategie indeksowania i wdrażanie ograniczeń, które są kluczowe dla wydajności i integralności bazy danych, ale zazwyczaj są zbyt szczegółowe, aby można było je wstępnie omówić.

Fazy modelowania danych
- Zrozumienie wymagań biznesowych: Angażuj się w szczegółowe dyskusje z interesariuszami, aby zrozumieć cel biznesowy bazy danych. Kluczowe kwestie obejmują identyfikację domeny biznesowej, potrzeby w zakresie przechowywania danych i problemy, które baza danych ma rozwiązać. Skoncentruj się na dostosowaniu projektu bazy danych do celów biznesowych w zakresie wydajności, kosztów i bezpieczeństwa.
- Praca drużynowa: Ściśle współpracuj z innymi zespołami (np. projektantami i programistami UX/UI), aby mieć pewność, że baza danych obsługuje szersze rozwiązanie. Dostosuj formaty i typy danych, aby spełnić wymagania aplikacji, kładąc nacisk na wspólne projektowanie i umiejętności komunikacyjne.
- Wykorzystaj standardy branżowe: Przeanalizuj istniejące modele i standardy, aby uniknąć zaczynania od zera. Wykorzystaj najlepsze praktyki branżowe, aby zaoszczędzić czas i zasoby, koncentrując wyjątkowe wysiłki na aspektach bazy danych, które odróżniają ją od istniejących modeli.
- Rozpocznij modelowanie bazy danych: Mając solidne zrozumienie potrzeb biznesowych, wkładu zespołu i standardów branżowych, rozpocznij od modelowania koncepcyjnego, przejdź do modelu logicznego i zakończ modelem fizycznym. To ustrukturyzowane podejście zapewnia kompleksowe zrozumienie wymaganych encji, atrybutów i relacji, ułatwiając płynne wdrażanie bazy danych zgodnie z celami biznesowymi.
Narzędzia do modelowania danych są niezbędne do projektowania, utrzymywania i rozwijania struktur danych organizacyjnych. Narzędzia te oferują szereg funkcjonalności wspierających cały cykl życia projektowania i zarządzania bazami danych. Kluczowe funkcje, których należy szukać w narzędziach do modelowania danych, obejmują:
- Buduj modele danych: Ułatw tworzenie koncepcyjnych, logicznych i fizycznych modeli danych, umożliwiając jasne zdefiniowanie jednostek, atrybutów i relacji. Ta podstawowa funkcjonalność wspiera początkowe i ciągłe projektowanie architektury bazy danych.
- Współpraca i Centralne Repozytorium: Umożliwiaj członkom zespołu współpracę przy projektowaniu i modyfikowaniu modelu danych. Centralne repozytorium zapewnia dostępność najnowszych wersji wszystkim zainteresowanym stronom, promując spójność i efektywność rozwoju.
- Inżynieria wsteczna: Zapewnij możliwość importowania skryptów SQL lub łączenia się z istniejącymi bazami danych w celu generowania modeli danych. Jest to szczególnie przydatne do zrozumienia i dokumentowania starszych systemów lub integracji istniejących baz danych.
- Inżynieria przyszłości: Umożliwia generowanie skryptów lub kodu SQL z modelu danych. Funkcja ta usprawnia wdrażanie zmian w strukturze bazy danych, zapewniając, że fizyczna baza danych odzwierciedla najnowszy model.
- Obsługa różnych typów baz danych: Oferuj kompatybilność z wieloma systemami zarządzania bazami danych (DBMS), takimi jak MySQL, PostgreSQL, Oracle, SQL Server i nie tylko. Ta elastyczność zapewnia, że narzędzie może być wykorzystywane w różnych projektach i środowiskach technologicznych.
- Kontrola wersji: Dołącz lub zintegruj z systemami kontroli wersji, aby śledzić zmiany w modelach danych w czasie. Ta funkcja jest kluczowa dla zarządzania iteracjami struktury bazy danych i ułatwienia powrotu do poprzednich wersji, jeśli zajdzie taka potrzeba.
- Eksportowanie diagramów w różnych formatach: Pozwól użytkownikom eksportować modele danych i diagramy w różnych formatach (np. PDF, PNG, XML), ułatwiając udostępnianie i dokumentację. Dzięki temu zainteresowane strony nietechniczne mogą również dokonać przeglądu i zrozumieć architekturę danych.
Wybór narzędzia do modelowania danych wyposażonego w te funkcje może znacznie zwiększyć wydajność, dokładność i współpracę w zakresie zarządzania danymi w organizacji, zapewniając, że bazy danych są dobrze zaprojektowane, aktualne i dostosowane do potrzeb biznesowych.
ostry dyżur/studio

Oferuje wszechstronne możliwości modelowania i funkcje współpracy oraz obsługuje różne platformy baz danych.
Połączenie z oddziałem ratunkowym/studio
Architekt danych IBM InfoSphere

Zapewnia solidne środowisko do projektowania modeli danych i zarządzania nimi, obsługując integrację i synchronizację z innymi produktami IBM.
Łącze IBM InfoSphere Data Architect
Narzędzie do modelowania danych dla programistów Oracle SQL

Bezpłatne narzędzie obsługujące inżynierię do przodu i wstecz, kontrolę wersji oraz obsługę wielu baz danych.
Łącze do narzędzia do modelowania danych Oracle SQL Developer
PowerDesigner (SAP)

Oferuje rozbudowane funkcje modelowania, w tym obsługę danych, informacji i architektury korporacyjnej.
Link do programu PowerDesigner (SAP).
Modelarz danych Navicat
Znany z przyjaznego dla użytkownika interfejsu i obsługi szerokiej gamy baz danych, pozwala na inżynierię do przodu i do tyłu.
Link do narzędzia modelowania danych Navicat
Narzędzia te usprawniają proces modelowania danych, usprawniają współpracę w zespole i zapewniają kompatybilność między różnymi systemami baz danych.
Przeczytaj także: Pytania do rozmowy kwalifikacyjnej dotyczące modelowania danych
Wnioski
W artykule tym zagłębiono się w podstawową praktykę modelowania danych, podkreślając jego kluczową rolę w organizowaniu, przechowywaniu i uzyskiwaniu dostępu do danych w bazach danych i systemach danych. Dzieląc proces na modele koncepcyjne, logiczne i fizyczne, zilustrowaliśmy, w jaki sposób modelowanie danych przekłada potrzeby biznesowe na ustrukturyzowane ramy danych, ułatwiając wydajną obsługę danych i wnikliwą analizę.
Najważniejsze wnioski obejmują znaczenie zrozumienia wymagań biznesowych, wspólny charakter projektowania baz danych z udziałem różnych interesariuszy oraz strategiczne wykorzystanie narzędzi do modelowania danych w celu usprawnienia procesu rozwoju. Modelowanie danych zapewnia optymalizację struktur danych pod kątem bieżących potrzeb i zapewnia skalowalność dla przyszłego rozwoju.
Modelowanie danych leży u podstaw skutecznego zarządzania danymi, umożliwiając organizacjom wykorzystanie ich do podejmowania strategicznych decyzji i zwiększania wydajności operacyjnej.
Często Zadawane Pytania
Odp. Modelowanie danych wizualnie reprezentuje dane systemu, określając, w jaki sposób są one przechowywane, zorganizowane i dostępne. Ma to kluczowe znaczenie w przypadku przekładania wymagań biznesowych na ustrukturyzowany format bazy danych, umożliwiający efektywne wykorzystanie danych.
Odp. Kluczowe przypadki użycia obejmują pozyskiwanie, ładowanie, obliczenia biznesowe i dystrybucję danych, co zapewnia efektywne gromadzenie, przechowywanie i wykorzystywanie danych do celów biznesowych.
Odp. Inżynierowie danych budują i utrzymują infrastrukturę danych, natomiast osoby zajmujące się modelowaniem danych projektują strukturę i organizację danych, aby wspierać cele biznesowe i integralność danych.
Odp. Proces przechodzi od zrozumienia wymagań biznesowych do współpracy z zespołami, wykorzystania standardów branżowych i modelowania bazy danych w fazach koncepcyjnych, logicznych i fizycznych.
Odp. Narzędzia te ułatwiają projektowanie, współpracę i ewolucję modeli danych, obsługując różne typy baz danych i umożliwiając inżynierię wsteczną i naprzód w celu wydajnego zarządzania bazami danych.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.analyticsvidhya.com/blog/2024/03/data-modeling-demystified-crafting-efficient-databases-for-business-insights/

