Ten post został napisany wspólnie z Amirem Souchamim i Fabianem Szenkierem z Unity.
Aura z Unity (wcześniej znany jako ironSource) to rynkowy standard umożliwiający tworzenie bogatych doświadczeń urządzeń, które angażują i zatrzymują klientów. Dzięki potężnemu zestawowi rozwiązań Aura umożliwia pełną transformację cyfrową, umożliwiając operatorom promowanie kluczowych usług poza sklepem, bezpośrednio na urządzeniu.
Amazonka Przesunięcie ku czerwieni to usługa zalecana w przypadku obciążeń związanych z przetwarzaniem analitycznym online (OLAP), takich jak hurtownie danych w chmurze, zbiory danych i inne magazyny danych analitycznych. Możesz używać prostego języka SQL do analizowania danych ustrukturyzowanych i częściowo ustrukturyzowanych, operacyjnych baz danych i jezior danych, aby zapewnić najlepszy stosunek ceny do wydajności w dowolnej skali. The Udostępnianie danych Amazon Redshift Funkcja zapewnia natychmiastowy, szczegółowy i wydajny dostęp bez kopiowania i przenoszenia danych pomiędzy wieloma hurtowniami danych Redshift na tym samym lub różnych kontach AWS i pomiędzy regionami AWS. Udostępnianie danych zapewnia dostęp do danych na żywo, dzięki czemu zawsze widzisz najbardziej aktualne i spójne informacje w miarę ich aktualizacji w hurtowni danych.
Bezserwerowe Amazon Redshift ułatwia uruchamianie i skalowanie analiz w ciągu kilku sekund, bez konieczności konfigurowania klastrów hurtowni danych i zarządzania nimi. Redshift Serverless automatycznie udostępnia i inteligentnie skaluje pojemność hurtowni danych, aby zapewnić szybką wydajność nawet w przypadku najbardziej wymagających i nieprzewidywalnych obciążeń, a płacisz tylko za to, z czego korzystasz. Możesz załadować swoje dane i od razu rozpocząć wysyłanie zapytań w edytorze zapytań Amazon Redshift Query Editor lub w swoim ulubionym narzędziu Business Intelligence (BI) i nadal cieszyć się najlepszym stosunkiem ceny do wydajności i znanymi funkcjami SQL w łatwym w obsłudze środowisku bez konieczności administrowania .
W tym poście opisujemy pomyślne i szybkie przyjęcie przez firmę Aura Redshift Serverless, co pozwoliło jej zoptymalizować ogólny czas wprowadzenia na rynek kampanii reklamowych z licytacją z 24 godzin do 2 godzin. Badamy, dlaczego Aura wybrała to rozwiązanie i jakie wyzwania technologiczne pomogło rozwiązać.
Początkowy potok danych Aury
Aura jest pionierem w korzystaniu z klastrów Redshift RA3 z udostępnianiem danych na potrzeby wyodrębniania, przekształcania i ładowania (ETL) oraz obciążeń BI. Jednym z działań Aury jest licytacja kampanii reklamowych. Kampanie te są optymalizowane przy użyciu procesu ustalania stawek opartego na sztucznej inteligencji, który wymaga uruchomienia setek zapytań analitycznych na kampanię. Te zapytania są uruchamiane na danych znajdujących się w klastrze Redshift z obsługą RA3.
Zintegrowany potok składa się z różnych usług AWS:
Poniższy diagram ilustruje tę architekturę.
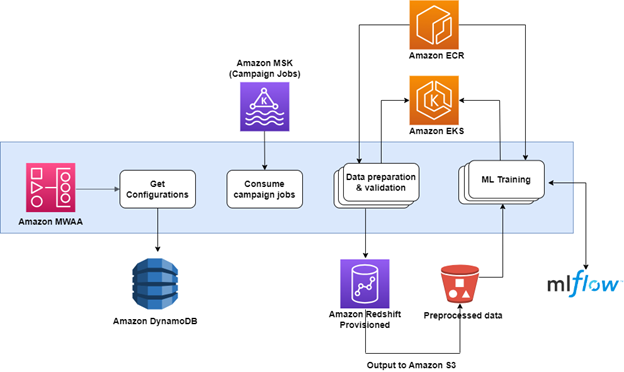
Wyzwania architektury początkowej
Zapytania dla każdej kampanii przebiegają w następujący sposób:
Najpierw zapytanie przygotowujące filtruje i agreguje surowe dane, przygotowując je do dalszej operacji. Po tym następuje zapytanie główne, które realizuje logikę zgodnie ze zbiorem wyników zapytania przygotowującego.
W miarę wzrostu liczby kampanii zespół ds. danych firmy Aura musiał wykonywać setki jednoczesnych zapytań na każdym z tych etapów. Istniejący aprowizowany klaster firmy Aura był już w dużym stopniu wykorzystywany do obsługi obciążeń związanych z pozyskiwaniem danych, ETL i BI, dlatego firma szukała opłacalnych sposobów izolowania tego obciążenia za pomocą dedykowanych zasobów obliczeniowych.
Zespół ocenił różne opcje, w tym przesyłanie danych do Amazon S3 i architekturę wieloklastrową wykorzystującą udostępnianie danych i technologię bezserwerową Redshift. Zespół skłaniał się ku architekturze wieloklastrowej z udostępnianiem danych, ponieważ nie wymaga ona przepisywania zapytań, pozwala na dedykowane obliczenia dla tego konkretnego obciążenia, pozwala uniknąć konieczności duplikowania lub przenoszenia danych z głównego klastra oraz zapewnia wysoką współbieżność i automatyczne skalowanie. Wreszcie, opłaty są naliczane w modelu „płać za to, czego używasz”, a udostępnianie jest proste i szybkie.
Dowód koncepcji
Po dokonaniu oceny opcji zespół Data firmy Aura zdecydował się przeprowadzić weryfikację koncepcji, używając Redshift Serverless jako konsumenta głównego klastra z obsługą Redshift, udostępniając tylko odpowiednie tabele do uruchamiania wymaganych zapytań. Redshift Serverless mierzy pojemność hurtowni danych w jednostkach przetwarzania Redshift (RPU). Pojedynczy RPU zapewnia 16 GB pamięci, a bezserwerowy punkt końcowy może mieć wartość od 8 RPU do 512 RPU.
Zespół firmy Aura Data rozpoczął weryfikację koncepcji przy użyciu bezserwerowego punktu końcowego 256 RPU Redshift i stopniowo obniżał liczbę RPU, aby obniżyć koszty, jednocześnie upewniając się, że czas wykonywania zapytań był niższy od wymaganego celu.
Ostatecznie zespół zdecydował się użyć punktu końcowego Redshift Serverless o pojemności 128 RPU (2 TB RAM) jako podstawowego RPU, korzystając jednocześnie z funkcji automatycznego skalowania Redshift Serverless, która umożliwia uruchamianie setek jednoczesnych zapytań poprzez automatyczne zwiększanie RPU w razie potrzeby.
Nowe rozwiązanie Aura z Redshift Serverless
Po pomyślnym sprawdzeniu koncepcji konfiguracja produkcyjna obejmowała dodanie kodu umożliwiającego przełączanie między udostępnionym klastrem Redshift a punktem końcowym Redshift Serverless. Dokonano tego przy użyciu konfigurowalnego progu opartego na liczbie zapytań oczekujących na przetworzenie w określonym temacie MSK wykorzystanych na początku potoku. Zapytania kampanii na małą skalę będą nadal uruchamiane w udostępnionym klastrze, a zapytania na dużą skalę będą korzystać z punktu końcowego Redshift Serverless. Nowe rozwiązanie wykorzystuje potok Amazon MWAA, który pobiera informacje konfiguracyjne z tabeli DynamoDB, wykorzystuje zadania reprezentujące kampanie reklamowe, a następnie uruchamia setki zadań EKS wyzwalanych za pomocą EKSPodOperator. Każde zadanie uruchamia dwa zapytania szeregowe (zapytanie przygotowawcze, po którym następuje zapytanie główne, które wysyła wyniki do Amazon S3). Dzieje się tak kilkaset razy jednocześnie przy użyciu zasobów obliczeniowych Redshift Serverless.
Następnie proces inicjuje kolejny zestaw operatorów EKSPodOperator w celu uruchomienia kodu szkoleniowego AI na podstawie wyniku danych zapisanych na Amazon S3.
Poniższy schemat ilustruje architekturę rozwiązania.
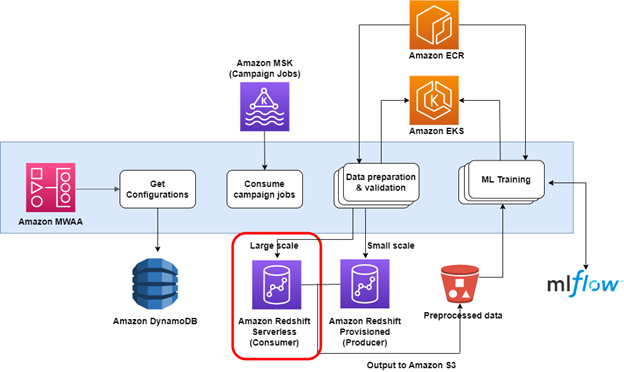
Wynik
Całkowity czas pracy rurociągu został skrócony z 24 godzin do zaledwie 2 godzin, co stanowi 12-krotną poprawę. Ta integracja Redshift Serverless w połączeniu z udostępnianiem danych doprowadziła do skrócenia czasu trwania potoku o 90%, eliminując konieczność duplikowania danych lub przepisywania zapytań. Co więcej, wprowadzenie dedykowanego konsumenta jako wyłącznego zasobu obliczeniowego znacznie zmniejszyło obciążenie klastra producenta, umożliwiając jeszcze szybsze uruchamianie zapytań na małą skalę.
„Redshift Serverless i udostępnianie danych umożliwiły nam udostępnienie i skalowanie pojemności naszej hurtowni danych, aby zapewnić szybką wydajność, wysoką współbieżność i obsługę trudnych obciążeń uczenia maszynowego przy bardzo minimalnym wysiłku”.
– Amir Souchami, główny architekt systemów technicznych w firmie Aura.
Nauka
Zespół firmy Aura Data jest bardzo skoncentrowany na ekonomicznej pracy i dlatego wdrożył kilka kontroli kosztów w swoim punkcie końcowym Redshift Serverless:
- Ogranicz całkowite wydatki, ustawiając maksymalny limit godzin wykorzystania RPU (na dzień, tydzień, miesiąc) dla grupy roboczej. Aura skonfigurowała ten limit, więc po jego osiągnięciu Amazon Redshift wyśle powiadomienie do odpowiedniego zespołu administratorów Amazon Redshift. Ta funkcja umożliwia także zapisanie wpisu do tabeli systemowej, a nawet wyłączenie zapytań użytkowników.
- Użyj maksymalna konfiguracja RPU, który określa górny limit zasobów obliczeniowych, z których Redshift Serverless może w danym momencie skorzystać. Po ustawieniu maksymalnego limitu RPU dla grupy roboczej, Redshift Serverless skaluje się w ramach tego limitu, aby kontynuować obciążenie.
- Wdrożenie zasady monitorowania zapytań które zapobiegają marnotrawstwu zasobów i niekontrolowanym kosztom spowodowanym przez źle napisane zapytania.
Wnioski
Hurtownia danych jest kluczową częścią każdej nowoczesnej firmy opartej na danych, umożliwiającą odpowiadanie na złożone pytania biznesowe i dostarczanie spostrzeżeń. Ewolucja Amazon Redshift umożliwiła firmie Aura szybkie dostosowanie się do wymagań biznesowych poprzez połączenie udostępniania danych pomiędzy hurtowniami danych udostępnianymi i hurtowniami danych Redshift Serverless. Podróż Aury z Redshift Serverless podkreśla ogromny potencjał strategicznej integracji technologii w zwiększaniu wydajności i doskonałości operacyjnej.
Jeśli podróż Aury wzbudziła Twoje zainteresowanie i zastanawiasz się nad wdrożeniem podobnego rozwiązania w swojej organizacji, oto kilka strategicznych kroków do rozważenia:
- Zacznij od dokładnego zrozumienia potrzeb swojej organizacji w zakresie danych i tego, w jaki sposób takie rozwiązanie może je zaspokoić.
- Skontaktuj się z ekspertami AWS, którzy mogą udzielić Ci wskazówek w oparciu o własne doświadczenia. Rozważ wzięcie udziału w seminariach, warsztatach lub forach internetowych omawiających te technologie. Na początek zalecane są następujące zasoby:
- Ważną częścią tej podróży byłoby wdrożenie weryfikacji koncepcji. Takie praktyczne doświadczenie zapewni cenne spostrzeżenia przed przejściem do produkcji.
Podnieś swoją wiedzę na temat przesunięcia ku czerwieni. Już cieszysz się mocą Amazon Redshift? Ulepsz swoją podróż danych dzięki najnowsze funkcje i wskazówki ekspertów. Skontaktuj się ze swoim dedykowanym zespołem obsługi klienta AWS, aby uzyskać spersonalizowaną pomoc, odkryć najnowocześniejsze możliwości i odblokować jeszcze większą wartość swoich danych dzięki Przesunięcie ku czerwieni Amazonki.
O autorach
 Amira Souchamiego, główny architekt Aura z Unity, skupiający się na tworzeniu odpornych i wydajnych systemów chmurowych oraz aplikacji mobilnych na dużą skalę.
Amira Souchamiego, główny architekt Aura z Unity, skupiający się na tworzeniu odpornych i wydajnych systemów chmurowych oraz aplikacji mobilnych na dużą skalę.
 Fabiana Szenkiera jest architektem ML i Big Data w Aura by Unity, pracuje nad budowaniem nowoczesnych rozwiązań AI/ML i najnowocześniejszych potoków inżynierii danych na dużą skalę.
Fabiana Szenkiera jest architektem ML i Big Data w Aura by Unity, pracuje nad budowaniem nowoczesnych rozwiązań AI/ML i najnowocześniejszych potoków inżynierii danych na dużą skalę.
 Liat Tzur jest starszym menedżerem ds. obsługi technicznej w Amazon Web Services. Pełni funkcję rzecznika klienta i pomaga swoim klientom w osiągnięciu doskonałości operacyjnej w chmurze zgodnie z ich celami biznesowymi.
Liat Tzur jest starszym menedżerem ds. obsługi technicznej w Amazon Web Services. Pełni funkcję rzecznika klienta i pomaga swoim klientom w osiągnięciu doskonałości operacyjnej w chmurze zgodnie z ich celami biznesowymi.
 Adiego Jabkowskiego jest starszym specjalistą Redshift w regionie EMEA, częścią Światowej Organizacji Specjalistycznej (WWSO) w AWS.
Adiego Jabkowskiego jest starszym specjalistą Redshift w regionie EMEA, częścią Światowej Organizacji Specjalistycznej (WWSO) w AWS.
 Yonatana Dolana jest głównym specjalistą ds. analityki w Amazon Web Services. Ma siedzibę w Izraelu i pomaga klientom wykorzystywać usługi analityczne AWS do wykorzystania danych, zdobywania wiedzy i czerpania wartości.
Yonatana Dolana jest głównym specjalistą ds. analityki w Amazon Web Services. Ma siedzibę w Izraelu i pomaga klientom wykorzystywać usługi analityczne AWS do wykorzystania danych, zdobywania wiedzy i czerpania wartości.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/how-aura-from-unity-revolutionized-their-big-data-pipeline-with-amazon-redshift-serverless/

