Modele podstawowe (FM) to duże modele uczenia maszynowego (ML) szkolone na szerokim spektrum nieoznaczonych i uogólnionych zbiorów danych. FM, jak sama nazwa wskazuje, stanowią podstawę do tworzenia bardziej wyspecjalizowanych aplikacji downstream i są wyjątkowe pod względem możliwości adaptacji. Mogą wykonywać szeroki zakres różnych zadań, takich jak przetwarzanie języka naturalnego, klasyfikacja obrazów, prognozowanie trendów, analizowanie nastrojów i odpowiadanie na pytania. Ta skala i możliwość dostosowania do ogólnego przeznaczenia odróżniają FM od tradycyjnych modeli ML. FM są multimodalne; działają z różnymi typami danych, takimi jak tekst, wideo, audio i obrazy. Modele wielkojęzykowe (LLM) to rodzaj FM, które są wstępnie szkolone na ogromnych ilościach danych tekstowych i zazwyczaj mają zastosowania aplikacyjne, takie jak generowanie tekstu, inteligentne chatboty lub podsumowania.
Przesyłanie strumieniowe danych ułatwia stały przepływ różnorodnych i aktualnych informacji, zwiększając zdolność modeli do adaptacji i generowania dokładniejszych, odpowiednich kontekstowo wyników. Umożliwia to dynamiczna integracja danych przesyłanych strumieniowo generatywna sztuczna inteligencja aplikacje, aby szybko reagowały na zmieniające się warunki, poprawiając ich możliwości adaptacyjne i ogólną wydajność w różnych zadaniach.
Aby lepiej to zrozumieć, wyobraź sobie chatbota, który pomaga podróżnym w rezerwacji podróży. W tym scenariuszu chatbot potrzebuje dostępu w czasie rzeczywistym do informacji o liniach lotniczych, statusie lotu, wyposażeniu hotelu, najnowszych zmianach cen i nie tylko. Dane te zwykle pochodzą od stron trzecich, a programiści muszą znaleźć sposób na ich przejęcie i przetwarzanie zmian danych w miarę ich pojawiania się.
Przetwarzanie wsadowe nie jest najlepszym rozwiązaniem w tym scenariuszu. Gdy dane zmieniają się szybko, przetwarzanie ich zbiorczo może spowodować, że chatbot wykorzysta nieaktualne dane, dostarczając klientowi niedokładnych informacji, co wpływa na ogólne doświadczenie klienta. Przetwarzanie strumieniowe może jednak umożliwić chatbotowi dostęp do danych w czasie rzeczywistym i dostosowywanie się do zmian w dostępności i cenie, zapewniając klientowi najlepsze wskazówki i poprawiając jego doświadczenie.
Innym przykładem jest rozwiązanie w zakresie obserwacji i monitorowania oparte na sztucznej inteligencji, w ramach którego FM monitoruje w czasie rzeczywistym wewnętrzne wskaźniki systemu i generuje alerty. Gdy model znajdzie anomalię lub nieprawidłową wartość metryki, powinien natychmiast wygenerować alert i powiadomić operatora. Jednak wartość tak ważnych danych znacznie maleje wraz z upływem czasu. Powiadomienia te powinny w idealnym przypadku zostać odebrane w ciągu kilku sekund lub nawet w trakcie zdarzenia. Jeśli operatorzy otrzymają te powiadomienia kilka minut lub godzin po zdarzeniu, takie spostrzeżenia nie będą przydatne i potencjalnie stracą swoją wartość. Podobne przypadki użycia można znaleźć w innych branżach, takich jak handel detaliczny, produkcja samochodów, energetyka i branża finansowa.
W tym poście omawiamy, dlaczego strumieniowanie danych jest kluczowym elementem generatywnych aplikacji AI ze względu na jego charakter w czasie rzeczywistym. Omawiamy wartość usług strumieniowego przesyłania danych AWS, takich jak Przesyłanie strumieniowe zarządzane przez Amazon dla Apache Kafka (Amazon MSK), Strumienie danych Amazon Kinesis, Usługa zarządzana przez Amazon dla Apache Flink, Wąż strażacki Amazon Kinesis Data w budowaniu generatywnych aplikacji AI.
Uczenie się w kontekście
LLM są szkolone na podstawie danych z określonego momentu i nie mają nieodłącznej możliwości dostępu do świeżych danych w momencie wnioskowania. W miarę pojawiania się nowych danych konieczne będzie ciągłe dostrajanie lub dalsze uczenie modelu. Jest to nie tylko kosztowna operacja, ale także bardzo ograniczająca w praktyce, ponieważ tempo generowania nowych danych znacznie przewyższa szybkość dostrajania. Ponadto LLM nie rozumieją kontekstu i polegają wyłącznie na danych treningowych, w związku z czym są podatni na halucynacje. Oznacza to, że mogą wygenerować płynną, spójną i poprawną składniowo, ale niepoprawną pod względem faktycznym odpowiedź. Są one również pozbawione znaczenia, personalizacji i kontekstu.
LLM mają jednak zdolność uczenia się na podstawie danych otrzymywanych z kontekstu, aby dokładniej reagować bez modyfikowania wag modeli. To się nazywa uczenie się w kontekściei można ich używać do tworzenia spersonalizowanych odpowiedzi lub zapewnienia dokładnej odpowiedzi w kontekście zasad organizacji.
Na przykład w chatbocie zdarzenia związane z danymi mogą odnosić się do spisu lotów i hoteli lub zmian cen, które są stale rejestrowane w silniku przechowywania strumieniowego. Co więcej, zdarzenia danych są filtrowane, wzbogacane i przekształcane do formatu użytkowego za pomocą procesora strumieniowego. Wynik jest udostępniany aplikacji poprzez zapytanie o najnowszą migawkę. Migawka jest stale aktualizowana poprzez przetwarzanie strumienia; dlatego też aktualne dane podawane są w kontekście podpowiedzi użytkownika do modelu. Dzięki temu model dostosowuje się do najnowszych zmian cenowych i dostępności. Poniższy diagram ilustruje podstawowy proces uczenia się w kontekście.
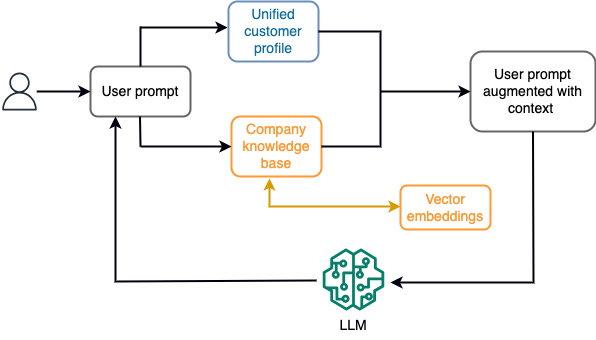
Powszechnie stosowanym podejściem do uczenia się kontekstowego jest zastosowanie techniki zwanej generacją rozszerzoną wyszukiwania (RAG). W RAG podajesz odpowiednie informacje, takie jak najważniejsze zasady i dane klientów, wraz z pytaniem użytkownika w odpowiedzi. W ten sposób LLM generuje odpowiedź na pytanie użytkownika, korzystając z dodatkowych informacji dostarczonych jako kontekst. Aby dowiedzieć się więcej o RAG, zob Odpowiadanie na pytania za pomocą Retrieval Augmented Generation z modelami podstawowymi w Amazon SageMaker JumpStart.
Aplikacja generatywnej sztucznej inteligencji oparta na RAG może generować jedynie ogólne odpowiedzi na podstawie danych szkoleniowych i odpowiednich dokumentów w bazie wiedzy. To rozwiązanie nie sprawdza się, gdy oczekuje się od aplikacji spersonalizowanej odpowiedzi w czasie zbliżonym do rzeczywistego. Na przykład oczekuje się, że chatbot podróżniczy będzie brał pod uwagę aktualne rezerwacje użytkownika, dostępne zasoby hoteli i lotów i nie tylko. Ponadto odpowiednie dane osobowe klientów (powszechnie znane jako ujednolicony profil klienta) zwykle podlega zmianom. Jeśli do aktualizacji bazy danych profili użytkowników generatywnej sztucznej inteligencji zostanie zastosowany proces wsadowy, klient może otrzymać niezadowalające odpowiedzi w oparciu o stare dane.
W tym poście omawiamy zastosowanie przetwarzania strumieniowego w celu ulepszenia rozwiązania RAG wykorzystywanego do budowania agentów odpowiadających na pytania z kontekstem od dostępu w czasie rzeczywistym do ujednoliconych profili klientów i bazy wiedzy organizacyjnej.
Aktualizacje profili klientów w czasie niemal rzeczywistym
Rekordy klientów są zazwyczaj rozproszone w magazynach danych w organizacji. Aby aplikacja generująca sztuczną inteligencję zapewniała odpowiedni, dokładny i aktualny profil klienta, konieczne jest zbudowanie potoków danych przesyłanych strumieniowo, które będą w stanie rozpoznawać tożsamość i agregować profile w rozproszonych magazynach danych. Zadania przesyłania strumieniowego stale pobierają nowe dane w celu synchronizacji między systemami i mogą wydajniej przeprowadzać wzbogacanie, transformacje, łączenia i agregacje w różnych przedziałach czasowych. Zdarzenia przechwytywania danych zmian (CDC) zawierają informacje o rekordzie źródłowym, aktualizacjach i metadanych, takich jak czas, źródło, klasyfikacja (wstawianie, aktualizacja lub usuwanie) oraz inicjator zmiany.
Poniższy diagram ilustruje przykładowy przepływ pracy dotyczący pozyskiwania i przetwarzania strumieniowego CDC dla ujednoliconych profili klientów.

W tej sekcji omawiamy główne komponenty wzorca przesyłania strumieniowego CDC wymaganego do obsługi generatywnych aplikacji AI opartych na RAG.
Pozyskiwanie strumieniowe CDC
Replikator CDC to proces, który zbiera zmiany danych z systemu źródłowego (zwykle poprzez odczyt dzienników transakcji lub dzienników binarnych) i zapisuje zdarzenia CDC w dokładnie tej samej kolejności, w jakiej wystąpiły w strumieniu danych lub temacie. Obejmuje to przechwytywanie oparte na logach za pomocą narzędzi takich jak Usługa migracji bazy danych AWS (AWS DMS) lub łączniki typu open source, takie jak Debezium dla Apache Kafka connect. Apache Kafka Connect jest częścią środowiska Apache Kafka, umożliwiającą pobieranie danych z różnych źródeł i dostarczanie ich do różnych miejsc docelowych. Możesz uruchomić łącznik Apache Kafka Amazon MSK Połącz w ciągu kilku minut, nie martwiąc się o konfigurację, instalację i obsługę klastra Apache Kafka. Wystarczy przesłać skompilowany kod łącznika do Usługa Amazon Simple Storage (Amazon S3) i skonfiguruj łącznik zgodnie z konfiguracją specyficzną dla Twojego obciążenia.
Istnieją również inne metody przechwytywania zmian danych. Na przykład, Amazon DynamoDB udostępnia funkcję przesyłania strumieniowego danych CDC do Strumienie Amazon DynamoDB lub strumienie danych Kinesis. Amazon S3 zapewnia wyzwalacz do wywołania AWS Lambda funkcja w przypadku zapisywania nowego dokumentu.
Pamięć strumieniowa
Pamięć strumieniowa działa jako bufor pośredni do przechowywania zdarzeń CDC przed ich przetworzeniem. Pamięć strumieniowa zapewnia niezawodne przechowywanie danych przesyłanych strumieniowo. Z założenia jest wysoce dostępny i odporny na awarie sprzętu lub węzłów oraz utrzymuje kolejność zdarzeń w takiej postaci, w jakiej są zapisywane. Pamięć strumieniowa może przechowywać zdarzenia danych na stałe lub przez określony czas. Umożliwia to procesorom strumieniowym odczytanie części strumienia w przypadku awarii lub konieczności ponownego przetworzenia. Kinesis Data Streams to bezserwerowa usługa przesyłania strumieniowego danych, która ułatwia przechwytywanie, przetwarzanie i przechowywanie strumieni danych na dużą skalę. Amazon MSK to w pełni zarządzana, wysoce dostępna i bezpieczna usługa świadczona przez AWS do uruchamiania Apache Kafka.
Przetwarzanie strumienia
Systemy przetwarzania strumieniowego powinny być zaprojektowane pod kątem równoległości w celu obsługi dużej przepustowości danych. Powinny podzielić strumień wejściowy pomiędzy wiele zadań uruchomionych w wielu węzłach obliczeniowych. Zadania powinny mieć możliwość przesyłania wyniku jednej operacji do drugiej poprzez sieć, umożliwiając równoległe przetwarzanie danych podczas wykonywania operacji takich jak łączenie, filtrowanie, wzbogacanie i agregacja. Aplikacje do przetwarzania strumieniowego powinny mieć możliwość przetwarzania zdarzeń w odniesieniu do czasu zdarzenia w przypadkach użycia, w których zdarzenia mogą nadejść z opóźnieniem lub prawidłowe obliczenia opierają się na czasie wystąpienia zdarzeń, a nie na czasie systemowym. Aby uzyskać więcej informacji, zobacz Pojęcia czasu: czas zdarzenia i czas przetwarzania.
Procesy strumieniowe w sposób ciągły generują wyniki w postaci zdarzeń danych, które należy przesłać do systemu docelowego. Systemem docelowym może być dowolny system, który można zintegrować bezpośrednio z procesem lub poprzez pamięć strumieniową, jak w przypadku pośrednika. W zależności od struktury wybranej do przetwarzania strumieniowego będziesz mieć różne opcje dla systemów docelowych w zależności od dostępnych złączy ujścia. Jeśli zdecydujesz się zapisać wyniki w pośrednim magazynie strumieniowym, możesz zbudować oddzielny proces, który odczytuje zdarzenia i stosuje zmiany w systemie docelowym, na przykład uruchamiając łącznik ujścia Apache Kafka. Niezależnie od tego, którą opcję wybierzesz, dane CDC wymagają dodatkowej obsługi ze względu na swój charakter. Ponieważ zdarzenia CDC niosą ze sobą informacje o aktualizacjach lub usunięciach, ważne jest, aby łączyć je w systemie docelowym we właściwej kolejności. Jeśli zmiany zostaną zastosowane w niewłaściwej kolejności, system docelowy nie będzie zsynchronizowany ze swoim źródłem.
Apache Flash to potężna platforma do przetwarzania strumieniowego, znana z niskich opóźnień i dużej przepustowości. Obsługuje przetwarzanie czasu zdarzenia, semantykę przetwarzania dokładnie raz i wysoką odporność na błędy. Dodatkowo zapewnia natywną obsługę danych CDC poprzez specjalną strukturę zwaną tabele dynamiczne. Tabele dynamiczne naśladują tabele źródłowej bazy danych i zapewniają kolumnową reprezentację danych przesyłanych strumieniowo. Dane w tabelach dynamicznych zmieniają się przy każdym przetwarzanym zdarzeniu. Nowe rekordy można dodawać, aktualizować lub usuwać w dowolnym momencie. Tabele dynamiczne eliminują dodatkową logikę, którą należy wdrożyć osobno dla każdej operacji na rekordzie (wstawianie, aktualizacja, usuwanie). Aby uzyskać więcej informacji, zobacz Tabele dynamiczne.
Z Usługa zarządzana przez Amazon dla Apache Flink, możesz uruchamiać zadania Apache Flink i integrować się z innymi usługami AWS. Nie ma serwerów ani klastrów do zarządzania, nie ma też infrastruktury obliczeniowej i pamięci masowej do skonfigurowania.
Klej AWS to w pełni zarządzana usługa wyodrębniania, przekształcania i ładowania (ETL), co oznacza, że AWS zajmuje się udostępnianiem, skalowaniem i konserwacją infrastruktury za Ciebie. Chociaż jest znany przede wszystkim ze swoich możliwości ETL, AWS Glue może być również używany w aplikacjach do przesyłania strumieniowego Spark. AWS Glue może współpracować z usługami przesyłania strumieniowego danych, takimi jak Kinesis Data Streams i Amazon MSK w celu przetwarzania i przekształcania danych CDC. AWS Glue może również bezproblemowo integrować się z innymi usługami AWS, takimi jak Lambda, Funkcje kroków AWSi DynamoDB, zapewniając kompleksowy ekosystem do tworzenia potoków przetwarzania danych i zarządzania nimi.
Ujednolicony profil klienta
Przezwyciężenie ujednolicenia profilu klienta w różnych systemach źródłowych wymaga opracowania solidnych potoków danych. Potrzebujesz potoków danych, które mogą przenosić i synchronizować wszystkie rekordy w jednym magazynie danych. Ten magazyn danych zapewnia Twojej organizacji całościowy widok rekordów klientów, który jest niezbędny do zapewnienia wydajności operacyjnej generatywnych aplikacji AI opartych na RAG. Do zbudowania takiego magazynu danych najlepszy byłby magazyn danych nieustrukturyzowanych.
Wykres tożsamości jest użyteczną strukturą do tworzenia ujednoliconego profilu klienta, ponieważ konsoliduje i integruje dane klientów z różnych źródeł, zapewnia dokładność danych i deduplikację, oferuje aktualizacje w czasie rzeczywistym, łączy spostrzeżenia między systemami, umożliwia personalizację, poprawia jakość obsługi klienta i wspiera zgodność z przepisami. Ten ujednolicony profil klienta umożliwia generatywnej aplikacji AI skuteczne zrozumienie klientów i nawiązywanie z nimi kontaktu oraz przestrzeganie przepisów dotyczących ochrony danych, co ostatecznie poprawia doświadczenia klientów i napędza rozwój firmy. Możesz zbudować rozwiązanie w postaci wykresu tożsamości, używając Amazon Neptun, szybka, niezawodna, w pełni zarządzana usługa bazy danych grafów.
AWS oferuje kilka innych zarządzanych i bezserwerowych usług przechowywania danych NoSQL dla nieustrukturyzowanych obiektów typu klucz-wartość. Amazon DocumentDB (z kompatybilnością z MongoDB) to szybkie, skalowalne, wysoce dostępne i w pełni zarządzane przedsiębiorstwo baza dokumentów usługa obsługująca natywne obciążenia JSON. DynamoDB to w pełni zarządzana usługa bazy danych NoSQL, która zapewnia szybką i przewidywalną wydajność oraz płynną skalowalność.
Aktualizacje bazy wiedzy organizacyjnej w czasie zbliżonym do rzeczywistego
Podobnie jak dane klientów, wewnętrzne repozytoria wiedzy, takie jak zasady firmy i dokumenty organizacyjne, są izolowane w systemach pamięci masowej. Są to zazwyczaj dane nieustrukturyzowane i są aktualizowane w sposób nieprzyrostowy. Wykorzystanie nieustrukturyzowanych danych w aplikacjach AI jest efektywne dzięki osadzaniu wektorów, czyli technice przedstawiania danych wielowymiarowych, takich jak pliki tekstowe, obrazy i pliki audio, w postaci wielowymiarowych liczb liczbowych.
AWS udostępnia kilka usługi silników wektorowych, Takie jak Amazon OpenSearch bez serwera, Amazonka Kendra, Wersja zgodna z Amazon Aurora PostgreSQL z rozszerzeniem pgvector do przechowywania osadzonych wektorów. Aplikacje generujące sztuczną inteligencję mogą poprawić komfort użytkownika, przekształcając monit użytkownika w wektor i wykorzystując go do wysyłania zapytań do silnika wektorowego w celu uzyskania informacji istotnych kontekstowo. Zarówno monit, jak i pobrane dane wektorowe są następnie przekazywane do LLM w celu otrzymania bardziej precyzyjnej i spersonalizowanej odpowiedzi.
Poniższy diagram ilustruje przykładowy przepływ pracy przetwarzania strumienia dla osadzania wektorów.
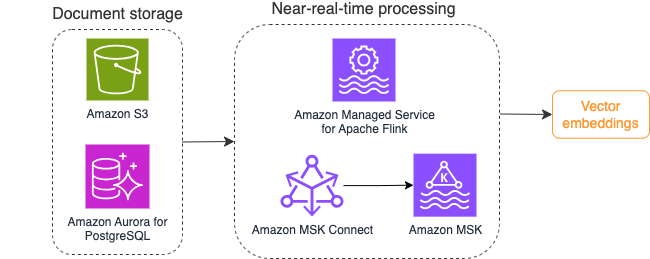
Zawartość bazy wiedzy należy przekonwertować na osadzenie wektorów przed zapisaniem w magazynie danych wektorowych. Amazońska skała macierzysta or Amazon Sage Maker może pomóc Ci uzyskać dostęp do wybranego modelu i udostępnić prywatny punkt końcowy dla tej konwersji. Ponadto można używać bibliotek takich jak LangChain do integracji z tymi punktami końcowymi. Budowanie procesu wsadowego może pomóc w przekonwertowaniu zawartości bazy wiedzy na dane wektorowe i początkowo przechowywaniu ich w wektorowej bazie danych. Musisz jednak polegać na interwałach, aby ponownie przetworzyć dokumenty, aby zsynchronizować bazę danych wektorów ze zmianami w zawartości bazy wiedzy. Przy dużej liczbie dokumentów proces ten może być nieefektywny. Pomiędzy tymi interwałami użytkownicy aplikacji generatywnej AI otrzymają odpowiedzi zgodnie ze starą treścią lub otrzymają niedokładną odpowiedź, ponieważ nowa treść nie została jeszcze wektoryzowana.
Przetwarzanie strumieniowe jest idealnym rozwiązaniem dla tych wyzwań. Początkowo generuje zdarzenia zgodnie z istniejącymi dokumentami, a następnie monitoruje system źródłowy i tworzy zdarzenie zmiany dokumentu, gdy tylko one wystąpią. Te zdarzenia mogą być przechowywane w magazynie przesyłania strumieniowego i czekać na przetworzenie przez zadanie przesyłania strumieniowego. Zadanie przesyłania strumieniowego odczytuje te zdarzenia, ładuje treść dokumentu i przekształca zawartość w tablicę powiązanych tokenów słów. Każdy token dalej przekształca się w dane wektorowe poprzez wywołanie API do osadzającego FM. Wyniki są wysyłane do przechowywania w magazynie wektorów za pośrednictwem operatora ujścia.
Jeśli używasz Amazon S3 do przechowywania dokumentów, możesz zbudować architekturę źródła zdarzeń opartą na wyzwalaczach zmiany obiektów S3 dla Lambda. Funkcja Lambda może utworzyć wydarzenie w żądanym formacie i zapisać je w pamięci strumieniowej.
Możesz także użyć Apache Flink do uruchomienia jako zadanie przesyłania strumieniowego. Apache Flink zapewnia natywny łącznik źródeł FileSystem, który może wykryć istniejące pliki i początkowo odczytać ich zawartość. Następnie może stale monitorować system plików pod kątem nowych plików i przechwytywać ich zawartość. Złącze obsługuje odczytywanie zestawu plików z rozproszonych systemów plików, takich jak Amazon S3 lub HDFS, w formacie zwykłego tekstu, Avro, CSV, Parquet i innych, a także tworzy zapis przesyłany strumieniowo. Jako usługa w pełni zarządzana, usługa zarządzana dla Apache Flink eliminuje obciążenie operacyjne związane z wdrażaniem i utrzymywaniem zadań Flink, umożliwiając skupienie się na tworzeniu i skalowaniu aplikacji do przesyłania strumieniowego. Dzięki płynnej integracji z usługami przesyłania strumieniowego AWS, takimi jak Amazon MSK lub Kinesis Data Streams, zapewnia funkcje takie jak automatyczne skalowanie, bezpieczeństwo i odporność, zapewniając niezawodne i wydajne aplikacje Flink do obsługi danych przesyłanych strumieniowo w czasie rzeczywistym.
W zależności od preferencji DevOps możesz wybrać pomiędzy strumieniami danych Kinesis lub Amazon MSK do przechowywania rekordów przesyłanych strumieniowo. Kinesis Data Streams upraszcza złożoność tworzenia niestandardowych aplikacji do przesyłania strumieniowego danych i zarządzania nimi, umożliwiając skupienie się na wyciąganiu wniosków z danych, a nie na utrzymaniu infrastruktury. Klienci korzystający z Apache Kafka często wybierają Amazon MSK ze względu na jego prostotę, skalowalność i niezawodność w nadzorowaniu klastrów Apache Kafka w środowisku AWS. Jako w pełni zarządzana usługa Amazon MSK przejmuje na siebie złożoność operacyjną związaną z wdrażaniem i utrzymaniem klastrów Apache Kafka, dzięki czemu możesz skoncentrować się na budowaniu i rozwijaniu aplikacji do przesyłania strumieniowego.
Ponieważ integracja interfejsu API RESTful odpowiada charakterowi tego procesu, potrzebna jest struktura obsługująca wzorzec wzbogacania stanowego za pośrednictwem wywołań interfejsu API RESTful w celu śledzenia błędów i ponawiania nieudanych żądań. Apache Flink to ponownie framework, który może wykonywać operacje stanowe z szybkością odpowiadającą pamięci. Aby poznać najlepsze sposoby wykonywania wywołań API za pośrednictwem Apache Flink, zobacz Typowe wzorce wzbogacania danych strumieniowych w Amazon Kinesis Data Analytics dla Apache Flink.
Apache Flink zapewnia natywne złącza ujścia do zapisywania danych w wektorowych magazynach danych, takich jak Amazon Aurora dla PostgreSQL za pomocą pgvector lub Usługa Amazon OpenSearch z VectorDB. Alternatywnie możesz umieścić dane wyjściowe zadania Flink (dane wektorowe) w temacie MSK lub strumieniu danych Kinesis. Usługa OpenSearch zapewnia obsługę natywnego pozyskiwania strumieni danych Kinesis lub tematów MSK. Aby uzyskać więcej informacji, zobacz Przedstawiamy Amazon MSK jako źródło przetwarzania Amazon OpenSearch i Ładowanie danych przesyłanych strumieniowo ze strumieni danych Amazon Kinesis.
Analiza opinii i dostrajanie
Dla menedżerów operacji na danych i programistów AI/ML ważne jest uzyskanie wglądu w wydajność aplikacji generatywnej AI i używanych FM. Aby to osiągnąć, należy zbudować potoki danych, które obliczają ważne dane kluczowych wskaźników wydajności (KPI) w oparciu o opinie użytkowników oraz różnorodne dzienniki i metryki aplikacji. Informacje te są przydatne dla interesariuszy, ponieważ pozwalają uzyskać w czasie rzeczywistym wgląd w wydajność FM, aplikację i ogólne zadowolenie użytkowników z jakości wsparcia, jakie otrzymują z Twojej aplikacji. Musisz także zbierać i przechowywać historię rozmów w celu dalszego dostrajania FM, aby poprawić jego zdolność do wykonywania zadań specyficznych dla domeny.
Ten przypadek użycia bardzo dobrze pasuje do domeny analityki strumieniowej. Twoja aplikacja powinna przechowywać każdą rozmowę w magazynie strumieniowym. Twoja aplikacja może pytać użytkowników o ocenę trafności każdej odpowiedzi i ogólne zadowolenie. Dane te mogą mieć format wyboru binarnego lub dowolny tekst. Dane te można przechowywać w strumieniu danych Kinesis lub temacie MSK i przetwarzać w celu generowania wskaźników KPI w czasie rzeczywistym. Możesz wykorzystać FM do analizy nastrojów użytkowników. FM mogą analizować każdą odpowiedź i przypisywać kategorię satysfakcji użytkownika.
Architektura Apache Flink pozwala na złożoną agregację danych w przedziałach czasowych. Zapewnia także obsługę zapytań SQL dotyczących strumienia zdarzeń danych. Dlatego używając Apache Flink, możesz szybko analizować surowe dane wejściowe użytkowników i generować KPI w czasie rzeczywistym, pisząc znane zapytania SQL. Aby uzyskać więcej informacji, zobacz Tabela API i SQL.
Z Usługa zarządzana przez Amazon dla Apache Flink Studio, możesz tworzyć i uruchamiać aplikacje do przetwarzania strumieniowego Apache Flink przy użyciu standardowych języków SQL, Python i Scala w interaktywnym notatniku. Notatniki Studio są obsługiwane przez Apache Zeppelin i wykorzystują Apache Flink jako silnik przetwarzania strumieniowego. Notebooki Studio płynnie łączą te technologie, dzięki czemu zaawansowane analizy strumieni danych są dostępne dla programistów o wszystkich umiejętnościach. Dzięki obsłudze funkcji zdefiniowanych przez użytkownika (UDF) Apache Flink umożliwia tworzenie niestandardowych operatorów w celu integracji z zasobami zewnętrznymi, takimi jak FM, w celu wykonywania złożonych zadań, takich jak analiza nastrojów. Funkcji UDF można używać do obliczania różnych wskaźników lub wzbogacania nieprzetworzonych danych opinii użytkowników o dodatkowe informacje, takie jak nastroje użytkowników. Aby dowiedzieć się więcej o tym wzorze, zob Proaktywne reagowanie na problemy klientów w czasie rzeczywistym za pomocą GenAI, Flink, Apache Kafka i Kinesis.
Dzięki usłudze zarządzanej dla Apache Flink Studio jednym kliknięciem możesz wdrożyć notatnik Studio jako zadanie przesyłania strumieniowego. Możesz użyć natywnych łączników ujścia dostarczonych przez Apache Flink, aby wysłać dane wyjściowe do wybranej pamięci lub umieścić je w strumieniu danych Kinesis lub temacie MSK. Amazonka Przesunięcie ku czerwieni i usługa OpenSearch doskonale nadają się do przechowywania danych analitycznych. Obydwa silniki zapewniają natywną obsługę pozyskiwania ze strumieni danych Kinesis i Amazon MSK za pośrednictwem oddzielnego potoku przesyłania strumieniowego do jeziora danych lub hurtowni danych w celu analizy.
Amazon Redshift wykorzystuje SQL do analizowania ustrukturyzowanych i częściowo ustrukturyzowanych danych w hurtowniach danych i jeziorach danych, korzystając ze sprzętu zaprojektowanego przez AWS i uczenia maszynowego, aby zapewnić najlepszy stosunek jakości do ceny na dużą skalę. Usługa OpenSearch oferuje możliwości wizualizacji obsługiwane przez OpenSearch Dashboards i Kibana (wersje od 1.5 do 7.10).
Możesz wykorzystać wynik takiej analizy w połączeniu z danymi wyświetlanymi przez użytkownika w celu dostrojenia FM, jeśli zajdzie taka potrzeba. SageMaker to najprostszy sposób na dostrojenie FM. Korzystanie z Amazon S3 z SageMaker zapewnia wydajną i bezproblemową integrację w celu dostrajania modeli. Amazon S3 to skalowalne i trwałe rozwiązanie do przechowywania obiektów, umożliwiające proste przechowywanie i odzyskiwanie dużych zbiorów danych, danych szkoleniowych i artefaktów modeli. SageMaker to w pełni zarządzana usługa ML, która upraszcza cały cykl życia ML. Używając Amazon S3 jako zaplecza pamięci masowej dla SageMaker, możesz skorzystać ze skalowalności, niezawodności i opłacalności Amazon S3, jednocześnie płynnie integrując go z możliwościami szkoleniowymi i wdrożeniowymi SageMaker. Ta kombinacja umożliwia efektywne zarządzanie danymi, ułatwia wspólne opracowywanie modeli i zapewnia usprawnienie i skalowalność przepływów pracy ML, co ostatecznie zwiększa ogólną elastyczność i wydajność procesu ML. Aby uzyskać więcej informacji, zobacz Dostosuj Falcona 7B i inne LLM na Amazon SageMaker za pomocą dekoratora @remote.
Dzięki złączu ujścia systemu plików zadania Apache Flink mogą dostarczać dane do Amazon S3 w plikach w otwartym formacie (takich jak JSON, Avro, Parquet i inne) jako obiekty danych. Jeśli wolisz zarządzać jeziorem danych przy użyciu transakcyjnej struktury jeziora danych (takiej jak Apache Hudi, Apache Iceberg lub Delta Lake), wszystkie te platformy udostępniają niestandardowy łącznik dla Apache Flink. Więcej szczegółów znajdziesz w Utwórz potok jeziora źródło-dane o niskim opóźnieniu za pomocą Amazon MSK Connect, Apache Flink i Apache Hudi.
Podsumowanie
W przypadku generatywnej aplikacji AI opartej na modelu RAG należy rozważyć zbudowanie dwóch systemów przechowywania danych i zbudować operacje na danych, które zapewnią ich aktualność ze wszystkimi systemami źródłowymi. Tradycyjne zadania wsadowe nie są wystarczające do przetworzenia rozmiaru i różnorodności danych potrzebnych do integracji z generatywną aplikacją AI. Opóźnienia w przetwarzaniu zmian w systemach źródłowych powodują niedokładną reakcję i zmniejszają wydajność generatywnej aplikacji AI. Przesyłanie strumieniowe danych umożliwia pozyskiwanie danych z różnych baz danych w różnych systemach. Umożliwia także wydajne przekształcanie, wzbogacanie, łączenie i agregowanie danych z wielu źródeł w czasie zbliżonym do rzeczywistego. Przesyłanie strumieniowe danych zapewnia uproszczoną architekturę danych, która umożliwia gromadzenie i przekształcanie w czasie rzeczywistym reakcji użytkowników lub komentarzy na temat odpowiedzi aplikacji, pomagając dostarczać i przechowywać wyniki w jeziorze danych w celu dostrajania modelu. Przesyłanie strumieniowe danych pomaga także optymalizować potoki danych, przetwarzając tylko zdarzenia zmian, co pozwala szybciej i efektywniej reagować na zmiany danych.
Dowiedz się więcej o: Usługi strumieniowego przesyłania danych AWS i rozpocznij tworzenie własnego rozwiązania do strumieniowego przesyłania danych.
O autorach
 Ali Alemi jest architektem rozwiązań streamingowych w AWS. Ali doradza klientom AWS w zakresie najlepszych praktyk architektonicznych i pomaga im projektować systemy danych analitycznych w czasie rzeczywistym, które są niezawodne, bezpieczne, wydajne i opłacalne. Pracuje wstecz od przypadków użycia klientów i projektuje rozwiązania danych w celu rozwiązania ich problemów biznesowych. Przed dołączeniem do AWS Ali wspierał kilku klientów z sektora publicznego i partnerów konsultingowych AWS w ich podróży do modernizacji aplikacji i migracji do chmury.
Ali Alemi jest architektem rozwiązań streamingowych w AWS. Ali doradza klientom AWS w zakresie najlepszych praktyk architektonicznych i pomaga im projektować systemy danych analitycznych w czasie rzeczywistym, które są niezawodne, bezpieczne, wydajne i opłacalne. Pracuje wstecz od przypadków użycia klientów i projektuje rozwiązania danych w celu rozwiązania ich problemów biznesowych. Przed dołączeniem do AWS Ali wspierał kilku klientów z sektora publicznego i partnerów konsultingowych AWS w ich podróży do modernizacji aplikacji i migracji do chmury.
 Imtiaz (Taz) Powiedział jest światowym liderem technologii analitycznej w AWS. Lubi kontaktować się ze społecznością we wszelkich kwestiach dotyczących danych i analiz. Można się z nim skontaktować poprzez LinkedIn.
Imtiaz (Taz) Powiedział jest światowym liderem technologii analitycznej w AWS. Lubi kontaktować się ze społecznością we wszelkich kwestiach dotyczących danych i analiz. Można się z nim skontaktować poprzez LinkedIn.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

